
Vor etwa neun Jahren war Cloudflare noch ein winziges Unternehmen und ich war ein Kunde, kein Mitarbeiter. Cloudflare gab es erst seit einem Monat. Eines Tages wurde ich darüber benachrichtigt, dass bei meiner kleinen Website jgc.org der DNS-Service nicht mehr funktionierte. Cloudflare hat seine Verwendung von Protocol Buffers angepasst und dadurch wurde der DNS-Service unterbrochen.
Ich habe eine E-Mail mit dem Titel „Where‘s my dns?“ (Wo ist mein DNS) direkt an Matthew Prince gesendet und er hat mit einer langen, detaillierten, technischen Erklärung reagiert (Sie können den vollständigen E-Mail-Austausch hier lesen), auf die ich antwortete:
Von: John Graham-Cumming
Datum: Do., 7. Okt. 2010 um 09:14
Betreff: Re: Wo ist mein DNS?
An: Matthew Prince
Toller Bericht, danke. Ich werde auf jeden Fall anrufen, wenn es ein
Problem geben sollte. Es wäre wahrscheinlich sinnvoll, all das in
einem Blog-Beitrag festzuhalten, wenn Sie alle technischen Details haben. Ich glaube nämlich,
dass es Kunden wirklich zu schätzen wissen, wenn mit solchen Dingen offen und ehrlich umgegangen wird.
Sie könnten auch die Traffic-Zunahme nach der Implementierung mit
Diagrammen veranschaulichen.
Ich habe eine recht zuverlässige Überwachung für meine Websites eingerichtet, deshalb bekomme ich eine SMS, wenn
etwas ausfällt. Meine Daten zeigen, dass die Website von 13:03:07 bis
14:04:12 nicht verfügbar war. Die Tests erfolgen alle fünf Minuten.
Das war nur ein kleiner Fehler und ich bin mir sicher, dass Sie etwas daraus lernen. Aber bräuchten Sie nicht vielleicht
jemanden in Europa? :-)
Darauf antwortete er:
Von: Matthew Prince
Datum: Do., 7. Okt. 2010 um 09:57
Betreff: Re: Wo ist mein DNS?
An: John Graham-Cumming
Vielen Dank. Wir haben allen geantwortet, die sich bei uns gemeldet haben. In bin gerade auf dem Weg
zum Büro und wir werden etwas in den Blog stellen oder einen offiziellen
Beitrag ganz oben auf dem Bulletin Board System verankern. Ich stimme Ihnen zu 100 % zu,
dass Transparenz der richtige Weg ist.
Und so kommt es, dass ich heute ein Mitarbeiter eines deutlich größeren Cloudflare bin und für Transparenz sorge, indem ich über unsere Fehler, ihre Auswirkungen und unsere Gegenmaßnahmen schreibe.
Die Ereignisse des 2. Juli
Am 2. Juli haben wir eine neue Regel zu unseren WAF Managed Rules hinzugefügt, durch die alle CPU-Kerne überlastet wurden, die HTTP/HTTPS-Traffic im weltweiten Cloudflare-Netzwerk verarbeiten. Wir optimieren die WAF Managed Rules kontinuierlich, um neue Schwachstellen und Bedrohungen zu eliminieren. Zum Beispiel haben wir mit einem schnellen WAF-Update im Mai eine Regel implementiert, um eine schwerwiegende SharePoint-Schwachstelle zu schließen. Die Möglichkeit, Regeln schnell und global bereitzustellen, ist ein besonders wichtiges Feature unserer WAF.
Leider enthielt das Update vom letzten Dienstag einen regulären Ausdruck, der ein enormes Backtracking ausgelöst hat und die CPUs der HTTP/HTTPS-Verarbeitung überlastet hat. Dadurch wurden die grundlegenden Proxy-, CDN- und WAF-Funktionen von Cloudflare deaktiviert. Auf dem folgenden Graphen können Sie sehen, dass die CPUs für den HTTP/HTTPS-Traffic bei allen Servern unseres Netzwerks fast zu 100 % ausgelastet waren.
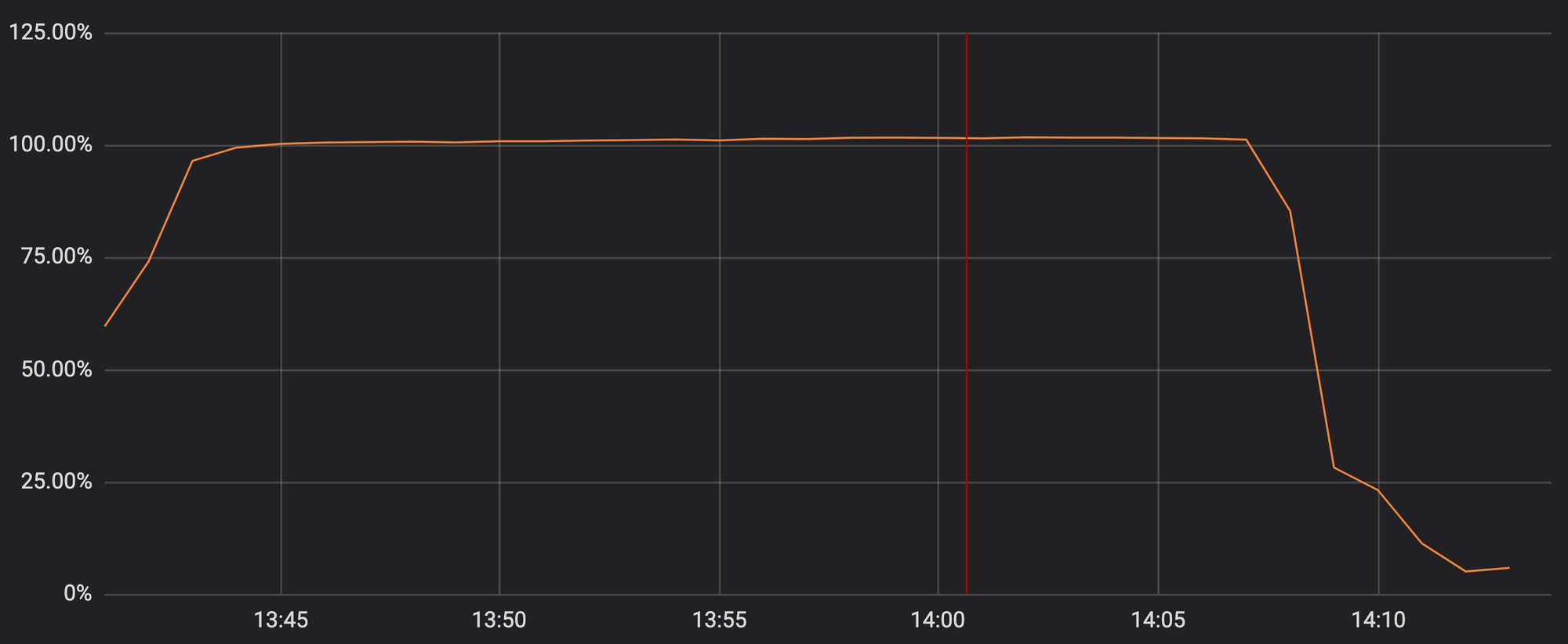
Deshalb wurde unseren Kunden (und deren Kunden) beim Aufrufen einer beliebigen Cloudflare-Domain eine 502-Fehlerseite angezeigt. Die 502-Fehler wurden von den Cloudflare-Webservern erzeugt, die noch über CPU-Kerne verfügten, aber die Prozesse für den HTTP/HTTPS-Traffic nicht erreichen konnten.
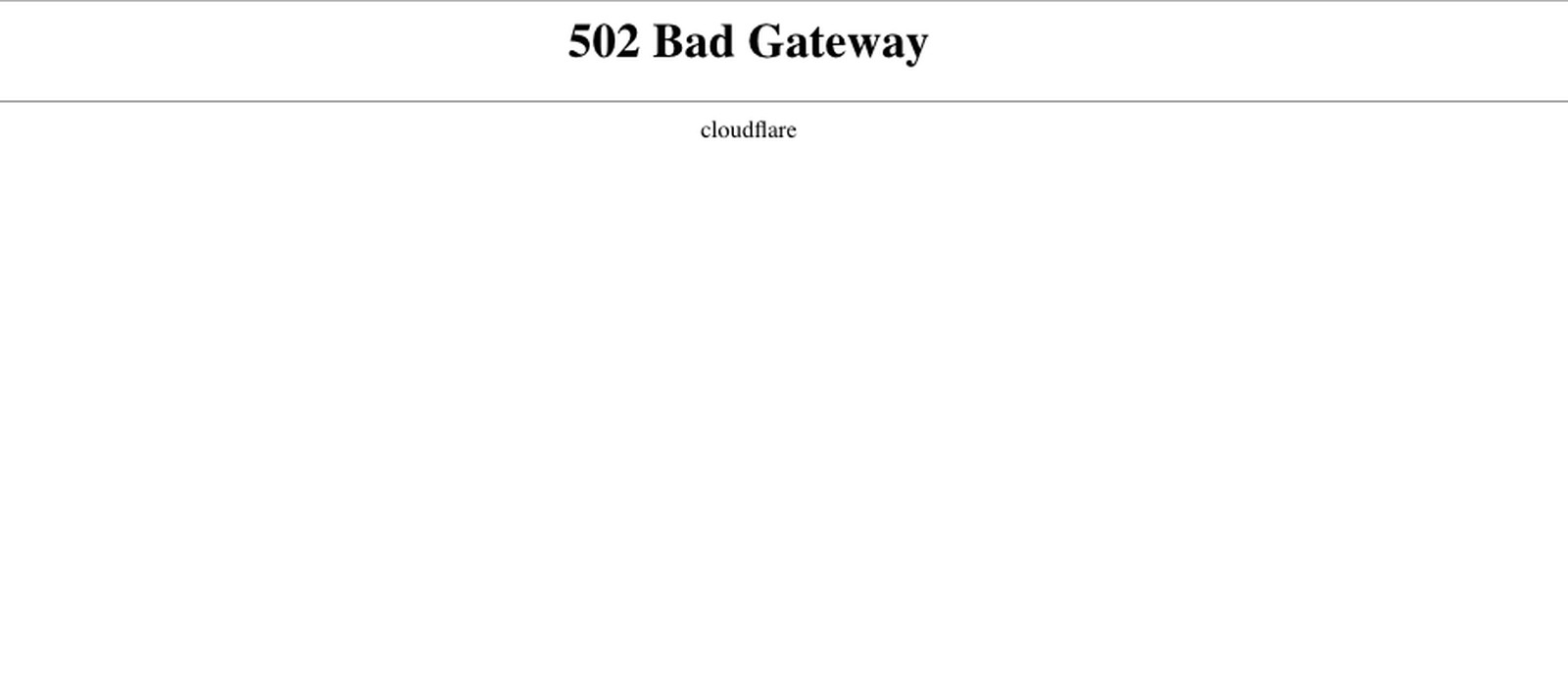
Wir wissen, wie sehr der Vorfall unseren Kunden geschadet hat. Wir schämen uns dafür. Auch unsere eigenen Betriebsabläufe waren betroffen, als wir Gegenmaßnahmen ergriffen haben.
Der Ausfall muss Ihnen als Kunde enormen Stress, Frustration und vielleicht sogar Verzweiflung bereitet haben. Wir hatten seit sechs Jahren keinen globalen Ausfall mehr, entsprechend groß war unser Ärger.
Die CPU-Überlastung wurde von einer einzigen WAF-Regel verursacht, die einen schlecht geschriebenen regulären Ausdruck enthielt, der ein enormes Backtracking auslöste. Dies ist der reguläre Ausdruck, der den Ausfall verursacht hat: (?:(?:\"|'|\]|\}|\\|\d|(?:nan|infinity|true|false|null|undefined|symbol|math)|\`|\-|\+)+[)]*;?((?:\s|-|~|!|{}|\|\||\+)*.*(?:.*=.*)))
Obwohl dieser reguläre Ausdruck für viele Personen von Interesse ist (und unten genauer beschrieben wird), sind die genauen Gründe für die 27 Minuten lange Nichtverfügbarkeit des Cloudflare-Services deutlich komplexer, als dass einfach nur ein schlecht geschriebener regulärer Ausdruck implementiert wurde. Wir haben uns die Zeit genommen, die Ereigniskette aufzuschreiben, die zum Ausfall geführt hat und unsere Reaktion gebremst hat. Wenn Sie mehr über das Backtracking bei regulären Ausdrücken und die möglichen Gegenmaßnahmen erfahren möchten, sehen Sie sich den Anhang am Ende des Beitrags an.
Was passiert ist
Betrachten wir die Ereignisse in ihrer Reihenfolge. Alle Zeitangaben in diesem Blog basieren auf UTC.
Um 13:42 hat ein Engineer des Firewall-Teams eine kleine Änderung an den Regeln der XSS-Erkennung mithilfe eines automatischen Prozesses implementiert. Dadurch wurde ein Ticket für eine Änderungsanfrage erzeugt. Wir verwenden Jira, um diese Tickets zu bearbeiten und unten sehen Sie einen Screenshot davon.
Drei Minuten später ist die erste PagerDuty-Seite ausgefallen, was auf einen Fehler bei der WAF hingedeutet hat. Das war ein synthetischer Test, mit dem außerhalb von Cloudflare überprüft wird, ob die WAF ordnungsgemäß funktioniert (wir nutzen Hunderte solcher Tests). Direkt darauf folgten die Meldungen weiterer End-to-End-Tests über die Ausfälle von Cloudflare-Services bei Websites, eine Warnung wegen einer rapide Abnahme des globalen Traffics, eine enorme Anzahl an 502-Fehlern und dann viele Berichte von unseren PoPs (Points-of-Presence) in Städten auf der ganzen Welt, die eine CPU-Überlastung anzeigten.


Einige dieser Meldungen wurden auf meiner Uhr angezeigt und ich bin während des Meetings aufgesprungen und war gerade auf dem Weg zu meinem Schreibtisch, als ein leitender Solutions Engineer mich darüber informierte, dass wir 80 % unseres Traffics verloren hatten. Ich rannte zu unserer SRE-Abteilung, wo das Team gerade die Situation analysierte. Anfangs wurde sogar spekuliert, ob es sich um einen Angriff ungeahnten Ausmaßes handeln könnte.

Das SRE-Team von Cloudflare ist auf der ganzen Welt verteilt, damit rund um die Uhr für Monitoring gesorgt ist. Warnungen wie diese, die meist nur sehr spezifische Probleme mit überschaubaren Auswirkungen betreffen, werden mit internen Dashboards überwacht und mehrfach täglich überprüft und behandelt. Diese Menge an Websites und Warnungen deutete aber darauf hin, dass etwas äußerst Schwerwiegendes vorgefallen ist, weshalb das SRE-Team dies sofort als P0-Vorfall deklariert hat und ihn zum leitenden Engineering und System Engineering eskaliert hat.
Das Engineering-Team aus London befand sich gerade im zentralen Veranstaltungsraum und hörte sich einen internen Tech Talk an. Der Tech Talk wurde unterbrochen, das Team versammelte sich in einem großen Konferenzraum und andere schalteten sich dazu. Das war kein normales Problem, um das sich das SRE-Team alleine kümmern konnte: Alle relevanten Teams mussten gleichzeitig verfügbar sein.
Um 14:00 wurde erkannt, dass die WAF der Ursprung des Problems ist, und die Möglichkeit eines Angriffs wurde ausgeschlossen. Das Performance Team konnte CPU-Daten in Echtzeit abrufen, die eindeutig belegten, dass die WAF ursächlich war. Ein Teammitglied konnte dies mit strace bestätigen. Ein anderes Team erhielt Fehlerprotokolle, die auf Probleme bei der WAF hindeuteten. Um 14:02 wandten sich alle Blicke des Teams zu mir, als die Verwendung eines „global kill“ im Raum stand, eines Cloudflare-Mechanismus, mit dem eine bestimmte Komponente weltweit deaktiviert werden kann.
Aber dazu mussten wir erst einmal die Fähigkeit zu einem „global kill“ der WAF erhalten. Ohne Weiteres war dies nicht möglich. Wir verwenden unsere eigenen Produkte und da unser Access-Dienst nicht mehr funktionierte, konnten wir uns bei unserem internen Control Panel nicht authentifizieren (wir haben festgestellt, dass einige Teammitglieder ihren Zugriff verloren hatten, weil eine Sicherheitsfunktion ihre Anmeldedaten deaktiviert, wenn sie das interne Control Panel nicht regelmäßig verwenden).
Und wir konnten andere interne Dienste wie Jira oder das Build-System nicht mehr aufrufen. Wir mussten dieses Problem mit einem Mechanismus umgehen, der nur sehr selten verwendet wurde (und ein weiterer Prozess, den wir nach dem Vorfall genauer unter die Lupe nahmen). Letztendlich konnte ein Teammitglied um 14:07 den „global kill“ der WAF ausführen und um 14:09 befanden sich Traffic und CPU-Niveaus wieder weltweit im normalen Bereich. Der restliche Cloudflare-Schutzmechanismus war wieder aktiv.
Dann sorgten wir dafür, dass die WAF wieder funktionierte. Da dieser Vorfall ziemlich ernst war, führten wir in einer einzigen Stadt sowohl negative Tests (mit der Frage, ob wirklich diese eine Änderung das Problem verursacht hatte) als auch positive Tests (zur Überprüfung, ob der Rollback wirklich funktioniert hatte) mit einem Teil des Traffics durch, nachdem wir den Traffic unserer zahlenden Kunden von diesem Standort abgezogen hatten.
Um 14:52 waren wir zu 100 % davon überzeugt, dass wir die Ursache verstanden hatten, das Problem behoben war und die WAF wieder global aktiv war.
Wie Cloudflare arbeitet
Cloudflare verfügt über ein Engineering-Team, das an WAF Managed Rules arbeitet. Es optimiert kontinuierlich die Erkennungsraten, minimiert die falsch-positiven Ergebnisse und reagiert unmittelbar auf neue Bedrohungen. In den vergangenen 60 Tagen wurden 476 Änderungsanfragen für die WAF Managed Rules bearbeitet (durchschnittlich eine alle 3 Stunden).
Diese spezielle Änderung wurde im „Simulationsmodus“ bereitgestellt, in dem der echte Kunden-Traffic zwar von der Regel überprüft wird, er aber ungehindert durchgeleitet wird. Mit diesem Modus testen wir die Effektivität einer Regel und messen die Raten falsch-positiver und falsch-negativer Ergebnisse. Aber selbst im „Simulationsmodus“ müssen die Regeln tatsächlich ausgeführt werden und in diesem Fall enthielt die Regel einen regulären Ausdruck, der eine CPU-Überlastung auslöste.
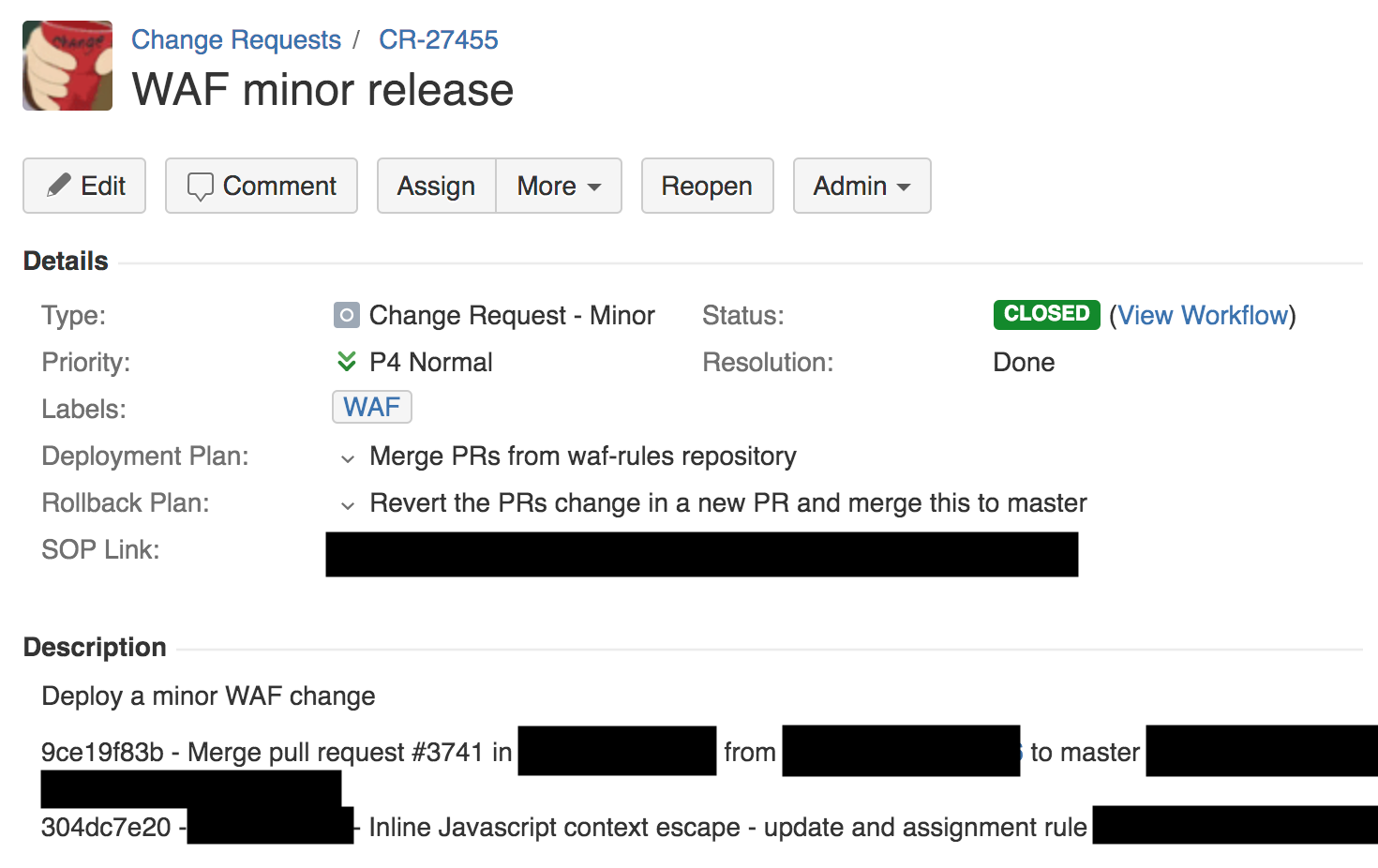
Wie oben in der Änderungsanfrage ersichtlich, gibt es einen Bereitstellungsplan, einen Rollbackplan und einen Link zum internen Standard Operating Procedure (SOP) für diese Art von Bereitstellung. Das SOP erlaubt ausdrücklich die globale Implementierung einer Regeländerung. Diese Methodik unterscheidet sich deutlich von unserem normalen Ansatz bei der Software-Veröffentlichung, wo SOP die Software zunächst bei einem internen Dogfooding-Netzwerk-PoP (Point of Presence) implementiert (den unsere Kunden nur passieren), dann bei einer geringen Kundenzahl an einem isolierten Standort, gefolgt von einer großen Kundenzahl und schließlich weltweit. „Dogfooding“ ist übrigens ein englischer Ausdruck dafür, dass ein Unternehmen sein eigenes Produkt verwendet.
Der Prozess zur Software-Veröffentlichung sieht folgendermaßen aus: Wir verwenden intern git mittels BitBucket. Die Engineers, die Änderungen bearbeiten, schreiben Code, der in TeamCity erstellt wird. Wenn das Build bestätigt wird, werden Prüfer zugewiesen. Sobald ein Pull Request bestätigt wurde, wird der Code erstellt und die Test-Suite (erneut) ausgeführt.
Wenn der Build-Test erfolgreich war, wird bei Jira eine Änderungsanfrage erstellt und die Änderung muss von der zuständigen Führungskraft oder einer technischen Leitung bestätigt werden. Nach der Bestätigung erfolgt die Bereitstellung an den „Animal PoPs“, wie wir sie nennen: DOG, PIG und Canaries.
Der DOG-PoP ist ein Cloudflare-PoP (genau wie eine unserer Städte auf der Welt), der aber nur von Cloudflare-Mitarbeitern verwendet wird. Mithilfe dieses Dogfooding-PoPs können wir Probleme beheben, bevor ein Kunden-Traffic damit in Kontakt kommt. Und genau das passiert auch häufig.
Wenn der DOG-Test erfolgreich abgeschlossen wird, geht der Code in die PIG-Phase über (Englisch „Guinea Pig“, zu Deutsch „Meerschweinchen“). Dies ist ein Cloudflare-PoP, an dem ein kleiner Anteil des Traffics von kostenlosen Benutzern den neuen Code durchläuft.
Wenn dieser Test erfolgreich ist, geht der Code zu den „Canaries“ (Kanarienvögeln) über. Wir verfügen über drei auf die ganze Welt verteilte Canary-PoPs, über die der Traffic von zahlenden und kostenlosen Kunden geleitet wird, damit der neue Code noch ein letztes Mal auf Fehler überprüft werden kann.
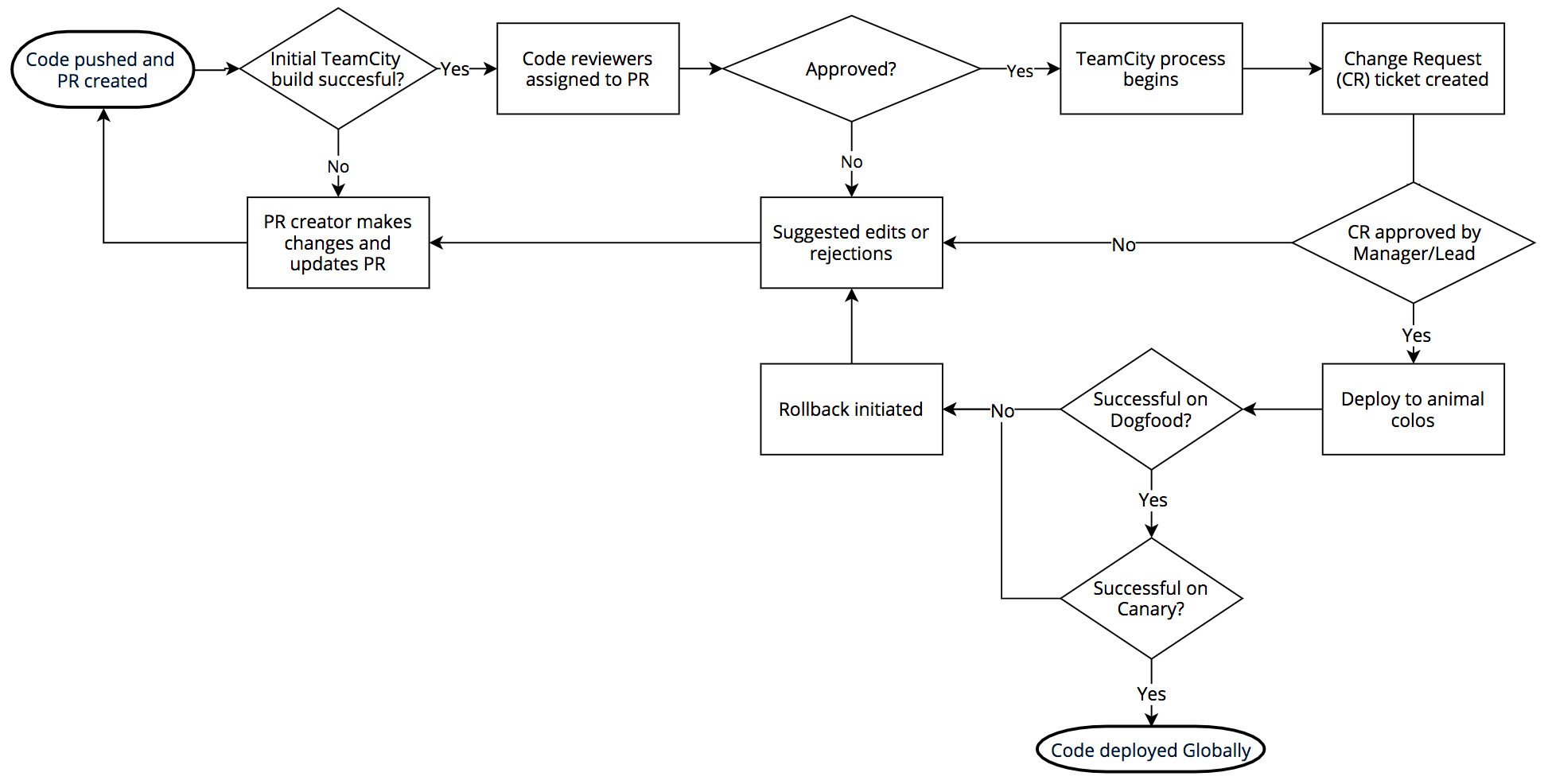
Nach dem erfolgreichen Canary-Test ist der Code zur globalen Implementierung freigegeben. Je nach Codeänderung können mehrere Stunden oder Tage bis zum Abschluss des gesamten Prozesses aus DOG, PIG, Canary und Global vergehen. Dank der Vielseitigkeit des Netzwerks und der Kunden von Cloudflare können wir den Code gründlich überprüfen, bevor eine neue Version global für alle Kunden eingeführt wird. Im Falle der WAF findet dieser Prozess aber keine Anwendung, da Bedrohungen ja eine schnelle Reaktion erfordern.
WAF-Bedrohungen
In den vergangenen Jahren mussten wir eine drastische Zunahme an Schwachstellen bei gängigen Anwendungen feststellen. Das lässt sich auf die steigende Verfügbarkeit von Softwaretestingtools mit Methoden wie Fuzzing zurückführen (einen neuen Blog-Beitrag zum Thema Fuzzing haben wir erst kürzlich hier veröffentlicht).
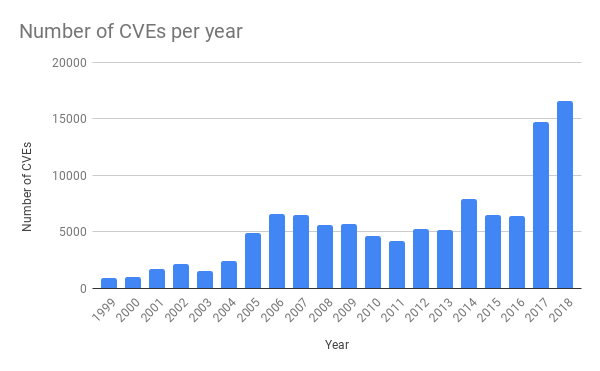
Häufig wird ein Proof of Concept (PoC) erstellt und direkt auf Github veröffentlicht, damit Teams, die Anwendungen ausführen und bearbeiten, ihre Tests durchführen können, um sicherzustellen, dass sie über geeignete Schutzmaßnahmen verfügen. Deshalb muss Cloudflare unbedingt so schnell wie möglich auf neue Bedrohungen reagieren und Softwarepatches für seine Kunden bereitstellen.
Ein gutes Beispiel für diesen proaktiven Schutz von Cloudflare ist die Bereitstellung der Schutzmaßnahmen wegen der SharePoint-Schwachstelle im Mai hier im Blog). Direkt nach der öffentlichen Bekanntgabe verzeichneten wir einen signifikanten Anstieg der Exploit-Versuche bei den SharePoint-Installationen unserer Kunden. Unser Team hält kontinuierlich Ausschau nach neuen Bedrohungen und schreibt Regeln, um sie im Sinne unserer Kunden zu bekämpfen.
Bei der spezifischen Regel, die den Ausfall am letzten Dienstag verursachte, ging es um XSS-Angriffe (Cross-Site Scripting). Auch diese haben in den letzten Jahren signifikant zugenommen.
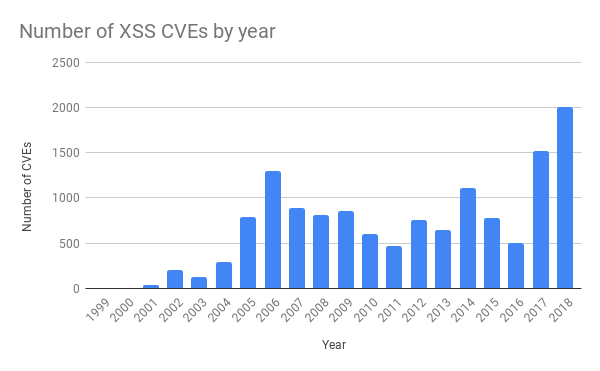
Im Rahmen des Standardverfahrens für eine Anpassung der WAF Managed Rules sind erfolgreiche CI-Tests (Continuous Integration) vor der globalen Bereitstellung vorgesehen. Diese wurden am letzten Dienstag erfolgreich durchgeführt und die Regeln wurden bereitgestellt. Um 13:31 hat ein Engineer des Teams einen Pull Request mit der Änderung implementiert, nachdem sie bestätigt worden war.
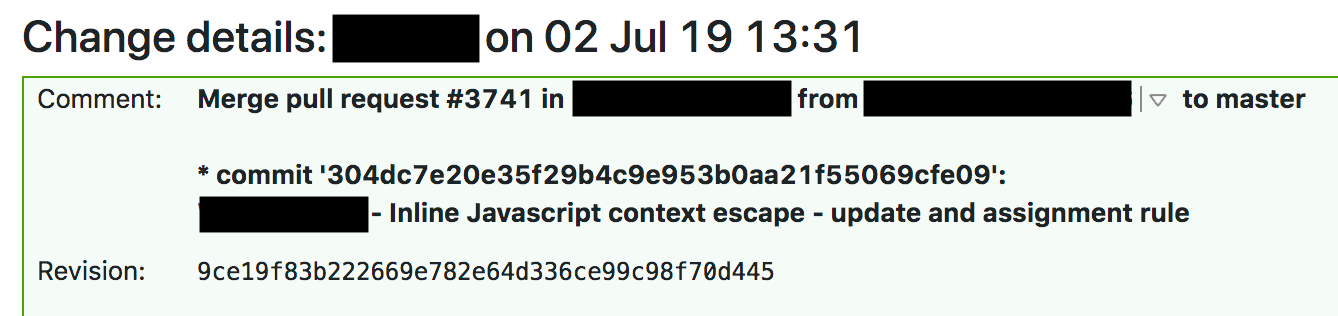
Um 13:37 hat TeamCity die Regeln erstellt, seine Tests durchgeführt und grünes Licht gegeben. Die WAF-Testsuite überprüft die grundlegenden WAF-Funktionen und besteht aus einer großen Testsammlung für individuelle Abgleichfunktionen. Nach dem Testlauf werden die individuellen WAF-Regeln getestet, indem eine große Anzahl an HTTP-Anfragen unter Einbeziehung der WAF ausgeführt wird. Diese HTTP-Anfragen sind als Testanfragen konzipiert, die von der WAF blockiert werden sollen (damit potenzielle Angriffe abgewehrt werden) bzw. nicht blockiert werden sollen (damit nicht zu viel blockiert wird und keine falsch-positiven Ergebnisse entstehen). Nicht getestet wurde jedoch die übermäßige CPU-Auslastung durch die WAF. Auch die Überprüfung der Protokolldateien von vorherigen WAF-Builds hat ergeben, dass bei der Regel keine überhöhte Testsuite-Laufzeit erkannt wurde, die letztendlich eine CPU-Auslastung verursachen könnte.
Die Tests wurden erfolgreich abgeschlossen und TeamCity begann um 13:42 mit der automatischen Bereitstellung der Änderung.
Quicksilver
Da WAF-Regeln akute Bedrohungen abwehren müssen, werden sie mit unserer verteilten Schlüssel-Werte-Datenbank Quicksilver bereitgestellt, die Änderungen in wenigen Sekunden global implementiert. Diese Technologie wird von allen unseren Kunden für Konfigurationsänderungen in unserem Dashboard oder per API verwendet und darauf beruht unsere Fähigkeit, auf Änderungen äußerst schnell zu reagieren.
Bis jetzt haben wir noch nicht viel über Quicksilver gesprochen. Zuvor haben wir Kyoto Tycoonals globalen Schlüssel-Werte-Speicher (KV-Speicher) verwendet, aber wir hatten damit Probleme im Betrieb und erstellten dann unseren eigenen KV-Speicher, der für unsere über 180 Standorte repliziert wird. Mit Quicksilver übertragen wir Änderungen an Kundenkonfigurationen, aktualisieren wir WAF-Regeln und verteilen JavaScript-Code, der von Kunden mit Cloudflare Workers geschrieben wurde.
Es dauert vom Klicken auf eine Schaltfläche im Dashboard oder Tätigen eines API-Aufrufs zum Ändern der Konfiguration nur ein paar Sekunden, bis die Änderung aktiv ist – global. Die Kunden lieben mittlerweile diese Konfigurierbarkeit mit Höchstgeschwindigkeit. Sie erwarten bei Workers eine praktisch sofortige, globale Softwarebereitstellung. Quicksilver verteilt durchschnittlich etwa 350 Änderungen pro Sekunde.
Und Quicksilver ist sehr schnell. Unser P99 für die Verteilung einer Änderung an jeden Rechner weltweit lag bei durchschnittlich 2,29 s. Diese Geschwindigkeit ist normalerweise eine tolle Sache. Wenn man ein Feature aktiviert oder den Cache entleert, weiß man, dass diese Änderung praktisch sofort live ist, weltweit. Jede Codeübermittlung mit Cloudflare Workers erfolgt mit der gleichen Geschwindigkeit. Das ist Teil des Versprechens der schnellen Updates von Cloudflare, die da sind, wenn man sie braucht.
In diesem Fall hieß die Geschwindigkeit jedoch, dass eine Änderung an den Regeln innerhalb von Sekunden global live war. Wie Sie sehen, nutzt der WAF-Code Lua. Cloudflare nutzt Lua bei der Produktion in hohem Maße. Details zu Lua in der WAF wurden bereits erörtert. Die Lua-WAF nutzt intern PCRE und verwendet Backtracking zum Abgleich. Sie hat keine Schutzvorrichtung gegen aus der Reihe tanzende Ausdrücke. Mehr dazu, und was wir dagegen tun, lesen Sie unten.

Alles bis zum Zeitpunkt der Regelbereitstellung erfolgte „korrekt“: eine Pull-Anfrage wurde gestellt, sie wurde genehmigt, CI/CD erstellte den Code und testete ihn, eine Änderungsanfrage mit einem SOP mit Details zu Rollout und Rollback wurde eingereicht und das Rollout wurde ausgeführt.
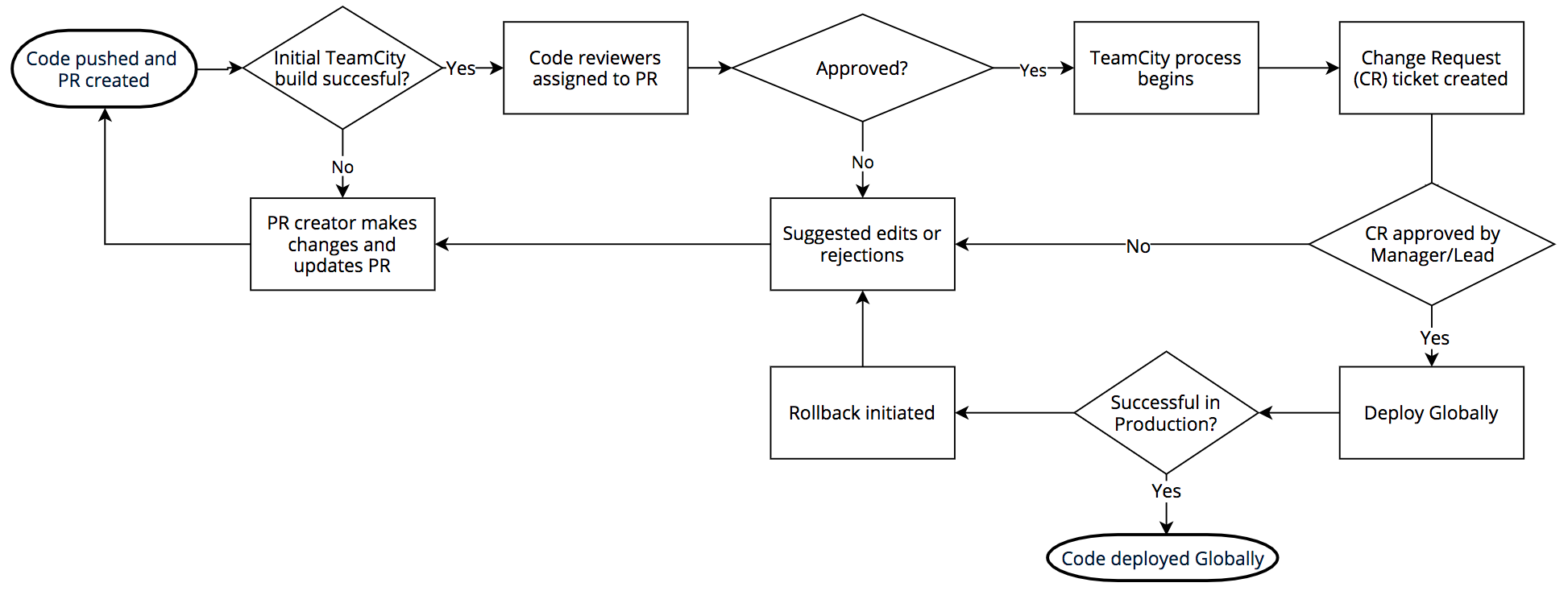
Was ist schiefgelaufen?
Wie erwähnt, stellen wir jede Woche Dutzende neuer Regeln für die WAF bereit und haben mehrere Systeme installiert, um negative Auswirkungen dieser Bereitstellungen zu vermeiden. Wenn also etwas schiefgeht, ist die Ursache normalerweise ein unwahrscheinliches Zusammentreffen mehrerer Faktoren. Die Suche nach einer einzigen Grundursache mag zwar befriedigend sein, geht aber oft an der Realität vorbei. Dies sind die Verwundbarkeiten, die alle zusammentrafen, bis der Punkt erreicht war, an dem die Cloudflare-Services für HTTP/HTTPS offline gingen.
- Ein Techniker schrieb einen regulären Ausdruck, der leicht ein enormes Backtracking bewirken konnte.
- Ein Schutz vor übermäßiger CPU-Auslastung durch einen regulären Ausdruck wurde versehentlich einige Wochen vorher während einer Umgestaltung der WAF entfernt. Die Umgestaltung war Teil des Bemühens, die CPU-Nutzung durch die WAF zu reduzieren.
- Die verwendete Engine für reguläre Ausdrücke hatte keine Komplexitätsgarantien.
- Die Testsuite konnte eine übermäßige CPU-Nutzung nicht erkennen.
- Das SOP erlaubte, dass eine nicht mit einem Notfall zusammenhängende Regeländerung global in die Produktion ging, ohne dass ein gestaffelter Rollout stattfand.
- Der Rollback-Plan erforderte, dass die komplette WAF zweimal ausgeführt wird, was zu lange dauerte.
- Das Auslösen der ersten Warnmeldung für den globalen Traffic-Rückgang dauerte zu lange.
- Unsere Statusseite wurde nicht schnell genug aktualisiert.
- Wir hatten wegen des Ausfalls Probleme, auf unsere eigenen Systeme zuzugreifen, und die Mitarbeiter waren für das Umgehungsverfahren nicht gut geschult.
- Die SREs hatten den Zugriff auf einige Systeme verloren, da ihre Anmeldedaten aus Sicherheitsgründen ausgesetzt wurden.
- Unsere Kunden konnten nicht auf das Cloudflare-Dashboard oder die Cloudflare-API zugreifen, da sie durch das Cloudflare-Edge laufen.
Das ist seit letztem Dienstag passiert
Zunächst stellten wir alle Release-Arbeiten am WAF komplett ein und widmeten uns Folgendem:
- Wiedereinführung des entfernten Schutzes vor übermäßiger CPU-Auslastung (erledigt)
- Manuelles Überprüfen aller 3.868 Regeln in den WAF Managed Rules, um etwaige andere Fälle von potenziell übermäßigem Backtracking zu finden und zu korrigieren (Prüfung abgeschlossen)
- Einführung von Performanceprofilierung für alle Regeln an die Testsuite (voraussichtl. Juli 2019)
- Wechsel zur re2- oder Rust regex-Engine, die beide Laufzeitgarantien bieten (voraussichtl. 31. Juli)
- Ändern der SOP, sodass gestaffelte Rollouts von Regeln erfolgen, wie sie auch für andere Software bei Cloudflare durchgeführt werden; dabei soll die Fähigkeit für globale Notfallbereitstellungen bei aktiven Angriffen erhalten bleiben
- Implementieren einer Notfallfunktion zum Entfernen von Cloudflare-Dashboard und -API aus dem Cloudflare-Edge
- Automatisieren von Aktualisierungen der Cloudflare Status-Seite
Langfristig möchten wir von der Lua-WAF abrücken, die ich vor Jahren schrieb. Wir migrieren die WAF, sodass sie die neue Firewall-Engine nutzen kann. Dadurch wird die WAF schneller und es wird eine weitere Schutzebene hinzugefügt.
Schlussfolgerung
Dieser Ausfall war für unsere Kunden und das Team äußerst ärgerlich. Wir reagierten schnell, um das Problem zu beheben, und korrigieren nun die Mängel im Prozess, die den Ausfall möglich machten. Wir gehen der Sache auf den Grund, um Schutz vor weiteren potenziellen Problemen durch die Verwendung regulärer Ausdrücke zu bieten, indem wir die zugrunde liegende Technologie ersetzen.
Wir sind beschämt über den Ausfall und entschuldigen uns bei unseren Kunden für die Auswirkungen. Wir denken, dass die von uns vorgenommenen Änderungen dafür sorgen, dass ein solcher Ausfall nie mehr auftreten wird.
Anhang: Über das Backtracking von regulären Ausdrücken
Um genau zu verstehen, wie (?:(?:\"|'|\]|\}|\\|\d|(?:nan|infinity|true|false|null|undefined|symbol|math)|\`|\-|\+)+[)]*;?((?:\s|-|~|!|{}|\|\||\+)*.*(?:.*=.*))) die CPU-Überlastung verursachte, müssen wir etwas darüber wissen, wie eine Standard-Engine für reguläre Ausdrücke funktioniert. Der kritische Teil ist .*(?:.*=.*). Das (?: und die passende ) sind eine Gruppe ohne Erfassung (d. h., der Ausdruck innerhalb der Klammern ist als ein einziger Ausdruck zusammen gruppiert).
Bei der Diskussion, warum dieses Muster eine CPU-Überlastung verursachte, können wir ihn getrost ignorieren und das Muster als .*.*=.* behandeln. Wenn es darauf reduziert wird, sieht das Muster natürlich unnötig komplex aus; das Wichtige ist jedoch, dass jeder Ausdruck aus der „realen Welt“ (wie die komplexen Ausdrücke in unseren WAF-Regeln), der von der Engine verlangt, „irgendetwas gefolgt von irgendetwas abzugleichen“, zu katastrophalem Backtracking führen kann. Hier ist der Grund:
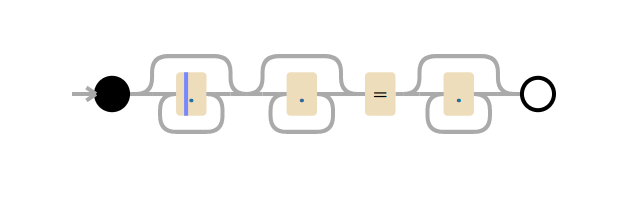
In einem regulären Ausdruck bedeutet . den Abgleich eines einzigen Zeichens. .* bedeutet einen „gierigen“ (greedy) Abgleich von null oder mehr Zeichen (d. h. einen Abgleich von so viel wie möglich). .*.*=.* bedeutet also den Abgleich von null oder mehr Zeichen, dann den Abgleich von null oder mehr Zeichen, dann das Finden eines literalen =-Zeichens, dann den Abgleich von null oder mehr Zeichen.
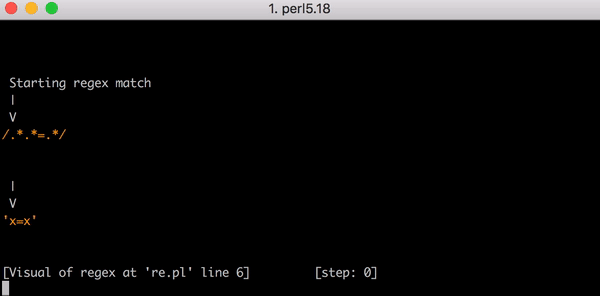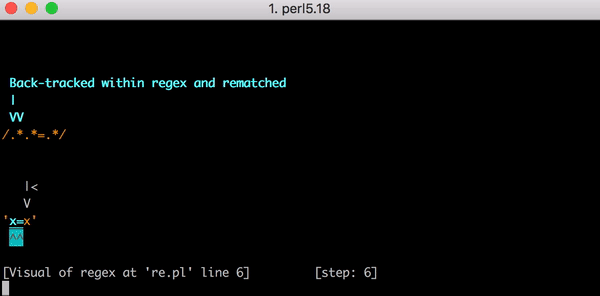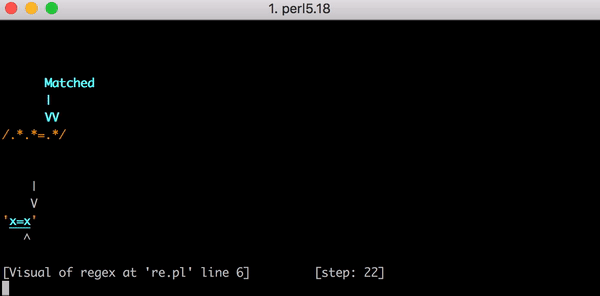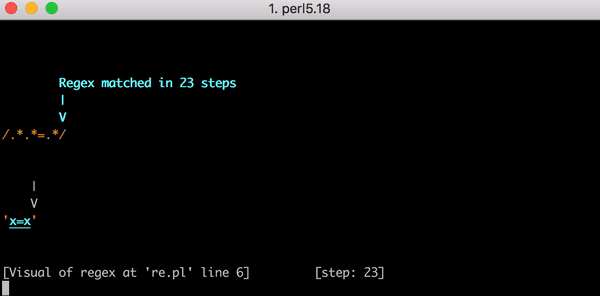
Nehmen wir die Testzeichenfolge x=x. Sie entspricht dem Ausdruck .*.*=.*. Die .*.* vor dem Gleichheitszeichen können mit dem ersten x abgeglichen werden (einer der .* entspricht dem x, der andere entspricht null Zeichen). Der .* nach dem = entspricht dem letzten x.
Dieser Abgleich erfordert 23 Schritte. Der erste .* in .*.*=.* verhält sich gierig und gleicht die gesamte Zeichenfolge x=x ab. Die Engine fährt dann mit dem nächsten .* fort. Es sind keine passenden Zeichen mehr übrig, also entspricht der zweite .* null Zeichen (das ist zulässig). Dann fährt die Engine mit dem = fort. Da keine Zeichen zum Abgleichen übrig sind (der erste .* hat alle x=x aufgebraucht), schlägt der Abgleich fehl.
An diesem Punkt führt die Engine für reguläre Ausdrücke Backtracking durch. Sie kehrt zum ersten .* zurück und gleicht ihn mit x= (anstatt x=x) ab, dann wechselt sie zum zweiten .*. Dieser .* entspricht dem zweiten x. Nun sind keine weiteren Zeichen zum Abgleichen übrig. Deshalb schlägt der Abgleich fehl, wenn die Engine nun versucht, das = in .*.*=.* abzugleichen. Die Engine führt erneut Backtracking durch.
Dieses Mal führt sie das Backtracking so durch, dass der erste .* noch x= entspricht, der zweite .* jedoch nicht mehr x, sondern null Zeichen entspricht. Die Engine fährt dann damit fort, das Literal = im Muster .*.*=.* zu suchen, aber das schlägt fehl (weil es bereits mit dem ersten .* abgeglichen wurde). Die Engine führt erneut Backtracking durch.
Dieses Mal entspricht der erste .* nur dem ersten x. Der zweite .* verhält sich jedoch gierig und gleicht =x ab. Sie ahnen, was nun kommt. Wenn die Engine versucht, das Literal = abzugleichen, schlägt dies fehl und sie führt erneut Backtracking durch.
Der erste .* entspricht immer noch nur dem ersten x. Nun entspricht der zweite .* nur =. Die Engine kann aber, Sie ahnen es, das Literal = nicht abgleichen, weil ihm der zweite .* entsprach. Die Engine führt also erneut Backtracking durch. Denn bei all dem geht es ja, Sie erinnern sich, darum, eine Zeichenfolge aus drei Zeichen abzugleichen.
Nun, da der erste .* nur dem ersten x entspricht und der zweite .* null Zeichen entspricht, kann die Engine schließlich den Literal = im Ausdruck mit dem = in der Zeichenfolge abgleichen. Sie fährt fort und der letzte .* entspricht dem letzten x.
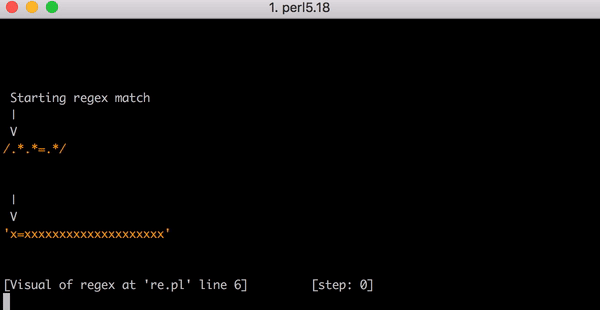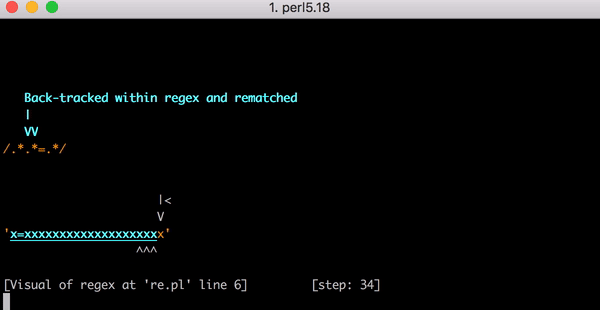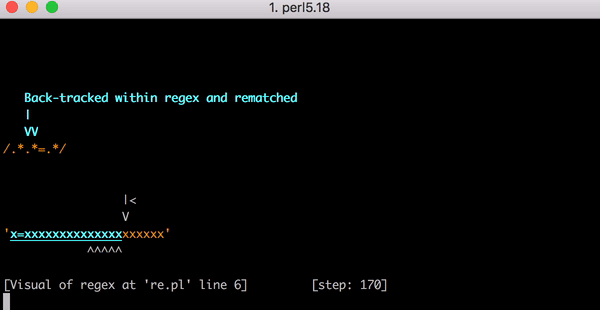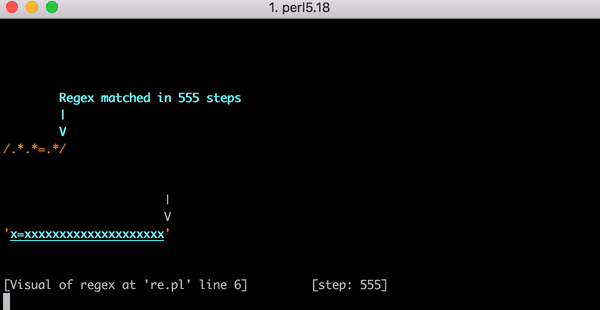
23 Schritte zum Abgleich von x=x. Hier ist ein kurzes Video davon mit dem Perl Regexp::Debugger, das die durchgeführten Schritte und Backtrackings zeigt.
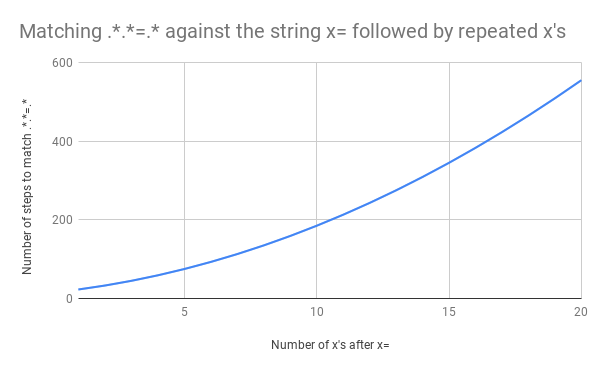
Das ist viel Arbeit. Was aber passiert, wenn die Zeichenfolge von x=x zu x=xx geändert wird? Dieses Mal erfordert der Abgleich 33 Schritte. Und wenn die Eingabe x=xxx lautet, sind es 45. Das ist nicht linear. Hier ist ein Diagramm, das den Abgleich von x=x bis x=xxxxxxxxxxxxxxxxxxxx zeigt (20 x nach dem =). Bei 20 x nach dem = benötigt die Engine 555 Schritte für den Abgleich! (Und wenn das x= fehlen würde, sodass die Zeichenfolge nur aus 20 x bestünde, würde die Engine sogar 4.067 Schritte benötigen, um herauszufinden, dass das Muster nicht übereinstimmt).
Dieses Video zeigt alle notwendigen Backtrackings zum Abgleich von x=xxxxxxxxxxxxxxxxxxxx:
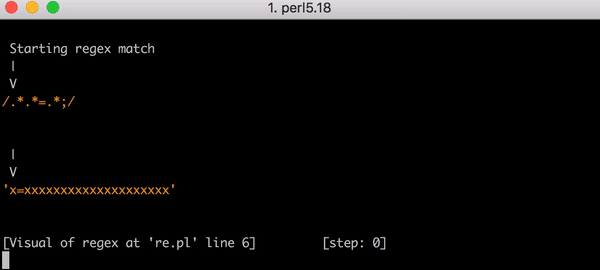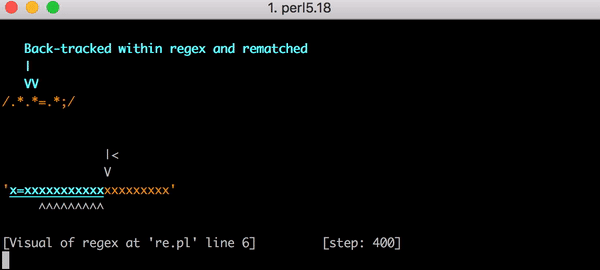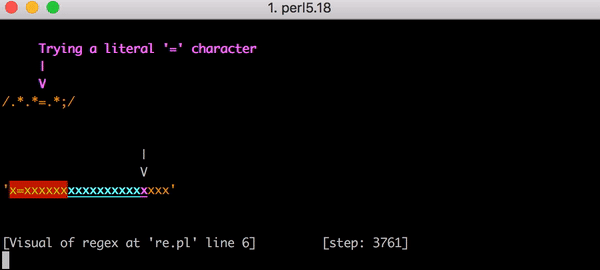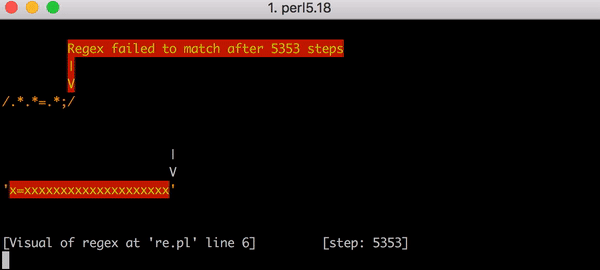
Das ist schlecht, denn wenn die Eingabegröße sich erhöht, steigt die Abgleichzeit superlinear. Es hätte jedoch noch schlimmer kommen können, wenn der reguläre Ausdruck etwas anders aussähe. Angenommen, er hätte .*.*=.*; gelautet (d. h. mit einem literalen Semikolon am Ende des Musters). Dieser Ausdruck könnte z. B. geschrieben werden, um einen Ausdruck wie foo=bar; abzugleichen.
Dieses Mal wäre das Backtracking katastrophal gewesen. Der Abgleich von x=x erfordert 90 Schritte statt 23. Und die Zahl der Schritte wächst sehr schnell. Das Abgleichen von x= gefolgt von 20 x erfordert 5.353 Schritte. Hier ist das entsprechende Diagramm. Sehen Sie sich die Y-Achsen-Werte genau an und vergleichen Sie sie mit dem vorherigen Diagramm.
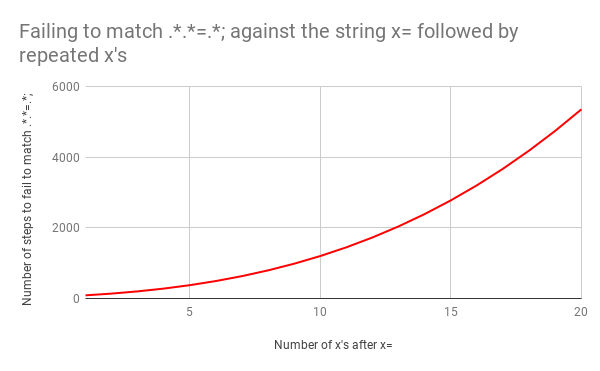
Um das Bild zu vervollständigen, sind hier alle 5.353 Schritte des fehlgeschlagenen Abgleichs von x=xxxxxxxxxxxxxxxxxxxx mit .*.*=.*;
Durch die Verwendung „fauler“ (lazy) anstelle gieriger Abgleiche lässt sich die Zahl der Backtrackings reduzieren, die in diesem Fall auftreten. Wenn der ursprüngliche Ausdruck zu .*?.*?=.*? geändert wird, erfordert der Abgleich von x=x 11 Schritte (statt 23). Genauso ist es beim Abgleich von x=xxxxxxxxxxxxxxxxxxxx. Der Grund ist, dass das ? nach dem .* die Engine anweist, zuerst die kleinste Anzahl von Zeichen abzugleichen, bevor sie mit den nächsten Schritten fortfährt.
Faulheit ist aber keine umfassende Lösung für dieses Backtracking-Verhalten. Wenn im Beispiel mit dem katastrophalen Backtracking .*.*=.*; zu .*?.*?=.*?; geändert wird, verändert sich seine Laufzeit überhaupt nicht. x=xerfordert weiterhin 555 Schritte und x= gefolgt von 20 x erfordert weiterhin 5.353 Schritte.
Die einzige echte Lösung, abgesehen von einem kompletten Umschreiben des Musters, ist, von einer Engine für reguläre Ausdrücke mit diesem Backtracking-Mechanismus abzurücken. Genau das tun wir innerhalb der nächsten paar Wochen.
Die Lösung dieses Problems ist seit 1968 bekannt, als Ken Thompson den Artikel „Programming Techniques: Regular expression search algorithm“ veröffentlichte. Darin wird ein Mechanismus zum Umwandeln eines regulären Ausdrucks in einen NEA (nichtdeterministischer endlicher Automat) beschrieben. Außerdem werden die Zustandswechsel im NEA erläutert, die einem Algorithmus folgen, der zeitlich linear für die Größe der abgeglichenen Zeichenfolge ausgeführt wird.
Thompsons Artikel nimmt nicht direkt Bezug auf den NEA, aber der Algorithmus mit linearer Zeit wird genau erklärt und ein ALGOL-60-Programm, das Assemblersprachencode für den IBM 7094 generiert, wird vorgestellt. Die Implementierung mag obskur erscheinen, die Idee ist es nicht.
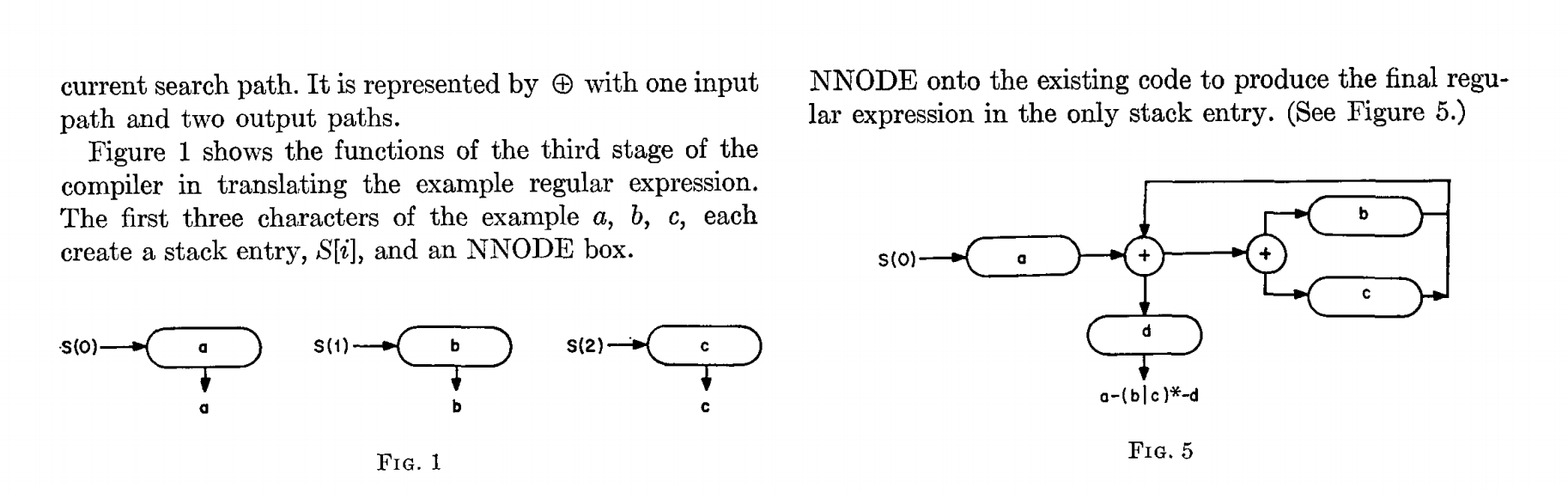
So sähe der reguläre Ausdruck .*.*=.* aus, wenn er gemäß den Zeichnungen in Thompsons Artikel dargestellt würde:
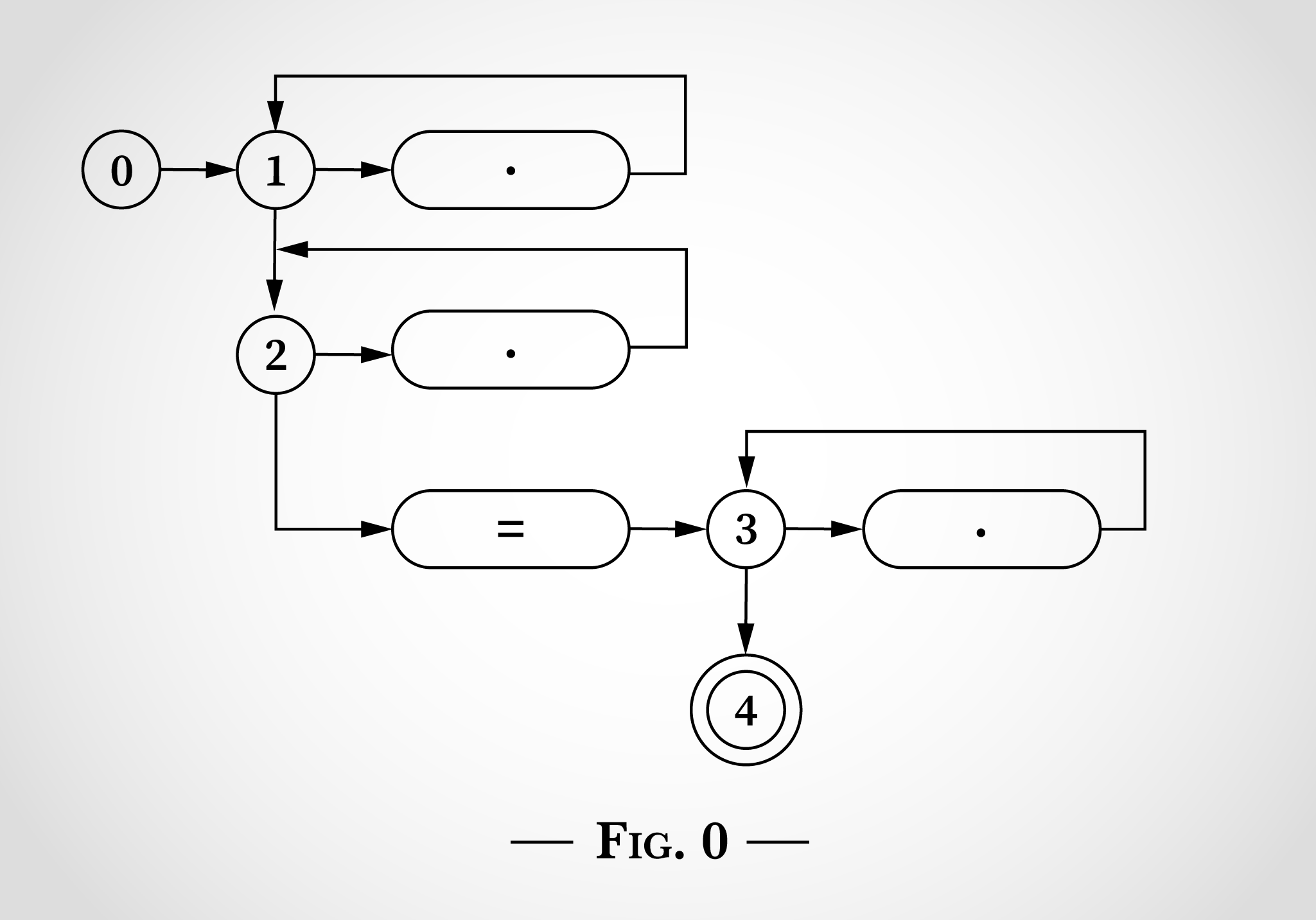
Abbildung 0 zeigt fünf Zustände, angefangen mit 0. Die drei Kreise zeigen die Zustände 1, 2 und 3. Sie entsprechen den drei .* im regulären Ausdruck. Die drei Rhomben mit Punkten darin entsprechen einem einzelnen Zeichen. Der Rhombus mit einem =-Zeichen entspricht dem literalen =-Zeichen. Zustand 4 ist der Endzustand. Wenn er erreicht ist, wurde der reguläre Ausdruck abgeglichen.
Um zu prüfen, wie ein solches Zustandsdiagramm zum Abgleich des regulären Ausdrucks .*.*=.* verwendet werden kann, sehen wir uns nun den Abgleich der Zeichenfolge x=x an. Das Programm beginnt mit Zustand 0, wie in Abbildung 1 gezeigt.
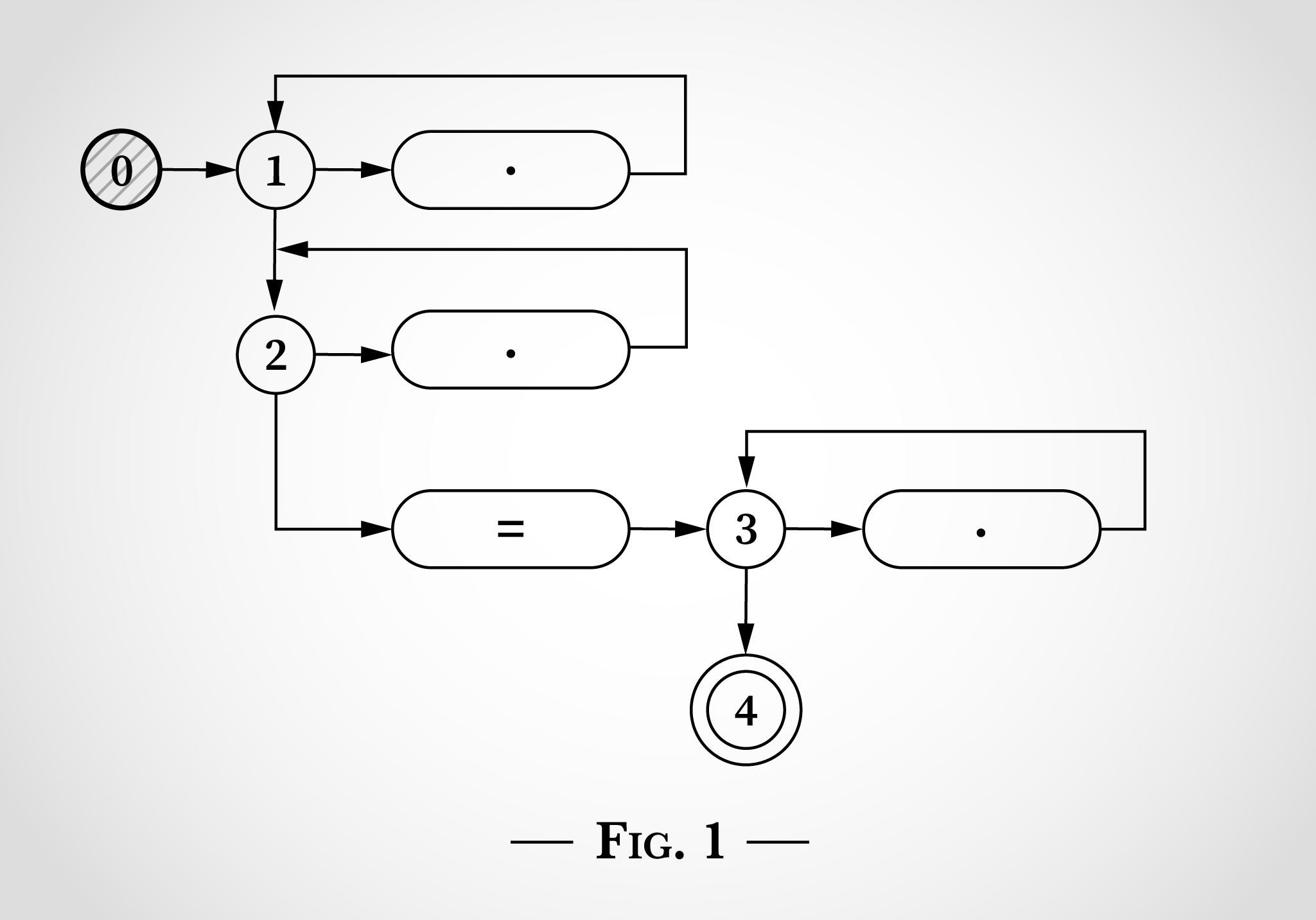
Der Schlüssel dazu, diesen Algorithmus zum Funktionieren zu bringen, ist, dass der Zustandsautomat gleichzeitig mehrere Zustände aufweist. Der NEA führt jeden Wechsel, den er erreichen kann, gleichzeitig durch.
Noch bevor er eine Eingabe liest, wechselt er sofort sowohl in Zustand 1 als auch in Zustand 2, wie in Abbildung 2 gezeigt.
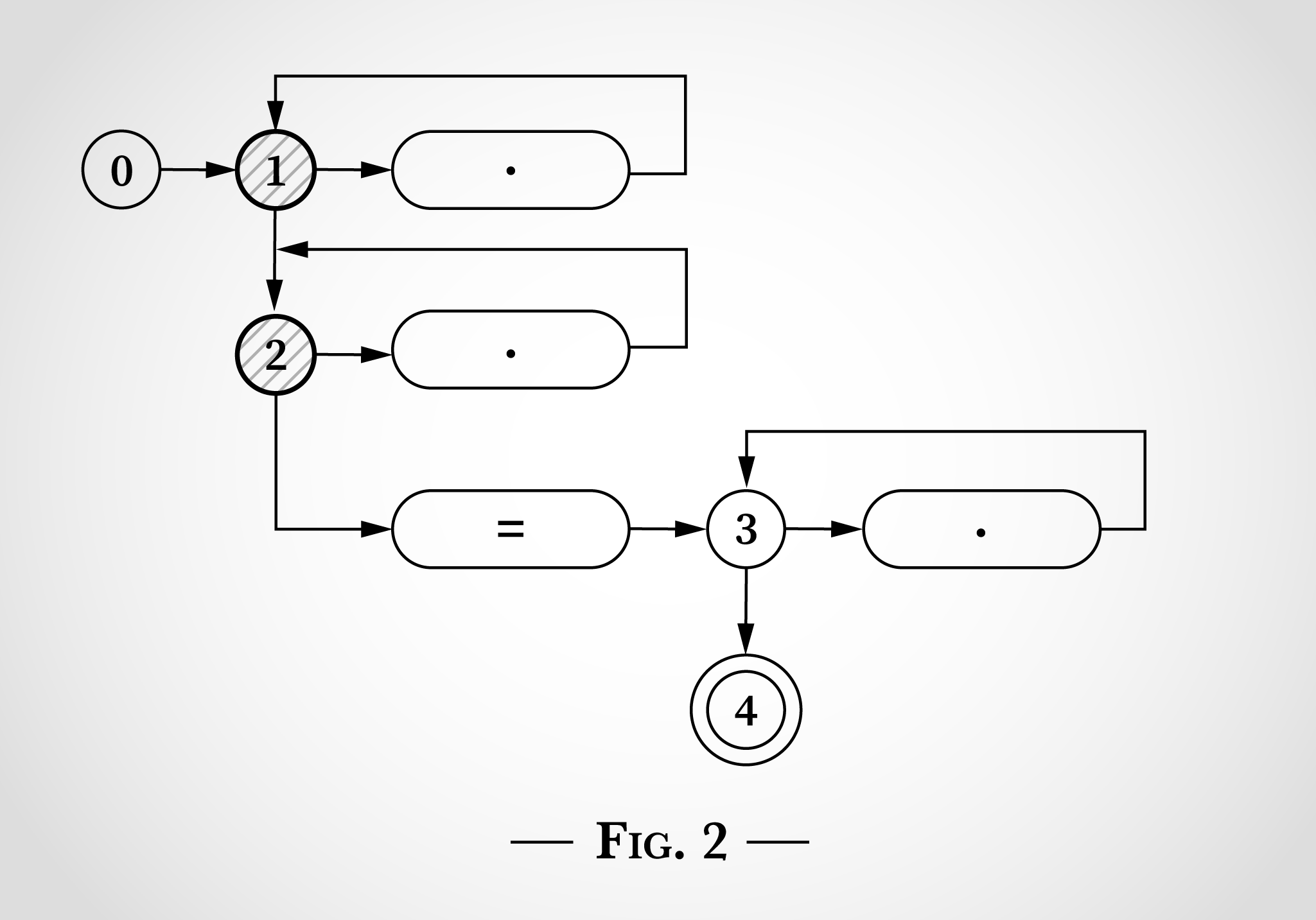
In Abbildung 2 sehen wir, was passieren würde, wenn er zuerst x in x=x berücksichtigt. Das x kann dem obersten Punkt entsprechen, indem von Zustand 1 gewechselt und wieder zurück zu Zustand 1 gewechselt wird. Oder das x kann dem Punkt darunter entsprechen, indem von Zustand 2 gewechselt und wieder zurück zu Zustand 2 gewechselt wird.
Nach dem Abgleich des ersten x in x=x sind die Zustände also weiterhin 1 und 2. Die Zustände 3 oder 4 können nicht erreicht werden, da dazu ein literales =-Zeichen benötigt wird.
Als nächstes nimmt sich der Algorithmus das = in x=x vor. Ähnlich wie das x zuvor kann es einem der beiden oberen Kreise mit dem Wechsel von Zustand 1 zu Zustand 1 bzw. Zustand 2 zu Zustand 2 entsprechen. Zusätzlich kann jedoch das Literal = abgeglichen werden und der Algorithmus kann von Zustand 2 zu Zustand 3 (und sofort zu Zustand 4) wechseln. Das ist in Abbildung 3 veranschaulicht.
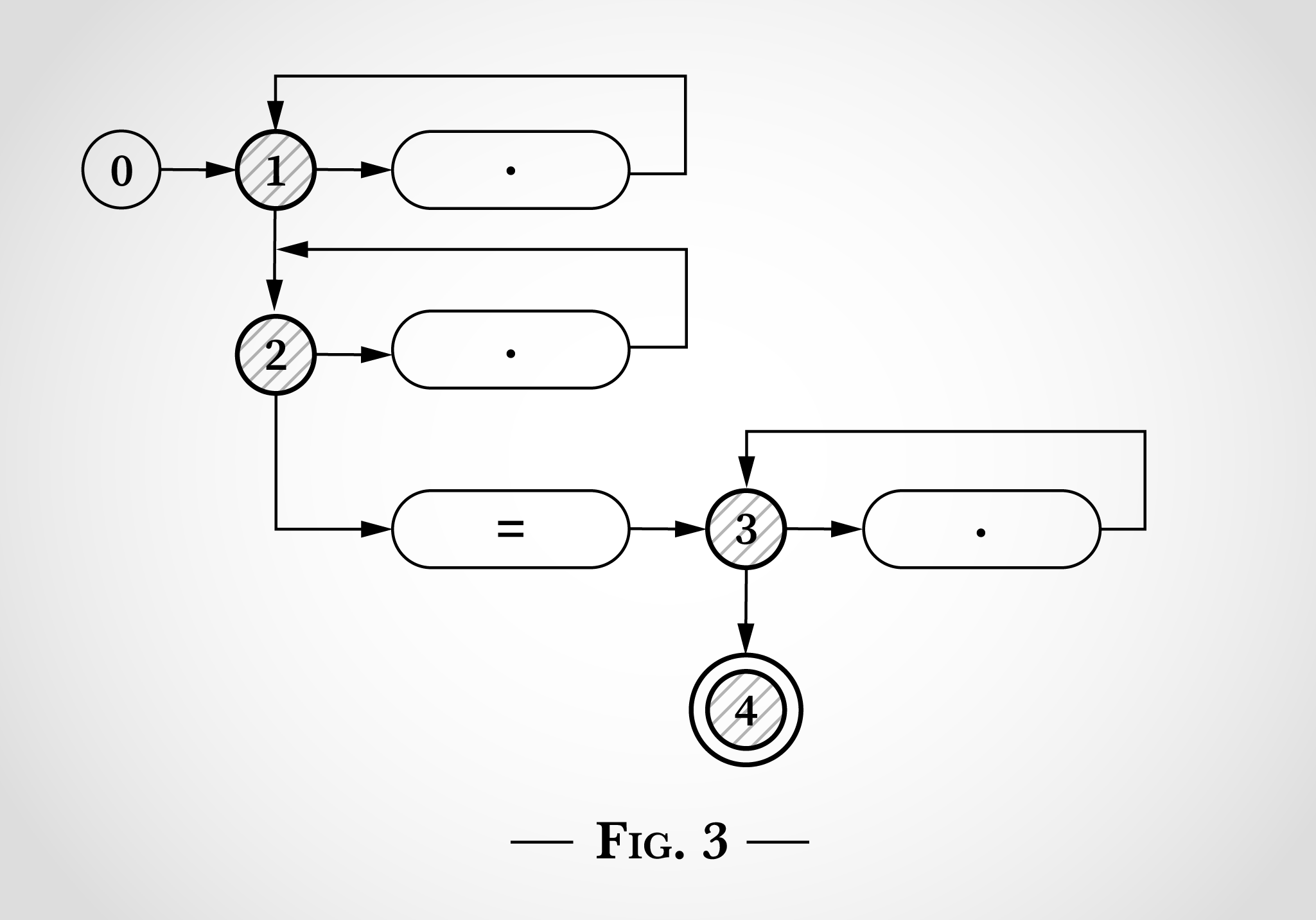
Als nächstes erreicht der Algorithmus das letzte x in x=x. Von den Zuständen 1 und 2 sind die gleichen Wechsel zurück zu den Zuständen 1 und 2 möglich. Von Zustand 3 kann das x dem Punkt auf der rechten Seite entsprechen und zurück zu Zustand 3 wechseln.
An diesem Punkt wurde jedes Zeichen in x=x berücksichtigt; da Zustand 4 erreicht wurde, entspricht der reguläre Ausdruck dieser Zeichenfolge. Jedes Zeichen wurde einmal verarbeitet. Der Algorithmus war also linear für die Länge der Eingabezeichenfolge. Und kein Backtracking war erforderlich.
Es mag offensichtlich sein, aber nachdem Zustand 4 erreicht wurde (nach dem Abgleich von x=), war der reguläre Ausdruck abgeglichen und der Algorithmus konnte enden, ohne das letzte x überhaupt zu berücksichtigen.
Der Algorithmus ist linear für die Größe seiner Eingabe.