
As the scale of Cloudflare’s edge network has grown, we sometimes reach the limits of parts of our architecture. About two years ago we realized that our existing solution for spreading load within our data centers could no longer meet our needs. We embarked on a project to deploy a Layer 4 Load Balancer, internally called Unimog, to improve the reliability and operational efficiency of our edge network. Unimog has now been deployed in production for over a year.
This post explains the problems Unimog solves and how it works. Unimog builds on techniques used in other Layer 4 Load Balancers, but there are many details of its implementation that are tailored to the needs of our edge network.

The role of Unimog in our edge network
Cloudflare operates an anycast network, meaning that our data centers in 200+ cities around the world serve the same IP addresses. For example, our own cloudflare.com website uses Cloudflare services, and one of its IP addresses is 104.17.175.85. All of our data centers will accept connections to that address and respond to HTTP requests. By the magic of Internet routing, when you visit cloudflare.com and your browser connects to 104.17.175.85, your connection will usually go to the closest (and therefore fastest) data center.
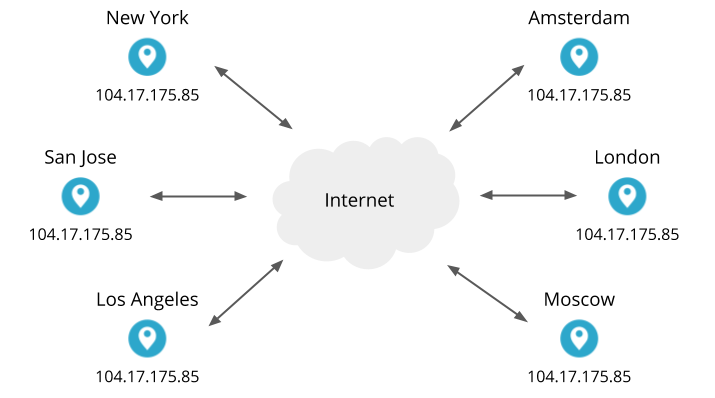
Inside those data centers are many servers. The number of servers in each varies greatly (the biggest data centers have a hundred times more servers than the smallest ones). The servers run the application services that implement our products (our caching, DNS, WAF, DDoS mitigation, Spectrum, WARP, etc). Within a single data center, any of the servers can handle a connection for any of our services on any of our anycast IP addresses. This uniformity keeps things simple and avoids bottlenecks.
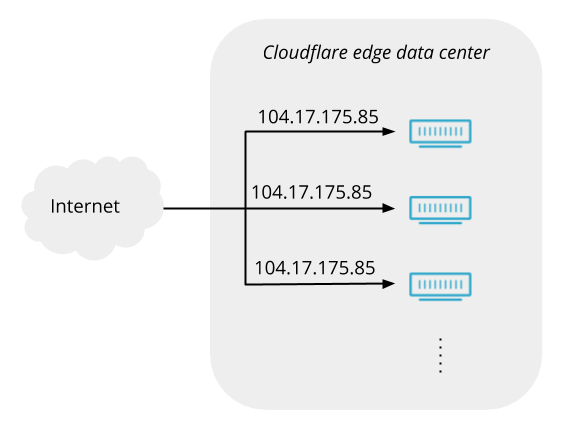
But if any server within a data center can handle any connection, when a connection arrives from a browser or some other client, what controls which server it goes to? That’s the job of Unimog.
There are two main reasons why we need this control. The first is that we regularly move servers in and out of operation, and servers should only receive connections when they are in operation. For example, we sometimes remove a server from operation in order to perform maintenance on it. And sometimes servers are automatically removed from operation because health checks indicate that they are not functioning correctly.
The second reason concerns the management of the load on the servers (by load we mean the amount of computing work each one needs to do). If the load on a server exceeds the capacity of its hardware resources, then the quality of service to users will suffer. The performance experienced by users degrades as a server approaches saturation, and if a server becomes sufficiently overloaded, users may see errors. We also want to prevent servers being underloaded, which would reduce the value we get from our investment in hardware. So Unimog ensures that the load is spread across the servers in a data center. This general idea is called load balancing (balancing because the work has to be done somewhere, and so for the load on one server to go down, the load on some other server must go up).
Note that in this post, we’ll discuss how Cloudflare balances the load on its own servers in edge data centers. But load balancing is a requirement that occurs in many places in distributed computing systems. Cloudflare also has a Layer 7 Load Balancing product to allow our customers to balance load across their servers. And Cloudflare uses load balancing in other places internally.
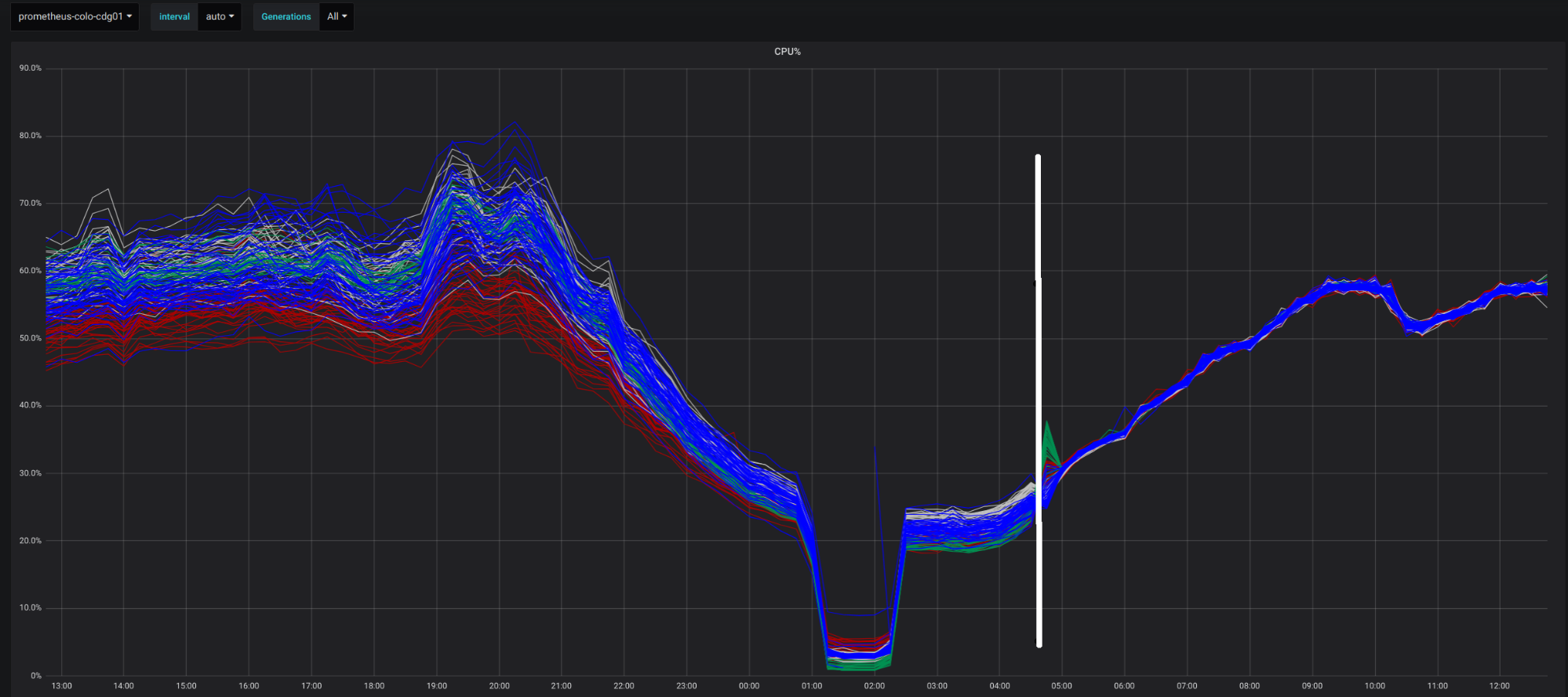
Deploying Unimog led to a big improvement in our ability to balance the load on our servers in our edge data centers. Here’s a chart for one data center, showing the difference due to Unimog. Each line shows the processor utilization of an individual server (the colour of the lines indicates server model). The load on the servers varies during the day with the activity of users close to this data center. The white line marks the point when we enabled Unimog. You can see that after that point, the load on the servers became much more uniform. We saw similar results when we deployed Unimog to our other data centers.
How Unimog compares to other load balancers
There are a variety of techniques for load balancing. Unimog belongs to a category called Layer 4 Load Balancers (L4LBs). L4LBs direct packets on the network by inspecting information up to layer 4 of the OSI network model, which distinguishes them from the more common Layer 7 Load Balancers.
The advantage of L4LBs is their efficiency. They direct packets without processing the payload of those packets, so they avoid the overheads associated with higher level protocols. For any load balancer, it’s important that the resources consumed by the load balancer are low compared to the resources devoted to useful work. At Cloudflare, we already pay close attention to the efficient implementation of our services, and that sets a high bar for the load balancer that we put in front of those services.
The downside of L4LBs is that they can only control which connections go to which servers. They cannot modify the data going over the connection, which prevents them from participating in higher-level protocols like TLS, HTTP, etc. (in contrast, Layer 7 Load Balancers act as proxies, so they can modify data on the connection and participate in those higher-level protocols).
L4LBs are not new. They are mostly used at companies which have scaling needs that would be hard to meet with L7LBs alone. Google has published about Maglev, Facebook open-sourced Katran, and Github has open-sourced their GLB.
Unimog is the L4LB that Cloudflare has built to meet the needs of our edge network. It shares features with other L4LBs, and it is particularly strongly influenced by GLB. But there are some requirements that were not well-served by existing L4LBs, leading us to build our own:
- Unimog is designed to run on the same general-purpose servers that provide application services, rather than requiring a separate tier of servers dedicated to load balancing.
- It performs dynamic load balancing: measurements of server load are used to adjust the number of connections going to each server, in order to accurately balance load.
- It supports long-lived connections that remain established for days.
- Virtual IP addresses are managed as ranges (Cloudflare serves hundreds of thousands of IPv4 addresses on behalf of our customers, so it is impractical to configure these individually).
- Unimog is tightly integrated with our existing DDoS mitigation system, and the implementation relies on the same XDP technology in the Linux kernel.
The rest of this post describes these features and the design and implementation choices that follow from them in more detail.
For Unimog to balance load, it’s not enough to send the same (or approximately the same) number of connections to each server, because the performance of our servers varies. We regularly update our server hardware, and we’re now on our 10th generation. Once we deploy a server, we keep it in service for as long as it is cost effective, and the lifetime of a server can be several years. It’s not unusual for a single data center to contain a mix of server models, due to expansion and upgrades over time. Processor performance has increased significantly across our server generations. So within a single data center, we need to send different numbers of connections to different servers to utilize the same percentage of their capacity.
It’s also not enough to give each server a fixed share of connections based on static estimates of their capacity. Not all connections consume the same amount of CPU. And there are other activities running on our servers and consuming CPU that are not directly driven by connections from clients. So in order to accurately balance load across servers, Unimog does dynamic load balancing: it takes regular measurements of the load on each of our servers, and uses a control loop that increases or decreases the number of connections going to each server so that their loads converge to an appropriate value.
Refresher: TCP connections
The relationship between TCP packets and connections is central to the operation of Unimog, so we’ll briefly describe that relationship.
(Unimog supports UDP as well as TCP, but for clarity most of this post will focus on the TCP support. We explain how UDP support differs towards the end.)
Here is the outline of a TCP packet:
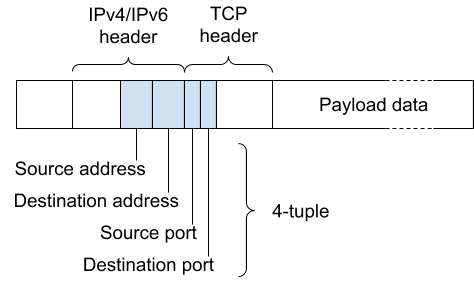
The TCP connection that this packet belongs to is identified by the four labelled header fields, which span the IPv4/IPv6 (i.e. layer 3) and TCP (i.e. layer 4) headers: the source and destination addresses, and the source and destination ports. Collectively, these four fields are known as the 4-tuple. When we say the Unimog sends a connection to a server, we mean that all the packets with the 4-tuple identifying that connection are sent to that server.
A TCP connection is established via a three-way handshake between the client and the server handling that connection. Once a connection has been established, it is crucial that all the incoming packets for that connection go to that same server. If a TCP packet belonging to the connection is sent to a different server, it will signal the fact that it doesn’t know about the connection to the client with a TCP RST (reset) packet. Upon receiving this notification, the client terminates the connection, probably resulting in the user seeing an error. So a misdirected packet is much worse than a dropped packet. As usual, we consider the network to be unreliable, and it’s fine for occasional packets to be dropped. But even a single misdirected packet can lead to a broken connection.
Cloudflare handles a wide variety of connections on behalf of our customers. Many of these connections carry HTTP, and are typically short lived. But some HTTP connections are used for websockets, and can remain established for hours or days. Our Spectrum product supports arbitrary TCP connections. TCP connections can be terminated or stall for many reasons, and ideally all applications that use long-lived connections would be able to reconnect transparently, and applications would be designed to support such reconnections. But not all applications and protocols meet this ideal, so we strive to maintain long-lived connections. Unimog can maintain connections that last for many days.
Forwarding packets
The previous section described that the function of Unimog is to steer connections to servers. We’ll now explain how this is implemented.
To start with, let’s consider how one of our data centers might look without Unimog or any other load balancer. Here’s a conceptual view:
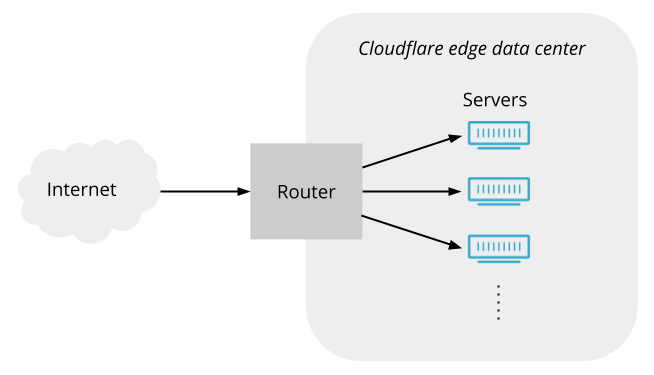
Packets arrive from the Internet, and pass through the router, which forwards them on to servers (in reality there is usually additional network infrastructure between the router and the servers, but it doesn’t play a significant role here so we’ll ignore it).
But is such a simple arrangement possible? Can the router spread traffic over servers without some kind of load balancer in between? Routers have a feature called ECMP (equal cost multipath) routing. Its original purpose is to allow traffic to be spread across multiple paths between two locations, but it is commonly repurposed to spread traffic across multiple servers within a data center. In fact, Cloudflare relied on ECMP alone to spread load across servers before we deployed Unimog. ECMP uses a hashing scheme to ensure that packets on a given connection use the same path (Unimog also employs a hashing scheme, so we’ll discuss how this can work in further detail below) . But ECMP is vulnerable to changes in the set of active servers, such as when servers go in and out of service. These changes cause rehashing events, which break connections to all the servers in an ECMP group. Also, routers impose limits on the sizes of ECMP groups, which means that a single ECMP group cannot cover all the servers in our larger edge data centers. Finally, ECMP does not allow us to do dynamic load balancing by adjusting the share of connections going to each server. These drawbacks mean that ECMP alone is not an effective approach.
Ideally, to overcome the drawbacks of ECMP, we could program the router with the appropriate logic to direct connections to servers in the way we want. But although programmable network data planes have been a hot research topic in recent years, commodity routers are still essentially fixed-function devices.
We can work around the limitations of routers by having the router send the packets to some load balancing servers, and then programming those load balancers to forward packets as we want. If the load balancers all act on packets in a consistent way, then it doesn’t matter which load balancer gets which packets from the router (so we can use ECMP to spread packets across the load balancers). That suggests an arrangement like this:
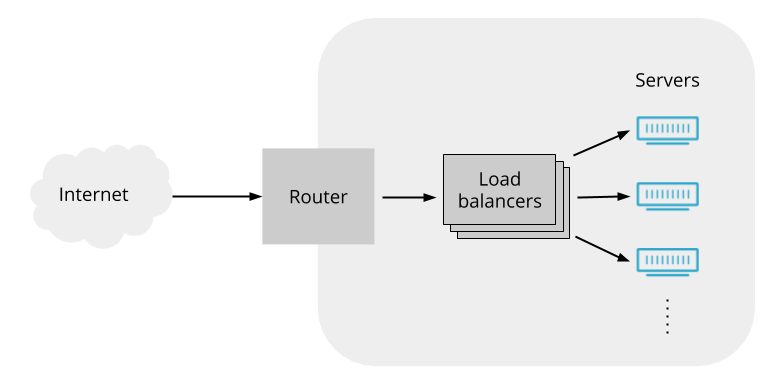
And indeed L4LBs are often deployed like this.
Instead, Unimog makes every server into a load balancer. The router can send any packet to any server, and that initial server will forward the packet to the right server for that connection:
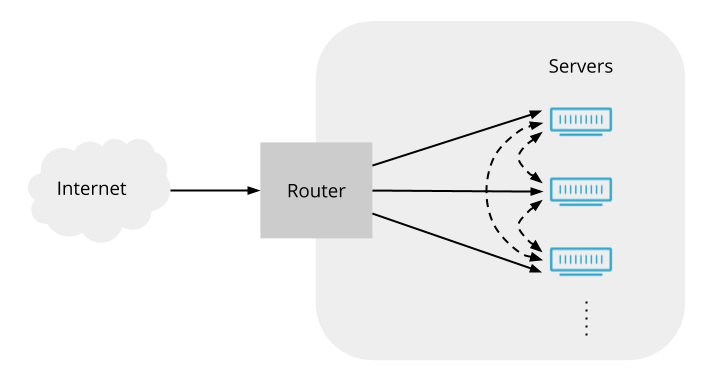
We have two reasons to favour this arrangement:
First, in our edge network, we avoid specialised roles for servers. We run the same software stack on the servers in our edge network, providing all of our product features, whether DDoS attack prevention, website performance features, Cloudflare Workers, WARP, etc. This uniformity is key to the efficient operation of our edge network: we don’t have to manage how many load balancers we have within each of our data centers, because all of our servers act as load balancers.
The second reason relates to stopping attacks. Cloudflare’s edge network is the target of incessant attacks. Some of these attacks are volumetric - large packet floods which attempt to overwhelm the ability of our data centers to process network traffic from the Internet, and so impact our ability to service legitimate traffic. To successfully mitigate such attacks, it’s important to filter out attack packets as early as possible, minimising the resources they consume. This means that our attack mitigation system needs to occur before the forwarding done by Unimog. That mitigation system is called l4drop, and we’ve written about it before. l4drop and Unimog are closely integrated. Because l4drop runs on all of our servers, and because l4drop comes before Unimog, it’s natural for Unimog to run on all of our servers too.
XDP and xdpd
Unimog implements packet forwarding using a Linux kernel facility called XDP. XDP allows a program to be attached to a network interface, and the program gets run for every packet that arrives, before it is processed by the kernel’s main network stack. The XDP program returns an action code to tell the kernel what to do with the packet:
- PASS: Pass the packet on to the kernel’s network stack for normal processing.
- DROP: Drop the packet. This is the basis for l4drop.
- TX: Transmit the packet back out of the network interface. The XDP program can modify the packet data before transmission. This action is the basis for Unimog forwarding.
XDP programs run within the kernel, making this an efficient approach even at high packet rates. XDP programs are expressed as eBPF bytecode, and run within an in-kernel virtual machine. Upon loading an XDP program, the kernel compiles its eBPF code into machine code. The kernel also verifies the program to check that it does not compromise security or stability. eBPF is not only used in the context of XDP: many recent Linux kernel innovations employ eBPF, as it provides a convenient and efficient way to extend the behaviour of the kernel.
XDP is much more convenient than alternative approaches to packet-level processing, particularly in our context where the servers involved also have many other tasks. We have continued to enhance Unimog since its initial deployment. Our deployment model for new versions of our Unimog XDP code is essentially the same as for userspace services, and we are able to deploy new versions on a weekly basis if needed. Also, established techniques for optimizing the performance of the Linux network stack provide good performance for XDP.
There are two main alternatives for efficient packet-level processing:
- Kernel-bypass networking (such as DPDK), where a program in userspace manages a network interface (or some part of one) directly without the involvement of the kernel. This approach works best when servers can be dedicated to a network function (due to the need to dedicate processor or network interface hardware resources, and awkward integration with the normal kernel network stack; see our old post about this). But we avoid putting servers in specialised roles. (Github’s open-source GLB uses DPDK, and this is one of the main factors that made GLB unsuitable for us.)
- Kernel modules, where code is added to the kernel to perform the necessary network functions. The Linux IPVS (IP Virtual Server) subsystem falls into this category. But developing, testing, and deploying kernel modules is cumbersome compared to XDP.
The following diagram shows an overview of our use of XDP. Both l4drop and Unimog are implemented by an XDP program. l4drop matches attack packets, and uses the DROP action to discard them. Unimog forwards packets, using the TX action to resend them. Packets that are not dropped or forwarded pass through to the normal Linux network stack. To support our elaborate use of XDP, we have developed the xdpd daemon which performs the necessary supervisory and support functions for our XDP programs.
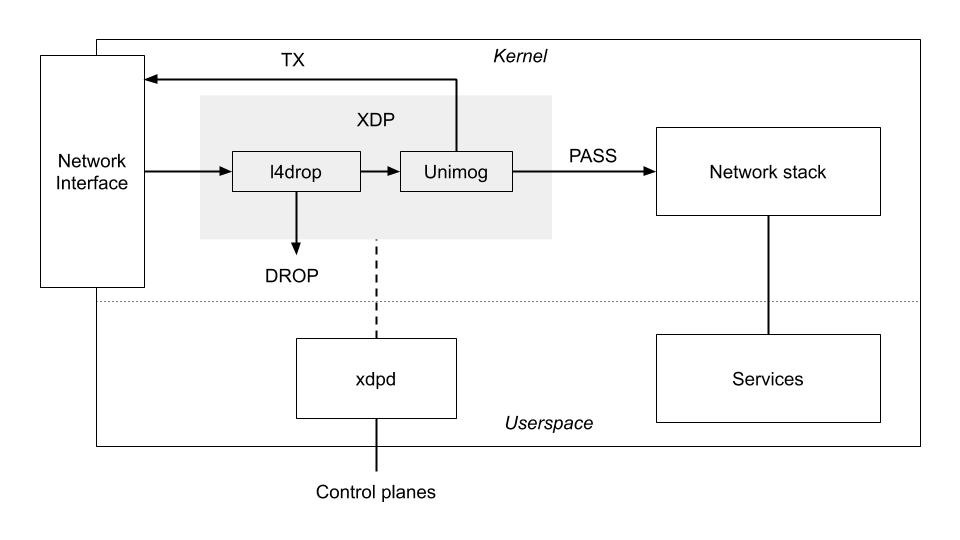
Rather than a single XDP program, we have a chain of XDP programs that must be run for each packet (l4drop, Unimog, and others we have not covered here). One of the responsibilities of xdpd is to prepare these programs, and to make the appropriate system calls to load them and assemble the full chain.
Our XDP programs come from two sources. Some are developed in a conventional way: engineers write C code, our build system compiles it (with clang) to eBPF ELF files, and our release system deploys those files to our servers. Our Unimog XDP code works like this. In contrast, the l4drop XDP code is dynamically generated by xdpd based on information it receives from attack detection systems.
xdpd has many other duties to support our use of XDP:
- XDP programs can be supplied with data using data structures called maps. xdpd populates the maps needed by our programs, based on information received from control planes.
- Programs (for instance, our Unimog XDP program) may depend upon configuration values which are fixed while the program runs, but do not have universal values known at the time their C code was compiled. It would be possible to supply these values to the program via maps, but that would be inefficient (retrieving a value from a map requires a call to a helper function). So instead, xdpd will fix up the eBPF program to insert these constants before it is loaded.
- Cloudflare carefully monitors the behaviour of all our software systems, and this includes our XDP programs: They emit metrics (via another use of maps), which xdpd exposes to our metrics and alerting system (prometheus).
- When we deploy a new version of xdpd, it gracefully upgrades in such a way that there is no interruption to the operation of Unimog or l4drop.
Although the XDP programs are written in C, xdpd itself is written in Go. Much of its code is specific to Cloudflare. But in the course of developing xdpd, we have collaborated with Cilium to develop https://github.com/cilium/ebpf, an open source Go library that provides the operations needed by xdpd for manipulating and loading eBPF programs and related objects. We’re also collaborating with the Linux eBPF community to share our experience, and extend the core eBPF technology in ways that make features of xdpd obsolete.
In evaluating the performance of Unimog, our main concern is efficiency: that is, the resources consumed for load balancing relative to the resources used for customer-visible services. Our measurements show that Unimog costs less than 1% of the processor utilization, compared to a scenario where no load balancing is in use. Other L4LBs, intended to be used with servers dedicated to load balancing, may place more emphasis on maximum throughput of packets. Nonetheless, our experience with Unimog and XDP in general indicates that the throughput is more than adequate for our needs, even during large volumetric attacks.
Unimog is not the first L4LB to use XDP. In 2018, Facebook open sourced Katran, their XDP-based L4LB data plane. We considered the possibility of reusing code from Katran. But it would not have been worthwhile: the core C code needed to implement an XDP-based L4LB is relatively modest (about 1000 lines of C, both for Unimog and Katran). Furthermore, we had requirements that were not met by Katran, and we also needed to integrate with existing components and systems at Cloudflare (particularly l4drop). So very little of the code could have been reused as-is.
Encapsulation
As discussed as the start of this post, clients make connections to one of our edge data centers with a destination IP address that can be served by any one of our servers. These addresses that do not correspond to a specific server are known as virtual IPs (VIPs). When our Unimog XDP program forwards a packet destined to a VIP, it must replace that VIP address with the direct IP (DIP) of the appropriate server for the connection, so that when the packet is retransmitted it will reach that server. But it is not sufficient to overwrite the VIP in the packet headers with the DIP, as that would hide the original destination address from the server handling the connection (the original destination address is often needed to correctly handle the connection).
Instead, the packet must be encapsulated: Another set of packet headers is prepended to the packet, so that the original packet becomes the payload in this new packet. The DIP is then used as the destination address in the outer headers, but the addressing information in the headers of the original packet is preserved. The encapsulated packet is then retransmitted. Once it reaches the target server, it must be decapsulated: the outer headers are stripped off to yield the original packet as if it had arrived directly.
Encapsulation is a general concept in computer networking, and is used in a variety of contexts. The headers to be added to the packet by encapsulation are defined by an encapsulation format. Many different encapsulation formats have been defined within the industry, tailored to the requirements in specific contexts. Unimog uses a format called GUE (Generic UDP Encapsulation), in order to allow us to re-use the glb-redirect component from github’s GLB (glb-redirect is discussed below).
GUE is a relatively simple encapsulation format. It encapsulates within a UDP packet, placing a GUE-specific header between the outer IP/UDP headers and the payload packet to allow extension data to be carried (and we’ll see how Unimog takes advantage of this):
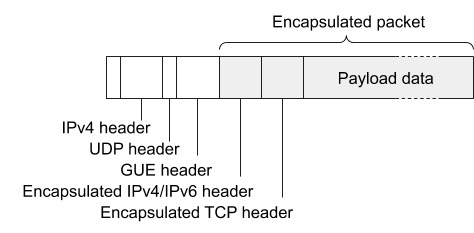
When an encapsulated packet arrives at a server, the encapsulation process must be reversed. This step is called decapsulation. The headers that were added during the encapsulation process are removed, leaving the original packet to be processed by the network stack as if it had arrived directly from the client.
An issue that can arise with encapsulation is hitting limits on the maximum packet size, because the encapsulation process makes packets larger. The de-facto maximum packet size on the Internet is 1500 bytes, and not coincidentally this is also the maximum packet size on ethernet networks. For Unimog, encapsulating a 1500-byte packet results in a 1536-byte packet. To allow for these enlarged encapsulated packets, we have enabled jumbo frames on the networks inside our data centers, so that the 1500-byte limit only applies to packets headed out to the Internet.
Forwarding logic
So far, we have described the technology used to implement the Unimog load balancer, but not how our Unimog XDP program selects the DIP address when forwarding a packet. This section describes the basic scheme. But as we’ll see, there is a problem, so then we’ll describe how this scheme is elaborated to solve that problem.
In outline, our Unimog XDP program processes each packet in the following way:
- Determine whether the packet is destined for a VIP address. Not all of the packets arriving at a server are for VIP addresses. Other packets are passed through for normal handling by the kernel’s network stack. (xdpd obtains the VIP address ranges from the Unimog control plane.)
- Determine the DIP for the server handling the packet’s connection.
- Encapsulate the packet, and retransmit it to the DIP.
In step 2, note that all the load balancers must act consistently - when forwarding packets, they must all agree about which connections go to which servers. The rate of new connections arriving at a data center is large, so it’s not practical for load balancers to agree by communicating information about connections amongst themselves. Instead L4LBs adopt designs which allow the load balancers to reach consistent forwarding decisions independently. To do this, they rely on hashing schemes: Take the 4-tuple identifying the packet’s connection, put it through a hash function to obtain a key (the hash function ensures that these key values are uniformly distributed), then perform some kind of lookup into a data structure to turn the key into the DIP for the target server.
Unimog uses such a scheme, with a data structure that is simple compared to some other L4LBs. We call this data structure the forwarding table, and it consists of an array where each entry contains a DIP specifying the target server for the relevant packets (we call these entries buckets). The forwarding table is generated by the Unimog control plane and broadcast to the load balancers (more on this below), so that it has the same contents on all load balancers.
To look up a packet’s key in the forwarding table, the low N bits from the key are used as the index for a bucket (the forwarding table is always a power-of-2 in size):
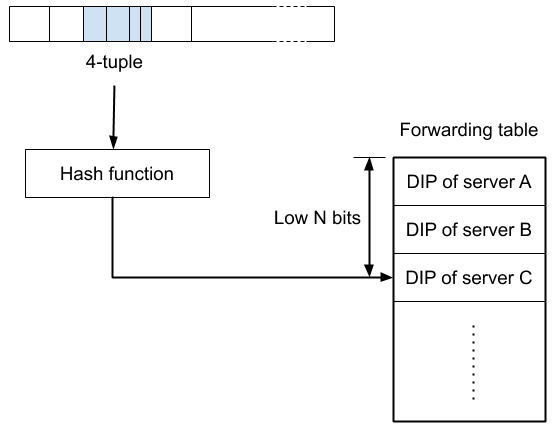
Note that this approach does not provide per-connection control - each bucket typically applies to many connections. All load balancers in a data center use the same forwarding table, so they all forward packets in a consistent manner. This means it doesn’t matter which packets are sent by the router to which servers, and so ECMP re-hashes are a non-issue. And because the forwarding table is immutable and simple in structure, lookups are fast.
Although the above description only discusses a single forwarding table, Unimog supports multiple forwarding tables, each one associated with a trafficset - the traffic destined for a particular service. Ranges of VIP addresses are associated with a trafficset. Each trafficset has its own configuration settings and forwarding tables. This gives us the flexibility to differentiate how Unimog behaves for different services.
Precise load balancing requires the ability to make fine adjustments to the number of connections arriving at each server. So we make the number of buckets in the forwarding table more than 100 times the number of servers. Our data centers can contain hundreds of servers, and so it is normal for a Unimog forwarding table to have tens of thousands of buckets. The DIP for a given server is repeated across many buckets in the forwarding table, and by increasing or decreasing the number of buckets that refer to a server, we can control the share of connections going to that server. Not all buckets will correspond to exactly the same number of connections at a given point in time (the properties of the hash function make this a statistical matter). But experience with Unimog has demonstrated that the relationship between the number of buckets and resulting server load is sufficiently strong to allow for good load balancing.
But as mentioned, there is a problem with this scheme as presented so far. Updating a forwarding table, and changing the DIPs in some buckets, would break connections that hash to those buckets (because packets on those connections would get forwarded to a different server after the update). But one of the requirements for Unimog is to allow us to change which servers get new connections without impacting the existing connections. For example, sometimes we want to drain the connections to a server, maintaining the existing connections to that server but not forwarding new connections to it, in the expectation that many of the existing connections will terminate of their own accord. The next section explains how we fix this scheme to allow such changes.
Maintaining established connections
To make changes to the forwarding table without breaking established connections, Unimog adopts the “daisy chaining” technique described in the paper Stateless Datacenter Load-balancing with Beamer.
To understand how the Beamer technique works, let’s look at what can go wrong when a forwarding table changes: imagine the forwarding table is updated so that a bucket which contained the DIP of server A now refers to server B. A packet that would formerly have been sent to A by the load balancers is now sent to B. If that packet initiates a new connection (it’s a TCP SYN packet), there’s no problem - server B will continue the three-way handshake to complete the new connection. On the other hand, if the packet belongs to a connection established before the change, then the TCP implementation of server B has no matching TCP socket, and so sends a RST back to the client, breaking the connection.
This explanation hints at a solution: the problem occurs when server B receives a forwarded packet that does not match a TCP socket. If we could change its behaviour in this case to forward the packet a second time to the DIP of server A, that would allow the connection to server A to be preserved. For this to work, server B needs to know the DIP for the bucket before the change.
To accomplish this, we extend the forwarding table so that each bucket has two slots, each containing the DIP for a server. The first slot contains the current DIP, which is used by the load balancer to forward packets as discussed (and here we refer to this forwarding as the first hop). The second slot preserves the previous DIP (if any), in order to allow the packet to be forwarded again on a second hop when necessary.
For example, imagine we have a forwarding table that refers to servers A, B, and C, and then it is updated to stop new connections going to server A, but maintaining established connections to server A. This is achieved by replacing server A’s DIP in the first slot of any buckets where it appears, but preserving it in the second slot:
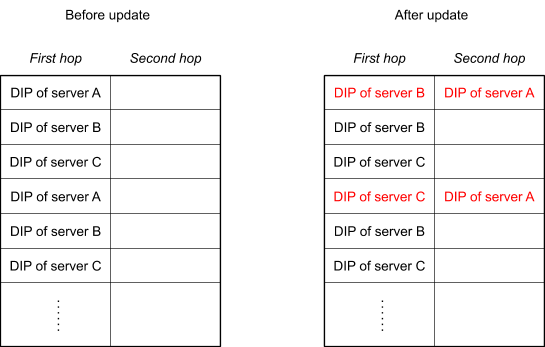
In addition to extending the forwarding table, this approach requires a component on each server to forward packets on the second hop when necessary. This diagram shows where this redirector fits into the path a packet can take:
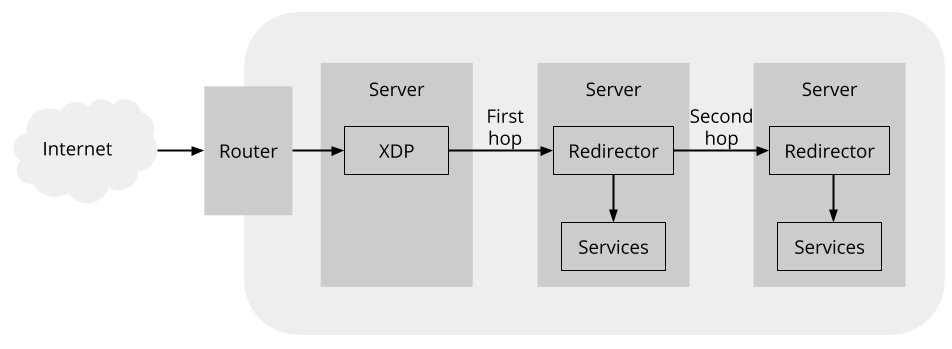
The redirector follows some simple logic to decide whether to process a packet locally on the first-hop server or to forward it on the second-hop server:
- If the packet is a SYN packet, initiating a new connection, then it is always processed by the first-hop server. This ensures that new connections go to the first-hop server.
- For other packets, the redirector checks whether the packet belongs to a connection with a corresponding TCP socket on the first-hop server. If so, it is processed by that server.
- Otherwise, the packet has no corresponding TCP socket on the first-hop server. So it is forwarded on to the second-hop server to be processed there (in the expectation that it belongs to some connection established on the second-hop server that we wish to maintain).
In that last step, the redirector needs to know the DIP for the second hop. To avoid the need for the redirector to do forwarding table lookups, the second-hop DIP is placed into the encapsulated packet by the Unimog XDP program (which already does a forwarding table lookup, so it has easy access to this value). This second-hop DIP is carried in a GUE extension header, so that it is readily available to the redirector if it needs to forward the packet again.
This second hop, when necessary, does have a cost. But in our data centers, the fraction of forwarded packets that take the second hop is usually less than 1% (despite the significance of long-lived connections in our context). The result is that the practical overhead of the second hops is modest.
When we initially deployed Unimog, we adopted the glb-redirect iptables module from github’s GLB to serve as the redirector component. In fact, some implementation choices in Unimog, such as the use of GUE, were made in order to facilitate this re-use. glb-redirect worked well for us initially, but subsequently we wanted to enhance the redirector logic. glb-redirect is a custom Linux kernel module, and developing and deploying changes to kernel modules is more difficult for us than for eBPF-based components such as our XDP programs. This is not merely due to Cloudflare having invested more engineering effort in software infrastructure for eBPF; it also results from the more explicit boundary between the kernel and eBPF programs (for example, we are able to run the same eBPF programs on a range of kernel versions without recompilation). We wanted to achieve the same ease of development for the redirector as for our XDP programs.
To that end, we decided to write an eBPF replacement for glb-redirect. While the redirector could be implemented within XDP, like our load balancer, practical concerns led us to implement it as a TC classifier program instead (TC is the traffic control subsystem within the Linux network stack). A downside to XDP is that the packet contents prior to processing by the XDP program are not visible using conventional tools such as tcpdump, complicating debugging. TC classifiers do not have this downside, and in the context of the redirector, which passes most packets through, the performance advantages of XDP would not be significant.
The result is cls-redirect, a redirector implemented as a TC classifier program. We have contributed our cls-redirect code as part of the Linux kernel test suite. In addition to implementing the redirector logic, cls-redirect also implements decapsulation, removing the need to separately configure GUE tunnel endpoints for this purpose.
There are some features suggested in the Beamer paper that Unimog does not implement:
- Beamer embeds generation numbers in the encapsulated packets to address a potential corner case where a ECMP rehash event occurs at the same time as a forwarding table update is propagating from the control plane to the load balancers. Given the combination of circumstances required for a connection to be impacted by this issue, we believe that in our context the number of affected connections is negligible, and so the added complexity of the generation numbers is not worthwhile.
- In the Beamer paper, the concept of daisy-chaining encompasses third hops etc. to preserve connections across a series of changes to a bucket. Unimog only uses two hops (the first and second hops above), so in general it can only preserve connections across a single update to a bucket. But our experience is that even with only two hops, a careful strategy for updating the forwarding tables permits connection lifetimes of days.
To elaborate on this second point: when the control plane is updating the forwarding table, it often has some choice in which buckets to change, depending on the event that led to the update. For example, if a server is being brought into service, then some buckets must be assigned to it (by placing the DIP for the new server in the first slot of the bucket). But there is a choice about which buckets. A strategy of choosing the least-recently modified buckets will tend to minimise the impact to connections.
Furthermore, when updating the forwarding table to adjust the balance of load between servers, Unimog often uses a novel trick: due to the redirector logic, exchanging the first-hop and second-hop DIPs for a bucket only affects which server receives new connections for that bucket, and never impacts any established connections. Unimog is able to achieve load balancing in our edge data centers largely through forwarding table changes of this type.
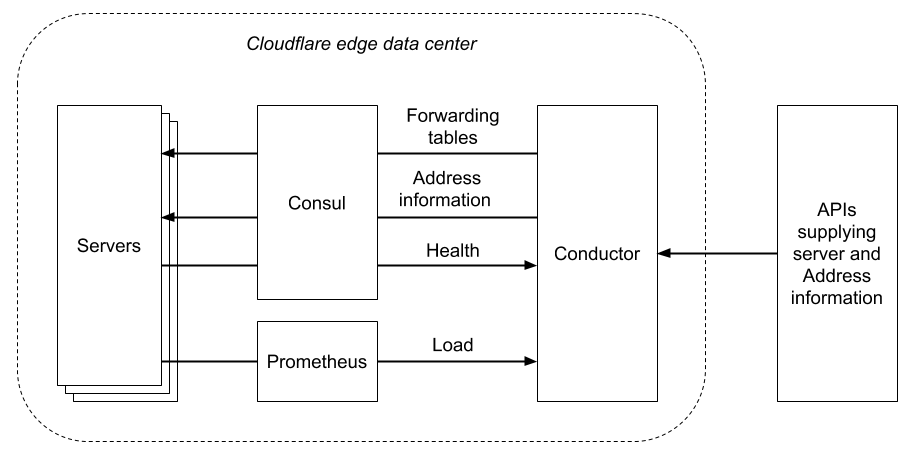
Control plane
So far, we have discussed the Unimog data plane - the part that processes network packets. But much of the development effort on Unimog has been devoted to the control plane - the part that generates the forwarding tables used by the data plane. In order to correctly maintain the forwarding tables, the control plane consumes information from multiple sources:
- Server information: Unimog needs to know the set of servers present in a data center, some key information about each one (such as their DIP addresses), and their operational status. It also needs signals about transitional states, such as when a server is being withdrawn from service, in order to gracefully drain connections (preventing the server from receiving new connections, while maintaining its established connections).
- Health: Unimog should only send connections to servers that are able to correctly handle those connections, otherwise those servers should be removed from the forwarding tables. To ensure this, it needs health information at the node level (indicating that a server is available) and at the service level (indicating that a service is functioning normally on a server).
- Load: in order to balance load, Unimog needs information about the resource utilization on each server.
- IP address information: Cloudflare serves hundreds of thousands of IPv4 addresses, and these are something that we have to treat as a dynamic resource rather than something statically configured.
The control plane is implemented by a process called the conductor. In each of our edge data centers, there is one active conductor, but there are also standby instances that will take over if the active instance goes away.
We use Hashicorp’s Consul in a number of ways in the Unimog control plane (we have an independent Consul server cluster in each data center):
- Consul provides a key-value store, with support for blocking queries so that changes to values can be received promptly. We use this to propagate the forwarding tables and VIP address information from the conductor to xdpd on the servers.
- Consul provides server- and service-level health checks. We use this as the source of health information for Unimog.
- The conductor stores its state in the Consul KV store, and uses Consul’s distributed locks to ensure that only one conductor instance is active.
The conductor obtains server load information from Prometheus, which we already use for metrics throughout our systems. It balances the load across the servers using a control loop, periodically adjusting the forwarding tables to send more connections to underloaded servers and less connections to overloaded servers. The load for a server is defined by a Prometheus metric expression which measures processor utilization (with some intricacies to better handle characteristics of our workloads). The determination of whether a server is underloaded or overloaded is based on comparison with the average value of the load metric, and the adjustments made to the forwarding table are proportional to the deviation from the average. So the result of the feedback loop is that the load metric for all servers converges on the average.
Finally, the conductor queries internal Cloudflare APIs to obtain the necessary information on servers and addresses.
Unimog is a critical system: incorrect, poorly adjusted or stale forwarding tables could cause incoming network traffic to a data center to be dropped, or servers to be overloaded, to the point that a data center would have to be removed from service. To maintain a high quality of service and minimise the overhead of managing our many edge data centers, we have to be able to upgrade all components. So to the greatest extent possible, all components are able to tolerate brief absences of the other components without any impact to service. In some cases this is possible through careful design. In other cases, it requires explicit handling. For example, we have found that Consul can temporarily report inaccurate health information for a server and its services when the Consul agent on that server is restarted (for example, in order to upgrade Consul). So we implemented the necessary logic in the conductor to detect and disregard these transient health changes.
Unimog also forms a complex system with feedback loops: The conductor reacts to its observations of behaviour of the servers, and the servers react to the control information they receive from the conductor. This can lead to behaviours of the overall system that are hard to anticipate or test for. For instance, not long after we deployed Unimog we encountered surprising behaviour when data centers became overloaded. This is of course a scenario that we strive to avoid, and we have automated systems to remove traffic from overloaded data centers if it does. But if a data center became sufficiently overloaded, then health information from its servers would indicate that many servers were degraded to the point that Unimog would stop sending new connections to those servers. Under normal circumstances, this is the correct reaction to a degraded server. But if enough servers become degraded, diverting new connections to other servers would mean those servers became degraded, while the original servers were able to recover. So it was possible for a data center that became temporarily overloaded to get stuck in a state where servers oscillated between healthy and degraded, even after the level of demand on the data center had returned to normal. To correct this issue, the conductor now has logic to distinguish between isolated degraded servers and such data center-wide problems. We have continued to improve Unimog in response to operational experience, ensuring that it behaves in a predictable manner over a wide range of conditions.
UDP Support
So far, we have described Unimog’s support for directing TCP connections. But Unimog also supports UDP traffic. UDP does not have explicit connections between clients and servers, so how it works depends upon how the UDP application exchanges packets between the client and server. There are a few cases of interest:
Request-response UDP applications
Some applications, such as DNS, use a simple request-response pattern: the client sends a request packet to the server, and expects a response packet in return. Here, there is nothing corresponding to a connection (the client only sends a single packet, so there is no requirement to make sure that multiple packets arrive at the same server). But Unimog can still provide value by spreading the requests across our servers.
To cater to this case, Unimog operates as described in previous sections, hashing the 4-tuple from the packet headers (the source and destination IP addresses and ports). But the Beamer daisy-chaining technique that allows connections to be maintained does not apply here, and so the buckets in the forwarding table only have a single slot.
UDP applications with flows
Some UDP applications have long-lived flows of packets between the client and server. Like TCP connections, these flows are identified by the 4-tuple. It is necessary that such flows go to the same server (even when Cloudflare is just passing a flow through to the origin server, it is convenient for detecting and mitigating certain kinds of attack to have that flow pass through a single server within one of Cloudflare’s data centers).
It's possible to treat these flows by hashing the 4-tuple, skipping the Beamer daisy-chaining technique as for request-response applications. But then adding servers will cause some flows to change servers (this would effectively be a form of consistent hashing). For UDP applications, we can’t say in general what impact this has, as we can for TCP connections. But it’s possible that it causes some disruption, so it would be nice to avoid this.
So Unimog adapts the daisy-chaining technique to apply it to UDP flows. The outline remains similar to that for TCP: the same redirector component on each server decides whether to send a packet on a second hop. But UDP does not have anything corresponding to TCP’s SYN packet that indicates a new connection. So for UDP, the part that depends on SYNs is removed, and the logic applied for each packet becomes:
- The redirector checks whether the packet belongs to a connection with a corresponding UDP socket on the first-hop server. If so, it is processed by that server.
- Otherwise, the packet has no corresponding UDP socket on the first-hop server. So it is forwarded on to the second-hop server to be processed there (in the expectation that it belongs to some flow established on the second-hop server that we wish to maintain).
Although the change compared to the TCP logic is not large, it has the effect of switching the roles of the first- and second-hop servers: For UDP, new flows go to the second-hop server. The Unimog control plane has to take account of this when it updates a forwarding table. When it introduces a server into a bucket, that server should receive new connections or flows. For a TCP trafficset, this means it becomes the first-hop server. For UDP trafficset, it must become the second-hop server.
This difference between handling of TCP and UDP also leads to higher overheads for UDP. In the case of TCP, as new connections are formed and old connections terminate over time, fewer packets will require the second hop, and so the overhead tends to diminish. But with UDP, new connections always involve the second hop. This is why we differentiate the two cases, taking advantage of SYN packets in the TCP case.
The UDP logic also places a requirement on services. The redirector must be able to match packets to the corresponding sockets on a server according to their 4-tuple. This is not a problem in the TCP case, because all TCP connections are represented by connected sockets in the BSD sockets API (these sockets are obtained from an accept system call, so that they have a local address and a peer address, determining the 4-tuple). But for UDP, unconnected sockets (lacking a declared peer address) can be used to send and receive packets. So some UDP services only use unconnected sockets. For the redirector logic above to work, services must create connected UDP sockets in order to expose their flows to the redirector.
UDP applications with sessions
Some UDP-based protocols have explicit sessions, with a session identifier in each packet. Session identifiers allow sessions to persist even if the 4-tuple changes. This happens in mobility scenarios - for example, if a mobile device passes from a WiFi to a cellular network, causing its IP address to change. An example of a UDP-based protocol with session identifiers is QUIC (which calls them connection IDs).
Our Unimog XDP program allows a flow dissector to be configured for different trafficsets. The flow dissector is the part of the code that is responsible for taking a packet and extracting the value that identifies the flow or connection (this value is then hashed and used for the lookup into the forwarding table). For TCP and UDP, there are default flow dissectors that extract the 4-tuple. But specialised flow dissectors can be added to handle UDP-based protocols.
We have used this functionality in our WARP product. We extended the Wireguard protocol used by WARP in a backwards-compatible way to include a session identifier, and added a flow dissector to Unimog to exploit it. There are more details in our post on the technical challenges of WARP.
Conclusion
Unimog has been deployed to all of Cloudflare’s edge data centers for over a year, and it has become essential to our operations. Throughout that time, we have continued to enhance Unimog (many of the features described here were not present when it was first deployed). So the ease of developing and deploying changes, due to XDP and xdpd, has been a significant benefit. Today we continue to extend it, to support more services, and to help us manage our traffic and the load on our servers in more contexts.