

Introducción
Mi equipo: el equipo de PROTOCOLOS de Cloudflare se encarga de la terminación del tráfico HTTP en el perímetro de la red de Cloudflare. Nos ocupamos de las características relacionadas con lo siguiente: TCP, QUIC, TLS y la gestión de certificados seguros, HTTP/1 y HTTP/2. Durante el primer trimestre, nos encargamos de implementar la priorización optimizada de HTTP/2 que Cloudflare anunció durante la Semana de la Velocidad.
Es apasionante formar parte de este proyecto, y lo es doblemente cuando observamos los resultados, pero durante el transcurso del proyecto hemos descubierto varias cosas interesantes sobre NGINX: el servidor orientado a HTTP en el que Cloudflare actualmente implementa su infraestructura de software. Rápidamente tuvimos la certeza de que nuestro proyecto de priorización optimizada de HTTP/2 no podría ser ni siquiera moderadamente exitoso si no se cambiaba el funcionamiento interno de NGINX.
Estos descubrimientos nos llevaron a una serie de cambios significativos en la estructura interna de NGINX, paralelamente al trabajo central sobre el priorización. Esta publicación del blog describe los motivos detrás de los cambios estructurales, cómo los abordamos y qué impacto tuvieron. También identificamos otros cambios que pensamos agregar a nuestra hoja de ruta, y que esperamos que mejoren aún más el rendimiento.
Antecedentes
El objetivo de la priorización optimizada de HTTP/2 con relación al tráfico web que fluye entre un cliente y un servidor es el siguiente: proporcionar un medio para dar forma a las transmisiones en secuencia de HTTP/2 a medida que fluyen en sentido ascendente (servidor u origen) en una sola conexión HTTP/2 que fluye en sentido descendente (cliente).
La priorización optimizada de HTTP/2 permite a los propietarios de sitios y a los sistemas perimetrales de Cloudflare dictar las reglas sobre cómo se deben combinar varios objetos en la conexión HTTP/2 única: si un objeto en particular debe tener prioridad y dominar esa conexión y llegar al cliente lo antes posible, o si un grupo de objetos debe compartir de manera uniforme la capacidad de la conexión y poner más énfasis en el paralelismo.
Como resultado, la priorización optimizada de HTTP/2 permite a los propietarios de sitios abordar dos problemas que existen entre un cliente y un servidor: cómo controlar la precedencia y el orden de los objetos, y cómo usar de la mejor manera un recurso de conexión limitado, que puede estar limitado por una serie de factores como el ancho de banda, el volumen de tráfico y la carga de trabajo de la CPU en las diversas etapas de la ruta de acceso de la conexión.
¿Qué vimos?
La clave de la priorización es comparar dos o más transmisiones en secuencia HTTP/2 para determinar cuál es la trama que sigue. El proyecto de priorización optimizada de HTTP/2 necesariamente nos llevó al código base principal de NGINX, ya que nuestra intención era alterar fundamentalmente la forma en que NGINX comparaba y ponía en cola las tramas de datos HTTP/2 a medida que se reescribían al cliente.
Desde el comienzo, en la etapa de análisis, mientras investigábamos en el interior de NGINX para examinar las características que propusimos en el sitio, advertimos una serie de deficiencias en la propia estructura de NGINX, en particular: la velocidad de carga de los datos (servidor) y la velocidad de descarga (cliente) y cómo almacenaba temporalmente (en búfer) esos datos en sus diversas etapas internas. La principal conclusión de nuestro primer análisis de NGINX fue que, gran parte del fracaso se debía a que no brindaba “proximidad” a las tramas de datos de secuencia. Cualquiera de las secuencias se procesaba en la capa HTTP/2 de NGINX en sucesión aislada o las tramas de diferentes secuencias permanecían muy poco tiempo en el mismo lugar: por ejemplo, una cola compartida. El efecto neto fue una reducción de las oportunidades de comparación útil.
Acuñamos una nueva medida, poco científica, pero que resultó útil: Potencial, para describir la eficacia con la que se pueden aplicar las estrategias de priorización optimizada de HTTP/2 (o incluso la priorización de NGINX predeterminada) a los flujos de datos en cola. Potencial no es una medida de la eficacia de la priorización en sí, esa métrica se dejaría para más adelante en el proyecto, es más bien una medida de los niveles de participación durante la aplicación del algoritmo. Sencillamente, considera la cantidad de secuencias y tramas que se incluyen en una iteración de priorización, con más secuencias y más tramas que generan un mayor potencial.
Lo que pudimos ver desde el principio fue que, por defecto, NGINX mostraba un bajo Potencial: representar instrucciones de priorización desde el navegador, como es el caso en el modelo de priorización de HTTP/2 tradicional, o desde nuestro producto de priorización optimizada de HTTP/2, resultaba bastante inútil.
¿Qué hicimos?
Con el fin de mejorar los problemas específicos relacionados con el Potencial, y mejorar el rendimiento general del sistema, identificamos algunos puntos débiles que son claves en NGINX. A continuación se describirán estos puntos, sobre los que se ha trabajado y los cuales se han mejorado como parte de nuestro lanzamiento inicial de la priorización optimizada de HTTP/2, o que ahora se han diversificado en proyectos significativos propios, en los que haremos tareas de ingeniería en el curso de los próximos meses.
Recuperación de cola de escritura de trama de HTTP/2
La recuperación de la cola de escritura se envió correctamente con nuestra versión de la priorización optimizada de HTTP/2 e irónicamente, no fue un cambio al NGINX original, de hecho fue un cambio a la implementación de nuestra priorización optimizada de HTTP/2 cuando estábamos en la mitad del proyecto, y sirve como un buen ejemplo de algo que podemos llamar: conservación de datos, que es una buena manera de aumentar el Potencial.
Al igual que el NGINX original, nuestro algoritmo de priorización optimizada de HTTP/2 ubicará una cohorte de tramas de datos HTTP/2 en una cola de escritura como resultado de una iteración de las estrategias de priorización que se les aplican. El contenido de la cola de escritura estaría destinado a escribirse en la capa TLS de flujo descendente. De manera similar al NGINX original, la cola de escritura solo se puede escribir parcialmente en la capa TLS debido a la contrapresión de la conexión de red que ha alcanzado temporalmente la capacidad de escritura.
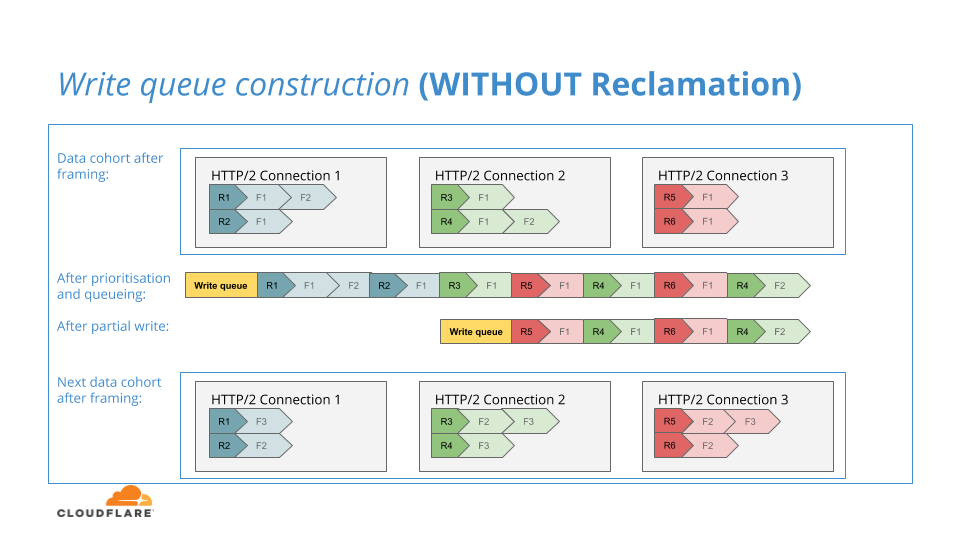
Al principio de nuestro proyecto, si la cola de escritura estaba escrita solo parcialmente en la capa TLS, simplemente dejábamos las tramas en la cola de escritura hasta que se borrara el registro, luego volvíamos a intentar escribir esos datos en la red en una iteración de escritura futura, al igual que en el NGINX original.
El NGINX original adopta este enfoque porque la cola de escritura es el único lugar donde se almacenan las tramas de datos en espera. Sin embargo, en nuestro NGINX modificado para la priorización optimizada de HTTP/2, tenemos una estructura única que no tiene el NGINX original: colas de trama de datos por secuencia donde almacenamos temporalmente tramas de datos antes de que se les apliquen nuestros algoritmos de priorización.
Nos dimos cuenta de que en el caso de una escritura parcial, podíamos restablecer las tramas no escritas en sus colas por secuencia. Si se tratara del caso en que una cohorte de datos consecutivos llegara detrás de uno escrito parcialmente, entonces las tramas no escritas previamente podrían formar parte de una ronda adicional de comparaciones de priorización, elevando así el potencial de nuestros algoritmos.
El siguiente diagrama ilustra este proceso:
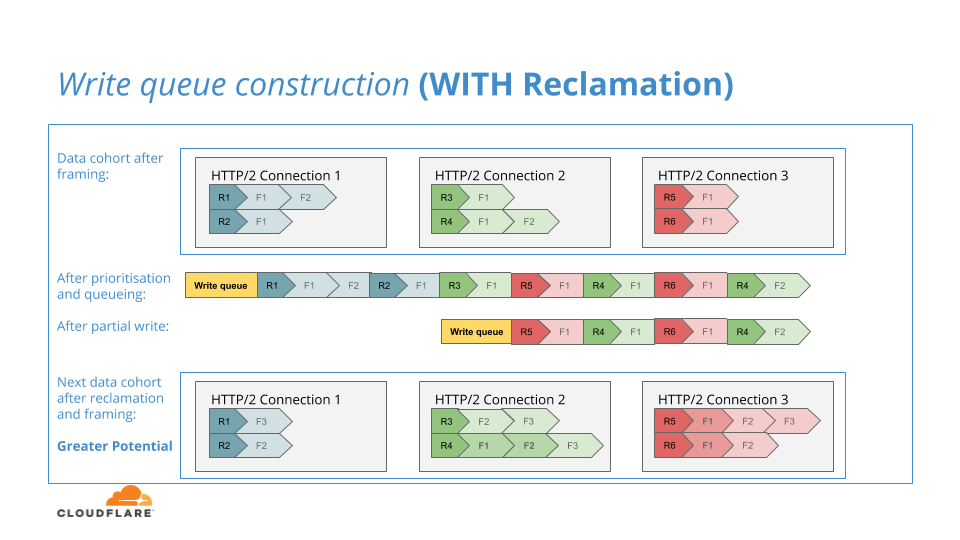
Estábamos muy contentos de enviar la priorización optimizada de HTTP/2 con la función de recuperación incluida, ya que esta única mejora aumentó en gran medida el Potencial y compensó el hecho de que teníamos que mantener oculta la próxima mejora para la semana de la velocidad debido a su sensibilidad.
Reordenación de eventos de escritura de tramas de HTTP/2
En la infraestructura de Cloudflare, asignamos las numerosas secuencias de una sola conexión HTTP/2 desde el globo ocular hasta varias conexiones HTTP/1.1 y hasta el plano de control de Cloudflare ascendente.
Nota: puede parecer contradictorio que cambiemos protocolos como este a una versión anterior, y puede parecer doblemente contradictorio cuando revelo que también inhabilitamos el HTTP keepalive o persistente en estas conexiones ascendentes, lo que da como resultado una sola transacción por conexión. Sin embargo, este arreglo ofrece una serie de ventajas, particularmente, en lo que se refiere a una mejor distribución de la carga de trabajo de la CPU.
Cuando NGINX supervisa sus conexiones HTTP/1.1 de flujo ascendente para la actividad de lectura, puede detectar legibilidad en muchas de esas conexiones y procesarlas a todas en un lote. Sin embargo, dentro de ese lote, cada una de las conexiones de flujo ascendente se procesa en forma secuencial, una por vez, de principio a fin: de lectura de conexión HTTP/1.1, a tramas en la secuencia HTTP/2, a escritura de conexión HTTP/2 a la capa TLS.
El flujo de trabajo existente de NGINX se ilustra en este diagrama:
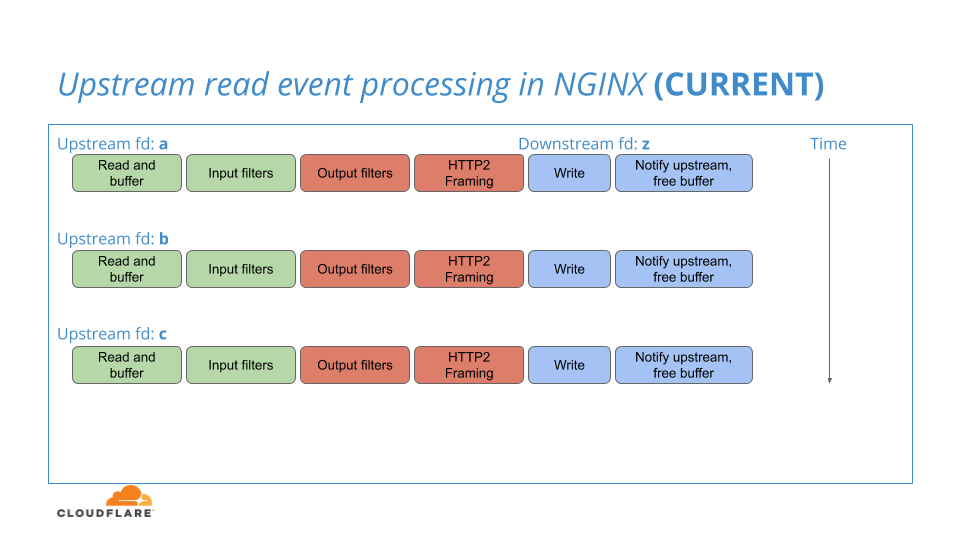
Al asignar las “tramas” de cada secuencia a la capa TLS, una secuencia por vez, muchas tramas pueden pasar totalmente a través del sistema de NGINX antes de que la contrapresión en la conexión de flujo descendente permita que la cola de tramas se acumule, lo que brinda una oportunidad para que estas tramas estén próximas y permitan que se aplique la lógica de priorización. Esto afecta de manera negativa al Potencial y reduce la eficacia de la priorización.
El NGINX modificado de la priorización optimizada de HTTP/2 de Cloudflare tiene como objetivo reorganizar el flujo de trabajo interno que se describe anteriormente en el siguiente modelo:
Si bien seguimos encuadrando datos de flujo ascendente en tramas de datos HTTP/2 en las diferentes iteraciones para cada conexión de flujo ascendente, ya no asignamos estas tramas a una sola cola de escritura en cada iteración, sino que organizamos las tramas en las colas por secuencia como se describió anteriormente. Luego publicamos un único evento al final de las iteraciones por conexión y hacemos la priorización, la cola y la escritura de las tramas de datos HTTP/2 de todas las secuencias en ese único evento.
Este único evento encuentra la cohorte de datos almacenada de manera adecuada en sus respectivas colas por secuencia, todo en estrecha proximidad, lo que aumenta considerablemente el Potencial de los algoritmos de priorización perimetral.
Más cercano al código actual, la esencia de esta modificación se ve más o menos de esta manera:
ngx_http_v2_process_data(ngx_http_v2_connection *h2_conn,
ngx_http_v2_stream *h2_stream,
ngx_buffer *buffer)
{
while ( ! ngx_buffer_empty(buffer) {
ngx_http_v2_frame_data(h2_conn,
h2_stream->frames,
buffer);
}
ngx_http_v2_prioritise(h2_conn->queue,
h2_stream->frames);
ngx_http_v2_write_queue(h2_conn->queue);
}
A esto:
ngx_http_v2_process_data(ngx_http_v2_connection *h2_conn,
ngx_http_v2_stream *h2_stream,
ngx_buffer *buffer)
{
while ( ! ngx_buffer_empty(buffer) {
ngx_http_v2_frame_data(h2_conn,
h2_stream->frames,
buffer);
}
ngx_list_add(h2_conn->active_streams, h2_stream);
ngx_call_once_async(ngx_http_v2_write_streams, h2_conn);
}
ngx_http_v2_write_streams(ngx_http_v2_connection *h2_conn)
{
ngx_http_v2_stream *h2_stream;
while ( ! ngx_list_empty(h2_conn->active_streams)) {
h2_stream = ngx_list_pop(h2_conn->active_streams);
ngx_http_v2_prioritise(h2_conn->queue,
h2_stream->frames);
}
ngx_http_v2_write_queue(h2_conn->queue);
}
Hay un alto nivel de riesgo al realizar esta modificación, ya que si bien es particularmente pequeña, estamos tomando el flujo de eventos bien establecido y depurado en NGINX y cambiándolo de manera significativa. Es como sacar una serie de piezas de Jenga de la torre y ubicarlas en otro lugar, corremos el riesgo de que se generen condiciones de carrera, fallas e incluso agujeros negros que causan bloqueos durante el procesamiento de transacciones.
Debido a este nivel de riesgo, no dimos a conocer este cambio en su totalidad durante la Semana de la Velocidad, pero continuaremos con las pruebas y los ajustes para su futuro lanzamiento.
Reutilización parcial del búfer de flujo ascendente
Nginx tiene una región de búfer interna para almacenar los datos de conexión que lee del flujo ascendente. Para empezar, este búfer está listo para usar en su totalidad. Cuando los datos se leen desde el flujo ascendente en el búfer listo, la parte del búfer que contiene los datos se pasa a la capa HTTP/2 de flujo descendente. Como HTTP/2 asume la responsabilidad de esos datos, esa parte del búfer se marca como: Ocupado y permanecerá ocupado durante el tiempo que tarde la capa HTTP/2 en escribir los datos en la capa TLS, que es un proceso que puede tardar cierto tiempo (¡en términos de informática!).
Durante este lapso de tiempo, la capa de flujo ascendente puede seguir leyendo más datos en las secciones listas restantes del búfer y continuar pasando esos datos incrementales a la capa HTTP/2 hasta que no haya secciones listas disponibles.
Cuando los datos ocupados se terminan finalmente en la capa HTTP/2, el espacio de búfer que contenía esos datos se marca como: Libre
El proceso se ilustra en este diagrama:
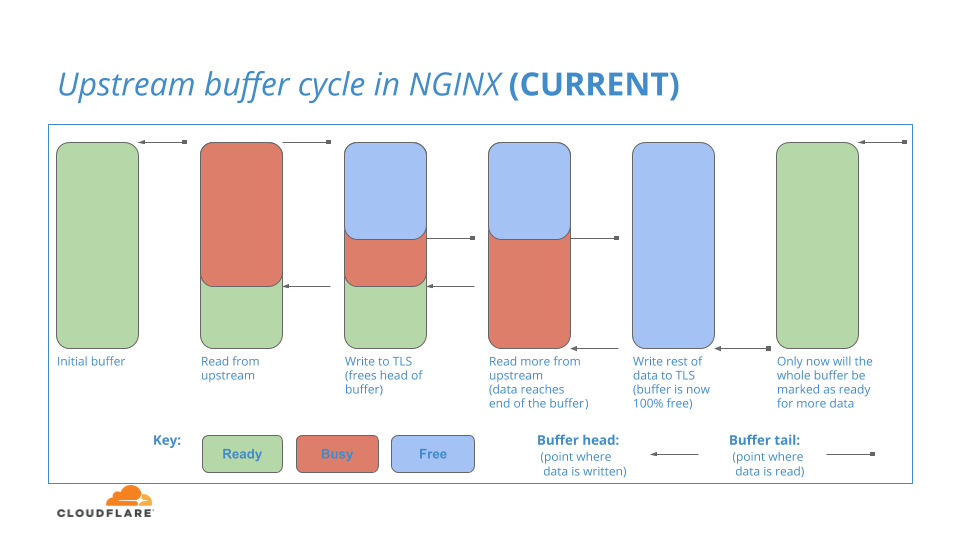
Usted puede preguntar: Cuando se marca como libre la parte principal del búfer ascendente (en azul en el diagrama), aunque la parte final del búfer ascendente todavía está ocupada, ¿se puede reutilizar la parte libre para leer más datos del flujo ascendente?
La respuesta a esta pregunta es: NO
Como solo una pequeña parte del búfer sigue ocupada, NGINX no permitirá que se vuelva a utilizar todo el espacio de búfer para las lecturas. Solo cuando la totalidad del búfer esté libre, puede volver al estado listo y utilizarse para otra iteración de lecturas de flujo ascendente. En resumen, los datos se pueden leer desde el flujo ascendente en el espacio listo en la cola del búfer, pero no en el espacio libre en la cabeza del búfer.
Se trata de una deficiencia en NGINX y es claramente algo no deseable, ya que interrumpe el flujo de datos en el sistema. Preguntamos: ¿qué pasaría si pudiéramos recorrer esta región de búfer y reutilizar las partes en la cabeza a medida que vuelven a estar libres? Esperamos poder responder esa pregunta en un futuro próximo mediante la prueba del siguiente modelo de almacenamiento en búfer en NGINX:
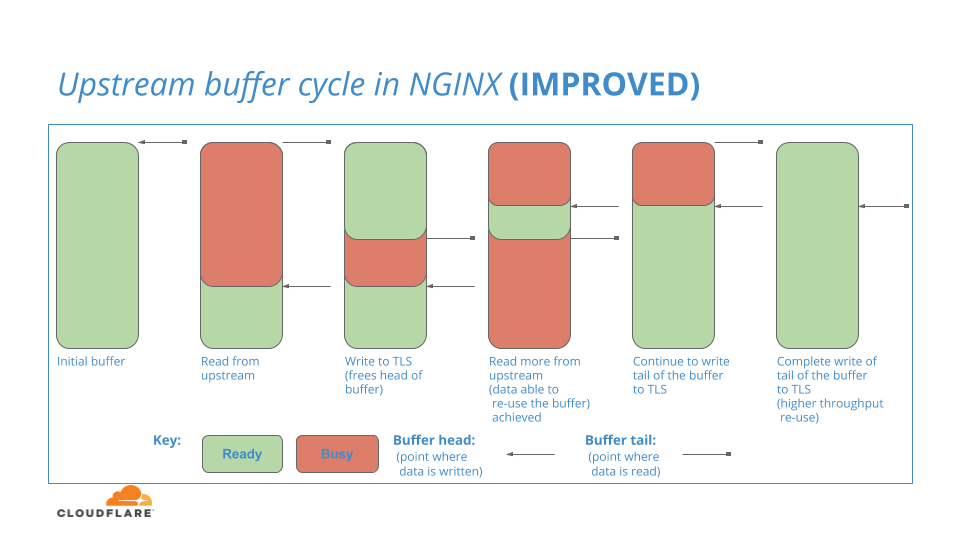
Almacenamiento en búfer de la capa TLS
En varias ocasiones en el texto anterior, he mencionado la capa TLS y cómo la capa HTTP/2 escribe datos en esta. En el modelo de red de interconexión de sistemas abiertos (OSI), TLS se encuentra justo debajo de la capa de protocolo (HTTP/2), y en muchos sistemas de software de red diseñados a conciencia como NGINX, las interfaces de software se separan de una manera que imita esta capa.
La capa HTTP/2 de NGINX recopilará la cohorte actual de tramas de datos y las colocará en orden de prioridad en una cola de salida, y luego enviará esta cola a la capa TLS. La capa TLS hace uso de un búfer por conexión para recopilar datos de capa HTTP/2 antes de hacer las transformaciones criptográficas reales en esos datos.
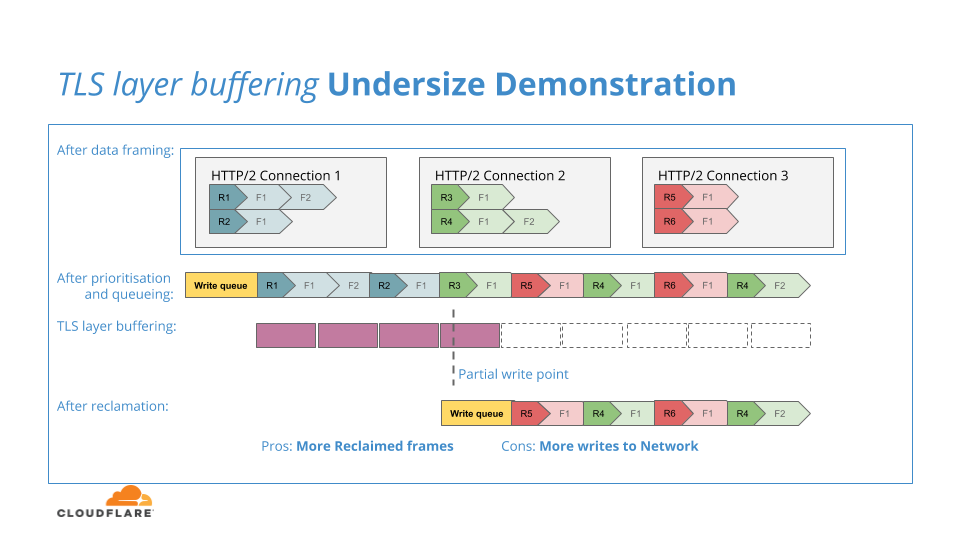
El propósito del búfer es brindar a la capa TLS una cantidad de datos más significativa para cifrar, ya que si el búfer fuera demasiado pequeño, o la capa TLS simplemente se basara en las unidades de datos de la capa HTTP/2, entonces la sobrecarga de cifrar y transmitir la gran cantidad de pequeños bloques podría afectar de manera negativa el rendimiento del sistema.
El siguiente diagrama ilustra esta situación de búfer de tamaño reducido:
Si el búfer TLS es demasiado grande, en el cifrado se conformará una cantidad excesiva de datos HTTP/2 y si no pudo escribir en la red debido a la contrapresión, se bloquearía en la capa TLS y no estaría disponible para volver a la capa HTTP/2 para el proceso de recuperación, reduciendo así la eficacia de la recuperación. El siguiente diagrama ilustra esta situación de búfer de gran tamaño:
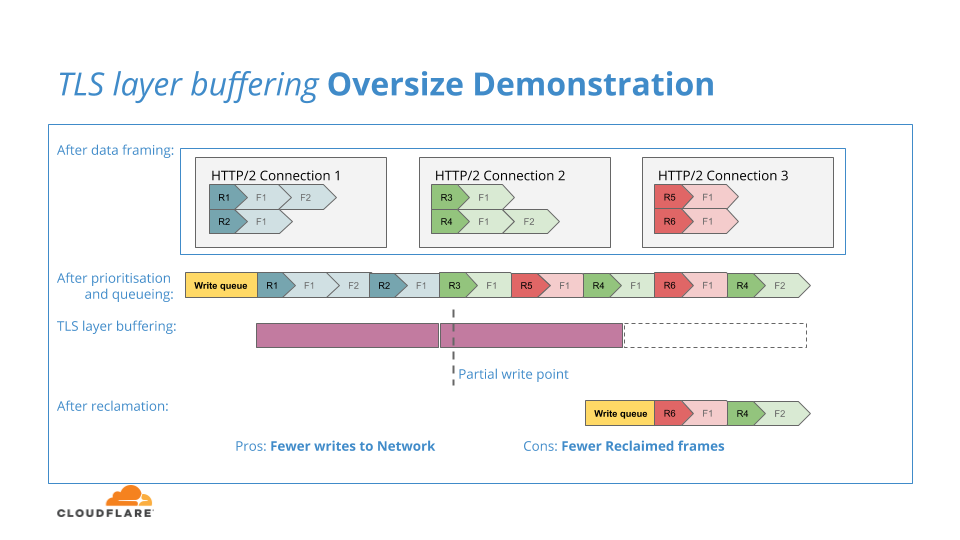
En los próximos meses, iniciaremos un proceso para intentar encontrar el punto “goldilocks” para el almacenamiento en búfer TLS: Para dimensionar el búfer TLS de modo que sea lo suficientemente grande como para mantener la eficiencia del cifrado y las escrituras de red, pero no tan grande como para disminuir la capacidad de respuesta a las escrituras de red incompletas y la eficiencia de la recuperación.
Gracias - ¡Siguiente!
El proyecto de priorización optimizada de HTTP/2 tiene, fundamentalmente, el ambicioso objetivo de remodelar la manera en que enviamos tráfico desde el perímetro de Cloudflare a los clientes, y según lo demuestran los resultados de nuestras pruebas y los comentarios de algunos de nuestros clientes, ¡ciertamente lo hemos logrado! Sin embargo, uno de los aspectos más importantes que eliminamos del proyecto fue el papel crítico que juega el flujo de datos internos dentro de nuestra infraestructura de software NGINX en la perspectiva del tráfico de nuestros usuarios finales. Descubrimos que cambiar algunas líneas de código (aunque crítico), podría tener impactos significativos en la eficacia y el rendimiento de nuestros algoritmos de priorización. Otro resultado positivo es que además de optimizar HTTP/2, deseamos aplicar las habilidades y lecciones recién adquiridas a HTTP/3 sobre QUIC.
Deseamos compartir nuestras modificaciones a NGINX con la comunidad, por lo que hemos abierto este ticket, a través del cual consideraremos subir el cambio de reordenación del evento y el cambio de la reutilización parcial del búfer con el equipo de NGINX.
Con el crecimiento de Cloudflare, también cambian los requisitos de nuestra infraestructura de software. Cloudflare ha avanzado más allá de las conexiones proxy de HTTP/1 sobre TCP para admitir las interrupciones y la protección de capa 3 y 4 para cualquier tráfico UDP y TCP. Ahora estamos avanzando hacia otras tecnologías y protocolos como QUIC y HTTP/3, y conexiones proxy plenas de una amplia variedad de otros protocolos como la mensajería y los medios de transmisión.
Para estas iniciativas buscamos nuevas formas de responder a preguntas sobre temas como la escalabilidad, el rendimiento localizado, el rendimiento a gran escala, la introspección, la depuración, la agilidad de lanzamiento y el mantenimiento.
Si desea ayudarnos a responder estas preguntas y saber un poco sobre escalabilidad de hardware y software, programación de red, diseño de software en base a eventos futuros y asincrónicos, protocolos TCP, TLS, QUIC, HTTP, y RPC, Rust ¿o tal vez algo más?, entonces dé un vistazo aquí.