

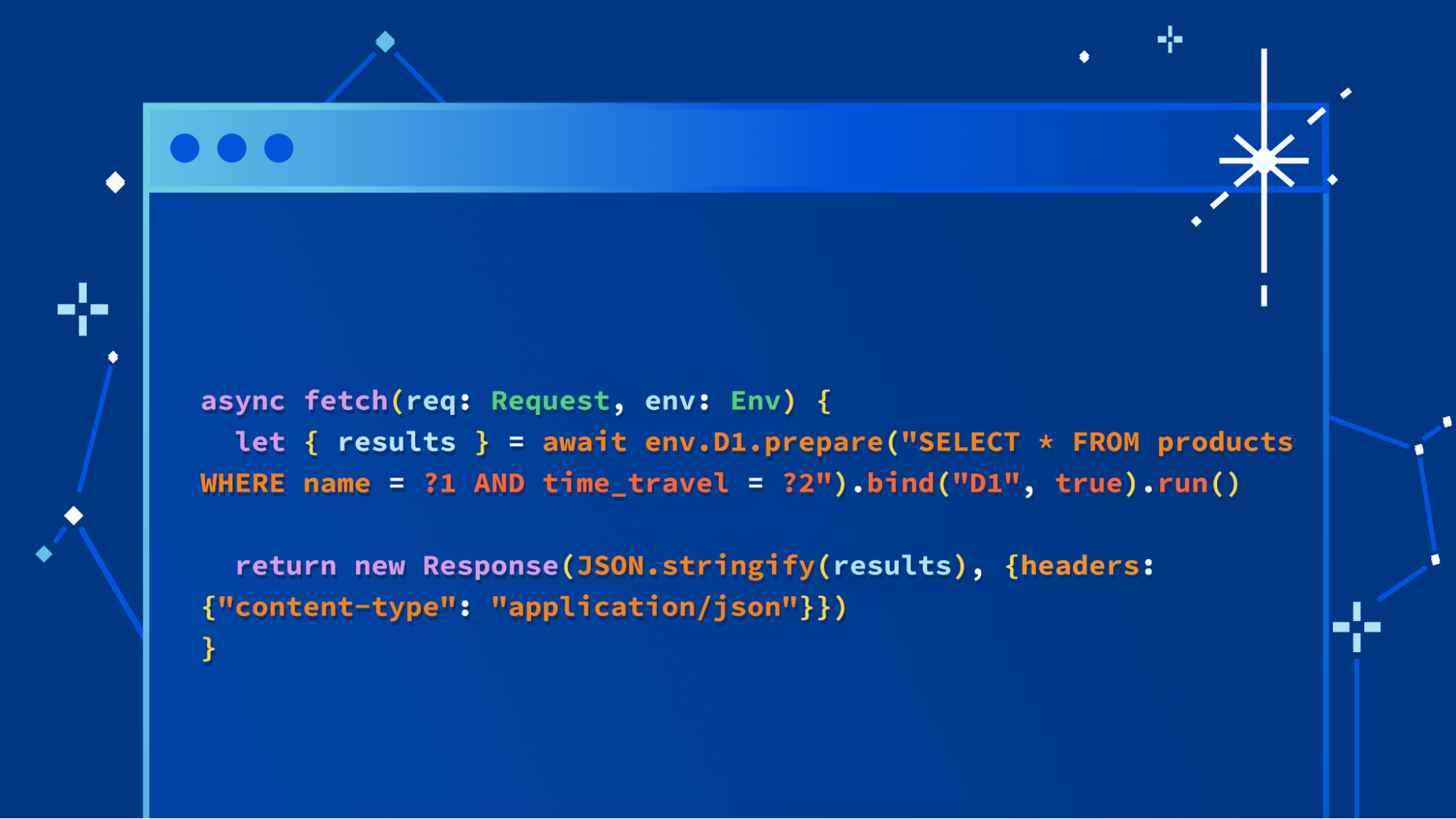
No vamos a eludir el tema: estamos entusiasmados de lanzar una actualización importante de nuestra base de datos D1, con mejoras espectaculares del rendimiento y de la escalabilidad. Los usuarios de la versión Alpha (que incluyen todos los usuarios de Workers) ya pueden crear nuevas bases de datos utilizando el nuevo back-end de almacenamiento mediante el comando siguiente:
$ wrangler d1 create your-database --experimental-backend
Durante las próximas semanas, esto pasará a ser la experiencia por defecto para todos los usuarios, pero queremos invitar a los desarrolladores a que empiecen a probar ya la nueva versión de D1. También proporcionaremos más información sobre cómo hemos desarrollado el nuevo subsistema de almacenamiento de D1, y cómo se beneficia de la red distribuida de Cloudflare, muy pronto.
Refréscame la memoria: ¿Qué es D1?
D1 es una base de datos sin servidor nativa de Cloudflare, cuya versión Alpha lanzamos en noviembre del año pasado. Los desarrolladores han creado aplicaciones complejas con Workers, KV, Durable Objects, y más recientemente, Queues & R2, pero nos han pedido una cosa: una base de datos en la que puedan realizar consultas.
También hemos recopilado numerosos comentarios que nos pedían una solución basada en SQL, "scale-to-zero" (es decir, que pueda escalar a cero instancias, como la propia solución Workers) y con un enfoque global ("Region: Earth") de la réplica. Por lo tanto, hemos tenido en cuenta esos comentarios y nos propusimos desarrollar D1. SQLite nos ofrece un dialecto SQL familiar, un motor de consultas eficaz y una de las bases de código más ampliamente probadas sobre la que desarrollar.
Lanzamos la primera versión de D1 como una versión Alpha "real": fue, para nosotros, una forma de adoptar un enfoque abierto al desarrollo, de recopilar los comentarios directamente de los desarrolladores y de priorizar mejor. Y, haciendo honor a su nombre, esta primera versión Alpha presentaba errores, problemas de rendimiento y una "trayectoria feliz" (es decir, un escenario en el que todas las funciones se ejecutaban de la forma prevista) bastante limitada.
A pesar de eso, hemos observado a los desarrolladores activar miles de bases de datos y ejecutar miles de millones de consultas; ORM populares como Drizzle y Kysely han añadido compatibilidad con D1 (¡ya!), y las plantillas de Remix y Nuxt asimismo ya se han desarrollado directamente en torno a D1.
D1 es ahora ultrarrápida
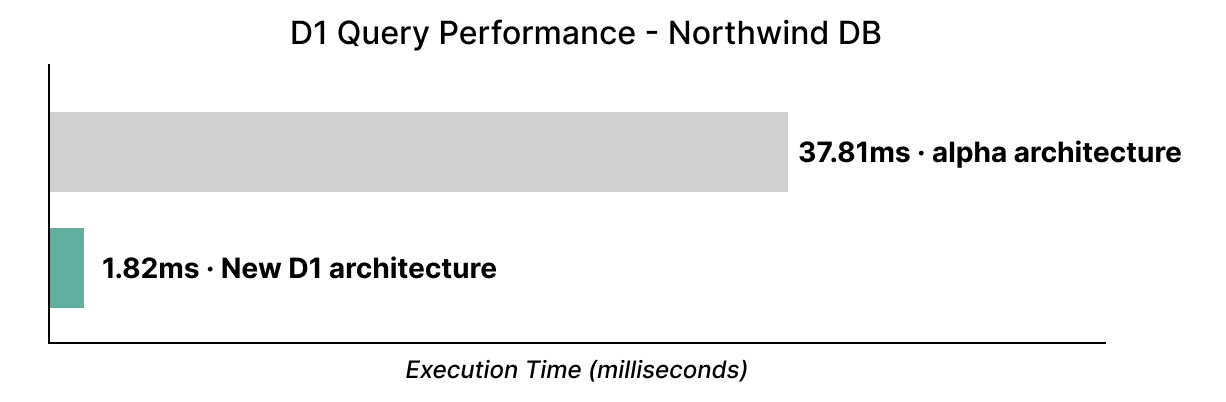
Si, hasta la fecha, has utilizado D1 en su versión Alpha, olvídate de todo lo que sabes. Ahora D1 es muchísimo más rápida: hasta 20 veces más rápida en la conocida demostración Northwind Traders, a la que acabamos de realizar la migración para utilizar nuestro nuevo back-end de almacenamiento:
Nuestra arquitectura también aumenta el rendimiento de la escritura: una sencilla prueba de referencia que inserta 1000 filas (cada fila con una longitud de unos 200 bytes) es aproximadamente 6,8 veces más rápida que la versión anterior de D1.
En el caso de los lotes más grandes (10 000 filas con una longitud de unos 200 bytes) la mejora es aún mayor: la inserción es entre 10 y 11 veces más rápida, y la latencia del nuevo back-end de almacenamiento también es considerablemente más coherente. No hemos empezado aún a optimizar nuestro rendimiento de escritura global. Por lo tanto, esperamos que D1 aún sea más rápida.
Con nuestro nuevo back-end de almacenamiento, quedemos también reivindicar que D1 no es algo que nos tomemos a la ligera, y comparamos continuamente nuestro rendimiento respecto al de otras bases de datos sin servidor. Una consulta en una tabla de clave-valor de 500 000 filas (sabiendo que los valores de referencia son inherentemente sintéticos) muestra que D1 tiene un rendimiento 3,2 veces más rápido que un conocido proveedor Postgres sin servidor:
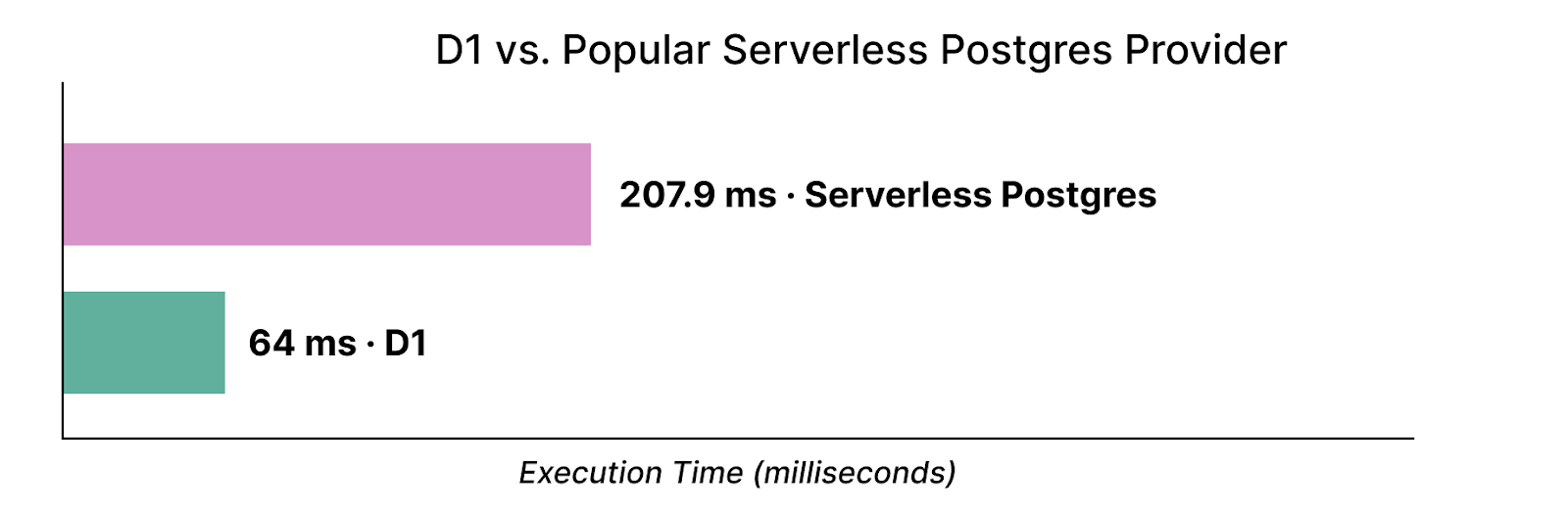
Hemos ejecutado las consultas Postgres varias veces, a fin de preparar la memoria caché de páginas, y a continuación hemos observado el tiempo medio de las consultas, según la medición del servidor. Continuaremos mejorando el rendimiento de nuestra solución a medida que avance su desarrollo.
Los desarrolladores con bases de datos existentes pueden importar los datos en una nueva base de datos respaldada por el motor de almacenamiento siguiendo los pasos descritos en nuestra documentación para exportar su base de datos y luego importarla.
¿Qué me he perdido?
Hemos trabajado también en diversas mejoras de la experiencia que ofrece D1 a los desarrolladores:
- Una nueva interfaz de consola, que te permite emitir consultas directamente desde el panel de control, por lo que es más fácil iniciar y/o emitir consultas puntuales.
- Compatibilidad formal con funciones JSON, que permite ejecutar consultas mediante JSON directamente en tu base de datos.
- Location Hints, que te permite influenciar dónde se encuentra tu líder (responsable de las escrituras) en todo el mundo.
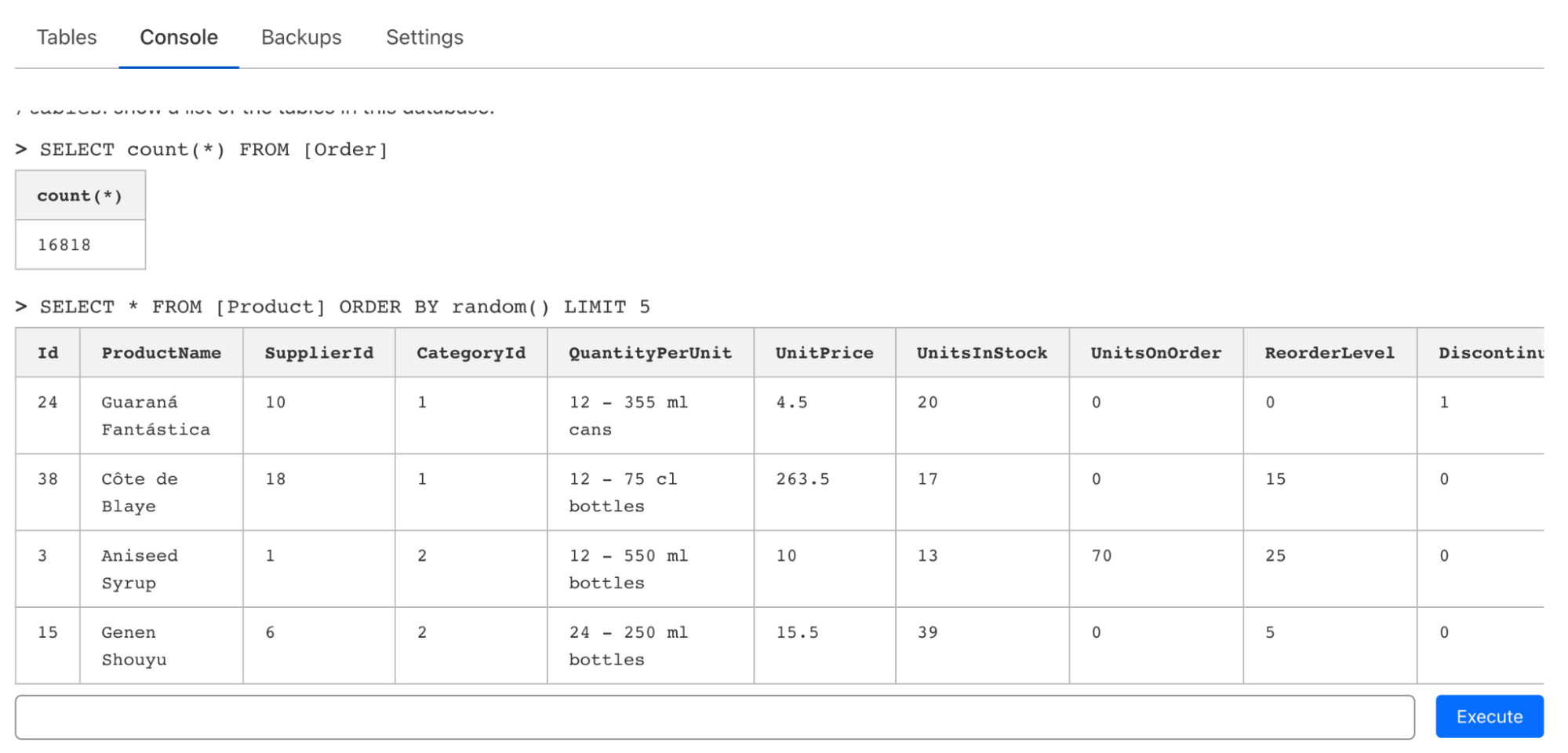
Aunque la solución D1 está diseñada para funcionar de forma nativa en Cloudflare Workers, somos conscientes de que a menudo es necesario emitir rápidamente consultas puntuales mediante la interfaz de línea de comandos o mediante un editor web al crear prototipos o simplemente explorar una base de datos. Además de la compatibilidad en wrangler para la ejecución de consultas (y archivos), también hemos añadido un editor de consola que te permite emitir consultas, inspeccionar tablas y editar datos sobre la marcha:
Las funciones JSON te permiten consultar los valores JSON almacenados en columnas TEXT en D1, y ofrecen flexibilidad respecto a los datos que están estrictamente asociados con tu esquema de base de datos y aquellos que no lo están, al mismo tiempo que puedes consultar todos tus datos mediante SQL (antes de que lleguen a tu aplicación).
Por ejemplo, supongamos que almacenas las indicaciones de fecha y hora del último inicio de sesión como una matriz JSON en una columna TEXT denominada login_history: puedes consultar (y extraer) subobjetos o elementos de matriz directamente proporcionando una ruta a la clave correspondiente:
SELECT user_id, json_extract(login_history, '$.[0]') as latest_login FROM users
La compatibilidad de D1 con las funciones JSON ofrece gran flexibilidad, y se basa en el núcleo SQLite sobre el que se ha desarrollado D1.
Cuando creas una base de datos por primera vez con D1, inferimos automáticamente la ubicación en función del lugar desde el que te estés conectando en ese momento. En algunos casos, sin embargo, es posible que desees cambiar esa opción: cuando estás de viaje, o tu equipo distribuido se encuentra en una región distinta de aquella donde crees que se realizarán la mayoría de las escrituras.
La compatibilidad de D1 con Location Hints facilita el proceso:
# Automatically inferred based your location
$ wrangler d1 create user-prod-db --experimental-backend
# Indicate a preferred location to create your database
$ wrangler d1 create eu-users-db --location=weur --experimental-backend
Location Hints también está disponible en el panel de control de Cloudflare:
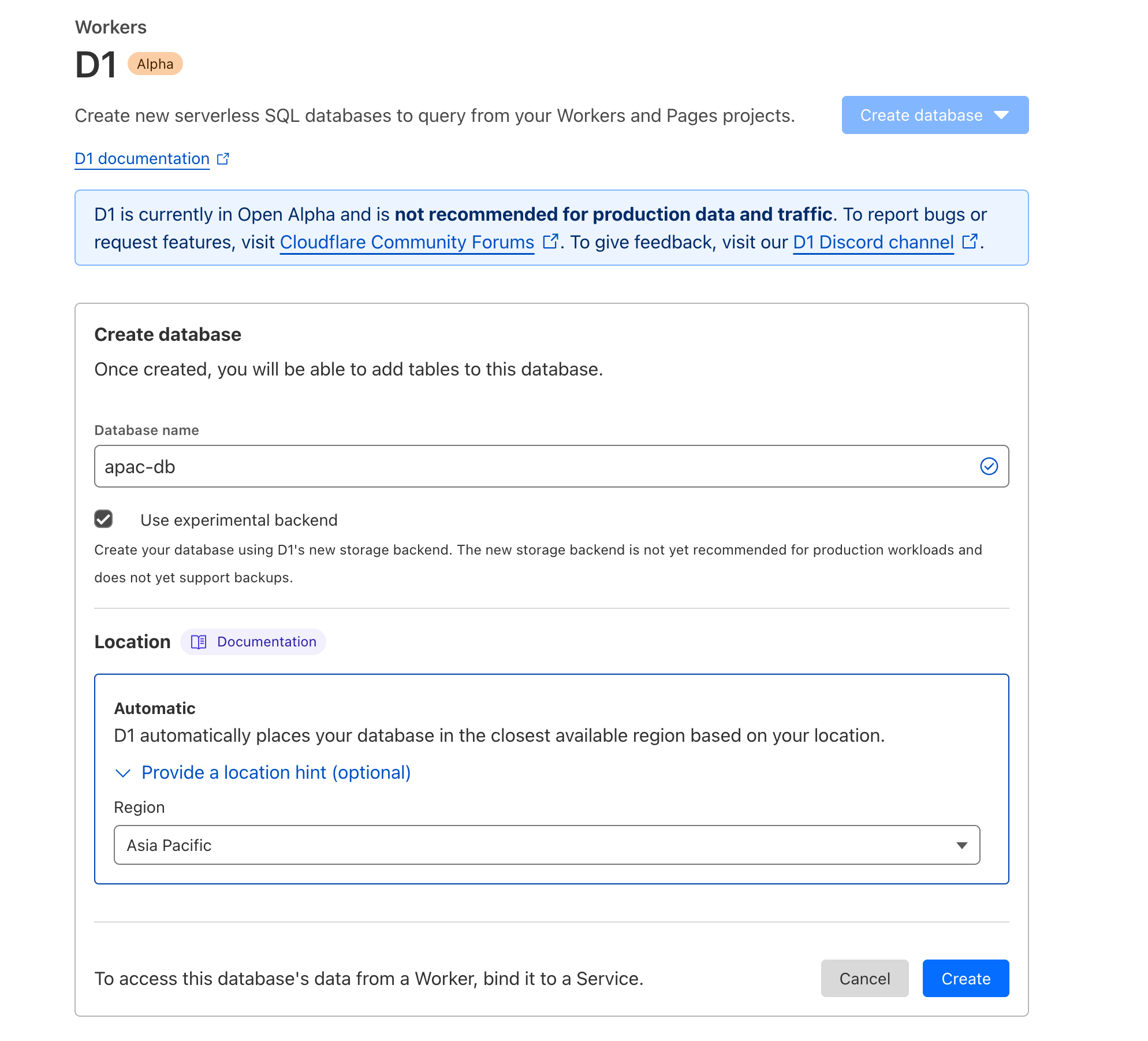
Hemos publicado también documentación adicional con el objetivo de ayudar a los desarrolladores no solo a dar los primeros pasos, sino también a utilizar las funciones avanzadas de D1. Verás que la documentación de D1 se ampliará considerablemente durante los próximos meses.
Una solución que no vaciará tu cartera
Desde que anunciamos la versión Alpha, muchos desarrolladores nos han preguntado acerca de cómo estableceremos las tarifas de D1, y ahora estamos listos para proporcionar esa información. Sabemos que es importante comprender lo que podría costar un servicio antes de empezar a desarrollar sobre él, a fin de no encontrarse sorpresas desagradables seis meses después.
En resumen:
- Anunciamos los precios para que puedas empezar a modelar por adelantado cuánto costará D1 para tu caso de uso. Los precios definitivos pueden estar sujetos a cambios, aunque esperamos que los cambios sean relativamente pequeños.
- No activaremos la facturación hasta más adelante este año, y notificaremos dicho cambio con antelación a los usuarios de D1 existentes mediante correo electrónico. Hasta entonces, la utilización de D1 seguirá siendo gratuita.
- D1 incluirá un nivel siempre gratuito, una utilización incluida como parte de nuestra suscripción de 5 USD/mes de Workers, así como una facturación en función de las lecturas, las escrituras y el almacenamiento.
Si ya estás suscrito a Workers, no necesitas hacer nada: tu suscripción existente incluirá la utilización de D1 cuando en el futuro activemos la facturación.
Aquí te proporcionamos un resumen (lo hemos simplificado intencionadamente):

Una cosa importante: cuando activemos la réplica global en lectura, esto no te supondrá ningún coste adicional, ni la réplica multiplicará tu consumo de espacio de almacenamiento. Creemos que la réplica automática integrada es importante, y no creemos que los desarrolladores deban asumir costes multiplicativos (réplicas x tarifas de almacenamiento) para que sus bases de datos sean rápidas en todas partes.
Además, nos hemos querido asegurar de que D1 incorporaba los mejores elementos de la tarificación sin servidor (es decir, la capacidad "scale-to-zero" y el pago por uso), para que no tengas que intentar determinar cuántas CPU y/o qué cantidad de memoria necesitas para tu carga de trabajo o que no tengas que escribir scripts para reducir tu infraestructura durante los periodos de menor uso.
Los precios de lectura de D1 se basan en el familiar concepto de las unidades de lectura (por 4 KB de datos leídos) y las unidades de escritura (por 1 KB de datos escritos). Una consulta que lea (explore) unas 10 000 filas de 64 bytes cada una consumiría 160 unidades leídas. La escritura de una fila larga de 3 KB en una tabla "blog_posts" que contenga mucho Markdown supone tres unidades escritas. Y si creas índices para tus consultas más frecuentes a fin de mejorar el rendimiento y reducir la cantidad de datos que necesitan explorar esas consultas, reducirás también el importe que te facturaremos. Creemos que el enfoque adecuado es acelerar el proceso de forma más rentable por defecto.
Importante: seguiremos recopilando comentarios sobre nuestras tarifas hasta que las activemos.
Time Travel
Presentamos también una nueva función de copia de seguridad: la recuperación de un punto en el tiempo, que denominamos Time Travel (es decir, "viaje en el tiempo"), porque es exactamente lo que parece. Time Travel te permite restaurar tu base de datos D1 al estado en el que se encontraba en cualquier momento de los últimos 30 días, y se integrará en las bases de datos D1 mediante nuestro nuevo sistema de almacenamiento. Tenemos previsto activar Time Travel para las nuevas bases de datos D1 muy pronto.
Lo que hace que Time Travel sea tan eficaz es que ya no tienes ninguna razón para entrar en pánico y preguntarte "oh, espera, ¿hice una copia de seguridad antes de hacer este cambio importante?!", porque nosotros lo hacemos por ti. Guardamos una secuencia de todos los cambios realizados en tu base de datos (el Write-Ahead Log), lo que nos permite restaurar tu base de datos a un punto en el tiempo reproduciendo esos cambios en secuencia hasta ese momento.
Aquí tienes un ejemplo (sujeto a algunos pequeños cambios de la API):
# Using a precise Unix timestamp (in UTC):
$ wrangler d1 time-travel my-database --before-timestamp=1683570504
# Alternatively, restore prior to a specific transaction ID:
$ wrangler d1 time-travel my-database --before-tx-id=01H0FM2XHKACETEFQK2P5T6BWD
Y aunque la idea de la recuperación a un punto en el tiempo no es nueva, suele ser un complemento de pago, si es que está disponible. Si te das cuenta de que deberías haberla activado una vez que ya has suprimido datos o cometido algún otro error, ya es demasiado tarde.
Por ejemplo, imagina que cometo el típico error de olvidar WHERE en una sentencia UPDATE:
-- Don't do this at home
UPDATE users SET email = '[email protected]' -- missing: WHERE id = "abc123"
Sin Time Travel, esperaría que se hubiera ejecutado recientemente una copia de seguridad planificada, o que me hubiera acordado de realizar una copia de seguridad manual justo antes. Gracias a Time Travel, puedo restaurar a un punto situado un minuto o dos antes ese error (y esperar haber aprendido la lección para la próxima vez).
Estamos analizando también funciones que puedan identificar los cambios más importantes en el estado de tu base de datos, como facilitar la identificación de las modificaciones de esquema, del número de tablas, de diferencias importantes en los datos almacenados e incluso de consultas específicas (mediante los identificadores de transacción), a fin de ayudarte a comprender mejor exactamente a qué momento preciso debes restaurar tu base de datos.
En la hoja de ruta
Entonces, ¿cuáles serán las siguientes innovaciones en D1?
- Versión Beta abierta: nos aseguramos de haber observado nuestro nuevo subsistema de almacenamiento bajo carga (y en condiciones de utilización reales) antes de que sea el valor por defecto para todos los comandos "d1 create". Ponemos el listón muy alto en materia de durabilidad y disponibilidad, incluso para una versión "beta", y también reconocemos que el acceso a las copias de seguridad (Time Travel) es importante para que los usuarios confíen en una nueva base de datos. No pierdas de vista las publicaciones del blog de Cloudflare durante las próximas semanas para mantenerte informado acerca de las últimas novedades.
- Bases de datos de mayor volumen: sabemos que esto es una demanda importante para muchos, y estamos a punto de lograrlo. Los desarrolladores del plan de Workers de pago podrán acceder muy pronto a bases de datos de 1 GB, y continuaremos aumentando el tamaño máximo por base de datos con el tiempo.
- Métricas y observabilidad: podrás inspeccionar el volumen global de consultas por base de datos, las consultas que han fallado, el almacenamiento consumido y las unidades de lectura/escritura tanto mediante el panel de control de D1 como mediante nuestra GraphQL, así que podrás depurar más fácilmente los problemas y realizar un seguimiento del gasto.
- Replica automática en lectura: nuestro nuevo subsistema de almacenamiento se ha concebido básicamente para la réplica, y estamos trabajando para garantizar que nuestra capa de réplica sea rápida y fiable antes de ofrecérsela a los desarrolladores. La réplica en lectura no solo se ha desarrollado para mejorar la latencia de las consultas mediante el almacenamiento de copias (las réplicas) de los datos en varias ubicaciones, cerca de los usuarios. También nos permitirá garantizar la escalabilidad horizontal de las bases de datos D1 para los usuarios con cargas de trabajo más grandes.
Mientras tanto, ya puedes empezar a crear prototipos y probar D1, explorar nuestro proyecto de ejemplo de D1 + Drizzle + Remix, o unirte al canal #d1 en el servidor Cloudflare Developers Discord a fin de interactuar directamente con el equipo de D1 y otros usuarios que desarrollan D1.