


L'inférence à partir de LLM affinés avec des LoRA est maintenant en version bêta ouverte
Aujourd'hui, nous sommes ravis d'annoncer que vous pouvez désormais exécuter une inférence affinée avec des LoRA sur Workers AI. Cette fonctionnalité est actuellement en bêta ouverte et disponible pour les adaptateurs LoRA préalablement formés, destinés à une utilisation avec Mistral, Gemma ou Llama 2, avec certaines limitations. Lisez notre article de blog consacré aux annonces de produits pour consulter une vue d'ensemble de notre fonctionnalité Bring Your Own (BYO) LoRAs.
Dans cet article, nous allons examiner dans le détail ce que sont l'affinage et les LoRA, vous montrer comment les utiliser sur notre plateforme Workers AI, puis nous plonger dans les aspects techniques de leur mise en œuvre sur notre plateforme.
Qu'est-ce que l'affinage ?
L'affinage est un terme général qui désigne la modification d'un modèle d'IA reposant sur l'apprentissage continu avec des données supplémentaires. L'objectif de l'affinage est d'augmenter la probabilité qu'une génération soit similaire à votre ensemble de données. Dans de nombreux scénarios d'utilisation, l'apprentissage d'un modèle en partant de zéro n'est pas une approche pratique, en raison du coût et de la durée de l'apprentissage. En affinant un modèle existant, préalablement formé, vous bénéficiez des capacités de ce dernier, tout en accomplissant également la tâche souhaitée. La technique Low-Rank Adaptation (LoRA, c'est-à-dire adaptation par modèle auxiliaire) est une méthode d'affinage spécifique qui peut être appliquée à différentes architectures de modèles, et pas uniquement aux LLM. Il est courant que les pondérations de modèles préalablement formés soient directement modifiées ou fusionnées avec des pondérations d'affinage supplémentaires dans les méthodes d'affinage traditionnelles. Un LoRA, en revanche, permet aux pondérations d'affinage et au modèle préalablement formé de rester distincts, et permet à ce dernier de rester inchangé. Le résultat final est que vous pouvez former des modèles afin qu'ils soient plus précis lors de l'exécution de tâches spécifiques, telles que la génération de code, l'adoption d'une personnalité spécifique ou la génération d'images dans un style spécifique. Vous pouvez même affiner un LLM existant, afin de comprendre des informations supplémentaires sur un sujet particulier.
L'approche consistant à conserver les pondérations du modèle de base original signifie que vous pouvez créer de nouvelles pondérations d'affinage avec une puissance de traitement relativement limitée. Vous pouvez tirer parti des modèles fondamentaux existants (tels que Llama 2, Mistral et Gemma) et les adapter à vos besoins.
Comment fonctionne l'affinage ?
Pour mieux comprendre l'affinage et la raison pour laquelle les LoRA sont si efficaces, nous devons prendre un peu de recul pour comprendre le fonctionnement des modèles d'IA. Les modèles d'IA (tels que les LLM) sont des réseaux neuronaux formés à l'aide de techniques d'apprentissage profond. Dans les réseaux neuronaux, il existe un ensemble de paramètres qui se comportent comme une représentation mathématique de la connaissance du domaine du modèle, composée de pondérations et de biais – en termes simples, de nombres. Ces paramètres sont généralement représentés sous la forme de grandes matrices de nombres. Plus un modèle comporte de paramètres, plus il est vaste ; aussi, lorsque vous voyez des modèles tels que llama-2-7b, l'indication « 7b » vous apprend que le modèle comporte 7 milliards de paramètres.
Les paramètres d'un modèle définissent son comportement. Lorsque vous formez un modèle en partant de zéro, ces paramètres commencent généralement sous la forme de nombres aléatoires. Lorsque vous formez le modèle à partir d'un ensemble de données, ces paramètres sont ajustés progressivement, jusqu'à ce que le modèle reflète l'ensemble de données et affiche le comportement recherché. Certains paramètres sont plus importants que d'autres ; nous appliquons donc une pondération que nous utilisons pour indiquer plus ou moins d'importance. Les pondérations jouent un rôle crucial dans la capacité du modèle à capturer les modèles et les relations dans les données à partir desquelles il est formé.
L'affinage traditionnel ajuste tous les paramètres du modèle formé avec un nouvel ensemble de pondérations. En tant que tel, un modèle affiné exige que nous servions le même nombre de paramètres que le modèle original, ce qui signifie que l'apprentissage et l'exécution de l'inférence avec un modèle entièrement affiné peuvent demander beaucoup de temps et nécessiter une grande quantité de calculs. En outre, de nouveaux modèles ultra-performants ou de nouvelles versions de modèles existants sont régulièrement publiés, ce qui signifie que la formation, la maintenance et le stockage de modèles entièrement affinés peuvent devenir coûteux.
Les LoRA sont une méthode d'affinage efficace
En termes très simples, les LoRA évitent de devoir ajuster les paramètres d'un modèle préalablement formé et, au lieu de cela, nous permettent d'appliquer un petit nombre de paramètres supplémentaires. Ces paramètres supplémentaires sont appliqués temporairement au modèle de base, afin de contrôler efficacement le comportement du modèle. Par rapport aux méthodes d'affinage traditionnelles, l'apprentissage de ces paramètres supplémentaires, que l'on appelle « adaptateur LoRA », demande beaucoup moins de temps et de calculs. Après l'apprentissage, nous présentons l'adaptateur LoRA sous la forme d'un fichier de modèle distinct, qui peut ensuite être intégré au modèle de base à partir duquel il a été formé. Un modèle entièrement affiné peut représenter des dizaines de gigaoctets de données, tandis que ces adaptateurs ne pèsent généralement que quelques mégaoctets. Ils sont donc beaucoup plus faciles à distribuer, et le fait de servir une inférence affinée avec un LoRA n'ajoute que quelques millisecondes de latence au temps d'inférence total.
Si vous êtes curieux de comprendre pourquoi les LoRA sont si efficaces, attachez votre ceinture ! Nous allons d'abord devoir passer par une brève leçon d'algèbre linéaire. Si vous n'avez pas repensé à ce terme depuis l'université, ne vous inquiétez pas, nous allons vous expliquer tout cela très simplement.
Montrez-moi les calculs !
Avec l'affinage traditionnel, nous pouvons prendre les pondérations d'un modèle (W0) et les modifier afin d'obtenir un nouvel ensemble de pondérations. La différence entre les pondérations du modèle original et les nouvelles pondérations est donc ΔW, qui représente la variation des pondérations. Par conséquent, un modèle ajusté comportera un nouvel ensemble de pondérations pouvant être représenté sous la forme des pondérations du modèle original ajoutées à la variation des pondérations : W0 + ΔW.
N'oubliez pas que toutes ces pondérations de modèles sont, en réalité, représentées par de grandes matrices de nombres. En mathématiques, chaque matrice possède une propriété appelée rang (r), qui caractérise le nombre de colonnes ou de lignes linéairement indépendantes dans une matrice. Lorsque les matrices ont un rang faible, elles ne comportent que quelques colonnes ou lignes « importantes » ; nous pouvons donc les décomposer ou les diviser en deux matrices plus petites, avec les paramètres les plus importants (vous pouvez rapprocher cela de la factorisation, en algèbre). Cette technique, appelée décomposition par rang, permet de réduire et simplifier considérablement les matrices, tout en conservant les éléments les plus importants. Dans le contexte de l'affinage, le rang détermine le nombre de paramètres modifiés par rapport au modèle original : plus le rang est élevé, plus l'affinage est important, ce qui offre davantage de granularité au regard du résultat.
Dans l'article original décrivant les LoRA, les chercheurs ont constaté que lorsqu'un modèle est de rang faible, la matrice représentant la variation des pondérations est également de rang faible. Par conséquent, nous pouvons appliquer la décomposition par rang à notre matrice représentant la variation des pondérations ΔW afin de créer deux matrices A, B plus petites, où ΔW = BA. Désormais, la variation du modèle peut être représentée par deux matrices de rang faible plus petites. C'est pourquoi cette méthode d'affinage est appelée « Low-Rank Adaptation » (c'est-à-dire adaptation par modèle auxiliaire).
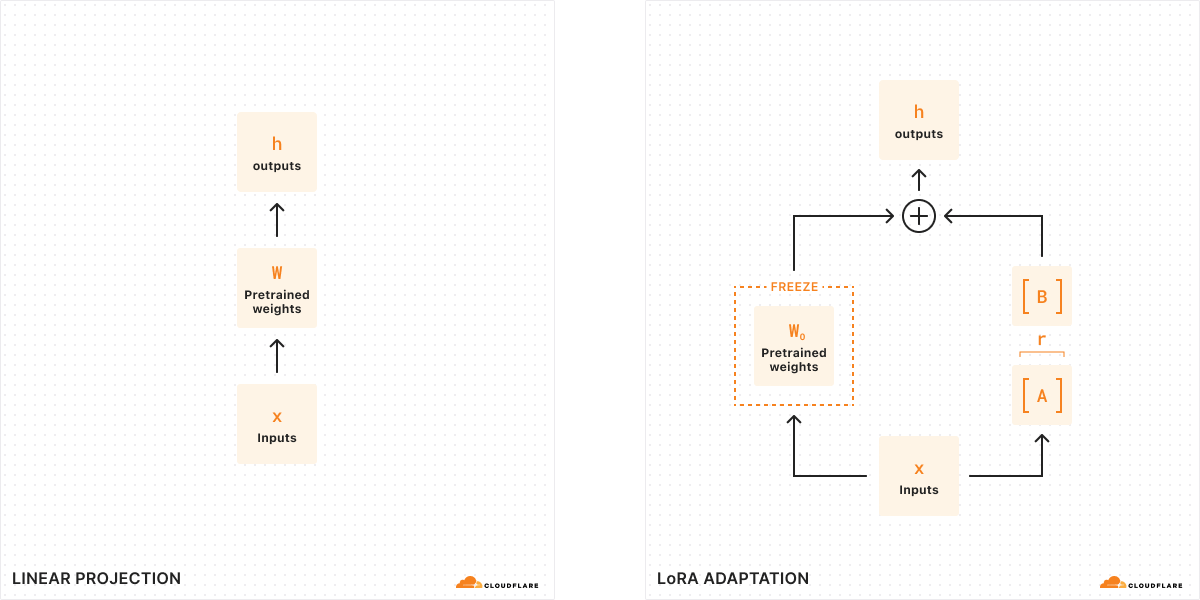
Lorsque nous exécutons une inférence, nous avons uniquement besoin des petites matrices A, B pour modifier le comportement du modèle. Les pondérations du modèle dans A, B constituent notre adaptateur LoRA (avec un fichier de configuration). Lors de l'exécution, nous additionnons les pondérations du modèle, en associant le modèle original (W0) et l'adaptateur LoRA (A, B). L'addition et la soustraction sont des opérations mathématiques simples, ce qui signifie que nous pouvons rapidement échanger différents adaptateurs LoRA en ajoutant et en soustrayant A, B de W0. En ajustant temporairement les pondérations du modèle original, nous modifions le comportement et les résultats du modèle et, par conséquent, nous obtenons une inférence affinée avec un ajout de latence minimal.
Selon l'article original décrivant les LoRA, « Les LoRA permettent de diviser par 10 000 le nombre de paramètres pouvant être formés et de diviser par 3 la quantité de mémoire GPU requise ». C'est pourquoi les LoRA constituent l'une des méthodes d'affinage les plus prisées, car ils s'avèrent, en termes de puissance de calcul, beaucoup moins coûteux qu'un modèle entièrement affiné, n'ajoutent pas de temps d'inférence matériel et sont beaucoup moins volumineux et plus portables.
Comment utiliser les LoRA avec Workers AI ?
Workers AI est très bien adapté à l'exécution de LoRA, en raison de la façon dont nous exécutons l'inférence serverless. Les modèles de notre catalogue sont toujours préchargés sur nos GPU ; cela signifie que nous les maintenons en activité, afin que vos requêtes ne se heurtent jamais à un démarrage à froid. De cette manière, le modèle de base est toujours disponible et nous pouvons charger et échanger dynamiquement les adaptateurs LoRA en fonction des besoins. En réalité, nous pouvons connecter plusieurs adaptateurs LoRA à un modèle de base, de manière à pouvoir répondre à plusieurs requêtes d'inférence affinée à la fois.
Lorsque vous effectuez un affinage avec un LoRA, vous obtenez deux fichiers : les pondérations de votre modèle personnalisé (au format safetensors) et un fichier de configuration de l'adaptateur (au format json). Pour créer vous-même ces pondérations, vous pouvez former un LoRA avec vos propres données en utilisant la bibliothèque Hugging Face PEFT (Parameter-Efficient Fine-Tuning), associée à la bibliothèque Hugging Face AutoTrain LLM. Vous pouvez également exécuter vos tâches d'apprentissage sur des services tels que Auto Train et Google Colab. Par ailleurs, de nombreux adaptateurs LoRA open source sont aujourd'hui disponibles sur Hugging Face, permettant de répondre à différents scénarios d'utilisation.
À terme, nous souhaitons proposer, sur notre plateforme, la prise en charge des charges de travail d'apprentissage de LoRA. Aujourd'hui, toutefois, nous avons besoin que vous fournissiez vous-même vos adaptateurs LoRA à Workers AI ; c'est pourquoi nous appelons cette fonctionnalité « Bring Your Own (BYO) LoRAs ».
Pour la première version bêta ouverte, nous autorisons les développeurs à utiliser les LoRA avec nos modèles Mistral, Llama 2 et Gemma. Nous avons mis de côté des versions de ces modèles qui acceptent les LoRA ; vous pouvez y accéder en ajoutant `-lora` à la fin du nom du modèle. Votre adaptateur doit avoir été affiné à partir de l'un des modèles de base pris en charge, énumérés ci-dessous :
@cf/meta-llama/llama-2-7b-chat-hf-lora@cf/mistral/mistral-7b-instruct-v0.2-lora@cf/google/gemma-2b-it-lora@cf/google/gemma-7b-it-lora
Dans la mesure où nous lançons cette fonctionnalité en version bêta ouverte, elle comporte actuellement certaines limitations que vous devez prendre en compte : les modèles LoRA quantifiés ne sont pas encore pris en charge ; la taille des adaptateurs LoRA doit être inférieure à 100 Mo, et leur rang doit être de 8 maximum ; enfin, vous pouvez essayer jusqu'à 30 LoRA par compte pendant la version bêta ouverte initiale. Pour commencer à utiliser les LoRA dans Workers AI, veuillez consulter la documentation pour développeurs.
Comme toujours, nous attendons des utilisateurs qu'ils utilisent Workers AI et notre nouvelle fonction BYO LoRA dans le respect de nos conditions d'utilisation, notamment au regard des restrictions d'utilisation spécifiques aux modèles mentionnées dans les conditions de licence des modèles.
Comment avons-nous développé la capacité de service multi-entités de modèles LoRA ?
Servir simultanément plusieurs modèles LoRA comporte certaines difficultés au regard de l'utilisation des ressources GPU. S'il est possible de grouper les requêtes d'inférence pour un modèle de base, il est beaucoup plus difficile de grouper les requêtes en présence de la complexité supplémentaire que représente le service d'adaptateurs LoRA uniques. Pour résoudre ce problème, nous nous appuyons sur l'architecture du noyau CUDA Punica et sur des optimisations globales du cache, afin de gérer la charge de travail à forte consommation de mémoire que constitue le service multi-entités d'adaptateurs LoRA, tout en offrant une faible latence d'inférence.
Le noyau CUDA Punica a été présenté dans l'article Punica: Multi-Tenant LoRA Serving ; il propose une méthode permettant de servir plusieurs modèles LoRA significativement différents, appliqués au même modèle de base. Par rapport aux techniques d'inférence précédentes, la méthode offre des améliorations considérables au regard du débit et de la latence. Cette optimisation est en partie obtenue grâce au groupement de requêtes, même avec des requêtes nécessitant le service de différents adaptateurs LoRA.
Le cœur du système de noyau Punica est un nouveau noyau CUDA, appelé Segmented Gather Matrix-Vector Multiplication (SGMV). SGMV permet à un GPU de ne stocker qu'une copie unique du modèle préalablement formé, tout en servant différents modèles LoRA. Le système d'architecture du noyau Punica consolide le groupement des requêtes de modèles LoRA uniques afin d'améliorer les performances, en parallélisant la multiplication de la pondération des caractéristiques des différentes requêtes dans un lot. Les requêtes concernant le même modèle LoRA sont ensuite groupées afin d'accroître l'intensité opérationnelle. Au départ, le GPU charge le modèle de base, tout en réservant la majeure partie de sa mémoire GPU au cache KV. Les composants LoRA (matrices A et B) sont ensuite chargés à la demande depuis un stockage distant (cache de Cloudflare ou R2) lorsqu'une requête entrante l'exige. Ce chargement à la demande entraîne une latence de quelques millisecondes seulement, ce qui signifie que plusieurs adaptateurs LoRA peuvent être recherchés et servis avec fluidité, avec un impact minimal sur les performances d'inférence. Les adaptateurs LoRA fréquemment demandés sont mis en cache afin d'offrir l'inférence la plus rapide possible.
Lorsqu'un LoRA demandé a été mis en cache localement, la vitesse à laquelle il peut être mis à disposition aux fins de l'inférence est uniquement limitée par la bande passante PCIe. Quoi qu'il en soit, étant donné que chaque requête peut nécessiter son propre LoRA, il est essentiel que les téléchargements de LoRA et les opérations de copie en mémoire soient effectués de manière asynchrone. L'ordonnanceur Punica s'attaque précisément à ce problème, en groupant uniquement les requêtes comportant les pondérations LoRA requises dans la mémoire du GPU et en mettant en file d'attente les requêtes qui en sont dépourvues jusqu'à ce que les pondérations requises soient disponibles et que la requête puisse être efficacement intégrée à un lot.
La gestion efficace du cache KV et le groupement de ces requêtes permettent de gérer d'importantes charges de travail multi-entités pour le service de LoRA. Une autre optimisation importante est l'utilisation du groupement continu. Les méthodes de groupement courantes exigent que toutes les requêtes adressées au même adaptateur atteignent leur condition d'arrêt avant d'être validées. Le groupement continu permet à une requête dans un lot d'être validée plus rapidement, et ainsi, d'éviter d'attendre la finalisation de la requête présentant le délai d'exécution le plus long.
Étant donné que les LLM déployés sur le réseau de Cloudflare sont disponibles dans le monde entier, il est important que les modèles d'adaptateurs LoRA le soient également. Nous mettrons prochainement en œuvre des fichiers de modèles distants qui seront mis en cache à la périphérie de Cloudflare, afin de réduire encore davantage la latence de l'inférence.
Une feuille de route pour l'affinage dans Workers AI
Le lancement de la prise en charge des adaptateurs LoRA est une étape importante vers la mise en œuvre des tâches d'affinage sur notre plateforme. En plus des affinages de LLM actuellement disponibles, nous espérons pouvoir prendre en charge davantage de modèles, ainsi qu'une sélection variée de types de tâches, parmi lesquelles la génération d'images.
Notre vision pour Workers AI consiste à offrir la meilleure plateforme pour l'exécution, par les développeurs, de leurs charges de travail d'IA – en incluant le processus d'affinage lui-même. À terme, nous voulons être en mesure d'exécuter la tâche d'apprentissage avec affinage, ainsi que des modèles entièrement affinés, directement dans Workers AI. Ceci permet de débloquer de nombreux scénarios d'utilisation qui rendront l'utilisation de l'IA plus pertinente au sein des entreprises, en permettant aux modèles d'offrir une granularité et un niveau de détail supérieurs pour des tâches spécifiques.
Avec AI Gateway, nous serons en mesure d'aider les développeurs à enregistrer leurs commandes et leurs réponses, qu'ils pourront ensuite utiliser pour affiner les modèles avec des données de production. Notre objectif est de proposer un service d'affinage « en un clic », où les données de journalisation d'AI Gateway peuvent être utilisées pour recommencer l'apprentissage d'un modèle (sur Cloudflare), afin que le modèle affiné puisse être ensuite déployé sur Workers AI aux fins de l'inférence. Cela permettra aux développeurs de personnaliser leurs modèles d'intelligence artificielle en fonction de leur application, avec une granularité précise, atteignant le niveau des utilisateurs individuels. Le modèle affiné peut alors être moins volumineux et plus optimisé, permettant aux utilisateurs d'économiser du temps et de l'argent sur l'inférence de l'IA – et la meilleure nouvelle est que toutes ces opérations peuvent se dérouler sur notre plateforme pour développeurs.
Nous sommes impatients de vous inviter à tester la version bêta ouverte de BYO LoRAs ! Consultez notre documentation pour développeurs pour plus de détails, et dites-nous ce que vous en pensez sur Discord.