


Wie die Zeit vergeht. Die Heartbleed-Sicherheitslücke wurde vor etwas mehr als fünfeinhalb Jahren entdeckt. Heartbleed wurde nicht nur deshalb zum Begriff, weil es sich um einen der ersten Bugs mit einer eigenen Webseite und eigenem Logo handelte, sondern auch, weil er verdeutlichte, wie anfällig das Internet insgesamt ist. Mit Heartbleed wurden die persönlichen Daten der Nutzer fast jeder Online-Website durch einen winzigen Bug in einer Kryptografie-Bibliothek offengelegt.
{kind=link}
Heartbleed ist ein Beispiel für eine unterschätzte Klasse von Bugs: Remote-Sicherheitslücken, die die Offenlegung von Speicherinhalten bewirken können. Zu anderen bekannten Beispielen neben Heartbleed gehören Cloudbleed und als neuester Zugang NetSpectre. Diese Sicherheitslücken ermöglichen es Angreifern, Geheimnisse aus Servern zu extrahieren, indem sie ihnen einfach speziell gestaltete Pakete senden. Cloudflare hat vor kurzem ein mehrjähriges Projekt abgeschlossen, um unsere Plattform widerstandsfähiger gegen diese Kategorie von Bugs zu machen.
Seit fünf Jahren beschäftigt sich die Branche mit den Folgen des Designs, das für die Auswirkungen von Heartbleed verantwortlich ist. In diesem Blogbeitrag untersuchen wir die Speichersicherheit und sprechen darüber, wie wir das Hauptprodukt von Cloudflare neu gestaltet haben, um private Schlüssel vor dem nächsten Heartbleed zu schützen.
Offenlegung von Speicherinhalten
Perfekte Sicherheit ist für Unternehmen mit einer Online-Komponente nicht möglich. Die jüngere Vergangenheit hat gezeigt, dass ein Unternehmen durch einen unerwarteten Exploit gefährdet werden kann – egal wie robust sein Sicherheitsprogramm ist. Einer der bekannteren neueren Vorfälle dieser Art ist Heartbleed, eine Sicherheitslücke in einer häufig verwendeten Kryptografie-Bibliothek namens OpenSSL, die die inneren Details von Millionen von Webservern für jeden zugänglich machte, der eine Verbindung zum Internet hat. Heartbleed machte internationale Schlagzeilen, verursachte Schäden in Millionenhöhe und wurde immer noch nicht vollständig behoben.
Typische Webdienste geben Daten nur über klar definierte öffentlich zugängliche Schnittstellen zurück, die als APIs bezeichnet werden. Kunden können in der Regel nicht sehen, was unter der Haube innerhalb des Servers vor sich geht, denn das wäre ein großes Datenschutz- und Sicherheitsrisiko. Heartbleed brach dieses Paradigma: Es ermöglichte jedem Internet-Teilnehmer Zugang, um einen Blick auf den von Webservern verwendeten Betriebsspeicher zu werfen und privilegierte Daten zu sehen, die normalerweise nicht über die API verfügbar gemacht werden. Heartbleed konnte eingesetzt werden, um das Ergebnis früherer, an den Server gesendeter Daten zu extrahieren – einschließlich Passwörtern und Kreditkarteninformationen. Er konnte auch die innere Funktionsweise und kryptografische Geheimnisse innerhalb des Servers offenlegen, einschließlich privater Schlüssel für TLS-Zertifikate.
Heartbleed ließ Angreifer hinter den Vorhang schauen, aber nicht zu weit. Sensible Daten konnten extrahiert werden, aber nicht alles auf dem Server war gefährdet. Heartbleed ermöglichte es Angreifern beispielsweise nicht, den Inhalt von Datenbanken auf dem Server zu stehlen. Sie fragen sich vielleicht: Warum waren einige Daten gefährdet, andere nicht? Der Grund dafür liegt im Aufbau moderner Betriebssysteme.
Eine vereinfachte Darstellung der Prozessisolation
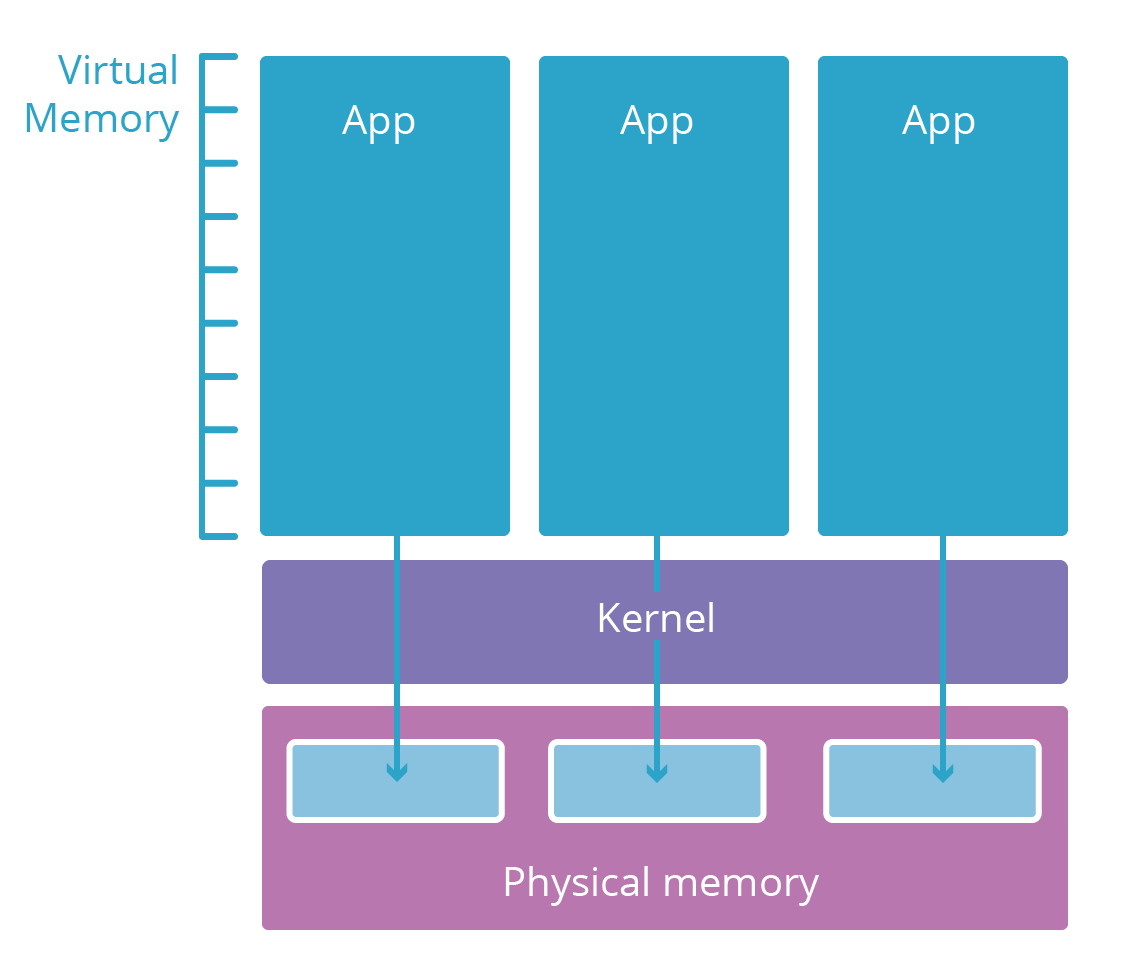
Die meisten modernen Betriebssysteme sind in mehrere Schichten unterteilt. Diese Schichten entsprechen Sicherheitsfreigabestufen. Sogenannte Benutzerbereichsanwendungen (wie Ihr Browser) befinden sich in der Regel in einer Schicht mit niedriger Sicherheitsstufe, die als Benutzerbereich bezeichnet wird. Sie haben nur dann Zugriff auf Computing-Ressourcen (Speicher, CPU, Netzwerk), wenn die niedrigeren Schichten mit ihren strengen Anmeldeinformationen es zulassen.
Benutzerbereichsanwendungen benötigen Ressourcen, um zu funktionieren. Sie benötigen z. B. Speicher für ihren Code und Arbeitsspeicher für ihre Berechnungen. Es wäre jedoch riskant, einer Anwendung direkten Zugriff auf das physische RAM des Computers zu gewähren, auf dem sie läuft. Stattdessen sind die rohen Computing-Elemente auf eine niedrigere Schicht, den Betriebssystemkernel, beschränkt. Der Kernel führt nur speziell entwickelte Anwendungen aus, die diese Ressourcen sicher verwalten und den Zugriff auf diese Ressourcen für Benutzerbereichsanwendungen vermitteln.
Wenn ein neuer Benutzerbereichsanwendungsprozess gestartet wird, weist ihm der Kernel einen virtuellen Speicherbereich zu. Dieser virtuelle Speicherbereich wirkt wie ein echter Speicher für die Anwendung, ist aber eigentlich eine sicher bewachte Übersetzungsschicht, die der Kernel einsetzt, um den realen Speicher zu schützen. Der virtuelle Speicherbereich jeder Anwendung ist wie ein Paralleluniversum, das speziell dieser Anwendung gewidmet ist. Dies macht es für einen Prozess unmöglich, den Bereich eines anderen Prozesses einzusehen oder zu ändern – die anderen Anwendungen sind einfach nicht adressierbar.
Heartbleed, Cloudbleed und die Prozessgrenze
Heartbleed war eine Sicherheitslücke in der OpenSSL-Bibliothek, die Teil vieler Webserver-Anwendungen war. Diese Webserver laufen wie alle gängigen Anwendungen im Benutzerbereich. Diese Sicherheitslücke führte dazu, dass der Webserver als Reaktion auf eine speziell gestaltete eingehende Anforderung bis zu 2 Kilobyte seines Speichers zurückgab.
Cloudbleed war ebenfalls ein Bug zur Offenlegung von Speicherinhalten – wenn auch speziell für Cloudflare –, der seinen Namen erhielt, weil er Heartbleed so ähnlich war. Bei Cloudbleed lag die Sicherheitslücke nicht bei OpenSSL, sondern bei einer sekundären Webserveranwendung, die für HTML-Parsen verwendet wird. Wenn dieser Code eine bestimmte Sequenz von HTML parste, fügte er einen Prozessspeicher in die bereitgestellte Webseite ein.
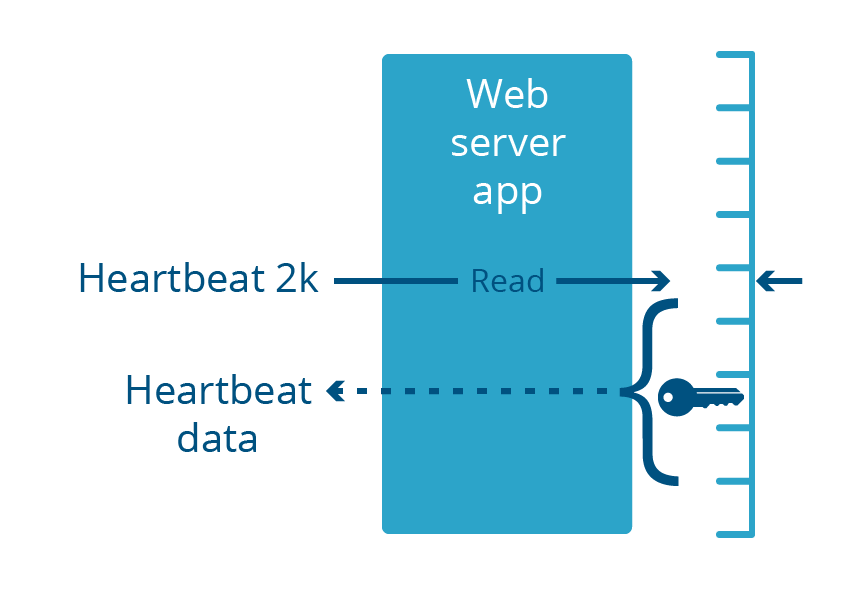
Es ist wichtig zu beachten, dass beide Bugs bei Anwendungen aufgetreten sind, die im Benutzerbereich und nicht im Kernelspace ausgeführt wurden. Das bedeutet, dass der durch den Bug offengelegte Speicher notwendigerweise Teil des virtuellen Speichers der Anwendung war. Selbst wenn der Fehler mehrere Megabyte an Daten offenlegen würde, würde es sich dabei nur um Daten handeln, die für diese Anwendung spezifisch sind, nicht für andere Anwendungen im System.
Damit ein Webserver Datenverkehr über das verschlüsselte HTTPS-Protokoll bereitstellen kann, benötigt er Zugriff auf den privaten Schlüssel des Zertifikats, der in der Regel im Speicher der Anwendung aufbewahrt wird. Diese Schlüssel wurden durch Heartbleed im Internet offengelegt. Die Cloudbleed-Sicherheitslücke betraf einen anderen Prozess – den HTML-Parser, der kein HTTPS ausführt und daher den privaten Schlüssel nicht im Speicher aufbewahrt. Das bedeutete, dass HTTPS-Schlüssel sicher waren, auch wenn andere Daten im Speicherbereich des HTML-Parsers es nicht waren.
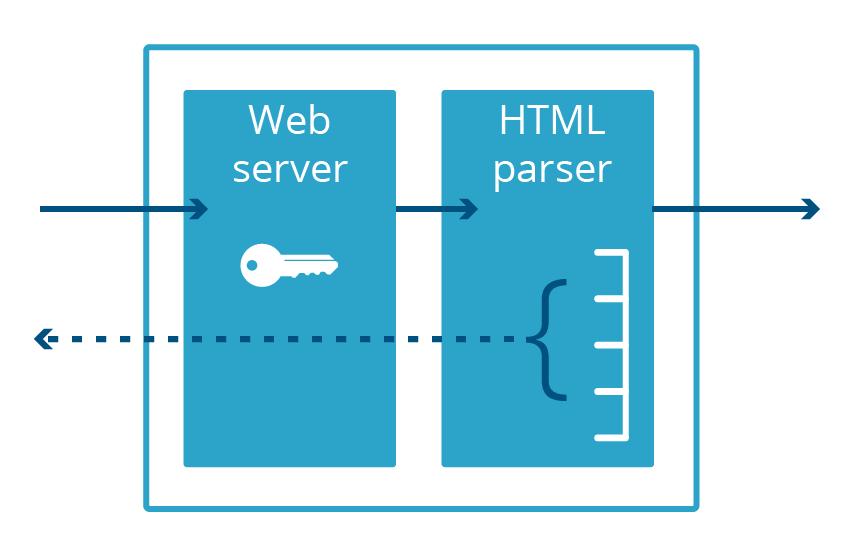
Die Tatsache, dass der HTML-Parser und der Webserver unterschiedliche Anwendungen waren, hat uns davor bewahrt, die TLS-Zertifikate unserer Kunden widerrufen und neu ausstellen zu müssen. Wenn jedoch eine weitere Sicherheitslücke im Webserver entdeckt wird, die die Offenlegung von Speicherinhalten bewirken kann, sind diese Schlüssel erneut gefährdet.
Verschieben von Schlüsseln aus Prozessen mit Internetzugriff
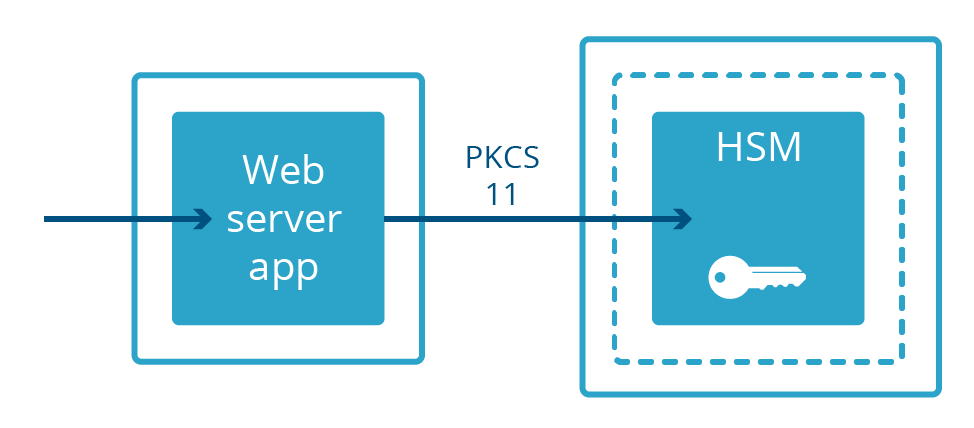
Nicht alle Webserver behalten private Schlüssel im Speicher. Bei einigen Bereitstellungen werden private Schlüssel auf einer separaten Maschine namens Hardwaresicherheitsmodul (HSM) aufbewahrt. HSMs haben die Aufgabe, physischen Angriffen und Manipulationen standzuhalten, und sind häufig so konzipiert, dass sie strengen Compliance-Anforderungen entsprechen. Sie können oft groß und teuer sein. Webserver, die die Vorteile von Schlüsseln in HSMs nutzen sollen, werden über ein physisches Kabel mit ihnen verbunden und kommunizieren über ein spezielles Protokoll namens PKCS-11. Dadurch kann der Webserver verschlüsselte Inhalte bereitstellen, während er physisch vom privaten Schlüssel getrennt ist.
Bei Cloudflare haben wir unsere eigene Methode entwickelt, einen Webserver von einem privaten Schlüssel getrennt zu halten: Keyless SSL. Anstatt die Schlüssel in einer separaten physischen Maschine aufzubewahren, die über ein Kabel mit dem Server verbunden ist, werden die Schlüssel in einem Schlüsselserver aufbewahrt, der vom Kunden in seiner eigenen Infrastruktur betrieben wird (dies kann auch durch ein HSM gesichert werden).
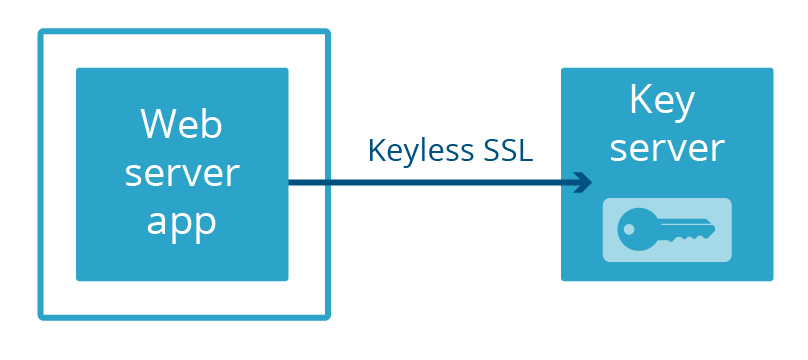
Vor Kurzem haben wir Geo Key Manager gestartet, einen Dienst, mit dem Benutzer private Schlüssel an ausgewählten Cloudflare-Standorten speichern können. Verbindungen zu Standorten, die keinen Zugriff auf den privaten Schlüssel haben, verwenden Keyless SSL mit einem Schlüsselserver, der in einem Rechenzentrum gehostet wird, das Zugriff auf den Schlüssel hat.
Sowohl bei Keyless SSL als auch bei Geo Key Manager sind private Schlüssel nicht nur kein Teil des Speicherbereichs des Webservers, sie befinden sich oft nicht einmal im selben Land! Dieser extreme Grad an Trennung ist nicht notwendig, um vor dem nächsten Heartbleed zu schützen. Es genügt, dass der Webserver und der Schlüsselserver nicht Teil derselben Anwendung sind. Und genau das haben wir erreicht. Wir nennen es „Keyless Everywhere“.
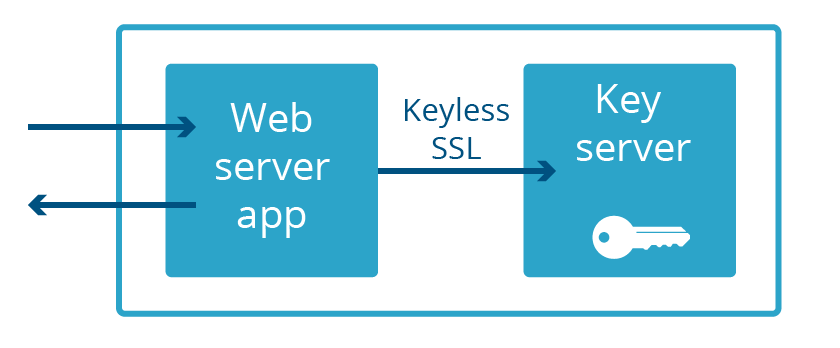
Keyless SSL kommt aus dem Inneren des Hauses
Es war leicht, sich die Umrüstung von Keyless SSL für private, von Cloudflare gehaltene Schlüssel vorzustellen, aber der Weg von der Idee zu ihrer Realisierung war weniger einfach. Die Kernfunktionalität von Keyless SSL stammt von der Open-Source-Software Gokeyless, die Kunden auf ihrer Infrastruktur ausführen, aber intern setzen wir sie als Bibliothek ein und haben das Hauptpaket durch eine Implementierung ersetzt, die unseren Anforderungen entspricht (wir nennen es kreativ „Gokeyless-intern“).
Wie bei allen größeren Architekturänderungen ist es ratsam, das Modell zuerst mit etwas Neuem mit geringem Risiko zu testen. In unserem Fall war der Prüfstand unsere experimentelle TLS-1.3-Implementierung. Um Entwurfsversionen der TLS-Spezifikation schnell iterieren und einsetzen zu können, ohne die Mehrheit der Cloudflare-Kunden zu beeinträchtigen, haben wir unseren benutzerdefinierten Nginx-Webserver in Go neu geschrieben und parallel zu unserer bestehenden Infrastruktur bereitgestellt. Dieser Server wurde von Anfang an so entwickelt, dass er niemals private Schlüssel aufbewahren und nur Gokeyless-intern einsetzen wird. Zu dieser Zeit gab es nur wenig TLS-1.3-Datenverkehr, der ausschließlich von den Beta-Versionen von Browsern kam. Dadurch waren wir in der Lage, die anfänglichen Macken von Gokeyless-intern zu beseitigen, ohne die Mehrheit der Besucher Sicherheitsrisiken oder Ausfällen aufgrund von Gokeyless-intern auszusetzen.
Der erste Schritt, um TLS 1.3 vollständig „schlüssellos“ zu machen, war die Identifizierung und Implementierung der neuen Funktionalität, die zu Gokeyless-intern hinzugefügt werden musste. Keyless SSL wurde entwickelt, um auf Kundeninfrastrukturen zu laufen – mit der Erwartung, nur eine Handvoll privater Schlüssel zu unterstützen. Da unsere Edge aber gleichzeitig Millionen von privaten Schlüsseln unterstützen muss, haben wir die gleiche Lazy Loading-Logik implementiert, die wir in unserem Webserver Nginx verwenden. Darüber hinaus stehen bei eine typischer Kundenbereitstellung Schlüsselserver hinter einem Netzwerk-Load-Balancer, sodass sie für Upgrades oder andere Wartungsarbeiten außer Betrieb genommen werden können. Vergleichen Sie das mit unserer Edge, wo es wichtig ist, das wir unsere Ressourcen maximieren, indem wir Datenverkehr während Software-Upgrades bereitstellen. Dieses Problem wird durch das ausgezeichnete Tableflip-Paket gelöst, das wir anderswo bei Cloudflare verwenden.
Das nächste Projekt, bei dem Keyless eingesetzt werden konnte, war Spectrum, das mit Standardunterstützung für Gokeyless-intern gestartet wurde. Nach diesen anfänglichen Erfolgen hatten wir das nötige Vertrauen, um die große Herausforderung anzugehen: unsere bestehende Nginx-Infrastruktur auf ein Modell komplett ohne Schlüssel zu übertragen. Nachdem wir die neue Funktionalität implementiert hatten und mit unseren Integrationstests zufrieden waren, mussten wir sie nur noch für den Einsatz freigeben, und damit hätte es sich, oder? Jeder, der Erfahrung mit großen verteilten Systemen hat, weiß, wie weit die Entwicklungsphase vom fertigen Produkt entfernt ist, und hier sieht es nicht anders aus. Glücklicherweise haben wir Probleme vorhergesehen und einen Fallback in Nginx eingebaut, damit der Handshake selbst vervollständigt wird, falls irgendwelche Probleme mit dem Pfad von Gokeyless-intern auftreten sollten. So konnten wir Gokeyless-intern Produktions-Datenverkehr aussetzen, ohne Ausfallzeiten zu riskieren, falls unsere erneute Implementierung der Nginx-Logik nicht 100 % fehlerfrei war.
Wenn durch Zurücksetzen des Codes das Problem nicht verschwindet
Unser Bereitstellungsplan bestand darin, Keyless Everywhere zu aktivieren, die häufigsten Ursachen für Fallbacks zu finden und diese dann zu beheben. Wir würden diesen Vorgang dann wiederholen, bis alle Quellen von Fallbacks eliminiert worden waren. Danach würden wir den Zugriff auf private Schlüssel (und damit den Fallback) von Nginx entfernen. Eine der frühen Ursachen für Fallbacks lag darin, dass Gokeyless-intern den Fehler ErrKeyNotFound zurückgab, was darauf hindeutete, dass der angeforderte private Schlüssel nicht im Speicher gefunden werden konnte. Dies hätte nicht möglich sein dürfen, weil Nginx erst eine Anfrage an Gokeyless-intern schickt, nachdem das Paar aus Zertifikat und Schlüssel im Speicher gefunden wurde, und wir den privaten Schlüssel und das Zertifikat immer zusammen schreiben. Es stellte sich heraus, dass der Fehler nicht nur für den beabsichtigten Fall eines wirklich nicht gefundenen Schlüssels zurückgegeben wurde, sondern auch, wenn vorübergehende Fehler wie Timeouts auftraten. Um dieses Problem zu beheben, aktualisierten wir diese vorübergehenden Fehlerbedingungen, damit ErrInternal zurückgegeben wird, und stellten das Ergebnis in unseren Versuchsrechenzentren bereit. Seltsamerweise mussten wir beobachten, dass es bei ein paar Instanzen in einem einzelnen Rechenzentrum zu hohen Fallbackraten kam. Die Protokolle von Nginx deuteten darauf hin, dass dies auf ein Timeout zwischen Nginx und Gokeyless-intern zurückzuführen war. Die Timeouts traten nicht sofort auf, aber sobald ein System mit der Protokollierung einiger Timeouts begann, hörte es nicht mehr auf damit. Sogar nachdem wir die Version zurückgesetzt hatten, wurden die Fallbacks mit der alten Version der Software fortgesetzt! Während sich Nginx über Timeouts beschwerte, schien Gokeyless-intern darüber hinaus vollkommen in Ordnung zu sein und meldete vernünftige Leistungsmetriken (mittlere Anforderungslatenz unter einer Millisekunde).
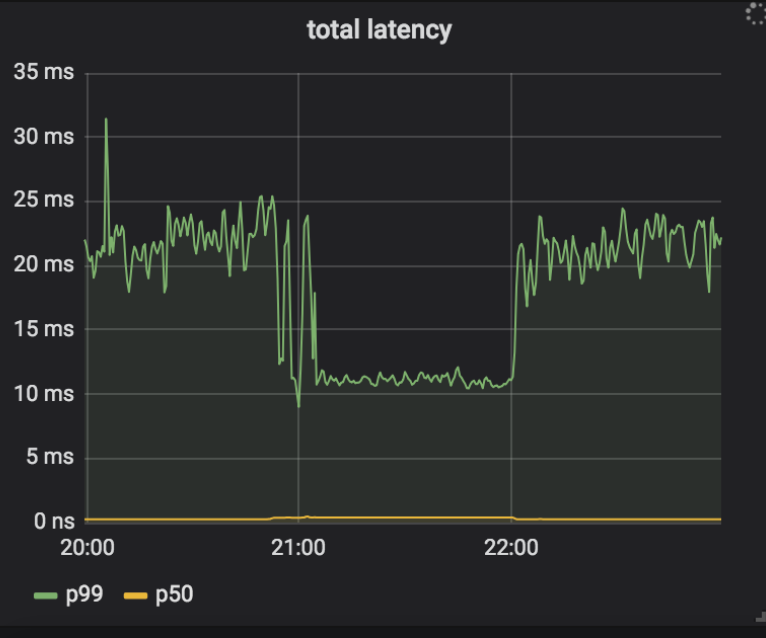
Um das Problem zu debuggen, haben wir sowohl zu Nginx als auch zu Gokeyless eine detaillierte Protokollierung hinzugefügt und die Kette von Ereignissen zurückverfolgt, sobald Timeouts auftraten.
➜ ~ grep 'timed out' nginx.log | grep Keyless | head -5
2018-07-25T05:30:49.000 29m41 2018/07/25 05:30:49 [error] 4525#0: *1015157 Keyless SSL request/response timed out while reading Keyless SSL response, keyserver: 127.0.0.1
2018-07-25T05:30:49.000 29m41 2018/07/25 05:30:49 [error] 4525#0: *1015231 Keyless SSL request/response timed out while waiting for Keyless SSL response, keyserver: 127.0.0.1
2018-07-25T05:30:49.000 29m41 2018/07/25 05:30:49 [error] 4525#0: *1015271 Keyless SSL request/response timed out while waiting for Keyless SSL response, keyserver: 127.0.0.1
2018-07-25T05:30:49.000 29m41 2018/07/25 05:30:49 [error] 4525#0: *1015280 Keyless SSL request/response timed out while waiting for Keyless SSL response, keyserver: 127.0.0.1
2018-07-25T05:30:50.000 29m41 2018/07/25 05:30:50 [error] 4525#0: *1015289 Keyless SSL request/response timed out while waiting for Keyless SSL response, keyserver: 127.0.0.1
Sie können sehen, dass die erste Anforderung zur Protokollierung eines Timeouts die ID 1015157 hatte. Es ist auch interessant, dass die erste Protokollzeile „timed out while reading“ war, aber alle anderen „timed out while waiting“ zeigten, und dass diese letzte Meldung danach immer erschien. Hier ist die passende Anforderung im Gokeyless-Protokoll:
➜ ~ grep 'id=1015157 ' gokeyless.log | head -1
2018-07-25T05:30:39.000 29m41 2018/07/25 05:30:39 [DEBUG] connection 127.0.0.1:30520: worker=ecdsa-29 opcode=OpECDSASignSHA256 id=1015157 sni=announce.php?info_hash=%a8%9e%9dc%cc%3b1%c8%23%e4%93%21r%0f%92mc%0c%15%89&peer_id=-ut353s-%ce%ad%5e%b1%99%06%24e%d5d%9a%08&port=42596&uploaded=65536&downloaded=0&left=0&corrupt=0&key=04a184b7&event=started&numwant=200&compact=1&no_peer_id=1 ip=104.20.33.147
Aha! Dieser SNI-Wert ist eindeutig ungültig (SNIs sind wie Host-Header, d. h. sie sind Domains, keine URL-Pfade), und er ist auch ziemlich lang. Unser Speichersystem indiziert Zertifikate auf der Grundlage von zwei Indizes: welchem SNI sie entsprechen und welchen IP-Adressen sie entsprechen (für ältere Clients, die SNI nicht unterstützen). Unsere Speicherschnittstelle setzt das Memcached-Protokoll ein und die Clientbibliothek, die von Gokeyless-intern verwendet wird, lehnt Anforderungen für Schlüssel ab, die länger als 250 Zeichen sind (die maximale Schlüssellänge von Memcached). Die Nginx-Logik hingegen besteht darin, ungültige SNIs einfach zu ignorieren und die Anforderung so zu behandeln, als ob sie nur eine IP-Adresse hätte. Die Änderung in unserer neuen Version hatte diese Bedingung von ErrKeyNotFound zu ErrInternal verschoben, wodurch kaskadierende Probleme in Nginx ausgelöst wurden. Die angetroffenen „Timeouts“ kamen in Wirklichkeit daher, dass alle an einer Verbindung im Multiplexmodus laufenden Anforderungen verworfen wurden, wenn ErrInternal für eine einzelne Anforderung zurückgegeben wurde. Diese Anforderungen wurden wiederholt, aber sobald dieser Zustand ausgelöst war, wurde Nginx durch die Anzahl der wiederholten Anforderungen zusätzlich zu dem kontinuierlichen Strom neuer Anforderungen, die mit fehlerhaften SNIs eingingen, überlastet und konnte sich nicht erholen. Das erklärt, warum das Zurücksetzen von Gokeyless-intern das Problem nicht behoben hat.
Diese Entdeckung lenkte unsere Aufmerksamkeit schließlich auf Nginx, das wir bisher nicht verdächtigt hatten, weil es jahrelang zuverlässig mit Schlüsselservern von Kunden gearbeitet hatte. Die Kommunikation mit einem mehrinstanzenfähigen Schlüsselserver über Localhost unterscheidet sich jedoch grundlegend von der Kommunikation mit dem Schlüsselserver eines Kunden über das öffentliche Internet, und wir mussten die folgenden Änderungen vornehmen:
- Anstelle eines langen Verbindungstimeouts und eines relativ kurzen Antworttimeouts für Kunden-Schlüsselserver sind für einen Localhost-Schlüsselserver extrem kurze Verbindungstimeouts und längere Anforderungstimeouts angemessen.
- Ebenso ist es sinnvoll, es erneut zu versuchen (mit Backoff), wenn das Warten auf eine Antwort von einem Kunden-Schlüsselserver einem Timeout unterliegt, da wir dem Netzwerk nicht vertrauen können. Über Localhost würde ein Timeout jedoch nur auftreten, wenn Gokeyless-intern überlastet ist und die Anforderung noch in einer Warteschlange auf die Verarbeitung wartet. In diesem Fall würde ein Wiederholungsversuch nur dazu führen, dass Gokeyless-intern insgesamt noch mehr Arbeit leisten müsste, was die Situation weiter verschlimmern würde.
- Vor allem darf Nginx nicht alle an einer Verbindung im Multiplexmodus laufenden Anforderungen verwerfen, wenn eine einzelne von ihnen auf einen Fehler stößt, da eine einzelne Verbindung keinen einzelnen Kunden mehr repräsentiert.
Implementierungen sind wichtig
CPU an der Edge ist eines unserer wertvollsten Assets, und es wird eng von unserem Performance-Team (auch bekannt als CPU-Polizei) bewacht. Bald nach dem Einschalten von Keyless Everywhere in einem unserer Versuchsrechenzentren bemerkte das Team, dass Gokeyless pro Instanz ca. 50 % eines Kerns beanspruchte. Da wir die Zeichenoperationen von Nginx auf Gokeyless verschoben hatten, würde es jetzt natürlich mehr CPU-Leistung beanspruchen. Aber es hätte eine entsprechende Reduzierung der CPU-Auslastung bei Nginx geben sollen, oder?
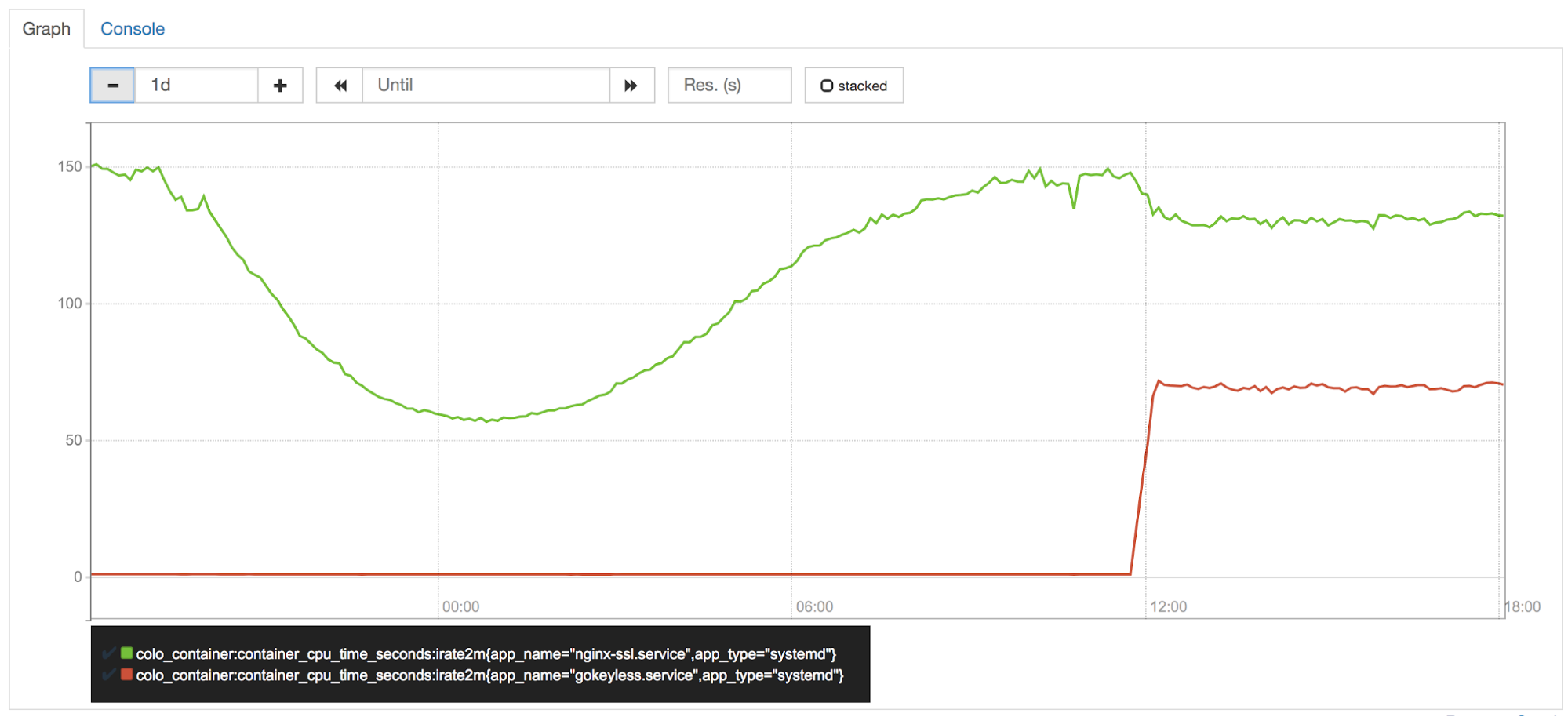
Falsch. Elliptische Kurvenoperationen sind in Go sehr schnell, aber es ist bekannt, dass RSA-Operationen viel langsamer sind als ihre BoringSSL-Pendants.
Obwohl Go 1.11 Optimierungen für mathematische RSA-Operationen enthält, benötigten wir mehr Geschwindigkeit. Um der Leistung von BoringSSL zu entsprechen, ist ein optimierter Assemblercode erforderlich. Also half Armando Faz von unserem Crypto-Team, einen Teil der verlorenen CPU-Leistung zurückzugewinnen, indem er Teile des mathematischen/großen Pakets mit plattformabhängigem Assemblercode in einer internen Go-Verzweigung neu implementierte. Die aktuelle Assemblerrichtlinie von Go bevorzugt die Verwendung von Go-portablem Code anstelle von Assemblercode, weshalb diese Optimierungen nicht vorgelagert wurden. Es gibt noch Platz für weitere Optimierungen, und aus diesem Grund evaluieren wir weiterhin den Wechsel zu cgo + BoringSSL für Zeichenoperationen – trotz der vielen Nachteile von cgo.
Wir ändern unsere Tools
Prozessisolation ist ein leistungsstarkes Tool zum Schutz von Geheimnissen im Speicher. Unser Wechsel zu Keyless Everywhere zeigt, dass dieses Tool nicht einfach einzusetzen ist. Die Neuarchitektur eines vorhandenen Systems wie Nginx für den Einsatz von Prozessisolation zum Schutz von Geheimnissen war zeitaufwändig und schwierig. Ein weiterer Ansatz zur Verbesserung der Speichersicherheit ist die Verwendung einer speichersicheren Sprache wie Rust.
Rust wurde ursprünglich von Mozilla entwickelt, wird aber allmählich in viel größerem Umfang eingesetzt. Der Hauptvorteil von Rust gegenüber C/C++ besteht darin, dass es Speichersicherheitsfunktionen ohne Garbage Collector hat.
Eine vorhandene Anwendung in eine neue Sprache wie Rust umzuschreiben, ist eine gewaltige Aufgabe. Dennoch wurden viele neue Cloudflare-Funktionen – von den leistungsstarken Firewall Rules bis hin zu unserer App 1.1.1.1 mit WARP – in Rust geschrieben, um dessen leistungsstarke Speichersicherheitseigenschaften zu nutzen. Wir sind mit Rust bisher sehr zufrieden und planen, es in Zukunft noch mehr einzusetzen.
Fazit
Die verheerenden Folgen von Heartbleed lehrten die Branche eine Lektion, die im Nachhinein hätte offensichtlich sein sollen: Es ist eine riskante Sicherheitspraxis, wichtige Geheimnisse in Anwendungen zu bewahren, auf die Remote-Zugriff über das Internet möglich ist. In den folgenden Jahren haben wir mit viel Arbeit Prozesstrennung und Keyless SSL eingesetzt, um sicherzustellen, dass der nächste Heartbleed keine Gefahr für Kundenschlüssel darstellt.
Das ist jedoch nicht das Ende des Wegs. In letzter Zeit wurden Sicherheitslücken wie NetSpectre entdeckt, die die Offenlegung von Speicherinhalten bewirken können und die in der Lage sind, Anwendungsprozessgrenzen zu umgehen. Daher suchen wir weiterhin aktiv nach neuen Möglichkeiten, um Schlüssel sicher zu halten.
