

A grandes escalas operativas, el direccionamiento IP impide la innovación en los servicios de red. En cada cambio de arquitectura, y desde luego, al empezar a diseñar nuevos sistemas, la primera batería de preguntas que nos vemos obligados a plantear es:
- ¿Qué bloque de direcciones IP debemos o podemos utilizar?
- ¿Tenemos suficientes direcciones en IPv4? Si no es así, ¿dónde o cómo podemos conseguirlas?
- ¿Cómo utilizamos las direcciones en IPv6? ¿Afecta a otros usos de este protocolo?
- Y, ¿qué recursos necesitamos para la migración en términos de planificación, controles, tiempo y personas?
Tener que parar a preocuparse por las direcciones IP cuesta tiempo, dinero y recursos. Puede parecer sorprendente, teniendo en cuenta la ambiciosa y prometedora llegada de las direcciones IP hace más de 40 años. Por su propio diseño, las direcciones IP deberían ser la última de las preocupaciones de cualquier red. Sin embargo, si algo ha puesto de manifiesto Internet es que las vulnerabilidades pequeñas o aparentemente sin importancia, a menudo imperceptibles o imposibles de ver en el momento del diseño, siempre se presentan a escala suficiente.
Una cosa sí tenemos clara, "más direcciones" nunca debería ser la respuesta. Pensar así solo intensifica la escasez de direcciones en IPv4, lo que a su vez eleva los precios de mercado. IPv6 es absolutamente necesario, pero es solo una parte de la solución. Por ejemplo, la mejor práctica en IPv6 establece que la asignación más pequeña, solo para uso personal es /56, es decir, 272 o unas 4.722.000.000.000.000 direcciones. Me bloqueo solo de pensar en un valor numérico tan alto, ¿y tú?
En esta publicación del blog, explicaremos por qué el direccionamiento IP es un problema para los servicios web y las causas subyacentes. A continuación, describiremos una solución innovadora a la que hemos bautizado con el nombre Addressing Agility, así como las lecciones aprendidas. Lo mejor de todo puede ser el tipo de nuevos sistemas y arquitecturas que permite Addressing Agility. Todos los detalles están disponibles en el documento informativo que presentamos en ACM SIGCOMM 2021. Como adelanto, podrás leer un resumen de algunas lecciones aprendidas:

Es cierto. No hay límite en el número de nombres que pueden aparecer en una misma dirección. La dirección de cualquier nombre puede cambiar con cada nueva consulta, en cualquier lugar, y se pueden realizar cambios de dirección por cualquier motivo, ya sea la prestación de servicios, la evaluación de políticas o del rendimiento, u otros que todavía desconocemos...
A continuación, explicamos las razones que validan este enfoque, la forma en que hemos llegado a estas conclusiones y las razones por las que estas lecciones son importantes para los servicios HTTP y TLS de cualquier tamaño. La idea clave sobre la que nos basamos es que en el diseño del protocolo de Internet (IP), al igual que en el sistema postal internacional, las direcciones nunca han sido, nunca deberían ser y de ninguna manera son necesarias para representar nombres, solo que a veces tratamos las direcciones como si lo hicieran. En cambio, este trabajo muestra que todos los nombres deberían compartir todas sus direcciones, cualquier conjunto de sus direcciones, o incluso una sola dirección.
La arquitectura "narrow waist" es un embudo, pero también un cuello de botella
Las convenciones de hace décadas vinculan artificialmente las direcciones IP a nombres y recursos. Esto es comprensible, ya que la arquitectura y el software que permiten que Internet funcione evolucionaron a partir de un entorno en el que un ordenador tenía un nombre y (casi siempre) una tarjeta de interfaz de red. Por lo tanto, sería natural que Internet evolucionara de manera que una dirección IP estuviera asociada a nombres y procesos de software.
Entre los clientes finales y los operadores de red, donde hay poca necesidad de nombres y menos necesidad de procesos de escucha, estos enlaces IP tienen poco impacto. Sin embargo, las convenciones de nombres y procesos crean significativas limitaciones para todos los proveedores de alojamiento, distribución y servicios de contenidos. Una vez asignadas a nombres, interfaces y sockets, las direcciones se vuelven en gran medida estáticas y requieren esfuerzo, planificación y atención para cambiarlas, si es que es posible hacerlo.
La arquitectura "narrow waist" de las direcciones IP ha hecho posible Internet, pero igual que han sido TCP y HTTP para los protocolos de transporte y aplicación, respectivamente, IP se ha convertido en un obstáculo que frena la innovación. La idea se representa en la siguiente ilustración, en la que vemos que los enlaces de comunicación (con nombres) y los enlaces de conexión (con interfaces y sockets), que de otro modo estarían separados, crean relaciones transitivas entre ellos.
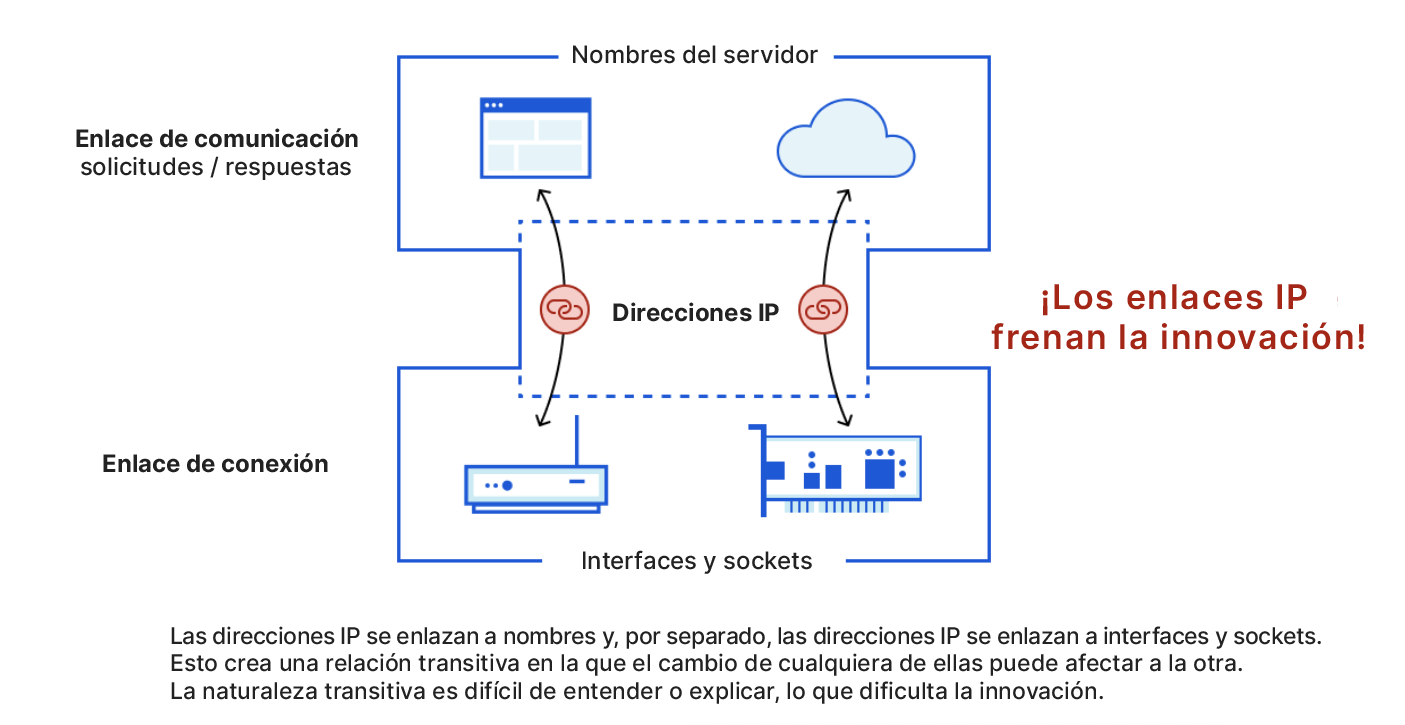
Es difícil interrumpir el bloqueo transitivo porque el cambio de cualquiera de ellos puede tener un impacto en el otro. Además, los proveedores de servicios suelen utilizar las direcciones IP para representar políticas y niveles de servicio que existen independientemente de los nombres. En definitiva, los enlaces IP son una cosa más a tener en cuenta, y no para bien.
En otras palabras. Cuando se piensa en nuevos diseños, nuevas arquitecturas o simplemente en una mejor asignación de recursos, las primera preguntas nunca deberían ser: "¿qué direcciones IP utilizamos?" o "¿tenemos direcciones IP para esto?". Este tipo de preguntas y sus respuestas frena el desarrollo y la innovación.
Nos dimos cuenta de que los enlaces IP no solo son artificiales, sino que, según las innovadoras y originales solicitudes de comentarios (RFC) y estándares, también son incorrectos. De hecho, la noción de que las direcciones IP son representativas de cualquier cosa que no sea la disponibilidad va en contra de su diseño original. En la RFC original y borradores relacionados, los arquitectos son explícitos: "Se hace una distinción entre nombres, direcciones y rutas. Un nombre indica lo que buscamos, una dirección muestra dónde está y una ruta señala cómo llegar". Cualquier asociación a una dirección IP de información como SNI o servidor HTTP en protocolos de capa superior es un incumplimiento claro del principio de la disposición en capas.
Por supuesto, ninguno de nuestros trabajos existe de forma aislada sino que completan una larga trayectoria para desvincular las direcciones IP de su uso convencional, una evolución que no sería posible sin el trabajo realizado en el pasado.
La evolución del pasado
Echando la vista atrás los últimos 20 años, es fácil ver que el deseo de agilizar el direccionamiento persiste desde hace algún tiempo, y es algo en lo que Cloudflare ha estado muy interesado.
El viejo enlace uno a uno entre direcciones IP y las interfaces de las tarjetas de red falló por primera vez hace unos años, cuando Maglev de Google combinó Equal Cost MultiPath (ECMP) y la técnica de hash consistente para distribuir el tráfico de una dirección IP "virtual" entre muchos servidores. Como apunte, según las RFC originales del protocolo de Internet, este uso de la dirección IP está prohibido y no hay nada virtual en él.
Desde entonces han surgido muchos sistemas similares en GitHub, Facebook y otros portales, incluido nuestro propio Unimog. Más recientemente, Cloudflare diseñó una nueva arquitectura de sockets programables llamada bpf_sk_lookup para desvincular las direcciones IP de los sockets y los procesos.
¿Pero qué pasa con esos nombres? El valor del "alojamiento virtual" se consolidó en 1997 cuando HTTP 1.1 definió el campo servidor como obligatorio. Este fue el primer reconocimiento oficial de que pueden coexistir varios nombres en una misma dirección IP, y fue necesariamente reproducido por TLS en el campo “indicación del nombre del servidor”. Se trata de requisitos absolutos, ya que el número de nombres posibles es mayor que el número de direcciones IP.
Indicios de un futuro ágil
Mirando al futuro, Shakespeare fue sabio al preguntarse: "¿Qué hay en un nombre?". Si Internet pudiera hablar, diría: "Ese nombre que etiquetamos con cualquier otra dirección sería igual de accesible".
Si Shakespeare preguntara en cambio "¿Qué hay en una dirección?", Internet respondería igualmente: "Esa dirección que etiquetamos con cualquier otro nombre también sería igual de accesible".
De la veracidad de estas respuestas se desprende una fuerte implicación: la asignación entre nombres y direcciones es universal. Si esto es cierto, cualquier dirección se puede utilizar para llegar a un nombre, siempre que un nombre sea accesible en una dirección.
De hecho, desde 1995, con la adopción del equilibrio de carga basado en DNS, hay disponible una versión de muchas direcciones para un nombre. Entonces, ¿por qué no todas las direcciones se pueden utilizar para todos los nombres, o cualquier dirección en un momento dado para todos los nombres? o, como pronto descubriremos, ¡el uso de una dirección para todos los nombres! Pero primero, hablemos de la forma en que se consigue agilizar el direccionamiento.
Cómo agilizar el direccionamiento: ignorar los nombres, asignar políticas
La clave de la agilidad en el direccionamiento es el DNS autoritativo, pero no en las asignaciones estáticas de nombre en direcciones IP almacenadas en alguna forma de registro o tabla de búsqueda. Considera que, desde la perspectiva de cualquier cliente, el enlace solo aparece en la "consulta". Para todos los usos prácticos de la asignación, la respuesta de la consulta es el último instante posible de la duración de una solicitud en el que se puede vincular un nombre a una dirección.
De esto se desprende que las asignaciones de nombres no se hacen en algún registro o archivo de zona sino en el momento en que se devuelve la respuesta. Es una distinción sutil, pero importante. Los sistemas DNS actuales utilizan un nombre para buscar un conjunto de direcciones y, a veces, utilizan alguna política para decidir qué dirección específica devolver. La idea se muestra en la siguiente ilustración. Cuando llega una consulta, una búsqueda revela las direcciones asociadas a ese nombre, y luego devuelve una o más de esas direcciones. A menudo, se utilizan filtros por políticas o sistemas lógicos adicionales para restringir la selección de direcciones, como el nivel de servicio o la cobertura georregional. El detalle importante es que las direcciones se identifican primero con un nombre, y las políticas se aplican después.
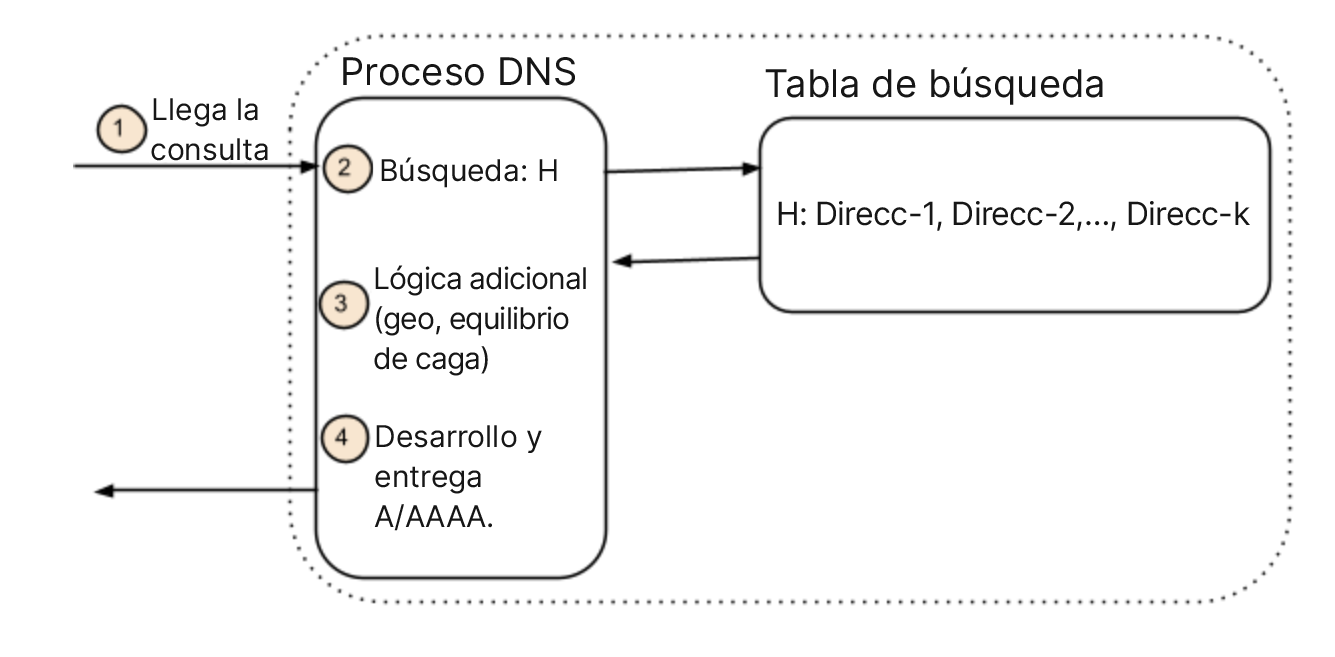
(a) DNS autoritativo convencional
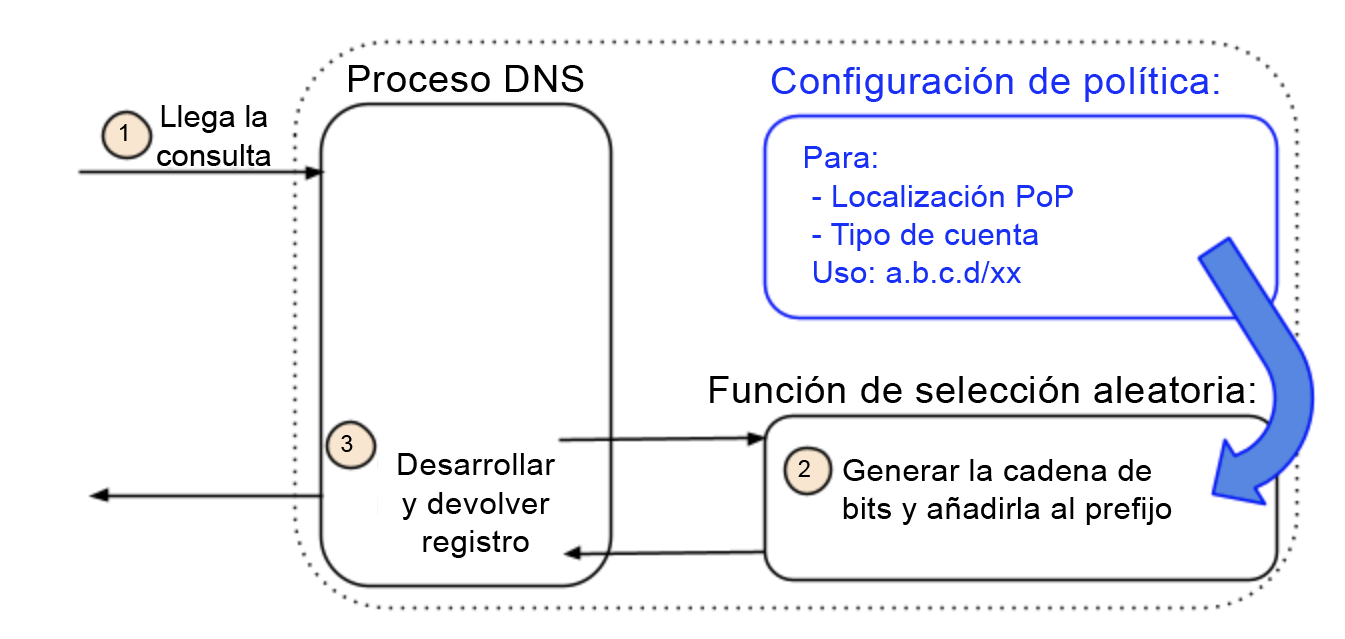
(b) Addressing Agility
La agilidad del direccionamiento se consigue invirtiendo esta relación. En lugar de direcciones IP preasignadas a un nombre, nuestra arquitectura comienza con una política que puede (o en nuestro caso, no) incluir un nombre. Por ejemplo, una política puede estar representada por atributos como la ubicación y el tipo de cuenta e ignorar el nombre (lo que hicimos en nuestra implementación). Los atributos identifican un grupo de direcciones que están asociadas a esa política. El grupo en sí puede estar aislado a esa política o tener elementos que comparte con otros grupos y políticas. Además, todas las direcciones del grupo son equivalentes. Esto significa que cualquiera de las direcciones se puede devolver, o incluso seleccionar al azar, sin inspeccionar el nombre de la consulta DNS.
Ahora hagamos una parada en el camino porque hay dos consecuencias muy importantes que afectan a las respuestas por consulta:
i. Las direcciones IP se pueden calcular y asignar en tiempo de ejecución o de consulta.
ii. La duración de la asignación de la dirección IP al nombre es la mayor del ciclo de la conexión siguiente y el TTL en las memorias caché de salida.
El resultado es potente y significa que el propio enlace es efímero y se puede cambiar sin tener en cuenta los enlaces anteriores, los solucionadores, los clientes o el propósito. Además, la escala no es un problema, y lo sabemos porque lo hemos implementado en el perímetro.
IPv6: nueva versión, mismo protocolo
Antes de hablar de nuestra implementación, dejemos primero de negar la evidencia : IPv6. Lo primero que hay que dejar claro es que todo lo que analizamos en este documento en el contexto de IPv4 se aplica igualmente en IPv6. Al igual que ocurre con el sistema postal internacional, las direcciones son direcciones, ya sea en Canadá, Camboya, Camerún, Chile o China, y eso incluye su naturaleza relativamente estática e inflexible.
A pesar de la equivalencia, la pregunta obvia sigue siendo: ¿Seguro que las razones que nos mueven a desarrollar Addressing Agility se resuelven simplemente cambiando a IPv6? Aunque la respuesta sea contraintuitiva, es un no rotundo. IPv6 puede mitigar el agotamiento de las direcciones, al menos durante la vida de todas las personas que viven hoy en día, pero la abundancia de prefijos y direcciones en IPv6 dificulta la lógica sobre sus enlaces con nombres y recursos.
La abundancia de direcciones en IPv6 también conlleva el riesgo de ineficiencias, ya que los operadores pueden aprovechar la longitud de los bits y los grandes tamaños de los prefijos para incorporar el significado en la dirección IP. Esta es una característica eficaz de IPv6, pero también significa que muchas direcciones en cualquier prefijo quedarán sin usar.
Para ser claros, Cloudflare es uno de los mayores defensores de IPv6, y con razón, sobre todo porque la abundancia de direcciones asegura su durabilidad. Aun así, IPv6 cambia poco la forma en que las direcciones están vinculadas a los nombres y recursos, mientras que la agilidad de una dirección garantiza la flexibilidad y la capacidad de respuesta durante su duración.
Agility es para todos
Un último comentario sobre la arquitectura y su transferibilidad. Addressing Agility es útil, e incluso deseable, para cualquier servicio que opere un DNS autoritativo. Otros proveedores de servicios orientados al contenido son claros candidatos, pero también lo son los operadores más pequeños. Las universidades, las empresas y los gobiernos son solo algunos ejemplos de organizaciones que pueden operar sus propios servicios autoritativos. Siempre que los operadores puedan aceptar conexiones en las direcciones IP devueltas, todos son beneficiarios potenciales de la agilidad de direccionamiento resultante.
Direcciones aleatorias basadas en políticas a escala
Desde junio de 2020, hemos estado trabajando con Addressing Agility en directo en el perímetro, con el tráfico de producción, de la siguiente manera:
- Más de 20 millones de nombres de servidor y servicios.
- Todos los centros de datos en Canadá (con una población razonable y múltiples zonas horarias).
- /20 (4.096 direcciones) en IPv4 y /44 en IPv6.
- /24 (256 direcciones) en IPv4 desde enero de 2021 hasta junio de 2021.
- Para cada consulta, se genera una porción correspondiente al servidor aleatorio dentro del prefijo.
Después de todo, la verdadera prueba de agilidad es más extrema cuando se genera una dirección aleatoria para cada consulta que llega a nuestros servidores. Fue entonces cuando decidimos poner a prueba la idea. En junio de 2021, se asignaron más de 20 millones de zonas a una única dirección en nuestro centro de datos de Montreal y poco después en el de Toronto.
En el transcurso de un año, cada consulta de un dominio reflejada en la política recibió una dirección seleccionada al azar, de un conjunto de hasta 4.096 direcciones, después 256 y luego uno. A nivel interno, nos referimos a un conjunto de direcciones como Ao1, y volveremos sobre ello más adelante.
La medida del éxito: "Aquí no hay nada que ver"
Es posible que nuestros lectores se pregunten en voz baja:
- ¿Cómo impactó esto en Internet?
- ¿Qué efecto tuvo en los sistemas de Cloudflare?
- ¿Qué es lo que vería si pudiera?
La respuesta a cada una de las preguntas anteriores es breve: nada. Sin embargo, y esto es importante, la selección aleatoria de direcciones sí expone las vulnerabilidades en los diseños de los sistemas que dependen de Internet. Todas las deficiencias siempre, se producen porque los diseñadores atribuyen un significado a las direcciones IP más allá de la disponibilidad. (Y, aunque solo sea por casualidad, cada una de esas vulnerabilidades se sortea con el uso de una dirección, o "Ao1").
Para comprender mejor la naturaleza de "nada", respondamos a las preguntas anteriores empezando por la última:
¿Qué vería si pudiera?
La respuesta se muestra en el ejemplo de la siguiente ilustración. Desde todos los centros de datos en el "resto del mundo", excluidos de nuestra implementación, una consulta para una zona devuelve las mismas direcciones (así es el sistema anycast global de Cloudflare). Por el contrario, cada consulta que llegue a un un centro de datos de la implementación recibe una dirección aleatoria. Se puede ver a continuación en comandos dig sucesivos a dos centros de datos diferentes.
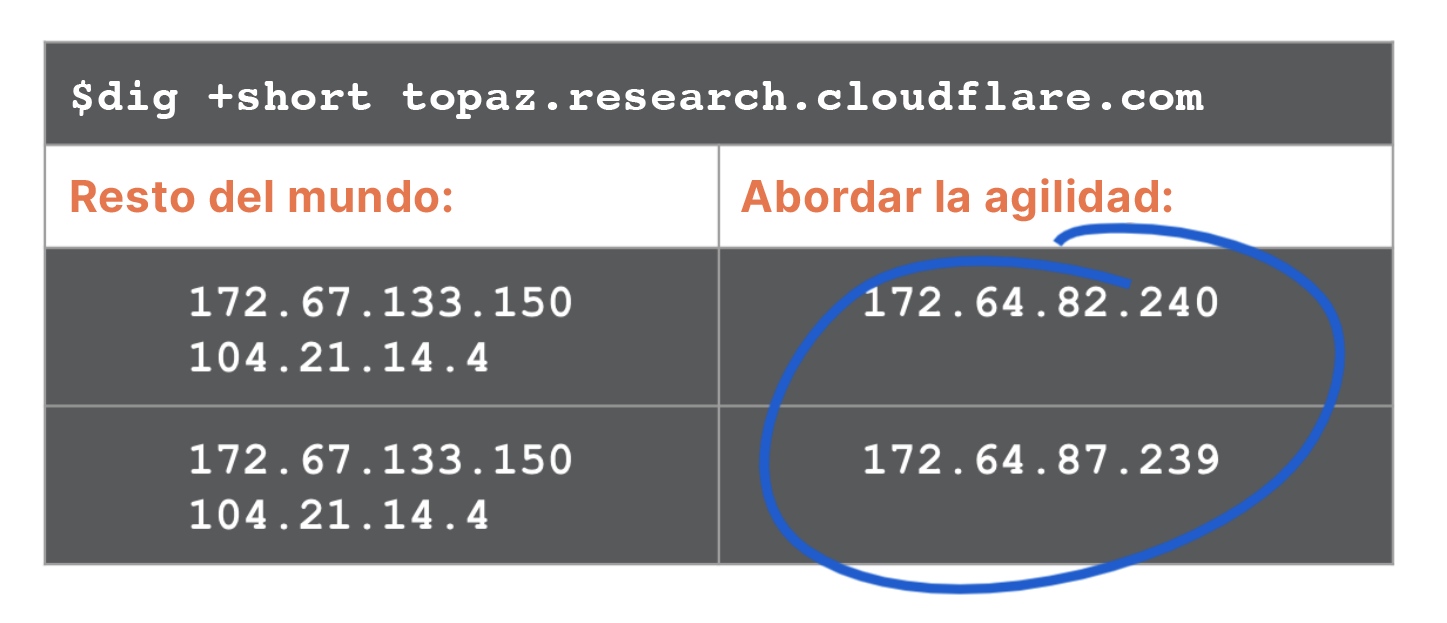
Para aquellos que se pregunten sobre el tráfico de solicitudes posteriores, sí, esto significa que los servidores están configurados para aceptar solicitudes de conexión para cualquiera de los más de 20 millones de dominios en todas las direcciones del conjunto de direcciones.
De acuerdo, pero ¿seguro que los sistemas circundantes de Cloudflare necesitaban una modificación?
No. Se trata de un cambio claro y directo en la canalización de datos para el DNS autoritativo. En cada uno de los anuncios de prefijos de enrutamiento en BGP, DDoS, equilibradores de carga, caché distribuida, ... no se requirieron cambios.
Sin embargo, hay un efecto secundario interesante. La selección aleatoria es para las direcciones IP lo que un buen algoritmo hash es para una tabla hash. Asigna uniformemente una entrada de tamaño arbitrario a un número fijo de salidas. El efecto se puede ver observando las medidas de carga por dirección IP antes y después de la selección aleatoria, como en los gráficos siguientes. Estos datos se han extraído de muestras del 1 % de las solicitudes en un centro de datos durante siete días.
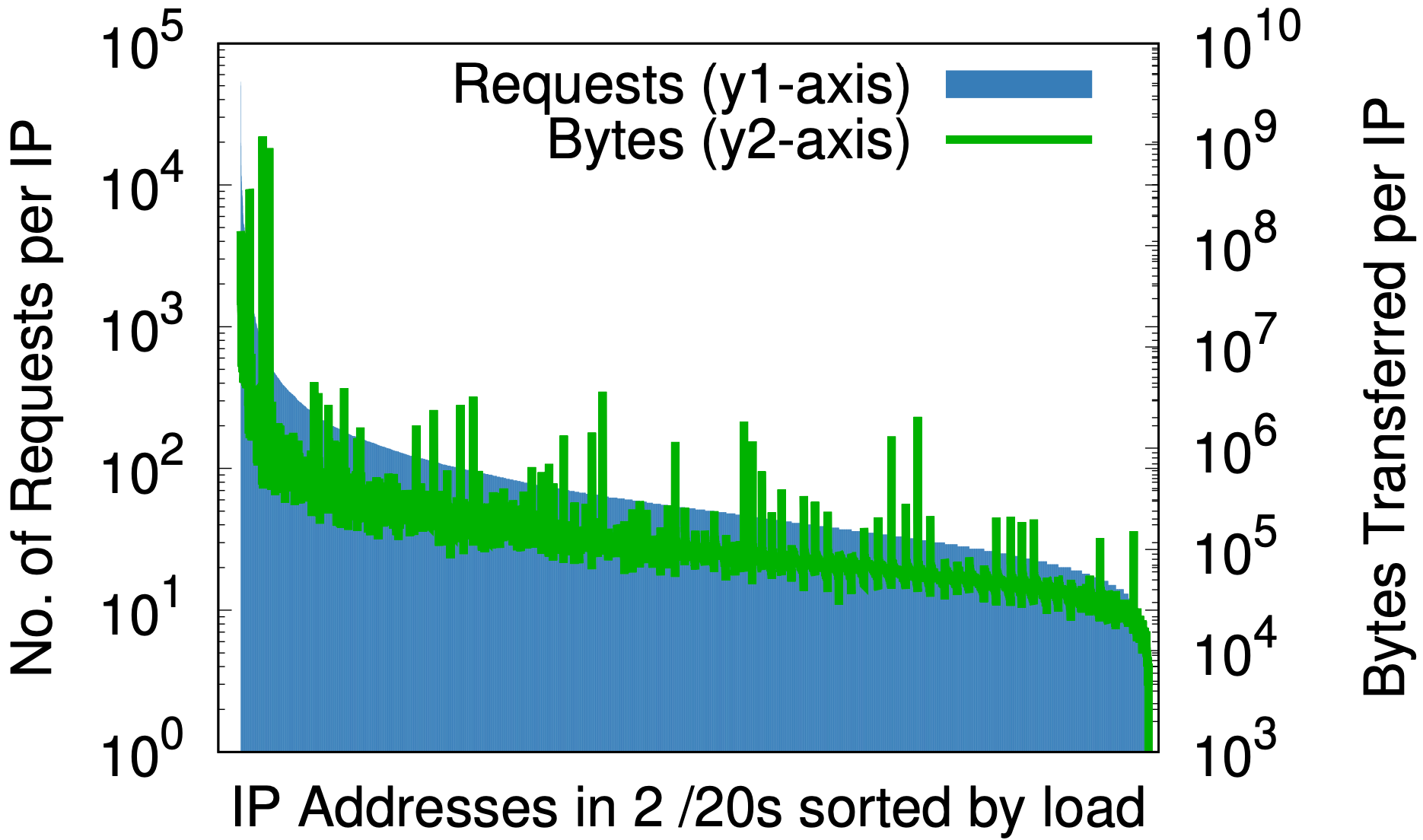
Antes de Addressing Agility
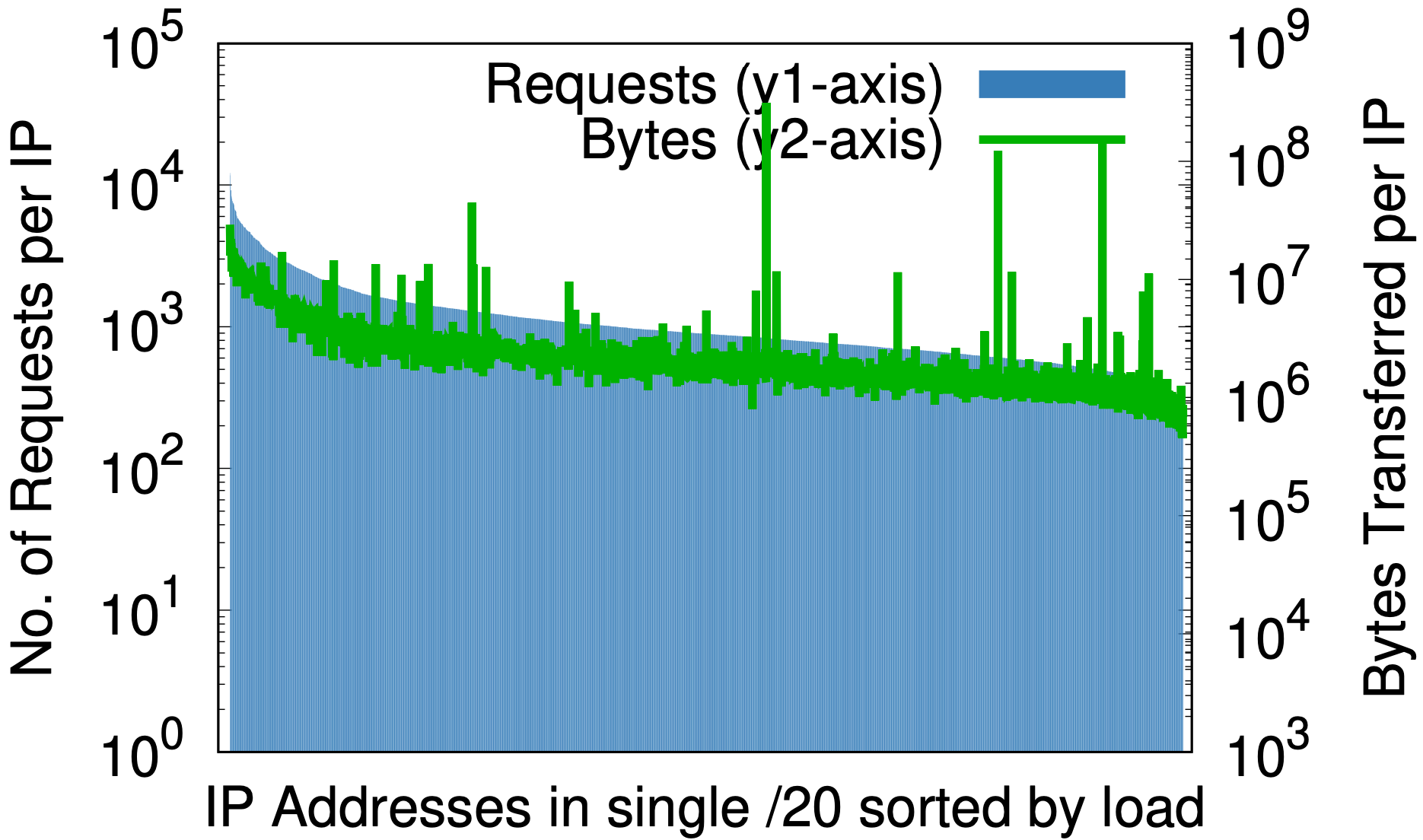
Selección aleatoria en /20
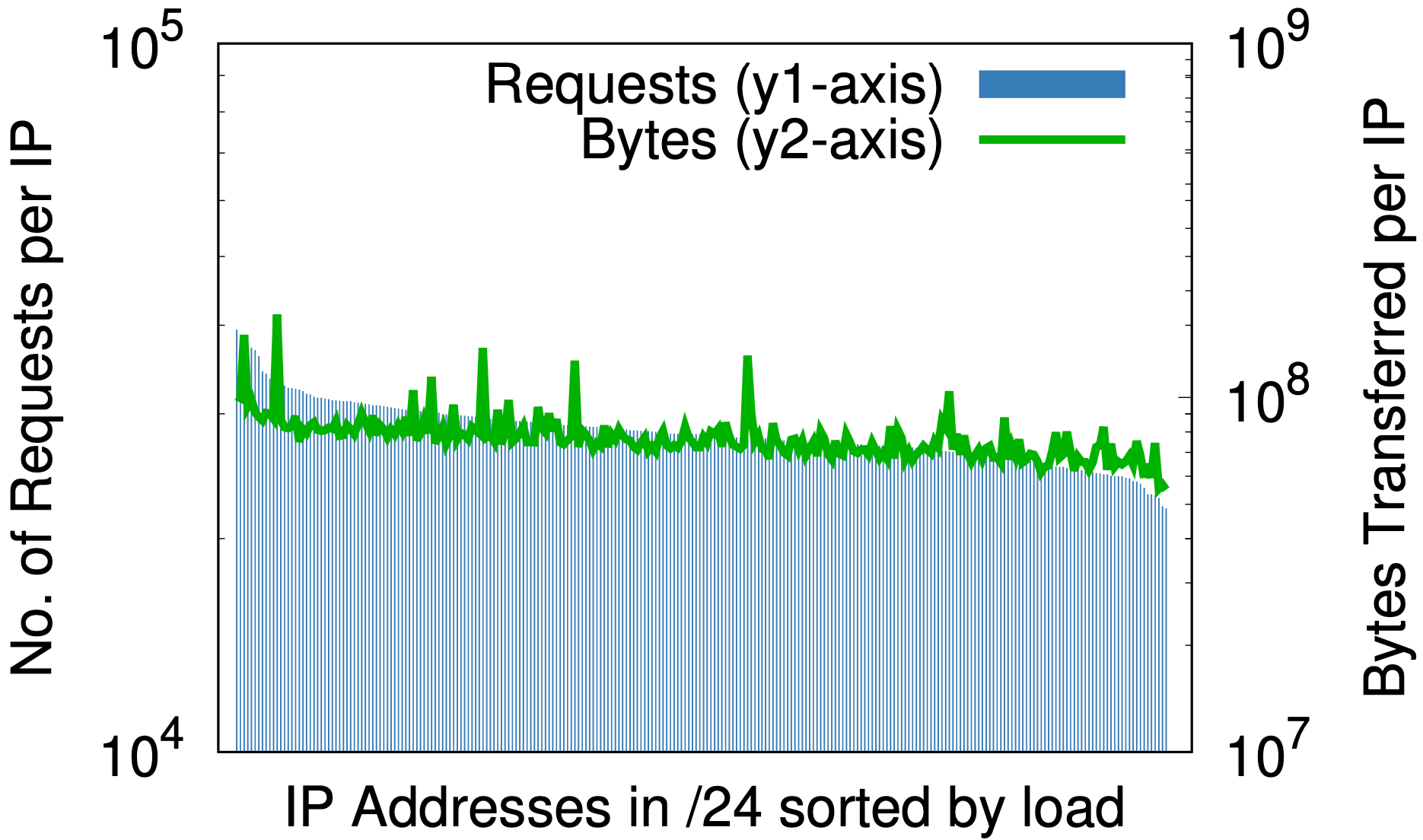
Selección aleatoria en /24
Antes de la selección aleatoria, solo para una pequeña parte del espacio IP de Cloudflare, (a) la diferencia entre las mayores y menores solicitudes por IP (eje y1 a la izquierda) es de tres órdenes de magnitud. De forma similar, los bytes por IP (eje y2 a la derecha) son de casi seis órdenes de magnitud. Después de la selección aleatoria, (b) para todos los dominios en un solo prefijo /20 que anteriormente ocupaban varios /20, estos se reducen hasta 2 y 3 órdenes de magnitud, respectivamente. Si se da un paso más hasta /24 en (c), la selección aleatoria por consulta de más de 20 millones de zonas en 256 direcciones reduce las diferencias de carga a pequeños factores constantes.
Esto podría ser importante para cualquier proveedor de servicios de contenido que piense en ofrecer recursos por dirección IP. Las predicciones a priori de la carga generada por un cliente pueden ser difíciles. Los gráficos anteriores demuestran que el mejor camino a seguir es dar todas las direcciones a todos los nombres.
¿Seguro que no afecta a Internet?
También en este caso la respuesta es no. Bueno, tal vez sea mejor matizar. "No, la selección aleatoria no afecta en nada... pero puede exponer las vulnerabilidades de los sistemas y sus diseños".
Cualquier sistema que pueda verse afectado por la selección aleatoria de direcciones parece tener un prerrequisito: que se atribuya algún significado a la dirección IP más allá de la mera disponibilidad. Addressing Agility mantiene e incluso restablece la semántica de las direcciones IP y el núcleo de la arquitectura de Internet, pero interrumpirá los sistemas de software que hacen suposiciones sobre su significado.
Vamos a ver primero algunos ejemplos, contestaremos a la pregunta de por qué no importan, y luego seguiremos con un pequeño cambio en la agilidad de direccionamiento que evita los puntos débiles (con el uso de una única dirección IP):
- La fusión de conexiones HTTP permite a un cliente reutilizar las conexiones existentes para solicitar recursos de diferentes orígenes. Los clientes como Firefox que permiten la fusión cuando la autoridad URI (identificador de recursos uniforme) coincide con la conexión no se ven afectados. Sin embargo, los clientes que requieren que el servidor URI se resuelva en la misma dirección IP que la conexión dada, fallarán.
- Los servicios no basados en TLS o HTTP se pueden ver afectados. Un ejemplo es ssh, que mantiene una asignación de nombre de servidor a IP en su known_hosts. Esta asociación, aunque comprensible, es obsoleta y ya no funciona dado que muchos registros DNS actualmente devuelven más de una dirección IP.
- Los certificados TLS sin SNI requieren una dirección IP dedicada. Los proveedores se ven obligados a facturar un extra porque cada dirección solo puede admitir un único certificado sin SNI. El problema mayor, independiente de la IP, es el uso de TLS sin SNI. Hemos empezado a trabajar para comprender el uso de TLS sin SNI para acabar, con suerte, con esta lamentable herencia.
- Las protecciones DDoS que dependen de las direcciones IP de destino pueden verse afectadas, inicialmente. Nosotros diríamos que abordar la agilidad es beneficioso por dos razones. En primer lugar, la selección aleatoria de las IP distribuye la carga de los ataques entre todas las direcciones en uso, sirviendo efectivamente como un equilibrador de carga de capa 3. En segundo lugar, las mitigaciones de DoS suelen funcionar cambiando las direcciones IP, una capacidad que es inherente a Addressing Agility.
Todos para uno y uno para todos
Empezamos con más de 20 millones de zonas vinculadas a direcciones en decenas de miles de direcciones, y las servimos con éxito desde 4.096 direcciones en un prefijo /20 y luego 256 direcciones en un prefijo /24. Sin duda, esta tendencia plantea la siguiente pregunta:
Si la selección aleatoria funciona en n direcciones, entonces ¿por qué no en una dirección?
¿Cuál es la explicación? Recordemos el comentario anterior sobre la selección aleatoria en direcciones IP equivalente a un hash perfecto en una tabla hash. Lo que ocurre con las estructuras basadas en hash bien diseñadas es que conservan sus propiedades para cualquier tamaño de la estructura, incluso de 1. Tal reducción sería una verdadera prueba de los pilares sobre los que se basa Addressing Agility.
Así que, hicimos la prueba. Desde un conjunto de direcciones con prefijo /20, a un conjunto de /24 y luego, a partir de junio de 2021, a un conjunto de direcciones de /32, y de manera equivalente a uno de /128 (Ao1). No solo funciona, sino que lo hace muy bien. Los problemas que podría plantear la selección aleatoria se resuelven con Ao1. Por ejemplo, los servicios que no son TLS o HTTP tienen una dirección IP fiable (o al menos no aleatoria y hasta que haya un cambio de política en el nombre). Además, la fusión de las conexiones HTTP cae como si fuera gratis y, sí, vemos un aumento de los niveles de fusión donde se utiliza Ao1.
Pero, ¿por qué en IPv6, donde hay tantas direcciones?
Un argumento en contra del enlace a una única dirección en IPv6 es que no hay necesidad porque es poco probable que se agoten las direcciones. Se trata de una posición anterior a la de CIDR que, según afirmamos, es favorable en el mejor de los casos e irresponsable en el peor. Como ya se ha mencionado, el número de direcciones en IPv6 dificulta el razonamiento sobre ellas. En lugar de preguntarnos por qué utilizar una única dirección IPv6, deberíamos preguntarnos "¿por qué no?".
¿Existen implicaciones previas? Sí, ¡y oportunidades!
Ao1 revela una serie de implicaciones totalmente diferentes respecto a la selección aleatoria de direcciones IP que, posiblemente, nos ofrece una ventana al futuro del enrutamiento y la disponibilidad de Internet al amplificar los efectos que pueden tener acciones aparentemente pequeñas.
¿Por qué? El número de nombres posibles de longitud variable en el universo siempre superará el número de direcciones de longitud fija. Esto significa que, por el principio de Dirichlet o principio del palomar, las direcciones IP únicas deben ser compartidas por múltiples nombres, y diferentes contenidos de partes no relacionadas.
Merece la pena plantear los posibles efectos previos agravados por Ao1, que se describen a continuación. Sin embargo, hasta ahora no hemos visto ninguno de ellos en nuestras evaluaciones, ni han surgido en las comunicaciones con redes previas.
- Los errores de enrutamiento previos son inmediatos y totales. Si todo el tráfico llega a una única dirección (o prefijo), los errores de enrutamiento previos afectan a todo el contenido por igual. (Esta es la razón por la que Cloudflare devuelve dos direcciones en rangos de direcciones no contiguos). Cabe destacar, sin embargo, que lo mismo ocurre con el bloqueo de amenazas.
- Se podrían activar protecciones DoS previas. Es lógico suponer que la concentración de solicitudes y tráfico en una sola dirección se pueda considerar como un ataque DoS previo y activar las protecciones que haya.
En ambos casos, las acciones son mitigadas por la capacidad de Addressing Agility de cambiar las direcciones en masa a gran velocidad. La prevención también es posible, pero requiere una comunicación y un debate abiertos.
Queda un último efecto previo:
- El agotamiento de los puertos en la NAT de IPv4 podría acelerarse, ¡y se soluciona con IPv6! Desde el punto de vista del cliente, el número de conexiones simultáneas permitidas a una dirección está limitado por el tamaño del campo de puerto de un protocolo de transporte, por ejemplo unos 65K en TCP.
Por ejemplo, en TCP en Linux esto era un problema hasta hace poco. (Véase esta confirmación y SO_BIND_ADDRESS_NO_PORT en la página man de ip(7)). En UDP el problema persiste. En QUIC, los identificadores de conexión pueden prevenir el agotamiento de los puertos, pero se tienen que utilizar. Hasta ahora, sin embargo, todavía no hemos visto ninguna evidencia de que esto sea un problema.
Aun así, y esto es lo mejor, hasta donde sabemos, este es el único riesgo para los usos de una sola dirección, y también se resuelve inmediatamente al migrar a IPv6. (Así que, proveedores de soluciones de Internet y administradores de redes, ¡adelante con la implantación de IPv6!)
Esto es solo el principio
Y así terminamos como empezamos. Sin límite en el número de nombres en una sola dirección IP, y con la posibilidad de cambiar la dirección por consulta, sea por el motivo que sea, ¿qué podrías desarrollar?

De hecho, ¡este es solo el comienzo! La flexibilidad y la capacidad de adaptación al futuro que permite Addressing Agility nos permite imaginar, diseñar y desarrollar nuevos sistemas y arquitecturas. Estamos planeando la detección y mitigación de fugas de rutas BGP para sistemas anycast, plataformas de medición y mucho más.
En este documento y breve exposición, se pueden encontrar más detalles técnicos sobre todo lo anterior, así como los agradecimientos a tantas personas que han ayudado a hacerlo posible. Incluso con estas nuevas posibilidades, siguen existiendo retos. Quedan muchas preguntas en el aire, entre otras:
- ¿Qué políticas pueden expresarse o aplicarse razonablemente?
- ¿Existe una sintaxis o gramática abstracta con la que expresarlas?
- ¿Podríamos utilizar métodos formales y de verificación para evitar políticas erróneas o conflictivas?
Addressing Agility es para todos, incluso necesario para que estas ideas triunfen. Todas las aportaciones e ideas son bienvenidas en [email protected].
Si eres estudiante matriculado en un programa de doctorado o de investigación equivalente y buscas unas prácticas para 2022 en los Estados Unidos o Canadá y en la UE o el Reino Unido, ponte en contacto con nosotros.
Si te interesa contribuir a proyectos como este o ayudar a Cloudflare a desarrollar sus sistemas de gestión de tráfico y direcciones, nuestro equipo de ingeniería de Addressing Agility está buscando gente ¡como tú!