



Heute ist die Workers-Plattform von Cloudflare der Ort, an dem über eine Million Entwickler anspruchsvolle Full-Stack-Anwendungen erschaffen, wie sie früher nicht möglich gewesen wären.
Natürlich war das nicht von Anfang an so. Alles begann an einem Tag wie diesem – mit einer Ankündigung während einer Birthday Week. Das Produkt umfasste auch noch nicht alle Funktionen, die es heute gibt. Doch wer Workers bei der Markteinführung ausprobieren konnte, der hatte das Gefühl, dass es sich um etwas anderes handelt, das die Dinge verändern wird. Plötzlich entstanden vollständig skalierbare, globale Anwendungen innerhalb von Sekunden und nicht erst nach Stunden, Tagen, Wochen oder gar Monaten. Es war der Beginn einer ganz neuen Art der Anwendungsentwicklung.
Wenn Sie in den letzten Monaten mit generativer KI experimentiert haben, hatten Sie vielleicht ein Déjà-vu. Als wir Leute aus unserem Freundes- und Kollegenkreis befragt haben, berichteten alle von verschiedenen „Aha“-Momenten. Und in der Branche ist man einhellig der Meinung, dass auch diese Technologie etwas anderes ist, das die Dinge verändern wird.
Wir möchten heute eine Reihe von neuen Produkten präsentieren und glauben, dass diesen eine ähnliche Bedeutung zukommen wird wie Workers damals für die Zukunft der Datenverarbeitung. Dabei handelt es sich um:
- Workers AI (früher bekannt als Constellation) läuft auf NVIDIA-Prozessoren im globalen Netzwerk von Cloudflare und überträgt das Serverless-Modell auf KI: Sie zahlen nur für das, was Sie nutzen, und verlieren weniger Zeit mit der Infrastruktur, sodass Sie sich stattdessen länger mit Ihren Anwendungen beschäftigen können.
- Unsere Vektordatenbank Vectorize erlaubt eine unkomplizierte, schnelle und erschwingliche Verktor-Indexierung und -Speicherung. Damit können Sie Anwendungsfälle unterstützen, die nicht nur Zugriff auf laufende Modelle, sondern auch auf benutzerdefinierte Daten erfordern.
- AI Gateway gibt Unternehmen die Möglichkeit, ihre KI-Implementierungen unabhängig von ihrem Ausführungsort zwischenzuspeichern, zu überwachen und eine Durchsatzbegrenzung für sie festzulegen.
Das ist aber lange noch nicht alles.
Die Umsetzung großer Projekte ist ein Mannschaftssport und wir wollen nicht alles im Alleingang erledigen. Wie bei so vielen Projekten stehen wir auch hier auf den Schultern von Riesen. Wir freuen uns darüber, mit einigen der größten Akteure in diesem Bereich zusammenarbeiten zu können: NVIDIA, Microsoft, Hugging Face und Meta.
Unsere heutigen Ankündigungen sind nur der Anfang der Entwicklung von Cloudflare auf dem Gebiet der künstlichen Intelligenz, ähnlich wie wir vor sechs Jahren mit Workers neue Wege beschritten haben. Wir möchten Sie einladen, sich mit jeder unserer heutigen Produktpräsentationen zu beschäftigen (Sie werden nicht enttäuscht sein!), aber wir möchten bei dieser Gelegenheit auch einen Schritt zurücktreten, Ihnen unsere allgemeinere Vision im Hinblick auf KI vorstellen und die heutigen Ankündigungen einordnen.
Inferenz: Die Zukunft der KI-Workloads
KI beinhaltet zwei Hauptprozesse: Training und Inferenz.
Das Training einer generativen KI ist ein langwieriger (manchmal monatelanger) rechenintensiver Prozess, aus dem schließlich ein Modell hervorgeht. Training-Workloads lassen sich daher am besten bei traditionellen, zentralisierten Cloud-Standorten ausführen. Seit einiger Zeit haben Unternehmen Schwierigkeiten, sich längerfristigen Zugang zu Prozessoren zu verschaffen. Das hat zu Multi-Cloud-Konstellationen geführt. In diesem Zusammenhang haben wir darüber gesprochen, dass R2 für den Zugriff auf Trainingsdaten von jeder zu ihrer Verarbeitung genutzten Cloud einen wichtigen Dienst bieten kann: die Beseitigung von Gebühren für ausgehenden Traffic. Heute soll es aber um etwas anderes gehen.
Das Training der KI erfordert von vornherein viele Ressourcen. Doch weitaus häufiger wird im Zusammenhang mit KI Rechenleistung für Inferenz benötigt. Wenn Sie ChatGPT in letzter Zeit eine Frage gestellt oder mit dem Tool ein Bild generiert oder einen Text übersetzt haben, dann haben Sie eine Inferenzaufgabe durchgeführt. Weil Inferenz bei jedem einzelnen Aufruf erforderlich ist (und zwar mehr als einmal), gehen wir davon aus, dass sie sich zum dominierenden Workload im Zusammenhang mit KI entwickeln wird.
Wenn für das Training eine zentral organisierte Cloud am besten geeignet ist, was ist dann der beste Ort für Inferenz?
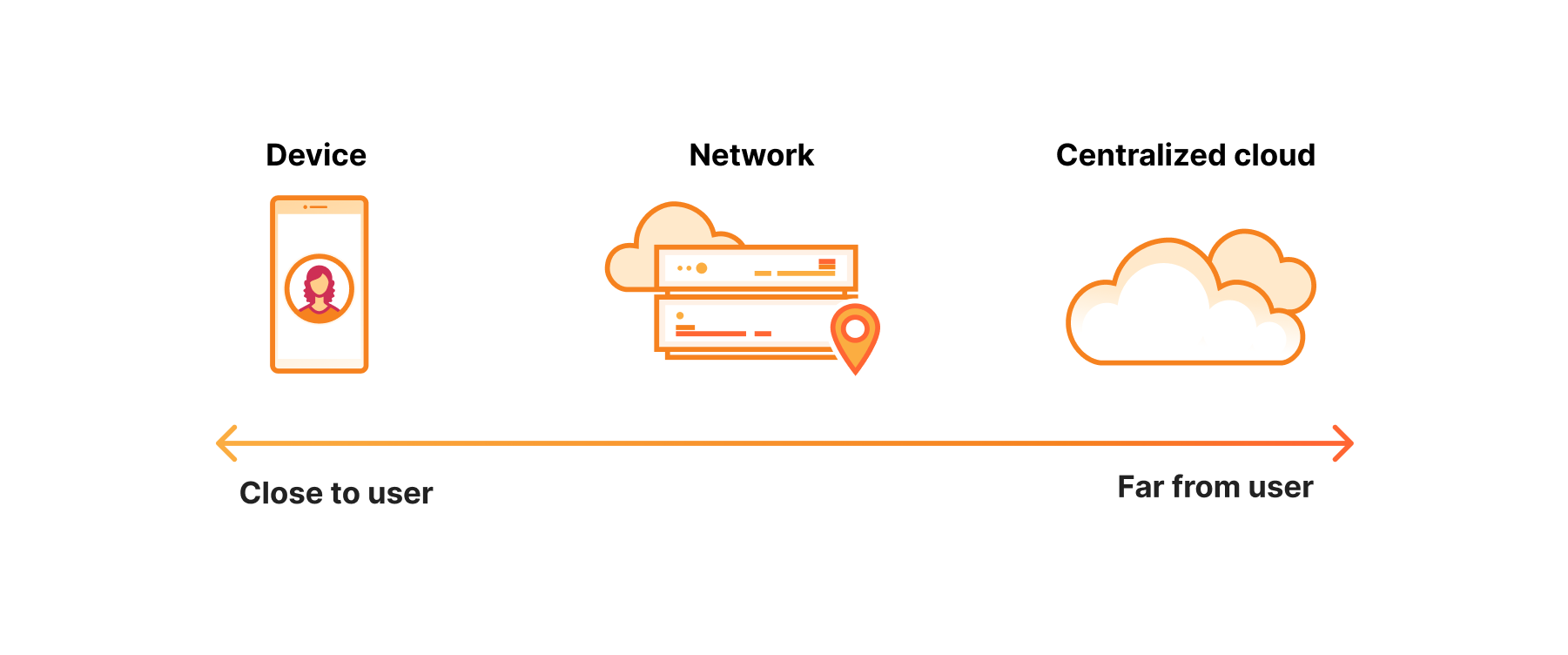
Das Netzwerk – „genau richtig“ für Inferenz
Das bestimmende Merkmal der Inferenz ist, dass am anderen Ende meist Nutzer warten. Es handelt sich also um eine Aufgabe, bei der Latenz eine Rolle spielt.
Man könnte meinen, der beste Ort für eine Aufgabe, bei der die Latenz relevant ist, sei das Gerät. Das mag in einigen Fällen auch zutreffen, aber dabei bestehen einige Probleme. Erstens ist die Hardware von Geräten nicht annähernd so leistungsfähig. Zweitens ist die Lebensdauer des Akkus beschränkt.
Auf der anderen Seite steht das zentralisierte Cloud-Computing. Im Gegensatz zu Endgeräten kann die Hardware, die an zentralisierten Cloud-Standorten betrieben wird, jede Menge Rechenleistung bieten. Das Problem ist natürlich, dass sie Hunderte von Millisekunden von den Nutzern entfernt ist. Und manchmal befindet sie sich sogar jenseits der Landesgrenzen, was ganz eigene Herausforderungen mit sich bringt.
Die Geräte sind also noch nicht leistungsfähig genug, und die zentralisierte Cloud ist zu weit entfernt. Das macht das Netzwerk zum idealen Ort für Inferenz: Nicht zu weit entfernt, mit ausreichender Rechenleistung – also genau richtig.
Die erste Inferenz-Cloud, die überall zu Hause ist
Eines haben wir beim Aufbau unserer Entwicklungsplattform gelernt: Die Ausführung von Anwendungen im Netzwerkmaßstab trägt zur Optimierung der Performance und Skalierung bei (was natürlich ein erfreulicher Vorteil ist). Noch wichtiger ist aber, dass sie die richtige Abstraktionsebene für eine schnelles Vorankommen von Entwicklungsteams schafft.
Workers AI für Serverless-Inferenz
Mit der Einführung von Workers AI bringen wir die erste echte Serverless-GPU-Cloud auf den Markt. Sie brauchen dafür weder Fachwissen über maschinelles Lernen, noch müssen Sie nach Prozessoren suchen. Wählen Sie einfach eines der von uns bereitgestellten Modelle und legen Sie los.
Wir haben uns bei der Entwicklung von Workers AI viele Gedanken gemacht, um die Bereitstellung eines Modells so reibungslos wie möglich zu gestalten.
Und wenn Sie 2023 Modelle implementieren, ist die Wahrscheinlichkeit hoch, dass ein LLM dabei ist.
Vectorize zum Speichern von Vektoren
Um einen Ende-zu-Ende-KI-gesteuerten Chatbot zu entwickeln, müssen Sie den Nutzern auch eine Benutzeroberfläche präsentieren. Darüber hinaus müssen Sie den Informationskorpus, den Sie ihnen übermitteln wollen (z. B. Ihren Produktkatalog), parsen. Sie müssen außerdem das Modell verwenden, um die Informationen in Einbettungen umzuwandeln – die wiederum irgendwo gespeichert werden müssen. Bislang haben wir die Produkte für die ersten beiden Aufgaben angeboten, aber für die letzte Aufgabe – das Speichern von Einbettungen – wird eine spezielle Lösung benötigt: eine Vektordatenbank.
Kurz nach der Vorstellung von Workers haben wir seinerzeit Workers KV präsentiert, denn ohne Datensätze lässt sich mit Rechenleistung wenig anstellen. Dasselbe gilt für KI: Um sinnvolle KI-Anwendungsfälle zu entwickeln, müssen Sie der KI Zugriff auf Datensätze geben. Hier kommt eine Vektordatenbank ins Spiel: Wir freuen uns, heute auch unsere eigene Vektordatenbank Vectorize vorstellen zu können.
AI Gateway: Caching, Durchsatzbegrenzung und ein besserer Überblick über Ihre KI-Implementierungen
Wenn wir bei Cloudflare etwas verbessern wollen, besteht der erste Schritt immer aus einer Messung. Denn wie soll man etwas verbessern, wenn man es nicht messen kann? Als wir uns Kunden von Problemen bei der Begrenzung der KI-Implementierungskosten berichteten, haben wir überlegt, wie wir vorgehen würden: erst messen, dann verbessern.
Mit AI Gateway gelingt Ihnen beides!
Echtzeit-Beobachtungsfunktionen ermöglichen ein proaktives Management, das die Überwachung, Fehlersuche und Feinjustierung von KI-Implementierungen erleichtert. AI Gateway ist für das Caching, die Durchsatzbegrenzung und die Überwachung von KI-Implementierungen unerlässlich, um die Performance zu optimieren und effektives Kostenmanagement zu betreiben. Durch das Zwischenspeichern häufig genutzter KI-Antworten wird die Latenz reduziert und die Zuverlässigkeit des Systems erhöht. Die Durchsatzbegrenzung sorgt für eine effiziente Ressourcenzuweisung und bekämpft die Kostenspirale im Zusammenhang mit KI.
Zusammenarbeit mit Meta zur Einbindung von Llama 2 in unser globales Netzwerk
Wer auf ein LLM zugreifen wollte, konnte dies bis vor kurzem nur durch Aufrufe, die an firmeneigene Modelle gerichtet waren. Das Trainieren von LLMs bedeutet eine erhebliche Investition in Zeit, Rechenleistung und finanzielle Ressourcen. Den meisten Entwicklern steht all dies nicht zur Verfügung. Mit der Veröffentlichung des quelloffenen LLM Llama 2 hat Meta einen spannenden Wandel eingeleitet, der es der Entwickler-Community ermöglicht, ihre eigenen LLMs zu betreiben. Einen kleinen Haken gibt es aber natürlich: Sie brauchen dazu immer noch Zugang zu einem Prozessor.
Wir stellen Llama 2 als Teil des Workers AI-Katalogs zur Verfügung und freuen uns darauf, jedem Entwickler Zugang zu einem LLM zu ermöglichen, ganz ohne Konfiguration.
Ein laufendes Modell ist natürlich nur eine Komponente einer KI-Anwendung.
Reibungsloser Wechsel zwischen Cloud, Edge und Gerät mit ONNX Runtime
Die Edge mag der optimale Ort für die Lösung vieler dieser Probleme sein, doch wir gehen davon aus, dass Anwendungen auch weiterhin an anderen Orten irgendwo in dem aus Gerät, Edge und zentralisierter Cloud bestehenden Spektrum bereitgestellt werden.
Denken Sie beispielsweise an selbstfahrende Autos: Wenn es bei Entscheidungen auf jede Millisekunde ankommt, müssen diese auf dem Gerät getroffen werden. Wenn Sie dagegen Modelle mit Hunderten Milliarden von Parametern ausführen wollen, ist die zentralisierte Cloud besser für Ihren Workload geeignet.
Die Frage ist also: Wie können Sie reibungslos zwischen diesen Orten navigieren?
Seit unserer ersten Version von Constellation (jetzt Workers AI) waren wir von einer Technologie besonders begeistert: ONNX Runtime. ONNX Runtime schafft eine standardisierte Umgebung für die Ausführung von Modellen, wodurch es möglich ist, verschiedene Modelle an unterschiedlichen Orten auszuführen.
Wir haben bereits darüber gesprochen, dass die Edge ein großartiger Ort für die Ausführung von Inferenzen selbst ist. Sie eignet sich aber auch hervorragend als Routing-Ebene, um Workloads reibungslos über alle drei Standorte zu leiten, je nach Anwendungsfall und Optimierungszielen – sei es Latenz, Präzision, Kosten, Compliance oder Datenschutz.
Partnerschaft mit Hugging Face zur Bereitstellung optimierter Modelle auf Knopfdruck
Nichts kann Entwicklungsteams schneller voranbringen, als sie dort abzuholen, wo sie sind. Deshalb gehen wir eine Partnerschaft mit Hugging Face ein, um Serverless-Inferenz auf verfügbare Modelle zu bringen, also genau dorthin, wo Entwickler damit experimentieren.
Partnerschaft mit Databricks zur Erstellung von KI-Modellen
Gemeinsam mit Databricks werden wir die Leistungsfähigkeit von MLflow für Data Scientists und die Entwickler-Community nutzbar machen. MLflow ist eine Open-Source-Plattform für die Verwaltung des gesamten Lebenszyklus des maschinellen Lernens. Diese Partnerschaft wird es Nutzern erleichtern, ML-Modelle in großem Umfang bereitzustellen und zu verwalten. Dank dieser Partnerschaft können Entwicklungsteams, die auf Cloudflare Workers AI arbeiten, MLFlow-kompatible Modelle für eine einfache Bereitstellung im globalen Netzwerk von Cloudflare nutzen. Sie können MLflow verwenden, um ein Modell effizient zu bündeln, zu implementieren, bereitzustellen und direkt in der Serverless-Entwicklungsplattform von Cloudflare zu überwachen.
KI, die Ihren CIO, CFO oder Rechtsabteilungen keine schlaflosen Nächte bereitet
Die Entwicklung im Bereich der KI schreitet schnell voran, und es ist wichtig, Entwicklern die nötigen Tools für ihre Arbeit an die Hand zu geben. Doch schnelle Fortschritte lassen sich nur schwer erzielen, wenn wichtige Überlegungen den Teams Sorgen bereiten: Was ist mit Compliance, Kosten, Datenschutz?
Compliance-freundliche KI
Auch wenn die meisten von uns die Tatsache lieber verdrängen würden, erlassen Regierungen immer mehr Vorschriften für KI und Datenresidenz. Wenn Regierungen verlangen, dass Daten lokal verarbeitet oder die Daten ihrer Bürger im Land gespeichert werden, müssen Unternehmen auch darüber nachdenken, wo Inferenz-Workloads ausgeführt werden. Wenn es um die Latenz geht, bietet die Netzwerk-Edge die Möglichkeit, so stark wie möglich in die Breite zu gehen. Was Compliance betrifft, liegt die Stärke eines Netzwerks, das sich über 300 Städte erstreckt, und eines Angebots wie unserer Datenlokalisierungs-Suite darin, dass es die nötige Granularität ermöglicht, um KI-Implementierungen lokal zu begrenzen.
Budgetfreundliche KI
In Gesprächen mit vielen Leuten aus unserem Freundes- und Kollegenkreis, die mit KI experimentieren, scheint stets ein Gefühl mitzuschwingen: KI ist teuer. Die Kosten können leicht aus dem Ruder laufen, bevor überhaupt etwas in Produktion geht oder ein Nutzen daraus gezogen wird. Mit unserer KI-Plattform wollen wir dafür sorgen, dass sich die Kosten in Grenzen halten. Was aber vielleicht noch wichtiger ist: Wir wollen Ihnen nur das berechnen, was Sie auch wirklich nutzen. Unabhängig davon, ob Sie Workers AI direkt oder AI Gateway verwenden, möchten wir Ihnen die nötige Transparenz und die Tools zur Verfügung stellen, damit Ihre Kosten für KI nicht aus dem Ruder laufen.
Datenschutzfreundliche KI
Wenn Sie KI in den Mittelpunkt Ihres Kundenerlebnisses und Ihrer Geschäftsabläufe stellen, möchten Sie sicher sein, dass alle von ihr genutzten Daten auch sicher sind. Bei Cloudflare hat Datenschutz schon immer an erster Stelle gestanden, und das ist auch heute noch so. Wir können unseren Kunden versichern, dass wir keine ihrer Daten, die über Cloudflare laufen, für Inferenzen zum Trainieren von Large Language Models verwenden.
Ganz im Ernst: Wir fangen gerade erst an
Wir fangen gerade erst mit KI an, und es wird auf jeden Fall noch sehr aufregend werden. Während wir die Vorteile dieser Technologie weiter erschließen, können wir nicht anders, als ein Gefühl der Ehrfurcht und des Staunens über die unendlichen Möglichkeiten zu empfinden, die vor uns liegen. Von der Revolutionierung des Gesundheitswesens bis zur Veränderung unserer Arbeitsweise – KI steht kurz davor, das Spiel auf Weisen zu verändern, die wir nie für möglich gehalten hätten. Also halten Sie sich fest, denn die Zukunft der KI sieht heller aus denn je – und wir können es kaum erwarten, zu sehen, was als Nächstes kommt!
Dieser Schlussteil stammt zwar von einer KI, aber das Gefühl ist echt: Wir stehen tatsächlich erst am Anfang, und wir können es kaum erwarten, die Früchte Ihrer Arbeit zu sehen.