

Hoje, a Cloudflare anuncia o desenvolvimento de um firewall para IA, uma camada de proteção que pode ser implantada na frente de modelos de linguagem grande (LLMs) para identificar abusos antes que eles cheguem aos modelos.

Embora os modelos de IA, especificamente os LLMs, estejam aumentando, os clientes nos dizem que estão preocupados com as melhores estratégias para proteger seus próprios LLMs. O uso de LLMs como parte de um aplicativo conectado à internet apresenta novas vulnerabilidades que podem ser exploradas por agentes mal-intencionados.
Algumas das vulnerabilidades que afetam os aplicativos web tradicionais e APIs também se aplicam ao mundo dos LLMs, incluindo injeções ou exfiltração de dados. No entanto, há um novo conjunto de ameaças que agora são relevantes devido à forma como os LLMs funcionam. Por exemplo, os pesquisadores descobriram recentemente uma vulnerabilidade em uma plataforma de colaboração de IA que lhes permite sequestrar modelos e realizar ações não autorizadas.
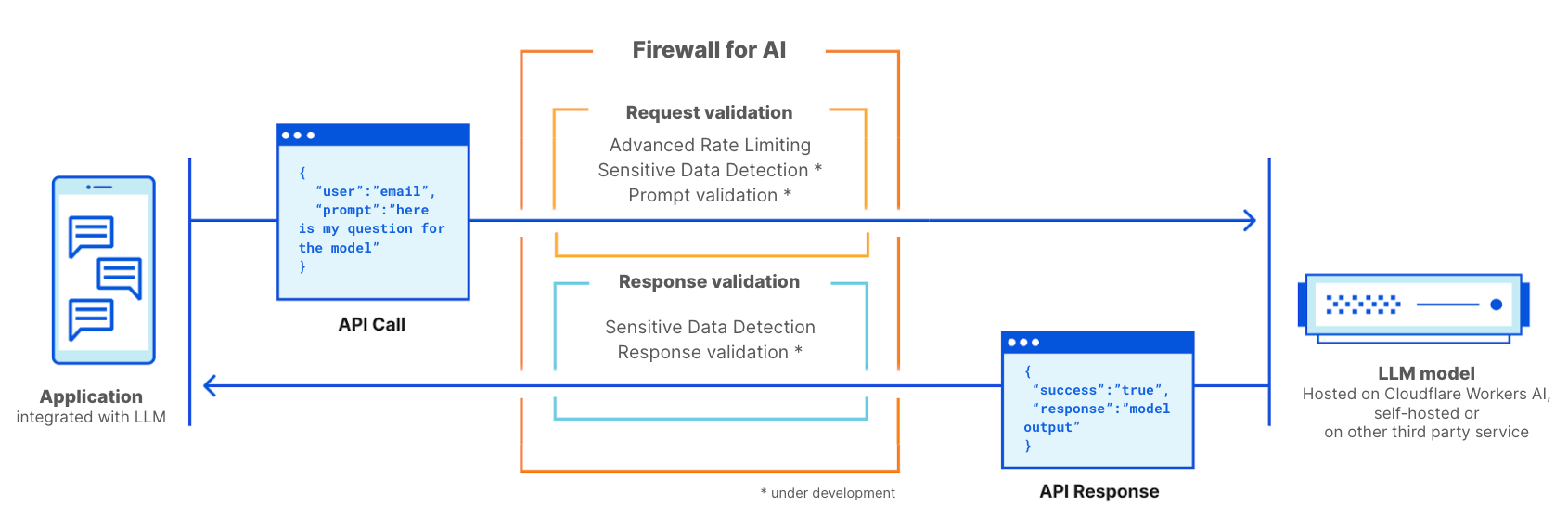
O firewall para IA é um firewall de aplicativos web (WAF) avançado feito sob medida especificamente para aplicativos que usam LLMs. Ele inclui um conjunto de ferramentas que podem ser implantadas na frente dos aplicativos para detectar vulnerabilidades e fornecer visibilidade aos proprietários de modelos. O kit de ferramentas inclui produtos que já fazem parte do WAF, como limitação de taxa e detecção de dados confidenciais, além de uma nova camada de proteção que está atualmente em desenvolvimento. Essa nova validação analisa o prompt enviado pelo usuário final para identificar tentativas de exploração do modelo para extrair dados e outras tentativas de abuso. Aproveitando o tamanho da rede da Cloudflare, o firewall para IA é executado o mais próximo possível do usuário, o que nos permite identificar ataques antecipadamente e proteger usuários finais e modelos contra abusos e ataques.
Antes de nos aprofundarmos em como funciona o firewall para IA e seu conjunto completo de recursos, vamos primeiro examinar o que torna os LLMs únicos e as superfícies de ataque que eles introduzem. Usaremos os Top 10 do OWASP para LLMs como referência.
Por que os LLMs são diferentes dos aplicativos tradicionais?
Ao considerar os LLMs como aplicativos conectados à internet, há duas diferenças principais em comparação com os aplicativos web mais tradicionais.
Primeiro, a maneira como os usuários interagem com o produto. Os aplicativos tradicionais são determinísticos por natureza. Pense em um aplicativo de banco, ele é definido por um conjunto de operações (verificar meu saldo, fazer uma transferência, etc.). A segurança da operação da empresa (e dos dados) pode ser obtida controlando o excelente conjunto de operações aceitas por esses endpoints: "GET /balance" ou "POST /transfer".
As operações de LLMs não são determinísticas por design. Para começar, as interações dos LLMs são baseadas em linguagem natural, o que torna a identificação de solicitações problemáticas mais difícil do que a correspondência de assinaturas de ataque. Além disso, a menos que uma resposta seja armazenada em cache, os LLMs normalmente fornecem uma resposta diferente a cada vez, mesmo que o mesmo prompt de entrada seja repetido. Isso torna muito mais difícil limitar a maneira como um usuário interage com o aplicativo. Isso também representa uma ameaça para o usuário, em termos de exposição a informações erradas que enfraquecem a confiança no modelo.
Em segundo lugar, uma grande diferença é como o plano de controle do aplicativo interage com os dados. Em aplicativos tradicionais, o plano de controle (código) está bem separado do plano de dados (banco de dados). As operações definidas são a única maneira de interagir com os dados subjacentes (por exemplo, mostrar o histórico das minhas transações de pagamento). Isso permite que os profissionais de segurança se concentrem em adicionar verificações e proteções ao plano de controle e, assim, proteger o banco de dados indiretamente.
Os LLMs são diferentes porque os dados de treinamento se tornam parte do próprio modelo por meio do processo de treinamento, tornando extremamente difícil controlar como esses dados são compartilhados como resultado de um prompt do usuário. Algumas soluções de arquitetura estão sendo exploradas, como a separação de LLMs em diferentes níveis e a segregação de dados. No entanto, nenhuma solução definitiva foi encontrada ainda.
Do ponto de vista da segurança, essas diferenças permitem que os invasores criem novos vetores de ataque que podem atingir LLMs e passar despercebidos pelo radar das ferramentas de segurança existentes projetadas para aplicativos web tradicionais.
Vulnerabilidades dos LLMs do OWASP
A fundação OWASP lançou uma lista das dez principais classes de vulnerabilidades dos LLMs, fornecendo uma estrutura útil para pensar em como proteger modelos de linguagem. Algumas das ameaças lembram os top 10 do OWASP para aplicativos web, enquanto outras são específicas dos modelos de linguagem.
Semelhante aos aplicativos web, algumas dessas vulnerabilidades podem ser melhor abordadas quando o aplicativo LLM é projetado, desenvolvido e treinado. Por exemplo, o envenenamento de dados de treinamento pode ser realizado introduzindo vulnerabilidades no conjunto de dados de treinamento usado para treinar novos modelos. As informações envenenadas são então apresentadas ao usuário quando o modelo está ativo. Vulnerabilidades da cadeia de suprimentos e design inseguro de plug-ins são vulnerabilidades introduzidas em componentes adicionados ao modelo, como pacotes de software de terceiros. Por fim, o gerenciamento de autorizações e permissões é essencial ao lidar com agência excessiva, onde modelos irrestritos podem realizar ações não autorizadas dentro do aplicativo ou infraestrutura mais amplos.
Por outro lado, a injeção de prompts, o modelo de negação de serviço e a divulgação de informações confidenciais podem ser mitigados com a adoção de uma solução de segurança de proxy como o firewall para IA da Cloudflare. Nas seções a seguir, daremos mais detalhes sobre essas vulnerabilidades e vamos discutir como a Cloudflare está posicionada de forma ideal para mitigá-las.
Implantações de LLMs
Os riscos do modelo de linguagem também dependem do modelo de implantação. Atualmente, podemos ver três abordagens principais de implantação: LLMs internos, públicos e de produto. Nos três cenários, você precisa proteger os modelos contra abusos, proteger quaisquer dados proprietários armazenados no modelo e proteger o usuário final contra informações erradas ou exposição a conteúdo inapropriado.
LLMs internos: as empresas desenvolvem LLMs para apoiar a força de trabalho em suas tarefas diárias. Eles são considerados ativos corporativos e não devem ser acessados por não funcionários. Os exemplos incluem um co-piloto de IA treinado em dados de vendas e interações com clientes usado para gerar propostas personalizadas, ou um LLM treinado em uma base de conhecimento interna que pode ser consultado por engenheiros.
LLMs públicos: são LLMs que podem ser acessados fora dos limites de uma corporação. Muitas vezes, essas soluções têm versões gratuitas que qualquer pessoa pode usar e, muitas vezes, são treinadas com base no conhecimento geral ou público. Exemplos incluem o GPT da OpenAI ou o Claude da Anthropic.
LLM de produto: do ponto de vista corporativo, os LLMs podem ser parte de um produto ou serviço oferecido aos seus clientes. Geralmente, são soluções auto-hospedadas personalizadas que podem ser disponibilizadas como uma ferramenta para interagir com os recursos da empresa. Os exemplos incluem bots de chat de suporte ao cliente ou o assistente de IA da Cloudflare .
Do ponto de vista do risco, a diferença entre os LLMs de produto e públicos é sobre quem carrega o impacto dos ataques bem-sucedidos. Os LLMs públicos são considerados uma ameaça aos dados porque os dados que acabam no modelo podem ser acessados por praticamente qualquer pessoa. Esse é um dos motivos pelos quais muitas corporações aconselham seus funcionários a não usar informações confidenciais em prompts de serviços disponíveis publicamente. Os LLMs de produtos podem ser considerados uma ameaça para as empresas e sua propriedade intelectual se os modelos tiverem acesso a informações proprietárias durante o treinamento (por design ou por acidente).
Firewall para IA
O firewall para IA da Cloudflare é implantado como um WAF tradicional, em que cada chamada de API com um prompt de LLM é verificada quanto a padrões e assinaturas de possíveis ataques.
O firewall para IA pode ser implantado na frente de modelos hospedados na plataforma Cloudflare Workers AI ou de modelos hospedados em qualquer outra infraestrutura de terceiros. Ele também pode ser usado com o Cloudflare AI Gateway e os clientes podem controlar e configurar o firewall para IA usando o plano de controle do WAF.
O firewall para IA funciona como um firewall de aplicativos web tradicional. Ele é implantado na frente de um aplicativo LLM e verifica todas as solicitações para identificar assinaturas de ataque.
Evitar ataques volumétricos
Uma das ameaças listadas pelo OWASP é o modelo de negação de serviço. Semelhante aos aplicativos tradicional, um ataque DoS é realizado consumindo uma quantidade excepcionalmente alta de recursos, resultando na redução da qualidade do serviço ou possivelmente aumentando os custos de execução do modelo. Dada a quantidade de recursos que os LLMs requerem para funcionar e a imprevisibilidade da entrada do usuário, esse tipo de ataque pode ser prejudicial.
Esse risco pode ser mitigado com a adoção de políticas de limitação de taxa que controlam a taxa de solicitações de sessões individuais, limitando assim a janela de contexto. Ao fazer proxy do seu modelo através da Cloudflare hoje, você obtém proteção contra DDoS pronta para uso. Você também pode usar limitação de taxa e limitação de taxa avançada para gerenciar a taxa de solicitações permitidas para alcançar seu modelo definindo uma taxa máxima de solicitações executada por um endereço de IP individual ou chave de API durante uma sessão.
Identificar informações confidenciais com a detecção de dados confidenciais
Existem dois casos de uso para dados confidenciais, dependendo de você ser o proprietário do modelo e dos dados ou se quiser evitar que os usuários enviem dados para LLMs públicos.
Conforme definido pelo OWASP, a divulgação de informações confidenciais ocorre quando os LLMs inadvertidamente revelam dados confidenciais nas respostas, levando ao acesso não autorizado de dados, violações de privacidade e falhas de segurança. Uma maneira de evitar isso é adicionar validações de prompt rigorosas. Outra abordagem é identificar quando as informações de identificação pessoal saem do modelo. Isso é relevante, por exemplo, quando um modelo foi treinado com uma base de conhecimento da empresa que pode incluir informações confidenciais, como informações de identificação pessoal (como número do seguro social), código proprietário ou algoritmos.
Os clientes que usam LLMs por trás do Cloudflare WAF podem empregar o conjunto de regras gerenciadas do WAF de detecção de dados confidenciais (SDD) para identificar determinadas informações de identificação pessoal que são retornadas pelo modelo na resposta. Os clientes podem analisar as correspondências de SDD no WAF Security Events. Hoje, a SDD é oferecida como um conjunto de regras gerenciadas projetadas para buscar informações financeiras (como números de cartão de crédito), bem como segredos (chave de API). Como parte do roteiro, planejamos permitir que os clientes criem suas próprias impressões digitais personalizadas.
O outro caso de uso destina-se a evitar que os usuários compartilhem informações de identificação pessoal ou outras informações confidenciais com provedores de LLM externos, como a OpenAI ou a Anthropic. Para se proteger contra esse cenário, planejamos expandir a SDD para verificar o prompt de solicitações e integrar seu resultado com o AI Gateway onde, juntamente com o histórico do prompt, detectamos se determinados dados confidenciais foram incluídos na solicitação. Vamos começar usando as regras de SDD existentes e planejamos permitir que os clientes escrevam suas próprias assinaturas personalizadas. Com relação a isso, a ofuscação é outro recurso sobre o qual ouvimos muitos clientes falarem. Uma vez disponível, a SDD expandida permitirá que os clientes ofusquem certos dados confidenciais em um prompt antes que eles cheguem ao modelo. A SDD na fase de solicitação está sendo desenvolvida.
Como prevenir abusos de modelo
O abuso de modelo é uma categoria mais ampla de abuso. Isso inclui abordagens como "injeção de prompt" ou o envio de solicitações que geram alucinações ou levam a respostas imprecisas, ofensivas, inadequadas ou simplesmente fora do tópico.
A injeção de prompt é uma tentativa de manipular um modelo de linguagem por meio de entradas especialmente criadas, causando respostas não intencionais pelo LLM. Os resultados de uma injeção podem variar, desde a extração de informações confidenciais até influenciar a tomada de decisões, imitando interações normais com o modelo. Um exemplo clássico de injeção de prompt é a manipulação de um CV para afetar o resultado das ferramentas de triagem de currículos.
Um caso de uso comum que ouvimos dos clientes do nosso AI Gateway é que eles desejam evitar que seu aplicativo gere linguagem tóxica, ofensiva ou problemática. Os riscos de não controlar o resultado do modelo incluem danos à reputação e danos ao usuário final ao fornecer uma resposta não confiável.
Esses tipos de abuso podem ser gerenciados com a adição de uma camada extra de proteção que fica na frente do modelo. Essa camada pode ser treinada para bloquear tentativas de injeção ou bloquear prompts que se enquadram em categorias inadequadas.
Validação de prompt e resposta
O firewall de IA executa uma série de detecções projetadas para identificar tentativas de injeção de prompt e outros abusos, como garantir que o tópico permaneça dentro dos limites definidos pelo proprietário do modelo. Como outros recursos existentes do WAF, o firewall para IA procura automaticamente prompts incorporados em solicitações HTTP ou permite que os clientes criem regras com base em onde no corpo JSON da solicitação o prompt pode ser encontrado.
Uma vez ativado, o firewall analisa cada prompt e fornece uma pontuação com base na probabilidade de ser malicioso. Ele também marca o prompt com base em categorias predefinidas. A pontuação varia de 1 a 99, que indica a probabilidade de uma injeção de prompt, com 1 sendo o mais provável.
Os clientes podem criar regras de WAF para bloquear ou lidar com solicitações com uma pontuação específica em uma ou ambas as dimensões. Você pode combinar essa pontuação com outros sinais existentes (como pontuação de bots ou pontuação de ataques) para determinar se a solicitação deve chegar ao modelo ou ser bloqueada. Por exemplo, poderia ser combinada com uma pontuação de bots para identificar se a solicitação é maliciosa e gerada por uma fonte automatizada.
A detecção de injeções de prompt e de abuso de prompt faz parte do escopo do firewall para IA. Iteração antecipada do design do produto.
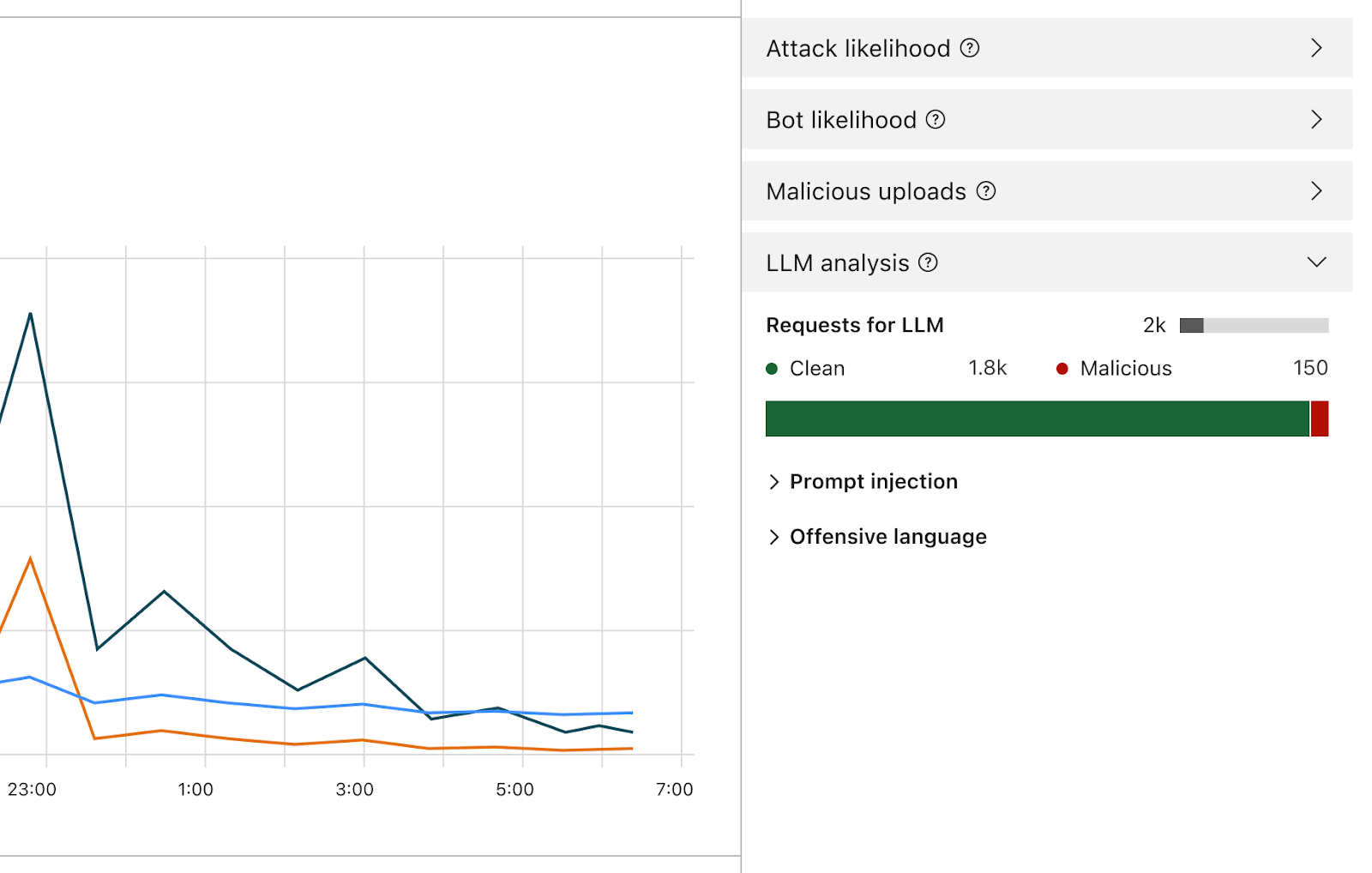
Além da pontuação, atribuímos tags a cada prompt que podem ser usadas ao criar regras para evitar que prompts pertencentes a qualquer uma dessas categorias cheguem ao seu modelo. Por exemplo, os clientes podem criar regras para bloquear tópicos específicos. Isso inclui prompts usando palavras categorizadas como ofensivas ou ligadas a religião, conteúdo sexual ou política, por exemplo.
Como posso usar o firewall para IA? Quem tem isso?
Os clientes Enterprise com a oferta avançada de segurança de aplicativos podem começar a usar imediatamente a limitação de taxa avançada e a detecção de dados confidenciais (na fase de resposta). Ambos os produtos podem ser encontrados na seção WAF do painel de controle da Cloudflare. O recurso de validação de prompt do firewall para IA está atualmente em desenvolvimento e uma versão beta será lançada nos próximos meses para todos os usuários do Workers AI . Inscreva-se para entrar na lista de espera e receba a notificação quando o recurso estiver disponível.
Conclusão
A Cloudflare é um dos primeiros provedores de segurança a lançar um conjunto de ferramentas para proteger aplicativos de IA. Usando o firewall para IA, os clientes podem controlar quais prompts e solicitações chegam aos seus modelos de linguagem, reduzindo o risco de abusos e exfiltração de dados. Continue acompanhando para saber mais sobre como a segurança de aplicativos de IA está evoluindo.