
Das @Cloudflare-Team hat gerade eine Änderung vorgenommen, die die Leistung unseres Netzwerks deutlich verbessert, insbesondere bei besonders langsamen Ausreißeranfragen. Wie viel schneller? Wir schätzen, dass wir dem Internet *pro Tag* ca. 54 Jahre an Zeit sparen, die wir sonst alle darauf warten müssten, dass Websites geladen werden.
- @eastdakota- 28. Juni 2018
10 Millionen Websites, Apps und APIs nutzen Cloudflare, um ihren Besuchern einen Geschwindigkeitsschub zu verpassen. Zu Spitzenzeiten bearbeiten wir in unseren 151 Rechenzentren mehr als 10 Millionen Anfragen pro Sekunde. Im Laufe der Jahre haben wir viele Änderungen an unserer Version von NGINX vorgenommen, um unserem Wachstum gerecht zu werden. In diesem Blogbeitrag geht es um eine davon.
So funktioniert NGINX
NGINX ist eines der Programme, das die Verwendung von Ereignisschleifen zur Lösung des C10K-Problems populär gemacht hat. Jedes Mal, wenn ein Netzwerkereignis eintritt (eine neue Verbindung, eine Anfrage oder eine Meldung, dass wir mehr Daten senden können usw.), wacht NGINX auf, verarbeitet das Ereignis und macht dann wieder das, was auch immer es tun muss (das kann das Verarbeiten von anderen Ereignissen sein). Wenn ein Ereignis eintrifft, stehen die mit dem Ereignis verbundenen Daten schon bereit, sodass NGINX viele Anfragen gleichzeitig effizient verarbeiten kann, ohne zu warten.
num_events = epoll_wait(epfd, /*returned=*/events, events_len, /*timeout=*/-1);
// events is list of active events
// handle event[0]: incoming request GET http://example.com/
// handle event[1]: send out response to GET http://cloudflare.com/
So könnte beispielsweise ein Codeabschnitt aussehen, mit dem Daten aus einem Datei-Deskriptor (fd) gelesen werden:
// we got a read event on fd
while (buf_len > 0) {
ssize_t n = read(fd, buf, buf_len);
if (n < 0) {
if (errno == EWOULDBLOCK || errno == EAGAIN) {
// try later when we get a read event again
}
if (errno == EINTR) {
continue;
}
return total;
}
buf_len -= n;
buf += n;
total += n;
}
Wenn fd ein Netzwerk-Socket ist, gibt dies die bereits angekommenen Bytes zurück. Der letzte Aufruf gibt EWOULDBLOCK zurück, was bedeutet, dass wir den lokalen Lesepuffer geleert haben, sodass wir nicht mehr aus dem Socket lesen sollten, bis mehr Daten verfügbar sind.
Festplatten-E/A ist nicht gleich Netzwerk-E/A
Wenn fd eine normale Datei in Linux ist, kommt es nie zu EWOULDBLOCK and EAGAIN und das Leseereignis wartet immer darauf, den gesamten Puffer zu lesen. Dies gilt auch dann, wenn die Datei mit O_NONBLOCK geöffnet wurde. Um open(2) zu zitieren:
Beachten Sie, dass dieses Flag keine Auswirkung auf reguläre Dateien und blockorientierte Geräte hat.
Mit anderen Worten, der obige Code reduziert sich im Wesentlichen auf:
if (read(fd, buf, buf_len) > 0) {
return buf_len;
}
Das bedeutet, dass ein Ereignishandler, der von der Festplatte lesen muss, die Ereignisschleife blockiert, bis das gesamte Leseereignis beendet ist, und die nachfolgenden Ereignishandler verzögert werden.
Dies ist für die meisten Arbeitslasten in Ordnung, da das Lesen von der Festplatte normalerweise schnell genug und viel vorhersehbarer ist als das Warten auf das Eintreffen eines Pakets aus dem Netzwerk. Dies gilt besonders jetzt, da jeder eine SSD hat und unsere Cache-Festplatten alle SSDs sind. Moderne SSDs haben eine sehr geringe Latenzzeit, normalerweise unter 100 µs. Darüber hinaus können wir NGINX mit multiplen Worker-Prozessen ausführen, sodass ein langsamer Ereignishandler Anfragen in anderen Prozessen nicht blockiert. Meistens können wir uns darauf verlassen, dass die Ereignisbehandlung von NGINX Anfragen schnell und effizient verarbeitet.
SSD-Performance: nicht immer das, was sie verspricht
Wie Sie vielleicht schon vermutet haben, sind diese rosigen Annahmen nicht immer wahr. Wenn jeder Lesevorgang immer 50 µs dauert, dann sollte es nur 2 ms dauern, um 0,19 MB in 4-KB-Blöcken zu lesen (und wir lesen in größeren Blöcken). Aber unsere eigenen Messungen haben gezeigt, dass unsere Zeit bis zum ersten Byte manchmal viel schlechter ist, besonders im 99. und 999. Perzentil. Mit anderen Worten, der langsamste Lesevorgang pro 100 (oder pro 1.000) Lesevorgänge dauert oft viel länger.
SSDs sind sehr schnell, aber sie sind bekanntermaßen auch kompliziert. In ihnen befinden sich Computer, die E/As aneinanderreihen und neu ordnen sowie verschiedene Hintergrundaufgaben wie Speicherbereinigung und Defragmentierung ausführen. Ab und zu wird eine Anfrage so verlangsamt, dass dies merkliche Auswirkungen hat. Mein Kollege Ivan Babrou hat einige E/A-Benchmark-Tests durchgeführt und erlebte Lesespitzen von bis zu 1 Sekunde. Darüber hinaus weisen einige unserer SSDs mehr Performance-Ausreißer auf als andere. In Zukunft werden wir Leistungskonstanz bei unseren SSD-Käufen berücksichtigen, aber bis dahin benötigen wir eine Lösung für unsere bestehende Hardware.
Gleichmäßige Lastverteilung mit SO_REUSEPORT
Eine einzelne langsame Antwort alle Jubeljahre einmal ist schwer zu vermeiden, aber was wir wirklich nicht wollen, ist eine E/A, die eine Sekunde dauert und dabei die 1.000 anderen Anfragen blockiert, die wir innerhalb derselben Sekunde erhalten. Konzeptionell kann NGINX viele Anfragen parallel verarbeiten, führt aber nur jeweils einen Ereignishandler aus. Deshalb habe ich eine Metrik hinzugefügt, die dies misst:
if (read(fd, buf, buf_len) > 0) {
return buf_len;
}
P99 von event_loop_blocked entpuppte sich als mehr als 50 % unserer TTFB. Das heißt, die Hälfte der Zeit, die für die Bearbeitung einer Anforderung benötigt wird, ist darauf zurückzuführen, dass die Ereignisschleife durch andere Anfragen blockiert wird. event_loop_blocked misst nur etwa die Hälfte der Blockierung (weil verzögerte Aufrufe von epoll_wait() nicht gemessen werden), sodass das tatsächliche Verhältnis der blockierten Zeit viel höher ist.
Auf jeder unserer Maschinen läuft NGINX mit 15 Worker-Prozessen, was bedeutet, dass eine langsame E/A nur bis zu 6 % der Anfragen blockieren sollte. Die Ereignisse sind jedoch nicht gleichmäßig verteilt, der Top-Worker bearbeitet 11 % der Anfragen (also doppelt so viele wie erwartet).
SO_REUSEPORT kann das Problem der ungleichen Verteilung lösen. Marek Majkowski hat bereits im Zusammenhang mit anderen NGINX-Instanzen über den Nachteil geschrieben, aber dieser Nachteil trifft in unserem Fall meist nicht zu, da Upstream-Verbindungen in unserem Cache-Prozess langlebig sind, sodass eine etwas höhere Latenz beim Öffnen der Verbindung vernachlässigbar ist. Diese Konfigurationsänderung allein, mit der SO_REUSEPORT aktiviert wird, verbesserte die Höchst-P99 um 33 %.
Verschieben von read() in den Thread-Pool: keine Wunderlösung
Eine Lösung dafür besteht darin, dafür zu sorgen, dass read() nicht blockiert. Tatsächlich ist diese Funktion im Upstream von NGINX implementiert! Wenn die folgende Konfiguration verwendet wird, werden read() und write() in einem Thread-Pool ausgeführt und blockieren die Ereignisschleife nicht:
aio threads;
aio_write on;
Als wir dies jedoch testeten, sahen wir anstelle einer 33-fachen Verbesserung der Antwortzeit tatsächlich einen leichten Anstieg von P99. Der Unterschied lag innerhalb der Fehlergrenze, aber wir waren durch das Ergebnis ziemlich entmutigt und haben diese Option für eine Weile nicht mehr verfolgt.
Es gibt mehrere Gründe dafür, dass wir nicht den Grad an Verbesserungen erhalten haben, den NGINX erlebt hat. Beim dortigen Test wurden 200 gleichzeitige Verbindungen genutzt, um Dateien mit einer Größe von 4 MB anzufordern, die sich auf rotierenden Festplatten befanden. Rotierende Festplatten erhöhen die E/A-Latenzzeit, deshalb ist es nachvollziehbar, dass eine Optimierung bei der Latenz dramatischere Auswirkungen haben würde.
Außerdem befassen wir uns vor allem mit der P99- (und P999-)Performance. Lösungen, die bei der Durchschnitts-Performance helfen, helfen nicht unbedingt bei Ausreißern.
Zu guter Letzt sind in unserer Umgebung die typischen Dateigrößen auch viel kleiner. 90 % unserer Cache-Treffer sind für Dateien, die kleiner als 60 KB sind. Kleinere Dateien bedeuten weniger Gelegenheiten für Blockierungen (wir lesen normalerweise die gesamte Datei in zwei Lesezugriffen).
Wenn wir uns die Festplatten-E/A ansehen, die bei einem Cache-Treffer ausgeführt werden muss:
// we got a request for https://example.com which has cache key 0xCAFEBEEF
fd = open("/cache/prefix/dir/EF/BE/CAFEBEEF", O_RDONLY);
// read up to 32KB for the metadata as well as the headers
// done in thread pool if "aio threads" is on
read(fd, buf, 32*1024);
32 KB ist keine statische Zahl. Wenn die Header klein sind, müssen wir nur 4 KB lesen (wir verwenden kein direktes E/A, sodass der Kernel auf 4 KB aufrunden wird). Das open() scheint harmlos zu sein, aber es hat tatsächlich seine Kosten. Als Minimum muss der Kernel prüfen, ob die Datei existiert und ob der aufrufende Prozess die Berechtigung hat, sie zu öffnen. Dazu müsste er den Inode von /cache/prefix/dir/EF/BE/CAFEBEEF finden, wozu er CAFEBEEF in /cache/prefix/dir/EF/BE/ nachschlagen müsste. Um es kurz zu fassen, im schlimmsten Fall muss der Kernel die folgenden Lookups durchführen:
/cache
/cache/prefix
/cache/prefix/dir
/cache/prefix/dir/EF
/cache/prefix/dir/EF/BE
/cache/prefix/dir/EF/BE/CAFEBEEF
Das sind sechs separate Lesevorgänge von open() im Vergleich zu nur einem Lesevorgang von read()! Glücklicherweise werden die meisten Lookups vom Verzeichniseintrag-Cache bedient und erfordern keine Ausflüge zu den SSDs. Aber dass read() im Thread-Pool ausgeführt wird, ist offensichtlich nur die halbe Miete.
Der Durchbruch: nicht blockierendes open() in Thread-Pools
Deshalb habe ich NGINX so modifiziert, dass es den größten Teil von open() ebenfalls innerhalb des Thread-Pools ausführt, damit es die Ereignisschleife nicht blockiert. Das Ergebnis (sowohl nicht blockierendes Öffnen als auch nicht blockierendes Lesen):
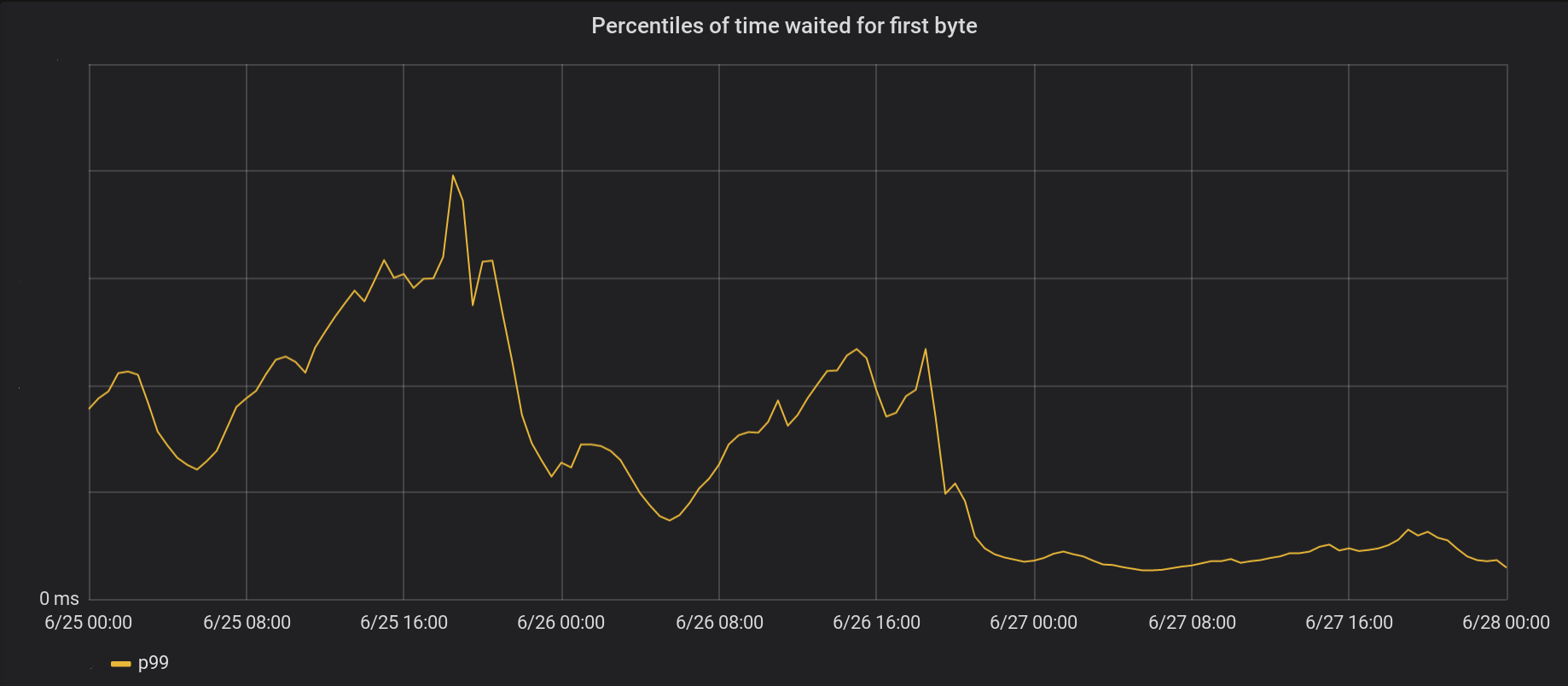
Am 26. Juni haben wir unsere Änderungen in fünf unserer verkehrsreichsten Rechenzentren eingeführt, gefolgt von einem weltweiten Roll-out am nächsten Tag. Insgesamt verbesserte sich die Höchst-P99-TTFB um den Faktor 6. Wenn wir sämtliche Verarbeitungszeiten von acht Millionen Anfragen pro Sekunde addieren, haben wir dem Internet tatsächlich jeden Tag 54 Jahre Wartezeit gespart.
Wir haben unsere Arbeit hier vorgelegt. Interessenten können sie nachverfolgen.
Unsere Ereignisschleifenbehandlung ist immer noch nicht vollständig blockierungsfrei. Insbesondere blockieren wir noch immer, wenn wir eine Datei zum ersten Mal zwischenspeichern (sowohl bei open(O_CREAT) als auch bei rename()) oder wenn wir Aktualisierungen zur Revalidierung durchführen. Das passiert im Vergleich zu Cache-Treffern jedoch eher selten. Für die Zukunft erwägen wir, dies aus der Ereignisschleife zu entfernen, um unsere P99-Latenzzeit weiter zu verbessern.
Fazit
NGINX ist eine leistungsstarke Plattform, aber die Skalierung extrem hoher E/A-Lasten auf Linux kann eine Herausforderung darstellen. Im Upstream kann NGINX Lesezugriffe in separaten Threads abladen, aber bei unserer Größenordnung müssen wir oft einen Schritt weiter gehen. Wenn die Arbeit an herausfordernden Performance-Problemen für Sie spannend klingt, bewerben Sie sich und kommen Sie in eins unserer Teams in San Francisco, London, Austin oder Champaign.