

当社はそのリードを埋めるつもりはありません:パフォーマンスとスケーラビリティが飛躍的に向上したD1データベースのメジャーアップデートを開始できることを嬉しく思います。アルファユーザー( あらゆるWorkersユーザーを含む)は、以下のコマンドで、新しいストレージバックエンドを使用して、今すぐ新しいデータベースを作成できます:
$ wrangler d1 create your-database --experimental-backend
今後数週間で、誰にとっても、デフォルトのエクスペリエンスになりますが、開発者に新しいバージョンのD1ですぐに実験を開始するように招待したいと思います。また、D1の新しいストレージサブシステムをどのように構築したか、そしてそれが、Cloudflareの分散型ネットワークからどのような恩恵を受けているのかについて、近日中にさらに多くを共有する予定です。。
教えてください:D1とは、何でしょう?
D1はCloudflareのネイティブなサーバーレスデータベースで、当社は、昨年11月に、アルファ版を開始しました。開発者は、Workers、KV、Durable Objects、そして最近ではQueue& R2を使用して複雑なアプリケーションを構築してきましたが、彼らは一貫して、当社に求めてきたものが1つあります:クエリーができるデータベースです。
また、SQLベース、ゼロへのスケールである必要があり、(Workers自体と同じように)レプリケーションへのRegion:Earth(地球全域)のアプローチを採用する必要があるという一貫したフィードバックも聞かれました。そこで当社はそのフィードバックを取り入れ、SQLiteを使用してD1の構築に着手しました。SQLiteは、馴染みのあるSQL方言、堅牢なクエリーエンジン、そして構築に最も試されたコードベースの1つを提供します。
当社は、D1の最初のバージョンは「本物の」アルファ版として出荷しました:公開で開発し、開発者から直接フィードバックを収集し、重要なことに優先順位をつけるための方法です。そして、アルファ版の名に沿うように、バグ、パフォーマンスの問題、そしてかなり狭い「ハッピーパス」がありました。
それにもかかわらず、開発者が何千ものデータベースをスピンアップし、何十億ものクエリーを作成し、DrizzleおよびKyselyのような人気のあるORMがD1のサポートを(すでに!)追加し、RemixやNuxtのテンプレートも、D1を中心に直接構築しているのを当社は見てきました。
11にグレードアップ
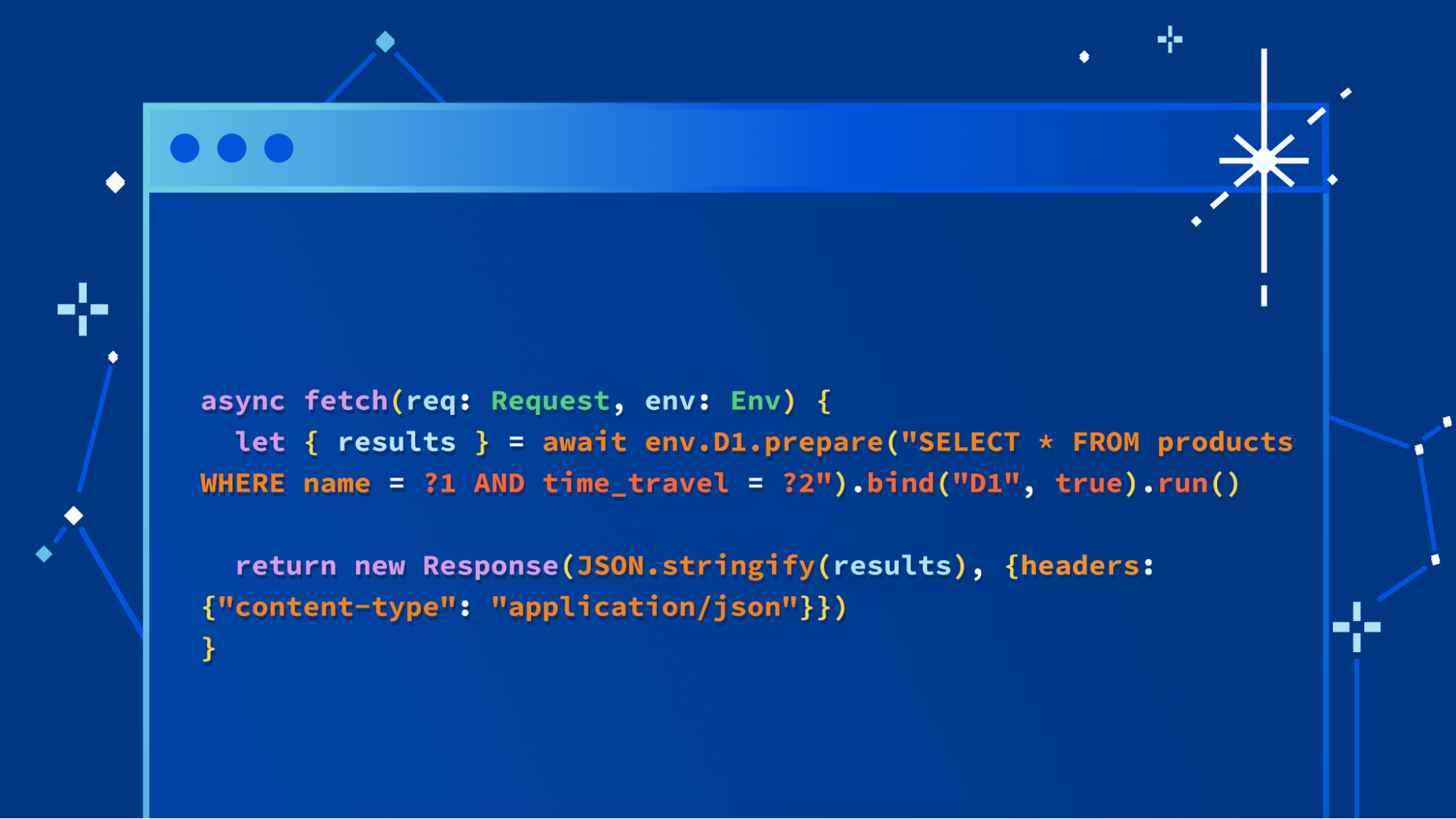
今までD1をアルファ版の状態で使用してきた場合:知っていることはすべて忘れてください。 D1は大幅に高速になりました:有名なNorthwind Traders Demoでは最大20倍高速になりました。これは、新しいストレージバックエンドを使用するために移行したばかりです:
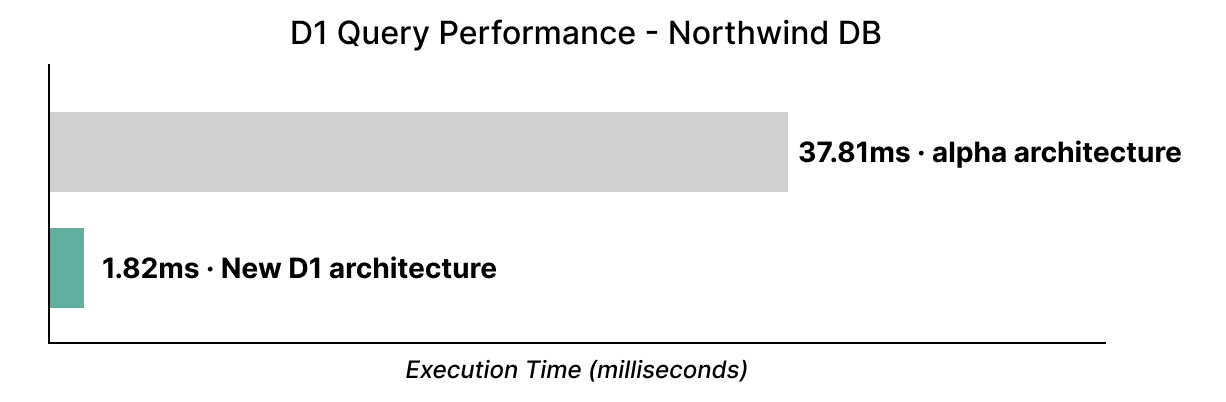
新しいアーキテクチャは書き込みパフォーマンスも向上します:1,000行(各行の幅は約200バイト)を挿入する単純なベンチマークでは、以前のバージョンのD1と比べて約6.8倍高速です。
より大きなバッチ(~200 バイト幅で 10,000 行)では、さらに大きな改善が見られます:10~11倍の間で、新しいストレージバックエンドの遅延も大幅に一貫しています。また、全体的な書き込みスループットの最適化にも、まだ着手していないので、D1はここでのみ高速化すると予想されます。
新しいストレージバックエンドでは、D1がおもちゃではないことも明確にしたいと考えており、その他のサーバーレスデータベースに対しパフォーマンスを常にベンチマークしています。50万行のキー値テーブルに対するクエリー(ベンチマークは本質的に合成であることを認識すること)では、D1は人気のあるサーバーレスPostgresプロバイダーよりも約3.2倍高速に実行します:
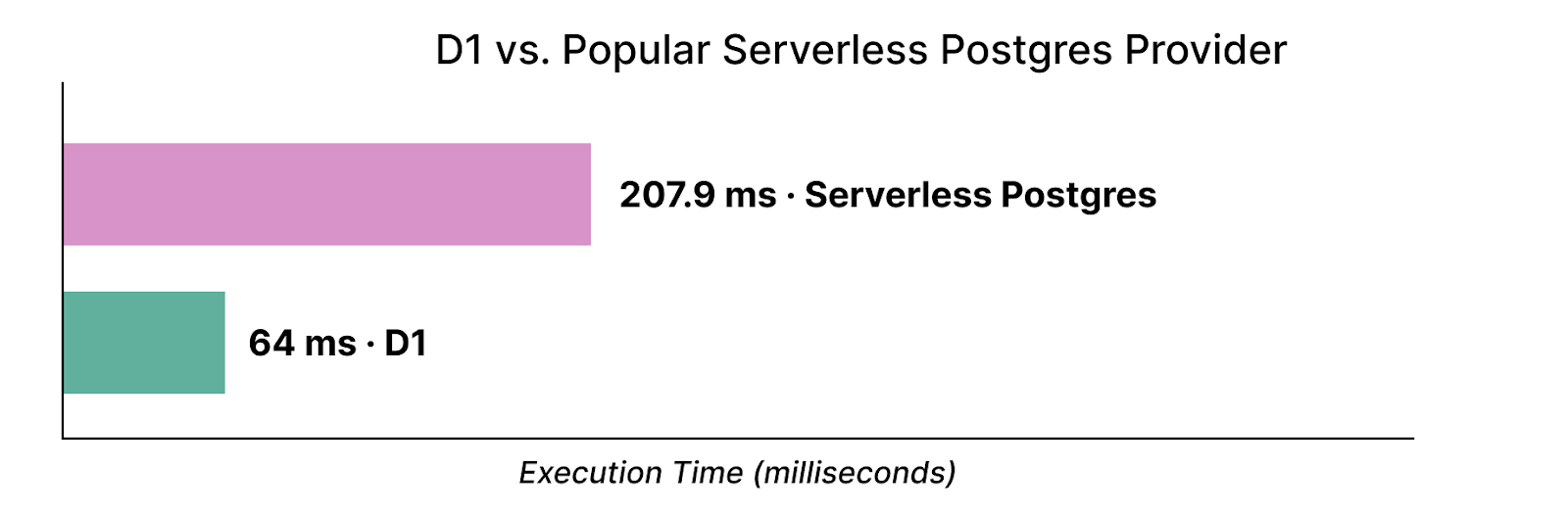
Postgresのクエリーを数回実行してページキャッシュを準備し、サーバーが計測したクエリー時間の中央値を取得しました。当社は今後も、パフォーマンスエッジを磨き続け、進んでいきます。
既存のデータベースを持つ開発者は、データベースをエクスポートし、その後、当社のドキュメントにそれをインポートする手順に従って、ストレージエンジンがサポートする新しいデータベースにデータをインポートできます。
見逃していたものは?
また、D1の開発者向けエクスペリエンスの多くの改善にも取り組んできています:
- ダッシュボードから直接クエリーを発行できる新しいコンソールインターフェースにより、クエリーの開始および/または単発クエリーの発行が容易になります。
- データベース内で直接JSONを介してクエリーを行うJSON関数の正式なサポート。
- ロケーションヒントは、リーダー(書き込みを担当する)がグローバルにどこに配置されているかに影響を与えることができます。
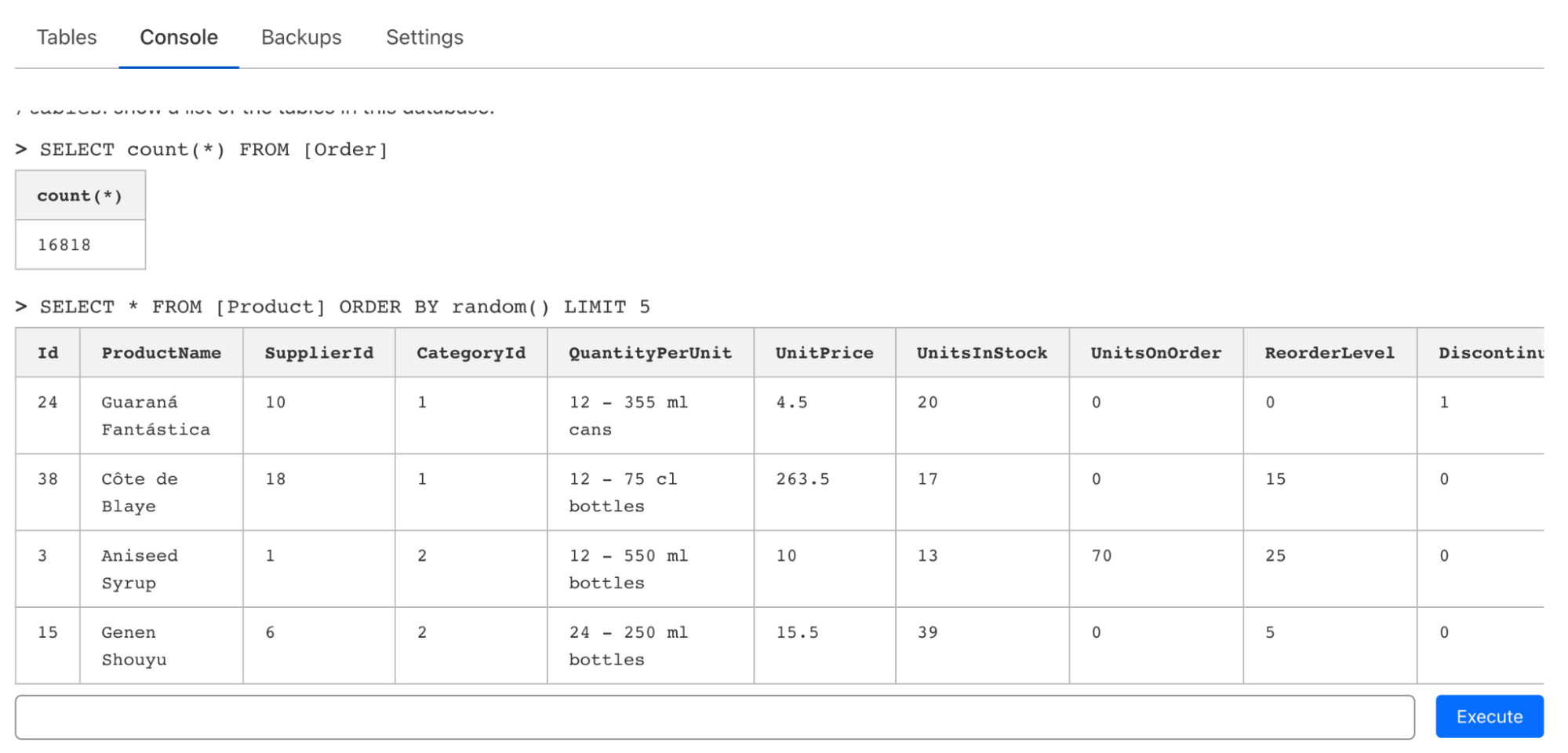
D1はCloudflare Workers内でネイティブに動作するように設計されていますが、プロトタイピングやデータベースを探索する際に、CLIやWebエディタを介して単発のクエリーを迅速に発行する必要がよくあることを認識しています。クエリー(およびファイル)を実行するためのWranglerでのサポートに加え、当社はクエリーの発行、テーブルの検査、およびオンザフライのデータの編集を可能にするコンソールエディタを導入しました:
JSON関数により、D1のTEXT列に格納されたJSONをクエリーできます:どのデータがリレーショナルデータベーススキーマに厳密に関連付けられ、何が関連付けられないのか、柔軟性を持たせることができ、同時にSQLを介して(アプリに届く前に)すべてのデータをクエリーできます。
たとえば、最終ログインのタイムスタンプをJSON配列として login_historyTEXT列に格納すると仮定します:サブオブジェクトや配列項目は、そのキーへのパスを指定することで直接クエリー(抽出)できます:
SELECT user_id, json_extract(login_history, '$.[0]') as latest_login FROM users
D1のJSON関数のサポートは非常に柔軟で、D1が構築しているSQLiteコアを活用しています。
D1で初めてデータベースを作成する際、現在接続している場所に基づいて位置情報を自動的に推測します。しかし、次のような影響を与えたいと思うような場所のケースもあります—旅行中であるとか、書き込みの大半が送信されると予想される地域とは異なる分散チームがあるなどです。
D1のロケーションヒントのサポートにより、次のことが容易になります:
# Automatically inferred based your location
$ wrangler d1 create user-prod-db --experimental-backend
# Indicate a preferred location to create your database
$ wrangler d1 create eu-users-db --location=weur --experimental-backend
ロケーションヒント は、Cloudflareのダッシュボードでも利用できるようになります:
また、開発者が始めるだけでなく、D1の高度な機能を利用できるようにさらに多くのドキュメンテーションも公開しました。D1のドキュメンテーションは今後数か月にわたって大幅に増加し続けることが予想されます。
大金をつぎ込むことはありません
アルファ版を発表して以来、非常に多くの開発者からD1の価格設定について質問を受けてきましたが、その内容をお伝えする準備が整いました。構築を開始する前に、どのような費用がかかるのかを理解することが重要だと思っています。そうすれば、半年後に驚くことはないでしょう。
要旨:
- ユースケースにかかるD1の費用を事前にモデル化できるように、価格を発表する予定です。最終的な価格は変更される可能性がありますが、変更は比較的軽微であると予想しています。
- 今年後半まで課金を有効にする予定はなく、そしてその変更に先立って既存のD1ユーザーに電子メールで通知します。それまで、D1は引き続き無料で使用できます。
- D1には、常時無料枠が含まれており、月額5ドルのWorkersサブスクリプションの一部としての使用量が含まれ、 読み取り、書き込み、ストレージに基づいて課金されます。
すでにWorkersにサブスクライブしている場合は、何もする必要はありません。今後、課金が有効になると、既存のサブスクリプションにはD1の使用量が含まれます。
以下はその要約です(意図的にシンプルにしています):

重要なことは、 グローバルな読み取りレプリケーションを有効にする場合、そのための追加料金を支払う必要はなく、レプリケーションによってストレージの消費量が増えることもありません。当社は、内蔵の自動レプリケーションが重要であると考えており、どこでもデータベースを高速化するために、開発者が乗算コスト(レプリカ×ストレージ料金)を支払う必要はないと考えています。
さらに、D1がサーバーレス価格設定の最良の部分—ゼロへのスケールと使用した分だけの支払い—を確実に取り入れ、ワークロードに必要なCPUおよび/またはメモリの数を把握し、静かな時間にインフラストラクチャをスケールダウンするスクリプトを書く必要がないようにしたかったのです。
D1の読み取りの価格設定は、読み取り単位(読み取り4KBごと)と書き込み単位(書き込み1KBごと)というよく知られた概念に基づいています。64バイトの行を10,000行ずつ読み取る(スキャンする)クエリーは、160の読み取り単位を消費します。大量のMarkdownを含む「blog_posts」テーブルに3KBの大きな行を書き込むと、3つの書き込み単位になります。また、最も一般的なクエリーのインデックスを作成してパフォーマンスを向上させ、それらのクエリーがスキャンする必要があるデータ量を削減すると、請求額も削減されます。当社は、デフォルトで高速パスをよりコスト効率の高いものにすることが正しいアプローチであると考えています。
重要:ネットワークスイッチを入れる前に、価格設定に関するフィードバックを受け続けることです。
タイムトラベル
新しいバックアップ機能も導入しています: ポイントインタイムリカバリ、そして当社はこれをタイムトラベルと呼んでいます。なぜなら、ポイントインタイムリカバリがまさにタイムトラベルに似ているからです。タイムトラベルは、D1データベースを過去30日以内の任意の時間に復元することができ、新しいストレージシステムを使用してD1データベースに組み込まれる予定です。近い将来、新しいD1データベースのタイムトラベルを有効にする予定です。
タイムトラベルを本当に強力にするものは、「ちょっと待って、この大きな変更をする前にバックアップを取ったっけ?」と慌てる必要がないことです。— なぜなら、当社がそれをやるからです。当社は、お客様のデータベースへのすべての変更のストリーム(先行書き込みログ)を保持し、その時点までの変更を順番に再生することによって、データベースをある時点に復元することができます。
以下はその例です(若干のAPIの変更の可能性があります):
# Using a precise Unix timestamp (in UTC):
$ wrangler d1 time-travel my-database --before-timestamp=1683570504
# Alternatively, restore prior to a specific transaction ID:
$ wrangler d1 time-travel my-database --before-tx-id=01H0FM2XHKACETEFQK2P5T6BWD
また、ポイントインタイムリカバリという考え方は新しいものではありませんが、利用できるとしても、多くは有料のアドオンです。削除あるいは間違いをしてからオンにしておけばよかったと気づいても、手遅れになることが多いのです。
例えば、UPDATE文のWHEREを忘れてしまうという典型的な間違いをしたとします:
-- Don't do this at home
UPDATE users SET email = '[email protected]' -- missing: WHERE id = "abc123"
タイムトラベルがなければ、スケジュールされたバックアップが最近実行されたか、直前に、忘れずに手動でバックアップを取ったということを願うしかないのです。タイムトラベルを使用すると、その間違いの1分ほど前の時点に復元することができます(そして、次回への教訓になれば幸いです)。
スキーマの変更、テーブルの数、保存されているデータの大きなデルタ 、さらには特定のクエリー (トランザクションID経由)を簡単に識別できるようにするなど、データベースの状態に対する大きな変更を表面化できる機能も検討しています—データベースを復元する正確な時点を理解できるようにします。
ロードマップ上で
では、D1の次は何でしょうか?
- オープンベータ:すべての「d1 create」コマンドのデフォルトにする前に、負荷時の新しいストレージサブシステム(および実際の使用)を観察したことを確認しています。当社は、「ベータ版」であっても、耐久性と可用性に高い基準を設けています。また、メンバーが、新しいデータベースを信頼するためには、バックアップへのアクセス(タイムトラベル)が重要であることも認識しています。今後数週間、Cloudflareのブログで続報にご注目ください!
- より大きなデータベース:これが多くの方からの大きな要望であることは承知していますが、当社は非常に近いところにいます。 Workers有料プラン の開発者は、ごく近い将来、1GBのデータベースにアクセスできるようになり、時間をかけてデータベースあたりの最大サイズを引き続き増加させる予定です。
- メトリクス&可観測性:D1ダッシュボードとGraphQL APIの両方を介して、データベース別の全体的なクエリー量、失敗したクエリー、消費されたストレージ、読み取り/書き込み単位を検査できるため、問題のデバッグと支出の追跡が容易になります。
- 自動読み取りレプリケーション: 当社の新しいストレージサブシステムはレプリケーションを念頭に置いて構築されており、開発者に展開する前に、レプリケーションレイヤーの高速性と信頼性の両方を確保するために取り組んでいます。読み取りレプリケーションは、ユーザーに近い複数の場所にデータのコピー—レプリカ—を保存することで、クエリーの遅延を改善するように設計されているだけでなく、ワークロードがさらに大きいデータベースに対し、D1データベースを水平方向にスケールアウトできます。
その間、今すぐにD1のプロトタイピングと実験を開始したり、D1 + Drizzle + Remixサンプルプロジェクトを探索したり、または Cloudflare開発者Discordサーバーの#d1チャンネルに参加してD1チームやD1を構築しているその他と直接交流したりできます。