

Einleitung
Mein Team, das Cloudflare PROTOCOLS-Team, ist für die Beendigung des HTTP-Datenverkehrs am Rande des Cloudflare-Netzwerks zuständig. Wir beschäftigen uns mit Funktionen im Zusammenhang mit: TCP, QUIC, TLS und Secure Certificate Management, HTTP/1 sowie HTTP/2. Im ersten Quartal waren wir für die Implementierung des Produkts Verbesserte HTTP/2-Priorisierung verantwortlich, das Cloudflare in der Speed Week vorgestellt hat.
Das ist ein sehr spannendes Projekt für uns, und es ist noch einmal so spannend, die Ergebnisse zu sehen. Aber im Laufe des Projekts gewannen wir eine Reihe interessanter Erkenntnisse über NGINX: den HTTP-orientierten Server, auf dem Cloudflare derzeit seine Software-Infrastruktur bereitstellt. Wir waren uns schnell sicher, dass unser Projekt „Verbesserte HTTP/2-Priorisierung“ nicht einmal mäßigen Erfolg erzielen konnte, wenn die internen Abläufe von NGINX nicht verändert wurden.
Aufgrund dieser Erkenntnisse haben wir parallel zur Arbeit am Priorisierungs-Produkt eine Reihe von wesentlichen Änderungen an der internen Struktur von NGINX vorgenommen. Dieser Blogbeitrag beschreibt die Motivation hinter den strukturellen Veränderungen, wie wir an sie herangegangen sind und welche Auswirkungen sie hatten. Wir identifizieren auch zusätzliche Änderungen, die wir unserer Roadmap hinzufügen wollen und die hoffentlich die Leistung noch weiter verbessern.
Hintergrund
Die verbesserte HTTP/2-Priorisierung zielt darauf ab, etwas für den Webverkehr zu tun, der zwischen einem Client und einem Server fließt: Sie bietet eine Möglichkeit, die vielen HTTP/2-Streams, die vom Upstream (Server- oder Ursprungsseite) kommen, in eine einzige HTTP/2-Verbindung zu formen, die downstream fließt (Client-Seite).
Die verbesserte HTTP/2-Priorisierung ermöglicht es Website-Besitzern und den Edge-Systemen von Cloudflare, die Regeln dafür zu festzulegen, wie verschiedene Objekte in der einzelnen HTTP/2-Verbindung kombiniert werden sollen: Ob ein bestimmtes Objekt Priorität haben, die Verbindung dominieren und den Client so schnell wie möglich erreichen soll oder ob eine Gruppe von Objekten die Kapazität der Verbindung gleichmäßig teilen und mehr Gewicht auf Parallelität gelegt werden soll.
Infolgedessen ermöglicht die verbesserte HTTP/2-Priorisierung Website-Besitzern, zwei Probleme anzugehen, die zwischen einem Client und einem Server bestehen: die Steuerung der Priorität und Reihenfolge der Objekte und die optimale Nutzung einer begrenzten Verbindungsressource, die in den verschiedenen Phasen auf dem Verbindungspfad durch eine Reihe von Faktoren wie Bandbreite, Traffic-Volumen und CPU-Auslastung eingeschränkt sein kann.
Was haben wir gesehen?
Der Schlüssel zur Priorisierung besteht darin, zwei oder mehr HTTP/2-Streams vergleichen zu können, um zu bestimmen, welcher Frame als nächstes an der Reihe sein soll. Das Projekt „Verbesserte HTTP/2-Priorisierung“ hat uns notwendigerweise in die zentrale NGINX-Codebasis geführt, da wir die Art und Weise, wie NGINX HTTP/2-Datenframes vergleicht und in die Warteschlange stellt, während sie an den Client zurückgeschrieben werden, grundlegend ändern wollten.
Sehr früh in der Analysephase, als wir die Feinheiten von NGINX unter die Lupe nahmen, um einen Überblick über den Ort unserer vorgeschlagenen Funktionen zu bekommen, stellten wir eine Reihe von Mängeln in der Struktur von NGINX selbst fest, insbesondere: wie es Daten vom Upstream (Server-Seite) downstream (Client-Seite) verschob und wie es diese Daten in den verschiedenen internen Phasen zwischenspeicherte (pufferte). Die wichtigste Schlussfolgerung aus unserer frühen Analyse von NGINX war, dass es weitgehend versäumte, den Datenframes des Streams „Proximität“ zu geben. Entweder wurden Streams im NGINX HTTP/2-Layer in isolierter Folge verarbeitet oder Frames verschiedener Streams verbrachten sehr wenig Zeit am selben Ort, z. B. in einer gemeinsamen Warteschlange. Der Nettoeffekt war eine Verringerung der Möglichkeiten für einen sinnvollen Vergleich.
Wir haben eine neue, wenig wissenschaftliche, aber nützliche Messgröße eingeführt: Potenzial, um zu beschreiben, wie effektiv die Strategien der verbesserten HTTP/2-Priorisierung (oder sogar die standardmäßige NGINX-Priorisierung) auf die Datenströme in der Warteschlange angewendet werden können. Potenzial ist nicht so sehr eine Messgröße für die Effektivität der Priorisierung per se; diese Metrik hoben wir uns für den späteren Verlauf des Projekts auf. Es handelt sich eher um eine Messgröße für die Höhe der Beteiligung bei der Anwendung des Algorithmus. Einfach ausgedrückt, betrachtet es die Anzahl der Streams und Frames, die in einer Iteration der Priorisierung enthalten sind, wobei mehr Streams und mehr Frames zu einem höheren Potenzial führen.
Was wir von Anfang an sehen konnten, war, dass NGINX standardmäßig geringes Potenzial zeigte: Anweisungen zur Priorisierung beim Seitenaufbau entweder vom Browser, wie es im herkömmlichen HTTP/2-Priorisierungsmodell der Fall ist, oder von unserer verbesserten HTTP/2-Priorisierung waren praktisch nutzlos.
Was haben wir getan?
Mit dem Ziel, die spezifischen Probleme im Zusammenhang mit Potenzial und auch den allgemeinen Durchsatz des Systems zu verbessern, haben wir einige wichtige Schwachpunkte von NGINX identifiziert. Diese Punkte, die im Folgenden beschrieben werden, wurden entweder im Rahmen unserer ersten Veröffentlichung der verbesserten HTTP/2-Priorisierung bearbeitet und verbessert oder sind nun zu eigenen sinnvollen Projekten geworden, denen wir uns im Laufe der nächsten Monate widmen werden.
Rückgewinnung von HTTP/2-Frame-Schreib-Warteschlangen
Die Rückgewinnung der Schreib-Warteschlange wurde erfolgreich mit unserer Veröffentlichung der verbesserten HTTP/2-Priorisierung ausgeliefert. Ironischerweise war es keine Änderung am ursprünglichen NGINX, sondern es war eine Änderung an unserer Implementierung der verbesserten HTTP/2-Priorisierung, als wir noch nicht mit dem Projekt fertig waren. Sie dient als gutes Beispiel für etwas, das man die Datenerhaltung nennen könnte, eine gute Möglichkeit, das Potenzial zu erhöhen.
Ähnlich wie beim ursprünglichen NGINX platziert unser Algorithmus der verbesserten HTTP/2-Priorisierung eine Folge von HTTP/2-Datenframes in einer Schreib-Warteschlange als Ergebnis einer Iteration der Priorisierungsstrategien, die auf sie angewendet werden. Der Inhalt der Schreib-Warteschlange ist dazu bestimmt, in den Downstream-TLS-Layer geschrieben zu werden. Wieder ähnlich wie beim ursprünglichen NGINX kann die Schreib-Warteschlange aufgrund des Gegendrucks der Netzwerkverbindung, die vorübergehend die Schreibkapazität ausgeschöpft hat, nur teilweise in den TLS-Layer geschrieben werden.
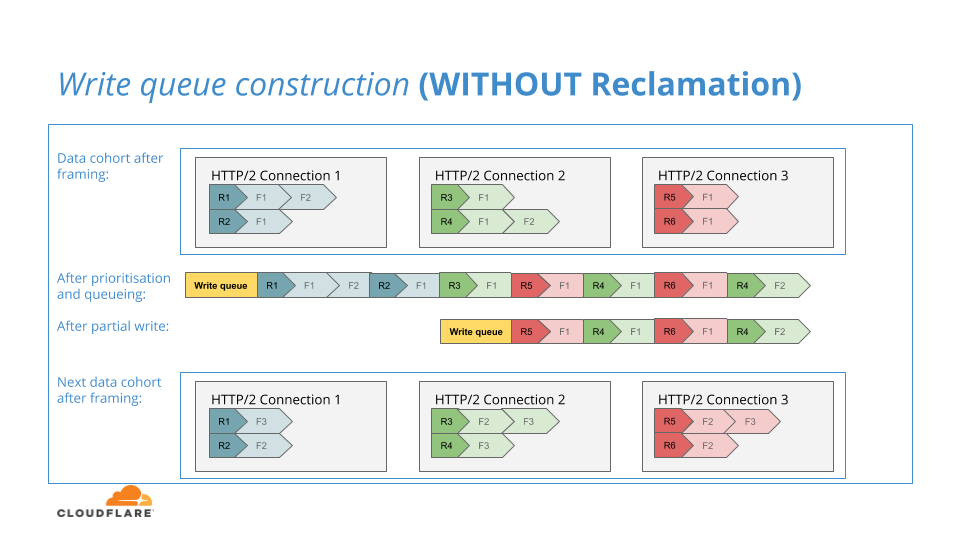
Wenn in einem frühen Stadium unseres Projekts die Schreib-Warteschlange nur teilweise in den TLS-Layer geschrieben wurde, beließen wir die Frames einfach in der Schreib-Warteschlange, bis der Backlog gelöscht war. Dann versuchten wir erneut, diese Daten in einer weiteren Iteration ins Netzwerk zu schreiben – genau wie das ursprüngliche NGINX.
Das ursprüngliche NGINX verfolgt diesen Ansatz, da die Schreib-Warteschlange der einzige Ort ist, an dem wartende Datenframes gespeichert werden. In unserem für die verbesserte HTTP/2-Priorisierung modifizierten NGINX haben wir jedoch eine einzigartige Struktur, die dem ursprünglichen NGINX fehlt: Datenframe-Warteschlangen pro Stream, in denen wir vorübergehend Datenframes zwischenspeichern, bevor unsere Priorisierungsalgorithmen auf sie angewendet werden.
Wir kamen zu dem Schluss, dass wir im Falle eines teilweisen Schreibens in der Lage waren, die ungeschriebenen Frames wieder in ihre Warteschlangen pro Stream zurückzusetzen. Falls hinter der teilweise ungeschriebenen Datenfolge eine weitere Datenfolge ankäme, dann könnten die zuvor ungeschriebenen Frames an einer zusätzlichen Runde von Priorisierungsvergleichen teilnehmen und so das Potenzial unserer Algorithmen erhöhen.
Das folgende Diagramm veranschaulicht diesen Prozess:
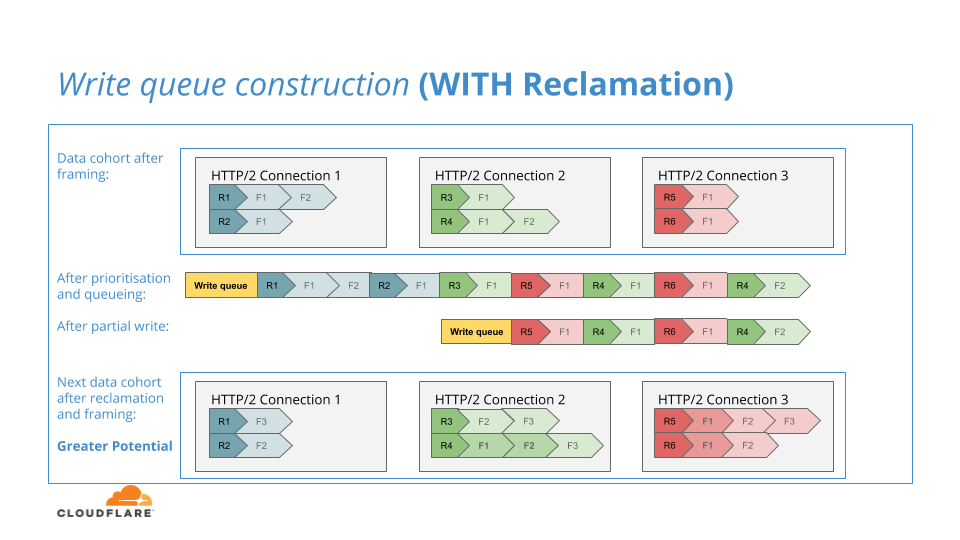
Wir waren sehr erfreut, die verbesserte HTTP/2-Priorisierung mit der Rückgewinnungsfunktion auszuliefern, da diese einzelne Verbesserung das Potenzial stark erhöht und den Umstand ausglich, dass wir die nächste Verbesserung aufgrund ihrer Empfindlichkeit bis zur Speed Week zurückhalten mussten.
Neuordnung des HTTP/2-Frame-Schreibereignisses
In der Cloudflare-Infrastruktur ordnen wir die vielen Streams einer einzelnen HTTP/2-Verbindung des Website-Besuchers mehreren HTTP/1.1-Verbindungen zur Upstream-Kontrollebene von Cloudflare zu.
Als Anmerkung: Es mag kontraintuitiv erscheinen, dass wir Protokolle auf diese Weise herabstufen, und es mag doppelt kontraintuitiv erscheinen, wenn ich verrate, dass wir auch HTTP-Keepalive auf diesen Upstream-Verbindungen deaktivieren, was zu nur einer Transaktion pro Verbindung führt. Diese Vorgehensweise bietet jedoch eine Reihe von Vorteilen, insbesondere in Form einer verbesserten CPU-Arbeitslastverteilung.
Wenn NGINX seine vorgelagerten HTTP/1.1-Verbindungen auf Lesetätigkeit überwacht, kann es Lesbarkeit auf vielen dieser Verbindungen erkennen und sie alle in einem Stapel verarbeiten. Innerhalb dieses Stapels wird jedoch jede der vorgelagerten Verbindungen nacheinander einzeln verarbeitet, von Anfang bis Ende: vom Lesen der HTTP/1.1-Verbindung über Framing im HTTP/2-Stream bis hin zum Schreiben der HTTP/2-Verbindung in den TLS-Layer.
Der bestehende NGINX-Workflow ist in diesem Diagramm dargestellt:
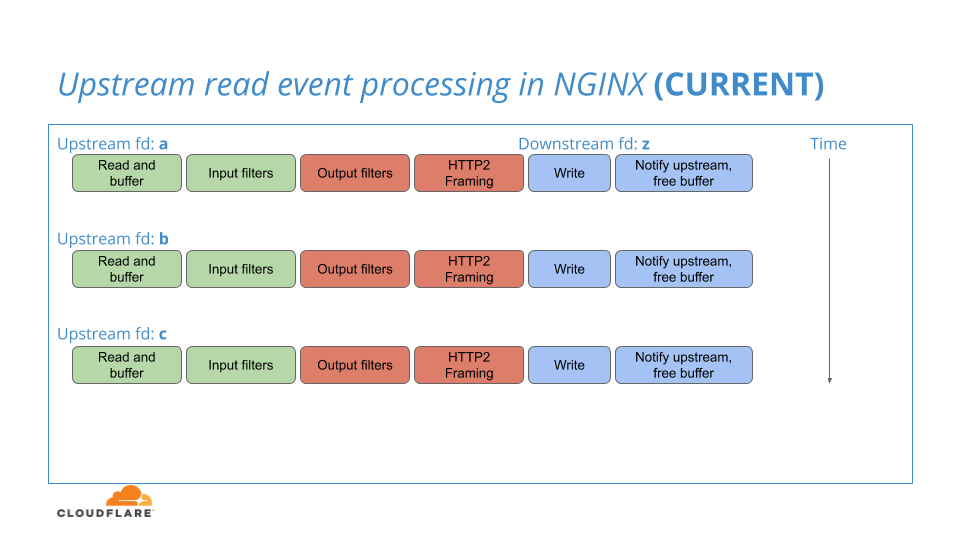
Durch das Übertragen der Frames jedes Streams in den TLS-Layer – jeweils einer nach dem anderen – können viele Frames vollständig durch das NGINX-System geleitet werden, bevor der Gegendruck auf die Downstream-Verbindung zum Aufbau der Warteschlange führt, was eine Möglichkeit für diese Frames bietet, in Proximität zu sein, und die Anwendung der Priorisierungslogik ermöglicht. Das wirkt sich negativ auf das Potenzial aus und reduziert die Wirksamkeit der Priorisierung.
Das durch Cloudflares verbesserte HTTP/2-Priorisierung modifizierte NGINX zielt darauf ab, den oben beschriebenen internen Workflow in das folgende Modell umzuordnen:
Obwohl wir weiterhin Upstream-Daten in HTTP/2-Datenframes in den separaten Iterationen für jede Upstream-Verbindung einrahmen, übertragen wir diese Frames nicht mehr in eine einzelne Schreib-Warteschlange innerhalb jeder Iteration. Stattdessen ordnen wir die Frames in die oben beschriebenen Warteschlangen pro Stream ein. Anschließend posten wir ein einzelnes Ereignis bis zum Ende der Iterationen pro Verbindung und führen die Priorisierung, das Anstehen und das Schreiben der HTTP/2-Datenframes aller Streams in diesem einzelnen Ereignis durch.
Dieses einzelne Ereignis findet die Folge von Daten, die komfortabel in ihren jeweiligen Warteschlangen pro Stream in enger Proximität gespeichert sind, was das Potenzial der Edge-Priorisierungsalgorithmen erheblich steigert.
In einer Form, die dem tatsächlichem Code nahekommt, sieht der Kern dieser Modifikation etwa so aus:
ngx_http_v2_process_data(ngx_http_v2_connection *h2_conn,
ngx_http_v2_stream *h2_stream,
ngx_buffer *buffer)
{
while ( ! ngx_buffer_empty(buffer) {
ngx_http_v2_frame_data(h2_conn,
h2_stream->frames,
buffer);
}
ngx_http_v2_prioritise(h2_conn->queue,
h2_stream->frames);
ngx_http_v2_write_queue(h2_conn->queue);
}
Dazu:
ngx_http_v2_process_data(ngx_http_v2_connection *h2_conn,
ngx_http_v2_stream *h2_stream,
ngx_buffer *buffer)
{
while ( ! ngx_buffer_empty(buffer) {
ngx_http_v2_frame_data(h2_conn,
h2_stream->frames,
buffer);
}
ngx_list_add(h2_conn->active_streams, h2_stream);
ngx_call_once_async(ngx_http_v2_write_streams, h2_conn);
}
ngx_http_v2_write_streams(ngx_http_v2_connection *h2_conn)
{
ngx_http_v2_stream *h2_stream;
while ( ! ngx_list_empty(h2_conn->active_streams)) {
h2_stream = ngx_list_pop(h2_conn->active_streams);
ngx_http_v2_prioritise(h2_conn->queue,
h2_stream->frames);
}
ngx_http_v2_write_queue(h2_conn->queue);
}
Es besteht ein hohes Risiko bei dieser Modifikation, denn obwohl sie bemerkenswert klein ist, nehmen wir den etablierten und debuggten Ereignisablauf in NGINX und wandeln ihn in erheblichem Maße um. Wie beim Herausnehmen einiger Jenga-Stücke aus dem Turm und deren Platzierung an anderer Stelle riskieren wir Wettlaufsituationen, Ereignis-Fehler und Event-Black-Holes, die zu Störungen bei der Transaktionsverarbeitung führen.
Aufgrund dieses Risikos haben wir diese Änderung während der Speed Week nicht vollständig freigegeben, aber wir werden sie weiterhin testen und für die zukünftige Veröffentlichung weiterentwickeln.
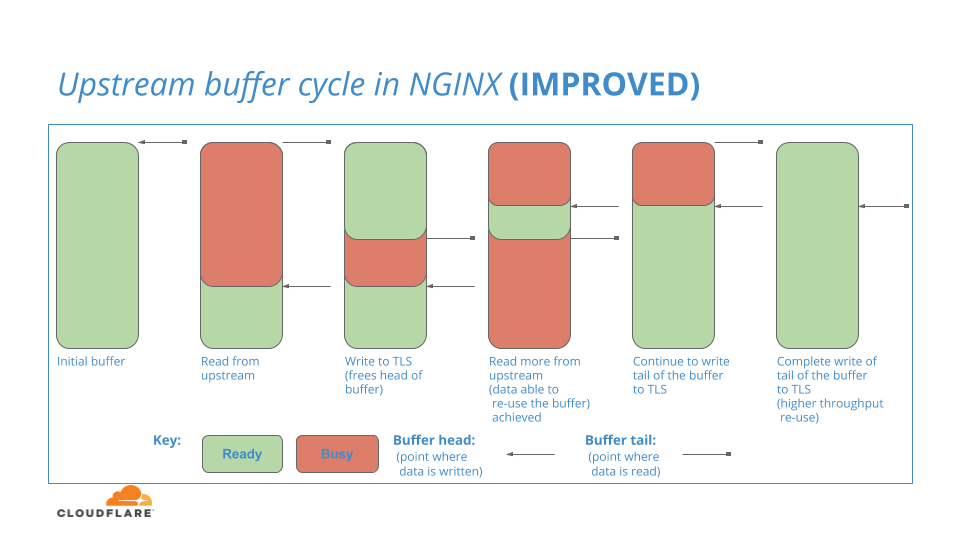
Teilweise Wiederverwendung von Upstream-Puffern
Nginx verfügt über einen internen Pufferbereich zum Speichern von Verbindungsdaten, die aus dem Upstream gelesen werden. Zunächst ist der gesamte Puffer einsatzbereit. Wenn Daten aus dem Upstream in den Ready-Puffer gelesen werden, wird der Teil des Puffers, der die Daten enthält, an den Downstream-HTTP/2-Layer übergeben. Da HTTP/2 die Verantwortung für diese Daten übernimmt, wird dieser Teil des Puffers als Busy markiert und bleibt so lange Busy, wie es dauert, bis der HTTP/2-Layer die Daten in den TLS-Layer geschrieben hat, was ein Prozess ist, der einige Zeit dauern kann (aus Rechnersicht!).
Während dieser Zeitspanne kann der Upstream-Layer weitere Daten in die verbleibenden Ready-Abschnitte des Puffers einlesen und diese inkrementellen Daten an den HTTP/2-Layer weiterleiten, bis keine Ready-Abschnitte mehr verfügbar sind.
Wenn Busy-Daten schließlich im HTTP/2-Layer fertig verarbeitet sind, wird der Pufferspeicher, der diese Daten enthielt, markiert als: Free
Der Prozess ist in diesem Diagramm veranschaulicht:
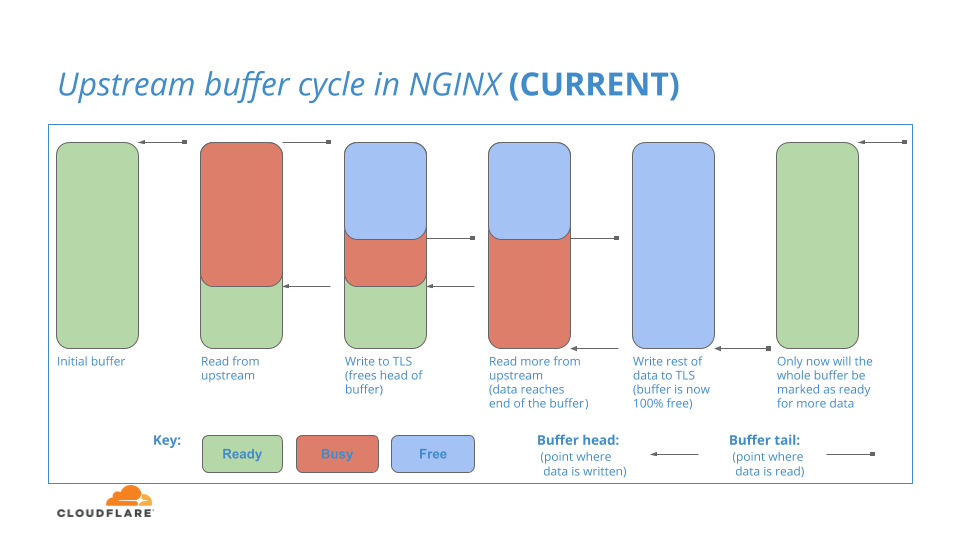
Sie könnten fragen: Wenn der führende Teil des Upstream-Puffers als Free markiert ist (im Diagramm blau), obwohl der nachfolgende Teil des Upstream-Puffers noch Busy ist, kann der Free-Teil dann wieder verwendet werden, um weitere Daten aus dem Upstream zu lesen?
Die Antwort auf diese Frage lautet: NEIN
Da ein kleiner Teil des Puffers noch Busy ist, weigert sich NGINX, die Wiederverwendung des gesamten Pufferspeichers für Lesevorgänge zu erlauben. Nur wenn der gesamte Puffer Free ist, kann der Puffer in den Status Ready zurückgesetzt und für eine weitere Iteration von Upstream-Lesevorgängen verwendet werden. Zusammenfassend lässt sich also sagen, dass Daten aus dem Upstream in den Ready-Bereich unten im Puffer gelesen werden können, nicht aber in den Free Bereich oben im Puffer.
Das ist ein Manko von NGINX und eindeutig unerwünscht, da es den Datenfluss in das System unterbricht. Wir fragten uns: Was wäre, wenn wir durch diese Pufferregion gehen und Teile oben wiederverwenden könnten, wenn sie Free werden? Wir versuchen, diese Frage in naher Zukunft zu beantworten, indem wir das folgende Pufferungsmodell in NGINX testen:
TLS-Layer-Pufferung
Im obigen Text habe ich mehrmals den TLS-Layer erwähnt und wie der HTTP/2-Layer Daten dorthin schreibt. Im OSI-Netzwerkmodell befindet sich TLS knapp unterhalb des Protokoll-Layers (HTTP/2-Layer) und in vielen bewusst gestalteten Netzwerksoftwaresystemen wie NGINX sind die Softwareschnittstellen so getrennt, dass sie dieses Layering nachahmen.
Der NGINX HTTP/2-Layer sammelt die aktuelle Folge von Datenframes, platziert sie in Prioritätsreihenfolge in einer Ausgabewarteschlange und sendet diese Warteschlange dann an den TLS-Layer. Der TLS-Layer verwendet einen Puffer pro Verbindung, um HTTP/2-Layer-Daten zu sammeln, bevor er die eigentlichen kryptografischen Transformationen dieser Daten durchführt.
Der Zweck des Puffers besteht darin, dem TLS-Layer eine sinnvollere Datenmenge zum Verschlüsseln zu geben, denn wenn der Puffer zu klein wäre oder der TLS-Layer sich einfach auf die Dateneinheiten des HTTP/2-Layers verließe, dann könnte sich der Aufwand für die Verschlüsselung und Übertragung der Vielzahl kleiner Blöcke negativ auf den Systemdurchsatz auswirken.
Das folgende Diagramm veranschaulicht diese Untergrößen-Puffersituation:
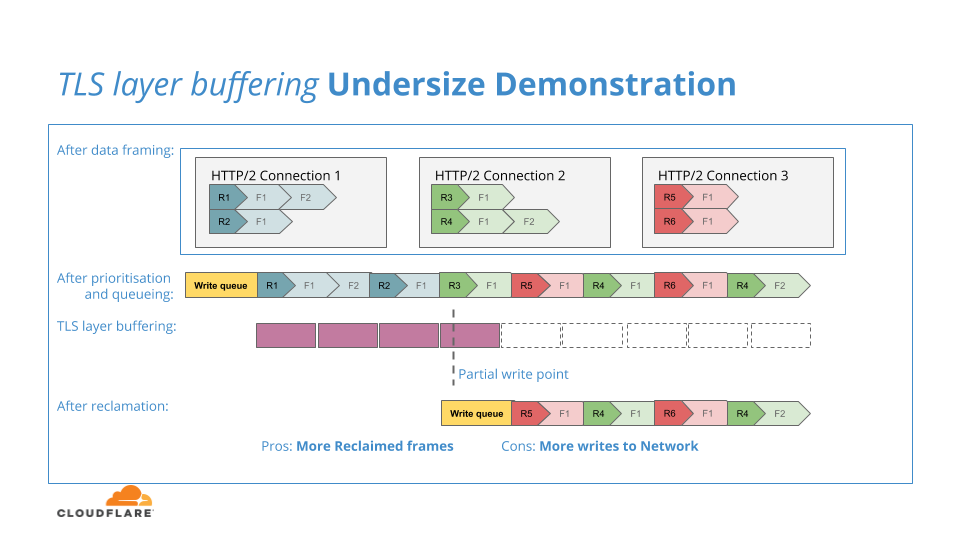
Wenn der TLS-Puffer zu groß ist, wird eine übermäßige Menge an HTTP/2-Daten zur Verschlüsselung übertragen. Wenn diese aufgrund von Gegendruck nicht in das Netzwerk geschrieben werden könnten, würden sie in den TLS-Layer eingesperrt und stünden nicht zur Verfügung, um zum Rückgewinnungsprozess zum HTTP/2-Layer zurückzukehren, was die Effektivität der Rückgewinnung verringern würde. Das folgende Diagramm veranschaulicht diese Übermaß-Puffersituation:
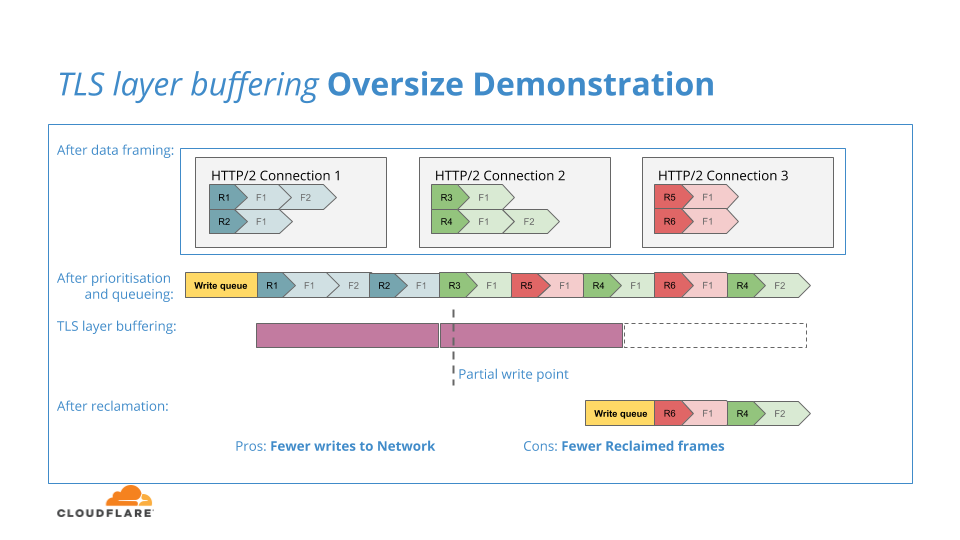
In den kommenden Monaten werden wir versuchen, den „goldenen Punkt“ für die TLS-Pufferung zu finden: Wir werden versuchen, den TLS-Puffer so zu dimensionieren, dass er groß genug ist, um die Effizienz von Verschlüsselungs- und Netzwerkschreibvorgängen aufrechtzuerhalten, aber nicht so groß, dass die Reaktionsfähigkeit auf unvollständige Netzwerkschreibvorgänge und die Effizienz der Rückgewinnung verringert werden.
Vielen Dank – Weiter!
Das Projekt „Verbesserte HTTP/2-Priorisierung“ hat das hochgesteckte Ziel, die Art und Weise, wie wir Datenverkehr von der Cloudflare-Edge an Clients senden, grundlegend neu zu gestalten. Wie die Ergebnisse unserer Tests und das Feedback einiger unserer Kunden zeigen, haben wir das sicherlich erreicht! Eine der wichtigsten Beobachtungen, die wir bei diesem Projekt gemacht haben, war jedoch die entscheidende Rolle, die der interne Datenfluss innerhalb unserer NGINX-Software-Infrastruktur aus Sichte des von unseren Endbenutzern beobachteten Datenverkehrs spielt. Wir fanden heraus, dass das Ändern einiger (wenn auch kritischer) Codezeilen erhebliche Auswirkungen auf die Effektivität und Leistung unserer Priorisierungsalgorithmen haben kann. Ein weiteres positives Ergebnis ist, dass wir uns neben der Verbesserung von HTTP/2 auch darauf freuen können, unsere neu gewonnenen Fähigkeiten und Erkenntnisse zu übertragen und auf HTTP/3 über QUIC anzuwenden.
Wir sind sehr daran interessiert, unsere Änderungen an NGINX mit der Community zu teilen, deshalb haben wir dieses Ticket geöffnet, unter dem wir das Upstreaming der Event-Neuordnung und die teilweise Wiederverwendung des Puffers mit dem NGINX-Team diskutieren werden.
Mit dem weiteren Wachstum von Cloudflare verändern sich auch unsere Anforderungen an unsere Software-Infrastruktur. Cloudflare ist bereits über das Proxying von HTTP/1 über TCP hinausgegangen, um die Termination und Layer-3- und Layer-4-Schutz für jeglichen UDP- und TCP-Datenverkehr zu unterstützen. Jetzt wenden wir uns anderen Technologien und Protokollen wie QUIC und HTTP/3 sowie dem vollständigen Proxying einer Vielzahl weiterer Protokolle wie Messaging und Streaming Media zu.
Für diese Bestrebungen suchen wir nach neuen Wegen, um Fragen zu Themen wie Skalierbarkeit, lokalisierte Leistung, umfassende Leistung, Introspektion und Debuggability, Release-Agilität, Instandhaltbarkeit zu beantworten.
Wenn Sie uns helfen wollen, diese Fragen zu beantworten, und Kenntnisse auf den Gebieten Skalierbarkeit von Hardware und Software, Netzwerkprogrammierung, asynchrones Event- und Futures-basiertes Software-Design, TCP-, TLS-, QUIC-, HTTP-, RPC-Protokolle, Rust oder vielleicht etwas anderes verfügen, dann schauen sie hier.