


À compter du 25 août 2023, nous avons commencé à observer des attaques HTTP inhabituellement volumineuses frappant bon nombre de nos clients. Ces attaques ont été détectées et atténuées par notre système anti-DDoS automatisé. Il n'a pas fallu longtemps pour que ces attaques atteignent des tailles record, pour finir par culminer à un peu plus de 201 millions de requêtes par seconde, soit un chiffre près de trois fois supérieur à la précédente attaque la plus volumineuse que nous ayons enregistrée.
Le fait que l'acteur malveillant soit parvenu à générer une attaque d'une telle ampleur à l'aide d'un botnet de tout juste 20 000 machines s'avère préoccupant. Certains botnets actuels se composent de centaines de milliers ou de millions de machines. Comme qu'Internet dans son ensemble ne reçoit habituellement qu'entre 1 et 3 milliards de requêtes chaque seconde, il n'est pas inconcevable que l'utilisation de cette méthode puisse concentrer l'intégralité du nombre de requêtes du réseau sur un petit nombre de cibles.
Détection et atténuation
Il s'agissait d'un nouveau vecteur d'attaque évoluant à une échelle sans précédent, mais les protections Cloudflare existantes ont largement pu absorber le plus gros de ces attaques. Si nous avons constaté au départ un certain impact sur le trafic client (environ 1 % des requêtes ont été touchées pendant la vague d'attaques initiale), nous avons ensuite pu perfectionner nos méthodes d'atténuation afin de bloquer l'attaque pour n'importe quel client Cloudflare sans affecter nos systèmes.
Nous avons remarqué ces attaques en même temps que deux autres acteurs majeurs du secteur : Google et AWS. Nous nous sommes attelés au renforcement des systèmes de Cloudflare afin de nous assurer qu'aujourd'hui tous nos clients sont protégés contre cette nouvelle méthode d'attaque DDoS sans impact sur ces derniers. Nous avons également participé, avec Google et AWS, à une révélation coordonnée de l'attaque aux prestataires affectés et aux fournisseurs d'infrastructure essentielle.
Cette attaque a été rendue possible par l'abus de certaines fonctionnalités du protocole HTTP/2 et des détails de mise en œuvre des serveurs (voir la CVE-2023-44487 pour plus d'informations). Comme l'attaque tire parti d'une faiblesse sous-jacente du protocole HTTP/2, nous pensons que tous les fournisseurs qui ont déployé le HTTP/2 subiront l'attaque. Ce constat comprend tous les serveurs web modernes. Aux côtés de Google et d'AWS, nous avons divulgué la méthode d'attaque aux fournisseurs de serveurs web qui, nous l'espérons, déploieront les correctifs. Entre temps, la meilleure défense consiste à utiliser un service d'atténuation des attaques DDoS tel que Cloudflare en amont de chaque réseau en contact avec Internet ou de chaque serveur d'API.
Cet article s'intéressera en profondeur aux détails du protocole HTTP/2, la fonctionnalité exploitée par les acteurs malveillants pour générer ces attaques d'envergure, ainsi qu'aux stratégies d'atténuation que nous avons appliquées pour nous assurer que tous nos clients sont protégés. Nous espérons qu'en publiant ces détails d'autres serveurs web et services affectés disposeront des informations dont ils ont besoin pour mettre en œuvre ces stratégies d'atténuation. En outre, l'équipe chargée des normes du protocole HTTP/2, de même que les équipes travaillant sur les futures normes web, pourront mieux concevoir ces dernières afin d'empêcher de telles attaques.
Détails de l'attaque RST
Le protocole d'application HTTP sous-tend Internet. La norme HTTP Semantics est commune à toutes les versions de HTTP : l'architecture générale, la terminologie et les aspects de protocole, comme les messages de requête et de réponse, les méthodes, les codes d'état, les champs d'en-tête et de trailer, le contenu des messages et bien d'autres. Chaque version individuelle de HTTP définit la manière dont la sémantique est transformée au « format conversation » (wire) pour l'échange sur Internet. Un client doit, par exemple, sérialiser un message de requête en données binaires avant de l'envoyer. Le serveur l'analyse ensuite et le retransforme en message qu'il peut traiter.
Le protocole HTTP/1.1 utilise une forme textuelle de sérialisation. Les messages de requête et de réponse sont échangés sous la forme d'un flux de caractères ASCII, envoyé via une couche de transport fiable, comme le TCP, selon le format suivant (dans lequel CRLF signifie retour chariot et saut de ligne) :
HTTP-message = start-line CRLF
*( field-line CRLF )
CRLF
[ message-body ]Une requête GET très simple pour https://blog.cloudflare.com/ ressemblerait, par exemple, à ceci sur la conversation :
GET / HTTP/1.1 CRLFHost: blog.cloudflare.comCRLFCRLF
Et la réponse ressemblerait à ce qui suit :
HTTP/1.1 200 OK CRLFServer: cloudflareCRLFContent-Length: 100CRLFtext/html; charset=UTF-8CRLFCRLF<100 bytes of data>
Ce format encapsule les messages sur la conversation, pour indiquer qu'il est possible d'utiliser une unique connexion TCP pour échanger plusieurs requêtes et réponses. Le format nécessite toutefois que chaque message soit envoyé en entier. En outre, afin de faire entrer correctement en corrélation les requêtes avec les réponses, un ordre strict se révèle nécessaire. Les messages peuvent donc être échangés de manière sérielle et ne peuvent pas être multiplexés. Deux requêtes GET, pour https://blog.cloudflare.com/ et https://blog.cloudflare.com/page/2/,, se présenteraient ainsi sous la forme suivante :
GET / HTTP/1.1 CRLFHost: blog.cloudflare.comCRLFCRLFGET /page/2/ HTTP/1.1 CRLFHost: blog.cloudflare.comCRLFCRLF
Et les réponses :
HTTP/1.1 200 OK CRLFServer: cloudflareCRLFContent-Length: 100CRLFtext/html; charset=UTF-8CRLFCRLF<100 bytes of data>CRLFHTTP/1.1 200 OK CRLFServer: cloudflareCRLFContent-Length: 100CRLFtext/html; charset=UTF-8CRLFCRLF<100 bytes of data>
Les pages web nécessitent davantage d'interactions HTTP compliquées que ces exemples. Lorsque vous visitez le blog de Cloudflare, votre navigateur charge plusieurs scripts, styles et ressources multimédias. Si vous accédez à la page d'accueil à l'aide du protocole HTTP/1.1 et que vous décidez rapidement de vous rendre sur la page 2, votre navigateur a le choix entre deux options. Soit attendre l'ensemble des réponses en attente pour la page que vous ne souhaitez plus consulter avant de démarrer la page 2, soit annuler les requêtes en transit en mettant fin à la connexion TCP et en établissant une nouvelle connexion. Aucune de ces options ne s'avère particulièrement pratique. Les navigateurs ont tendance à contourner ces limitations en gérant un pool de connexions TCP (jusqu'à 6 par hôte) et en mettant en œuvre une logique complexe de répartition des requêtes au sein du pool.
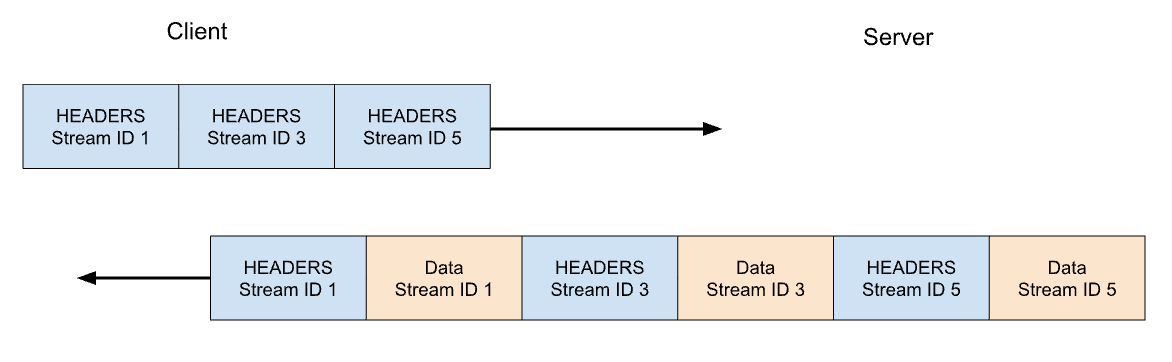
Le protocole HTTP/2 répond à bon nombre des problèmes du HTTP/1.1. Chaque message HTTP est sérialisé sous la forme d'un ensemble de trames HTTP/2 disposant d'un type, d'une longueur, de marqueurs, d'un identifiant (ID) de flux et d'un contenu. L'ID de flux indique clairement quels octets sur la conversation s'appliquent à un message donné, afin de permettre le multiplexage et la concurrence en toute sécurité. Les flux sont bidirectionnels. Les clients envoient des trames et les serveurs répondent par des trames utilisant le même ID.
En HTTP/2, notre requête GET pour https://blog.cloudflare.com serait échangée sur l'ID de flux 1, le client envoyant une trame HEADERS et le serveur répondant par une trame HEADERS, suivies par une ou plusieurs trames DATA. Comme les requêtes du client utilisent toujours des ID de flux impairs, les requêtes suivantes utiliseront donc les ID de flux 3, 5 et ainsi de suite. Les réponses peuvent être transmises dans n'importe quel ordre et les trames provenant de flux différents peuvent être entrelacées.
Le multiplexage et la concurrence des flux constituent de puissantes fonctionnalités du protocole HTTP/2. Elles permettent l'utilisation plus efficace d'une unique connexion TCP. Le HTTP/2 optimise la récupération de ressources, notamment lorsqu'elle est associée à la priorisation. En réciproque, le fait de faciliter le lancement de vastes quantités de tâches parallèles aux clients peut accroître le pic de demande de ressources serveur par rapport au HTTP/1.1. Il s'agit là d'un vecteur évident de déni de service.
Afin de proposer quelques garde-fous, le HTTP/2 avance la notion de maximum de flux concurrents actifs. Le paramètre SETTINGS_MAX_CONCURRENT_STREAMS permet à un serveur d'annoncer sa limite de concurrence. Par exemple, si le serveur annonce une limite de 100, seules 100 requêtes pourront être actives à un moment donné. Si un client tente d'ouvrir un flux au-delà de cette limite, ce dernier devra être rejeté par le serveur à l'aide d'une trame RST_STREAM. Le rejet d'un flux n'affecte pas les autres flux en transit sur la connexion.
La réalité de l'affaire est un peu plus compliquée. Les flux présentent un cycle de vie. Vous trouverez ci-dessous un schéma de l'état d'un flux HTTP/2. Le client et le serveur gèrent leurs propres vues de l'état d'un flux. L'envoi ou la réception de trames HEADERS, DATA et RST_STREAM déclenchent les transitions. Les vues de l'état d'un flux sont indépendantes, mais restent synchronisées.
Les trames HEADERS et DATA intègrent un marqueur END_STREAM qui, lorsqu'il est défini sur la valeur 1 (true), peut déclencher une transition d'état.
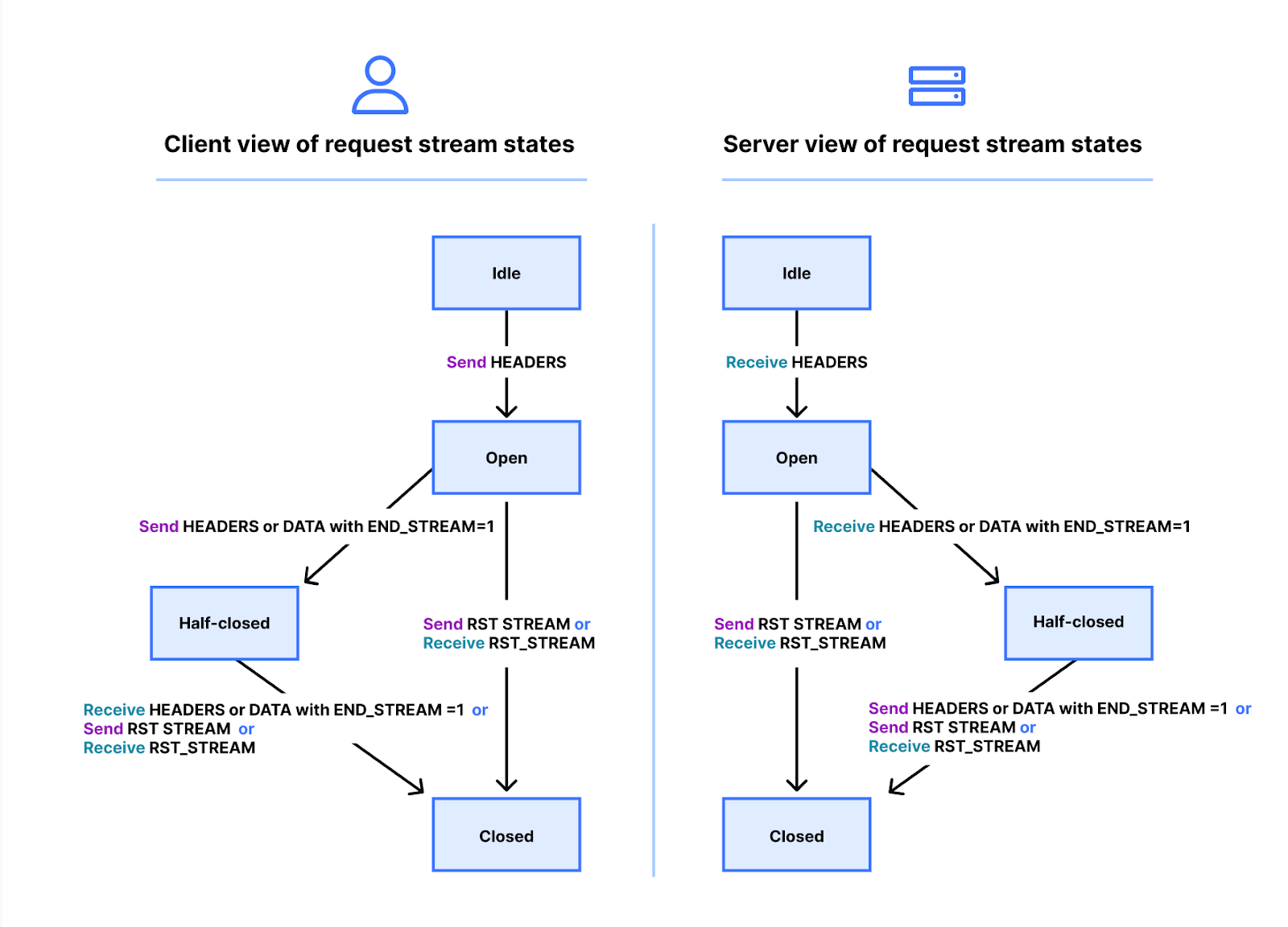
Examinons ceci plus en détail avec un exemple de requête GET sans contenu de message. Le client envoie la requête sous la forme d'une trame HEADERS comportant le marqueur END_STREAM défini sur 1. Il déclenche en premier lieu la transition de l'état « idle » (à l'arrêt) à « open » (ouvert), avant de déclencher immédiatement une transition vers l'état « half-closed » (mi-fermé). L'état « half-closed » du client indique qu'il ne peut plus envoyer de trames HEADERS ou DATA, mais uniquement des trames WINDOW_UPDATE, PRIORITY ou RST_STREAM. Il peut toutefois recevoir n'importe quelle trame.
Une fois que le serveur reçoit et analyse la trame HEADERS, il fait passer l'état du flux d'« idle » à « open », puis à « half-closed », afin de correspondre à celui du client. L'état « half-closed » du serveur indique qu'il peut envoyer n'importe quelle trame, mais qu'il ne peut recevoir que des trames WINDOW_UPDATE, PRIORITY ou RST_STREAM.
La réponse à la requête GET contient un contenu de message, aussi le serveur envoie-t-il une trame HEADERS comportant le marqueur END_STREAM défini sur 0, puis une trame DATA comportant le marqueur END_STREAM défini sur 1. La trame DATA déclenche la transition du flux de half-closed à closed (fermé) sur le serveur. Lorsque le client la reçoit, il lance également sa transition vers l'état « closed ». Une fois un flux fermé, plus aucune trame ne peut être envoyée ou reçue.
En appliquant ce cycle de vie dans le contexte de la concurrence, le protocole HTTP/2 précise :
Les flux à l'état « open » ou dans l'un des deux états « half-closed » comptent dans le nombre maximum de flux qu'un point de terminaison est autorisé à ouvrir. Les flux dans l'un de ces trois états comptent à l'égard de la limite annoncée dans le paramètre SETTINGS_MAX_CONCURRENT_STREAMS.
En théorie, la limite de concurrence est utile. Certains facteurs pratiques entravent toutefois son efficacité, que nous aborderons plus tard dans cet article.
Annulation de requête HTTP/2
Un peu plus tôt, nous avons évoqué l'annulation de requêtes en transit par le client. Le protocole HTTP/2 prend cette fonctionnalité en charge de manière plus efficace que le HTTP/1.1. Plutôt que de devoir abandonner la connexion dans son ensemble, un client peut désormais envoyer une trame RST_STREAM pour un seul flux. Cette dernière demande au serveur de mettre fin au traitement de la requête et d'abandonner la réponse. Cette opération libère des ressources serveur et permet d'éviter de gaspiller de la bande passante.
Reprenons notre exemple précédent, avec les trois requêtes. Cette fois, le client annule la requête sur le flux 1 après l'envoi de toutes les trames HEADERS. Le serveur analyse la trame RST_STREAM avant d'être prêt à diffuser la réponse et, à la place, ne répond qu'aux flux 3 et 5 :
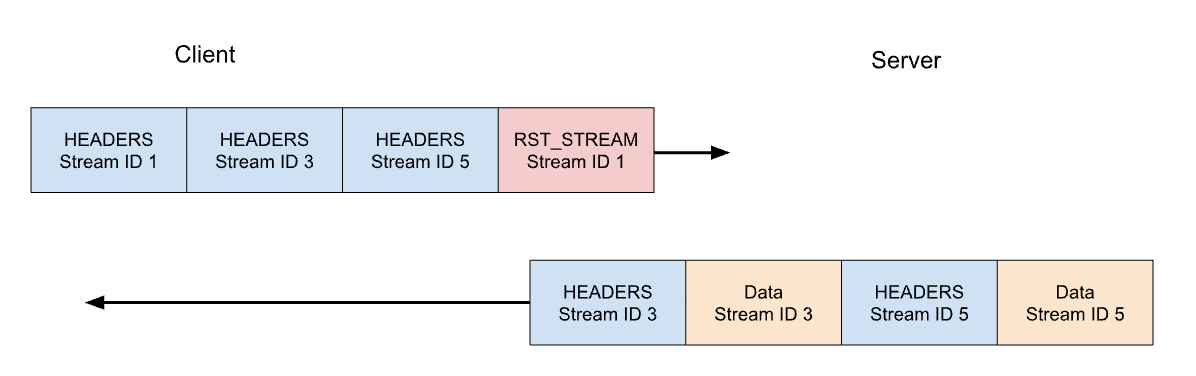
L'annulation de requête constitue une fonctionnalité bien utile. Lorsque vous parcourez une page web comportant plusieurs images, par exemple, un navigateur web peut annuler les images qui ne sont pas affichées dès l'ouverture. Les images qui lui parviennent peuvent donc être chargées plus rapidement. Le protocole HTTP/2 rend ce comportement bien plus efficace par rapport au HTTP/1.1.
Un flux de requête annulé passe rapidement par tous les états du cycle de vie d'un flux. La trame HEADERS envoyée par le client, comportant le marqueur END_STREAM défini sur 1, passe de l'état « idle » à « open », puis à « half-closed », avant que la trame RST_STREAM ne déclenche immédiatement sa transition de l'état « half-closed » à « closed ».

Souvenez-vous que seuls les flux à l'état « open » ou « half-closed » sont comptabilisés dans la limite de concurrence du flux. Lorsqu'un client annule un flux, il regagne instantanément la capacité d'ouvrir un autre flux à la place et peut immédiatement envoyer une nouvelle requête. C'est là le cœur du fonctionnement de la vulnérabilité CVE-2023-44487.
Des réinitialisations rapides conduisant à un déni de service
Le processus d'annulation de requête du protocole HTTP/2 peut être utilisé de manière abusive en réinitialisant rapidement un nombre illimité de flux. Lorsqu'un serveur HTTP/2 peut traiter des trames client-sent RST_STREAM et leur faire changer d'état suffisamment rapidement, ces réinitialisations rapides ne posent pas de problème. Les soucis commencent lorsqu'une quelconque forme de retard ou de latence apparaît lors du nettoyage. Le client peut avoir à traiter un nombre de requêtes si important que les tâches s'accumulent, en entraînant une consommation excessive de ressources sur le serveur.
Une architecture de déploiement HTTP courante consiste à exécuter un proxy HTTP/2 ou un équilibreur de charge en amont des autres composants. Lorsqu'une requête client arrive, elle est rapidement retransmise et la tâche réelle est effectuée sous forme d'activité asynchrone à un autre endroit. Cette opération permet au proxy de traiter le trafic client très efficacement. Toutefois, cette séparation des préoccupations peut compliquer la phase de nettoyage des tâches en cours pour le proxy. Ce type de déploiement est donc plus susceptible de rencontrer des problèmes en cas de réinitialisations rapides.
Lorsque les proxys inverses de Cloudflare traitent du trafic client entrant HTTP/2, ils copient les données du socket de la connexion au sein d'un tampon et traitent ces données en tampon dans l'ordre. Chaque requête est lue (trames HEADERS et DATA) et transmise à un service en amont. Lorsque les trames RST_STREAM sont lues, l'état local de la requête est abandonné et l'amont est notifié de l'annulation de la requête. Les proxys répètent ensuite le processus jusqu'à ce que toutes les données en tampon aient été traitées. Cette logique peut toutefois être utilisée de manière abusive : si un client malveillant commence à envoyer une énorme chaîne de requêtes, qu'il réinitialise au début d'une connexion, nos serveurs s'empresseront de toutes les lire. Cette situation engendrera alors une pression sur les serveurs en amont, au point qu'ils se retrouveront incapables de traiter les nouvelles requêtes entrantes.
Un point important à souligner est que la concurrence de flux ne peut pas, par elle-même, atténuer les réinitialisations rapides. Le client peut créer des requêtes afin de produire des taux de requêtes élevés, peu importe la valeur choisie par le serveur pour le paramètre SETTINGS_MAX_CONCURRENT_STREAMS.
Anatomie d'une réinitialisation rapide

Il est un peu difficile à analyser, en raison du grand nombre de trames. Nous pouvons en obtenir un résumé rapide à l'aide de l'outil HTTP/2 de Wireshark, disponible sous « Statistics » (Statistiques) :
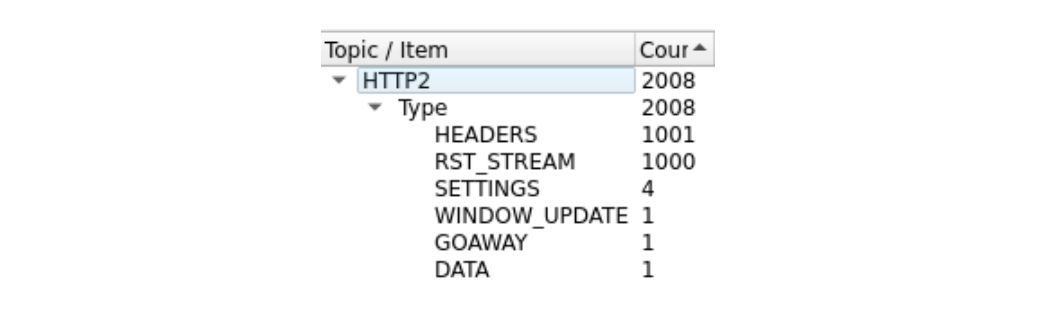
La première trame de cette trace, dans le paquet 14, est la trame SETTINGS du serveur, qui annonce un nombre maximum de flux concurrents de 100. Dans le paquet 15, le client envoie quelques trames de contrôle, puis commence à envoyer des requêtes, rapidement réinitialisées. La première trame HEADERS fait 26 octets de long, tandis que toutes les trames HEADERS suivantes ne mesurent que 9 octets. Cette différence de taille est due à une technologie de compression nommée HPACK. Au total, le paquet 15 contient 525 requests, remontant le long du flux 1051.
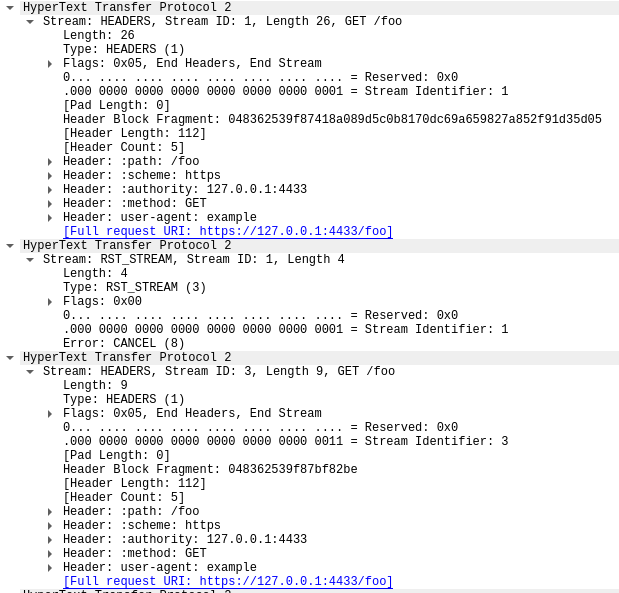
Curieusement, la trame RST_STREAM du flux 1051 ne rentre pas dans le paquet 15. Nous voyons donc, dans le paquet 16, le serveur répondre par une erreur 404. Le client envoie ensuite la trame RST_STREAM dans le paquet 17, avant de passer à l'envoi des 475 requêtes suivantes.
Veuillez noter que bien que le serveur ait annoncé 100 flux concurrents, les deux paquets envoyés par le client comportaient bien plus de trames HEADERS. Le client n'a pas attendu le trafic de retour du serveur, il n'était limité que par la taille des paquets qu'il pouvait envoyer. Aucune trame RST_STREAM du serveur n'apparaît dans cette trace, un constat qui indique que le serveur n'a pas observé de violation du nombre de flux concurrents.
Impact sur les clients
Comme mentionné plus haut, lorsque les requêtes sont annulées, les services en amont sont notifiés et peuvent abandonner ces dernières avant de gaspiller trop de ressources sur leur traitement. C'est ce qui s'est passé dans cette attaque, au cours de laquelle les requêtes malveillantes n'ont jamais été retransmises aux serveurs d'origine. Toutefois, l'ampleur de ces attaques a engendré des effets.
Tout d'abord, lorsque le taux de requêtes entrantes a atteint des pics jamais encore observés jusqu'ici, nous avons reçu des signalements de niveaux élevés d'erreurs 502 observées par les clients. C'est ce qui s'est produit dans nos datacenters les plus impactés, car ils avaient du mal à traiter toutes les requêtes. Notre réseau est conçu pour faire face aux attaques d'envergure, mais cette vulnérabilité a révélé une faiblesse au sein de notre infrastructure. Intéressons-nous de plus près aux détails, en nous concentrant sur la manière dont les requêtes entrantes sont traitées lorsqu'elles arrivent dans l'un de nos datacenters :
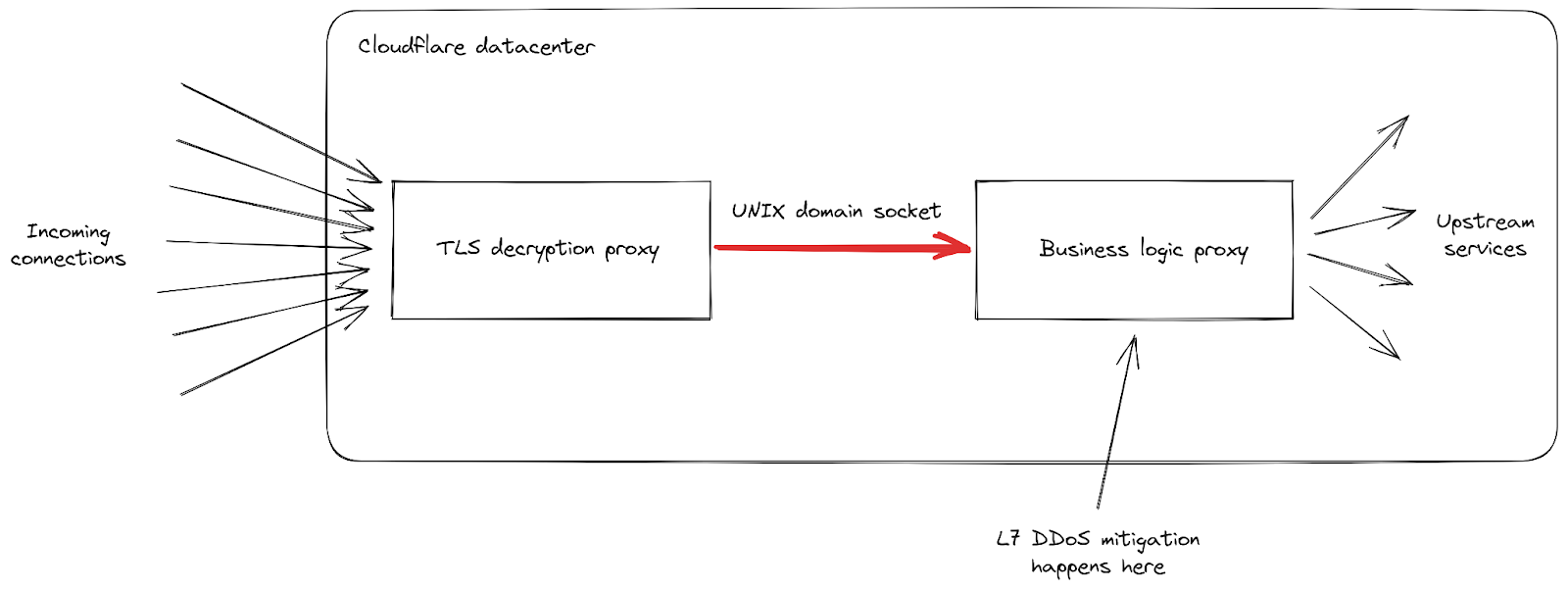
Nous pouvons voir que notre infrastructure se compose d'une chaîne de différents serveurs de proxy aux responsabilités différentes. Plus particulièrement, lorsqu'un client se connecte à Cloudflare pour envoyer du trafic HTTPS, ce dernier passe en premier par notre proxy de déchiffrement TLS, qui déchiffre le trafic TLS et traite le trafic HTTP 1, 2 ou 3, avant de le transmettre à notre proxy de « logique métier ». Ce dernier est responsable du chargement de l'ensemble des paramètres pour chaque client, puis du routage correct des requêtes vers les autres services d'amont. Plus important encore dans le cas qui nous intéresse, il est également responsable des fonctionnalités de sécurité. C'est là que l'atténuation des attaques sur la couche 7 est mise en œuvre.
Le problème avec ce vecteur d'attaque réside dans le fait qu'il parvient à envoyer un grand nombre de requêtes de manière très rapide, sur chaque connexion. Chacune d'elles devait être retransmise au proxy de logique métier avant que nous n'ayons l'occasion de la bloquer. Lorsque le volume de requêtes s'est révélé supérieur à la capacité de notre proxy, le pipeline reliant ces deux services a atteint son niveau de saturation dans certains de nos serveurs.
Quand cette situation se produit, le proxy TLS ne peut plus se connecter à son proxy d'amont. C'est pourquoi certains de nos clients ont vu s'afficher une erreur « 502 Bad Gateway » lors des attaques les plus graves. Il est important de noter qu'à la date d'aujourd'hui, les journaux utilisés pour produire les analyses HTTP sont également émis par notre proxy de logique métier. En conséquence, ces erreurs ne sont pas visibles au sein du tableau de bord Cloudflare. Nos tableaux de bord internes révèlent qu'environ 1 % des requêtes ont été affectées lors de la vague d'attaques initiale (avant la mise en œuvre des mesures d'atténuation), avec un pic se situant autour de 12 % pendant quelques secondes lors de l'attaque la plus massive, le 29 août. Le graphique suivant montre la proportion de ces erreurs sur une période de deux heures au cours de l'attaque :
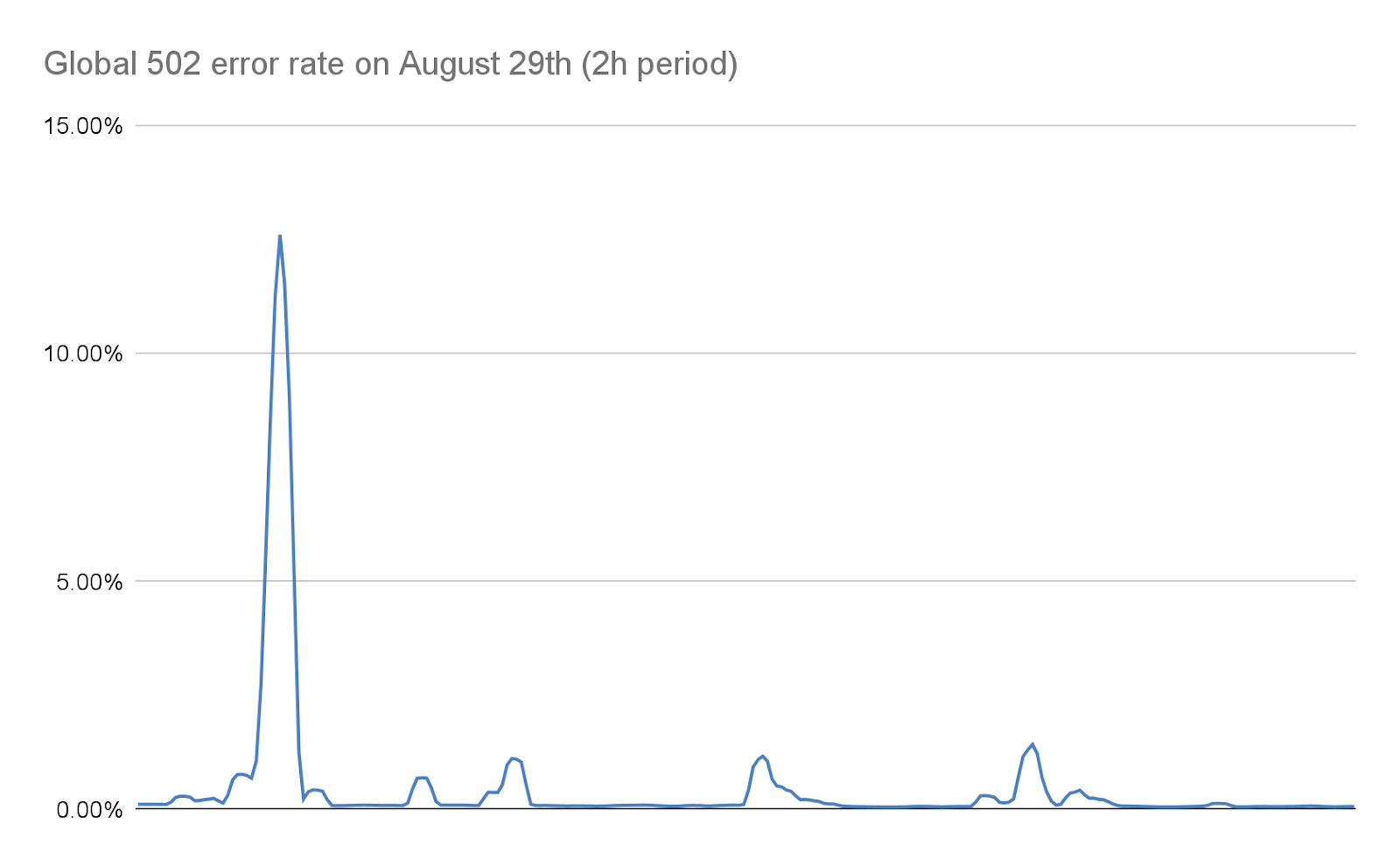
Nous nous sommes efforcés de réduire ce nombre de manière considérable les jours suivants, comme nous le détaillons plus loin dans cet article. Ce nombre aujourd'hui est effectivement de zéro, à la fois grâce aux modifications apportées à notre pile et à nos mesures d'atténuation, qui ont drastiquement réduit la taille de ces attaques.
Erreurs 499 et les défis liés à la concurrence des flux HTTP/2
Un autre symptôme signalé par certains clients réside dans l'augmentation des erreurs 499. La raison est ici quelque peu différente et se trouve liée à la concurrence de flux maximale au sein d'une connexion HTTP/2, comme détaillée précédemment dans l'article.
Les paramètres HTTP/2 sont échangés au début d'une connexion à l'aide de trames SETTINGS. En l'absence de réception d'un paramètre explicite, ce sont les valeurs par défaut qui s'appliquent. Lorsqu'un client établit une connexion HTTP/2, il peut soit attendre la trame SETTINGS d'un serveur (lent), soit présupposer les valeurs par défaut et commencer à envoyer des requêtes (rapide). Pour le paramètre SETTINGS_MAX_CONCURRENT_STREAMS, la valeur par défaut est, dans les faits, illimitée (les ID de flux s'appuient sur un espace mathématique de 31 bits et les requêtes utilisent les nombres impairs. la limite réelle est donc établie à 1 073 741 824). La spécification recommande qu'un serveur ne propose pas moins de 100 flux concurrents. Les clients sont généralement axés sur la vitesse. Ils n'ont donc pas tendance à attendre les paramètres du serveur et ce fait entraîne en quelque sorte une situation de compétition. Ils « parient » sur la limite que le serveur pourrait avoir choisie. S'ils se trompent, la requête sera rejetée et devra être renvoyée. Le fait de parier sur un ensemble numérique de 1 073 741 824 nombres s'avère pour le moins absurde. Pour contrebalancer cette situation, de nombreux clients décident de se limiter à l'émission de 100 flux concurrents, dans l'espoir que les serveurs suivent la recommandation de la spécification. Si les serveurs ont sélectionné une valeur inférieure à 100, le pari du client échoue et les flux sont réinitialisés.
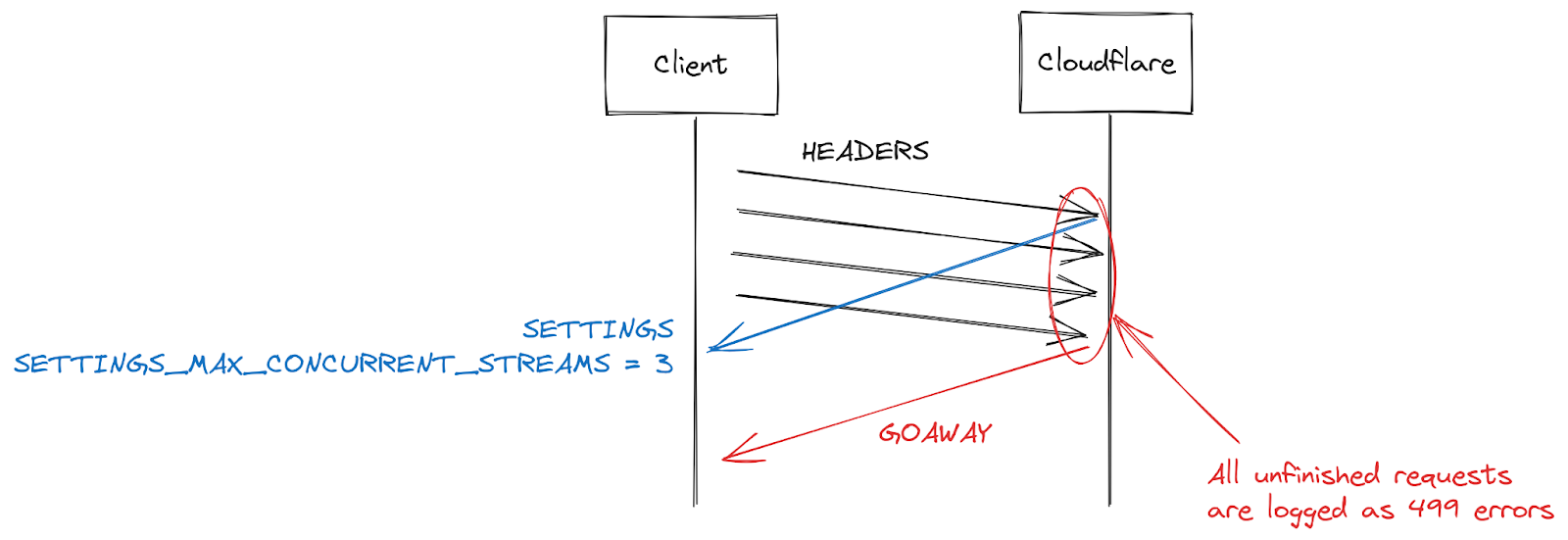
Un serveur pourrait réinitialiser un flux pour de nombreuses raisons en dehors d'un dépassement de la limite de concurrence. Le HTTP/2 est strict et nécessite qu'un flux soit fermé (closed) en cas d'erreurs d'interprétation ou d'erreurs logiques. En 2019, Cloudflare a développé plusieurs mesures d'atténuation en réponse aux vulnérabilités DoS du protocole HTTP/2. Plusieurs de ces vulnérabilités résultaient d'un mauvais comportement de la part du client, qui poussait le serveur à réinitialiser un flux. Une stratégie très efficace pour freiner ces clients consiste à compter le nombre de réinitialisations du serveur au cours d'une connexion puis, lorsque ce chiffre dépasse un certain seuil, de mettre un terme à cette dernière à l'aide d'une trame GOAWAY. Les clients peuvent commettre une ou deux erreurs au cours d'une connexion et il s'agit là d'un constat acceptable. Un client qui commet trop d'erreurs est probablement soit défectueux, soit malveillant, et le fait de mettre fin à la connexion répond aux deux cas.
En réponse aux attaques DoS permises par la vulnérabilité CVE-2023-44487, Cloudflare a réduit la concurrence de flux maximale à 64. Avant d'effectuer cette modification, nous n'avions pas conscience que les clients n'attendaient pas la trame SETTINGS et supposaient à la place que la concurrence était fixée à 100. Certaines pages web, comme les galeries d'images, entraînent effectivement l'envoi immédiat de 100 requêtes par le navigateur au début d'une connexion. Malheureusement, les 36 flux au-delà de notre limite devaient être réinitialisés et cette opération déclenchait les compteurs de nos mesures d'atténuation. Nous interrompions donc des connexions sur des clients légitimes, avec pour résultat un échec total du chargement des pages. Dès que nous avons constaté ce problème d'interopérabilité, nous avons de nouveau fixé la concurrence de flux maximale à 100.
Actions côté Cloudflare
En 2019, nous avons découvert plusieurs vulnérabilités DoS liées à l'implémentation du protocole HTTP/2. Cloudflare a développé et déployé une série de mesures de détection et d'atténuation en réponse. La vulnérabilité CVE-2023-44487 est une différente manifestation de la vulnérabilité HTTP/2. Toutefois, pour l'atténuer, nous avons pu étendre les protections existantes afin de surveiller les trames RST_STREAM envoyées par les clients et de mettre fin aux connexions lorsque ces dernières étaient utilisées à des fins abusives. Les scénarios d'utilisation légitimes des trames RST_STREAM par les clients n'ont pas été affectés.
En plus d'un correctif direct, nous avons mis en œuvre plusieurs améliorations du serveur concernant le traitement des trames HTTP/2 et du code de répartition des requêtes. Le serveur de logique métier a, en outre, fait l'objet de perfectionnements au niveau de la mise en file d'attente et de la planification. Ces derniers réduisent le travail inutile et améliorent la réponse aux annulations. Ensemble, ces mesures diminuent l'impact des divers schémas d'abus potentiels, tout en accordant plus d'espace au serveur pour traiter les requêtes avant d'atteindre la saturation.
Atténuer les attaques à un moment plus précoce
Cloudflare dispose déjà de systèmes en place permettant d'atténuer efficacement les attaques de très grande ampleur à l'aide de méthodes moins coûteuses. L'une d'elles se nomme « IP Jail » (Prison IP). En cas d'attaques hypervolumétriques, ce système collecte les adresses IP des clients participant à l'attaque et les empêche de se connecter à la propriété attaquée, que ce soit au niveau de l'adresse IP ou de notre proxy TLS. Ce système demande toutefois quelques secondes pour être pleinement efficace. Au cours de ces précieuses secondes, les serveurs d'origine sont déjà protégés, mais notre infrastructure doit encore absorber l'ensemble des requêtes HTTP. Comme ce nouveau botnet ne dispose dans les faits d'aucune période de démarrage, nous devons pouvoir neutraliser ces attaques avant qu'elles ne deviennent un problème.
Pour y parvenir, nous avons étendu le système IP Jail afin qu'il protège l'intégralité de notre infrastructure. Une fois une adresse IP « en prison », nous l'empêchons non seulement de se connecter à la propriété attaquée, mais interdisons également aux adresses IP correspondants d'utiliser le HTTP/2 pour se connecter à un autre domaine sur Cloudflare pendant quelque temps. Comme de tels abus du protocole ne sont pas possibles à l'aide du HTTP/1.x, l'acteur malveillant se trouve sévèrement limité dans sa capacité à conduire des attaques d'envergure, tandis qu'un client légitime partageant la même adresse IP ne constaterait d'une très légère diminution des performances pendant ce temps. Les mesures d'atténuation basées sur l'IP constituent un outil pour le moins brutal. C'est pourquoi nous devons faire preuve d'une extrême prudence lorsque nous les utilisons à grande échelle et chercher à éviter les faux positifs autant que possible. De même, comme la durée de vie d'une adresse IP donnée au sein d'un botnet est généralement courte, l'atténuation à long terme risque davantage de nuire que d'aider. Le graphique suivant montre l'évolution du nombre d'adresses IP lors de l'attaque dont nous avons été témoins :
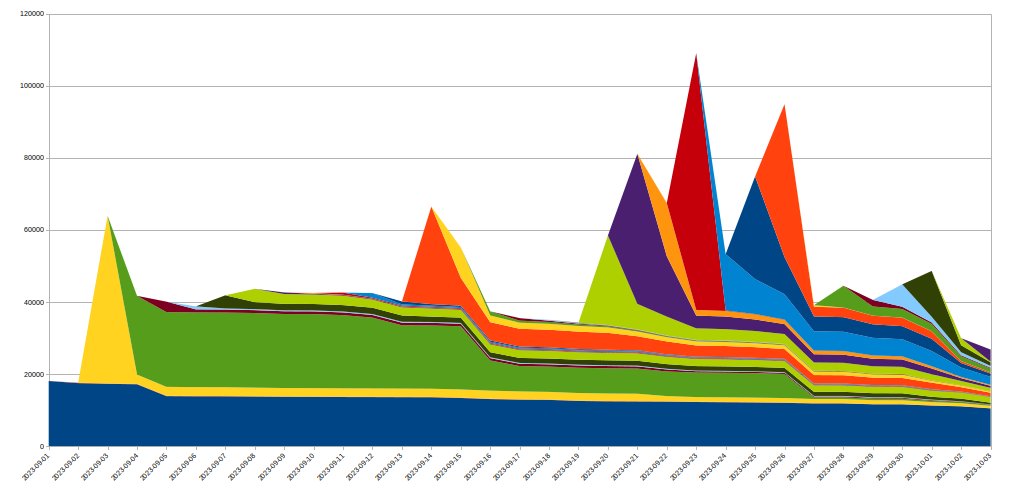
Il apparaît très clairement que les nouvelles adresses IP repérées lors d'une journée donnée disparaissent très rapidement après l'attaque.
Le fait que ces actions se déroulent dans notre proxy TLS, à l'entrée de notre pipeline HTTPS, permet d'économiser des ressources considérables par rapport à notre système d'atténuation de couche 7 habituel. Cette situation nous a permis de supporter ces attaques d'autant plus facilement et, aujourd'hui, le nombre d'erreurs 502 aléatoires dues à ces botnets a été réduit à zéro.
Améliorations en matière d'observabilité
L'un des autres fronts sur lequel nous avons apporté des modifications est celui de l'observabilité. Le fait de renvoyer des erreurs aux clients sans que ces dernières soient visibles dans les outils d'analyse des clients se révèle pour le moins insatisfaisant. Fort heureusement, nous avons lancé un projet visant à réorganiser ces systèmes bien avant les attaques récentes. Il permettra à terme à chaque service compris au sein de notre infrastructure de journaliser ses propres données, au lieu de s'en remettre à notre proxy de logique métier pour consolider et émettre les données de journalisation. Cet incident a fait ressortir l'importance de ce travail, dans le cadre duquel nous redoublons d'efforts.
Nous travaillons également à une meilleure journalisation au niveau de la connexion, afin de nous permettre de repérer ce type d'abus de protocole bien plus rapidement, afin d'améliorer nos capacités d'atténuation des attaques DDoS.
Conclusion
Si l'attaque à laquelle cet article est consacré constituait sans conteste la dernière attaque record à ce jour, nous savons que ce ne sera pas la dernière. Alors que les attaques gagnent chaque jour en sophistication, Cloudflare travaille avec acharnement aux moyens d'identifier les nouvelles menaces de manière proactive, en déployant des contremesures sur notre réseau mondial afin de protéger nos millions de clients, immédiatement et automatiquement.
Cloudflare fournit une protection contre les attaques DDoS gratuite, totalement illimitée et sans surcoût lié à l'utilisation à l'ensemble de ses clients, et ce depuis 2017. Nous proposons en outre une gamme de fonctionnalités de sécurité supplémentaires afin de répondre aux besoins des entreprises de toutes les tailles. Contactez-nous si vous n'êtes pas sûr de savoir si vous êtes protégé ou si vous souhaitez comprendre comment vous pourriez l'être.