



Cloudflare’s global network spans more than 310 cities in over 120 countries. That means thousands of servers geographically spread across different data centers, running services that protect and accelerate our customer’s Internet applications. Operating hardware at such a scale means that hardware can break anywhere and at any time. In such cases, our systems are engineered such that these failures cause little to no impact. However, detecting and managing server failure at scale requires automation. This blog aims to provide insights into the difficulties involved in handling broken servers and how we were able to simplify the process through automation.
Challenges dealing with broken servers
When a server is found to have faulty hardware and needs to be removed from production, it is considered broken and its state is set to Repair in the internal database where server status is tracked. In the past, our Data Center Operations team were essentially left to troubleshoot and diagnose broken servers on their own. They had to go through laborious tasks like performing queries to locate and repair servers, conducting diagnostics, reviewing results, evaluating if a server can be restored to production, and creating the necessary tickets for re-enabling servers and executing operations to put them back in production. Such effort can take hours for a single server alone, and can easily consume an engineer’s entire day.
As you can see, addressing server repairs was a labor-intensive process performed manually, Additionally, a lot of these servers remained powered on within the racks, wasting energy. With our fleet expanding rapidly, the attention of Data Center Operations is primarily devoted to supporting this growth, leaving less time to handle servers in need of repair.
It was clear that our infrastructure was growing too fast for us to be able to handle repairs and recovery, so we had to find a better way to handle these sorts of inefficiencies in our operations. This would allow our engineers to focus on the growth of our footprint while not abandoning repair and recovery – after all, these are still huge CapEx investments and wasted capacity that otherwise would have been fully utilized.
Using automation as an autonomous system
As members of the Infrastructure Software Systems and Automation team at Cloudflare, we primarily work on building tools and automation that help reduce excess work in order to ease the pressure on our operations teams, increase productivity, and enable people to execute operations with the highest efficiency.
Our team continuously strives to challenge our existing processes and systems, finding ways we can evolve them and make significant improvements – one of which is to build not just a typical automated system but an autonomous one. Building autonomous automations means creating systems that can operate independently, without the need for constant human intervention or oversight – a perfect example of this is Phoenix.
Introducing Phoenix
Phoenix is an autonomous diagnostics and recovery automation that runs at regular intervals to discover Cloudflare data centers with servers that are broken, performing diagnostics on detection, recovering those that pass diagnostics by re-provisioning, and ultimately re-enabling those that have successfully been re-provisioned in the safest and most unobtrusive way possible – all without requiring any human intervention! Should a server fail at any point in the process, Phoenix will take care of updating relevant tickets, even pinpointing the cause of the failure, and reverting the state of the server accordingly when needed – again, all without any human intervention!
The image below illustrates the whole process:
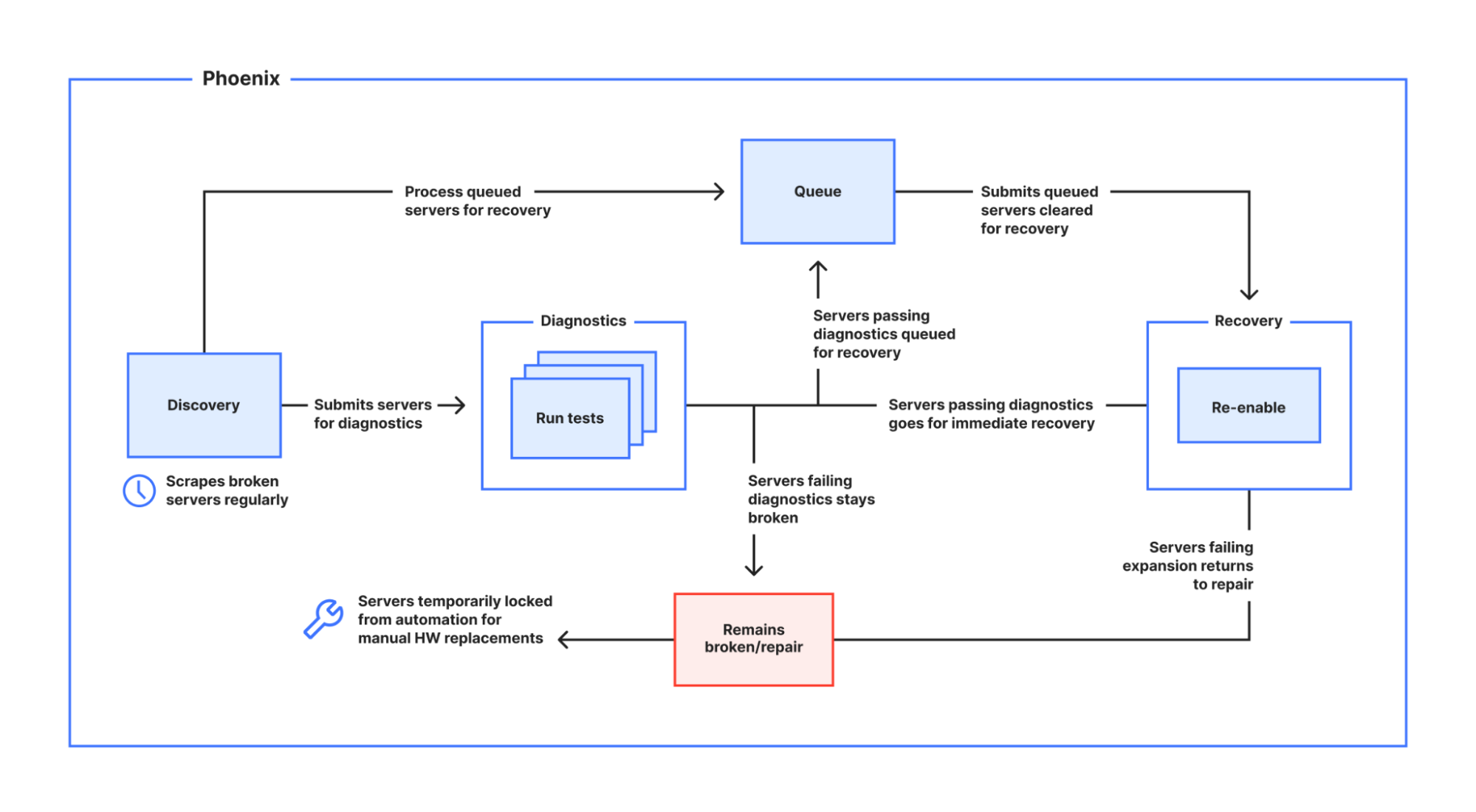
To better understand exactly how Phoenix works, let’s dive into some details about its core functionality.
Discovery
Discovery runs at a regular interval of 30 minutes, selecting a maximum of two Cloudflare data centers that have broken or repair state servers in its fleet, which are all configurable depending on business and operational needs, against which it can immediately execute diagnostics. At this rate, Phoenix is able to discover and operate on all broken servers in the fleet in about 3 days. On each run, it also detects data centers that may have broken servers already queued for recovery, and takes care of ensuring that the Recovery phase is executed immediately.
Diagnostics
Diagnostics takes care of running various tests across the broken servers of a selected data center in a single run, verifying viability of the hardware components, and identifying the candidates for recovery.
A diagnostic operation includes running the following:
- Out-of-Band connectivity check
This check determines the reachability of a device via out-of-band network. We employ IPMI (Intelligent Platform Management Interface) to ensure proper physical connectivity and accessibility of devices. This allows for effective monitoring and management of hardware components, enhancing overall system reliability and performance. Only devices that pass this check can progress to the Node Acceptance Testing phase. - Node Acceptance Tests
We leverage an existing internally-built tool called INAT (Integrated Node Acceptance Testing) that runs various tests suites/cases (Hardware Validation, Performance, etc.).
For every server that needs to be diagnosed, Phoenix will send relevant system instructions to have it boot into a custom Linux boot image, internally called INAT-image. Built into this image are the various tests that need to run when the server boots up, publishing the results to an internal resource in both human-readable (HTML) and machine-readable (JSON) formats, with the latter consumed and interpreted by Phoenix. Upon completion of the boot diagnostics, the server is powered off again to ensure it is not wasting energy.
Our node acceptance tests encompass a range of evaluations, including but not limited to benchmark testing, CPU/Memory/Storage checks, drive wiping, and various other assessments. Look out for an upcoming in-depth blog post covering INAT.
A summarized diagnostics result is immediately added to the tracking ticket, including pinpointing the exact cause of a failure.
Recovery
Recovery executes what we call an expansion operation, which in its first phase will provision the servers that pass diagnostics. The second phase is to re-enable the successfully provisioned servers back to production, where only those that have been re-enabled successfully will start receiving production traffic again.
Once the diagnostics are passed and the broken servers move on towards the first phase of recovery, we change their statuses from Repair to Pending Provision. If the servers don't fully recover, for example, because there are server configuration errors or issues enabling services, Phoenix assesses the situation. In such cases, it returns those servers to the Repair state for additional evaluation. Additionally, if the diagnostics indicate that the servers need any faulty components replaced, then Phoenix notifies our Data Center operation team for manual repairs as required, ensuring that the server is not repeatedly selected until the required part replacement is completed. This ensures any necessary human intervention can be applied promptly, making the server ready for Phoenix to rediscover in its next iteration.
An autonomous recovery operation requires infusing intelligence into the automated system so that we can fully trust that it’s able to execute an expansion operation in the safest way possible and handle situations on its own without any human interventions. To do this, we’ve made sure Phoenix is automation-aware – this means that it knows when there are other automations executing certain operations such as expansions, and will only execute an expansion when there are no ongoing provisioning operations in the target data center. This ability to execute only when it’s safe to do so is to ensure that the recovery operation will not interfere with any other ongoing operations in the data center. We’ve also adjusted its tolerance with faulty hardware – this means it’s able to gracefully deal with misbehaving servers by letting these quickly drop out of the recovery candidate list upon misbehavior that prevents blocking the operation.
Visibility
While our autonomous system, Phoenix, seamlessly handles operations without human intervention, it doesn't mean we sacrifice visibility. Transparency is a key feature of Phoenix. It meticulously logs every operation, from executing tasks to providing progress updates, and shares this information in communication channels like chat rooms and Jira tickets. This ensures a clear understanding of what Phoenix is doing at all times.
Tracking of actions taken by automation as well as the state transitions of a server keeps us in the loop and gives us a better understanding of what these actions were and when they were executed, essentially giving us valuable insights that will help us improve not only the system but our processes as well. Having this operational data allows us to generate dashboards that let various teams monitor automation activities and measure their success. We are able to generate dashboards to guide business decisions and even answer common operational questions related to repair and recovery.
Balancing automation and empathy: Error Budgets
When we launched Phoenix, we were well aware that not every broken server can be re-enabled and successfully returned to production, and more importantly, there's no 100% guarantee that a recovered server will be as stable as the ones with no repair history – there's a risk that these servers could fail and end up back in Repair status again.
Although there's no guarantee that these recovered servers won't fail again, causing additional work for SRE’s due to the monitoring alerts that get triggered, what we can guarantee is that Phoenix immediately stops recoveries without any human intervention if a certain number of failures for a server are reached in a given time window – this is where we applied the concept of an Error Budget.
The Error Budget is the amount of error that automation can accumulate over a certain period of time before our SRE’s start being unhappy due to the excessive server failures or unreliability of the system. It is empathy embedded in automation.
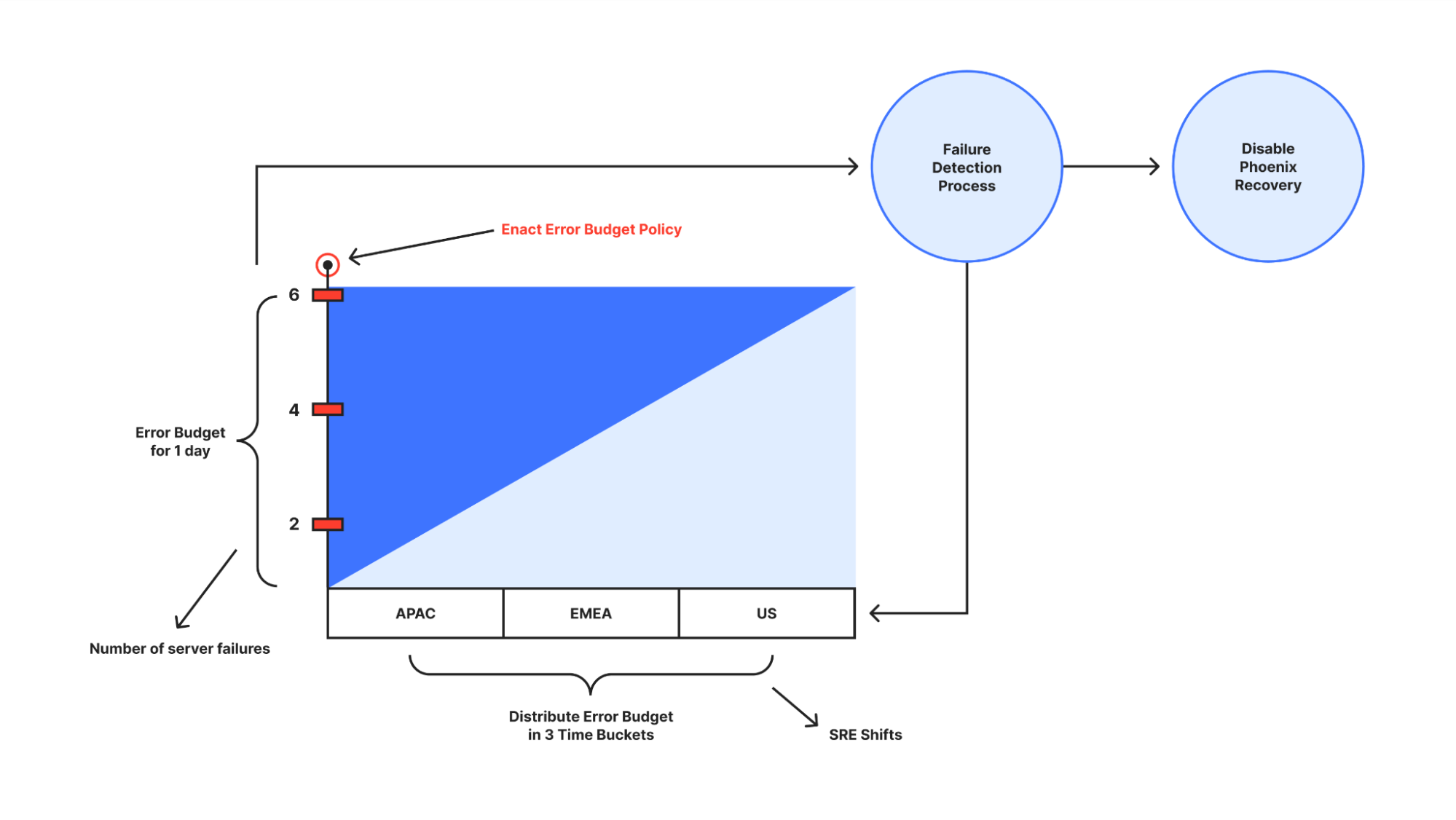
In the figure above, the y-axis represents the error budget. In this context, the error budget applies to the number of recovered servers that failed and were moved back to Repair state again. The x-axis represents the time unit allocated to the error budget – in this case, 24 hours. To ensure that Phoenix is strict enough in mitigating possible issues, we divide the time unit into three consecutive buckets of the same duration – representing the three “follow the sun” SRE shifts in a day. With this, Phoenix can only execute recoveries if the number of server failures is no more than 2. Additionally, Phoenix will also have to compensate succeeding time buckets by deducting the error budget of any excess failures in a given time bucket.
Phoenix will immediately stop recoveries if it exhausts its error budget prematurely. In this context, prematurely means before the end of the time unit for which the error budget was granted. Regardless of the error budget depletion rate within a time unit, the error budget is fully replenished at the beginning of each time unit, meaning the budget resets every day.
The Error Budget has helped us define and manage our tolerance for hardware failures without causing significant harm to the system or too much noise for SREs, and gave us opportunities to improve our diagnostics system. It provides a common incentive that allows both the Infrastructure Engineering and SRE teams to focus on finding the right balance between innovation and reliability.
Where we go from here
With Phoenix, we’ve not only witnessed the significant and far-reaching potential of having an autonomous automated system in our infrastructure, we’re actually reaping its benefits as well. It provides a win-win situation by successfully recovering hardware and ensuring that broken devices are powered off, thus preventing them from consuming unnecessary power while being idle in our racks. This not only reduces energy wastage but also contributes to sustainability efforts and cost savings. Automated processes that operate independently have not only freed our colleagues on various Infrastructure teams from doing mundane and repetitive tasks, allowing them to focus more on areas where they can use their skill sets for more interesting and productive work, but have also led us to evolving our old processes for handling hardware failures and repairs, making us much more efficient than ever.
Autonomous automation is a reality that is now beginning to shape the future of how we are building better and smarter systems here at Cloudflare, and we will continue to invest engineering time for these initiatives.
A huge thank you to Elvin Tan for his awesome work on INAT, and to Graeme, Darrel and David for INAT’s continuous improvements.