

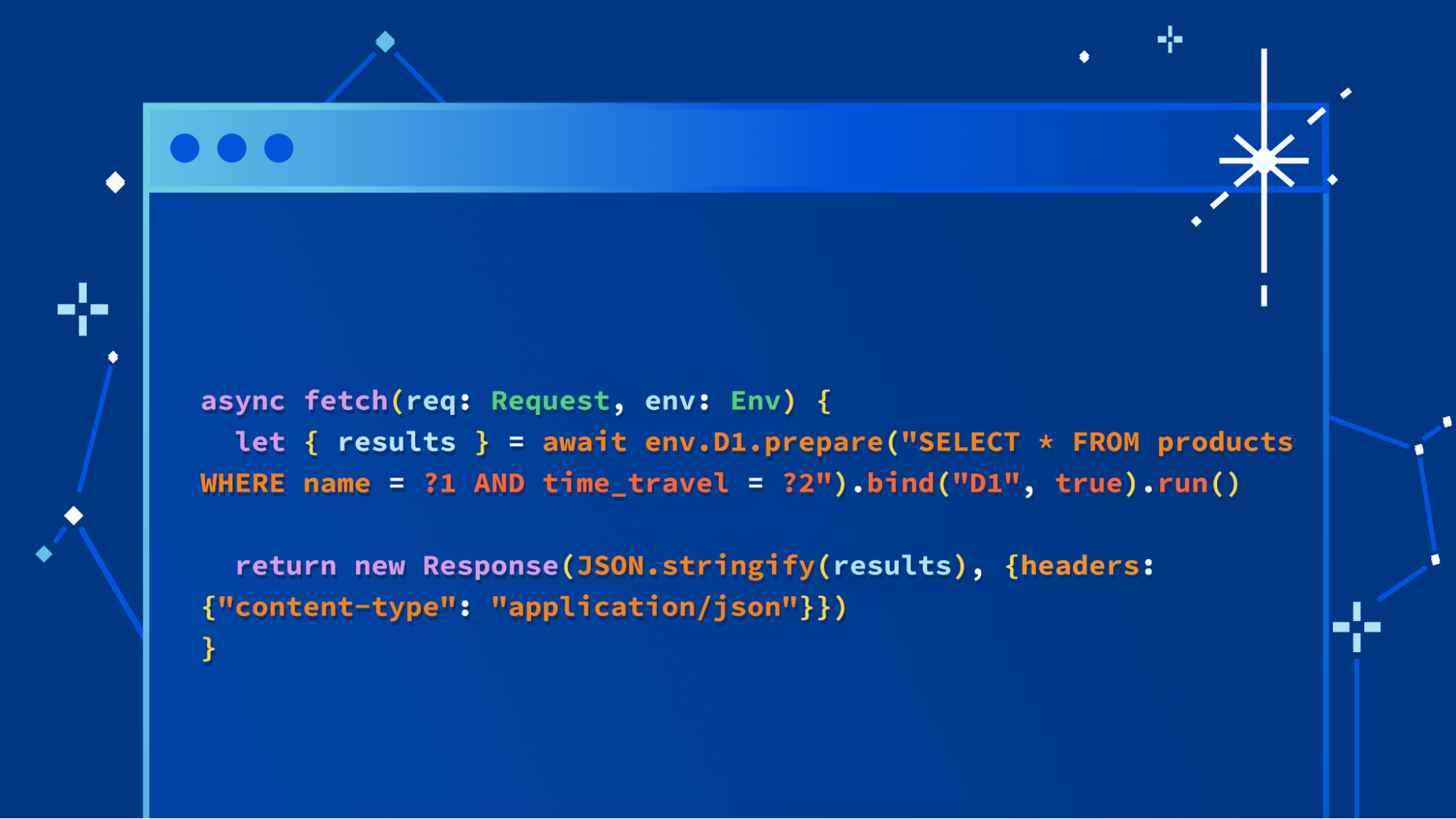
Nous n'allons pas noyer le poisson : nous sommes ravis de lancer une mise à jour majeure de notre base de données D1, offrant des améliorations spectaculaires en termes de performances et d'évolutivité. Les utilisateurs de la version alpha (cela inclut tous les utilisateurs de Workers) peuvent dès maintenant créer de nouvelles bases de données sur le nouveau backend de stockage avec la commande suivante :
$ wrangler d1 create your-database --experimental-backend
Dans les semaines à venir, ceci deviendra l'expérience par défaut pour tous les utilisateurs, mais nous voulons inviter les développeurs à commencer à expérimenter dès maintenant avec la nouvelle version de D1. Nous partagerons également, très prochainement, d'autres informations sur le développement du nouveau sous-système de stockage de D1 et les avantages que lui apporte le réseau distribué de Cloudflare..
Rafraîchissez-moi la mémoire : D1, qu'est-ce que c'est ?
D1 est la base de données serverless native de Cloudflare, que nous avons lancée dans sa version alpha en novembre de l'année dernière. Des développeurs ont créé des applications complexes avec Workers, KV, Durable Objects, et dernièrement, Queues et R2 ; cependant, ils nous demandent également une chose : une base de données qu'ils peuvent interroger.
Nous avons, par ailleurs, recueilli de nombreux commentaires nous demandant une solution basée sur SQL, « scale-to-zero » (c'est-à-dire pouvant être réduite à zéro instance, comme le service Workers lui-même), qui adopte une approche globale (« Region: Earth ») de la réplication. Nous avons donc entendu ces commentaires et avons entrepris de créer D1. SQLite nous a offert un dialecte SQL que nous connaissions, un moteur de requêtes robuste et une base de code particulièrement éprouvée, sur laquelle développer notre solution.
Nous avons livré la première version de D1 sous la forme d'une « véritable » version alpha : c'était, pour nous, une façon d'aborder le développement sous un angle ouvert, de recueillir les commentaires directement auprès des développeurs et de mieux hiérarchiser nos priorités. Et, fidèle à la tradition de l'appellation « alpha », cette première version se distinguait par des bugs, des problèmes de performances et un « parcours heureux » (c'est-à-dire un scénario dans lequel toutes les fonctions s'exécutent comme prévu) assez étroit.
Malgré cela, nous avons constaté que des développeurs créaient des milliers de bases de données et exécutaient des milliards de requêtes, que des ORM populaires telles que Drizzle et Kysely ont ajouté la prise en charge de D1 (déjà !), et que des modèles Remix et Nuxt ont également été développés directement autour de D1.
Régler la puissance sur 11
Si, à ce jour, vous avez utilisé D1 dans sa version alpha, oubliez tout ce que vous savez. D1 est désormais beaucoup plus rapide – jusqu'à 20 fois plus rapide avec la célèbre démo Northwind Traders, dont nous venons d'effectuer la migration vers notre nouveau backend de stockage :
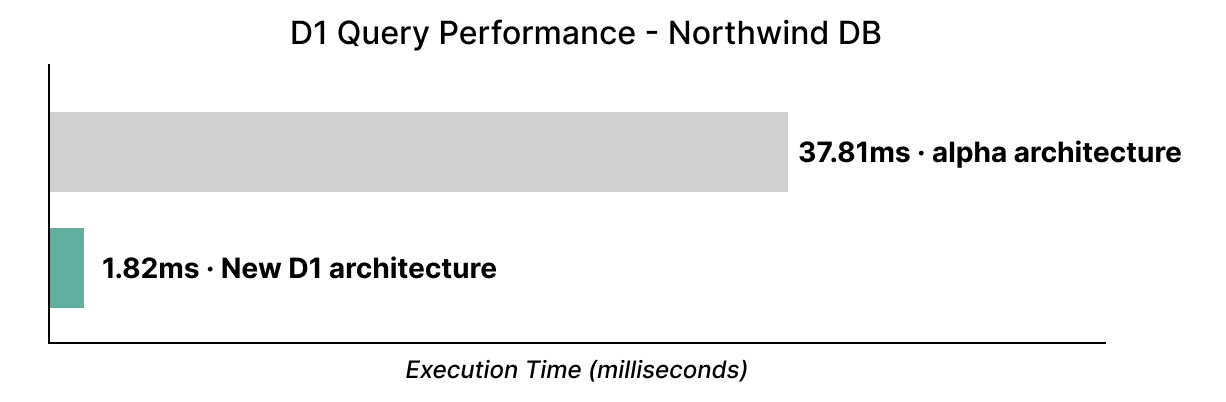
Notre nouvelle architecture améliore également les performances en écriture : un simple test de référence consistant à insérer 1 000 lignes (chaque ligne mesurant environ 200 octets en largeur) se déroule environ 6,8 fois plus rapidement qu'avec la précédente version de D1.
Pour les lots plus volumineux (10 000 lignes d'une largeur d'environ 200 octets), l'amélioration est encore plus remarquable : l'insertion est 10 à 11 fois plus rapide, la latence du nouveau backend de stockage étant également beaucoup plus constante. Nous n'avons pas encore commencé à optimiser notre débit d'écriture global ; nous pensons donc que désormais, D1 deviendra encore plus rapide.
Avec notre nouveau backend de stockage, nous tenons également à revendiquer que D1 n'est pas un « gadget », et nous comparons continuellement les performances de notre solution à celles d'autres bases de données serverless. Une requête sur une table clé-valeur de 500 000 lignes (en n'oubliant pas que les valeurs de référence sont intrinsèquement synthétiques) démontre que D1 est 3,2 fois plus rapide qu'une célèbre solution Postgres serverless :
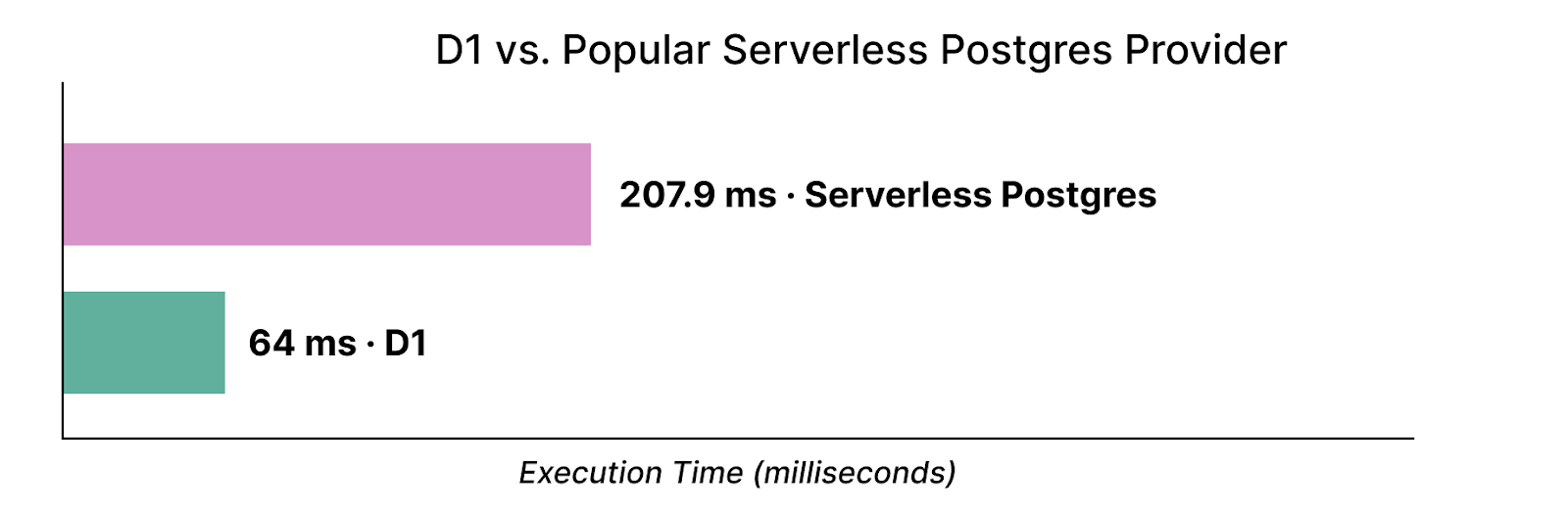
Nous avons exécuté les requêtes Postgres à plusieurs reprises, afin d'amorcer le cache des pages, puis nous avons observé le temps médian des requêtes, mesuré par le serveur. Nous continuerons à affiner les performances de notre solution au fur et à mesure du développement.
Les développeurs disposant de bases de données existantes peuvent importer des données dans une nouvelle base de données utilisant le moteur de stockage en suivant les étapes décrites, dans notre documentation, pour exporter une base de données, puis l'importer.
Qu'est-ce que j'ai manqué ?
Nous avons également travaillé sur un certain nombre d'améliorations de l'expérience qu'offre D1 aux développeurs :
- Une nouvelle interface de console permettant d'émettre des requêtes directement depuis le tableau de bord, facilitant la prise en main et/ou l'émission de requêtes ponctuelles.
- La prise en charge formelle de fonctions JSON permettant d'exécuter des requêtes via JSON directement dans votre base de données.
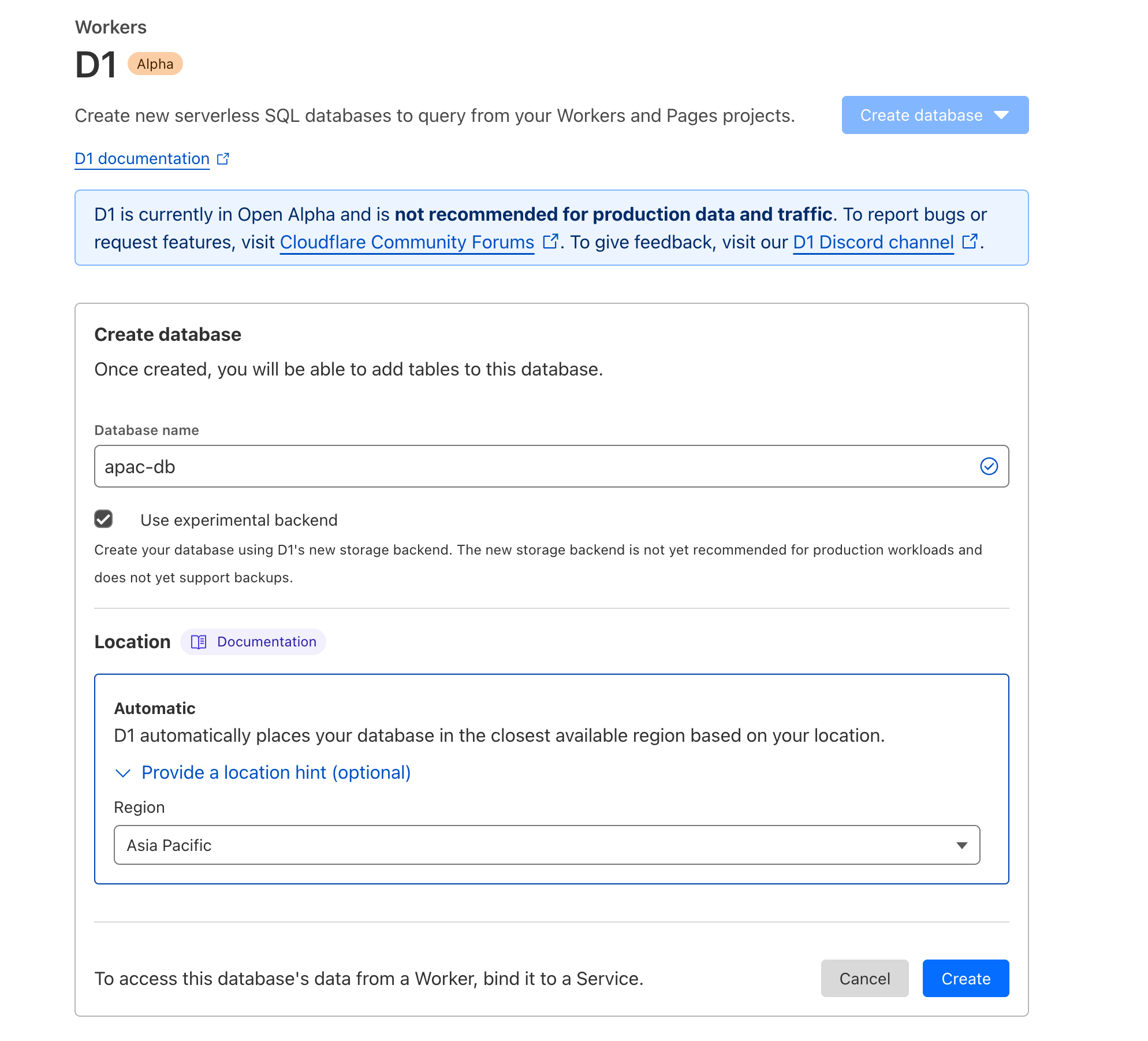
- Location Hints, qui permet d'influer sur le choix de l'endroit où se trouve votre leader (responsable des écritures) dans le monde entier.
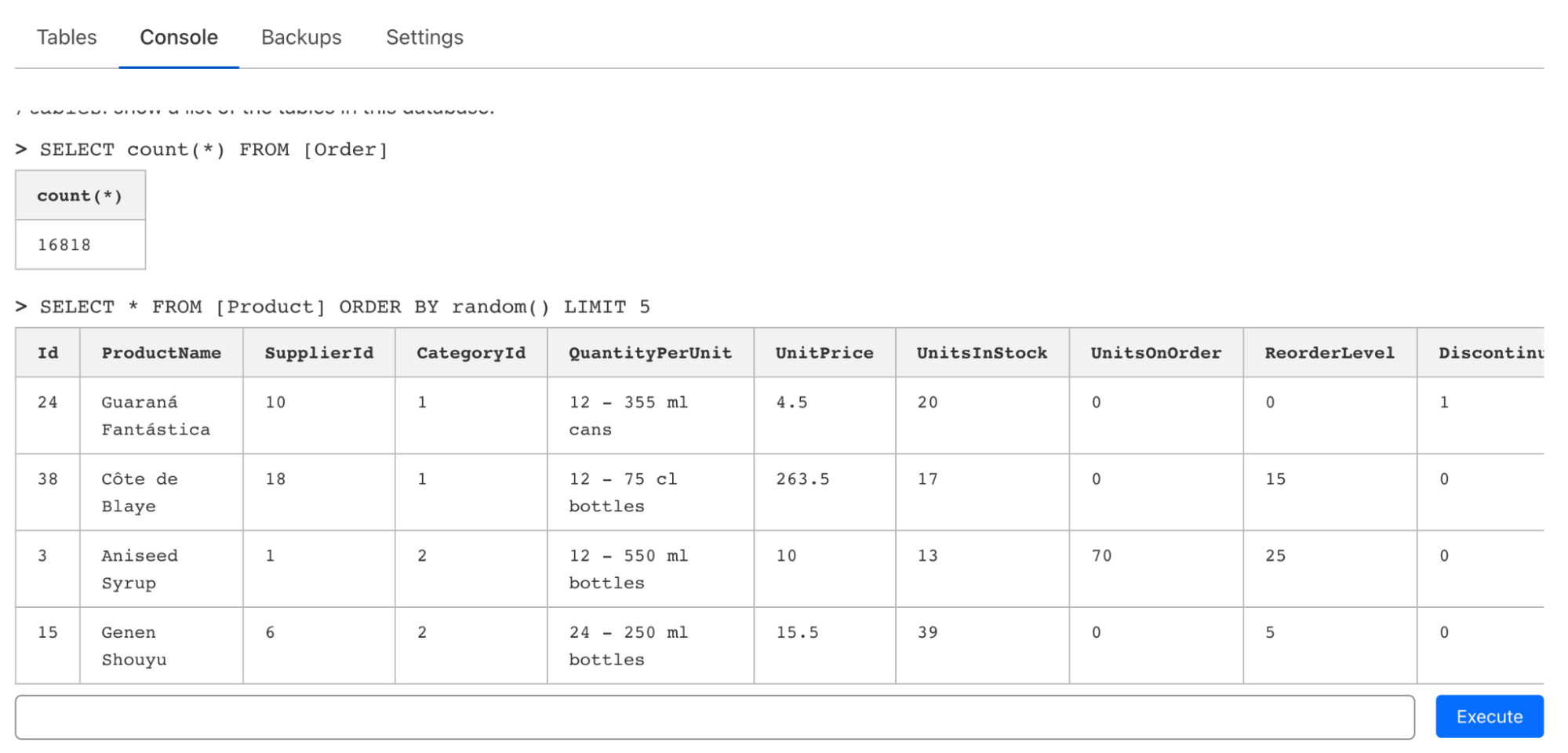
Bien que D1 soit conçue pour s'exécuter nativement dans une instance Cloudflare Workers, nous avons conscience qu'il est souvent nécessaire d'émettre rapidement des requêtes ponctuelles via une interface de ligne de commande ou un éditeur web lors du prototypage ou, simplement, de l'exploration d'une base de données. En plus de la prise en charge dans wrangler pour l'exécution de requêtes (et de fichiers), nous avons également introduit un éditeur de console permettant d'émettre des requêtes, d'inspecter des tables et même d'éditer des données à la volée :
Les fonctions JSON vous permettent d'interroger les valeurs JSON stockées dans des colonnes TEXT dans D1, offrant davantage de flexibilité quant aux données associées strictement (ou non) à votre schéma de base de données relationnelle, tout en vous permettant d'interroger toutes vos données via SQL (avant qu'elles n'atteignent votre application).
Par exemple, supposons que vous stockiez les informations d'horodatage des dernières connexions sous forme de tableau JSON dans une colonne TEXT intitulée login_history : vous pouvez interroger (et extraire) directement des sous-objets ou des éléments de la table en fournissant un chemin d'accès à la clé correspondante :
SELECT user_id, json_extract(login_history, '$.[0]') as latest_login FROM users
La prise en charge des fonctions JSON par D1 est extrêmement flexible, et tire profit du cœur SQLite sur lequel est développée D1.
Lorsque vous créez pour la première fois une base de données avec D1, nous déduisons automatiquement la localisation de l'endroit depuis lequel vous vous connectez actuellement. Dans certains cas, cependant, il peut être souhaitable d'influer sur ce choix, par exemple, lorsque vous êtes en déplacement ou que votre équipe est présente dans une région différente de celle depuis laquelle proviendra, selon vous, la majorité de vos écritures.
La prise en charge de Location Hints par D1 simplifie cette procédure :
# Automatically inferred based your location
$ wrangler d1 create user-prod-db --experimental-backend
# Indicate a preferred location to create your database
$ wrangler d1 create eu-users-db --location=weur --experimental-backend
Location Hints est désormais également accessible depuis le tableau de bord de Cloudflare :
Par ailleurs, nous avons publié d'autres documents destinés à aider les développeurs à effectuer leurs premiers pas, mais également à utiliser les fonctionnalités avancées de D1. Vous pouvez vous attendre à ce que la documentation de D1 continue à s'étoffer considérablement au cours des prochains mois.
Une solution qui ne videra pas votre portefeuille
Depuis l'annonce de la version alpha, de très nombreux développeurs nous ont demandé comment nous allions établir la tarification de D1 ; nous sommes maintenant prêts à vous indiquer comment elle se présentera. Nous savons qu'il est important de comprendre le coût potentiel d'un service avant de commencer à développer une solution avec celui-ci, afin de ne pas avoir de mauvaise surprise six mois plus tard.
En résumé :
- Nous annonçons la tarification pour vous permettre de commencer à modéliser à l'avance le coût de D1 pour votre scénario d'utilisation. La tarification définitive est susceptible d'être modifiée, mais nous nous attendons à ce que les changements soient relativement mineurs.
- La facturation ne sera pas activée avant la fin de l'année, et nous informerons les utilisateurs actuels de D1 par e-mail préalablement à ce changement. D'ici là, l'utilisation de D1 restera gratuite.
- D1 comprendra un niveau toujours gratuit, correspondant à une utilisation incluse dans notre abonnement à 5 $/mois à Workers, ainsi qu'une facturation établie en fonction des lectures, des écritures et du stockage.
Si vous avez déjà souscrit un abonnement à Workers, vous n'avez rien à faire : l'utilisation de D1 sera incluse dans votre abonnement existant lorsque la facturation sera activée, à l'avenir.
Voici un récapitulatif (nous avons volontairement simplifié les choses) :

Une chose importante : lorsque nous activerons la réplication globale en lecture, celle-ci n'entraînera pas de coût supplémentaire, et la réplication ne multipliera pas non plus votre consommation d'espace de stockage. Nous pensons que la réplication automatique intégrée est importante, et nous pensons que les développeurs ne devraient pas avoir à s'acquitter de coûts multiplicatifs (répliques × frais de stockage) pour assurer la rapidité de leur base de données partout dans le monde.
Par ailleurs, nous avons voulu veiller à ce que D1 reprenne les meilleurs aspects de la tarification serverless (à savoir la capacité scale-to-zero et le paiement en fonction de l'utilisation), afin que vous n'ayez pas besoin d'essayer de déterminer le nombre de processeurs et/ou la quantité de mémoire requis par votre charge de travail, ni d'écrire des scripts destinés à réduire l'échelle de votre infrastructure pendant les heures plus calmes.
La tarification des lectures de D1 est basée sur le concept familier des unités de lecture (pour 4 Ko de données lues) et des unités d'écriture (pour 1 Ko de données écrites). Une requête qui lit (analyse) environ 10 000 lignes de 64 octets chacune consommera 160 unités de lecture. L'écriture d'une longue ligne de 3 Ko dans une table « blog_posts » contenant beaucoup de Markdown représentera trois unités d'écriture. Et si vous créez des index pour vos requêtes les plus fréquemment utilisées, afin d'améliorer les performances et de réduire le volume de données que doivent analyser ces requêtes, vous réduirez également le montant qui vous sera facturé. Nous pensons que l'approche consistant, par défaut, à faire du chemin rapide le plus rentable également est la bonne.
Une chose importante : nous continuerons à recueillir des commentaires sur notre tarification avant de la mettre en application.
Time Travel
Nous inaugurons également une nouvelle fonctionnalité de sauvegarde : la restauration ponctuelle, que nous appelons Time Travel (c'est-à-dire « voyage dans le temps »), parce que c'est précisément le ressenti qu'elle procure. Time Travel vous permet de restaurer votre base de données D1 à n'importe quelle minute au cours des 30 derniers jours ; la fonction intégrée aux bases de données D1 par l'intermédiaire de notre nouveau système de stockage. Nous avons l'intention d'activer Time Travel pour les nouvelles bases de données D1 dans un avenir très proche.
Ce qui rend la fonctionnalité Time Travel si puissante, c'est que vous n'avez plus lieu de paniquer et de vous demander « Oh, mais attends – est-ce que j'ai fait une sauvegarde avant de déployer ce changement majeur ? » ; nous le faisons à votre place. Nous conservons un flux de toutes les modifications apportées à votre base de données (Write-Ahead Log), qui nous permet de restaurer votre base de données à un instant donné en lisant ces modifications dans l'ordre jusqu'à ce point.
Voici un exemple (sous réserve de quelques modifications mineures de l'API) :
# Using a precise Unix timestamp (in UTC):
$ wrangler d1 time-travel my-database --before-timestamp=1683570504
# Alternatively, restore prior to a specific transaction ID:
$ wrangler d1 time-travel my-database --before-tx-id=01H0FM2XHKACETEFQK2P5T6BWD
Et bien que l'idée de la restauration à un instant donné ne soit pas nouvelle, il s'agit souvent d'une option payante, si tant est qu'elle soit disponible. Si vous vous rendez compte que vous auriez dû l'activer après avoir supprimé des données ou avoir commis une autre erreur, il est souvent trop tard.
Par exemple, supposons que je commette l'erreur classique consistant à oublier WHERE dans une instruction UPDATE :
-- Don't do this at home
UPDATE users SET email = '[email protected]' -- missing: WHERE id = "abc123"
Sans Time Travel, je n'aurais plus qu'à espérer qu'une sauvegarde programmée ait été exécutée récemment ou que j'aie pensé à effectuer une sauvegarde manuelle juste avant. Grâce à Time Travel, je peux revenir à un point situé une minute ou deux avant cette erreur (et espérer en tirer une leçon pour la prochaine fois).
Nous explorons également des fonctionnalités permettant d'identifier des changements plus importants dans l'état de votre base de données, notamment en facilitant l'identification des modifications de schéma, du nombre de tables, des écarts importants dans les données stockées et même des requêtes spécifiques (via les identifiants de transaction), afin de vous aider à mieux comprendre à quel instant précis vous devez restaurer votre base de données.
En prévision
Alors, quelles sont les prochaines innovations pour D1 ?
- Bêta ouverte : nous nous assurons d'avoir observé notre nouveau sous-système de stockage sous charge (et en conditions d'utilisation réelle) avant d'en faire la valeur par défaut pour toutes les commandes « d1 create ». Nous plaçons la barre très haut, en termes de durabilité et de disponibilité, même pour une version « bêta », et nous sommes également conscients que l'accès aux sauvegardes (Time Travel) est un aspect important de la confiance qu'accordent les utilisateurs à une nouvelle base de données. Surveillez le blog de Cloudflare dans les semaines à venir pour plus de nouvelles à ce sujet !
- Des bases de données plus volumineuses : nous savons que c'est une demande très courante de la part d'un grand nombre d'utilisateurs, et nous sommes à deux doigts d'y répondre. Les développeurs bénéficiant de l'offre payante Workers auront accès à des bases de données de 1 Go dans un avenir très proche, et nous continuerons à augmenter la taille maximale par base de données au fil du temps.
- Indicateurs et observabilité : vous pourrez inspecter le volume global de requêtes par base de données, les requêtes ayant échoué, le stockage consommé et les unités de lecture/d'écriture depuis le tableau de bord de D1 et via notre API GraphQL, afin de faciliter le débogage des problèmes et le suivi des dépenses.
- Réplication automatique en lecture : notre nouveau sous-système de stockage est fondamentalement conçu dans l'optique de la réplication, et nous nous veillons actuellement à nous assurer que notre couche de réplication est à la fois rapide et fiable, avant de la proposer aux développeurs. La réplication en lecture est conçue pour améliorer la latence des requêtes, en stockant des copies (des répliques) de vos données dans plusieurs endroits, à proximité de vos utilisateurs, mais elle nous permettra également d'assurer l'évolutivité horizontale des bases de données D1 pour les utilisateurs exécutant des charges de travail plus importantes.
En attendant, vous pouvez dès maintenant commencer à prototyper et expérimenter avec D1, explorer notre exemple de projet D1 + Drizzle + Remix ou rejoindre le canal #d1 sur le serveur Discord Cloudflare Developers, afin d'échanger directement avec l'équipe D1 et d'autres utilisateurs développant dans D1.