
A veces, a nivel interno, a nuestro equipo de mitigación de DDoS se lo llama “packet droppers” (eliminadores de paquetes). Cuando otros equipos desarrollan productos interesantes para hacer cosas inteligentes con el tráfico que pasa a través de nuestra red, nos divertimos al tratar de descubrir nuevas formas de descartarlos.

La capacidad de descartar paquetes de manera rápida es muy importante para resistir los ataques DDoS.
La eliminación de paquetes que afectan a nuestros servidores, tan simple como suena, se puede hacer en varias capas. Cada técnica tiene sus ventajas y limitaciones. En esta publicación de blog, analizaremos todas las técnicas que hemos probado hasta ahora.
Banco de pruebas
Para ilustrar el rendimiento relativo de los métodos, mostraremos algunas cifras. Los parámetros son sintéticos, de manera que hay que tomar las cifras con cautela. Usaremos uno de nuestros servidores Intel, con una tarjeta de red de 10 Gbps. Los detalles de hardware no son demasiado importantes, ya que las pruebas están preparadas para mostrar las limitaciones del sistema operativo, no del hardware.
Nuestra configuración de pruebas se prepara de la siguiente manera:
- Transmitimos una gran cantidad de paquetes pequeños del protocolo de datagramas del usuario (UDP) y se alcanzan 14Mpps (millones de paquetes por segundo).
- Este tráfico se dirige hacia una sola CPU en un servidor de destino.
- Medimos la cantidad de paquetes que administra el núcleo en esa CPU.
No estamos tratando de maximizar la velocidad de la aplicación del espacio del usuario, ni la tasa de transferencia efectiva de los paquetes, sino que tratamos de mostrar específicamente los cuellos de botella del núcleo.
El tráfico sintético está preparado para poner el máximo esfuerzo en el seguimiento de conexiones (conntrack). Utiliza el IP de origen aleatorio y los campos de puerto. Tcpdump lo mostrará de la siguiente manera:
$ tcpdump -ni vlan100 -c 10 -t udp and dst port 1234
IP 198.18.40.55.32059 > 198.18.0.12.1234: UDP, length 16
IP 198.18.51.16.30852 > 198.18.0.12.1234: UDP, length 16
IP 198.18.35.51.61823 > 198.18.0.12.1234: UDP, length 16
IP 198.18.44.42.30344 > 198.18.0.12.1234: UDP, length 16
IP 198.18.106.227.38592 > 198.18.0.12.1234: UDP, length 16
IP 198.18.48.67.19533 > 198.18.0.12.1234: UDP, length 16
IP 198.18.49.38.40566 > 198.18.0.12.1234: UDP, length 16
IP 198.18.50.73.22989 > 198.18.0.12.1234: UDP, length 16
IP 198.18.43.204.37895 > 198.18.0.12.1234: UDP, length 16
IP 198.18.104.128.1543 > 198.18.0.12.1234: UDP, length 16En el destino, todos los paquetes serán remitidos exactamente a una cola RX, por lo tanto una CPU. Hacemos esto con el control de flujo por hardware:
ethtool -N ext0 flow-type udp4 dst-ip 198.18.0.12 dst-port 1234 action 2
La evaluación comparativa siempre es difícil. Al preparar las pruebas, aprendimos que tener sockets activos sin procesar arruina el rendimiento. Es obvio en retrospectiva, pero suele pasarse por alto. Antes de ejecutar cualquier prueba, asegúrese de no tener ningún proceso tcpdump obsoleto en ejecución. Esta es la manera de comprobarlo, mostrando un proceso activo defectuoso:
$ ss -A raw,packet_raw -l -p|cat
Netid State Recv-Q Send-Q Local Address:Port
p_raw UNCONN 525157 0 *:vlan100 users:(("tcpdump",pid=23683,fd=3))Por último, desactivaremos la función Intel Turbo Boost en el equipo:
echo 1 | sudo tee /sys/devices/system/cpu/intel_pstate/no_turbo
Si bien Turbo Boost mejora el rendimiento en al menos un 20%, también empeora considerablemente la desviación estándar en nuestras pruebas. Con Turbo activado, tuvimos una desviación de ±1,5% en nuestras cifras. Con Turbo desactivado, la desviación se reduce a un 0,25%, cifra que resulta controlable.
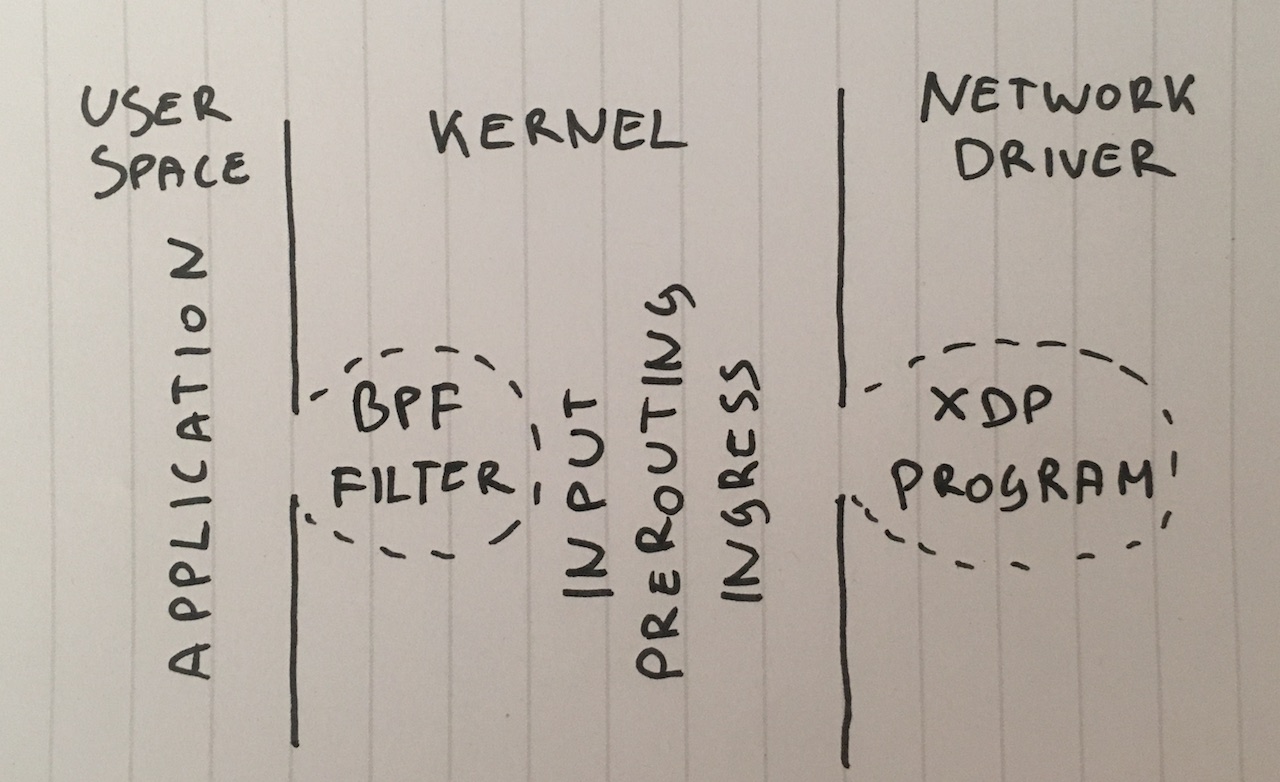
Paso 1. Eliminación de paquetes en la aplicación
Comencemos con la idea de enviar paquetes a una aplicación e ignorarlos en el código del espacio de usuario. Para la configuración de prueba, verifiquemos que nuestro iptables no afecte al rendimiento:
iptables -I PREROUTING -t mangle -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
iptables -I INPUT -t filter -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
El código de la aplicación es un bucle simple, que recibe datos e inmediatamente los descarta en el espacio de usuario:
s = socket.socket(AF_INET, SOCK_DGRAM)
s.bind(("0.0.0.0", 1234))
while True:
s.recvmmsg([...])Preparamos el código para ejecutarlo:
$ ./dropping-packets/recvmmsg-loop
packets=171261 bytes=1940176Esta configuración permite que el núcleo reciba un escaso 175kpps de la cola de recepción de hardware, medido por ethtooly utilizando nuestra sencilla herramienta mmwatch:
$ mmwatch 'ethtool -S ext0|grep rx_2'
rx2_packets: 174.0k/sEl hardware técnicamente quita 14Mpps del cable, pero es imposible pasarlo todo a una sola cola RX administrada por un solo núcleo de CPU que realiza el trabajo del núcleo. mpstat confima esto:
$ watch 'mpstat -u -I SUM -P ALL 1 1|egrep -v Aver'
01:32:05 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
01:32:06 PM 0 0.00 0.00 0.00 2.94 0.00 3.92 0.00 0.00 0.00 93.14
01:32:06 PM 1 2.17 0.00 27.17 0.00 0.00 0.00 0.00 0.00 0.00 70.65
01:32:06 PM 2 0.00 0.00 0.00 0.00 0.00 100.00 0.00 0.00 0.00 0.00
01:32:06 PM 3 0.95 0.00 1.90 0.95 0.00 3.81 0.00 0.00 0.00 92.38
Como se puede observar, el código de la aplicación no es un cuello de botella, utiliza 27% del sistema + 2% de espacio de usuario en CPU #1, mientras que la red SOFTIRQ en CPU #2 utiliza el 100% de los recursos.
Por cierto, el uso de recvmmsg(2) es importante. En estos días posteriores a Spectre, las llamadas del sistema se encarecieron más y, de hecho, ejecutamos el núcleo 4.14 con KPTI y retpolines:
$ tail -n +1 /sys/devices/system/cpu/vulnerabilities/*
==> /sys/devices/system/cpu/vulnerabilities/meltdown <==
Mitigation: PTI
==> /sys/devices/system/cpu/vulnerabilities/spectre_v1 <==
Mitigation: __user pointer sanitization
==> /sys/devices/system/cpu/vulnerabilities/spectre_v2 <==
Mitigation: Full generic retpoline, IBPB, IBRS_FWPaso 2. Destrucción del seguimiento de conexiones (conntrack)
Diseñamos específicamente la prueba, mediante la elección de IP y puertos de origen aleatorios, para poner el acento en la capa de conntrack. Esto se puede verificar al observar la cantidad de entradas de conntrack, que durante la prueba alcanzan el máximo:
$ conntrack -C
2095202
$ sysctl net.netfilter.nf_conntrack_max
net.netfilter.nf_conntrack_max = 2097152También puede observar el seguimiento de conexiones (conntrack) en dmesg:
[4029612.456673] nf_conntrack: nf_conntrack: table full, dropping packet
[4029612.465787] nf_conntrack: nf_conntrack: table full, dropping packet
[4029617.175957] net_ratelimit: 5731 callbacks suppressed
Para acelerar nuestras pruebas, lo desactivaremos:
iptables -t raw -I PREROUTING -d 198.18.0.12 -p udp -m udp --dport 1234 -j NOTRACK
Y vuelva a ejecutar las pruebas:
$ ./dropping-packets/recvmmsg-loop
packets=331008 bytes=5296128Esto instantáneamente aumenta el rendimiento de recepción de la aplicación a 333kpps. ¡Bravo!
PS. Con SO_BUSY_POLL podemos aumentar las cifras a 470k pps, pero trataremos este tema en otro momento.
Paso 3. Eliminación del BPF en un socket
Si vamos aún más allá, ¿por qué enviar paquetes a la aplicación de espacio de usuario? Si bien esta técnica es poco común, podemos adjuntar un filtro BPF clásico a un socket SOCK_DGRAM con setsockopt( SO_ATTACH_FILTER ) y programar el filtro para descartar paquetes en el espacio del núcleo.
Consulte el código para ejecutarlo:
$ ./bpf-drop
packets=0 bytes=0Con las eliminaciones en el BPF (tanto el clásico como el eBPF extendido tienen un rendimiento similar) procesamos aproximadamente 512 kpps. Todos ellos se eliminan en el filtro BPF mientras están todavía en el modo de interrupción de software, lo que genera un ahorro de la CPU necesaria para activar la aplicación del espacio de usuario.
Paso 4. ELIMINACIÓN de iptables después del enrutamiento
Como paso siguiente, simplemente podemos eliminar paquetes en la cadena de ENTRADA de firewall de iptables mediante la adición de una regla como la siguiente:
iptables -I INPUT -d 198.18.0.12 -p udp --dport 1234 -j DROP
Recuerde que ya hemos desactivado conntrack con -j NOTRACK. Estas dos reglas nos proporcionan 608kpps.
Los números en los contadores de iptables:
$ mmwatch 'iptables -L -v -n -x | head'
Chain INPUT (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
605.9k/s 26.7m/s DROP udp -- * * 0.0.0.0/0 198.18.0.12 udp dpt:1234
¡600kpps no está mal, pero podemos hacerlo mejor!
Paso 5. ELIMINACIÓN de iptables ANTES DEL ENRUTAMIENTO
Una técnica aún más rápida es la eliminación de los paquetes antes de enrutarlos. Esta regla puede hacer lo siguiente:
iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j DROP
Esto produce un total de 1.688mpps.
Este es un salto bastante significativo en el rendimiento, no lo entiendo del todo. O bien nuestra capa de enrutamiento es inusualmente compleja o hay un error en nuestra configuración de servidor.
En cualquier caso, la tabla de iptables “sin formato” es definitivamente mucho más rápida.
Paso 6. ELIMINACIÓN de nftables antes de CONNTRACK
En estos días, iptables es parte del pasado. La novedad es nftables. Mire estevideo para obtener una explicación técnica de por qué nftables es superior. Nftables promete más velocidad que la anterior iptables por muchas razones, entre ellas hay un rumor de que retpolines (también conocida como: sin ejecución especulativa para saltos indirectos) perjudica bastante a iptables.
Como el objetivo de este artículo no es comparar la velocidad de nftables con la de iptables, solo probaremos la eliminación más rápida que encontré:
nft add table netdev filter
nft -- add chain netdev filter input { type filter hook ingress device vlan100 priority -500 \; policy accept \; }
nft add rule netdev filter input ip daddr 198.18.0.0/24 udp dport 1234 counter drop
nft add rule netdev filter input ip6 daddr fd00::/64 udp dport 1234 counter drop
Los contadores se pueden ver con este comando:
$ mmwatch 'nft --handle list chain netdev filter input'
table netdev filter {
chain input {
type filter hook ingress device vlan100 priority -500; policy accept;
ip daddr 198.18.0.0/24 udp dport 1234 counter packets 1.6m/s bytes 69.6m/s drop # handle 2
ip6 daddr fd00::/64 udp dport 1234 counter packets 0 bytes 0 drop # handle 3
}
}El enlace “ingress” (entrada) de nftables se conecta aproximadamente a 1.53mpps. Esto es ligeramente más lento que iptables en la capa de PREENRUTAMIENTO. Esto resulta desconcertante, teóricamente la “entrada” ocurre antes del PREENRUTAMIENTO, por lo tanto, debería ser más veloz.
En nuestra prueba, nftables fue un poco más lento que iptables, pero no demasiado. Nftables es aún mejor :P
Paso 7. ELIMINACIÓN de controlador de entrada de tc (control de tráfico)
El hecho sorprendente es que un enlace de entrada de tc (control de tráfico) ocurra incluso antes del PREENRUTAMIENTO. tc hace los posible por seleccionar paquetes en función de criterios básicos y, de hecho, los elimina. La sintaxis es bastante torpe, por lo que se recomienda utilizar este script para configurarla. Necesitamos una coincidencia de tc un poco más compleja, esta es la línea de comandos:
tc qdisc add dev vlan100 ingress
tc filter add dev vlan100 parent ffff: prio 4 protocol ip u32 match ip protocol 17 0xff match ip dport 1234 0xffff match ip dst 198.18.0.0/24 flowid 1:1 action drop
tc filter add dev vlan100 parent ffff: protocol ipv6 u32 match ip6 dport 1234 0xffff match ip6 dst fd00::/64 flowid 1:1 action drop
Podemos verificarla:
$ mmwatch 'tc -s filter show dev vlan100 ingress'
filter parent ffff: protocol ip pref 4 u32
filter parent ffff: protocol ip pref 4 u32 fh 800: ht divisor 1
filter parent ffff: protocol ip pref 4 u32 fh 800::800 order 2048 key ht 800 bkt 0 flowid 1:1 (rule hit 1.8m/s success 1.8m/s)
match 00110000/00ff0000 at 8 (success 1.8m/s )
match 000004d2/0000ffff at 20 (success 1.8m/s )
match c612000c/ffffffff at 16 (success 1.8m/s )
action order 1: gact action drop
random type none pass val 0
index 1 ref 1 bind 1 installed 1.0/s sec
Action statistics:
Sent 79.7m/s bytes 1.8m/s pkt (dropped 1.8m/s, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
Un enlace de entrada de tc que coincide con u32 nos permite eliminar 1.8mpps en una sola CPU. ¡Esto es genial!
Pero podemos ir aún más rápido...
Paso 8. XDP_DROP
Por último, el arma fundamental es XDP - eXpress Data Path. Con XDP podemos ejecutar el código eBPF en el contexto de un controlador de red. Lo más importante, es que esto es anterior a la asignación de memoriaskbuff, lo que permite grandes velocidades.
Por lo general, los proyectos XDP tienen dos partes:
- el código eBPF cargado en el contexto del núcleo
- el cargador de espacio de usuario, que carga el código en la tarjeta de red correcta y lo administra
Desarrollar el cargador es bastante difícil, así que en su lugar podemos usar la nuevafuncióniproute2 y cargar el código con este comando trivial:
ip link set dev ext0 xdp obj xdp-drop-ebpf.o
¡Y listo!
El código fuente para el programa eBPF de XDP cargado está disponible aquí. El programa analiza los paquetes de IP y busca las características deseadas: Transporte IP, protocolo UDP, subred de destino deseada y puerto de destino:
if (h_proto == htons(ETH_P_IP)) {
if (iph->protocol == IPPROTO_UDP
&& (htonl(iph->daddr) & 0xFFFFFF00) == 0xC6120000 // 198.18.0.0/24
&& udph->dest == htons(1234)) {
return XDP_DROP;
}
}El programa XDP debe compilarse con un clang moderno que pueda emitir código de bytes BPF. Después de esto podemos cargar y verificar el programa XDP en ejecución:
$ ip link show dev ext0
4: ext0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 xdp qdisc fq state UP mode DEFAULT group default qlen 1000
link/ether 24:8a:07:8a:59:8e brd ff:ff:ff:ff:ff:ff
prog/xdp id 5 tag aedc195cc0471f51 jited
Y ver los números en las estadísticas de la tarjeta de red ethtool-S:
$ mmwatch 'ethtool -S ext0|egrep "rx"|egrep -v ": 0"|egrep -v "cache|csum"'
rx_out_of_buffer: 4.4m/s
rx_xdp_drop: 10.1m/s
rx2_xdp_drop: 10.1m/s
¡Guau! Con XDP podemos eliminar 10 millones de paquetes por segundo en una sola CPU.

Resumen
Repetimos esto para IPv4 e IPv6 y preparamos este gráfico:
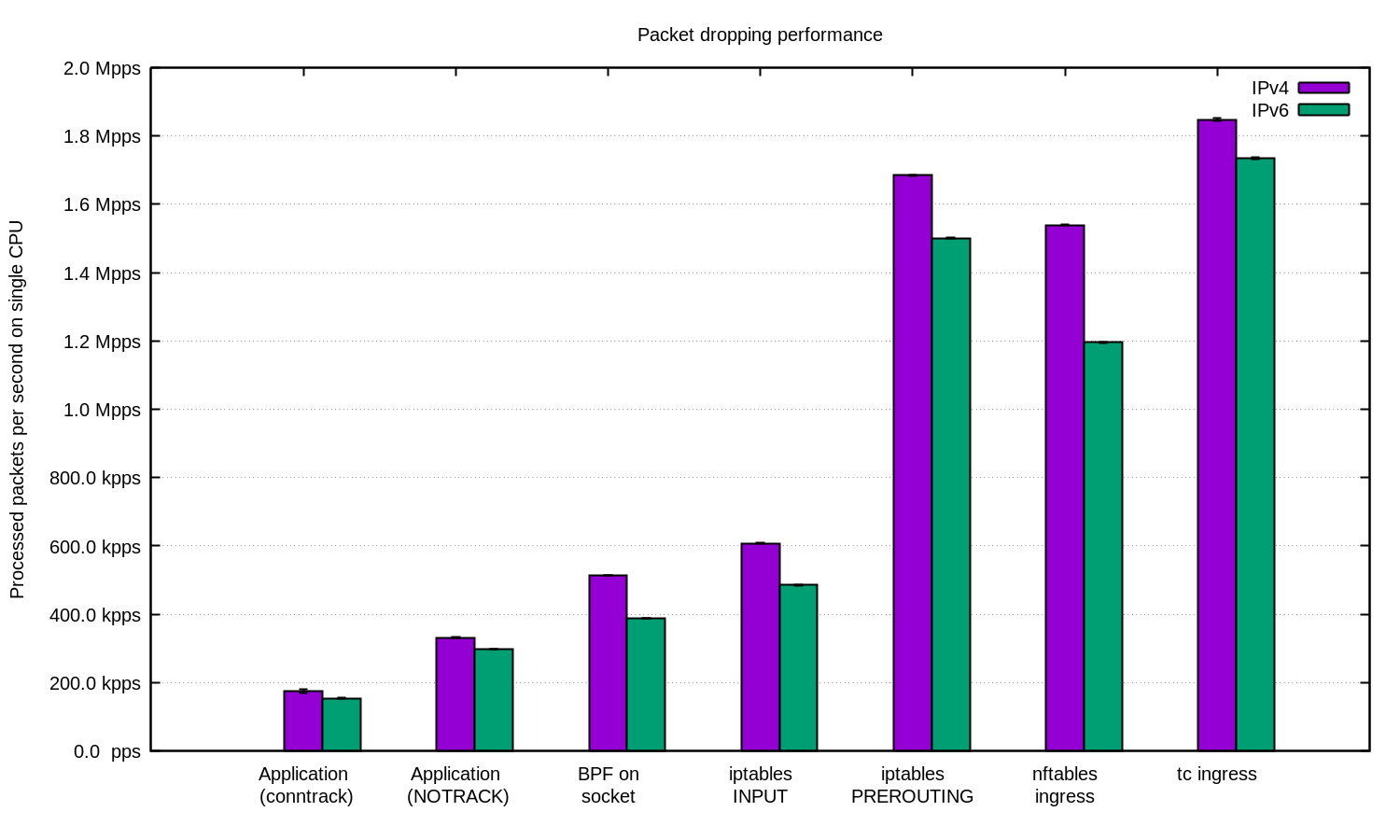
En términos generales, en nuestra configuración IPv6 tenía un rendimiento ligeramente menor. Recuerde que los paquetes IPv6 son ligeramente más grandes, por lo tanto, es inevitable cierta diferencia de rendimiento.
Linux tiene varios enlaces que se pueden utilizar para filtrar paquetes, cada uno con diferente rendimiento y características fáciles de usar.
A los fines de DDoS, puede ser totalmente razonable simplemente recibir los paquetes en la aplicación y procesarlos en el espacio de usuario. Las aplicaciones correctamente ajustadas pueden obtener cifras bastante aceptables.
Para los ataques DDoS con IP de origen aleatorio /falsificado, podría valer la pena desactivar conntrack para ganar algo de velocidad. Sin embargo, tenga cuidado, conntrack es muy útil para combatir ciertos ataques.
En otras circunstancias, puede tener sentido integrar el firewall de Linux en la canalización de mitigación de DDoS. En tales casos, recuerde poner las mitigaciones en una capa “-t raw PREROUTING”, ya que es significativamente más rápida que la tabla “filtro”.
Para cargas de trabajo aún más exigentes, siempre contamos con XDP. Y vaya si es potente. Este es el mismo gráfico que se mostró anteriormente, pero ahora incluye XDP:
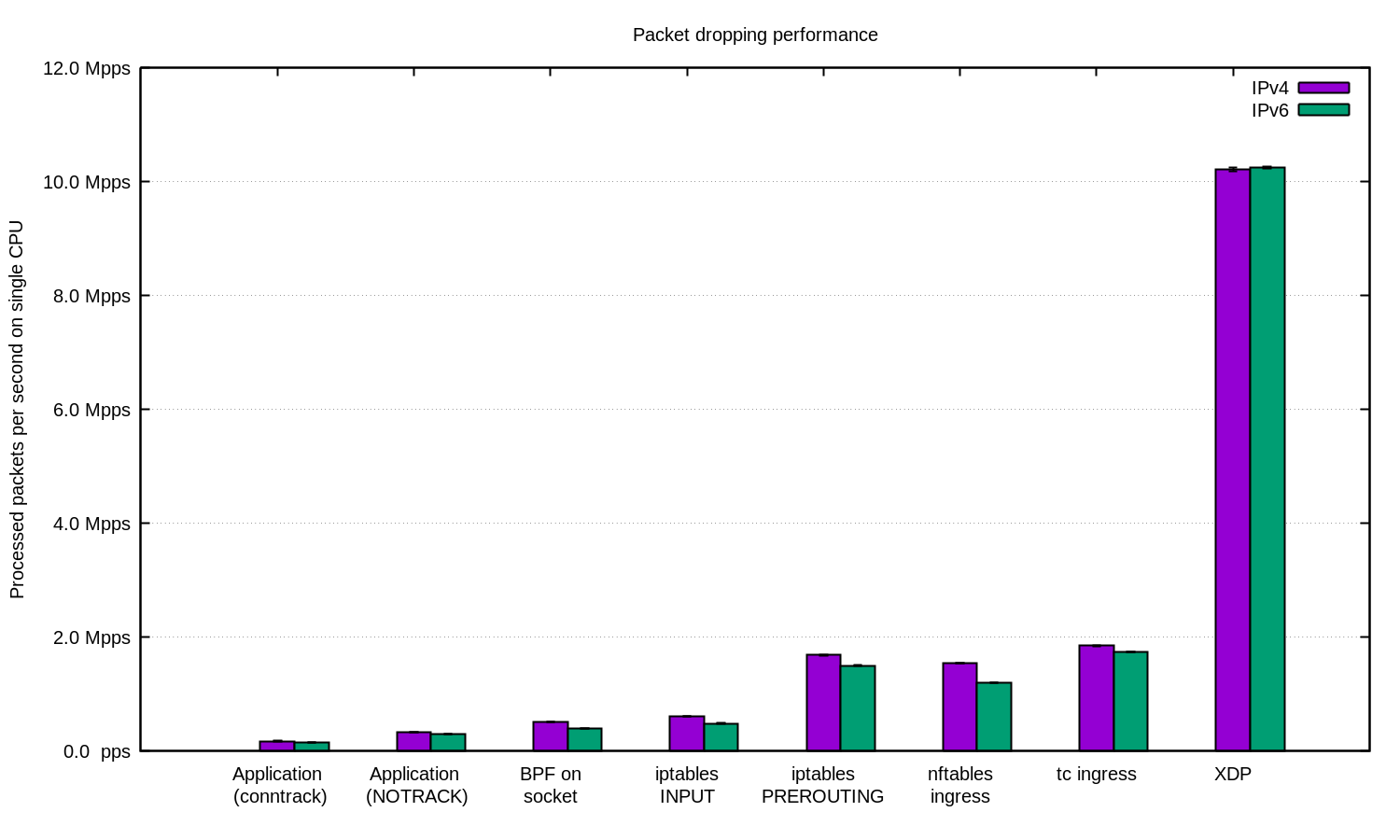
Si desea reproducir estos números, consulte el archivo README donde documentamos todo.
Aquí en Cloudflare usamos... casi todas estas técnicas. Algunos de los trucos del espacio de usuario están integrados con nuestras aplicaciones. La capa iptables está administrada por nuestra canalización Gatebot DDoS. Por último, estamos trabajando en el reemplazo de nuestra propia solución de descarga del núcleo con XDP.
¿Quiere ayudarnos a eliminar más paquetes? ¡Estamos contratando personal para cubrir varios cargos, que incluyen personal encargado de eliminar paquetes, ingenieros de sistemas y más!
Agradecemos especialmente aJesper Dangaard Brouer por su colaboración en este trabajo.