


Cloudflare möchte Internetwebsites überall schneller, sicherer und zuverlässiger machen. Load Balancing (Lastverteilung) fördert Geschwindigkeit und Zuverlässigkeit und hat sich in den letzten drei Jahren weiterentwickelt.
Lassen Sie uns ein Szenario durchgehen, an dem man etwas besser erkennen kann, was ein Load Balancer ist und welchen Nutzen er bieten kann. Ein normaler Load Balancer besteht aus einer Reihe von Pools, jeweils mit eigenen Ursprungsservern mit Hostnamen und/oder IP-Adressen. Jeder Load Balancer bekommt eine Routingrichtlinie, die den Auswahlprozess für den Pool der Ursprungsserver bestimmt.
Angenommen, Sie entwickeln eine API, die den Cloud-Anbieter ACME Web Services verwendet. Leider hatte ACME in dieser Woche Probleme und der Service ist in den östlichen USA regional ausgefallen. Das führte dazu, dass Ihre Website in diesem Zeitraum keinen Traffic verarbeiten konnte. Dadurch sank das Vertrauen der Nutzer in Ihre Marke und es kam zu Umsatzausfällen. Damit so etwas nicht wieder passiert, entscheiden Sie sich für zwei Maßnahmen: Sie nutzen einen sekundären Cloud-Anbieter (damit ACME nicht zur Schwachstelle, zum „Single Point of Failure“ wird) und Sie nutzen das Load Balancing von Cloudflare, um die Multi-Cloud-Architektur auszunutzen. Durch das Load Balancing von Cloudflare können Sie die Verfügbarkeit Ihrer API für Ihre neue Architektur maximieren. Sie können z. B. Health Checks für jeden Pool von Ursprungsservern festlegen. Durch diese Health Checks können Sie den Zustand Ihrer Ursprungsserver überwachen, indem Sie die HTTP-Statuscodes, die Hauptteile von Antworten und anderes prüfen. Wenn die Antwort eines Ursprungsserver-Pools nicht den Erwartungen entspricht, wird kein Traffic mehr dorthin geleitet. Dadurch werden die Ausfallzeiten für Ihre API bei einem regionalen Ausfall von ACME reduziert, denn der Traffic in dieser Region wird übergangslos zu den Fallback-Serverpools umgeleitet. In diesem Szenario können Sie bei Ihrem sekundären Cloud-Anbieter den Fallback-Pool als Ursprungsserver festlegen. Zusätzlich zu den Health Checks können Sie die Routingrichtlinie „Zufällig“ verwenden, um die API-Anfragen Ihrer Kunden gleichmäßig auf Ihr Backend zu verteilen. Wenn Sie stattdessen die Reaktionszeit optimieren möchten, können Sie die „dynamische Steuerung“ verwenden. Dadurch wird der Traffic an den Ursprungsserver gesendet, der Ihrem Kunden am nächsten ist.
Unsere Kunden sind begeistert von Cloudflare Load Balancing, und wir sind immer bestrebt, unseren Kunden das Leben noch leichter zu machen. Seit der ersten Veröffentlichung von Cloudflare Load Balancing haben uns Kunden immer wieder darum gebeten, einen Analytics-Dienst zu entwickeln, der Einblicke in die Entscheidungen bei der Traffic-Steuerung bietet.
Heute stellen wir Load Balancing Analytics vor. Sie finden es auf der Registerkarte „Traffic“ des Cloudflare-Dashboards. Die drei Hauptkomponenten dieses Analytics-Dienstes sind:
- Eine Übersicht über die Traffic-Ströme, die nach Load Balancer, Pool, Ursprungsserver und Region gefiltert werden können.
- Eine Latenzkarte mit dem Status des Ursprungsservers und Latenzkennzahlen aus dem globalen Cloudflare-Netzwerk mit 194 Städten, das immer noch wächst!
- Ereignisprotokolle über Zustandsänderungen bei Ursprungsservern. Diese Funktion wurde 2018 veröffentlicht und verfolgt Übergänge zwischen Normal- und Fehlerzuständen bei Pools und Ursprungsservern. Wir haben diese Protokolle in die neue Unterregisterkarte „Load Balancing Analytics“ verschoben. Weitere Informationen finden Sie in der Dokumentation.
In diesem Blogbeitrag geht es um die Verteilung der Traffic-Ströme und die Latenzkarte.
Übersicht über Traffic-Ströme
Unsere Anwender wünschen sich einen detaillierten Überblick darüber, wohin ihr Traffic geht und warum er dorthin geht, und außerdem Erkenntnisse über Änderungen, mit denen sie ihre Infrastruktur optimieren können. Mit Load Balancing Analytics kann der Anwender die Traffic-Beanspruchung der Load Balancer, Pools und Ursprungsserver über variable Zeitbereiche hinweg grafisch darstellen lassen.
Wenn man weiß, wie sich die Traffic-Ströme verteilen, kann man den Aufbau neuer Ursprungsserver-Pools besser steuern und an Traffic-Spitzen anpassen. Auch die Beobachtung der Failover-Reaktion bei Ausfällen des Serverpools ist hilfreich.
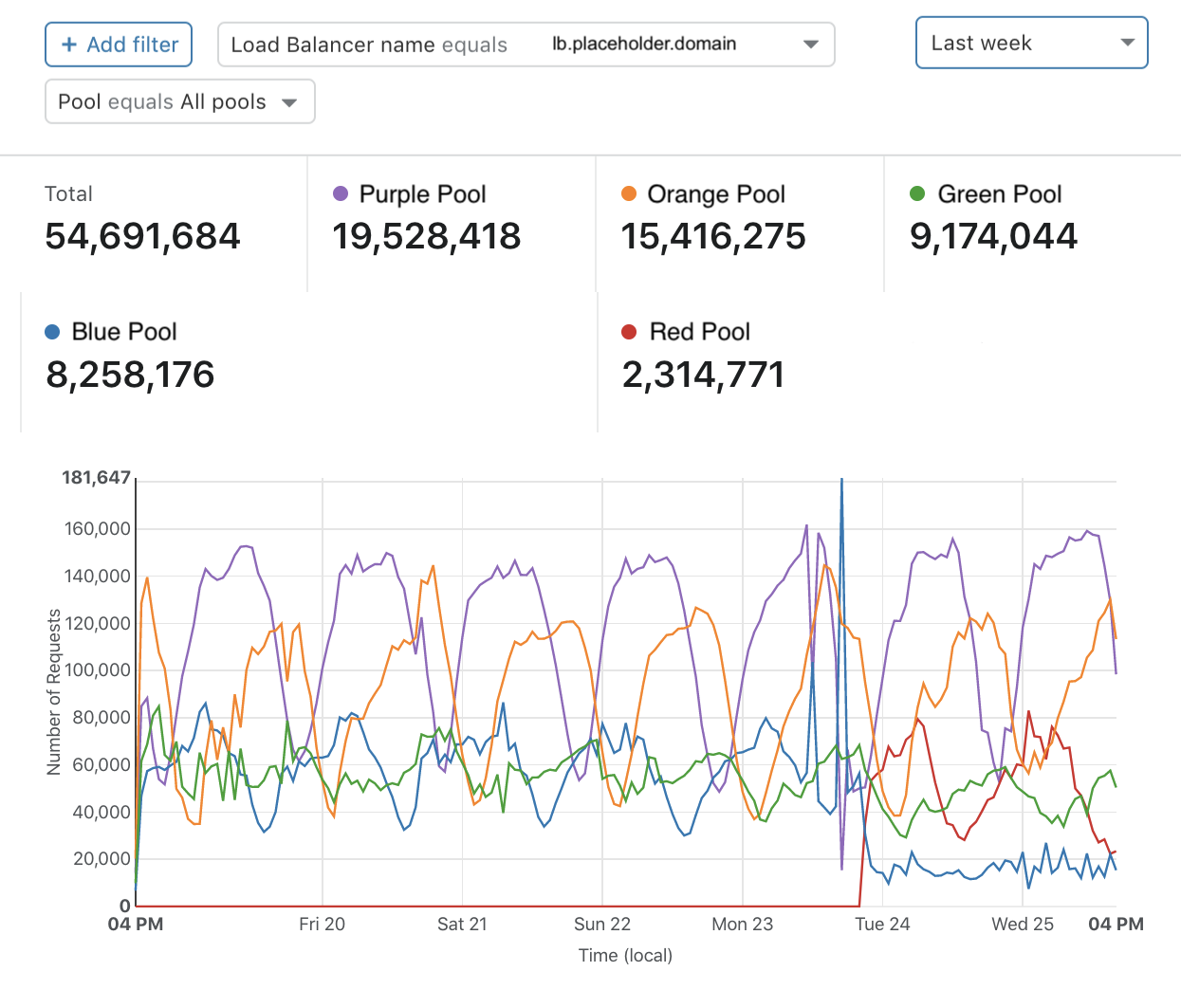
Abbildung 1
Abbildung 1 zeigt eine Übersicht über den Traffic für eine bestimmte Domain. Am Dienstag, dem 24., wurde der rote Pool erstellt und in den Load Balancer aufgenommen. In den folgenden 36 Stunden wurde über den roten Pool mehr Traffic abgewickelt und der blaue und der grüne Pool dadurch entlastet. In diesem Szenario lieferte das Diagramm für die Traffic-Verteilung dem Kunden neue Erkenntnisse. Erstens konnte er erkennen, dass der Traffic in den neuen roten Pool gelenkt wurde. Außerdem konnte er das neue Niveau der Traffic-Verteilung über sein Netzwerk verstehen. Schließlich konnte er überprüfen, ob der Traffic in bestimmten Pools erwartungsgemäß zurückgegangen ist. Derartige Diagramme helfen dabei, im Laufe der Zeit die Kapazität besser zu verwalten und für künftige Anforderungen an die Infrastruktur zu planen.
Latenzkarte
Die Übersicht über die Traffic-Verteilung ist nur ein Teil des ganzen Puzzles. Eine weitere wesentliche Komponente besteht darin, die Performance von Anfragen weltweit zu verstehen. Dies ist nützlich, denn so kann der Kunde dafür sorgen, dass die Anfragen der Nutzer so schnell wie möglich bearbeitet werden, unabhängig davon, aus welchem Teil der Welt die Anfrage stammt.
Die Standardkonfiguration für das Load Balancing umfasst Monitore, die den Zustand der Ursprungsserver des Kunden überprüfen. Diese Monitore können so konfiguriert werden, dass sie von bestimmten Regionen aus oder – für Enterprise-Kunden – von allen Cloudflare-Standorten aus ausgeführt werden. Sie sammeln nützliche Daten, wie z. B. die Roundtrip-Zeit, die aggregiert werden können, um die Latenzkarte zu erstellen.
In dieser Karte wird zusammengefasst, wie reaktionsschnell die Ursprungsserver auf der ganzen Welt sind. So können Kunden Regionen erkennen, in denen bei Anfragen eine unterdurchschnittliche Performance erzielt wird und die deshalb näher untersucht werden sollten. Eine gängige Kennzahl für die Performance ist die Latenz bei Anfragen. Nach unseren Erkenntnissen beträgt die p90-Latenz für alle überwachten Ursprungsserver mit Load Balancing 300 Millisekunden. Das bedeutet, dass 90 % der Health Checks aller Monitore eine Roundtrip-Zeit von weniger als 300 Millisekunden hatten. Mit diesem Wert konnten wir Standorte identifizieren, an denen die Latenz höher war als die p90-Latenz bei anderen Kunden mit Load Balancing.
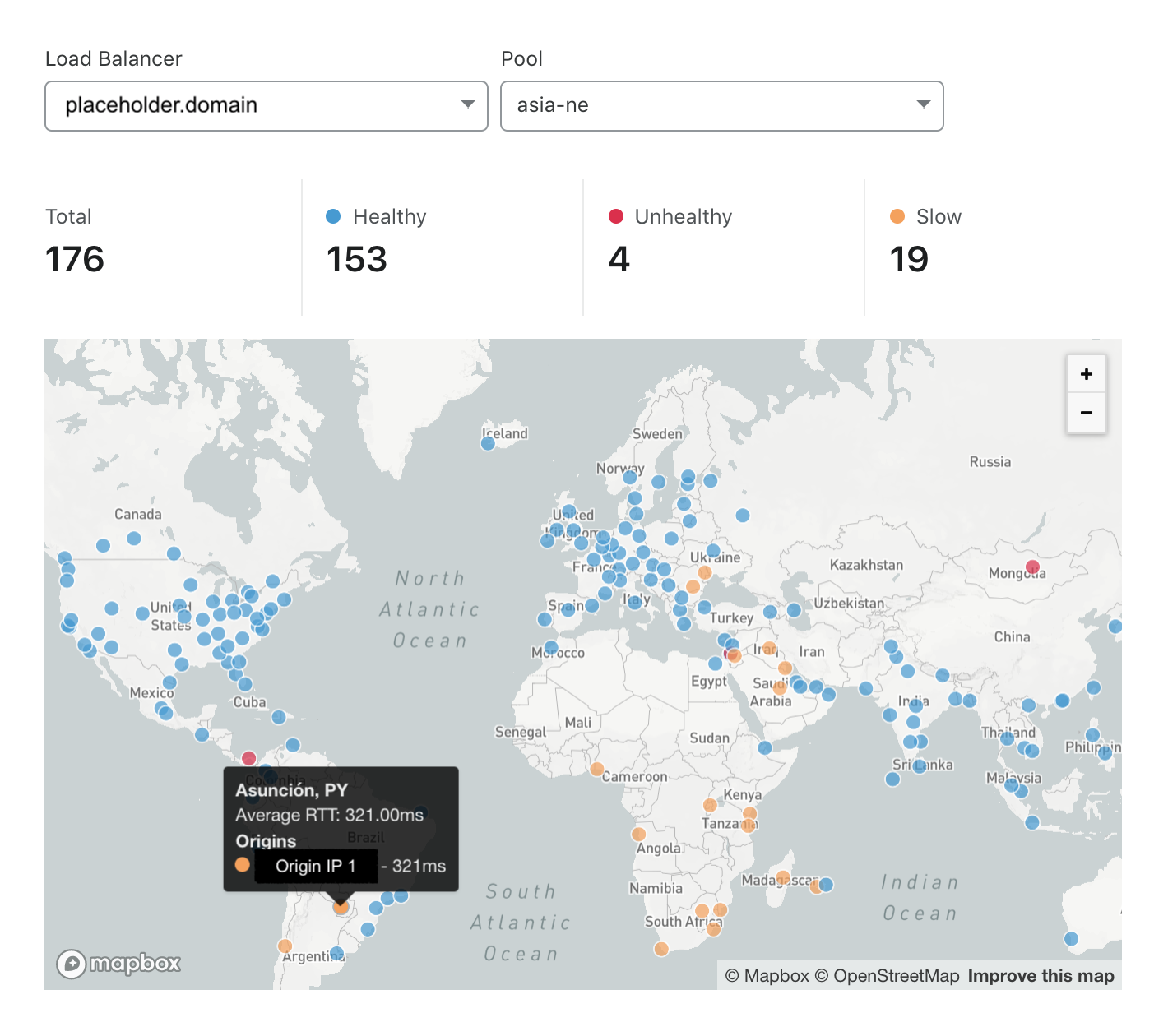
Abbildung 2
In Abbildung 2 wird die Reaktionsgeschwindigkeit des Nordostasien-Pools dargestellt. Der Nordostasien-Pool ist insbesondere für Monitore in Südamerika, dem Nahen Osten und dem südlichen Afrika langsam, aber schnell bei Monitoren, die näher am Ursprungsserver-Pool liegen. Leider bedeutet dies, dass Nutzer in Ländern wie Paraguay bei diesem Pool eine hohe Latenz ihrer Anfragen erleben. Lange Seitenladezeiten ziehen viele negative Folgen nach sich: höhere Absprungraten und geringere Zufriedenheit bei Besuchern sowie ein niedrigeres Suchmaschinen-Ranking. Um diese Auswirkungen zu vermeiden, könnte ein Standortadministrator sich überlegen, einen neuen Serverpool in einer Region einzurichten, die näher an den unterversorgten Regionen liegt. In Abbildung 3 sehen wir das Ergebnis nach der Aufnahme eines neuen Serverpools im östlichen Nordamerika. Wie wir sehen, ist die Anzahl der Standorte, an denen die Domain als fehlerhaft eingestuft wurde, auf Null gesunken und die Anzahl der langsamen Standorte ist um über 50 % geringer.
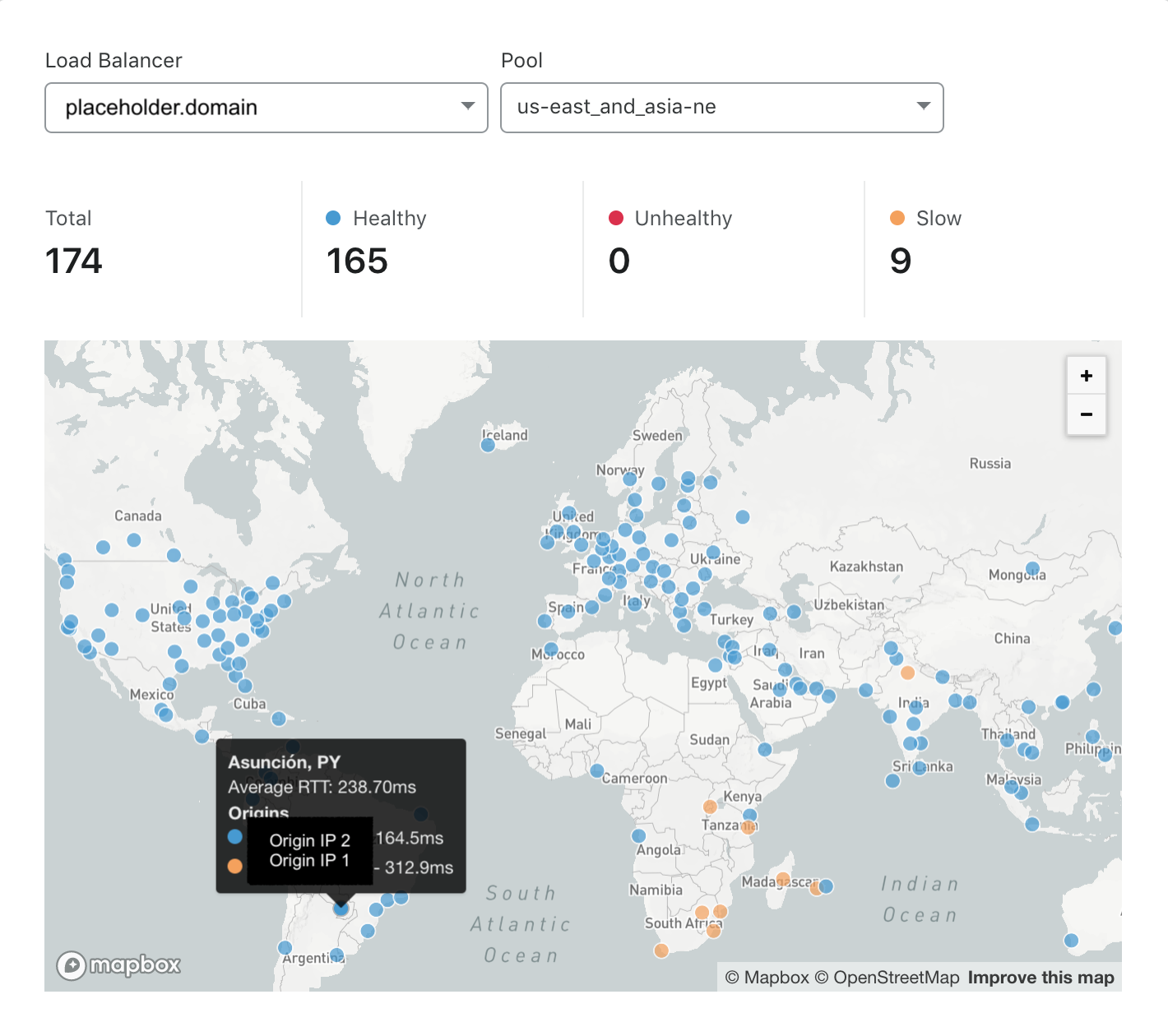
Abbildung 3
Wenn der Anwender die Latenzkarte mit den Kennzahlen für Traffic-Ströme verknüpft, gewinnt er wertvolle Erkenntnisse zur Optimierung seiner internen Systeme, zur Kostensenkung und zur Steigerung der Verfügbarkeit seiner Anwendungen.
GraphQL Analytics API
Load Balancing Analytics nutzt im Hintergrund die GraphQL Analytics API. Wie Sie in dieser Woche noch erfahren werden, bietet GraphQL uns bei Cloudflare viele Vorteile. Kunden müssen jetzt nur noch ein einziges API-Format erlernen, mit dem sie genau die Daten extrahieren können, die sie brauchen. Für die interne Entwicklung macht GraphQL spezifische Analytics-APIs für jeden Dienst überflüssig,. Außerdem reduziert es die Abfragekosten durch Erhöhung der Cache-Treffer und die Belastung für Entwickler durch die Verwendung einer einfachen Abfragesprache mit standardisierten Ein- und Ausgabeformaten. Schon bald erhalten alle Load-Balancing-Kunden mit kostenpflichtigen Tarifen die Möglichkeit, die GraphQL API für eigene Erkenntnisse zu nutzen. Schauen wir uns einige Beispiele dafür an, wie man Load-Balancing-Protokolle mit der GraphQL API auswerten kann.
Angenommen, Sie möchten die Anzahl der Anfragen ermitteln, die die Pools für einen Load Balancer von den verschiedenen Standorten im globalen Netzwerk von Cloudflare bekommen. Bei der Abfrage in Abbildung 4 wird im Laufe einer Woche alle 15 Minuten die Anzahl der eindeutigen Kombinationen (Standort, Pool-ID) gezählt.
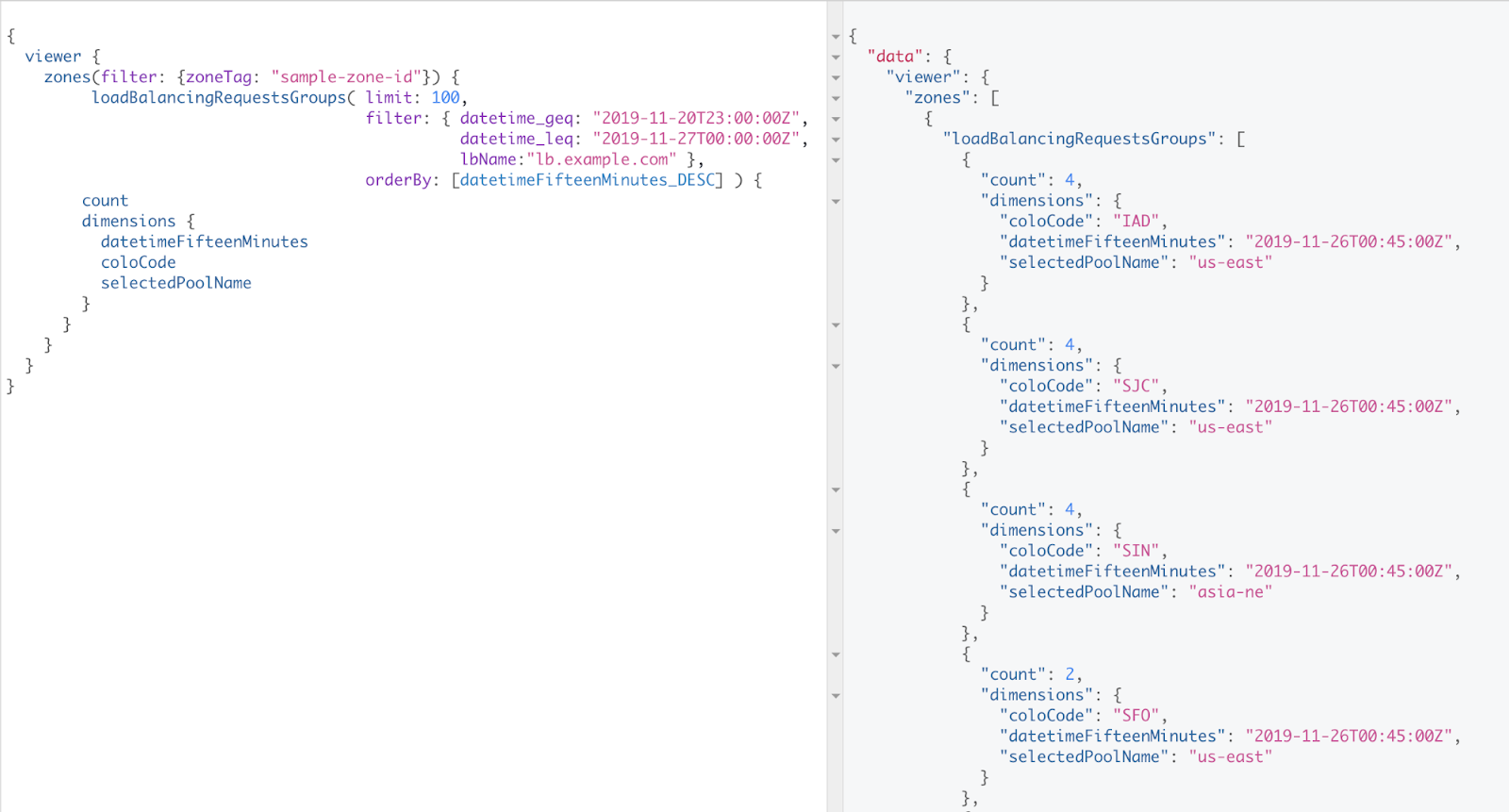
Abbildung 4
Unser Beispiel-Load-Balancer lb.example.com arbeitet mit dynamischer Lenkung. Bei dynamischer Lenkung werden Anfragen an den reaktionsschnellsten verfügbaren Ursprungsserver-Pool weitergeleitet. Das ist meist der am nächsten liegende Pool. Dies geschieht mit einer gewichteten Roundtrip-Zeitmessung. Lassen Sie uns versuchen zu verstehen, warum der gesamte Traffic von Singapur (SIN) zu unserem Pool in Nordostasien (asia-ne) gelenkt wird. Wir können die Abfrage in Abbildung 5 ausführen. Diese Abfrage zeigt uns, dass der Pool asia-ne einen avgRttMs-Wert von 67 ms aufweist, während die anderen beiden Pools avgRttMs-Werte über 150 ms haben. Der niedrigere avgRttMs-Wert ist die Erklärung dafür, dass der Traffic in Singapur an den Pool asia-ne geleitet wird.
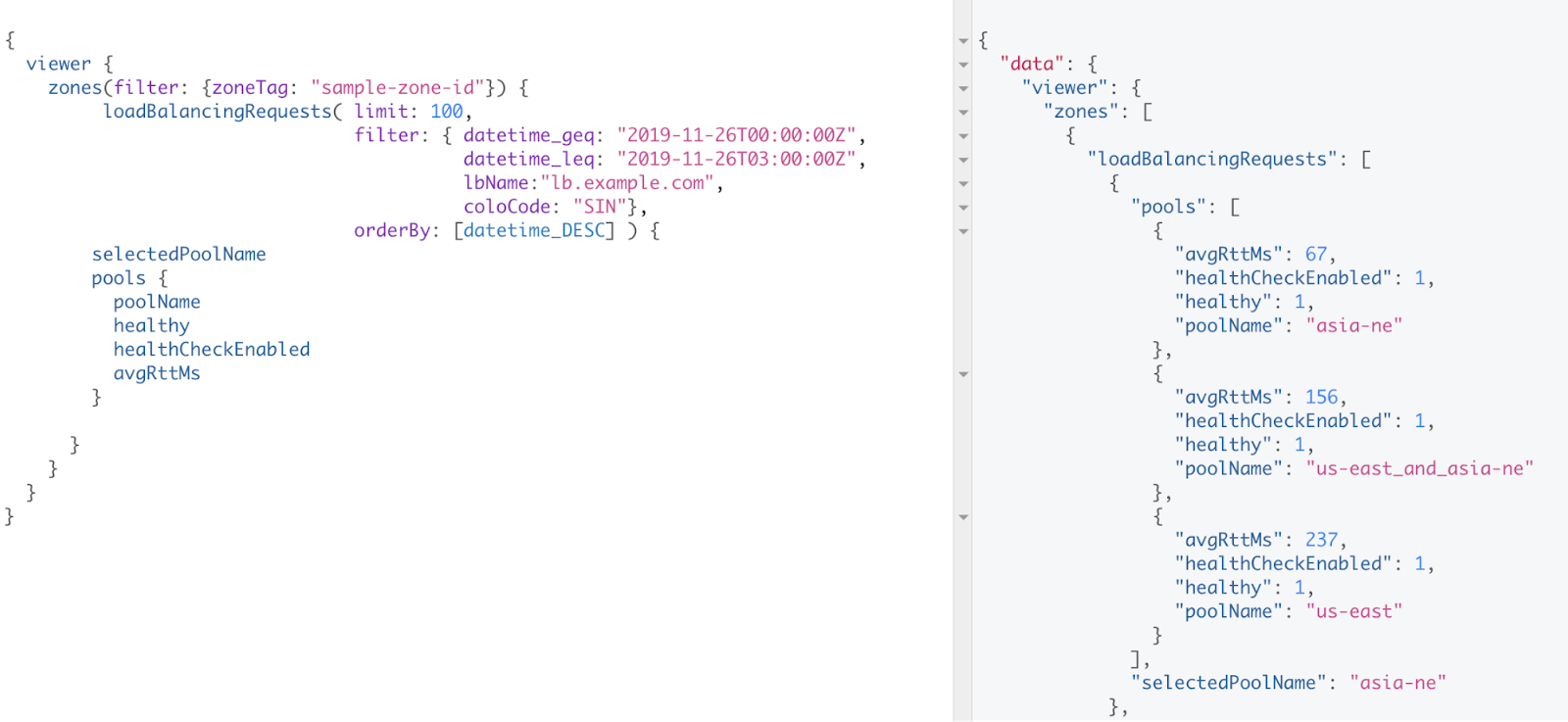
Abbildung 5
Wie Sie sehen, verwendet die Abfrage in Abbildung 4 das Schema loadBalancingRequestsGroups. Die Abfrage in Abbildung 5 verwendet das Schema loadBalancingRequests. Bei Abfragen mit dem Schema loadBalancingRequestsGroups werden Daten über das angeforderte Abfrageintervall aggregiert, bei loadBalancingRequests werden detaillierte Informationen zu einzelnen Anfragen geliefert. Für alle, die jetzt gleich loslegen möchten, hat Cloudflare einen hilfreichen Leitfaden geschrieben. Auch die GraphQL-Website ist eine großartige Ressource. Wir empfehlen Ihnen, für Ihre Abfragen eine IDE wie GraphiQL zu verwenden. GraphiQL bettet die Schemadokumentation in die IDE ein, vervollständigt Abfragen automatisch, speichert Ihre Abfragen und verwaltet Ihre benutzerdefinierten Header. All das macht dem Entwickler das Leben leichter.
Fazit
Load Balancing Analytics ist ab sofort einsatzbereit und steht allen Pro-, Business- und Enterprise-Kunden zur Verfügung. Wir sind gespannt, wann Sie anfangen! Wir haben eine Umfrage auf der Traffic-Übersichtsseite platziert und würden uns über Ihr Feedback freuen.