
El equipo de @Cloudflare acaba de lograr un cambio que mejora significativamente el rendimiento de nuestra red, especialmente para solicitudes de valores atípicos particularmente lentos. ¿Cuánto más rápido? Estimamos que ahorramos a Internet unos 54 años *al día* del tiempo que, de otra manera, dedicaríamos a esperar que los sitios se cargaran.
- @eastdakota - 28 de junio de 2018
10 millones de sitios web, aplicaciones y API utilizan Cloudflare para proporcionar mayor velocidad a sus usuarios . En los picos, atendemos más de 10 millones de solicitudes por segundo a través de nuestros 151 centros de datos. A lo largo de los años, hemos hecho muchas modificaciones en nuestra versión de NGINX para gestionar nuestro crecimiento. Esta publicación del blog trata sobre una de ellas.
Cómo funciona NGINX
NGINX es uno de los programas que popularizó el uso de bucles de eventos para resolver el problema de C10K. Cada vez que aparece un evento de red (una nueva conexión, una solicitud, una notificación de que podemos enviar más datos, etc.) NGINX reacciona, controla el evento y luego continúa haciendo lo que debe (que puede ser gestionar otros eventos). Cuando tiene lugar un evento, los datos asociados con el evento ya están listos, lo que permite a NGINX gestionar eficientemente muchas solicitudes al mismo tiempo, sin esperar.
num_events = epoll_wait(epfd, /*returned=*/events, events_len, /*timeout=*/-1);
// events is list of active events
// handle event[0]: incoming request GET http://example.com/
// handle event[1]: send out response to GET http://cloudflare.com/
Por ejemplo, un trozo de código podría tener este aspecto al leer datos de un descriptor de archivo:
// we got a read event on fd
while (buf_len > 0) {
ssize_t n = read(fd, buf, buf_len);
if (n < 0) {
if (errno == EWOULDBLOCK || errno == EAGAIN) {
// try later when we get a read event again
}
if (errno == EINTR) {
continue;
}
return total;
}
buf_len -= n;
buf += n;
total += n;
}
Cuando fd es un socket de red, se devolverán los bytes que ya han llegado. La llamada final devolverá EWOULDBLOCK, que significa que se ha agotado el búfer de lectura local, así que no debemos leer del socket otra vez hasta que haya más datos disponibles.
El I/O del disco no es como el I/O de la red
Cuando fd es un archivo normal en Linux, nunca aparecen EWOULDBLOCK y EAGAIN, y la lectura siempre se mantiene en espera para leer el búfer completo. Esto se cumple incluso si el archivo se abre con O_NONBLOCK. Según open(2):
Ten en cuenta que este indicador no tiene ningún efecto para archivos regulares y dispositivos de bloque
En otras palabras, el código anterior se reduce básicamente a:
if (read(fd, buf, buf_len) > 0) {
return buf_len;
}
Significa que si un controlador de eventos tiene que leer desde el disco, se bloqueará el bucle de eventos hasta que se haya completado la lectura y los controladores de eventos subsecuentes se retrasarán.
Es algo adecuado para la mayoría de cargas de trabajo, porque la lectura del disco es generalmente bastante rápida y mucho más predecible en comparación con esperar a que llegue un paquete desde la red. Eso es especialmente cierto ahora que todo el mundo tiene un disco SSD, y de hecho todos nuestros discos de caché son SSD. Los SSD modernos tiene muy baja latencia, típicamente 10 s de μs. Además de eso, podemos ejecutar NGINX con múltiples procesos de trabajo para que un controlador de eventos lento no bloquee las solicitudes de otros procesos. La mayoría de las veces, podemos confiar en que NGINX gestione los eventos para dar servicio a las solicitudes de forma rápida y eficiente.
Rendimiento de SSD: no siempre es lo que pone en la etiqueta
Como imaginarás, esas previsiones tan optimistas no son siempre verdaderas. Si cada lectura siempre tardara 50 μs, entonces solo debería tomar 2 ms leer 0,19 MB en bloques de 4 KB (y se lee en bloques mayores). Pero nuestras propias mediciones demostraron que nuestro tiempo hasta el primer byte a veces es mucho peor, especialmente en los percentiles 99 y 999. En otras palabras, la lectura más lenta por 100 o por 1000 lecturas tarda a menudo mucho más tiempo.
Los SSD son muy rápidos, pero también entrañan una gran complejidad. En ellos hay equipos que hacen cola y reordenan el I/O y también realizan distintas tareas de fondo como la recolección de elementos no utilizados y la desfragmentación. De vez en cuando, una solicitud se ralentiza de manera importante. Mi colega Ivan Babrou realizó algunas pruebas de I/O y vio picos de lectura de hasta 1 segundo. Además, algunos de nuestros SSD tienen más valores atípicos de rendimiento que otros. De ahora en adelante, tendremos en cuenta la consistencia de rendimiento en nuestras compras de SSD, pero mientras tanto necesitamos contar con una solución para nuestros equipos actuales.
Distribuir la carga uniformemente con SO_REUSEPORT
Es difícil de evitar que haya una respuesta lenta individual en alguna ocasión puntual, pero lo que claramente no queremos es que un segundo de I/O bloquee otras 1000 solicitudes que se reciben en el mismo segundo. Conceptualmente, NGINX puede gestionar muchas solicitudes en paralelo, pero solo lleva a cabo un controlador de eventos cada vez. Así que añadí una métrica para valorar esto:
gettimeofday(&start, NULL);
num_events = epoll_wait(epfd, /*returned=*/events, events_len, /*timeout=*/-1);
// events is list of active events
// handle event[0]: incoming request GET http://example.com/
gettimeofday(&event_start_handle, NULL);
// handle event[1]: send out response to GET http://cloudflare.com/
timersub(&event_start_handle, &start, &event_loop_blocked);
p99 de event_loop_blocked resultó ser más del 50 % de nuestro TTFB. Es decir, la mitad del tiempo que se tarda en dar servicio a una solicitud es el resultado del bloqueo del bucle de eventos por parte de otras solicitudes. event_loop_blocked solo mide aproximadamente la mitad del bloqueo (porque las llamadas retrasadas a epoll_wait() no se miden) así que la proporción real de tiempo de bloqueo es mucho mayor.
Cada uno de nuestros equipos opera NGINX con 15 procesos de trabajo, lo que significa que un I/O lento solo bloquearía un máximo del 6 % de las solicitudes. Sin embargo, los eventos no se distribuyen uniformemente, pues el principal proceso de trabajo se encarga del 11 % de las solicitudes, el doble de lo esperado.
SO_REUSEPORT puede solucionar el problema de la distribución desigual. Marek Majkowski ha escrito anteriormente sobre la desventaja en relación a otras instancias NGINX, pero esa desventaja en su mayoría no se aplica en nuestro caso, ya que las conexiones ascendentes de nuestro proceso de caché son duraderas, por lo que una latencia ligeramente superior en la apertura de la conexión es insignificante. Este cambio de configuración individual para permitir SO_REUSEPORT mejoró el pico p99 hasta un 33 %.
Llevar read() al grupo de subprocesos no es la panacea
Una solución a esto es hacer que read() no se bloquee. De hecho, es una característica que se implementa en el canal de subida de NGINX. Cuando se utiliza la siguiente configuración, read() y write() se llevan a cabo en un grupo de subprocesos y no bloquearán el bucle de eventos:
aio threads;
aio_write on;
Sin embargo, cuando probamos esto, en lugar de una mejora en 33 veces del tiempo de respuesta, en realidad vimos un ligero aumento en p99. La diferencia estaba en el margen de error, pero el resultado nos desanimó bastante y dejamos de intentar esta opción durante un tiempo.
Hay algunas razones por las que no vimos el nivel de mejoras de NGINX. En la prueba, se utilizaban 200 conexiones simultáneas para solicitar archivos de 4 MB de tamaño que se almacenaban en los discos giratorios. Los discos giratorios aumentan la latencia de I/O, así que es lógico que una optimización que ayuda a la latencia surta un mayor efecto.
También nos preocupa especialmente el rendimiento con p99 y p999. Las soluciones que ayudan al rendimiento promedio no necesariamente sirven para los valores atípicos.
Por último, en nuestro entorno, los tamaños de archivo típicos son mucho menores. 90 % de nuestros aciertos de caché son de archivos menores de 60 KB. Los archivos más pequeños implican menos ocasiones de bloqueo (por lo general, leemos el archivo entero en dos lecturas).
Si nos fijamos en el I/O del disco que un acierto de caché tiene que hacer:
// we got a request for https://example.com which has cache key 0xCAFEBEEF
fd = open("/cache/prefix/dir/EF/BE/CAFEBEEF", O_RDONLY);
// read up to 32KB for the metadata as well as the headers
// done in thread pool if "aio threads" is on
read(fd, buf, 32*1024);
32 KB no es una cantidad estática; si los cabeceros son pequeños, tenemos que leer apenas 4 KB (no usamos IO directo así que el kernel redondeará hasta 4 KB). El open() parece inofensivo, pero en realidad no sale gratis. Como mínimo, el kernel necesita comprobar si el archivo existe y si el proceso de llamada tiene permiso para abrirlo. Para eso, tendría que encontrar el inodo de /cache/prefix/dir/EF/BE/CAFEBEEF y para ello tendría que buscar CAFEBEEF en /cache/prefijo/dir/EF/BE/. En resumen, en el peor de los casos el kernel tiene que hacer las siguientes búsquedas:
/cache
/cache/prefix
/cache/prefix/dir
/cache/prefix/dir/EF
/cache/prefix/dir/EF/BE
/cache/prefix/dir/EF/BE/CAFEBEEF
¡Son seis lecturas por separado hechas por open() en comparación con solo una lectura realizada por read()! Afortunadamente, casi siempre las búsquedas se realizan a través de la caché dentry y no requieren remitirse a la SSD. Pero, claramente, llevar a cabo read() en el grupo de subprocesos no lo es todo.
El golpe de gracia: open() sin bloqueo en el grupo de subprocesos
Así que modifiqué NGINX para hacer la mayor parte de open() dentro del grupo de subprocesos para que no bloqueara el bucle de eventos. Y el resultado es open sin bloqueo y read sin bloqueo:
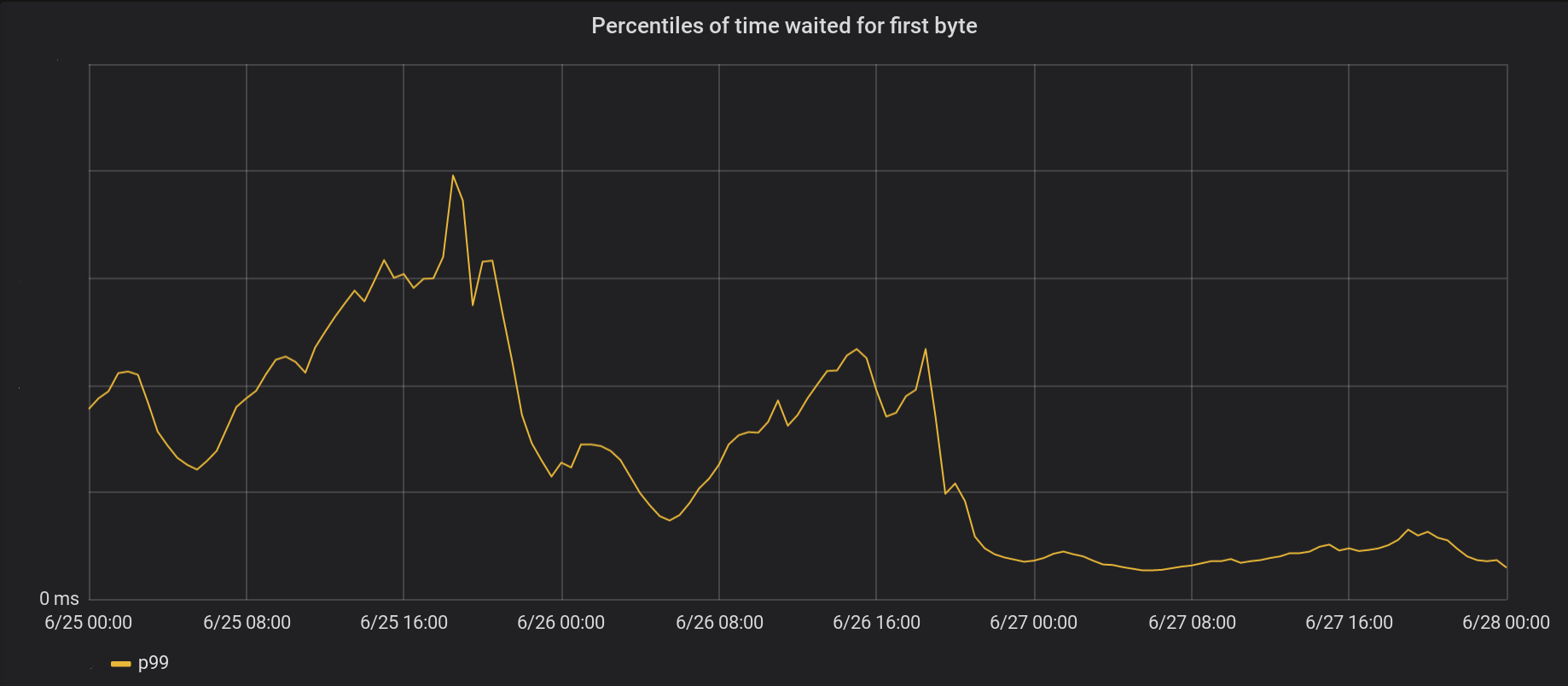
El 26 de junio implantamos nuestros cambios en cinco de nuestros centros de datos más activos, seguidos de un amplio lanzamiento al día siguiente. El pico general p99 de TTFB mejoró en seis veces. De hecho, sumando todo el tiempo de procesamiento de ocho millones de solicitudes por segundo, ahorramos a Internet 54 años de espera todos los días.
Hemos enviado nuestro trabajo al canal de subida. Los interesados pueden seguirnos.
Nuestra gestión del bucle de eventos todavía no está completamente libre de bloqueos. En particular, nos bloqueamos cuando almacenamos en caché un archivo por primera vez (tanto en open(O_CREAT) como rename()), o haciendo actualizaciones de revalidación. Sin embargo, son casos raros en comparación con los aciertos de caché. En el futuro, consideraremos dejarlos fuera del bucle de eventos para mejorar la latencia de la p99.
Conclusión
NGINX es una plataforma potente, pero escalar cargas extremadamente altas de I/O en Linux puede ser difícil. El canal de subida de NGINX puede descargar en procesos separados, pero a nuestra escala a menudo tenemos que ir un paso más allá. Si te atrae trabajar en problemas desafiantes de rendimiento, envía tu solicitud para unirte a nuestro equipo en San Francisco, Londres, Austin o Champaign.