
Intern wird unser DDoS-Abwehrteam manchmal „the packet droppers“ („die Paketverwerfer“) genannt. Während andere Teams aufregende Produkte entwickeln, um intelligente Dinge mit dem Datenverkehr zu tun, der durch unser Netzwerk fließt, freuen wir uns, wenn wir neue Wege finden, ihn zu entsorgen.

Die Möglichkeit, Pakete schnell zu verwerfen, ist sehr wichtig, um DDoS-Angriffen standzuhalten.
Das Verwerfen von Paketen, die auf unsere Server gelangen, kann auf mehreren Ebenen durchgeführt werden. Jede Technik hat ihre Vor- und Nachteile. In diesem Blogbeitrag besprechen wir alle Techniken, die wir bisher ausprobiert haben.
Prüfstand
Um die relative Leistung der einzelnen Methoden zu veranschaulichen, werden wir einige Zahlen zeigen. Die Benchmarks sind künstlich und daher mit Vorsicht zu genießen. Wir verwenden einen unserer Intel-Server mit einer 10-Gbit/s-Netzwerkkarte. Die Hardwaredetails sind nicht allzu wichtig, da die Tests so ausgerichtet sind, dass sie Einschränkungen des Betriebssystems und nicht die der Hardware aufzeigen.
Unser Test-Setup sieht wie folgt aus:
- Wir übertragen eine große Anzahl winziger UDP-Pakete und erreichen 14 Mpps (Millionen Pakete pro Sekunde).
- Dieser Traffic wird auf eine einzelne CPU auf einem Zielserver geleitet.
- Wir messen die Anzahl der Pakete, die vom Kernel auf dieser einen CPU verarbeitet werden.
Wir versuchen nicht, die Anwendungsgeschwindigkeit des Userspace oder den Paketdurchsatz zu maximieren – stattdessen versuchen wir, gezielt Kernel-Engpässe aufzuzeigen.
Der künstliche Traffic ist darauf ausgerichtet, conntrack maximal zu belasten – er verwendet zufällige Quell-IP- und Port-Felder. Tcpdump zeigt das wie folgt an:
$ tcpdump -ni vlan100 -c 10 -t udp and dst port 1234
IP 198.18.40.55.32059 > 198.18.0.12.1234: UDP, length 16
IP 198.18.51.16.30852 > 198.18.0.12.1234: UDP, length 16
IP 198.18.35.51.61823 > 198.18.0.12.1234: UDP, length 16
IP 198.18.44.42.30344 > 198.18.0.12.1234: UDP, length 16
IP 198.18.106.227.38592 > 198.18.0.12.1234: UDP, length 16
IP 198.18.48.67.19533 > 198.18.0.12.1234: UDP, length 16
IP 198.18.49.38.40566 > 198.18.0.12.1234: UDP, length 16
IP 198.18.50.73.22989 > 198.18.0.12.1234: UDP, length 16
IP 198.18.43.204.37895 > 198.18.0.12.1234: UDP, length 16
IP 198.18.104.128.1543 > 198.18.0.12.1234: UDP, length 16Auf der Zielseite werden alle Pakete an genau eine RX-Warteschlange weitergeleitet, also an eine CPU. Wir tun dies mit der Hardware-Flusssteuerung:
ethtool -N ext0 flow-type udp4 dst-ip 198.18.0.12 dst-port 1234 action 2
Benchmarking ist immer schwer. Bei der Vorbereitung der Tests haben wir gelernt, dass aktive Raw Sockets die Leistung beeinträchtigen. Im Nachhinein ist das offensichtlich, aber es ist auch leicht zu übersehen. Bevor Sie Tests ausführen, vergewissern Sie sich, dass kein veralteter tcpdump-Prozess ausgeführt wird. So überprüfen Sie es und zeigen einen fehlerhaften Prozess an:
$ ss -A raw,packet_raw -l -p|cat
Netid State Recv-Q Send-Q Local Address:Port
p_raw UNCONN 525157 0 *:vlan100 users:(("tcpdump",pid=23683,fd=3))Schließlich deaktivieren wir die Intel-Turbo-Boost-Funktion auf dem Rechner:
echo 1 | sudo tee /sys/devices/system/cpu/intel_pstate/no_turbo
Obwohl Turbo Boost eine schöne Sache ist und den Durchsatz um mindestens 20 % erhöht, verschlechtert die Funktion aber auch die Standardabweichung in unseren Tests drastisch. Bei aktiviertem Turbo Boost hatten wir eine Abweichung von ±1,5 % in unseren Zahlen. Bei deaktiviertem Turbo Boost sinkt dieser Wert auf überschaubare 0,25 %.
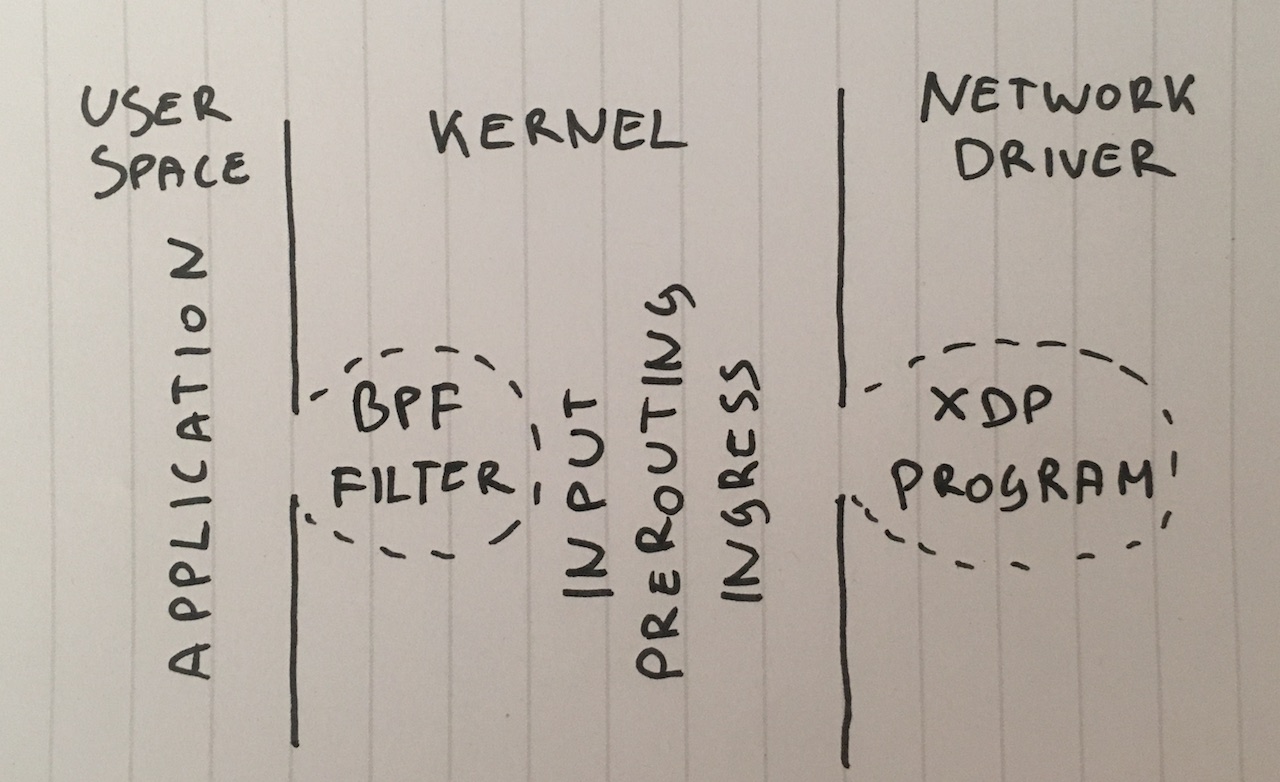
Schritt 1: Verwerfen von Paketen in der Anwendung
Beginnen wir mit der Idee, Pakete an eine Anwendung zu liefern und sie im Userspace-Code zu ignorieren. Für das Test-Setup stellen wir sicher, dass unsere iptables die Leistung nicht beeinträchtigen:
iptables -I PREROUTING -t mangle -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
iptables -I INPUT -t filter -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
Der Anwendungscode ist eine einfache Schleife, die Daten empfängt und sofort im Userspace verwirft:
s = socket.socket(AF_INET, SOCK_DGRAM)
s.bind(("0.0.0.0", 1234))
while True:
s.recvmmsg([...])Wir haben den Code vorbereitet, um ihn auszuführen:
$ ./dropping-packets/recvmmsg-loop
packets=171261 bytes=1940176Dieses Setup ermöglicht es dem Kernel, magere 175 kpps aus der Hardware-Empfangsqueue zu erhalten, gemessen mit ethtool und mit unserem einfachen mmwatch-Tool:
$ mmwatch 'ethtool -S ext0|grep rx_2'
rx2_packets: 174.0k/sDie Hardware erhält technisch gesehen 14 Mpps übertragen. Aber es ist unmöglich, das alles an eine einzige RX-Warteschlange zu übergeben, die von nur einem CPU-Kern verarbeitet wird, der Kernelarbeit leistet. mpstat bestätigt das:
$ watch 'mpstat -u -I SUM -P ALL 1 1|egrep -v Aver'
01:32:05 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
01:32:06 PM 0 0.00 0.00 0.00 2.94 0.00 3.92 0.00 0.00 0.00 93.14
01:32:06 PM 1 2.17 0.00 27.17 0.00 0.00 0.00 0.00 0.00 0.00 70.65
01:32:06 PM 2 0.00 0.00 0.00 0.00 0.00 100.00 0.00 0.00 0.00 0.00
01:32:06 PM 3 0.95 0.00 1.90 0.95 0.00 3.81 0.00 0.00 0.00 92.38
Wie Sie sehen können, ist der Anwendungscode kein Engpass. Er verwendet 27 % sys + 2 % Userspace auf CPU Nr. 1, während Netzwerk-SOFTIRQ auf CPU Nr. 2 100 % der Ressourcen verwendet.
Übrigens, die Verwendung von recvmmsg(2) ist wichtig. In diesen Tagen nach Spectre sind Syscalls teurer geworden und tatsächlich laufen bei uns Kernel 4.14 mit KPTI und Retpolines:
$ tail -n +1 /sys/devices/system/cpu/vulnerabilities/*
==> /sys/devices/system/cpu/vulnerabilities/meltdown <==
Mitigation: PTI
==> /sys/devices/system/cpu/vulnerabilities/spectre_v1 <==
Mitigation: __user pointer sanitization
==> /sys/devices/system/cpu/vulnerabilities/spectre_v2 <==
Mitigation: Full generic retpoline, IBPB, IBRS_FWSchritt 2: Niederringen von conntrack
Wir haben den Test durch die Wahl zufälliger Quell-IPs und Ports speziell so entwickelt,dass wir den conntrack-Layer belasten. Das kann anhand der Anzahl der conntrack-Einträge überprüft werden, die während des Tests das Maximum erreichen:
$ conntrack -C
2095202
$ sysctl net.netfilter.nf_conntrack_max
net.netfilter.nf_conntrack_max = 2097152Sie können den Aufschrei von conntrack in dmesg beobachten:
[4029612.456673] nf_conntrack: nf_conntrack: table full, dropping packet
[4029612.465787] nf_conntrack: nf_conntrack: table full, dropping packet
[4029617.175957] net_ratelimit: 5731 callbacks suppressed
Um unsere Tests zu beschleunigen, deaktivieren wir es:
iptables -t raw -I PREROUTING -d 198.18.0.12 -p udp -m udp --dport 1234 -j NOTRACK
Und führen die Tests erneut aus:
$ ./dropping-packets/recvmmsg-loop
packets=331008 bytes=5296128Dadurch wird die Empfangsleistung der Anwendung sofort auf 333 kpps erhöht. Hurra!
PS: Mit SO_BUSY_POLL können wir die Zahlen auf 470 kpps erhöhen, aber das ist ein Thema für ein anderes Mal.
Schritt 3: Verwerfen in BPF auf einem Socket
Warum überhaupt Pakete an die Userspace-Anwendung liefern? Obwohl diese Technik ungewöhnlich ist, können wir mit setsockopt( SO_ATTACH_FILTER ) einen klassischen BPF-Filter an einen SOCK_DGRAM-Socket anfügen und den Filter so programmieren, dass er Pakete im Kernelspace verwirft.
Hier ist der Code zum Auszuführen:
$ ./bpf-drop
packets=0 bytes=0Beim Verwerfen in BPF (sowohl das klassische BPF als auch das erweiterte eBPF haben eine ähnliche Leistung) verarbeiten wir rund 512 kpps. Sie werden alle im BPF-Filter verworfen, obwohl der noch im Software-Interrupt-Modus ist, was uns CPU einspart, die zum Aufwecken der Userspace-Anwendung benötigt würde.
Schritt 4: VERWERFEN in iptables nach dem Routen
Als nächsten Schritt können wir Pakete einfach in der iptables-Firewall-INPUT-Kette verwerfen, indem wir eine Regel wie diese hinzufügen:
iptables -I INPUT -d 198.18.0.12 -p udp --dport 1234 -j DROP
Denken Sie daran, dass wir conntrack bereits mit -j NOTRACK deaktiviert haben. Mit diesen beiden Regeln bekommen wir 608 kpps.
Die Zahlen in den Zählern von iptables:
$ mmwatch 'iptables -L -v -n -x | head'
Chain INPUT (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
605.9k/s 26.7m/s DROP udp -- * * 0.0.0.0/0 198.18.0.12 udp dpt:1234
600 kpps sind nicht schlecht, aber es geht noch besser!
Schritt 5: VERWEREN in iptables beim PREROUTING
Eine noch schnellere Technik besteht darin, Pakete zu verwerfen, bevor sie weitergeleitet werden. Diese Regel kann das:
iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j DROP
Das produziert satte 1,688 mpps.
Das ist ein ziemlich signifikanter Leistungssprung, den ich allerdings nicht ganz verstehe. Entweder ist unser Routing-Layer ungewöhnlich komplex oder es gibt einen Fehler in unserer Serverkonfiguration.
In jedem Fall ist die „rohe“ iptables-Tabelle definitiv viel schneller.
Schritt 6: VERWERFEN in nftables vor CONNTRACK
Iptables gilt heutzutage als passé. Der neue Stern am Himmel ist nftables. In diesem Video erhalten Sie eine technische Erklärung, warum nftables überlegen ist. Nftables verspricht aus vielen Gründen, schneller zu sein als ergraute iptables. Es hält sich das Gerücht, dass Retpolines (aka: keine Spekulation auf indirekte Sprünge) iptables ziemlich zugesetzt haben.
Da es in diesem Artikel nicht darum geht, die Geschwindigkeit von nftables und iptables zu vergleichen, versuchen wir nur das schnellste Verwerfen, auf das ich gekommen bin:
nft add table netdev filter
nft -- add chain netdev filter input { type filter hook ingress device vlan100 priority -500 \; policy accept \; }
nft add rule netdev filter input ip daddr 198.18.0.0/24 udp dport 1234 counter drop
nft add rule netdev filter input ip6 daddr fd00::/64 udp dport 1234 counter drop
Die Zähler können mit diesem Befehl angesehen werden:
$ mmwatch 'nft --handle list chain netdev filter input'
table netdev filter {
chain input {
type filter hook ingress device vlan100 priority -500; policy accept;
ip daddr 198.18.0.0/24 udp dport 1234 counter packets 1.6m/s bytes 69.6m/s drop # handle 2
ip6 daddr fd00::/64 udp dport 1234 counter packets 0 bytes 0 drop # handle 3
}
}Der „ingress“-Hook von nftables liefert etwa 1,53 mpps. Das ist etwas langsamer als iptables im PREROUTING-Layer. Das ist rätselhaft – theoretisch erfolgt „ingress“ vor dem PREROUTING, es sollte also schneller sein.
In unserem Test war nftables etwas langsamer als iptables, aber nicht viel. Nftables ist trotzdem besser :P
Schritt 7: VERWERFEN mit tc Ingress-Handler
Eine etwas überraschende Tatsache ist, dass ein tc (Traffic Control) Ingress-Hook noch vor dem PREROUTING passiert. tc ermöglicht es, Pakete nach grundlegenden Kriterien auszuwählen und in der Tat mit „action drop“ zu verwerfen. Die Syntax ist eher unelegant, daher wird empfohlen, zum Einrichten dieses Skript zu verwenden. Wir brauchen einen etwas komplexeren tc-Match, hier ist die Befehlszeile:
tc qdisc add dev vlan100 ingress
tc filter add dev vlan100 parent ffff: prio 4 protocol ip u32 match ip protocol 17 0xff match ip dport 1234 0xffff match ip dst 198.18.0.0/24 flowid 1:1 action drop
tc filter add dev vlan100 parent ffff: protocol ipv6 u32 match ip6 dport 1234 0xffff match ip6 dst fd00::/64 flowid 1:1 action drop
Wir können es überprüfen:
$ mmwatch 'tc -s filter show dev vlan100 ingress'
filter parent ffff: protocol ip pref 4 u32
filter parent ffff: protocol ip pref 4 u32 fh 800: ht divisor 1
filter parent ffff: protocol ip pref 4 u32 fh 800::800 order 2048 key ht 800 bkt 0 flowid 1:1 (rule hit 1.8m/s success 1.8m/s)
match 00110000/00ff0000 at 8 (success 1.8m/s )
match 000004d2/0000ffff at 20 (success 1.8m/s )
match c612000c/ffffffff at 16 (success 1.8m/s )
action order 1: gact action drop
random type none pass val 0
index 1 ref 1 bind 1 installed 1.0/s sec
Action statistics:
Sent 79.7m/s bytes 1.8m/s pkt (dropped 1.8m/s, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
Ein tc-Ingress-Hook mit u32-Match ermöglicht es uns, 1,8 mpps auf einer einzelnen CPU zu verwerfen. Das ist genial!
Aber wir können noch schneller werden ...
Schritt 8: XDP_DROP
Zu guter Letzt die ultimative Waffe: XDP – der eXpress Data Path. Mit XDP können wir eBPF-Code im Kontext eines Netzwerktreibers ausführen. Am wichtigsten ist, dass dies vor der skbuff-Speicherzuweisung erfolgt, was hohe Geschwindigkeiten ermöglicht.
In der Regel bestehen XDP-Projekte aus zwei Teilen:
- dem eBPF-Code, der in den Kernelkontext geladen wurde,
- dem Userspace-Loader, der den Code auf die richtige Netzwerkkarte lädt und verwaltet.
Das Schreiben des Laders ist ziemlich schwierig, sodass wir stattdessen die neue iproute2-Funktion verwenden und den Code mit diesem trivialen Befehl laden können:
ip link set dev ext0 xdp obj xdp-drop-ebpf.o
Bitte sehr!
Den Quellcode fürdas geladene eBPF XDP-Programm finden Sie hier. Das Programm analysiert IP-Pakete und sucht nach den gewünschten Eigenschaften: IP-Transport, UDP-Protokoll, gewünschtes Zielsubnetz und Zielport:
if (h_proto == htons(ETH_P_IP)) {
if (iph->protocol == IPPROTO_UDP
&& (htonl(iph->daddr) & 0xFFFFFF00) == 0xC6120000 // 198.18.0.0/24
&& udph->dest == htons(1234)) {
return XDP_DROP;
}
}Das XDP-Programm muss mit einem modernen Clang kompiliert werden, der BPF-Bytecode ausgeben kann. Danach können wir das ausgeführte XDP-Programm laden und überprüfen:
$ ip link show dev ext0
4: ext0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 xdp qdisc fq state UP mode DEFAULT group default qlen 1000
link/ether 24:8a:07:8a:59:8e brd ff:ff:ff:ff:ff:ff
prog/xdp id 5 tag aedc195cc0471f51 jited
Und wir sehen die Zahlen in der ethtool -S -Netzwerkkartenstatistik:
$ mmwatch 'ethtool -S ext0|egrep "rx"|egrep -v ": 0"|egrep -v "cache|csum"'
rx_out_of_buffer: 4.4m/s
rx_xdp_drop: 10.1m/s
rx2_xdp_drop: 10.1m/s
Wow! Mit XDP können wir 10 Millionen Pakete pro Sekunde auf einer einzelnen CPU verwerfen.

Zusammenfassung
Wir haben das für IPv4 und IPv6 wiederholt und dieses Diagramm erstellt:
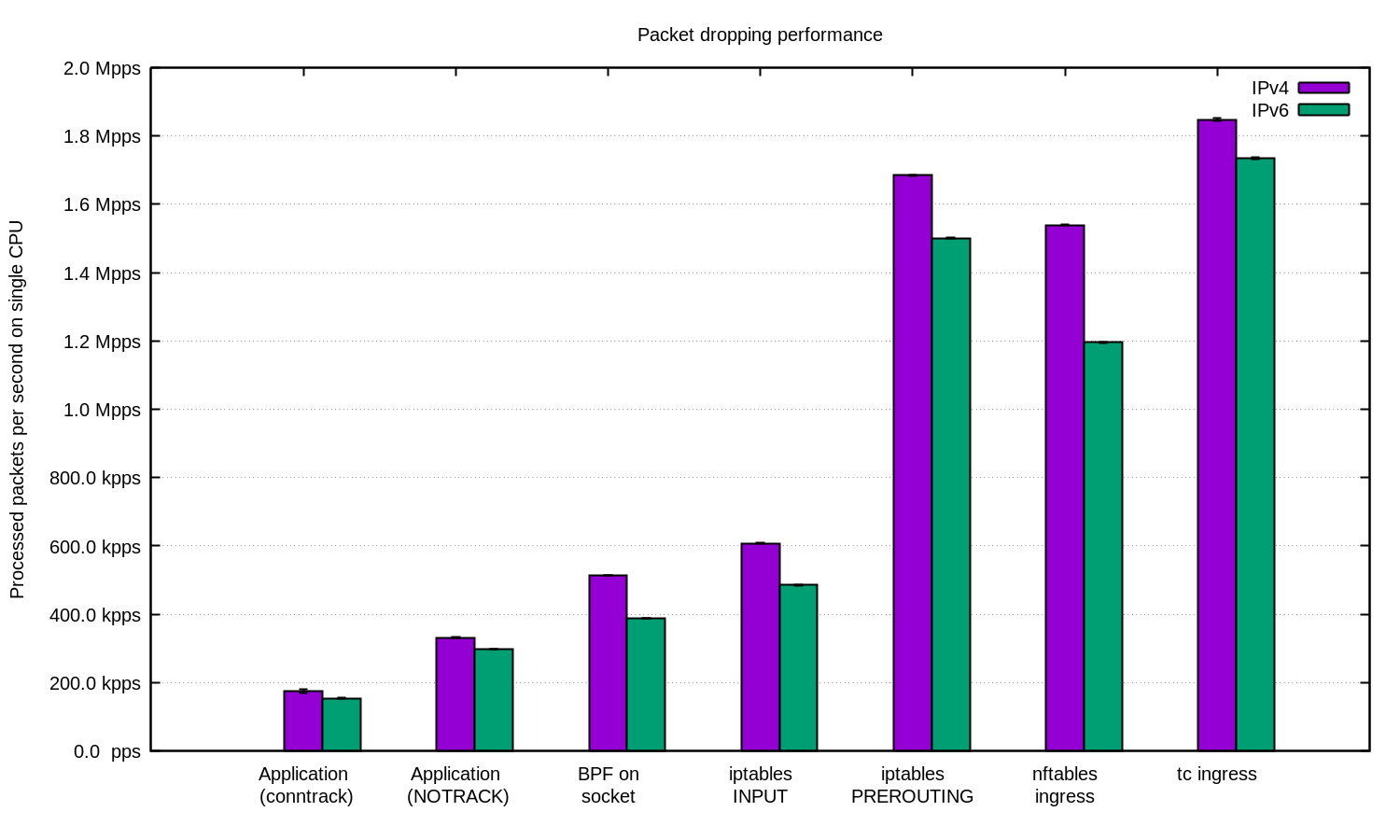
Im Allgemeinen hatte IPv6 in unserem Setup eine etwas geringere Leistung. Sie sollten aber daran denken, dass IPv6-Pakete etwas größer sind, sodass ein gewisser Leistungsunterschied unvermeidbar ist.
Linux verfügt über zahlreiche Hooks, mit denen Pakete gefiltert werden können und die jeweils unterschiedliche Eigenschaften hinsichtlich Leistung und Benutzerfreundlichkeit aufweisen.
Für DDoS-Zwecke kann es durchaus sinnvoll sein, die Pakete einfach in der Anwendung zu empfangen und im Userspace zu verarbeiten. Richtig abgestimmte Anwendungen können ziemlich gute Zahlen erreichen.
Bei DDoS-Angriffen mit zufälligen/gefälschten Quell-IPs kann es sich lohnen, conntrack zu deaktivieren, um mehr Geschwindigkeit zu erzielen. Seien Sie jedoch vorsichtig – es gibt Angriffe, bei denen conntrack sehr hilfreich ist.
Unter anderen Umständen kann es sinnvoll sein, die Linux-Firewall in die DDoS-Abwehrpipeline zu integrieren. Denken Sie in solchen Fällen daran, die Abwehr in einen „-t raw PREROUTING“-Layer zu legen, weil der deutlich schneller ist als die „filter“-Tabelle.
Für noch anspruchsvollere Workloads haben wir immer XDP. Und Junge, ist der stark. Hier ist das gleiche Diagramm wie oben, aber mit XDP:
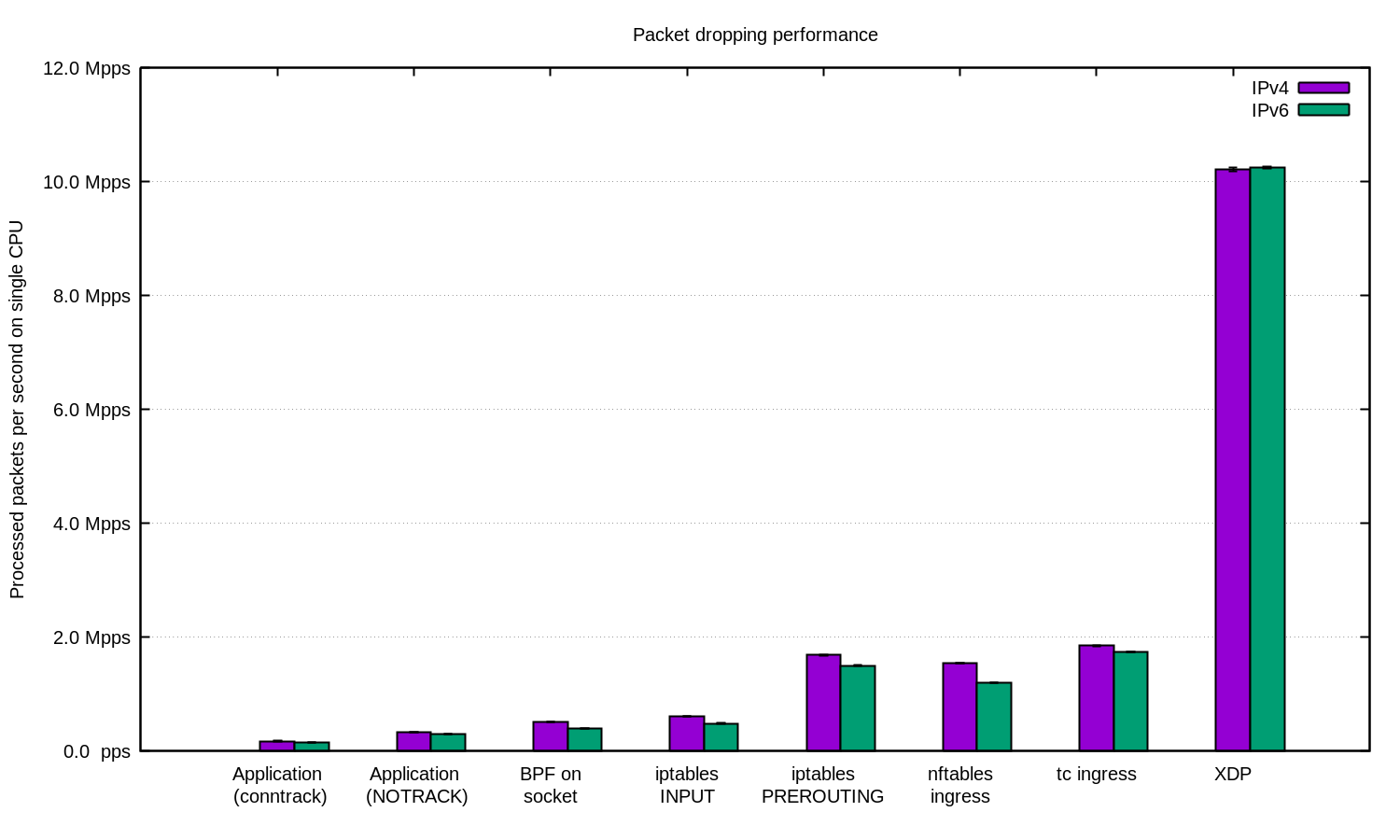
Wenn Sie diese Zahlen reproduzieren möchten, lesen Sie die README-Datei, in der wir alles dokumentiert haben.
Hier bei Cloudflare verwenden wir ... fast alle diese Techniken. Einige der Userspace-Tricks sind in unsere Anwendungen integriert. Der iptables-Layer wird von unserer Gatebot DDoS-Pipeline verwaltet. Außerdem arbeiten wir daran, unsere proprietäre Kernel-Offload-Lösung durch XDP zu ersetzen.
Möchten Sie uns helfen, noch mehr Pakete zu verwerfen? Wir stellen für viele Aufgaben ein, darunter Paketverwerfer, Systemingenieure und mehr!
Ein besonderer Dank für die Unterstützung bei dieser Arbeit geht anJesper Dangaard Brouer.