

我们开门见山吧,Alpha 版用户 (包括任何 Workers 用户) 可以通过以下命令立即使用全新存储后端创建新数据库:
$ wrangler d1 create your-database --experimental-backend
在接下来的几周内,它将成为每个人的默认体验,但我们希望邀请开发人员立即开始尝试新版本的 D1。我们也将进一步分享如何构建 D1 新存储子系统以及它如何从 Cloudflare 的分布式网络中受益。。
提醒我一下:什么是 D1?
D1 是 Cloudflare 的原生无服务器数据库,在去年 11 月 发布 Alpha 版。开发人员一直在使用 Workers、KV、Durable Objects 等构建复杂的应用程序,但是他们一致要求我们做一件事情:一个可以查询的数据库。
我们还收到一致的反馈:这个数据库应该基于 SQL,自动缩放,并且(和 Workers 本身一样),采用全球(“Region: Earth”)复制方式。因此,我们接受了这些反馈并开始构建 D1,SQLite 为我们提供了一种熟悉的 SQL 方言、强大的查询引擎和经过最充分实战考验的代码库之一。
我们将 D1 的第一个版本以“真正的” alpha 版发布:这是我们公开开发的一种方式,可以直接从开发人员那里收集反馈,并更好地优先考虑重要的事情。名副其实,这个 alpha 版存在 bug 和性能问题,而且“理想路径”相当狭窄。
尽管如此,我们已经看到开发人员启动了数千个数据库,进行了数十亿次查询,流行的 ORM(例如 Drizzle 和 Kysely)增加对 D1 的支持(已经!),且 Remix 和 Nuxt 模板直接围绕它构建。
不断完善
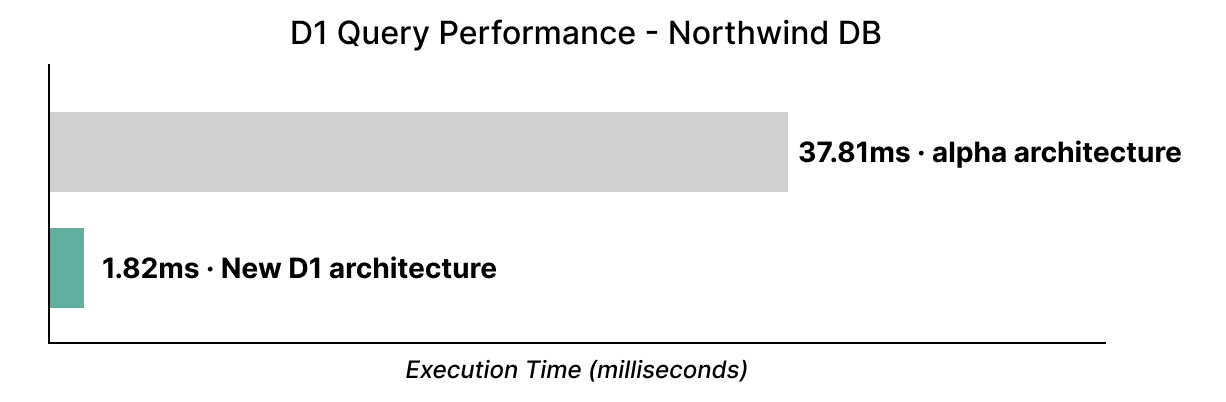
如果您使用了迄今为止的 alpha 版 D1:请忘记您所知道的一切。D1 现已显著提速,我们刚将著名的 Northwind Traders 演示数据库 迁移到使用我们的全新存储后端,速度提高了 20 倍:
我们的新架构还提高了写入性能:一个插入 1000 行(每行约 200 字节宽)的简单基准测试比先前版本的 D1 快大约 6.8 倍。
更大的批次(每批 1 万行,每行约 200 字节宽)看到更大的改进:达到 10-11 倍,而且新存储后端的延迟也明显更加一致。我们还没有开始优化总体写吞吐量,因此 D1 只会变得更快。
通过我们的新存储后端,我们还要证明 D1 不是一个玩具,我们不断将其性能与其他无服务器数据库进行基准测试。对一个 50 万行的键值对表进行查询(认识到基准测试本质上是合成的),D1 的性能比流行的无服务器数据库 Postgres 快大约 3.2 倍:
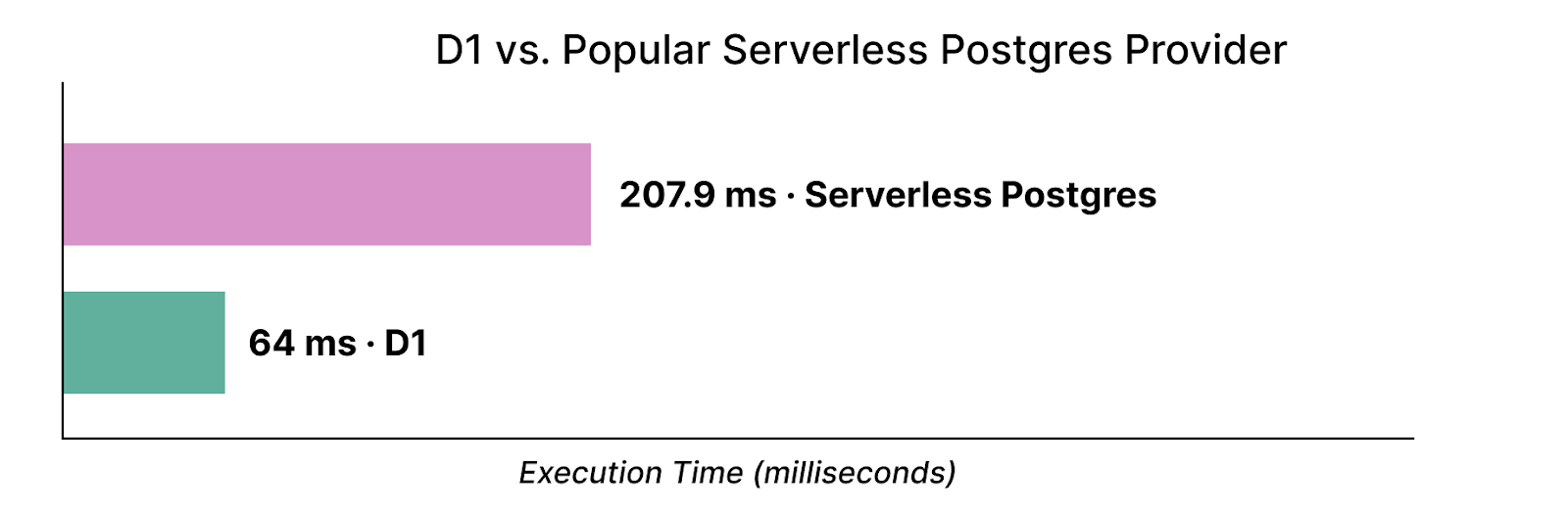
我们运行了多次 Postgres 查询来预热页面缓存,然后采用服务器测量的中位数查询时间。后续开发中,我们将继续提高性能优势。
已有数据库的开发人员可以按照文档中的步骤将数据导入到由该存储引擎支持的新数据库中,方法是先将数据库导出,然后将其导入。
我错过了什么?
我们还一直在努力改进 D1 的开发人员体验:
- 新增控制台界面,可直接从仪表板发出查询,更易开始使用和/或发出一次性查询。
- 正式支持 JSON 函数,通过 JSON 在数据库中直接查询。
- Location Hints,允许影响 leader(负责写入)在全球范围内的位置。
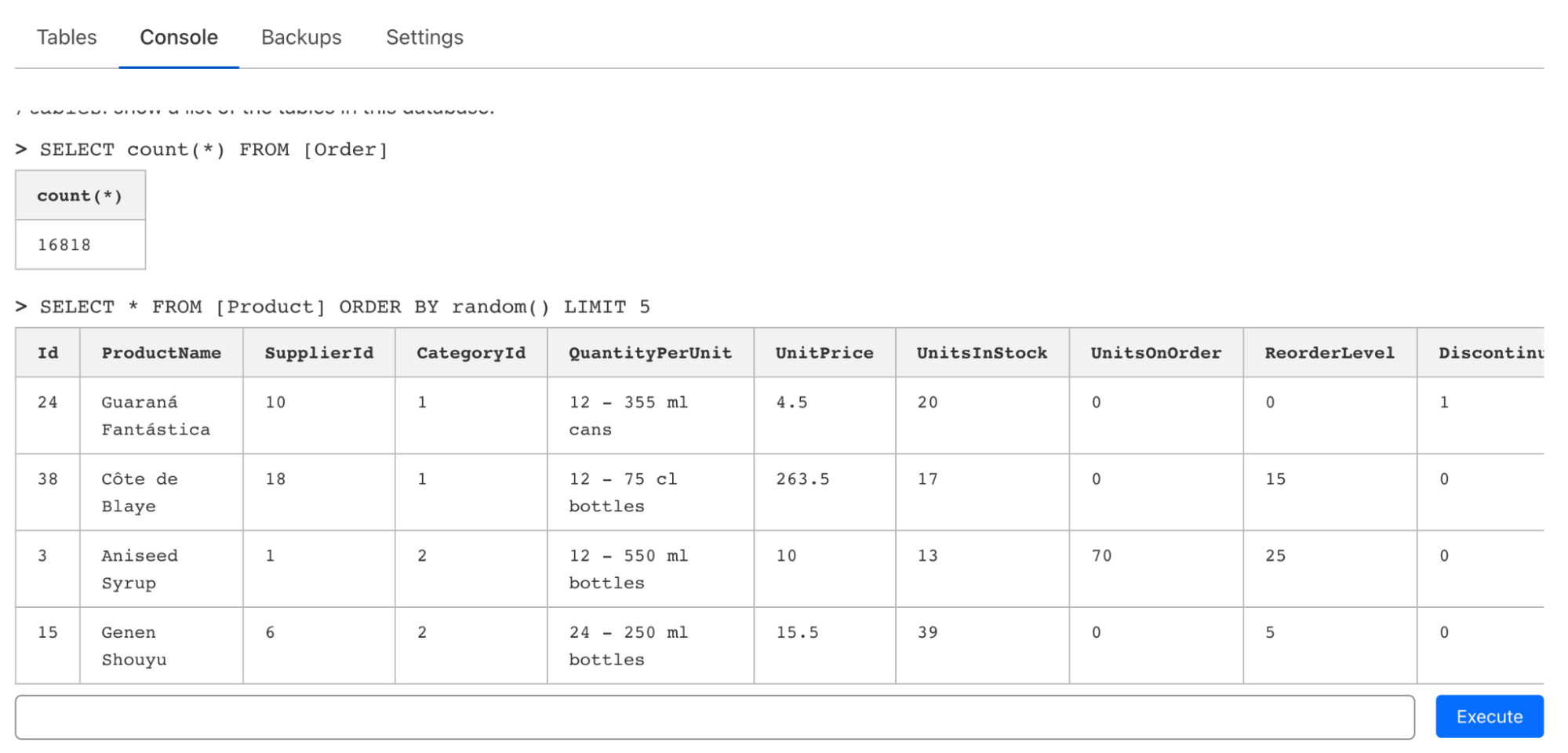
尽管 D1 是专为在 Cloudflare Workers 内原生运行而设计的,但我们意识到,在进行原型设计或仅探索一个数据库时,通常需要快速通过 CLI 或 Web 编辑器发出一次性查询。除了支持在 wrangler 内支持执行查询 (和文件)外,我们还引入了控制台编辑器,用于发出查询、检查表格,甚至可以实时编辑数据:
JSON 函数让您可以查询 D1 数据库 TEXT 列存储的 JSON:这使您可以灵活地确定哪些数据与您的关系数据库模式严格相关,哪些不相关,同时仍然能够通过 SQL 查询所有数据(在数据到达您的应用程序之前)。
例如,假设您将最后登录时间戳以 JSON 数组格式存储在 login_history TEXT 列:我可以通过提供到其键的路径直接查询(和提取)子对象或数组项:
SELECT user_id, json_extract(login_history, '$.[0]') as latest_login FROM users
D1 对 JSON 函数的支持非常灵活,并利用了构建 D1 的 SQLite 核心。
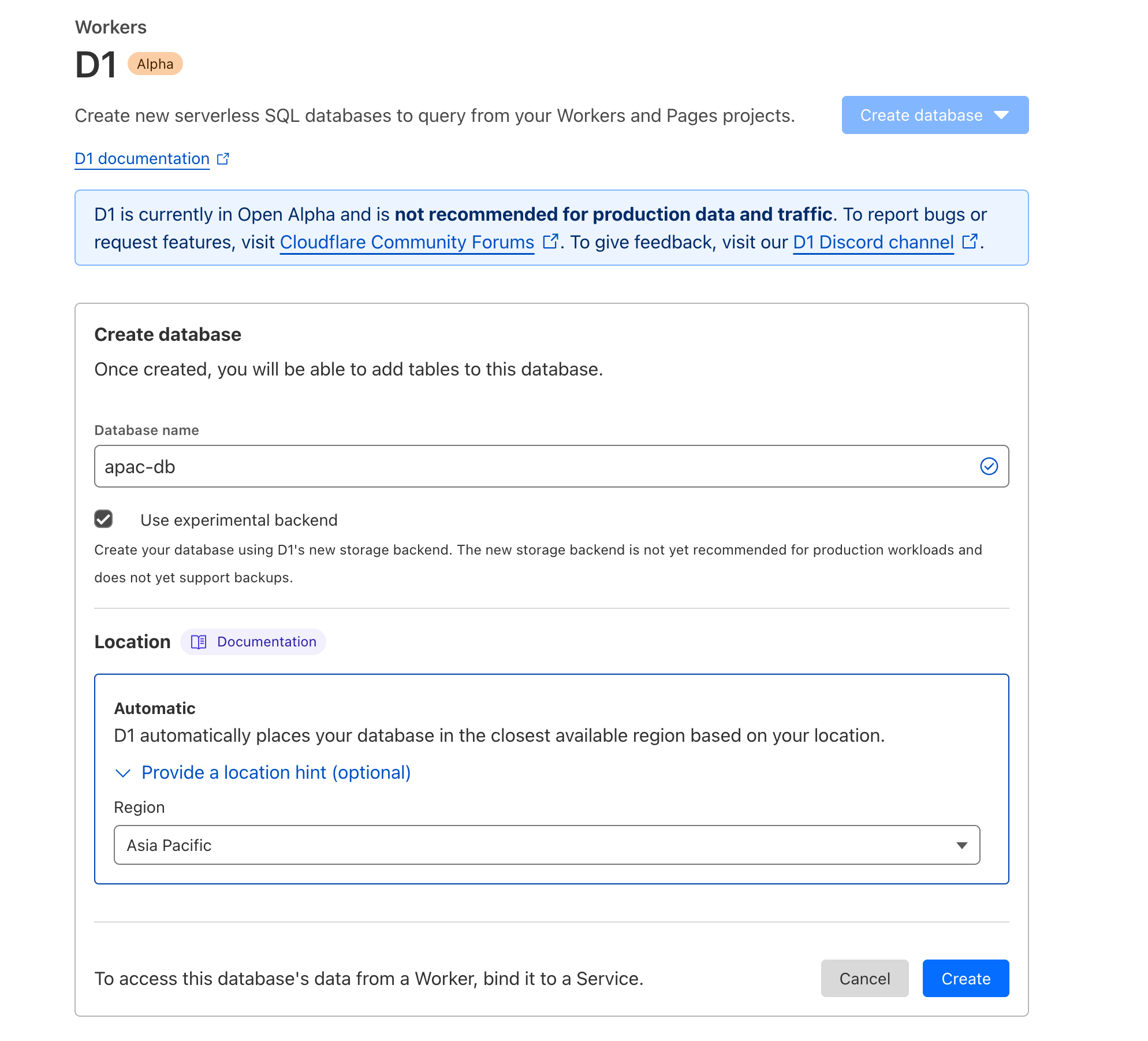
当您首次使用 D1 创建数据库时,我们会根据您当前连接的位置自动推断位置。然而,某些情况下,您可能希望影响数据库的位置 —— 也许您正在旅行,或者您的分布式团队不同于您预期大多数写入来自的地区。
D1 对 Location Hints 的支持
# Automatically inferred based your location
$ wrangler d1 create user-prod-db --experimental-backend
# Indicate a preferred location to create your database
$ wrangler d1 create eu-users-db --location=weur --experimental-backend
Location Hints 也可通过 Cloudflare 仪表板使用:
我们还发布了更多文档,不仅能帮助开发人员入门, 还能利用 D1 的高级特性。未来几个月内,预计 D1 的文档将继续大幅增加。
定价不会过高
自从宣布 alpha 版以来,已经有许多开发人员问到 D1 价格的问题,现在我们准备介绍一下定价。我们知道,在开始使用某个产品进行构建之前了解其定价很重要,这样您就不会在 6 个月后感到吃惊了。
简而言之:
- 我们准备宣布定价,以便您可以提前预估 D1 将为您的用例带来多少成本。最终定价可能会有所变化,尽管我们预计变化幅度会比较小。
- 我们将在今年晚些时候才开始计费,而且我们将提前通过电子邮件通知现有客户。在那之前,D1 将依然免费使用。
- D1 将包括一个永远免费的级别,包括作为 5 美元/月 Workers 订阅的一部分使用,并根据读、写和存储量收费。
如果您已经订阅了 Workers,那么您不会受到任何影响:在我们未来启用计费时,您的现有订阅将包括 D1 使用。
总结如下 (我们刻意使其简单明了):

重要的是, 当我们启用全球读取复制时,您将不需要支付额外费用,复制也不会使您的您的存储消耗倍增。我们认为内置、自动的复制很重要,并不认为开发人员应该支付倍乘费用 (副本 x 存储费),以便使其数据库在每一个地方都能快速运行。
除此之外,我们希望确保 D1 具有无服务器产品定价的优点 —— 可以根据需求进行自动缩放和按使用量付费,这样您就不需要尝试确定工作负载所需的 CPU 和/或内存数量,也不需要编写脚本在负载较低的时间段缩小基础架构规模。
D1 的读取定价基于“读取单位”(每 4KB 读取)和“写入单位”(每 1KB 写入)的熟悉概念。查询(扫描)大约 10000 行,每行 64个字节,将消耗 160 个读取单位。在“blog_posts” 表中写入一个大的 3KB 行,其中包含大量 Markdown,这将消耗 3 个写入单位。如果您如果您为最常用的查询创建索引以提高性能并减少这些查询需要扫描的数据量,您还将减少我们对您的计费。我们认为通过默认使快速路径更具成本效益是正确的方法。
重要的是:在开始收费前,我们将继续接受有关定价的反馈。
Time Travel
我们还引入了新的备份功能:时间点恢复,并将其称为“Time Travel(时间旅行)”,因为这就是它给人的感觉。 Time Travel 允许您将 D1 数据库恢复到过去 30 天内的任何一分钟,并且将内置于使用我们新存储系统的 D1 数据库中。我们预计在不久的将来为新的 D1 数据库开启 Time Travel 功能。
使 Time Travel 真正强大的地方在于,您不再需要惊慌地想 “噢,等等,我在做这个重大更改之前是否备份了数据库?” —— 因为我们已经为您做了这件事。我们保留了对您的数据库所有更改的流 ( Write-Ahead Log),允许我们通过按顺序重放这些更改,从而将您的数据库恢复到某个时间点。
这里是一个示例(API 可能会有一些小的变化):
# Using a precise Unix timestamp (in UTC):
$ wrangler d1 time-travel my-database --before-timestamp=1683570504
# Alternatively, restore prior to a specific transaction ID:
$ wrangler d1 time-travel my-database --before-tx-id=01H0FM2XHKACETEFQK2P5T6BWD
尽管时间点恢复并非新的想法,但它通常是一个付费的附加功能,甚至根本不提供。在进行了删除或犯了错误之后才意识到应该打开它,通常为时已晚。
例如,想象一下我犯了这个经典错误:在一条 UPDATE 语句中忘记了 WHERE:
-- Don't do this at home
UPDATE users SET email = '[email protected]' -- missing: WHERE id = "abc123"
如果没有 Time Travel,我必须希望最近运行了计划备份,或者记得在之前进行了手动备份。有了 Time Travel,我可以将数据库恢复到在犯错误前一分钟左右的某个时间点(并希望下次能吸取教训)。
我们还在探索一些功能,以显示数据库状态的更大变化, 包括使识别模式更改、表数、存储数据的重大变化,甚至特定查询(通过事务 ID),以帮助您更好地了解恢复数据库的确切时间点。
路线图
那么 D1 的下一步?
- 开放 beta:我们正在确保,在将新的存储子系统作为所有“d1 create”命令的默认设置之前,在负载(和实际使用)下观察它的表现。即使是“beta”,我们对耐久性和可用性也有很高的要求,并且我们还意识到备份功能(Time Travel)对于人们信任一个新数据库是很重要的。接下来的几周内,欢迎关注 Cloudflare 博客以获取更多相关消息!
- 更大的数据库:这是很多人的重大要求,我们已经非常接近实现了。使用 Workers Paid 计划 的开发人员将在不久的将来获得 1 GB 数据库的使用权限,我们也将继续提升每个数据库的最大大小。
- 指标和可观察性:您将能够通过 D1 仪表板和我们的 GraphQL API检查每个数据库的总体查询量、失败查询、消耗的存储空间以及读/写单位数,以便更轻松地调试问题和跟踪支出。
- 自动读取复制:我们的新存储子系统在构建时就考虑到了复制,并且我们正在努力确保复制层快速和可靠,然后才提供给开发人员使用。读取复制不仅旨在通过在接近用户的多个地点存储副本来改善查询延迟,还将允许我们横向扩展具有更大工作负载的 D1 数据库。
与此同时,您可以立即开始使用 D1 构建原型和进行试验,探索我们的 D1 + Drizzle + Remix 示例项目,或加入 Cloudflare Developers Discord 服务器上的 #d1 频道 ,与 D1 团队和其他正在利用 D1 构建的人进行直接交流。