



Imagine o seguinte: você está em um aeroporto e está passando por um posto de controle de segurança aeroportuária. Há vários agentes que escaneiam seu cartão de embarque e seu passaporte e enviam você para o seu portão. De repente, alguns dos agentes fazem uma pausa. Talvez haja um vazamento no teto acima do posto de controle. Ou talvez vários voos saiam às 18h e vários passageiros aparecem ao mesmo tempo. De qualquer maneira, esse desequilíbrio entre oferta e demanda localizadas pode causar filas enormes e viajantes insatisfeitos, que só querem passar pela fila para embarcar em seu voo. Como os aeroportos lidam com isso?
Alguns aeroportos podem não fazer nada e apenas deixam você sofrer em uma fila mais longa. Alguns aeroportos podem oferecer vias rápidas através dos postos de controle por uma taxa. Mas a maioria dos aeroportos dirá para você ir a outro posto de controle de segurança um pouco mais distante para garantir que você possa chegar ao seu portão o mais rápido possível. Eles podem até ter placas informando o comprimento de cada fila, para que você possa tomar uma decisão mais fácil ao tentar passar.
Na Cloudflare, temos o mesmo problema. Estamos localizados em 300 cidades ao redor do mundo, criadas para receber tráfego de usuários finais para todos os nossos pacotes de produtos. E em um mundo ideal, sempre teremos computadores e largura de banda suficientes para atender todos no local mais próximo possível. Mas o mundo nem sempre é ideal. Às vezes, deixamos um data center off-line para manutenção, ou uma conexão com um data center fica inativa, ou algum equipamento falha, e assim por diante. Quando isso acontece, podemos não ter assistentes suficientes para atender todas as pessoas que passam pela segurança em todos os locais. Não é porque não construímos quiosques suficientes, mas algo aconteceu em nosso data center que nos impede de atender a todos.
Por isso, criamos o Traffic Manager, uma ferramenta que equilibra a oferta e a demanda em toda a nossa rede global. Este blog é sobre o Traffic Manager: como ele surgiu, como o desenvolvemos e o que ele faz agora.
O mundo antes do Traffic Manager
O trabalho agora realizado pelo Traffic Manager costumava ser um processo manual realizado por engenheiros de rede: nossa rede operava normalmente até que algo acontecesse que causasse o impacto no tráfego de usuários em um data center específico.
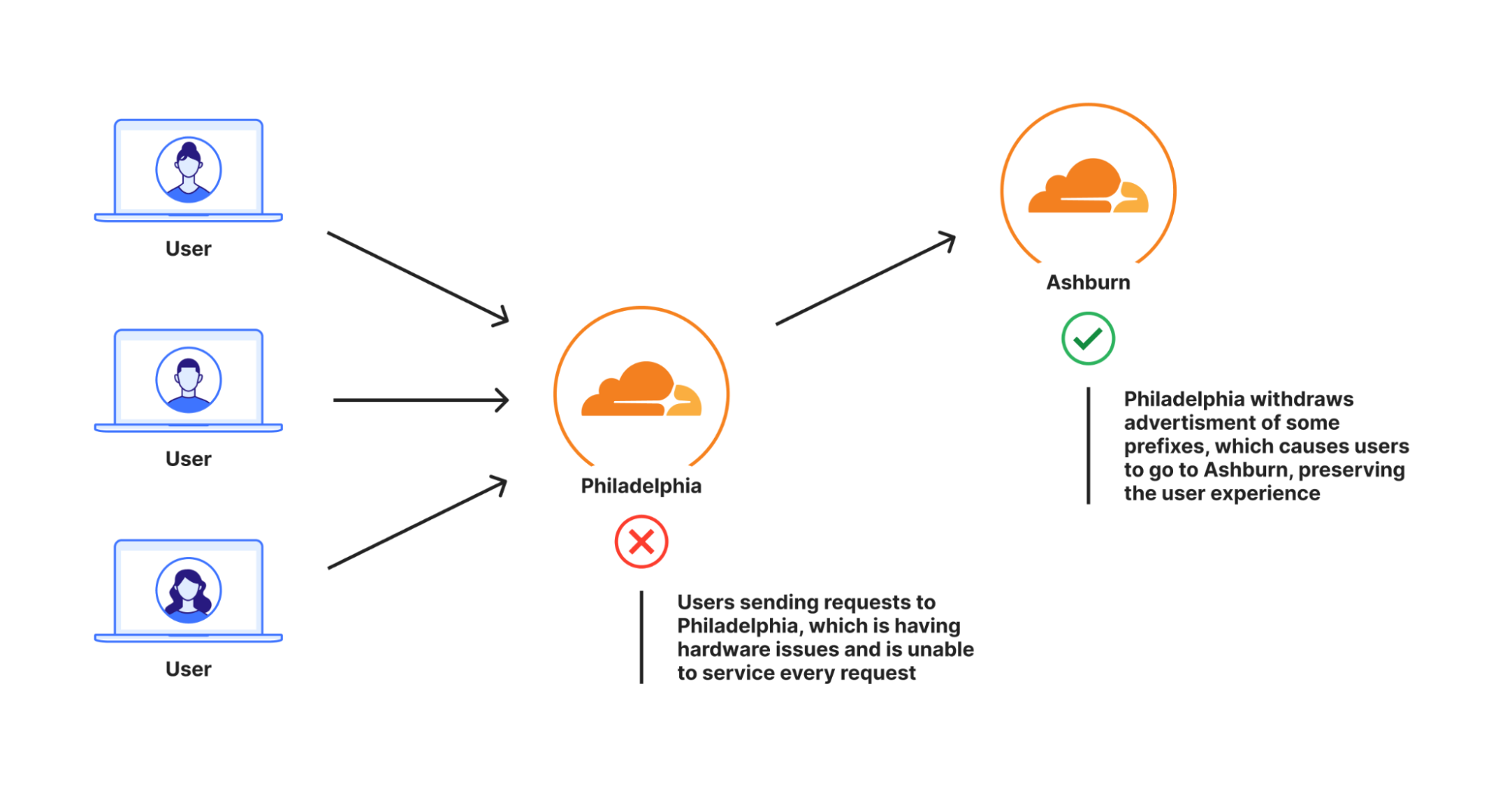
Quando tais eventos ocorriam, as solicitações de usuários começavam a falhar com erros 499 ou 500, porque não havia máquinas suficientes para lidar com a carga de solicitações de nossos usuários. Isso acionaria uma página para nossos engenheiros de rede, que removeriam algumas rotas Anycast para aquele data center. O resultado final: ao não anunciar mais esses prefixos no data center afetado, o tráfego de usuários seria desviado para um data center diferente. É assim que o Anycast funciona fundamentalmente: o tráfego de usuários é direcionado para o data center mais próximo anunciando o prefixo ao qual o usuário está tentando se conectar, conforme determinado pelo Border Gateway Protocol. Para saber o que é Anycast , confira este artigo de referência.
Dependendo da gravidade do problema, os engenheiros removiam algumas ou até mesmo todas as rotas de um data center. Quando o data center novamente era capaz de absorver todo o tráfego, os engenheiros colocavam as rotas de volta e o tráfego retornava naturalmente ao data center.
Como você pode imaginar, essa era uma tarefa desafiadora para nossos engenheiros de rede sempre que um hardware em nossa rede apresentava um problema. Isso não escalava.
Nunca envie um humano para fazer o trabalho de uma máquina
Mas fazer isso manualmente não era um fardo apenas para a nossa equipe de operações de rede. Também resultou em uma experiência abaixo do esperado para nossos clientes; nossos engenheiros precisavam de tempo para diagnosticar e redirecionar o tráfego. Para resolver esses dois problemas, queríamos criar um serviço que detectasse imediata e automaticamente se os usuários não conseguissem acessar um data center da Cloudflare e removesse rotas do data center até que os usuários não tivessem mais problemas. Assim que o serviço recebesse notificações de que o data center afetado poderia absorver o tráfego, ele poderia colocar as rotas de volta e reconectar o data center. Esse serviço é chamado de Traffic Manager, porque sua função (como você pode imaginar) é gerenciar o tráfego que chega à rede da Cloudflare.
Responsabilidade pelas consequências de segunda ordem
Quando um engenheiro de rede remove uma rota de um roteador, ele pode adivinhar para onde as solicitações do usuário irão e tentar garantir que o data center de failover tenha recursos suficientes para lidar com as solicitações, caso contrário, eles podem ajustar as rotas adequadamente antes de remover a rota no data center inicial. Para conseguir automatizar esse processo, precisávamos passar de um mundo de intuição para um mundo de dados, prevendo com precisão para onde o tráfego iria quando uma rota era removida e alimentar o Traffic Manager com essas informações para que ele pudesse garantir que a situação não ficaria pior.
Conheça o Traffic Predictor
Embora possamos ajustar quais data centers anunciam uma rota, não podemos influenciar a proporção de tráfego que cada data center recebe. Cada vez que adicionamos um novo data center ou uma nova sessão de peering, a distribuição do tráfego muda e como estamos em mais de 300 cidades e 12.500 sessões de peering, tornou-se bastante difícil para um ser humano acompanhar ou prever a maneira como o tráfego se moverá em nossa rede. O Traffic Manager precisava de um amigo: o Traffic Predictor
Para fazer seu trabalho, o Traffic Predictor realiza uma série contínua de testes do mundo real para ver onde o tráfego realmente se move. O Traffic Predictor conta com um sistema de teste que simula a remoção de um data center de serviço e mede para onde o tráfego iria se esse data center não estivesse distribuindo tráfego. Para ajudar a entender como esse sistema funciona, vamos simular a remoção de um subconjunto de um data center em Christchurch, Nova Zelândia:
Primeiro, o Traffic Predictor obtém uma lista de todos os endereços de IP que normalmente se conectam ao Christchurch. O Traffic Predictor enviará uma solicitação de ping a centenas de milhares de IPs que recentemente fizeram uma solicitação lá.
O Traffic Predictor registra se o IP responde e se a resposta retorna para o Christchurch usando um intervalo de IP Anycast especial configurado especificamente para o Traffic Predictor.
Quando o Traffic Predictor tem uma lista de IPs que respondem a Christchurch, ele remove a rota que contém aquele intervalo especial de Christchurch, espera alguns minutos para que a tabela de roteamento da internet seja atualizada e executa o teste novamente.
Em vez de serem roteadas para Christchurch, as respostas são enviadas para data centers em torno de Christchurch. O Traffic Predictor então usa o conhecimento das respostas para cada data center e registra os resultados como o failover para Christchurch.
Isso nos permite simular o Christchurch ficar off-line sem realmente colocar o Christchurch off-line.
Mas o Traffic Predictor não faz isso apenas para qualquer data center. Para adicionar camadas adicionais de resiliência, o Traffic Predictor até calcula uma segunda camada de indireção: para cada cenário de falha do data center, o Traffic Predictor também calcula cenários de falha e cria políticas para quando os data centers circundantes falharem.
Usando o nosso exemplo anterior, quando o Traffic Predictor testa o Christchurch, ele executa uma série de testes que removem vários data centers circundantes do serviço, incluindo o Christchurch, para calcular diferentes cenários de falha. Isso garante que, mesmo que algo catastrófico aconteça que afete vários data centers em uma região, ainda tenhamos a capacidade de atender ao tráfego de usuários. Se você acha que este modelo de dados é complicado, você está certo: leva vários dias para calcular todos esses caminhos e políticas de falha.
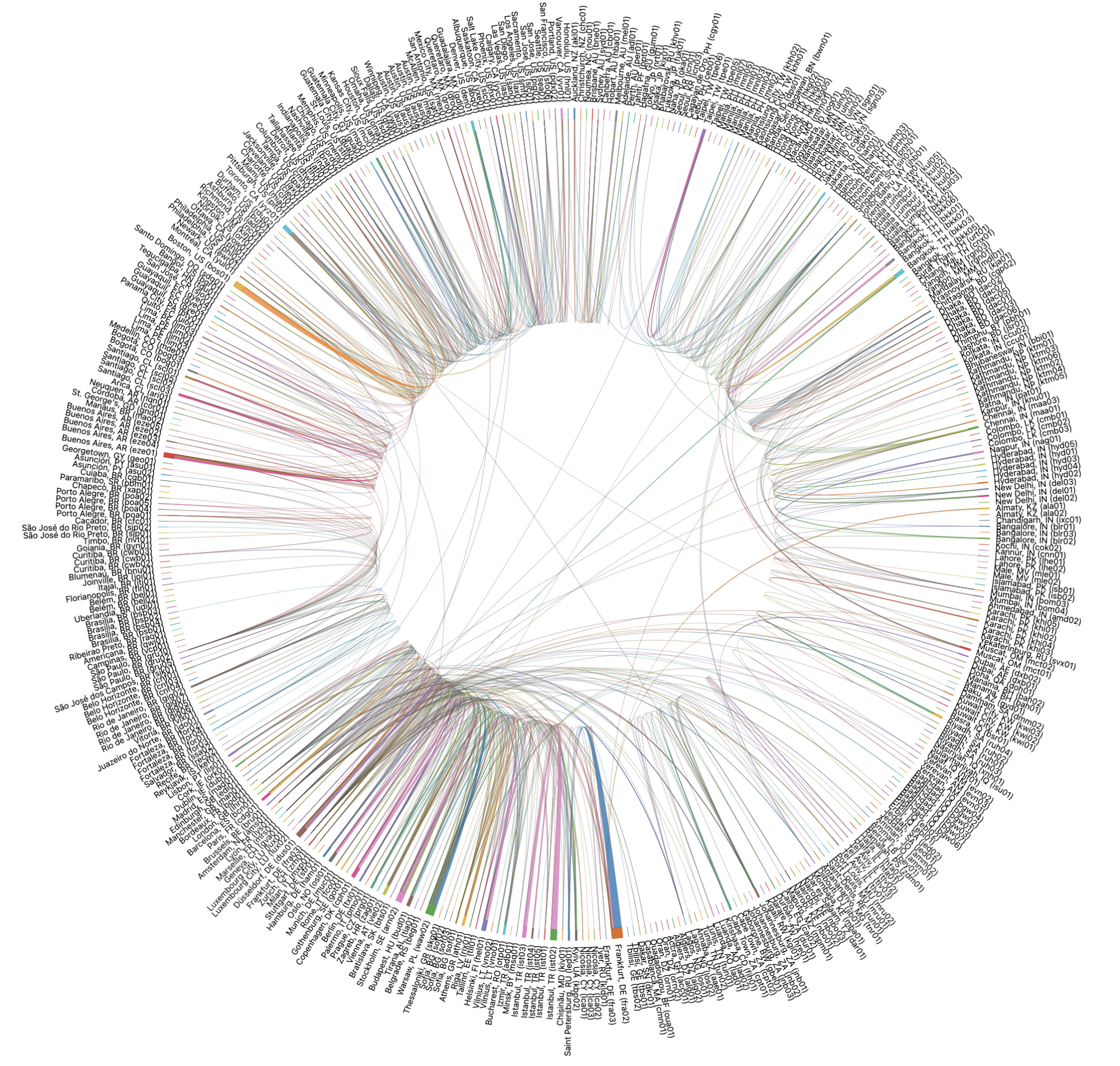
Veja como são esses caminhos de falha e cenários de failover para todos os nossos data centers ao redor do mundo quando visualizados:
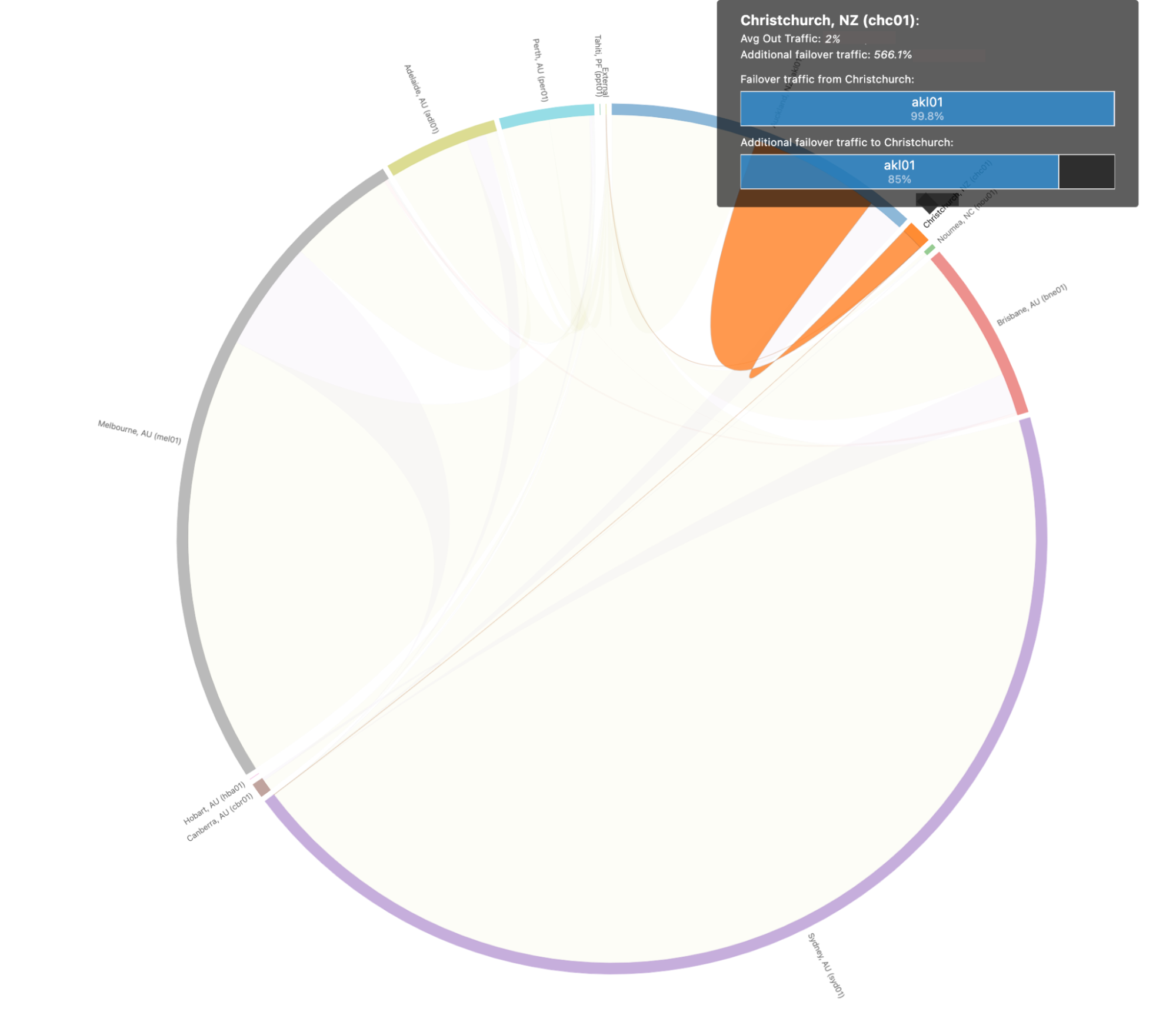
Isso pode ser um pouco complicado para os humanos analisarem, então vamos nos aprofundar no cenário acima para Christchurch, Nova Zelândia, para deixar isso um pouco mais claro. Quando examinamos os caminhos de failover especificamente para Christchurch, vemos que eles se parecem com isto:
Neste cenário, prevemos que 99,8% do tráfego de Christchurch seria transferido para Auckland, que é capaz de absorver todo o tráfego de Christchurch no caso de uma interrupção catastrófica.
O Traffic Predictor nos permite não apenas ver para onde o tráfego será desviado se algo acontecer, mas também nos permite pré-configurar as políticas do Traffic Manager para desviar solicitações para fora dos data centers de failover e evitar um "thundering herd scenario" onde o fluxo súbito de solicitações pode causar falhas em um segundo data center se o primeiro tiver problemas. Com o Traffic Predictor, o Traffic Manager não apenas desvia o tráfego para fora de um data center quando esse falha, mas também desvia proativamente o tráfego para fora de outros data centers para garantir a continuação do serviço.
De uma marreta a um bisturi
Com o Traffic Predictor, o Traffic Manager pode anunciar e remover prefixos dinamicamente, garantindo que cada data center possa lidar com todo o tráfego. Mas a remoção de prefixos como forma de gerenciamento de tráfego às vezes pode ser um pouco pesada. Uma das razões para isso é que a única maneira de adicionar ou remover tráfego de um data center era por meio de rotas de publicidade de nosso roteadores voltados para a internet. Cada uma das nossas rotas tem milhares de endereços de IP, portanto, remover apenas um ainda representa uma grande parcela do tráfego.
Especificamente, os aplicativos de internet anunciarão prefixos na internet de uma sub-rede /24 em um mínimo absoluto, mas muitos anunciarão prefixos maiores do que isso. Isso geralmente é feito para evitar coisas como vazamentos de rotas ou sequestros de rotas: muitos provedores na verdade filtram rotas que são mais específicas do que uma /24 (para obter mais informações sobre isso, confira este blog aqui). Se presumirmos que a Cloudflare mapeia propriedades protegidas para endereços de IP na proporção de 1:1, então cada sub-rede /24 seria capaz de atender a 256 clientes, que é o número de endereços de IP em uma sub-rede /24. Se cada endereço de IP enviasse uma solicitação por segundo, teríamos que desviar 4 sub-redes /24 de um data center se precisássemos desviar mil solicitações por segundo (RPS).
Na realidade, a Cloudflare mapeia um único endereço de IP para centenas de milhares de propriedades protegidas. Portanto, para a Cloudflare, uma /24 pode receber 3 mil solicitações por segundo, mas se precisássemos desviar mil RPS, não teríamos escolha a não ser desviar uma única /24. E isso apenas presumindo que anunciamos no nível /24. Se usarmos /20s para anunciar, o valor que podemos retirar fica menos granular: em um mapeamento de site para endereço de IP 1:1, são 4.096 solicitações por segundo para cada prefixo, e ainda mais se o mapeamento de site para endereço de IP for muitos para um.
Embora a remoção de anúncios de prefixo melhorou a experiência do cliente, para os usuários que veriam um erro 499 ou 500, pode haver uma parte significativa de usuários que não foram afetados por um problema, mas que ainda foram desviados do data center ao qual deveriam ter ido, provavelmente os atrasando, mesmo que apenas um pouco. Esse conceito de desviar mais tráfego do que o necessário é chamado de "capacidade ociosa": o data center é teoricamente capaz de atender mais usuários em uma região, mas não consegue devido à forma como o Traffic Manager foi desenvolvido.
Queríamos aprimorar o Traffic Manager para que ele transferisse apenas o mínimo absoluto de usuários de um data center que estava apresentando um problema e não limitar mais a capacidade. Para fazer isso, precisávamos mudar as porcentagens de prefixos, para que pudéssemos ser mais refinados e desviar apenas as coisas que absolutamente precisavam ser movidas. Para resolver isso, criamos uma extensão do nosso Unimog, balanceador de carga da camada 4, que chamamos de Plurimog.
Uma rápida atualização sobre Unimog e balanceamento de carga da camada 4: cada uma das nossas máquinas contém um serviço que determina se essa máquina pode receber uma solicitação de usuário. Se a máquina puder receber uma solicitação de usuário, então ela enviará a solicitação para nossa pilha HTTP que processa a solicitação antes de devolvê-la ao usuário. Se a máquina não puder aceitar a solicitação, a máquina enviará a solicitação para outra máquina no data center que pode. As máquinas podem fazer isso porque estão constantemente conversando entre si para entender se podem atender às solicitações dos usuários.
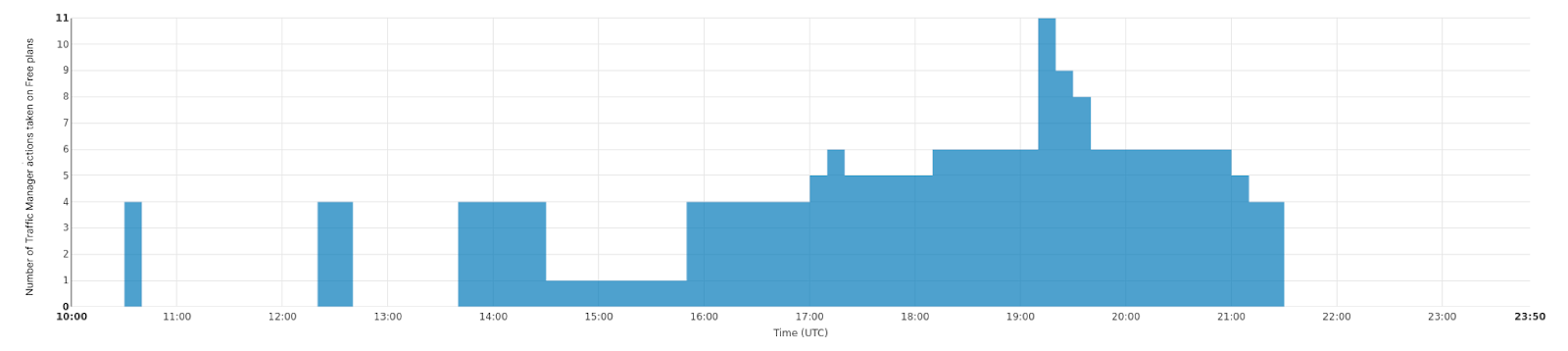
O Plurimog faz a mesma coisa, mas em vez de "conversas" entre máquinas, o Plurimog se comunica entre data centers e pontos de presença. Se uma solicitação chegar à Filadélfia e a Filadélfia não puder atendê-la, o Plurumog a encaminhará para outro data center que pode atender a solicitação, como Ashburn, onde a solicitação é descriptografada e processada. Como o Plurimog opera na camada 4, ele pode enviar solicitações de TCP ou UDP individuais para outros lugares, o que permite que ele seja muito refinado: ele pode enviar porcentagens de tráfego para outros data centers com muita facilidade, o que significa que só precisamos desviar tráfego suficiente para garantir que todos possam ser atendidos o mais rápido possível. Confira como isso funciona em nosso data center em Frankfurt, onde somos capazes de desviar progressivamente mais e mais tráfego para lidar com problemas em nossos data centers. Este gráfico mostra o número de ações tomadas sobre o tráfego livre que fazem com que ele seja enviado para fora de Frankfurt ao longo do tempo.
Mas mesmo dentro de um data center, podemos rotear o tráfego para evitar que ele saia do data center. Nossos grandes data centers, chamados Multi-Colo Points of Presence (MCPs), contêm seções lógicas de computação dentro de um data center que são distintas umas das outras. Esses data centers MCP são habilitados com outra versão do Unimog chamada Duomog, que permite que o tráfego seja deslocado entre seções lógicas de computação automaticamente. Isso torna os data centers MCP tolerantes a falhas sem sacrificar o desempenho para nossos clientes, e permite que o Traffic Manager funcione dentro de um data center e também entre data centers.
Ao avaliar partes das solicitações para desviar, o Traffic Manager faz o seguinte:
O Traffic Manager identifica a proporção de solicitações que precisam ser removidas de um data center ou subseção de um data center para que todas as solicitações possam ser atendidas.
O Traffic Manager então calcula as métricas de espaço agregadas para cada destino para ver quantas solicitações cada data center de failover pode receber.
Em seguida, o Traffic Manager identifica a quantidade de tráfego em cada plano que precisamos desviar e desvia uma proporção do plano ou todo o plano pelo Plurimog/Duomog, até que tenhamos desviado tráfego suficiente. Desviamos primeiro os clientes gratuitos e, se não houver mais clientes gratuitos em um data center, desviamos os clientes Pro e, em seguida, os clientes Business , se necessário.
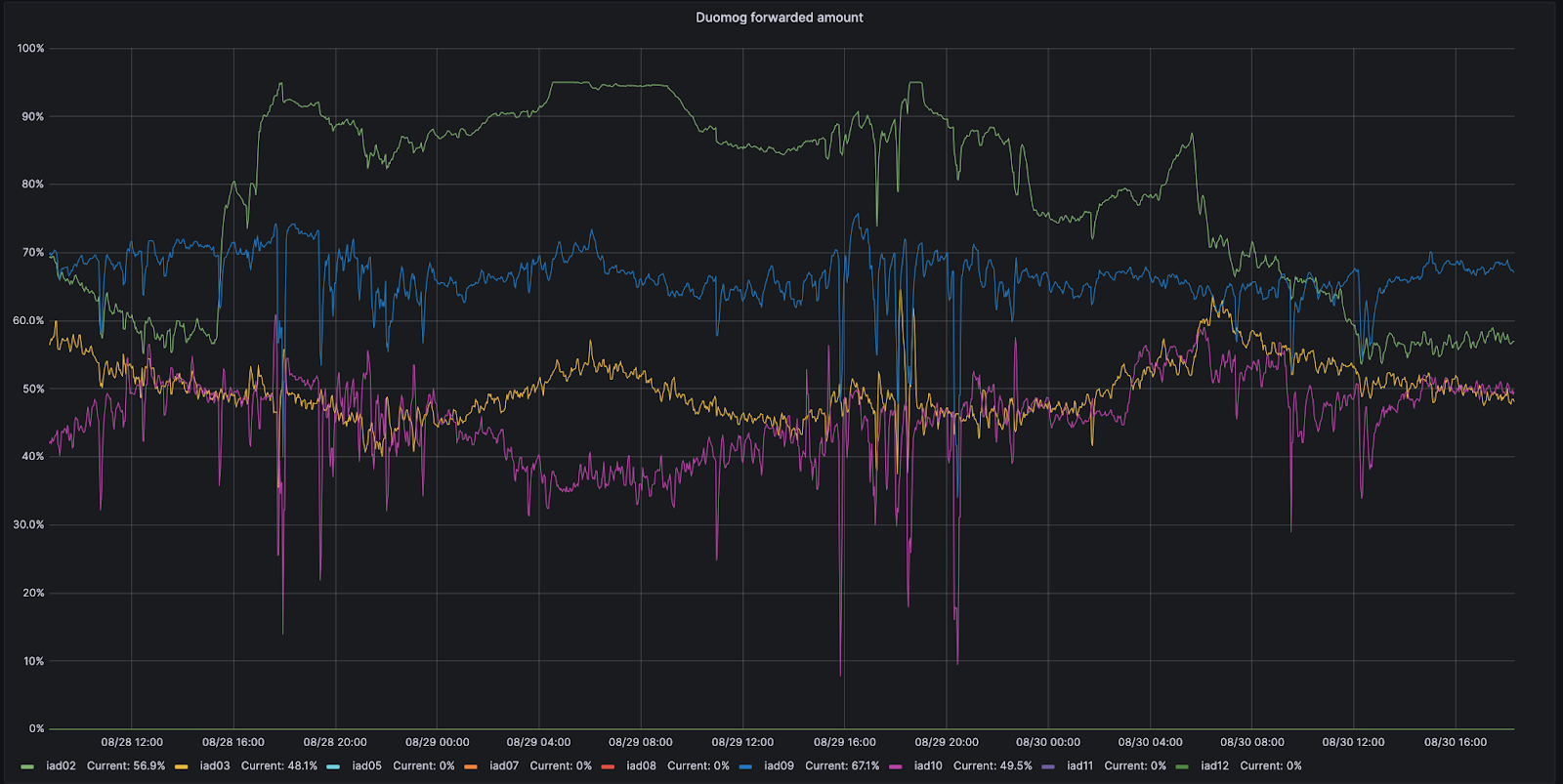
Por exemplo, vamos analisar Ashburn, na Virgínia: um de nossos MCPs. Ashburn tem nove subseções diferentes de capacidade, cada uma podendo receber tráfego. Em 28/08, uma dessas subseções, a IAD02, teve um problema que reduziu a quantidade de tráfego com a qual ela podia lidar.
Durante esse período de tempo, o Duomog enviou mais tráfego da IAD02 para outras subseções dentro de Ashburn, garantindo que Ashburn estivesse sempre on-line e que o desempenho não fosse afetado durante esse problema. Então, quando a IAD02 conseguiu receber o tráfego novamente, o Duomog deslocou o tráfego de volta automaticamente. Você pode observar essas ações visualizadas no gráfico de séries temporais abaixo, que rastreia a porcentagem de tráfego movimentado ao longo do tempo entre subseções de capacidade dentro da IAD02 (mostrada em verde):
Como o Traffic Manager sabe o quanto desviar?
Embora tenhamos usado solicitações por segundo no exemplo acima, usar solicitações por segundo como métrica não é preciso o suficiente para desviar o tráfego A razão para isso é que clientes diferentes têm custos de recursos diferentes para o nosso serviço; um site atendido principalmente pelo cache com o WAF desativado é muito mais barato em termos de CPU do que um site com todas as regras do WAF habilitadas e o armazenamento em cache desabilitado. Então, registramos o tempo que cada solicitação leva na CPU. Podemos então agregar o tempo de CPU em cada plano para encontrar o uso de tempo de CPU por plano. Registramos o tempo de CPU em ms e adotamos um valor por segundo, resultando em uma unidade de milissegundos por segundo.
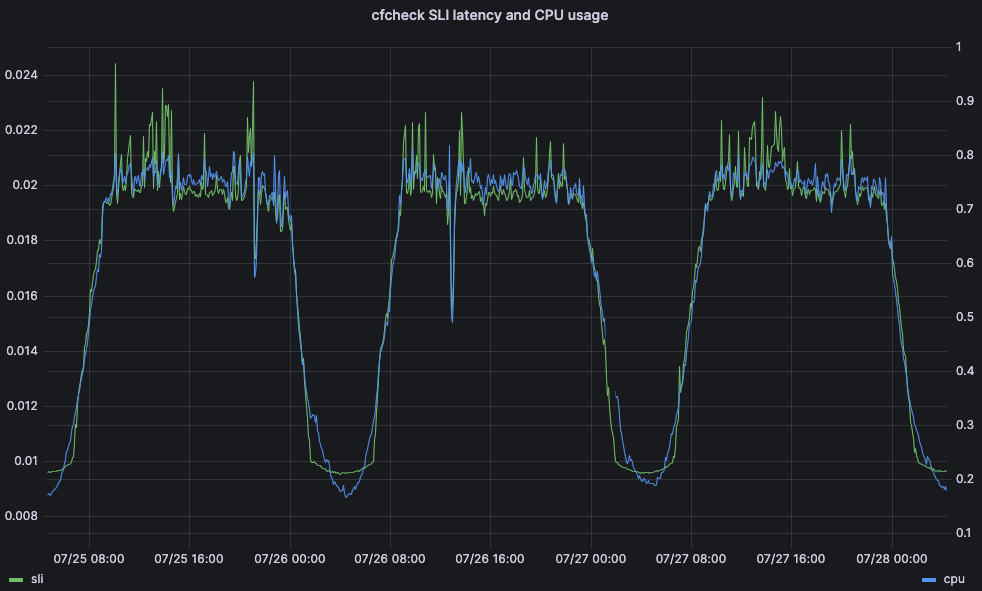
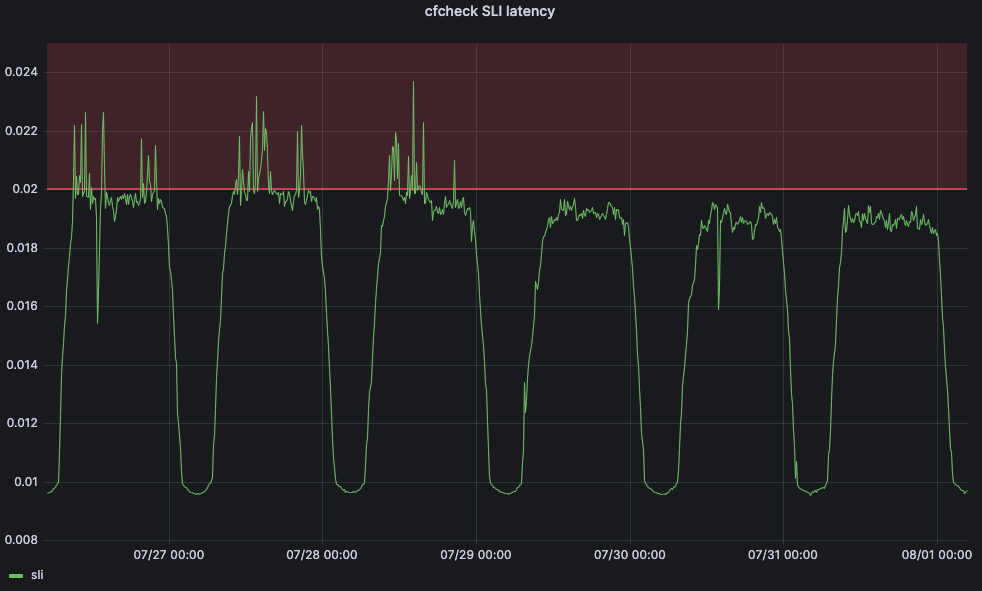
O tempo de CPU é uma métrica importante devido ao impacto que pode ter na latência e no desempenho do cliente. Como exemplo, considere o tempo que uma solicitação de visitante leva para passar inteiramente pelos servidores de linha de frente da Cloudflare: chamamos isso de latência cfcheck. Se esse número for muito alto, nossos clientes começarão a perceber e terão uma experiência ruim. Quando a latência cfcheck fica alta, geralmente a causa é a alta utilização da CPU. O gráfico abaixo mostra a latência cfcheck no 95º percentil em relação à utilização da CPU em todas as máquinas no mesmo data center, e você pode ver a forte correlação:
Portanto, fazer com que o Traffic Manager analise o tempo de CPU em um data center é uma boa maneira de garantir que estamos oferecendo aos clientes a melhor experiência e não causando problemas.
Depois de obter o tempo de CPU por plano, precisamos descobrir quanto desse tempo de CPU devemos transferir para outros data centers. Para fazer isso, agregamos a utilização da CPU em todos os servidores para fornecer uma única utilização da CPU em todo o data center. Se uma proporção de servidores no data center falhar, devido a uma falha de dispositivo de rede, falha de energia, etc., então as solicitações que atingiam esses servidores são roteadas automaticamente para outro lugar no data center pelo Duomog. À medida que o número de servidores diminui, a utilização geral da CPU do data center aumenta. O Traffic Manager tem três limites para cada data center; o limite máximo, o limite desejado e o limite aceitável:
Máximo: o nível da CPU no qual o desempenho começa a degradar, onde o Traffic Manager tomará medidas
Desejado: o nível ao qual o Traffic Manager tentará reduzir a utilização da CPU para restaurar o serviço ideal aos usuários
Aceitável: o nível abaixo do qual um data center pode receber solicitações encaminhadas de outro data center ou reverter desvios ativos
Quando um data center fica acima do limite máximo, o Traffic Manager assume a proporção do tempo total de CPU em todo o plano para a utilização da CPU atual e, em seguida, aplica-a à utilização de destino da CPU para encontrar o tempo de CPU desejado. Fazer isso significa que podemos comparar um data center com 100 servidores a um data center com 10 servidores, sem precisar nos preocupar com o número de servidores em cada data center. Isso pressupõe que a carga aumenta linearmente, o que é próximo o suficiente da verdade para que a suposição seja válida para nossos propósitos.
A taxa desejada é igual à taxa atual:
Portanto,
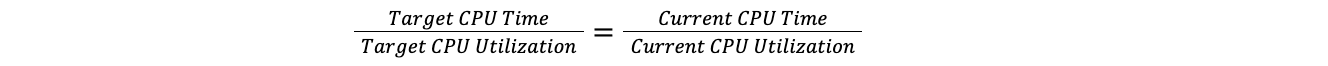
Subtraindo o tempo de CPU desejado do tempo de CPU atual nos dá o tempo de CPU para desviar:

Por exemplo, se a utilização atual da CPU estivesse em 90% em todo o data center, o desejado fosse 85% e o tempo da CPU em todo o plano fosse 18 mil, teríamos:

Isso significaria que o Traffic Manager precisaria mover mil de tempo de CPU:
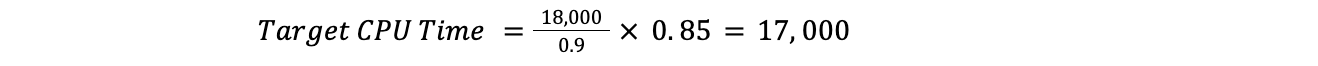
Agora que sabemos o tempo total de CPU necessário para o desvio, podemos seguir o plano até que o tempo necessário para a movimentação seja atingido.
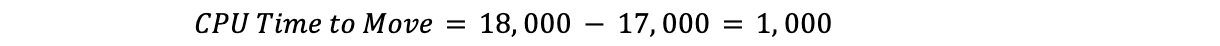
Qual é o limite máximo?
Um problema frequente que enfrentamos foi determinar em que ponto o Traffic Manager deveria começar a agir em um data center, que métrica ele deveria observar e o que é um nível aceitável?
Como dissemos antes, serviços diferentes têm requisitos diferentes em termos de utilização de CPU, e há muitos casos de data centers que têm padrões de utilização muito diferentes.
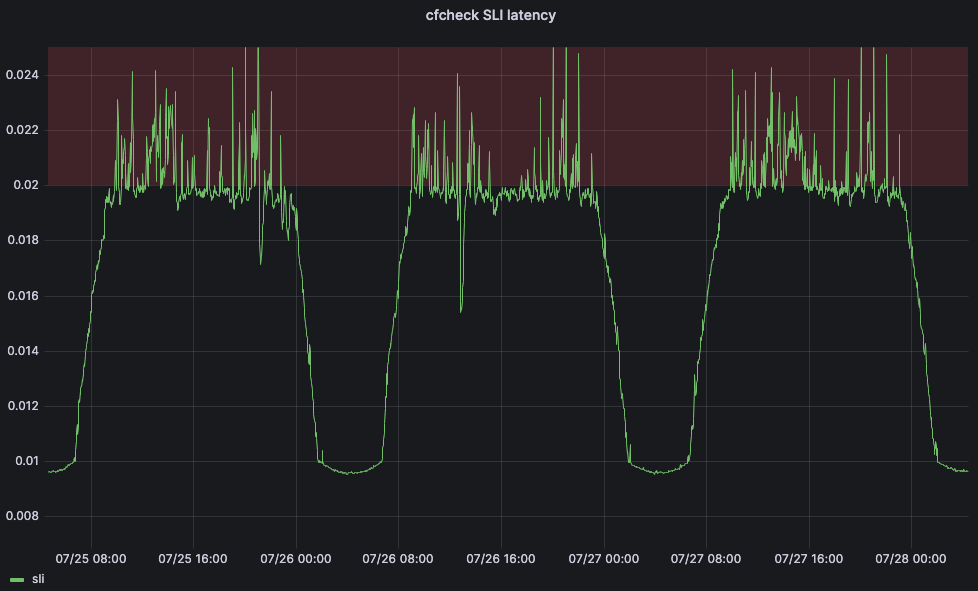
Para resolver esse problema, recorremos ao aprendizado de máquina. Criamos um serviço que ajusta automaticamente os limites máximos para cada data center de acordo com os indicadores voltados para o cliente. Para nosso principal indicador de nível de serviço (SLI), decidimos usar a métrica de latência cfcheck que descrevemos anteriormente.
Mas também precisamos definir um objetivo de nível de serviço (SLO) para que nosso aplicativo de aprendizado de máquina possa ajustar o limite. Definimos o SLO para 20ms. Comparando nosso SLO com nosso SLI, nossa latência cfcheck do 95º percentil nunca deve ultrapassar 20 ms e, se isso ocorrer, precisamos fazer algo. O gráfico abaixo mostra a latência cfcheck no 95º percentil ao longo do tempo e os clientes começam a ficar insatisfeitos quando a latência cfcheck entra na zona vermelha:
Se os clientes têm uma experiência ruim quando a CPU fica muito alta, o objetivo dos limites máximos do Traffic Manager é garantir que o desempenho do cliente não seja afetado e começar a redirecionar o tráfego antes que o desempenho comece a degradar. Em um intervalo agendado, o serviço do Traffic Manager busca uma série de métricas para cada data center e aplica uma série de algoritmos de aprendizado de máquina. Após limpar os dados para detectar discrepantes, aplicamos um ajuste de curva quadrática simples e atualmente estamos testando um algoritmo de regressão linear.
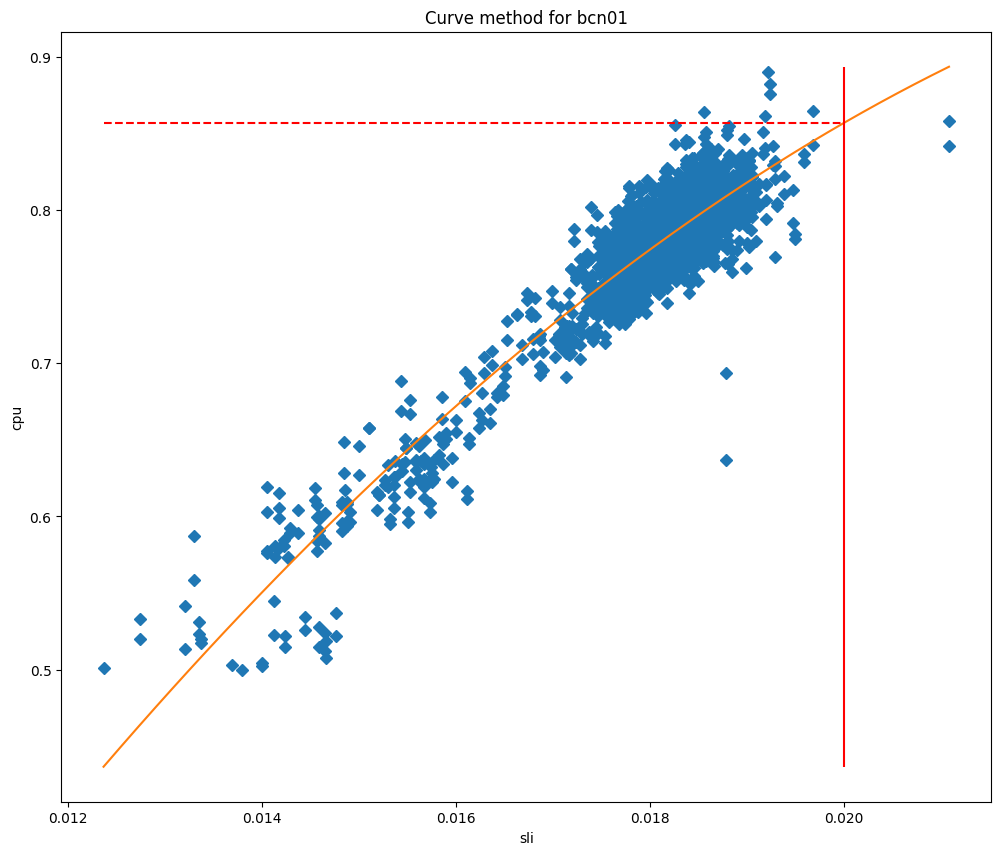
Depois de ajustar os modelos, podemos usá-los para prever o uso da CPU quando o SLI for igual ao nosso SLO e, em seguida, usá-lo como nosso limite máximo. Se plotarmos os valores de CPU em relação ao SLI, podemos ver claramente por que esses métodos funcionam tão bem para nossos data centers, como você pode ver para Barcelona nos gráficos abaixo, que são representados em relação ao ajuste de curva e ao ajuste de regressão linear, respectivamente.
Nestes gráficos, a linha vertical é o SLO e a interseção desta linha com o modelo ajustado representa o valor que será usado como limite máximo. Este modelo provou ser muito preciso e conseguimos reduzir significativamente as violações de SLO. Vamos analisar quando começamos a implantar este serviço em Lisboa:
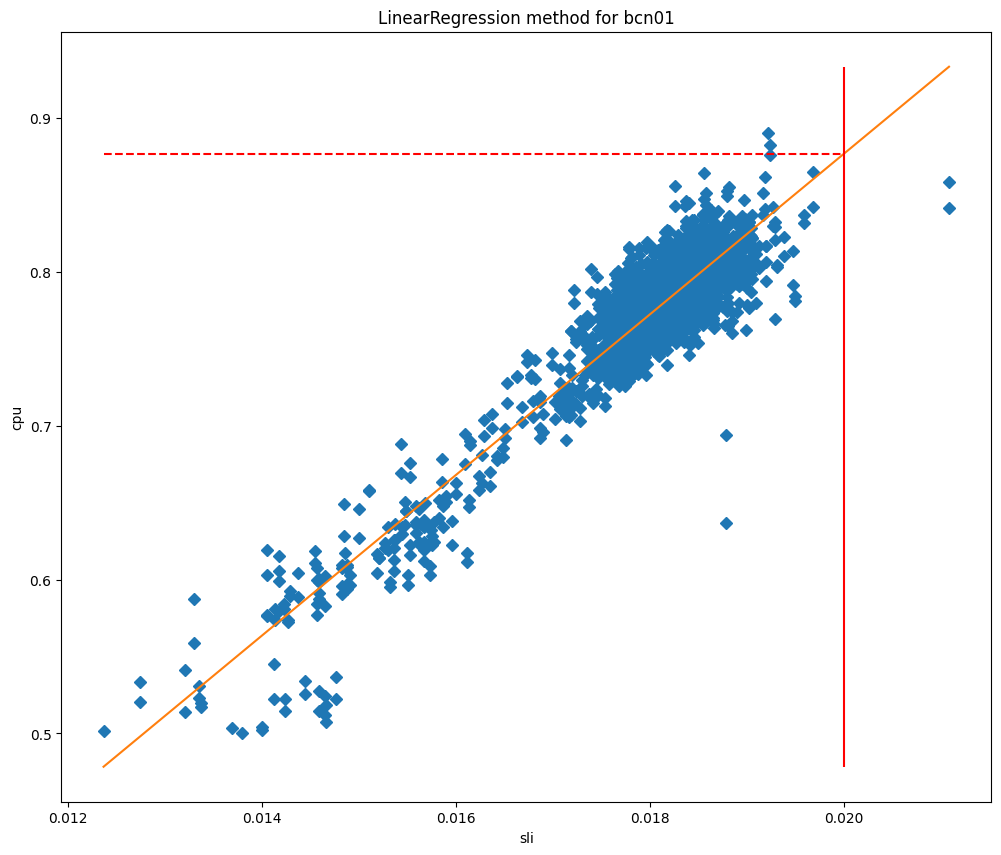
Antes da alteração, a latência cfcheck estava aumentando constantemente, mas o Traffic Manager não estava realizando ações porque o limite máximo era estático. Porém, depois de 29 de julho, vemos que a latência cfcheck nunca atingiu o SLO porque estamos constantemente medindo para garantir que os clientes nunca sejam afetados por aumentos de CPU.
Para onde enviar o tráfego?
Agora que temos um limite máximo, precisamos encontrar o terceiro limite de utilização da CPU que não é usado para calcular a quantidade de tráfego a ser movimentada, o limite aceitável. Quando um data center está abaixo desse limite, ele tem capacidade não utilizada que, desde que não esteja encaminhando o tráfego propriamente dito, é disponibilizada para outros data centers usarem quando necessário. Para calcular o quanto cada data center é capaz de receber, usamos a mesma metodologia acima, substituindo "desejado" por "aceitável":
Portanto,
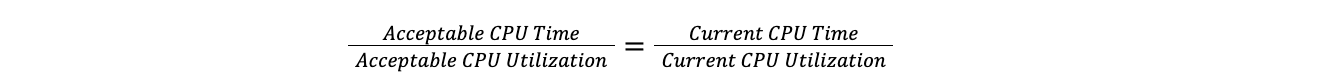
Subtrair o tempo de CPU atual do tempo de CPU aceitável nos dá a quantidade de tempo de CPU que um data center poderia aceitar:

Para descobrir para onde enviar o tráfego, o Traffic Manager encontra o tempo de CPU disponível em todos os data centers e, em seguida, ordena por latência a partir do data center que precisa desviar o tráfego. Ele se move por cada um dos data centers, usando toda a capacidade disponível com base nos limites máximos antes de passar para o próximo. Ao descobrir quais planos desviar, passamos do plano de menor prioridade para o de maior prioridade, mas ao descobrir para onde desviá-lo, avançamos na direção oposta.
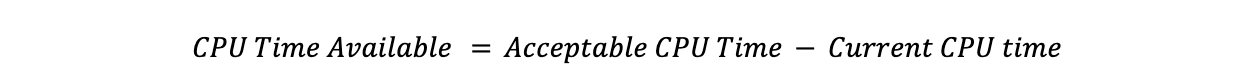
Para tornar isso mais claro, vamos usar um exemplo:
Precisamos mover mil de tempo de CPU do data center A e temos o seguinte uso por plano: gratuito: 500 ms/s, Pro: 400 ms/s, Business: 200 ms/s, Enterprise: 1000 ms/s.
Moveríamos 100% do Gratuito (500 ms/s), 100% do Pro (400 ms/s), 50% do Business (100 ms/s) e 0% do Enterprise.
Os data centers próximos têm o seguinte tempo de CPU disponível: B: 300 ms/s, C: 300 ms/s, D: 1.000 ms/s.
Com latências: A-B: 100ms, A-C: 110ms, A-D: 120ms.
Começando com o plano de latência mais baixa e prioridade mais alta que requer ação, poderíamos mover todo o tempo de CPU do Business para o data center B e metade do Pro. Em seguida, passaríamos para o data center C, onde poderíamos migrar o restante do Pro e 20% do tráfego do Gratuito. O restante do Gratuito poderia ser encaminhado para o data center D. Resultando na seguinte ação: Business: 50% → B, Pro: 50% → B, 50% → C, Gratuito: 20% → C, 80% → D.
Reverter ações
Da mesma forma que o Traffic Manager está constantemente procurando evitar que os data centers ultrapassem o limite, ele também tenta trazer qualquer tráfego encaminhado de volta para um data center que esteja encaminhando o tráfego ativamente.
Vimos acima como o Traffic Manager calcula a quantidade de tráfego que um data center é capaz de receber de outro data center, o que ele chama de tempo disponível de CPU. Quando há uma movimentação ativa, usamos esse tempo de CPU disponível para trazer de volta o tráfego para o data center, sempre priorizamos a reversão de uma movimentação ativa em vez de aceitar o tráfego de outro data center.
Quando junta tudo isso, você obtém um sistema que mede constantemente métricas de integridade do sistema e do cliente para cada data center e distribui o tráfego para garantir que cada solicitação possa ser atendida, de acordo com o estado atual de nossa rede. Quando colocamos todas essas movimentações entre os data centers em um mapa, ele se parece com algo assim, um mapa com todos os desvios do Traffic Manager por um período de uma hora. Este mapa não mostra a implantação completa do nosso data center, mas mostra os data centers que estão enviando ou recebendo tráfego desviado durante esse período:
Os data centers em vermelho ou amarelo estão sobrecarregados e transferindo o tráfego para outros data centers até ficarem verdes, o que significa que todas as métricas estão sendo exibidas como íntegras. O tamanho dos círculos representa quantas solicitações são transferidas de ou para esses data centers. O destino do tráfego é indicado pelo local onde as linhas estão se movendo. Isso é difícil de ver em escala mundial, então vamos ampliar os Estados Unidos para ver isso em ação no mesmo período:
Aqui você pode ver que Toronto, Detroit, Nova York e Kansas City não conseguem atender a algumas solicitações devido a problemas de hardware, então enviam essas solicitações para Dallas, Chicago e Ashburn até que o equilíbrio seja restaurado para usuários e data centers. Quando data centers como o de Detroit são capazes de atender a todas as solicitações que estão recebendo sem a necessidade de enviar o tráfego para longe, Detroit vai, gradualmente, parar de encaminhar solicitações para Chicago até que todos os problemas no data center sejam completamente resolvidos, momento em que não vai mais encaminhar nada. Durante tudo isso, os usuários finais estão on-line e não são afetados por nenhum problema físico que possa estar acontecendo em Detroit ou em qualquer outro local que envie tráfego.
Rede feliz, produtos felizes
Como o Traffic Manager está conectado à experiência do usuário, ele é um componente fundamental da rede da Cloudflare: ele mantém nossos produtos on-line e garante que eles sejam o mais rápidos e confiáveis possíveis. É o nosso balanceador de carga em tempo real, que ajuda a manter nossos produtos rápidos, apenas transferindo o tráfego necessário para longe dos data centers que estão apresentando problemas. Como menos tráfego é desviado, nossos produtos e serviços permanecem rápidos.
Mas o Traffic Manager também pode ajudar a manter nossos produtos on-line e confiáveis, pois permite que nossos produtos prevejam onde podem ocorrer problemas de confiabilidade e desviem os produtos para outro lugar preventivamente. Por exemplo, o Isolamento do navegador trabalha diretamente com o Traffic Manager para ajudar a garantir o tempo de atividade do produto. Quando você se conecta a um data center da Cloudflare para criar uma instância de navegador hospedada, o Isolamento do navegador primeiro pergunta ao Traffic Manager se o data center tem capacidade suficiente para executar a instância localmente e, em caso afirmativo, a instância é criada naquele momento. Se não houver capacidade suficiente disponível, o Traffic Manager informa ao Isolamento do navegador qual é o data center mais próximo com capacidade disponível suficiente, ajudando assim o Isolamento do navegador a fornecer a melhor experiência possível para o usuário.
Rede feliz, usuários felizes
Na Cloudflare, operamos essa enorme rede para atender a todos os nossos produtos e cenários de clientes. Construímos essa rede para resiliência: além de nossos locais MCP projetados para reduzir o impacto de uma única falha, estamos constantemente mudando o tráfego em nossa rede em resposta a problemas internos e externos.
Mas esse é o nosso problema, não o seu.
Da mesma forma, quando os seres humanos tiveram que corrigir esses problemas, foram os clientes e usuários finais que foram afetados. Para garantir que você esteja sempre on-line, criamos um sistema inteligente que detecta nossas falhas de hardware e equilibra preventivamente o tráfego em nossa rede para garantir que esteja on-line, o mais rápido possível. Esse sistema funciona mais rápido do que qualquer pessoa, não apenas permitindo que nossos engenheiros de rede durmam à noite, mas também proporcionando uma experiência melhor e mais rápida para todos os nossos clientes.
E, finalmente, se esses tipos de desafios de engenharia parecem empolgantes para você, considere verificar a vaga aberta para a equipe de Engenharia de Tráfego na página de Carreiras da Cloudflare.