


Workerアプリを構築する開発者は、必要なインフラストラクチャではなく作成するものに集中し、Cloudflareネットワークのグローバルなリーチを活用しています。個人的プロジェクトからビジネスクリティカルなワークロードまで、アプリケーションの多くは永続データを必要とします。Workersは開発者のニーズに合わせて、キーバリューやオブジェクトストレージなど、さまざまなデータベースとストレージのオプションを提供します。
リレーショナルデータベースは今日、多くのアプリケーションのバックボーンになっています。Cloudflareのリレーショナルデータベースを補完する D1は、現在一般公開されています。2022年末のアルファ版から2024年4月のGA版までに至るまでの過程では、開発者が慣れ親しんだリレーショナルデータとSQLで本番ワークロードを構築できるようにすることに重点を置きました。
D1とは?
D1は、Cloudflareに組み込まれたサーバレスのリレーショナルデータベースです。Workerアプリでは、D1がSQLiteのSQL方言を活用してSQLの表現力を提供し、Drizzle ORMのようなオブジェクトリレーショナルマッパー(ORM)を含めた開発者ツールの統合を可能にします。D1には、WorkersまたはHTTP APIを通じてアクセスできます。
サーバレスでプロビジョニングが不要。Time Travelによるディザスタリカバリ機能がデフォルトで組み込まれており、利用料金は従量制です。D1には無料枠がたっぷりあるため、開発者はD1で実験し、本番環境に移行することができます。
データをグローバル化するには?
D1のGA版では、信頼性と開発者体験に重点を置きました。 当社は現在、グローバルに分散されたアプリケーションのサポートを強化するためにD1の拡張を計画しています。
Workersモデルでは、着信リクエストが最寄りのデータセンターでのサーバレス実行を呼び出します。 Workerアプリは、ユーザーのリクエストに応じてグローバルに拡張できます。 しかし、アプリケーションデータは中央集中型のデータベースに保存されたままであり、グローバルユーザートラフィックはデータロケーションへのアクセスラウンドトリップを考慮する必要があります。例えば、現在のD1データベースは一か所に存在します。
Workersは、頻繁にアクセスされるデータの局所性を考慮するSmart Placementをサポートしています。Smart Placementは、データベースなど中央集中型のバックエンドサービスに近いWorkerを呼び出すことで遅延を減らし、アプリケーションのパフォーマンスを向上させます。こうしてグローバルアプリのWorker配置については解決しましたが、データ配置を解決する必要があります。
では、CloudflareのビルトインデータベースソリューションD1は、どうすればグローバルアプリケーションのデータ配置のサポートを強化できるのでしょうか。 その答えは、非同期読み取りレプリケーションです。
非同期読み取りレプリケーションとは?
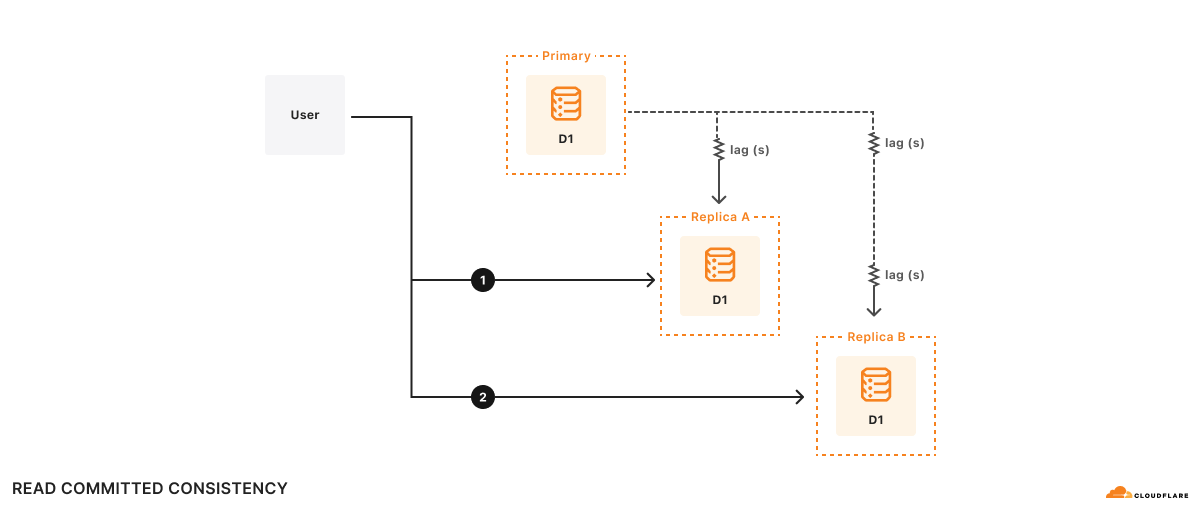
Postgres、MySQL、SQL Server、Oracleといったサーバベースのデータベース管理システムにおけるリードレプリカは、プライマリデータベースサーバのほぼリアルタイムの読み取り専用コピーとして機能する別のデータベースサーバです。管理者は、プライマリサーバのスナップショットから新しいサーバを起動し、プライマリサーバがレプリカサーバに更新を非同期で送信するように設定することで、リードレプリカを作成します。更新は非同期に行われるため、リードレプリカはプライマリサーバの現在の状態より遅れている可能性があります。プライマリサーバとレプリカの差は、レプリカラグと呼ばれます。複数のリードレプリカを持つことも可能です。
非同期読み取りレプリケーションは、データベースのパフォーマンスを向上させる手段として実績のあるソリューションです:
- 複数のレプリカに負荷を分散することで、スループットを向上できます。
- クエリを作成するユーザーの近くにレプリカを配置することで、クエリの遅延を低減できます。
データベースシステムによっては、同期レプリケーションを提供するものもあります。 同期レプリケーション方式のシステムでは、書き込みはすべてのレプリカが書き込みを確認するまで待たなければなりません。 同期レプリケーション方式のシステムは、最も遅いレプリカと同じ速度でしか実行できず、レプリカに障害が発生すると停止します。 グローバル規模でパフォーマンスを向上させようとするなら、同期レプリケーションはできるだけ避けたいものです!
一貫性モデルとリードレプリカ
ほとんどのデータベースシステムは、設定に応じてコミット済み読み取り、スナップショット分離、または直列化可能の一貫性モデルを提供しています。例えば、Postgresのデフォルトはコミット済み読み取りですが、より厳密なモードを使用するように設定できます。SQLiteはWALモードでスナップショット分離を提供しています。スナップショット分離や直列化可能のような厳密なモードは、許容されるシステム並行性のシナリオや、プログラマが心配しなければならない並行性の競合状態の種類を制限するため、プログラムするのが容易です。
リードレプリカは独立して更新されるため、各レプリカの内容は常に異なる可能性があります。プライマリであろうとリードレプリカであろうと、同じサーバにすべてのクエリが送られるのであれば、基礎となるデータベースが提供する一貫性モデルに従って、一貫した結果になるはずです。リードレプリカを使用していれば結果が少し古いかもしれないというだけのことです。
リードレプリカを使用するサーバベースのデータベースでは、セッション内のすべてのクエリで同じサーバを使用することが重要です。 同じセッションで別のリードレプリカに切り替えると、アプリケーションが提供する一貫性モデルが損なわれて、データベースの動作に関する仮定に違反し、アプリケーションが正しくない結果を返す場合があります!
例
例えば、AとBの2つのレプリカがあり、レプリカAはプライマリデータベースから100ms遅れ、レプリカBはプライマリデータベースから2s遅れています。 あるユーザーが次のように望んだとします:
- クエリ1の実行
1a. クエリ1の結果に基づいて計算 - (1a)の計算結果に基づいてクエリ2を実行
時刻t=10sでクエリ1はレプリカAに行って返ります。 クエリ1が見るのは、t=9.9sのプライマリデータベースの状態です。 計算に500msかかるとすると、t=10.5sでクエリ2はレプリカBに行きます。レプリカBはプライマリデータベースより2s遅れているため、t=10.5sでクエリ2はt=8.5sのデータベースを見ることになります。 このアプリケーションに関する限り、クエリ2の結果はデータベースが過去に遡ったように見えます!
形式的には、コミットされたデータのみをクエリが参照するためコミット済み読み取りの一貫性ですが、それ以外の保証はありません。自分の書き込みを読み取れる保証すらないのです。コミット済み読み取りは有効な一貫性モデルですが、コミット済み読み取りモデルが許容するすべての競合状態を推論することは難しく、アプリケーションを正しく書くことは困難です。
D1の一貫性モデルとリードレプリカ
D1のデフォルトは、SQLiteが提供するスナップショット分離です。
スナップショット分離は多くの開発者にとって使いやすい一貫性モデルです。D1では、D1データベースのアクティブなコピーを1つだけ確保し、その1つのデータベースへHTTPリクエストを全てルーティングすることで、この一貫性モデルを実装しています。D1データベースのアクティブなコピーが最大1つであることを保証するのは厄介な分散システムの問題ですが、Durable Objectsを使用してD1を構築することで解決しました。Durable Objectはグローバルな一意性を保証するため、一度Durable Objectsに依存すればHTTPリクエストのルーティングは簡単です。D1 Durable Objectへ送ればいいだけです。
データベースのアクティブなコピーが複数あると、一般的な着信HTTPリクエストを見て毎回確実に同じレプリカにルーティングすることができないため、この方法は通用しません。残念ながら、前節の例のように関連するリクエストを毎回同じレプリカにルーティングしない場合は、当社が提供できる最善の一貫性モデルはコミット済み読み取りとなります。
特定のレプリカに一貫してルーティングすることが不可能な場合、もう一つのアプローチは、リクエストを任意のレプリカにルーティングし、選択されたレプリカがプログラマにとって「理に適った」一貫性モデルに従ってリクエストに応答することを保証することです。リクエストにLamportタイムスタンプを含めることを厭わなければ、どのレプリカを使っても逐次一貫性を実装することができます。逐次一貫性モデルには、「自分の書き込みを読み取る」と「書き込みは読み取りに追従する」などの重要なプロパティと、書き込みの全順序があります。書き込みの全順序とは、すべてのレプリカでトランザクションが同じ順序でコミットされることを意味し、これはまさにトランザクション処理システムに望まれる動作です。逐次一貫性には、システム内のいずれかのエンティティが恣意的に古くなる可能性があるという注意点が伴いますが、APIを設計する際にレプリカの遅延を考慮することができるため、この注意点は当社にとっては機能です。
つまり、D1がすべてのデータベースクエリについてLamportタイムスタンプをアプリケーションに与え、それらのアプリケーションが最後に見たLamportタイムスタンプをD1に伝えれば、逐次一貫性モデルに従ったクエリの動作を各レプリカに決定させることができるという発想です。
レプリカで逐次一貫性を実装する堅牢でシンプルな方法は、次の通りです:
- データベースへの各リクエストとLamportタイムスタンプを関連付けます。 単調増加するコミットトークンが効果的です。
- すべての書き込みクエリをプライマリデータベースに送信し、書き込みの全順序を確保します。
- 任意のレプリカに読み込みクエリを送信しますが、そのレプリカでのクエリ処理は、プライマリデータベースからクエリのLamportタイムスタンプより遅い更新を受信するまで遅延します。
この実装の良いところは、読み込みの多いワークロードが常に同じレプリカに送られるような一般的なケースで高速に動作し、リクエストが異なるレプリカにルーティングされても動作する点です。
スニークプレビュー:SessionsでD1に読み取りレプリケーションを導入
D1に読み取りレプリケーションを導入するために、「セッション(Sessions)」という新概念でD1 APIを拡張します。セッションとは、アプリケーションの1つの論理セッションを成すすべてのクエリをカプセル化したものです。例えば、特定のWebブラウザからのすべてのリクエストもセッションですし、モバイルアプリからのすべてのリクエストもセッションになります。セッションを使う場合、クエリは、プライマリデータベースであれ近くのレプリカであれ、リクエストにとって最も有用なD1データベースのコピーを使用します。D1にセッション機能を実装すれば、セッション内の全クエリについて逐次一貫性を確保できます。
セッションAPIはD1の一貫性モデルを変更するため、開発者は新しいAPIにオプトインする必要があります。既存のD1 APIメソッドに変更はなく、スナップショット分離の一貫性モデルも以前と同じです。ただし、新しいセッションAPIを使って作成したクエリのみがレプリカを使用します。
D1セッションAPIの例です:
export default {
async fetch(request: Request, env: Env) {
// When we create a D1 Session, we can continue where we left off
// from a previous Session if we have that Session's last commit
// token. This Worker will return the commit token back to the
// browser, so that it can send it back on the next request to
// continue the Session.
//
// If we don't have a commit token, make the first query in this
// session an "unconditional" query that will use the state of the
// database at whatever replica we land on.
const token = request.headers.get('x-d1-token') ?? 'first-unconditional'
const session = env.DB.withSession(token)
// Use this Session for all our Workers' routes.
const response = await handleRequest(request, session)
if (response.status === 200) {
// Set the token so we can continue the Session in another request.
response.headers.set('x-d1-token', session.latestCommitToken)
}
return response
}
}
async function handleRequest(request: Request, session: D1DatabaseSession) {
const { pathname } = new URL(request.url)
if (pathname === '/api/orders/list') {
// This statement is a read query, so it will execute on any
// replica that has a commit equal or later than `token` we used
// to create the Session.
const { results } = await session.prepare('SELECT * FROM Orders').all()
return Response.json(results)
} else if (pathname === '/api/orders/add') {
const order = await request.json<Order>()
// This statement is a write query, so D1 will send the query to
// the primary, which always has the latest commit token.
await session
.prepare('INSERT INTO Orders VALUES (?, ?, ?)')
.bind(order.orderName, order.customer, order.value)
.run()
// In order for the application to be correct, this SELECT
// statement must see the results of the INSERT statement above.
// The Session API keeps track of commit tokens for queries
// within the session and will ensure that we won't execute this
// query until whatever replica we're using has seen the results
// of the INSERT.
const { results } = await session
.prepare('SELECT COUNT(*) FROM Orders')
.all()
return Response.json(results)
}
return new Response('Not found', { status: 404 })
}
D1のセッション実装ではコミットトークンを使用します。 コミットトークンは、データベースに対する特定のコミット済みクエリを識別します。D1はコミットトークンを使って、セッション内のクエリの実行順序が逐次的になるようにします。上の例でいうと、D1セッションは、SELECT COUNT(*) というクエリが必ず新しい順序のINSERTの後に実行されるようにます。awaitとawaitの間でレプリカを切り換えたとしても、この逐次性は保証されます。
Workersフェッチハンドラでセッションを開始する方法はいくつかあります。 db.withSession(<condition>) は、以下の引数を受け付けます:
セッションの最後のクエリからコミットトークンを 「ラウンドトリップ」し、それを使って新しいセッションを開始することで、セッションが複数のリクエストにまたがるようにすることができます。 これにより、Webアプリやモバイルアプリのような個々のユーザーエージェントは、ユーザーが見るすべてのクエリに逐次一貫性を持たせることができます。
D1の読み取りレプリケーションはビルトインにし、追加の使用料やストレージコストはなく、レプリカの設定も不要にします。CloudflareがアプリのD1トラフィックを監視し、自動的にデータベースのレプリカを作成して、ユーザーに近い場所にある複数のサーバにユーザートラフィックを分散させます。当社のサーバレスモデルと整合するため、D1開発者がレプリカのプロビジョニングや管理について心配する必要はありません。開発者には、レプリケーションとデータ一貫性のトレードオフに関するアプリの設計に注力していただきたいのです。
当社はグローバルな読み取りレプリケーションに力を入れ、上記の提案の実現に取り組んでいます(Developer Discordの#d1チャンネルでフィードバックを共有してください)。それが実現するまで、いくつかのエキサイティングな新機能を加えたD1 GAをご活用ください。
D1 GAをチェック
当社は、2023年10月にD1のオープンベータ版を提供して以来、重要サービスに求められる信頼性、拡張性、開発者体験を重視してD1を開発してきました。開発者がD1でアプリケーションの構築とデバッグを高速化できるよう、いくつかの新機能に投資しています。
より大きなデータベースで大きく構築
当社は、より大きなデータベースを求める開発者の声に耳を傾けてきました。D1は現在、最大10GBのデータベースをサポートし、Workersの有料プランでは5万件のデータベースをサポートしています。D1のスケールアウトによって、アプリはビジネスエンティティごとのデータベースのユースケースをモデル化することができます。ベータ版になってから、新しいD1データベースが一定期間に処理するリクエストはアルファ版の40倍になっています。
バルクデータのインポートとエクスポート
開発者がデータをインポートおよびエクスポートする理由はさまざまです:
- 異なるデータベースシステムとのデータベース移行テスト
- ローカル開発またはテスト用のデータコピー
- コンプライアンスなどのカスタム要件に対応するための手動バックアップ
D1に対するSQLファイル実行は可能でしたが、大規模なインポートをアトミック操作にし、データベースが中途半端な状態にならないように wrangler d1 execute –file=<filename> を改良しています。wrangler d1 execute のデフォルトもローカル優先になり、リモートの本番用データベースを保護できるようになっています。
当社でご用意したNorthwind Tradersのデモデータベースをインポートするには、スキーマとデータをダウンロードし、SQLファイルを実行します。
npx wrangler d1 create northwind-traders
# omit --remote to run on a local database for development
npx wrangler d1 execute northwind-traders --remote --file=./schema.sql
npx wrangler d1 execute northwind-traders --remote --file=./data.sql
以下を使って、D1データベースのデータとスキーマ、スキーマのみ、またはデータのみをSQLファイルにエクスポートできます:
# database schema & data
npx wrangler d1 export northwind-traders --remote --output=./database.sql
# single table schema & data
npx wrangler d1 export northwind-traders --remote --table='Employee' --output=./table.sql
# database schema only
npx wrangler d1 export <database_name> --remote --output=./database-schema.sql --no-data=true
クエリパフォーマンスのデバッグ
SQLクエリのパフォーマンスを理解し、遅いクエリをデバッグすることは、本番環境ワークロードでは重要なステップです。開発者がクエリパフォーマンスメトリクスを分析できるように、実験用の wrangler d1 insights を追加しました。こちらもGraphQL APIからご利用いただけます。
# To find top 10 queries by average execution time:
npx wrangler d1 insights <database_name> --sort-type=avg --sort-by=time --count=10
開発者ツール
さまざまなコミュニティ開発者プロジェクトがD1をサポートしています。新たに加わったのはPrisma ORMなどで、Prisma ORMはバージョン5.12.0でWorkersとD1をサポートしています。
次のステップ
GAとグローバル読み取りレプリケーション設計で利用可能になった機能は、開発者のアプリケーションに必要なSQLデータベースを提供するためのスタートに過ぎません。まだD1をお使いでない方は、今すぐ利用を開始していただけます。D1の開発者向けドキュメントを見て着想のきっかけにしていただいたり、Developer Discordの#d1チャンネルに参加して他のD1開発者や当社の製品エンジニアリングチームとお話しください。
