


让全栈开发更简单
虽然今天是愚人节,而且我们也和其他人一样喜欢玩乐,但我们希望在今天发布一些严肃的公告。事实上,截至今天,已有超过 200 万开发者在 Cloudflare 平台上进行开发——这绝对不是开玩笑!
作为本届 Developer Week 的序幕,我们宣布三个产品进入“生产就绪”状态: D1 ——我们的无服务器 SQL 数据库;Hyperdrive——使您的现有数据库运行犹如分布式(而且更快!);以及 Workers Analytics Engine——我们的时间序列数据库。
一段时间以来,我们一直致力于让开发人员将他们的整个技术栈迁移到 Cloudflare 上,但在 Cloudflare 上构建的应用程序会是什么样子呢?
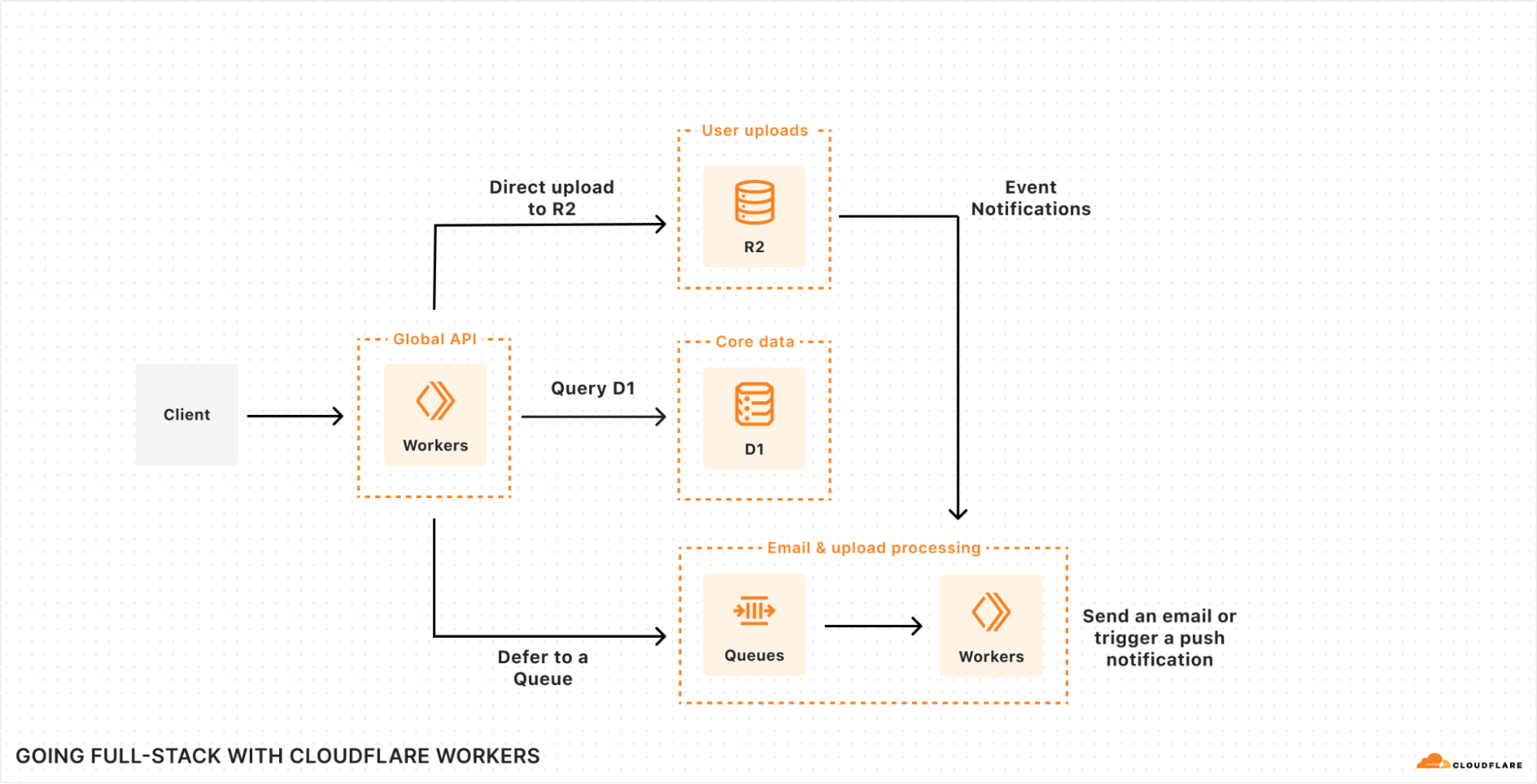
这个图表本身看起来应该与您已经熟悉的工具没有太大差异:您需要一个数据库用于存储核心用户数据。对象存储用于存储资产和用户内容。也许一个队列用于处理后台任务,例如电子邮件或上传处理。一个快速键值存储用于运行时配置。也许甚至一个时间序列数据库聚合用户事件和/或性能数据。我们甚至还没有涉及到 AI(人工智能)——它正日益成为许多应用程序在搜索、推荐和/或图像分析任务(最低限度!)中的一个核心部分。
而且,无需多想,这种架构需要运行在全球范围内,意味着它是可扩展、可靠和快速的,全部开箱即用。
D1 正式版:生产就绪

核心数据库是基础设施中最关键的组成部分之一。它需要高度可靠,不能丢失数据,需要能够扩展。因此,在过去的一年里,我们一直全力以赴使 D1 达到生产就绪状态。现在,我们隆重宣布 D1 —— 我们的全球、无服务器 SQL 数据库 —— 现在已经正式发布。
D1 的正式发布带来了一些备受期待的功能,包括:
- 支持 10 GB 数据库——以及每个账户 5 万个数据库;
- 全新数据导出功能;以及
- 增强查询调试功能(我们称之为“D1 Insights”)——以便您了解哪些查询消耗了最多的时间、成本,或者哪些查询效率低下……
……旨在赋能开发人员以利用 D1 构建满足其所有关系型 SQL 需求的生产就绪应用程序。而且重要的是,在“免费计划”或“爱好型计划”显然面临风险的情况下,我们无意取消 D1 的免费级,也不打算降低 5 美元/月 Workers Paid 计划包含的 250 亿行读取配额:
如果您从一开始就关注 D1:这与我们在 公开测试版时宣布的价格一致
但正式发布并不意味着我们的工作停顿下来:我们计划为 D1 推出一些重大全新功能,包括全球读复制,甚至更大的数据库,更多 Time Travel 功能,以便您对数据库进行分支;以及用于动态查询和/或从 Worker 中动态创建新数据库的全新 API。
D1 的读复制会根据需要自动部署读副本,使数据更靠近您的用户:而且无需您启动或管理扩展,也不会遇到一致性(复制滞后)问题。让我们提前一窥 D1 即将推出的 Replication API 是什么模样:
export default {
async fetch(request: Request, env: Env) {
const {pathname} = new URL(request.url);
let resp = null;
let session = env.DB.withSession(token); // An optional commit token or mode
// Handle requests within the session.
if (pathname === "/api/orders/list") {
// This statement is a read query, so it will work against any
// replica that has a commit equal or later than `token`.
const { results } = await session.prepare("SELECT * FROM Orders");
resp = Response.json(results);
} else if (pathname === "/api/orders/add") {
order = await request.json();
// This statement is a write query, so D1 will send the query to
// the primary, which always has the latest commit token.
await session.prepare("INSERT INTO Orders VALUES (?, ?, ?)")
.bind(order.orderName, order.customer, order.value);
.run();
// In order for the application to be correct, this SELECT
// statement must see the results of the INSERT statement above.
//
// D1's new Session API keeps track of commit tokens for queries
// within the session and will ensure that we won't execute this
// query until whatever replica we're using has seen the results
// of the INSERT.
const { results } = await session.prepare("SELECT COUNT(*) FROM Orders")
.run();
resp = Response.json(results);
}
// Set the token so we can continue the session in another request.
resp.headers.set("x-d1-token", session.latestCommitToken);
return resp;
}
}
重要的是,我们将使开发人员能够维持基于会话的一致性,以便用户既能看到自己的更改得到反映,同时仍然能够享受复制带来的性能和延迟优势。
如需进一步了解 D1 读复制的底层工作原理,欢迎阅读我们的深入探讨文章。如果您希望立即开始使用 D1 进行构建,请浏览我们的开发人员文档以创建您的第一个数据库。
Hyperdrive: 正式发布

我们在去年 9 月的生日周期间推出 Hyperdrive 的公测版,现已正式发布,换句话说,这个产品经过实战测试并已生产就绪。
如果您还不了解 Hyperdrive 是什么,它旨在使您已有的中心化数据库给人分布式的感觉。我们使用我们的全球网络来获得到您的数据库的更快路径,保持连接池处于最佳状态,并在尽可能接近用户的地方缓存您最频繁执行的查询。
重要的是,Hyperdrive 开箱就支持最流行的驱动程序和 ORM(对象关系映射)库,因而您无需重新学习或重写您的查询:
// Use the popular 'pg' driver? Easy. Hyperdrive just exposes a connection string
// to your Worker.
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
await client.connect();
// Prefer using an ORM like Drizzle? Use it with Hyperdrive too.
// https://orm.drizzle.team/docs/get-started-postgresql#node-postgres
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
await client.connect();
const db = drizzle(client);
但是有关 Hyperdrive 的工作不会因为正式发布而停下来。接下来的几个月内,我们将为另一个部署最广泛的数据库引擎提供支持:MySQL。我们还将支持通过 Cloudflare Tunnel 和 Magic WAN 连接到专用网络(包括云 VPC 网络)内的数据库。除此之外,我们计划推出围绕失效和缓存策略的配置选项,以便您能就性能与数据新鲜度做出更细致的决策。
当我们考虑如何为 Hyperdrive 定价时,我们意识到对其收费似乎并不合适。毕竟,Hyperdrive 不仅带来显著的的性能提升,而且对于连接传统数据库引擎至关重要。如果没有 Hyperdrive,每个连接和查询数据库的请求都需要支付 6 次以上往返的延迟开销,这样做显然是不合理的。
因此,我们很高兴地宣布:对于任何订阅 Workers Paid 计划的开发人员,Hyperdrive 均免费使用。 这包括查询缓存和连接池,以及创建多个 Hyperdrive 的能力——以区分不同的应用程序、生产环境与测试环境,或提供不同的配置(例如,缓存与不缓存)。
要开始使用 Hyperdrive,请查看文档以了解如何连接您的现有数据库并开始从您的 Workers 进行查询。
Queues:从任何地方拉取
对于构建现代全栈应用而言,任务队列是越来越关键的一个部分。这正是我们最初宣布推出 Queues 公测时所考虑的因素。自那以后,我们一直在开发几个重要的 Queues 特性,并在本周推出其中的两个:基于拉取的消费者和新的消息传递控制。
任何支持HTTP的客户端现在都可以从一个队列中拉取消息:调用一个队列的新 /pull 端点以请求一批消息,并在成功处理每条消息(或每批消息)后调用 /ack 端点以进行确认:
// Pull and acknowledge messages from a Queue using any HTTP client
$ curl "https://api.cloudflare.com/client/v4/accounts/${CF_ACCOUNT_ID}/queues/${QUEUE_ID}/messages/pull" -X POST --data '{"visibilityTimeout":10000,"batchSize":100}}' \
-H "Authorization: Bearer ${QUEUES_TOKEN}" \
-H "Content-Type:application/json"
// Ack the messages you processed successfully; mark others to be retried.
$ curl "https://api.cloudflare.com/client/v4/accounts/${CF_ACCOUNT_ID}/queues/${QUEUE_ID}/messages/ack" -X POST --data '{"acks":["lease-id-1", "lease-id-2"],"retries":["lease-id-100"]}' \
-H "Authorization: Bearer ${QUEUES_TOKEN}" \
-H "Content-Type:application/json"
基于拉取的消费者可以在任何地方运行,允许您与现有的传统云基础设施一同运行队列消费者。Cloudflare的内部团队很早就采用了这种方式,其中一个用例专注于从我们的 310+数据中心写入设备遥测数据到队列,并在一些在Kubernetes上运行的后台基础设施中进行消费。重要的是,我们全球分布的队列基础设施意味着消息保留在队列中,直到消费者准备好处理它们。
Queues 现在也支持推迟消息, 包括在发送到队列时和在标记消息以便重试时。这个功能适用于为将来对任务进行排队,以及如果上游 API 或基础设施有速率限制,需要您控制处理消息的速度,用于应用退避机制。
// Apply a delay to a message when sending it
await env.YOUR_QUEUE.send(msg, { delaySeconds: 3600 })
// Delay a message (or a batch of messages) when marking it for retry
for (const msg of batch.messages) {
msg.retry({delaySeconds: 300})
}
在未来几个月中,我们还将大幅提高每个队列的吞吐量,以便将 Queues 到正式发布。对我们来说,Queues 的 高度可靠性非常重要:丢失或掉落的消息意味着用户收不到订单确认邮件,密码重置通知,和/或他们的上传未被处理的反馈——每一种情况都会对用户产生影响且难以恢复。

Workers Analytics Engine 正式发布
Workers Analytics Engine 通过内置 API 从 Workers 写入数据点,并通过 SQL API 查询那些数据,提供了大规模的无限基数分析。
Workers Analytics Engine 背后是 Cloudflare 已经依赖多年、基于 ClickHouse 的系统。我们用它来观察自己服务的健康状况,捕获产品使用数据进行计费,以及回答有关特定客户使用模式的问题。几乎每一个对 Cloudflare 网络的请求都会向这个系统写入至少一个数据点。Workers Analytics Engine 让您可以使用同样的基础设施构建自己的自定义分析,同时我们为您管理那些困难的部分。
自从推出测试版以来, 从大型企业到诸如 Counterscale 的开源项目,开发人员都开始依赖 Workers Analytics Engine 来处理这些相同的用例以及其他。Workers Analytics Engine 已经以生产规模运行了数年,处理任务关键性工作负载 —— 但直到今天,我们还没有分享过任何关于定价的信息。
我们使 Workers Analytics Engine 的定价保持简单,基于两个指标:
- 写入数据点 —— 每次在一个 Worker 中调用 writeDataPoint(),都会算作写入一个数据点。每个数据点的成本相同 —— 与其他平台不同,我们不会因为增加维度或基数而额外收费,也不需要预测压缩数据点的大小和成本可能是—多少。
- 读取查询 —— 每次向 Workers Analytics Engine SQL API 发出 POST 请求,就算作一次读查询。每次查询的成本相同 —— 与其他平台不同,我们不会因为查询复杂性而额外收费,也不需要考虑每次查询将读取的数据行数。
Workers Free 和 Workers Paid 都将包括一定数量的数据点写入和读取查询,额外使用量的定价如下:
根据这一定价,通过计算在 Worker 中调用函数的次数,以及向 HTTP API 端点发出请求的次数,即可回答 “Workers Analytics Engine 会花费我多少钱?” 的问题。计算简单明了,无需使用电子表格。
这一定价将在未来几个月内向所有人开放。在那以前,Workers Analytics Engine 继续免费提供使用。您今天就可以开始从 Worker 中写入数据点 ——只需要短短几分钟,不到 10 行代码,即可开始捕获数据。我们期待听到您的反馈。
本周才刚刚开始
欢迎关注我们将在 Developer Week 第二天为您准备的精彩内容。如有任何问题,或者希望展示您已经构建的炫酷作品,欢迎加入我们的 Discord 服务器。