


Einleitung
Heute, am 21. Juni 2022, kam es bei Cloudflare zu einem Ausfall, der den Datenverkehr in 19 unserer Rechenzentren beeinträchtigte. Leider sind diese 19 Standorte unsere größten und wickeln einen erheblichen Teil unseres weltweiten Traffics ab. Dieser Ausfall wurde durch eine Änderung verursacht, die Teil eines langjährigen Projekts zur Erhöhung der Ausfallsicherheit an unseren größten Standorten war. Diese Standorte sind ein kritischer Teil unserer Infrastruktur und wickeln einen erheblichen Teil des Cloudflare-Datenverkehrs ab. Eine Änderung der Netzwerkkonfiguration an diesen Standorten verursachte einen Ausfall, der um 06:27 UTC begann. Um 06:58 UTC war das erste Rechenzentrum wieder online und um 07:42 UTC waren alle Rechenzentren online und funktionierten einwandfrei.
Je nach Ihrem Standort in der Welt konnten Sie möglicherweise nicht auf Websites und Dienste zugreifen, die auf Cloudflare angewiesen sind. An anderen Standorten funktionierte Cloudflare weiterhin normal.
Wir möchten uns vielmals für diesen Ausfall entschuldigen. Es war unser Fehler und nicht das Ergebnis eines Angriffs oder einer bösartigen Aktivität.
Hintergrund
In den letzten 18 Monaten hat Cloudflare daran gearbeitet, alle unsere größten Standorte auf eine redundantere Architektur umzustellen. In diesem Zeitraum haben wir 19 unserer Rechenzentren auf diese Architektur umgestellt, die wir intern Multi-Colo PoP (MCP) nennen: Amsterdam, Atlanta, Ashburn, Chicago, Frankfurt, London, Los Angeles, Madrid, Manchester, Miami, Mailand, Mumbai, Newark, Osaka, São Paulo, San Jose, Singapur, Sydney und Tokio.
Ein kritischer Teil dieser neuen Architektur, die als Clos-Netzwerk konzipiert ist, ist eine zusätzliche Routing-Ebene, die ein Netzwerk von Verbindungen schafft. Dieses Netzwerk ermöglicht es uns, Teile des internen Netzwerks in einem Rechenzentrum zu Wartungszwecken oder zur Behebung eines Problems einfach zu deaktivieren und zu aktivieren. Diese Schicht wird durch die Spines im folgenden Diagramm dargestellt.
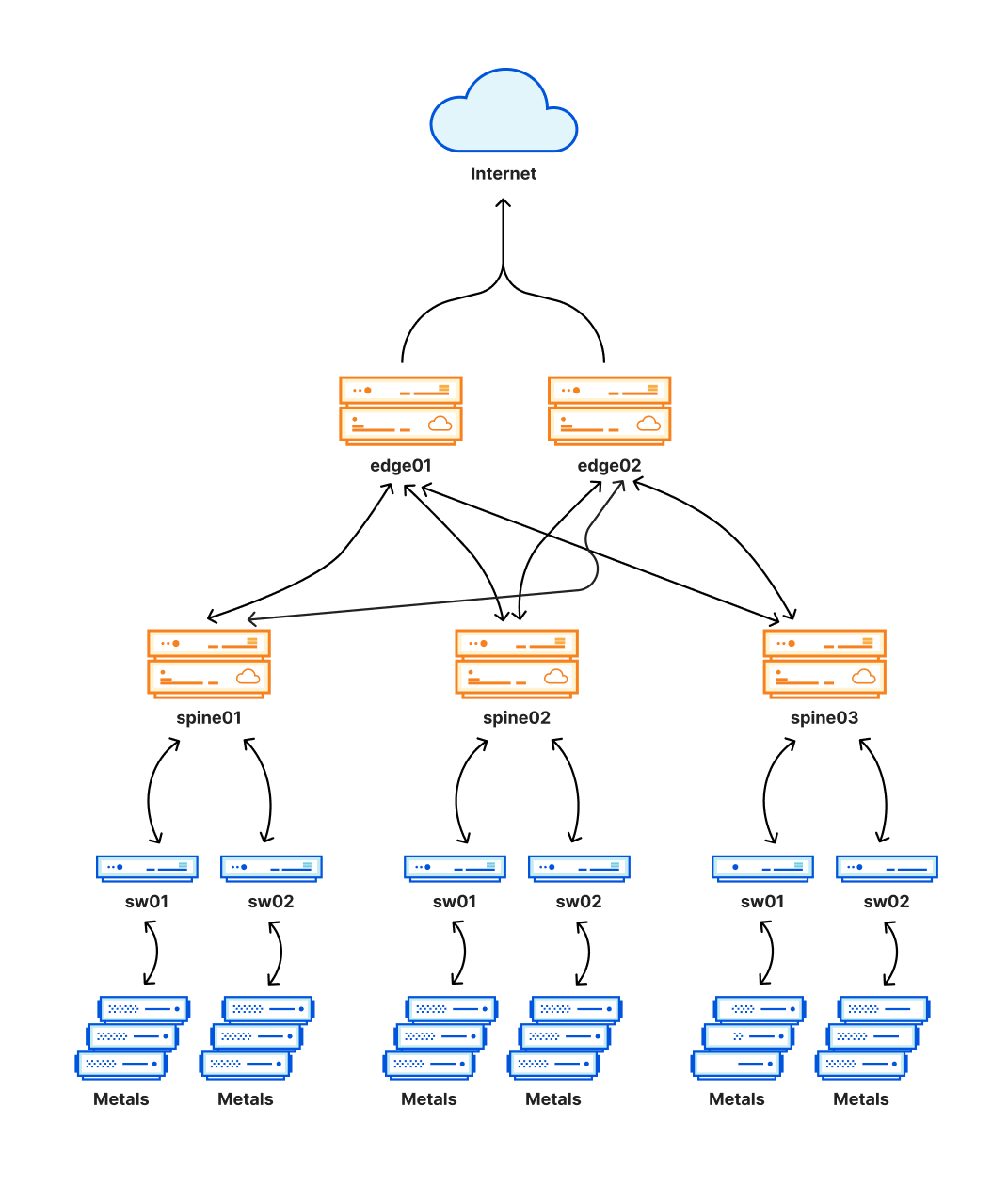
Diese neue Architektur hat unsere Zuverlässigkeit erheblich verbessert und ermöglicht es uns, an diesen Standorten Wartungsarbeiten durchzuführen, ohne den Kunden-Traffic zu unterbrechen. Da diese Standorte auch einen erheblichen Teil des Cloudflare-Traffics abwickeln, kann jedes Problem hier sehr große Auswirkungen haben. Genau das ist heute leider passiert.
Zeitleiste des Vorfalls (UTC) und Auswirkungen
Um im Internet erreichbar zu sein, verwenden Netzwerke wie Cloudflare ein Protokoll namens BGP. Als Teil dieses Protokolls definieren die Betreiber Richtlinien, die darüber entscheiden, welche Präfixe (eine Sammlung benachbarter IP-Adressen) den Peers (den anderen Netzwerken, mit denen sie verbunden sind) angekündigt oder von den Peers akzeptiert werden.
Diese Richtlinien werden aus einzelnen Komponenten bestehen, die nacheinander bewertet werden. Das Endergebnis ist, dass bestimmte Präfixe entweder angekündigt oder nicht angekündigt werden. Eine Änderung der Richtlinie kann bedeuten, dass ein zuvor beworbenes Präfix nicht mehr angekündigt wird. In diesem Fall wird es widerrufen und diese IP-Adressen sind im Internet nicht mehr erreichbar.
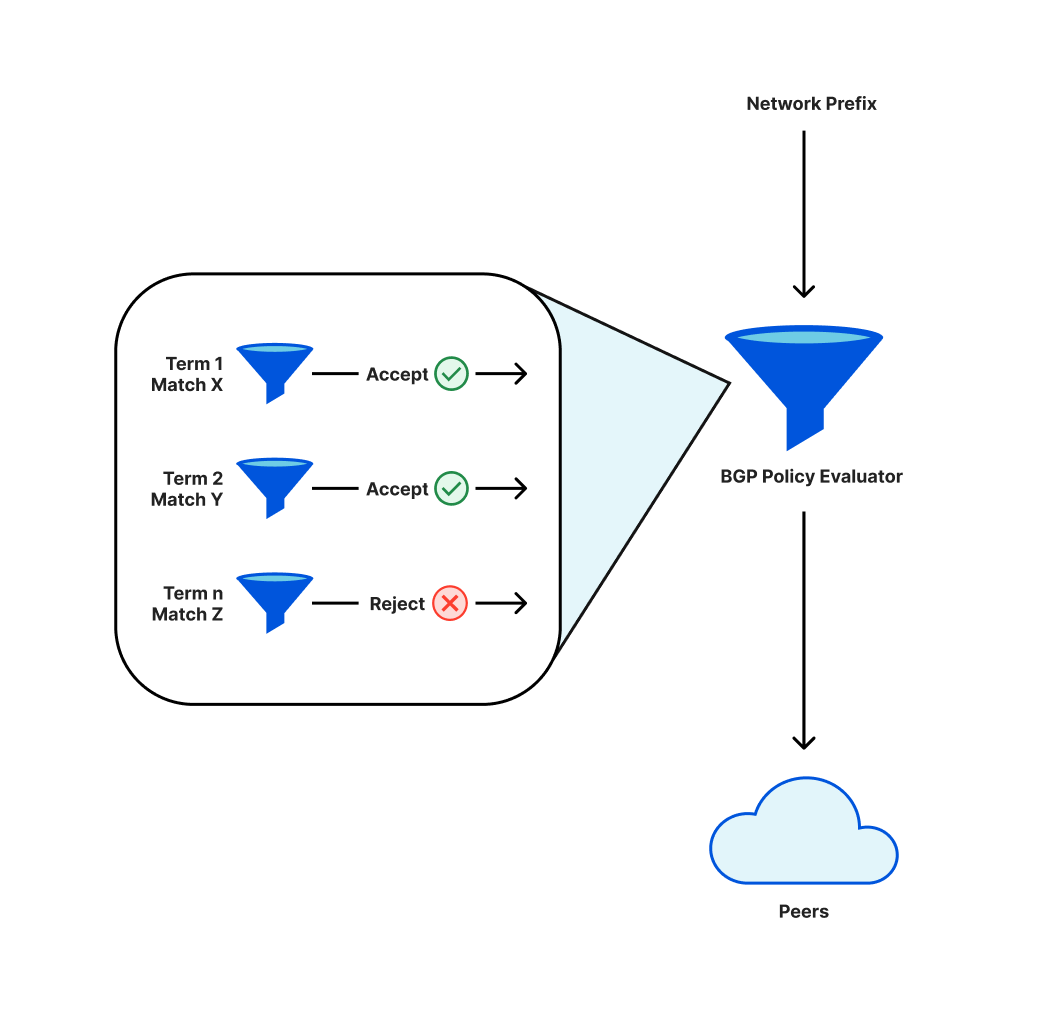
Bei der Einführung einer Änderung unserer Richtlinien für die Anzeige von Präfixen führte eine Neuordnung der Bedingungen dazu, dass wir eine kritische Teilmenge von Präfixen widerrufen mussten.
Aufgrund dieses Widerrufs hatten die Techniker von Cloudflare zusätzliche Schwierigkeiten, die betroffenen Standorte zu erreichen, um die problematische Änderung rückgängig zu machen. Wir haben Backup-Verfahren für den Umgang mit einem solchen Ereignis und nutzten sie, um die Kontrolle über die betroffenen Standorte zu übernehmen.
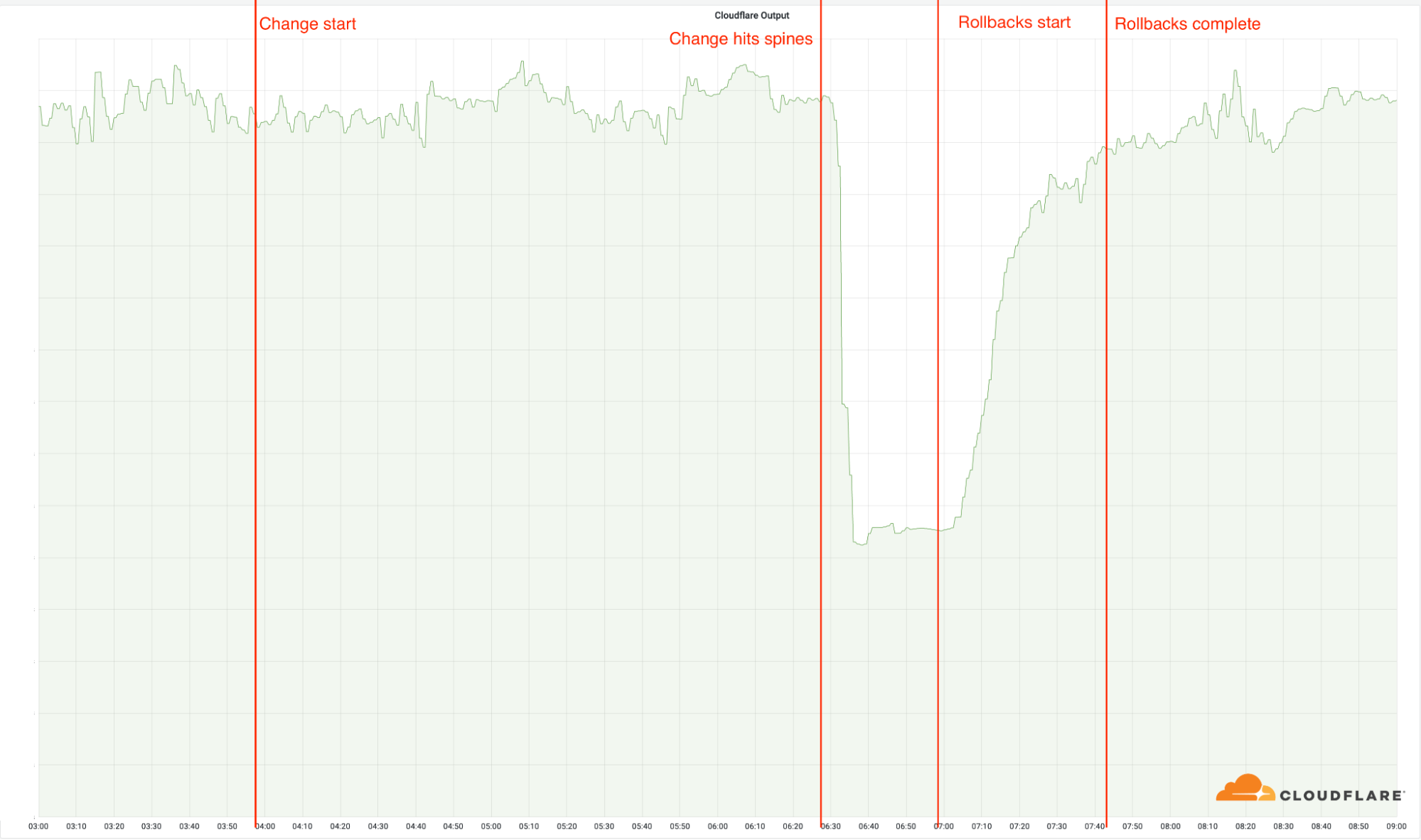
03:56: Wir setzen die Änderung an unserem ersten Standort um. Keiner unserer Standorte ist von der Änderung betroffen, da diese unsere ältere Architektur verwenden.
06:17: Die Änderung wird an unseren größten Standorten umgesetzt, aber nicht an den Standorten mit der neuen Architektur.
06:27: Der Rollout hat unsere größten Standorte mit der neuen Architektur erreicht, und die Änderung wird auf unseren Spines implementiert. Damit begann der Vorfall, denn diese 19 Standorte wurden schnell offline genommen.
06:32: Interner Cloudflare-Vorfall gemeldet.
06:51: Erste Änderung an einem Router, um eine mögliche Ursache zu verifizieren.
06:58: Grundursache gefunden und verstanden. Die Arbeiten beginnen, um die problematische Änderung rückgängig zu machen.
07:42: Die letzte Rückgängigmachung ist abgeschlossen. Dies verzögerte sich, da sich die Netzwerktechniker gegenseitig die Änderungen abnahmen und die vorherigen Änderungen rückgängig machten, wodurch das Problem sporadisch wieder auftrat.
09:00: Vorfall abgeschlossen.
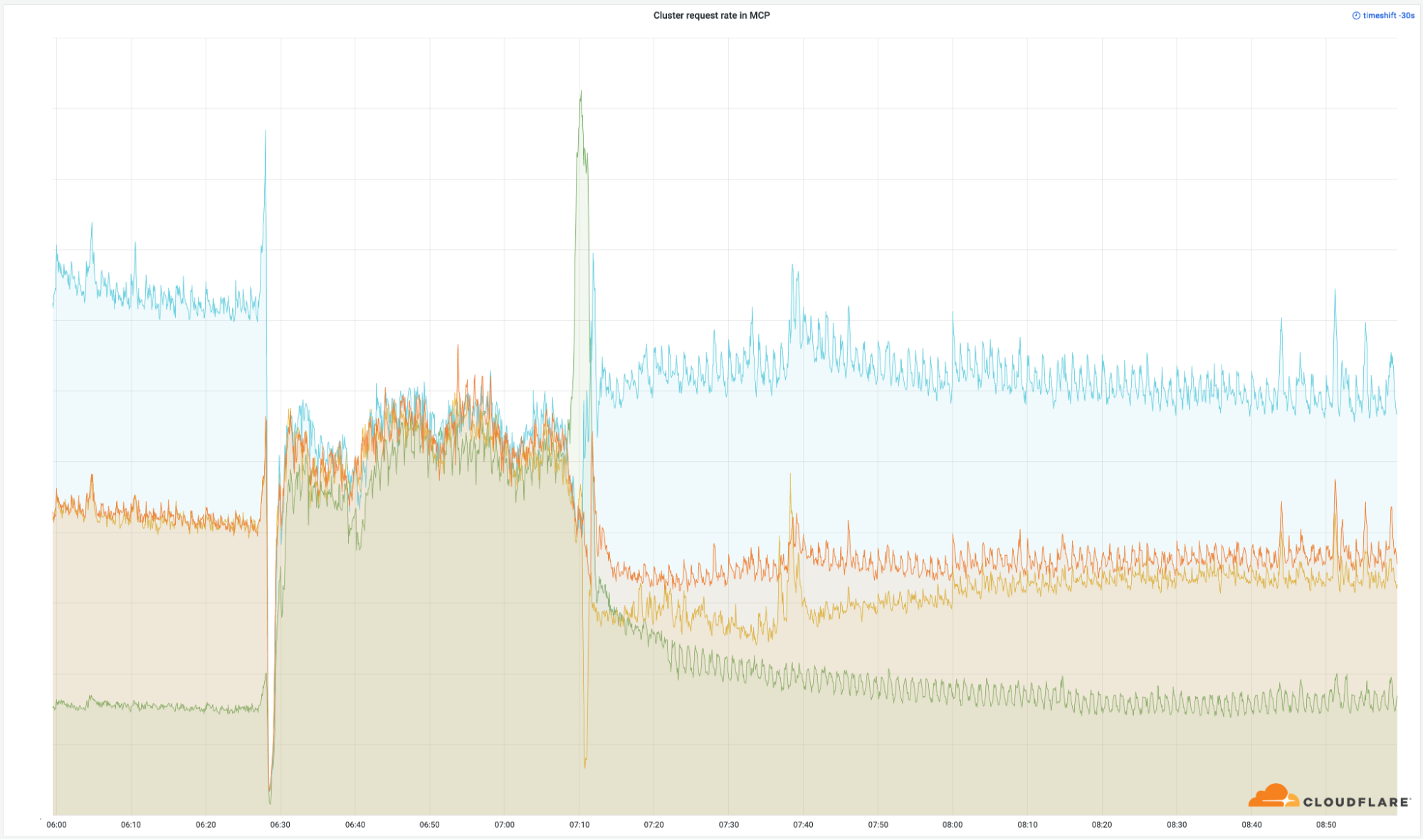
Wie wichtig diese Rechenzentren sind, zeigt sich deutlich an der Anzahl der erfolgreichen Anfragen, die wir weltweit zurückgeschickt haben:
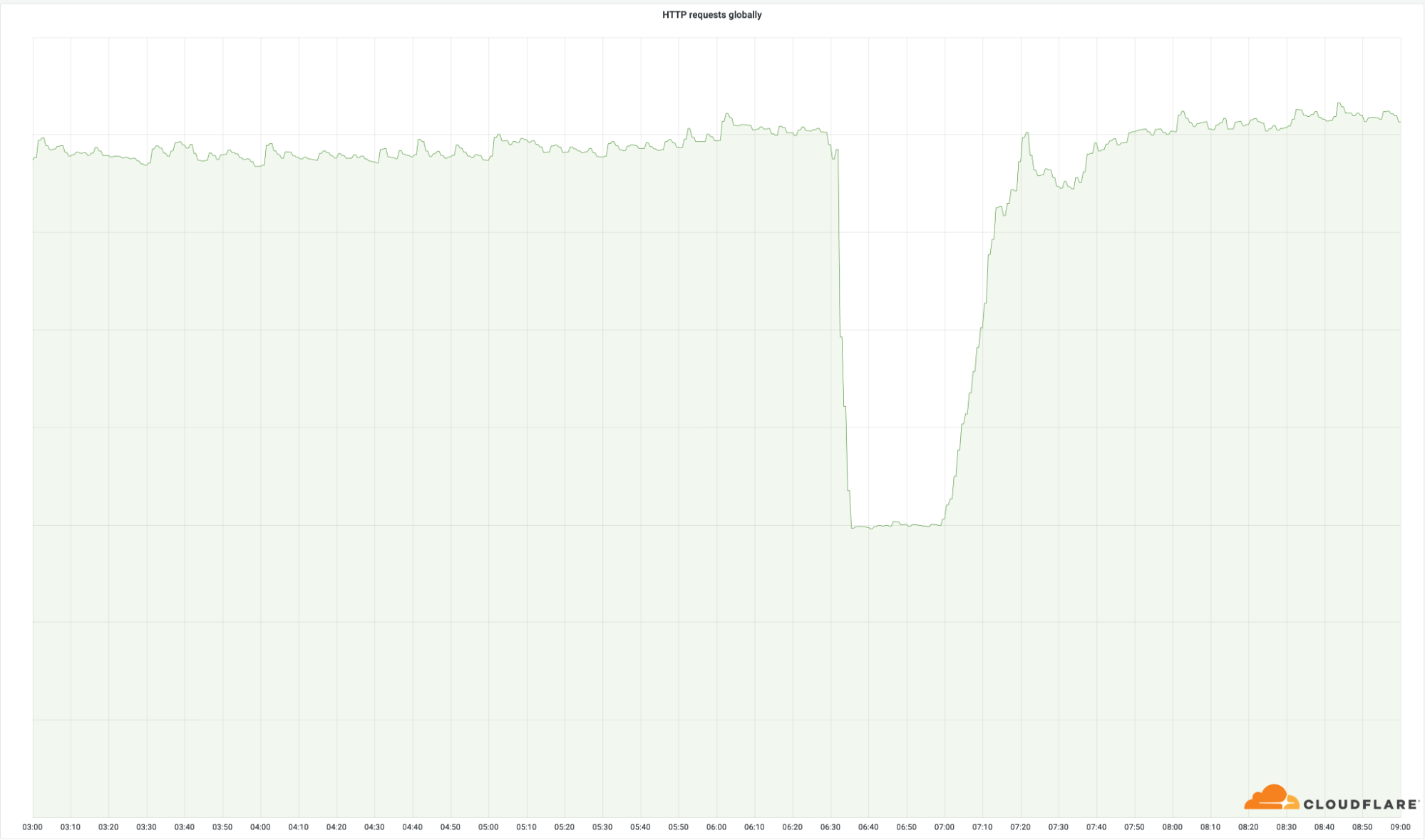
Obwohl diese Standorte nur einen kleinen Prozentsatz unseres gesamten Netzwerks ausmachen (4%), haben wir 50% unserer gesamten Anfragen bearbeitet. Das Gleiche gilt für unsere Egress-Bandbreite:
Technische Beschreibung des Fehlers und wie er passiert ist
Im Rahmen unserer laufenden Bemühungen, unsere Infrastrukturkonfiguration zu standardisieren, haben wir eine Änderung eingeführt, um die BGP-Communities zu standardisieren, die wir einer Untergruppe der von uns angekündigten Präfixe zuordnen. Genauer gesagt, haben wir unseren site-local-Präfixen Informations-Communities hinzugefügt. Diese Präfixe ermöglichen es unseren Rechenknoten, miteinander zu kommunizieren und eine Verbindung zu den Ursprüngen der Kunden herzustellen. Im Rahmen des Änderungsverfahrens bei Cloudflare wurde ein Change Request (CR)-Ticket erstellt, das einen Probelauf der Änderung sowie ein schrittweises Rollout-Verfahren beinhaltet. Bevor es veröffentlicht wurde, wurde es außerdem von mehreren Technikern begutachtet. Leider waren in diesem Fall die Schritte nicht klein genug, um den Fehler abzufangen, bevor er alle unsere Spines traf.
Auf einem der Router sah die Änderung folgendermaßen aus:
[edit policy-options policy-statement 4-COGENT-TRANSIT-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
[edit policy-options policy-statement 4-PUBLIC-PEER-ANYCAST-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
[edit policy-options policy-statement 6-COGENT-TRANSIT-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
[edit policy-options policy-statement 6-PUBLIC-PEER-ANYCAST-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
Dies war harmlos und fügte diesen Präfix-Ankündigungen lediglich einige zusätzliche Informationen hinzu. An den Spines wurden folgende Änderungen vorgenommen:
[edit policy-options policy-statement AGGREGATES-OUT]
term 6-DISABLED_PREFIXES { ... }
! term 6-ADV-TRAFFIC-PREDICTOR { ... }
! term 4-ADV-TRAFFIC-PREDICTOR { ... }
! term ADV-FREE { ... }
! term ADV-PRO { ... }
! term ADV-BIZ { ... }
! term ADV-ENT { ... }
! term ADV-DNS { ... }
! term REJECT-THE-REST { ... }
! term 4-ADV-SITE-LOCALS { ... }
! term 6-ADV-SITE-LOCALS { ... }
[edit policy-options policy-statement AGGREGATES-OUT term 4-ADV-SITE-LOCALS then]
community delete NO-EXPORT { ... }
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add AMS07;
+ community add EUROPE;
[edit policy-options policy-statement AGGREGATES-OUT term 6-ADV-SITE-LOCALS then]
community delete NO-EXPORT { ... }
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add AMS07;
+ community add EUROPE;
Ein erster Blick auf dieses diff könnte den Eindruck erwecken, dass diese Änderung identisch ist, aber das ist leider nicht der Fall. Wenn wir uns auf 1 Teil des diffs konzentrieren, wird vielleicht klar, warum:
! term REJECT-THE-REST { ... }
! term 4-ADV-SITE-LOCALS { ... }
! term 6-ADV-SITE-LOCALS { ... }
In diesem diff-Format zeigen die Ausrufezeichen vor den Begriffen eine Neuordnung der Begriffe an. In diesem Fall sind mehrere Begriffe nach oben gerückt und zwei Begriffe wurden nach unten hinzugefügt. Insbesondere wurde der Begriff 4-ADV-SITE-LOCALS von oben nach unten verschoben. Dieser Begriff stand nun hinter dem Begriff REJECT-THE-REST, und wie aus dem Namen ersichtlich sein dürfte, ist dieser Begriff ein explizites Reject:
term REJECT-THE-REST {
then reject;
}
Da dieser term nun vor den site-local-terms steht, haben wir sofort die Ankündigung für unsere site-local-Präfixe gestoppt. Dadurch wurde unser direkter Zugang zu allen betroffenen Standorten in kürzester Zeit entfernt und auch die Möglichkeit unserer Server, die Ursprungsserver zu erreichen.
Neben der Unfähigkeit, die Ursprungsserver zu kontaktieren, führte die Entfernung dieser site-local-Präfixe auch dazu, dass unser internes Load-Balancing-System Multimog (eine Variante unseres Unimog-Lastausgleichs) nicht mehr funktionierte, da es keine Anfragen mehr zwischen den Servern in unseren MCPs weiterleiten konnte. Das bedeutete, dass unsere kleineren Compute-Cluster in einem MCP die gleiche Menge an Traffic erhielten wie unsere größten Cluster, wodurch die kleineren Cluster überlastet wurden.
Abhilfe- und Folgemaßnahmen
Dieser Vorfall hatte weitreichende Auswirkungen, und wir nehmen die Verfügbarkeit sehr ernst. Wir haben mehrere Bereiche identifiziert, in denen Verbesserungen möglich sind, und werden weiter daran arbeiten, weitere Lücken aufzudecken, die einen erneutes Auftreten verursachen könnten.
An diesen Aspekten arbeiten wir sofort:
Prozess: Das MCP-Programm sollte zwar die Verfügbarkeit verbessern, aber eine Verfahrenslücke in der Art und Weise, wie wir diese Rechenzentren aktualisierten, hatte letztlich breitere Auswirkungen speziell auf die MCP-Standorte. Wir haben für diese Änderung zwar ein Stagger-Verfahren verwendet, aber die Stagger-Richtlinie umfasste erst im letzten Schritt ein MCP-Rechenzentrum. Änderungsverfahren und Automatisierung müssen MCP-spezifische Test- und Bereitstellungsverfahren beinhalten, um sicherzustellen, dass es keine unbeabsichtigten Folgen gibt.
Architektur: Die falsche Routerkonfiguration verhinderte, dass die richtigen Routen an unseren Edge bekannt gegeben wurden, wodurch der Datenverkehr nicht richtig zu unserer Infrastruktur fließen konnte. Letztendlich wird die Richtlinienanweisung, die die falsche Routing-Ankündigung verursacht hat, umgestaltet, um eine unbeabsichtigte falsche Sortierung zu verhindern.
Automatisierung: Es gibt mehrere Möglichkeiten in unserer Automatisierungssuite, die die Auswirkungen dieses Ereignisses ganz oder teilweise abmildern würden. In erster Linie werden wir uns auf Verbesserungen bei der Automatisierung konzentrieren, die eine bessere Staffelung der Rollouts von Netzwerkkonfigurationen und ein automatisches „Commit-Confirm“-Rollback ermöglichen. Die erste Verbesserung hätte die Gesamtauswirkungen deutlich verringert, und die zweite hätte die Time-to-Resolve (Lösungszeit) während des Vorfalls erheblich verkürzt.
Fazit
Obwohl Cloudflare erheblich in unser MCP-Design investiert hat, um die Serviceverfügbarkeit zu verbessern, sind wir mit diesem sehr schmerzhaften Vorfall eindeutig hinter den Erwartungen unserer Kunden zurückgeblieben. Wir bedauern die Unterbrechung für unsere Kunden und alle Nutzer, die während des Ausfalls nicht auf Internetangebote zugreifen konnten, sehr. Wir haben bereits mit der Arbeit an den oben beschriebenen Änderungen begonnen und werden uns weiterhin darum bemühen, dass sich so etwas nicht wiederholt.