


はじめに
本日2022年6月21日、Cloudflareの19か所のデータセンターにおいて、トラフィックに影響を与える障害が発生しました。折り悪くこの19か所の拠点は当社最大の拠点であり、全世界のトラフィック処理の大半を占めています。この障害は、当社のインフラの重要な一部であり、Cloudflareのトラフィックの大部分を処理する当社最大の拠点における耐障害性を高めるための長期的なプロジェクトの一環として行われた変更により発生したものです。06:27 UTC、今回の障害の原因となったネットワーク設定の変更をこれらの拠点で実施。06:58 UTC、最初のデータセンターがオンラインになる。07:42 UTC、すべてのデータセンターがオンラインになり、正常稼働となる。
お客様の拠点によっては、Cloudflareを使用するWebサイトやサービスにアクセスできない場合があります。その他の拠点では、Cloudflareは通常通り稼動しております。
この度は、ご迷惑をおかけして大変申し訳ございませんでした。これは当社のミスが引き起こしたものであり、攻撃や悪意ある行為によるものではございません。
背景
この18か月に渡り、Cloudflareは当社最大の拠点をすべて、より冗長性の高いアーキテクチャに移行するために取り組んでまいりました。今回、社内ではMulti-Colo PoP(MCP)と呼んでいる19のデータセンター(アムステルダム、アトランタ、アッシュバーン、シカゴ、フランクフルト、ロンドン、ロサンゼルス、マドリッド、マンチェスター、マイアミ、ミラノ、ムンバイ、ニューアーク、大阪、サンパウロ、サンノゼ、シンガポール、シドニー、東京)を、このアーキテクチャに移行しております。
Closネットワークとして設計されたこの新しいアーキテクチャに関する重要な点は、メッシュ型の接続を確立するルーティングレイヤーを追加したことです。このメッシュ型により、メンテナンス時や問題発生時に、データセンターの内部ネットワークの一部を簡単に無効化・有効化することができます。このレイヤーは、次の図のスパインで示しています。
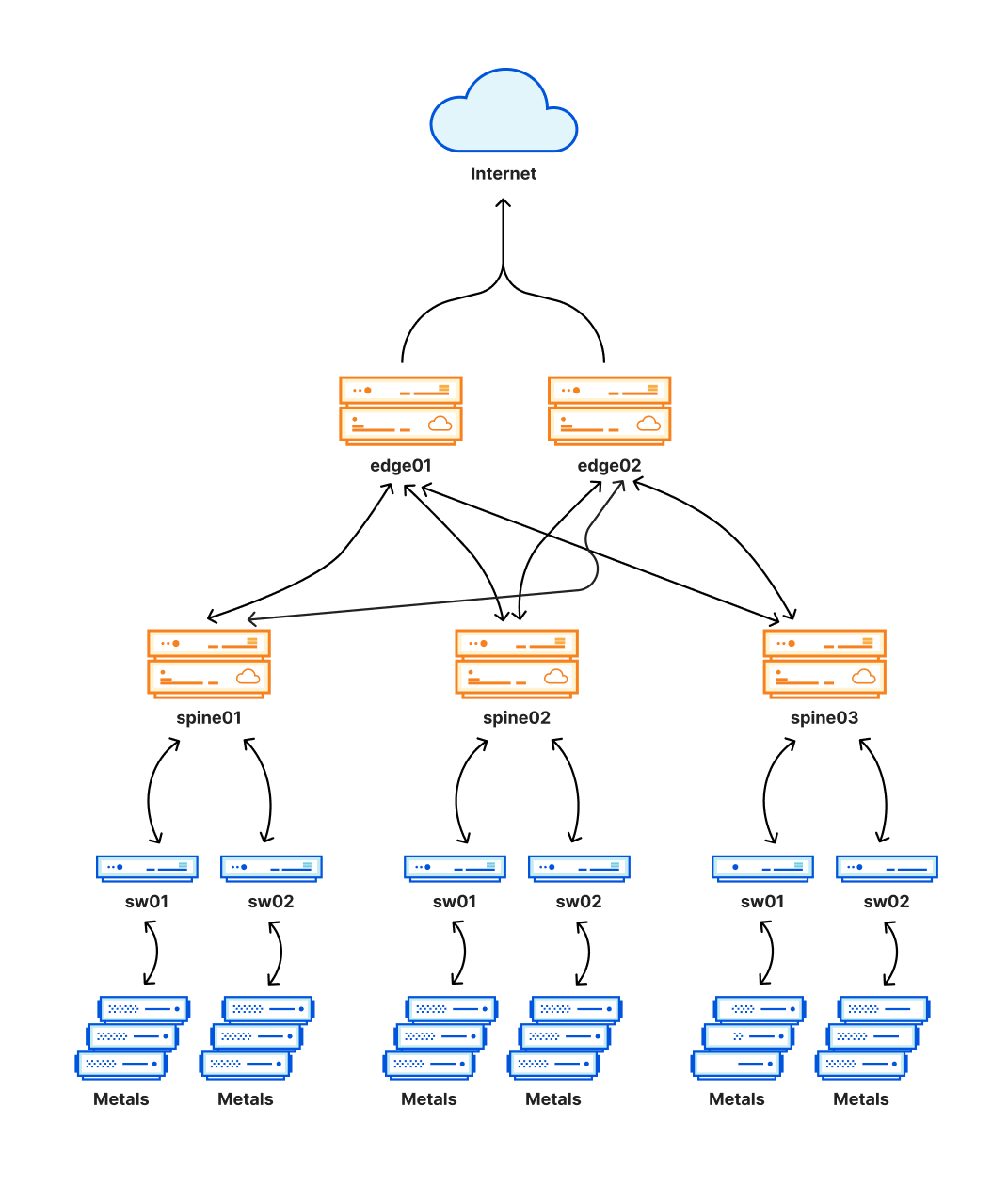
この新しいアーキテクチャは、信頼性を大幅に向上させ、お客様のトラフィックを妨げることなく、これらの拠点でメンテナンスを実行することができるようにするものです。これらの拠点はCloudflareのトラフィックの大半を占めているため、ここで問題が発生すると非常に広範囲に影響を及ぼす可能性があり、残念ながら本日そのような事態が発生してしまいました。
インシデントのタイムライン(UTC)と影響について
Cloudflareのようなネットワークでは、インターネット上で到達可能であるためにBGPと呼ばれるプロトコルを使用しています。このプロトコルの一部として、オペレータは、どのプレフィックス(隣接するIPアドレスの集合)をピア(接続する他のネットワーク)にアドバタイズするか、またはピアから受け入れるかを決定するポリシーを定義します。
これらのポリシーには個々のコンポーネントがあり、順次評価されます。最終結果として、与えられたプレフィックスがアドバタイズされる、またはアドバタイズされないということになります。ポリシーを変更することで、以前アドバタイズされたプレフィックスがアドバタイズされなくなる場合があります。その場合そのプレフィックスが失われ、それらのIPアドレスがインターネット上に到達できなくなります。
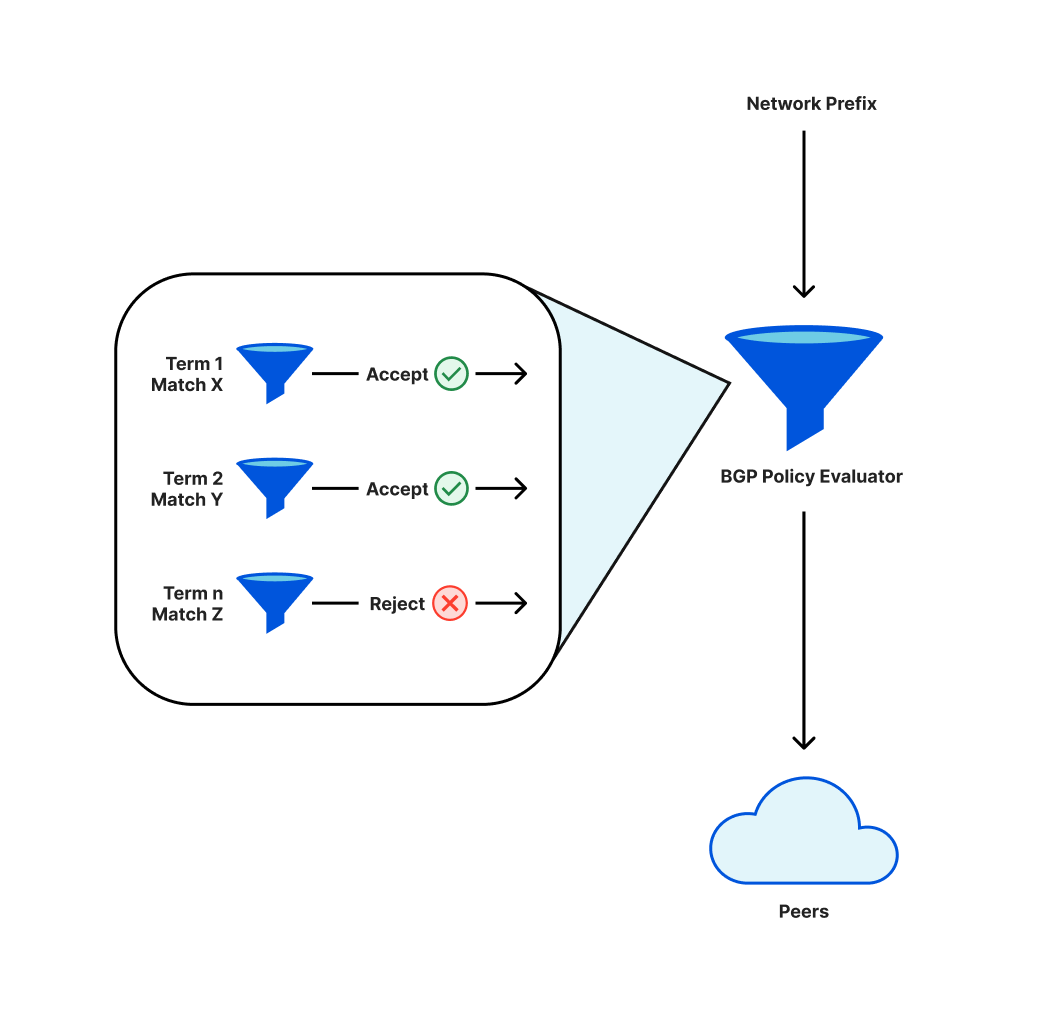
プレフィックスについてアドバタイズポリシーの変更をデプロイした際、条件の並べ替えにより、重要なプレフィックスのサブセットが削除されてしまいました。
削除されたことにより、Cloudflareのエンジニアが問題のある変更を元に戻すために、影響のあった拠点に到達することがさらに困難なものになりました。このような事態に対処するためのバックアップ手順があるため、それを使用して影響のあった拠点の制御を行いました。
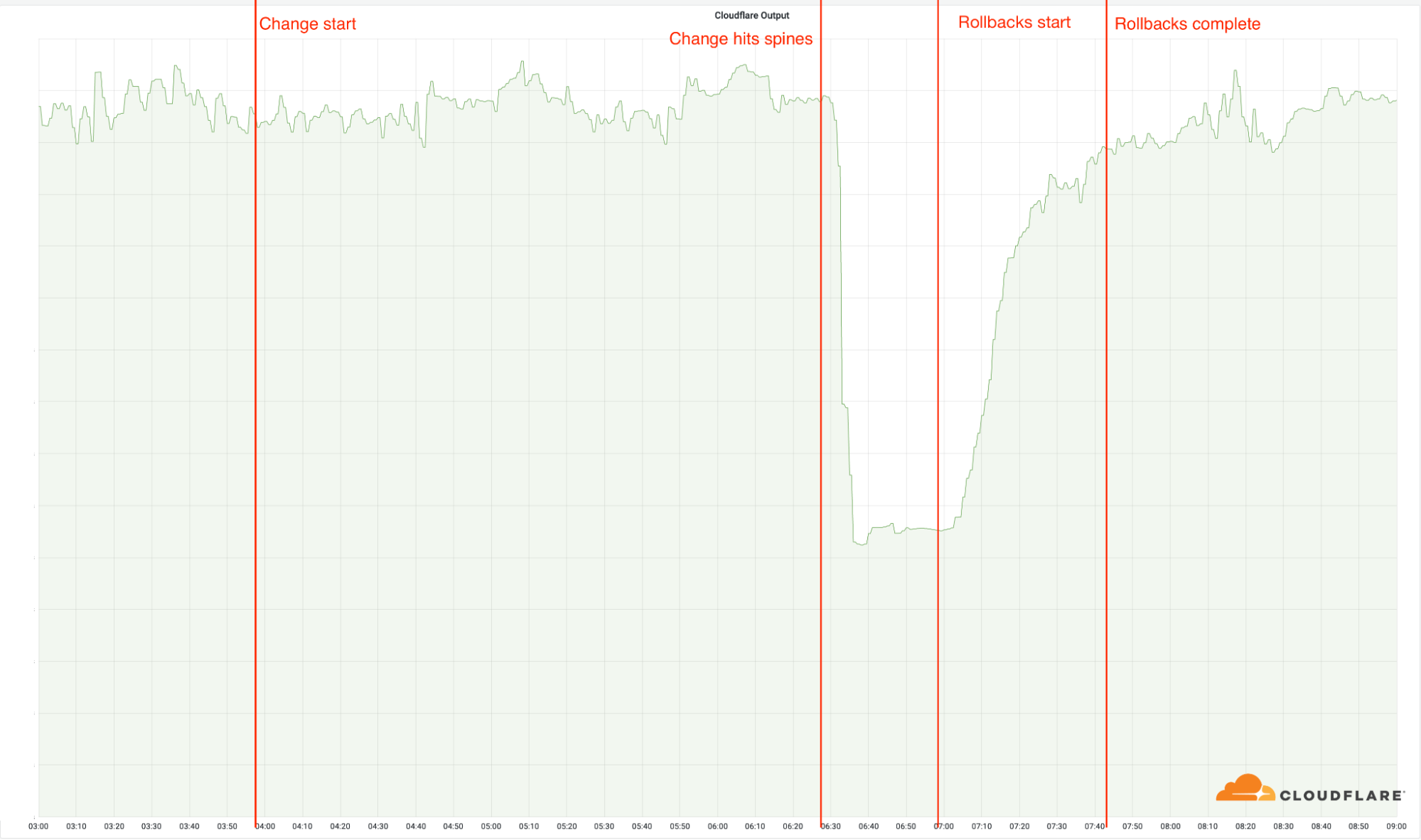
03:56: 最初の拠点に変更を展開。これらの拠点は古いアーキテクチャを使用しているため、どの拠点もこの変更の影響を受けることはありません。
06:17: この変更が新しいアーキテクチャ以外の最大の拠点に展開される。
06:27: ロールアウトが新しいアーキテクチャの当社最大の拠点に到達し、スパイン部分に変更が展開される。インシデントが発生したのはこの時点で、この19か所の拠点が一気にオフラインとなりました。
06:32: Cloudflareの内部でインシデントが宣言される。
06:51:根本原因の可能性を検証するために、ルーターに初回の変更を加える。
06:58:根本原因を確認して状況を把握。問題のある変更を元に戻す作業を開始。
07:42:最終の差し戻しが完了。ネットワークエンジニアが互いの変更点を確認し合い、以前の状態に戻したため、散発的に問題が再発してしまい、この作業に遅れが生じました。
08:00:インシデントをクローズ。
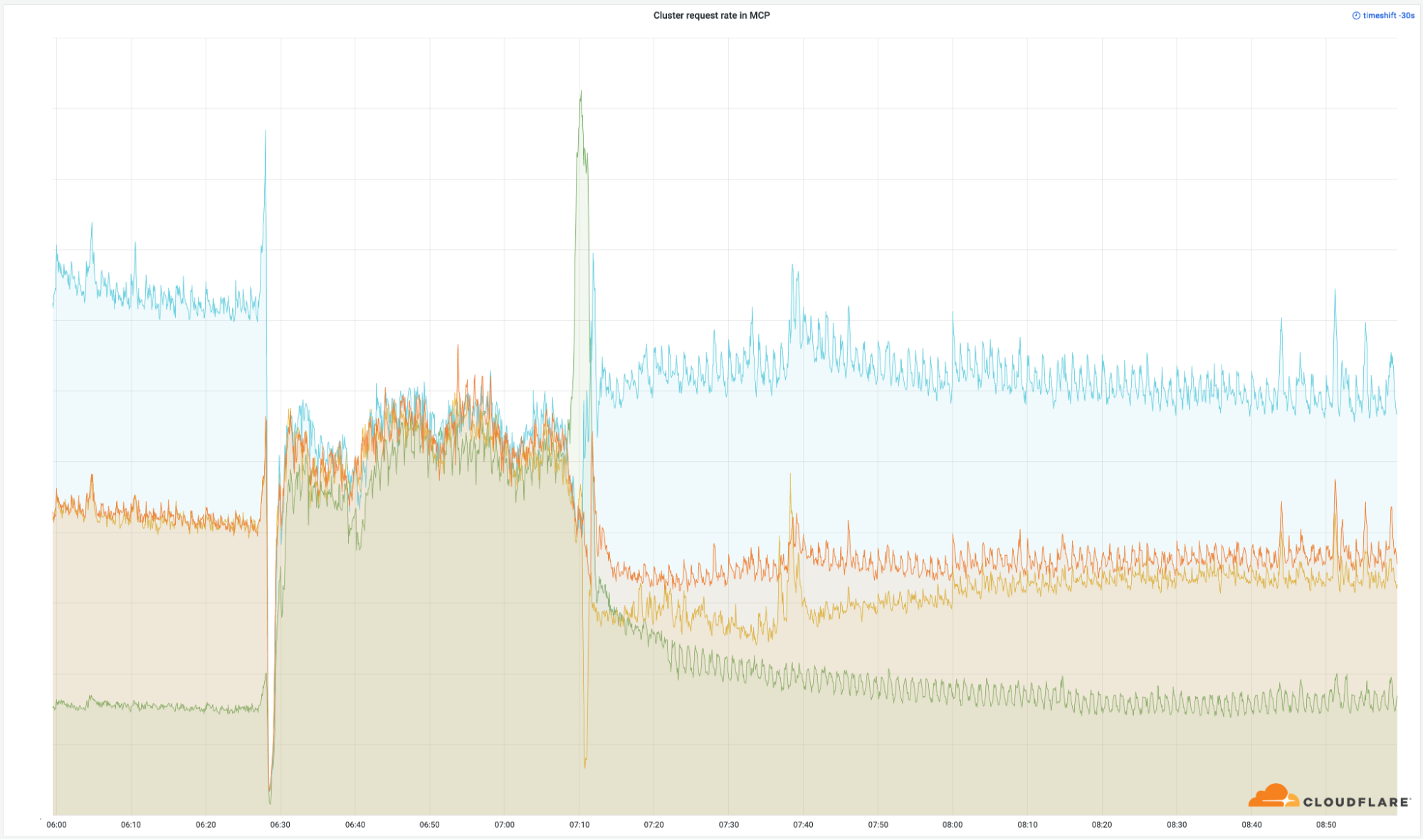
これらのデータセンターの重要性は、以下に示す当社が世界中のリクエストに正常に返信した数に明確に表れています。
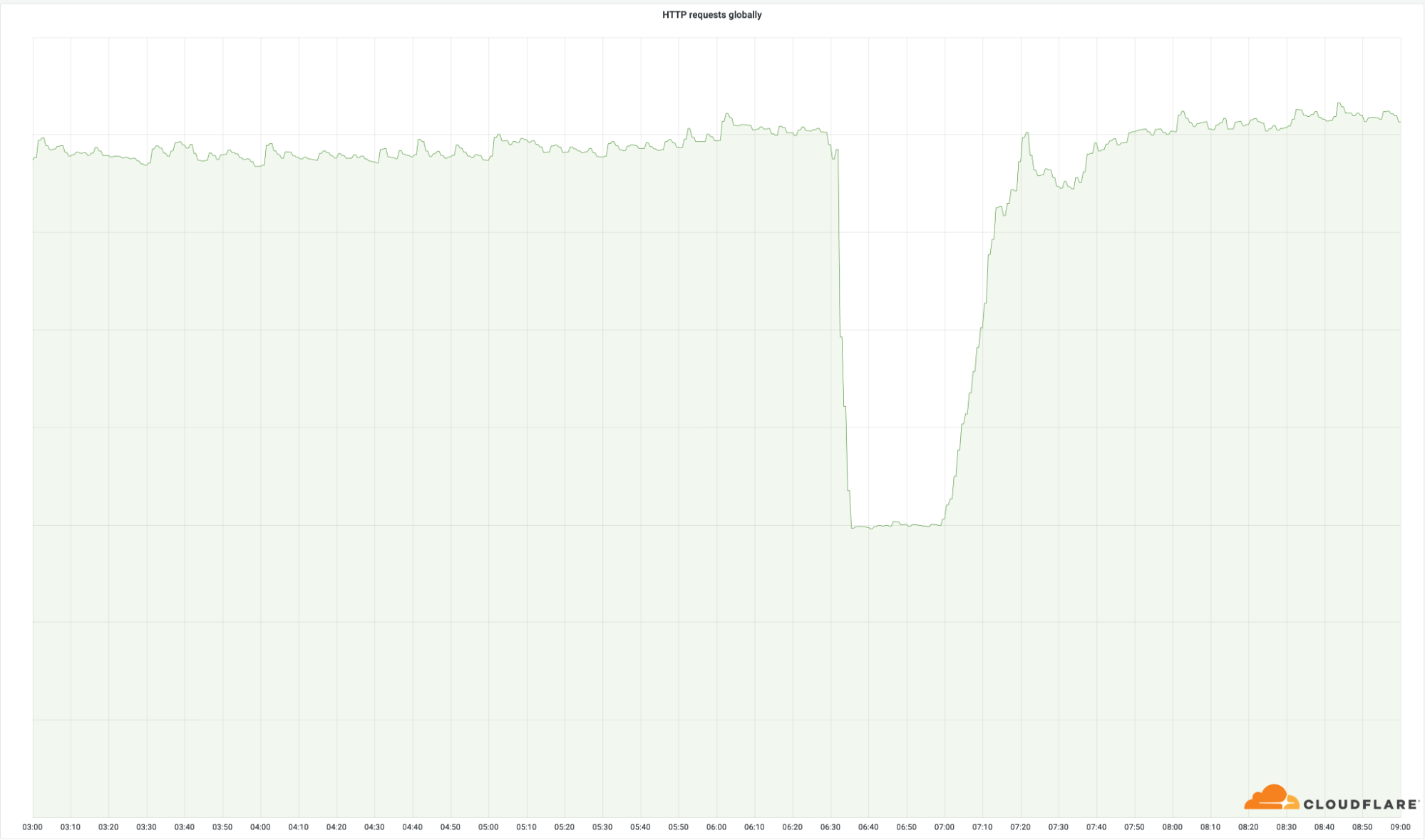
これらの拠点の数は、当社のネットワーク全体のわずかな割合(4%)であるにもかかわらず、当社の総リクエストの50%に影響を与えました。同じことが、エグレス帯域幅にも見られます。
障害の技術的説明と発生原因について
インフラストラクチャの構成の標準化に向けた継続的な取り組みの一環として、アドバタイズするプレフィックスのサブセットに付加するBGPコミュニティを標準化するための変更を展開しておりました。具体的には、サイトローカルのプレフィックスに情報コミュニティを追加していました。これらのプレフィックスにより、計算ノード同士の通信や、お客様のオリジンへの接続が可能になります。Cloudflareの変更手順の一部として、変更のドライランと段階的なロールアウト手順を含む変更要求(CR)チケットが作成されました。また、公開を許可する前に、複数のエンジニアによるピアレビューも行われました。今回のケースでは、残念なことに当社のスパイン部分にまで到達する前にミスを捉えるステップとして、十分なものではありませんでした。
ルータの1つで、次のような変更が見られました。
[edit policy-options policy-statement 4-COGENT-TRANSIT-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
[edit policy-options policy-statement 4-PUBLIC-PEER-ANYCAST-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
[edit policy-options policy-statement 6-COGENT-TRANSIT-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
[edit policy-options policy-statement 6-PUBLIC-PEER-ANYCAST-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
これは無害なものであり、これらのプレフィックスのアドバタイズにいくつかの追加の情報が加えられるだけのものです。スパインの変化は次のようなものでした。
[edit policy-options policy-statement AGGREGATES-OUT]
term 6-DISABLED_PREFIXES { ... }
! term 6-ADV-TRAFFIC-PREDICTOR { ... }
! term 4-ADV-TRAFFIC-PREDICTOR { ... }
! term ADV-FREE { ... }
! term ADV-PRO { ... }
! term ADV-BIZ { ... }
! term ADV-ENT { ... }
! term ADV-DNS { ... }
! term REJECT-THE-REST { ... }
! term 4-ADV-SITE-LOCALS { ... }
! term 6-ADV-SITE-LOCALS { ... }
[edit policy-options policy-statement AGGREGATES-OUT term 4-ADV-SITE-LOCALS then]
community delete NO-EXPORT { ... }
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add AMS07;
+ community add EUROPE;
[edit policy-options policy-statement AGGREGATES-OUT term 6-ADV-SITE-LOCALS then]
community delete NO-EXPORT { ... }
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add AMS07;
+ community add EUROPE;
この違いを一見したところで、この変更は同一であるかのような印象を受けるかもしれませんが、残念ながらそうではありません。相違の1つに着目すると、その理由が見えてきます。
! term REJECT-THE-REST { ... }
! term 4-ADV-SITE-LOCALS { ... }
! term 6-ADV-SITE-LOCALS { ... }
この差分フォーマットでは、条件の前にある感嘆符は、条件の順序を入れ替えることを示します。このケースでは、複数の条件が上に移動し、2つの条件が下に追加されています。具体的には、4-ADV-SITE-LOCALSの条件が上から下へ移動しています。この条件は、REJECT-THE-RESTの条件の後ろにありましたが、名前からわかるとおり、この条件は明示的な拒否を示すものです。
term REJECT-THE-REST {
then reject;
}
この条件がサイトローカルの条件より前に位置するため、直ちにサイトローカルのプレフィックスのアドバタイズが停止され、影響を受けたすべての拠点への当社の直接アクセスが一気に削除され、当社のサーバーがオリジンに到達する能力も削除されました。
オリジンに接続できないことに加え、これらのサイトローカルプレフィックスが削除されたことにより、内部負荷分散システムMultimog(Unimogロードバランサーのバリエーション)も動作を停止し、MCPのサーバー間でリクエスト転送ができなくなりました。このため、MCP内の小規模な計算クラスタが当社最大のクラスタと同じ量のトラフィックを受け、小規模なクラスタが過負荷になる事態が発生しました。
改善とフォローアップのステップ
今回のインシデントは広範囲に影響を及ぼしており、当社では可用性について非常に重く受け止めております。当社はいくつかの領域における改善点の特定に至りましたが、今後も再発の原因となるその他のギャップの発見に努めてまいります。
当社が直後から取り組んでいる内容は以下のとおりです。
プロセス:MCPプログラムは可用性を向上させるために設計されたものですが、これらのデータセンターを更新する手順に不備があったため、結果的に広範囲、特にMCPの拠点に影響を引き起こしてしまいました。この変更には段階的な手順を使用しましたが、この段階的なポリシーには最終ステップまでMCPデータセンターが含まれていませんでした。変更手順と自動化には、意図しない結果を招かないように、MCP固有のテストと展開の手順を含めます。
アーキテクチャ:ルーター設定の不備により、適切なルートがエッジにアナウンスされず、トラフィックが当社のインフラストラクチャに適切に流れなくなりました。最終的には、不備のあるルーティングアドバタイズの原因となったポリシーステートメントを、意図しない誤った順序付けを防止するよう再設計します。
自動化:当社の自動化スイートには、今回の事象による影響の一部または全部を軽減するための可能性がいくつか存在します。主に、ネットワーク設定のロールアウトを段階的に行うポリシーの改善と、「コミット-確認」の自動ロールバックの実現などの自動化の改善に注力します。前者の改善によって全体的な影響が大幅に軽減され、後者の改善にって、インシデント発生時の解決時間が大幅に短縮されます。
まとめ
Cloudflareはサービスの可用性を高めるためにMCPの設計に多大な投資を行ってまいりましたが、今回の痛ましいインシデントにより、多くのお客様の期待を裏切る結果となってしまいました。お客様、および停止中にインターネットの資源にアクセスできなかったすべてのユーザーにご迷惑をおかけしましたことを深くお詫び申し上げます。私たちはすでに上記の変更に取り組み始めており、このような事態が二度と起こらないように努力を続けます。