


A finales de agosto de 2022, el equipo de atención al cliente de Cloudflare empezó a recibir quejas acerca de que los sitios de nuestra red habían dejado de funcionar en Austria. Nuestro equipo se puso de inmediato manos a la obra para intentar identificar el origen de lo que parecía externamente una interrupción parcial de Internet en Austria. Pronto nos dimos cuenta de que había un problema con nuestros proveedores de servicios de Internet austriacos locales.
Pero la interrupción del servicio no era consecuencia de un problema técnico. Como nos enteramos más adelante por los informes en los medios de comunicación, lo que observábamos era el resultado de una orden judicial. Sin que Cloudflare hubiera recibido ningún aviso, un tribunal austriaco había ordenado a los proveedores de servicios de Internet (ISP) austriacos bloquear 11 de las direcciones IP de Cloudflare.
Al intentar bloquear 14 sitios web que, según algunos propietarios de derechos de autor, violaban estos derechos, el bloqueo de las direcciones IP ordenado por el tribunal dejó inaccesibles durante dos días miles de sitios web para los usuarios de Internet de Austria en general. ¿Qué hicieron mal estos otros miles de sitios? Nada. Fueron una víctima temporal de la incapacidad de desarrollar sistemas y soluciones legales que reflejen la arquitectura real de Internet.
Hoy, vamos a analizar en detalle el bloqueo de direcciones IP: por qué se produce, qué es, qué hace, a quién afecta y por qué es una forma tan problemática de abordar el contenido en línea
Efectos colaterales, grandes y pequeños
Lo más increíble es que este tipo de bloqueo se produce periódicamente, en todo el mundo. Sin embargo, a menos que su alcance sea al menos tan importante como el del que se produjo en Austria, o que alguien decida llamar la atención sobre él, normalmente pasa completamente desapercibido al mundo exterior. Ni siquiera Cloudflare, con toda su experiencia técnica, y que comprende perfectamente el funcionamiento de un bloqueo, puede descubrir sistemáticamente cuándo una dirección IP está bloqueada.
Para los usuarios de Internet, esto es aún más ininteligible. Normalmente no saben por qué no se pueden conectar a un sitio web determinado, a qué se debe el problema de conexión, o como resolverlo. Lo único que saben es que no pueden acceder al sitio que están intentando visitar. Por ello, puede resultar difícil documentar cuándo los sitios han dejado de estar accesibles debido a un bloqueo de direcciones IP.
Además, la práctica del bloqueo está muy extendida. En su informe "Freedom on the Net", Freedom House comunicó recientemente que 40 de los 70 países que analizaron (y que incluyen desde Rusia, Irán y Egipto a democracias occidentales como el Reino Unido y Alemania) llevaron a cabo algún tipo de bloqueo de sitios web. Aunque el informe no profundiza en cómo estos países realizaron exactamente los bloqueos, muchos de ellos utilizan formas de bloqueo de direcciones IP, con potencialmente las mismas consecuencias de una desconexión parcial de Internet que las que observamos en Austria.
Puede que no resulte fácil evaluar el alcance de los daños colaterales debido al bloqueo de direcciones IP. Pero contamos con algunos ejemplos. Algunas organizaciones han intentado cuantificarlos. Junto con un caso ante el Tribunal Europeo de Derechos Humanos, el European Information Society Institute, una organización sin ánimo de lucro con sede en Eslovaquia, analizó el bloqueo de sitios web bajo el régimen ruso en 2017. Rusia utilizó exclusivamente direcciones IP para bloquear contenido. Esta organización concluyó que el bloqueo de direcciones IP causó un "bloqueo colateral de sitios web a gran escala". También indicó que, a partir del 28 de junio de 2017, “se habían bloqueado en Rusia 6 522 629 recursos de Internet, de los que 6 335 850 (el 97 %) se habían bloqueado de forma colateral, es decir, sin ninguna justificación legal".
En el Reino Unido, el sobrebloqueo impulsó a Open Rights Group, una organización sin ánimo de lucro, a crear el sitio web Blocked.org.uk. Este tiene una herramienta que permite a los usuarios y a los propietarios de los sitios comunicar un sobrebloqueo y solicitar a los ISP que retiren los bloqueos indebidos. El grupo también tiene cientos de historias individuales sobre las consecuencias del bloqueo para aquellos cuyos sitios web se han bloqueado indebidamente. Estos incluyen desde organizaciones benéficas a propietarios de pequeñas empresas. No siempre es evidente qué métodos de bloqueo se están utilizando, pero el solo hecho de que el sitio sea necesario ya refleja un sobrebloqueo. Imaginemos que un modista, un relojero o un vendedor de automóviles desea anunciar sus servicios para conseguir nuevos clientes mediante su sitio web. Eso no funcionará si los usuarios locales no pueden acceder a él.
Una posible respuesta sería: "Simplemente es necesario asegurarse de que no haya sitios restringidos que compartan una dirección con los sitios no restringidos". No obstante, como comentaremos más detalladamente, esto omite la gran diferencia entre el número de posibles nombres de dominio y el número de direcciones IP disponibles. También va en contra de las propias especificaciones técnicas en las que se basa Internet. Además, las definiciones de sitios restringidos y sitios no restringidos varían según los países, las comunidades y las organizaciones. Incluso si fuera posible conocer todas las restricciones, los diseños de los protocolos (de la propia red de Internet) indican que sencillamente es inviable, si no imposible, cumplir las restricciones de todos los organismos.
Problemas legales y de derechos humanos
El sobrebloqueo de sitios web no supone un problema únicamente para los usuarios. También tiene implicaciones legales. Debido a las consecuencias que puede tener para los ciudadanos normales intentar ejercer sus derechos en línea, los organismos gubernamentales (tanto judiciales como legislativos) están obligados legalmente a garantizar la necesidad y proporcionalidad de sus resoluciones, así como que estas no afecten innecesariamente a aquellos que no hayan contribuido al daño.
Por ejemplo, sería inimaginable que un tribunal, en respuesta a una presunta infracción, emitiera a ciegas una orden de registro, basándose exclusivamente en una dirección postal, sin tomarse la molestia de comprobar si esa dirección correspondía a una única vivienda familiar, a un edificio de seis apartamentos o a uno con decenas de plantas y cientos de apartamentos individuales. Sin embargo, cuando se trata de direcciones IP, estas prácticas parecen generalizadas.
En 2020, el Tribunal Europeo de Derechos Humanos (TEDH), el tribunal que supervisa la implementación del Convenio Europeo de Derechos Humanos del Consejo de Europa, consideró un caso que implicaba un sitio web bloqueado en Rusia. Este estaba bloqueado no porque el gobierno ruso así lo hubiera dictaminado, sino porque compartía una dirección IP con un sitio web bloqueado. El propietario del sitio presentó una demanda por el bloqueo. El TEDH concluyó que el bloqueo indiscriminado era inadmisible. Declaró que el bloqueo de contenido legítimo del sitio "equivale a la interferencia arbitraria con los derechos de los propietarios de estos sitios web". En otras palabras, el TEDH declaró que era impropio de un gobierno dictar órdenes que causaran el bloqueo de sitios que no estuvieran incluidos en dichas órdenes.
Utilización de la infraestructura de Internet para resolver los desafíos del contenido
Los usuarios normales de Internet no se paran mucho a pensar cómo se les entrega el contenido al que están intentando acceder en línea. Dan por supuesto que, cuando escriben un nombre de dominio en su navegador, el contenido aparece automáticamente. Si no es así, tienden a suponer que el propio sitio web está teniendo problemas, a menos que toda la conexión de Internet parezca haber caído. No obstante, estas suposiciones básicas ignoran la realidad de que las conexiones a un sitio web a menudo se utilizan para limitar el acceso al contenido en línea.
¿Por qué los países bloquean las conexiones a los sitios web? Tal vez quieren limitar el acceso de sus propios ciudadanos a lo que, según ellos, es contenido ilegal, como las apuestas en línea o material explícito, que están permitidos en otras partes del mundo. Quizás quieren impedir la visualización de una fuente de noticias extranjera que, en su opinión, lo que proporciona básicamente es desinformación. O, a lo mejor, quieren prestar su apoyo a los propietarios de derechos de autor que desean bloquear el acceso a un sitio web para limitar la visualización de contenido que, consideran, infringe su propiedad intelectual.
Para que quede claro, bloquear el acceso y eliminar contenido de Internet son dos acciones distintas. Existen diversas autoridades y obligaciones legales diseñadas para permitir la propia eliminación de contenido ilegal. De hecho, la expectativa legal en muchos países es que el bloqueo es el último recurso, después de que se haya intentado eliminar el contenido en el origen.
El bloqueo únicamente impide que determinados usuarios, aquellos cuyo acceso a Internet depende del ISP que aplica el bloqueo, puedan acceder a los sitios web. El propio sitio web sigue existiendo en línea, y los demás usuarios pueden acceder a él. No obstante, cuando el contenido se origina en una ubicación distinta y no se puede eliminar fácilmente, es posible que un país considere el bloqueo como su mejor o su única estrategia.
Reconocemos las dificultades que a veces impulsan a los países a implementar bloqueos. Sin embargo, básicamente, creemos que es importante que los usuarios sepan cuándo los sitios web a los que están intentando acceder están bloqueados y, en la medida de lo posible, quién los ha bloqueado para que no los puedan visualizar y por qué. Además, es imprescindible que cualquier restricción del acceso al contenido esté lo más limitada posible, a fin de reparar el daño causado y, al mismo tiempo, evitar infringir los derechos de otras personas.
Esto no es posible con el bloqueo de direcciones IP por la fuerza bruta. Esta práctica es completamente incomprensible para los usuarios de Internet. También tiene consecuencias imprevistas e inevitables sobre otro contenido. Y, debido a la propia estructura de Internet, no hay ninguna forma adecuada de identificar qué otros sitios web podrían verse afectados antes o durante un bloqueo de direcciones IP.
Para comprender lo que sucedió en Austria y lo que sucede en muchos otros países de todo el mundo que desean bloquear contenido con un método tan contundente como el bloqueo de direcciones IP, es necesario entender lo que sucede a nivel interno. Es decir, debemos analizar más algunos detalles técnicos.
La identidad va asociada a los nombres, nunca a las direcciones
Antes de que empecemos siquiera a describir la realidad del bloqueo a nivel técnico, debemos destacar que la primera y mejor opción para ocuparnos del contenido es en su origen. Un propietario de un sitio web o un proveedor de alojamiento web tiene la opción de retirar contenido de forma granular, sin tener que eliminar el sitio por completo. En el lado más técnico, un registrador o un registro de nombres de dominio puede, potencialmente, retirar todo un nombre de dominio y, por lo tanto, un sitio web, de Internet.
No obstante, ¿cómo bloqueas el acceso a un sitio web, si por alguna razón el propietario o la fuente del contenido no puede o no quiere retirarlo de Internet? Solo hay tres posibles puntos de control.
El primero es mediante el sistema de nombres de dominio (DNS), que traduce los nombres de dominio a direcciones IP para que sea posible encontrar el sitio. En lugar de devolver una dirección IP válida para un nombre de dominio, el solucionador de DNS podría mentir y responder con un código, NXDOMAIN, que indicara que "ese nombre no existe". Un enfoque mejor sería utilizar uno de los números de error reales estandarizados en 2020, incluido el error 15 para un sitio bloqueado, el error 16 para un sitio censurado, el error 17 para un sitio filtrado o el error 18 para un sitio prohibido, aunque actualmente su uso no está muy extendido.
Curiosamente, la precisión y la efectividad del DNS como punto de control depende de si el solucionador de DNS es privado o público. Los solucionadores de DNS privados o "internos" los utilizan los ISP y los entornos empresariales para sus propios clientes conocidos. Esto significa que los operadores pueden ser precisos al aplicar las restricciones de contenido. Por el contrario, este nivel de precisión no está disponible para los solucionadores abiertos o públicos. Esto se debe, principalmente, a que en el mapa de Internet el enrutamiento y las direcciones son globales y cambian constantemente, de forma radicalmente distinta a las direcciones y rutas de un mapa callejero o postal fijo. Por ejemplo, es posible que los solucionadores de DNS privados puedan bloquear el acceso a los sitios web en regiones geográficas especificadas con al menos cierto nivel de precisión. Los solucionadores de DNS públicos, por el contrario, no pueden bloquear el acceso de esta forma. Esto es extremadamente importante si consideramos los diversos (e incoherentes) regímenes de bloqueo en todo el mundo.
El segundo enfoque es bloquear las solicitudes de conexión individuales a un nombre de dominio restringido. Cuando un usuario o un cliente desea visitar un sitio web, se inicia una conexión desde el cliente a un nombre de servidor, p. ej., el nombre de dominio. Si una red o un dispositivo en ruta puede observar el nombre de servidor, la conexión se puede terminar. A diferencia del DNS, no hay ningún mecanismo para comunicar al usuario que el acceso al nombre de servidor se ha bloqueado, ni por qué.
El tercer enfoque es bloquear el acceso a una dirección IP donde se puede encontrar el nombre de dominio. Es similar a bloquear la entrega de todo el correo a una dirección física. Imagina, por ejemplo, que esa dirección corresponde a un edificio con decenas de plantas donde residen muchos inquilinos independientes que no están relacionados entre sí. Si interrumpimos en bloque la entrega de correo a esa dirección, esto causará daños colaterales, ya que afectará a todas las personas partícipes de esa dirección. Las direcciones IP funcionan de la misma forma.
Concretamente, la dirección IP es la única de las tres opciones que no está vinculada de ninguna forma al nombre de dominio. El nombre de dominio del sitio web no es necesario para el enrutamiento y la entrega de los paquetes de datos. De hecho, se ignora por completo. Un sitio web puede estar disponible en cualquier dirección IP, o incluso en muchas direcciones IP, al mismo tiempo. Y el conjunto de direcciones IP en el que se encuentra un sitio web puede cambiar en cualquier momento. Definitivamente, no podemos conocer el conjunto de direcciones IP consultando el DNS, que ha podido devolver cualquier dirección válida en cualquier momento por cualquier motivo, desde 1995.
La idea de que una dirección es representativa de una identidad es un anatema del diseño de Internet, ya que la desvinculación de una dirección del nombre está profundamente arraigada en los estándares y los protocolos de Internet, como explicaremos a continuación.
Internet es un conjunto de protocolos, no una política o una perspectiva
Muchas personas aún suponen erróneamente que una dirección IP representa un único sitio web. Hemos indicado anteriormente que entendemos la asociación entre nombres y direcciones, puesto que los primeros componentes conectados de Internet aparecieron como un ordenador, una interfaz, una dirección y un nombre. Esta asociación "de uno a uno" era un artificio del ecosistema en el que se había implementado el protocolo de Internet, y satisfacía las necesidades de aquel momento.
A pesar de la práctica de la nomenclatura "de uno a uno" de los primeros tiempos de Internet, siempre ha sido posible asignar más de un nombre a un servidor (o "host"). Por ejemplo, a menudo se configuraba (y aún se configura) un servidor con nombres que reflejan sus ofertas de servicio, por ejemplo, mail.example.com y www.example.com. Sin embargo, estos comparten un nombre de dominio base. Hasta que surgió la necesidad de coubicar sitios web completamente distintos en un único servidor, había pocas razones para tener nombres de dominio completamente distintos. En 1997, esta práctica empezó a ser más fácil gracias al encabezado Host en HTTP/1.1, una función que mantuvo el campo SNI en una extensión TLS en 2003.
Durante todos estos cambios, el protocolo de Internet y, por separado, el protocolo DNS, no solo han mantenido el ritmo, sino que básicamente no han cambiado. Estos protocolos han posibilitado la escala y la evolución de Internet, porque tratan de direcciones, accesibilidad y relaciones entre nombres arbitrarios y direcciones IP.
Los diseños de las direcciones IP y el DNS son también completamente independientes. Esto refuerza la idea de que los nombres y las direcciones están separados. Un análisis más detallado de los elementos de diseño de los protocolos aclara las percepciones erróneas de las políticas que llevan a la práctica habitual actual de controlar el acceso al contenido mediante el bloqueo de direcciones IP.
Por diseño, la dirección IP es exclusivamente para la accesibilidad
De la misma forma que los proyectos de ingeniería civil públicos se basan en las prácticas recomendadas y los códigos de construcción, Internet se desarrolla utilizando un conjunto de estándares y especificaciones abiertos sustentados en la experiencia y conformes a un consenso internacional. Los estándares de Internet que conectan el hardware y las aplicaciones los publica la Internet Engineering Task Force (IETF) en forma de "Requests for Comment" o RFC. Reciben este nombre no para sugerir un estado incompleto, sino para reflejar que los estándares deben poder evolucionar junto con los conocimientos y la experiencia. La IETF y sus RFC están consolidados en la propia estructura de las comunicaciones, por ejemplo, con el primer RFC 1 publicado en 1969. La especificación del protocolo de Internet (IP) logró su estado de RFC en 1981.
Junto con las organizaciones que establecen los estándares, una idea fundamental ha contribuido al éxito de Internet. Es lo que conocemos como el principio end-to-end (e2e) o de extremo a extremo, codificado también en 1981, y respaldado por años de experiencia basada en prueba y error. El principio de extremo a extremo es una eficaz abstracción que, a pesar de adoptar muchas formas, expresa la noción básica de la especificación del protocolo de Internet: la única responsabilidad de la red es establecer la accesibilidad, cada otra posible función tiene un coste o un riesgo.
La idea de "accesibilidad" en el protocolo de Internet también está plasmada en el diseño de las propias direcciones IP. Si consultamos la especificación del protocolo de Internet, RFC 791, el siguiente extracto de la Sección 2.3 declara explícitamente que las direcciones IP no tienen ninguna asociación con nombres, interfaces ni ningún otro elemento.
Addressing
A distinction is made between names, addresses, and routes [4]. A
name indicates what we seek. An address indicates where it is. A
route indicates how to get there. The internet protocol deals
primarily with addresses. It is the task of higher level (i.e.,
host-to-host or application) protocols to make the mapping from
names to addresses. The internet module maps internet addresses to
local net addresses. It is the task of lower level (i.e., local net
or gateways) procedures to make the mapping from local net addresses
to routes.
[ RFC 791, 1981 ]
Al igual que las direcciones postales en el caso de los edificios con decenas de plantas en el entorno físico, las direcciones IP no son más que direcciones postales escritas en un papel. Y, al igual que con una dirección postal en papel, nunca puedes estar seguro de las entidades o las organizaciones existentes tras una dirección IP. En una red como la de Cloudflare, cualquier dirección IP individual representa miles de servidores, y es posible que el número de sitios web y servicios que tenga sea aún mayor. En algunos casos, estas cifras pueden alcanzar millones. Y esto es expresamente así porque el protocolo de Internet está diseñado para que esto sea posible.
Surge aquí una pregunta interesante: ¿podríamos nosotros, o cualquier proveedor de servicios de contenido, garantizar que cada dirección IP coincide únicamente con un nombre, no con varios? La respuesta es, inequívocamente, no. Aquí, también, debido al diseño de un protocolo. En este caso, el DNS.
El número de nombres en el DNS siempre supera el número de direcciones disponibles
Dadas las especificaciones de Internet, una relación "de uno a uno" entre los nombres y las direcciones es imposible. Por las mismas razones por las que no es viable en el entorno físico. Olvida por un momento el hecho de que las personas y las organizaciones pueden cambiar de dirección. Básicamente, el número de personas y organizaciones en el planeta es mayor que el número de direcciones postales. No queremos, pero necesitamos, que Internet acomode más nombres que direcciones.
La diferencia de magnitud entre los nombres y las direcciones también está codificada en las especificaciones. Las direcciones IPv4 son de 32 bits, y las direcciones IPv6 de 128 bits. El tamaño de un nombre de dominio que puede consultar el DNS puede tener hasta 253 octetos, o 2024 bits (Sección 2.3.4 del RFC 1035, publicado en 1987). La tabla siguiente nos ayuda a poner estas diferencias en perspectiva:
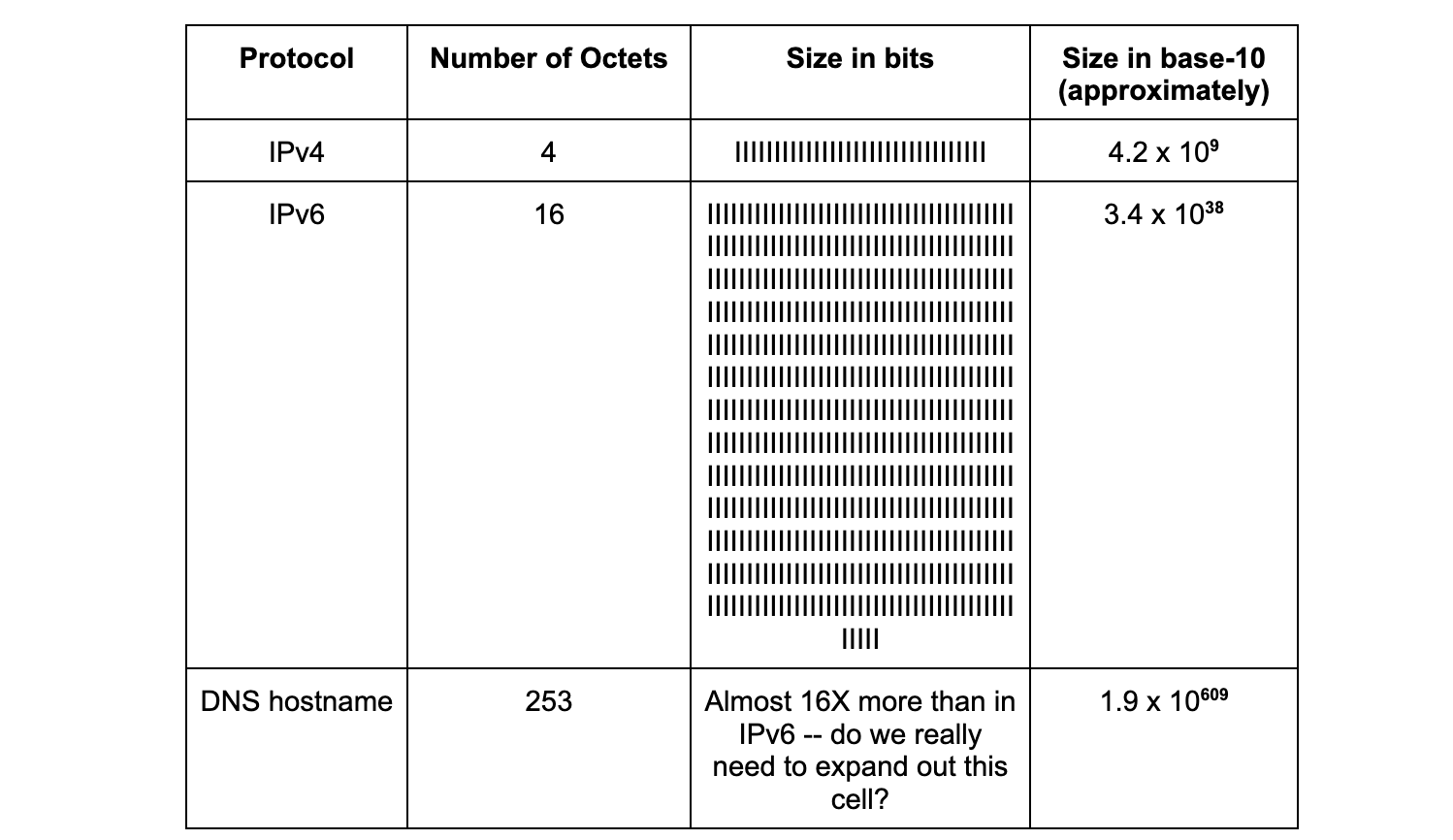
El 15 de noviembre de 2022, las Naciones Unidas anunciaron que la población mundial había superado los 8000 millones de personas. Intuitivamente, sabemos que el número de direcciones postales que puede haber es muchísimo menor. La diferencia entre el número de nombres posibles en el planeta, y de forma similar en Internet, sobrepasa, y debe sobrepasar, el número de direcciones disponibles.
A las pruebas nos remitimos!
Ahora comprendemos estos dos principios relevantes sobre las direcciones IP y los nombres de DNS en los estándares internacionales. Entendemos que las direcciones IP y los nombres de dominio tienen finalidades distintas y que no hay ninguna relación "de uno a uno" entre ambos. Un análisis de un caso reciente de bloqueo de contenido utilizando direcciones IP puede ayudarnos a ver por qué es problemático. Tomemos, por ejemplo, el incidente del bloqueo de direcciones IP en Austria a finales de agosto de 2022. El objetivo era restringir el acceso a 14 dominios específicos, mediante el bloqueo de 11 direcciones IP (fuente: RTR.Telekom. Publicación mediante Internet Archive). La discrepancia entre estas dos cifras debería haber alertado de que era posible que el bloqueo de las direcciones IP no tuviera el efecto deseado.
Las analogías y los estándares internacionales pueden explicar las razones por las que el bloqueo de direcciones IP se debería evitar. No obstante, podemos observar el alcance del problema si analizamos los datos a escala de Internet. Para comprender y explicar mejor la gravedad del bloqueo de direcciones IP, decidimos generar una vista global de los nombres de dominio y las direcciones IP (debemos expresar nuestro agradecimiento por sus esfuerzos a Sudheesh Singanamalla, becario de investigación de doctorado). En septiembre de 2022, utilizamos los archivos de zona autoritativos para los dominios de nivel superior (TLD) .com, .net, .info, y .org, junto con listas del millón de sitios web más importantes, para dar con un total de 255 315 270 nombres exclusivos. A continuación, consultamos el DNS de cada una de las cinco regiones y registramos el conjunto de direcciones IP devueltas. La tabla siguiente resume nuestras conclusiones:
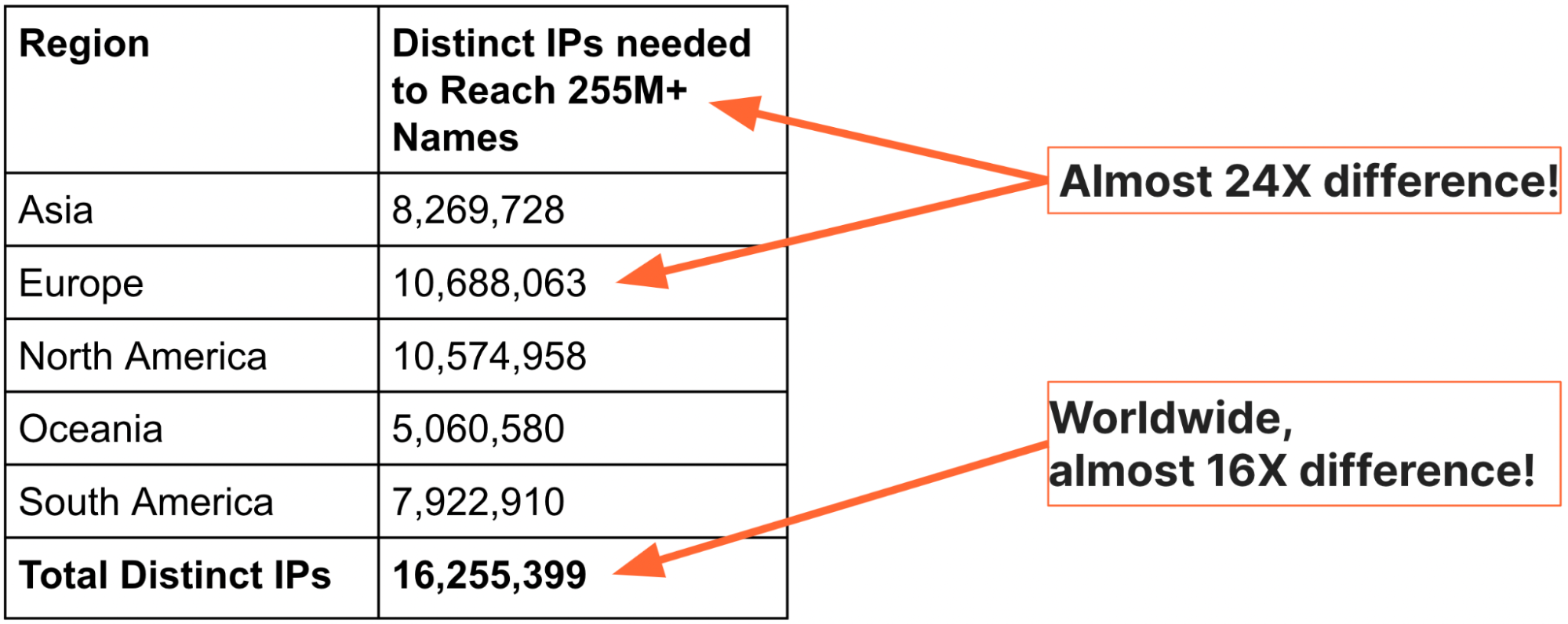
La tabla anterior deja claro que no se requieren más de 10,7 millones de direcciones para acceder a 255 315 270 de nombres de cualquier región del planeta. El conjunto total de direcciones IP para estos nombres de cualquier ubicación es de aproximadamente 16 millones, una proporción de nombres a direcciones IP de casi 24 veces más en Europa y de 16 veces más a nivel global.
Hay otro detalle que vale la pena mencionar acerca de las cifras anteriores: las direcciones IP son los totales combinados de las direcciones IPv4 y IPv6, lo que quiere decir que se requieren muchas menos direcciones para acceder a los 255 millones de sitios web.
También hemos analizado los datos de distintas maneras para llegar a algunas interesantes conclusiones. Por ejemplo, la figura siguiente muestra la de distribución acumulada (FDA) de la proporción de sitios web que se pueden visitar con cada dirección IP adicional. En el eje y está la proporción de sitios web a los que se puede acceder dado cierto número de direcciones IP. En el eje x, los 16 millones de direcciones IP están clasificadas de manera que las que tienen más dominios están a la izquierda y las que tienen menos están a la derecha. Ten en cuenta que cualquier dirección IP de este conjunto es una respuesta del DNS. Por lo tanto, debe tener al menos un nombre de dominio. Sin embargo, las cifras más altas de dominios en las direcciones IP del conjunto están en millones de 8 dígitos.
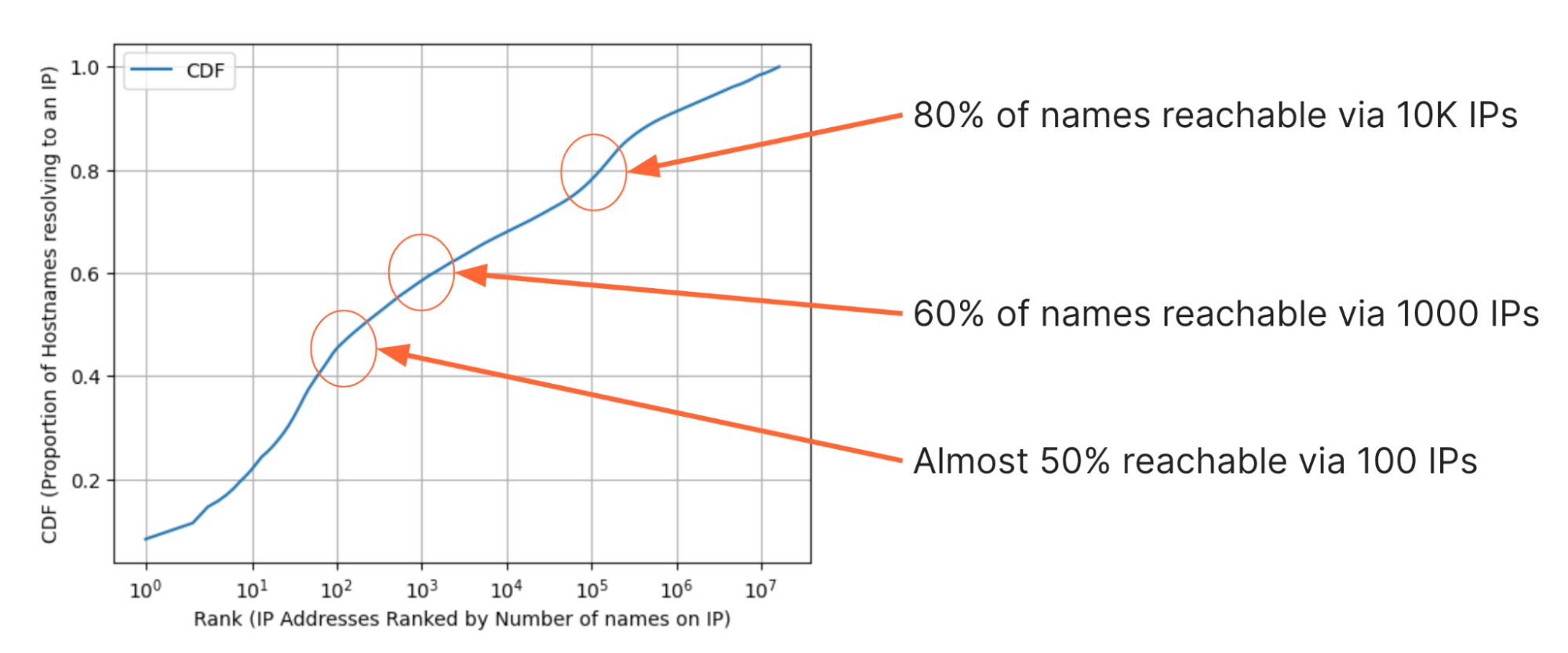
Si observamos la FDA, realizamos algunas observaciones sorprendentes:
- Se necesitan menos de 10 direcciones IP para acceder al 20 %, aproximadamente 51 millones, de los dominios del conjunto;
- 100 direcciones IP son suficientes para acceder al 50 % de los dominios;
- 1000 direcciones IP son suficientes para acceder al 60 % de los dominios;
- 10 000 direcciones IP son suficientes para acceder al 80 %, aproximadamente 204 millones, de los dominios.
De hecho, del conjunto total de 16 millones de direcciones, menos de la mitad, 7,1 millones (el 43,7 %), de las direcciones del conjunto de datos tenían solo un nombre. Respecto a este nombre "único", debemos subrayar otro aspecto. No podemos determinar si había solo un nombre, y ningún otro, en esas direcciones, ya que hay muchos otros nombres de dominio que los que contienen .com, .org, .info. y .net. Podría perfectamente haber otros nombres en estas direcciones.
Además de tener varios dominios en una única dirección IP, cualquier dirección IP puede cambiar a lo largo del tiempo para cualquiera de esos dominios. Cambiar regularmente las direcciones IP puede ser útil en determinadas condiciones de seguridad y rendimiento, y para mejorar la fiabilidad de los sitios web. Por ejemplo, el equilibrio de carga es un caso de uso habitual de muchas operaciones. Esto significa que las consultas de DNS pueden devolver distintas direcciones IP a lo largo del tiempo, o en distintas ubicaciones, para el mismo sitio web. Esta es una razón adicional, y aparte, por la que el bloqueo basado en direcciones IP, con el tiempo, no será útil para la finalidad para la que se ha aplicado.
Por último, no hay ninguna manera fiable de saber el número de dominios en una dirección IP sin inspeccionar todos los nombres en el DNS, de cada una de las ubicaciones del planeta, en todo momento en el tiempo. Y esto es una proposición absolutamente inviable.
Se espera que cualquier acción en una dirección IP debe, por la propia definición de los protocolos que rigen Internet y en los que se basa, tener efectos colaterales.
Falta de transparencia del bloqueo de direcciones IP
Por lo tanto, si es de esperar que el bloqueo de una dirección IP tenga efectos colaterales, y en líneas generales se acepta que es inadecuado o incluso legalmente inadmisible el sobrebloqueo mediante el bloqueo de direcciones IP que contienen múltiples dominios, ¿por qué sigue sucediendo? Es difícil determinarlo con certeza, así que solo podemos especular. A veces refleja la falta de conocimientos técnicos acerca de los posibles efectos, especialmente en el caso de entidades tales como los jueces, que no son tecnólogos. A veces, los gobiernos simplemente ignoran el daño colateral (como hacen con las desconexiones de Internet) porque consideran que el bloqueo es beneficioso para sus intereses. Y, cuando hay daños colaterales, normalmente no resultan evidentes para el mundo exterior, por lo que la presión externa para remediarlos es prácticamente inexistente.
Vale la pena destacar este punto. Cuando un dirección IP está bloqueada, un usuario simplemente ve una conexión que falla. No sabe por qué la conexión ha fallado, o quién ha hecho que falle. En el otro extremo, el servidor que actúa en nombre del sitio web ni siquiera sabe que está bloqueado hasta que empieza a recibir quejas porque no es posible acceder a él. El sobrebloqueo es prácticamente opaco y nadie asume su responsabilidad. Para un propietario de un sitio web, puede ser difícil, si no imposible, desafiar un bloqueo o intentar resolver su bloqueo indebido.
Algunos gobiernos, incluido el de Austria, publican las listas de bloqueos activos. Esto es importante en términos de transparencia. Sin embargo, por todas las razones que hemos comentado, publicar una dirección IP no revela todos los sitios que es posible que se hayan bloqueado de manera inintencional. Tampoco proporciona a las personas afectadas una forma de desafiar el sobrebloqueo. De nuevo, en el ejemplo del entorno físico, es difícil imaginar una orden judicial sobre un edificio de decenas de plantas sin que su anuncio se colgara en la puerta. Sin embargo, en el espacio virtual a menudo nos saltamos estos requisitos de comunicación y proceso debido.
Un número creciente de países intentan bloquear contenido en línea. Por ello, creemos que es más importante que nunca hablar sobre las consecuencias problemáticas del bloqueo de direcciones IP. Por desgracia, los ISP a menudo utilizan los bloqueos de direcciones IP para implementar estos requisitos. Es posible que el ISP en cuestión sea más nuevo o menos eficaz que sus homólogos más grandes. Sin embargo, los ISP más grandes también participan en la práctica. Y es normal que así sea, ya que el bloqueo de direcciones IP es lo que requiere menos esfuerzo y está inmediatamente disponible en la mayoría de los equipos.
Y, a medida que cada vez se incluyan más dominios en el mismo número de direcciones IP, el problema no hará sino que empeorar.
Pasos siguientes
¿Qué podemos hacer?
Creemos que el primer paso es mejorar la transparencia en materia de la utilización del bloqueo de direcciones IP. No conocemos ninguna manera de documentar íntegramente los daños colaterales causados por el bloqueo de direcciones IP, pero creemos que hay medidas que podemos adoptar para concienciar sobre esta práctica. Nuestro compromiso es trabajar en nuevas iniciativas que subrayen esta información, como hemos hecho con Cloudflare Radar Outage Center.
También reconocemos que este problema afecta a todo Internet. Por lo tanto, la solución debe formar parte de un esfuerzo más generalizado. La alta probabilidad de que el bloqueo mediante direcciones IP cause la restricción del acceso a toda una serie de dominios no relacionados (y que no son el objetivo) debería llevar a cualquiera a renunciar a este método. Por este motivo, nos hemos implicado con socios de la sociedad civil y empresas afines para que sigan desafiando la utilización del bloqueo de direcciones IP como una forma de abordar los desafíos del contenido, y señalen también los datos colaterales que observen.
Para que no haya dudas: para abordar los desafíos del contenido ilegal en línea, los países necesitan mecanismos legales que permitan la eliminación o la restricción de contenido de forma respetuosa con los derechos. Creemos que lo mejor, y el primer paso necesario, es abordar el contenido en el origen. Leyes como la nueva Ley de Servicios Digitales o la Ley de Derechos de Autor de la Era Digital de la UE proporcionan herramientas que podemos utilizar para abordar el contenido digital en el origen, al mismo tiempo que se respetan importantes principios de proceso debido. Los gobiernos deben centrarse en desarrollar y aplicar mecanismos legales que afecten lo menos posible los derechos de otras personas, acorde con las expectativas en materia de derechos humanos.
En términos muy sencillos, no se pueden satisfacer estas necesidades mediante el bloqueo de direcciones IP.
Continuaremos buscando nuevas formas para hablar sobre la actividad y la interrupción de la red, especialmente cuando lleva a limitaciones innecesarias del acceso. Echa un vistazo a Cloudflare Radar para obtener más información sobre lo que vemos en línea.