
Yesterday, around 16:36 GMT, we had an interruption to our network services. The interruption was caused by a combination of factors. First, we had an upstream bandwidth provider with some network issues that primarily affected our European data centers. Second, we misapplied a network rate limit in an attempt to mitigate a large DDoS our ops team had been fighting throughout the night.
CloudFlare is designed to make sites faster, safer and more reliable so any time an incident on our network causes any of our customers' sites to be unreachable it is unacceptable. I wanted to take some time to give you more of a sense of exactly what happened and what our ops and engineering teams have been working on since we got things restored in order to protect our network from incidents like this in the future.
Two Visible Events
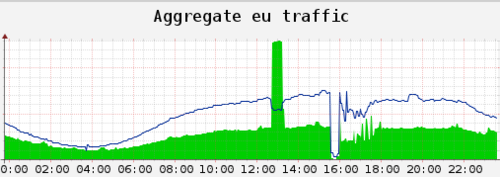
The graph at the top of this post is the aggregate traffic across CloudFlare's eight European data centers. The green section represents traffic that is inbound to our network, the blue line represents traffic that is outbound from our network. Inbound traffic includes both requests that we receive from visitors to our customers' sites as well as any content that we pull from our customers' origin servers. Since we cache content on our network, the blue line should always be significantly above the green one.
Two things you notice from the graph: the big green spike around 13:30 GMT and the fall off in the blue line around 16:30 GMT. While the two were almost 3 hours apart, they are in fact related. Here's what happened.
Limited Network and a Nasty Attack
One of our upstream network providers began having issues in Europe so we routed traffic around their network, which concentrated more traffic than usual in some of our facilities in the region. These incidents happen all the time and our network is designed to make them invisible to our customers. Around 13:00 GMT, a very large DDoS attack was launched against one of our customer's websites. The initial attack was initially a basic layer 4 attack — sending a large amount of garbage traffic from a large number of infected machines to the site. The attack peaked at over 65 Gbps of traffic, much of that concentrated in Europe.
This attack is represented by the big green spike in the graph above. It was a lot of traffic, but nothing our network can't handle. We're pretty good at stopping simple attacks like this and, by 13:30 GMT, that attacker had largely stopped with that simple attack vector. During that time, the attack didn't affect any other customers on our network. Nothing so far is atypical for a normal day at CloudFlare.
Mitigation and a Mistake
The attacker switched to trying other vectors over the next several hours. While we have automated systems to deal with many of these attacks, the size of the attack was sufficient that several members of our ops team were monitoring the situation and manually adjusting routing and rules in order to ensure the customer under attack stayed online and none of the rest of the network was impacted.
Around 16:30 GMT the attacker switched vectors again. Our team implemented a new rate limit. The rate limit was supposed to apply only to the affected customer, but was misapplied to a wider number of customers. Because traffic was already concentrated in Europe more so than usual, the misapplied network rate limit impacted a large number of customers in the region. There was some spillover to traffic to our facilities in North America and Asia Pacific, however the brunt of the outage was felt in Europe.
As you can see from the graph, both inbound and outbound traffic fell off almost entirely in the region. We realized our mistake and reverted the rate limit. In some cases, the rate limit also affected BGP announcements that setup routes to our network. The spikes on the graph you see over the next hour are from the network routing rebalancing in the region.
Smoke Tests
We have been working to automate more and more of our attack mitigation. For most manual changes that could affect our network we have smoke tests in place to ensure mistake don't make it into production. The events of today have exposed one more place we need to put such checks in place. Our team worked yesterday to build additional smoke tests to protect against something similar to this happening again in the future.
CloudFlare has grown very quickly because we provide a service many websites need in a way that is affordable and easy for anyone to implement. Core to what we do is ensuring the uptime and availability of our network. We let many of our customers down yesterday. We will learn from the outage and continue to work toward implementing systems that ensure our network is among the most reliable on the Internet.