
Hoy, CenturyLink/Level(3), uno de los principales proveedores de ancho de banda y servicios de Internet, sufrió una importante interrupción que afectó a algunos de los clientes de Cloudflare, así como a muchos otros servicios y proveedores de Internet. Mientras esperamos un análisis post mortem de CenturyLink/Level(3), quería escribir la cronología de lo que vimos, cómo los sistemas de Cloudflare desviaron el problema, por qué a pesar de nuestras mitigaciones algunos de nuestros clientes se vieron afectados, y la causa probable del problema.
Aumento de los errores
A las 10:03 UTC, nuestros sistemas de supervisión comenzaron a observar un aumento en el número de errores que llegaban a los servidores de origen de nuestros clientes. Se mostraban como "Errores 522" e indicaban que había un problema con la conexión de la red de Cloudflare al lugar donde nuestros clientes tenían alojadas sus aplicaciones.
Cloudflare está conectado a CenturyLink/Level(3) mediante un amplio y diverso conjunto de proveedores de red. Cuando nos encontramos con un aumento de errores en un proveedor de red, automáticamente nuestros sistemas intentan llegar a las aplicaciones de los clientes a través de proveedores alternativos. Debido al número de proveedores a los que tenemos acceso, normalmente podemos continuar enrutando el tráfico incluso cuando un proveedor tiene un problema.
Conjunto diverso de proveedores de red a los que se conecta Cloudflare. Fuente: https://bgp.he.net/AS13335#_asinfo
Mitigaciones automáticas
En este caso, a los pocos segundos de producirse el aumento de errores 522, nuestros sistemas automáticamente redirigieron el tráfico de CenturyLink/Level(3) a proveedores de red alternativos a los que nos conectamos, incluidos Cogent, NTT, GTT, Telia y Tata.
Nuestro centro de operaciones de red también recibió la alerta y, a partir de las 10:09 UTC, nuestro equipo empezó a tomar medidas adicionales para mitigar los problemas que nuestros sistemas automatizados no fueran capaces de resolver automáticamente. A pesar de haber perdido a CenturyLink/Level(3) como uno de nuestros proveedores de red, conseguimos mantener el flujo de tráfico a través de nuestra red para la mayoría de clientes y usuarios finales.
Sistemas automatizados del panel de control de Cloudflare reconociendo los daños que el fallo de CenturyLink/Level(3) provoca en Internet y enrutando automáticamente para evitarlo.
El siguiente gráfico muestra el tráfico entre la red de Cloudflare y las seis redes principales de nivel 1 que se encuentran entre los proveedores de red que utilizamos. La parte en rojo muestra el tráfico de CenturyLink/Level(3), que se desplomó casi a cero durante el incidente. También puedes ver cómo pudimos redirigir automáticamente el tráfico a otros proveedores de red durante el incidente para mitigar el impacto y asegurar que el tráfico siguiera fluyendo.
Tráfico a través de las seis redes principales de nivel 1 de los proveedores de red a los que Cloudflare se conecta. CenturyLink/Level(3) en rojo.
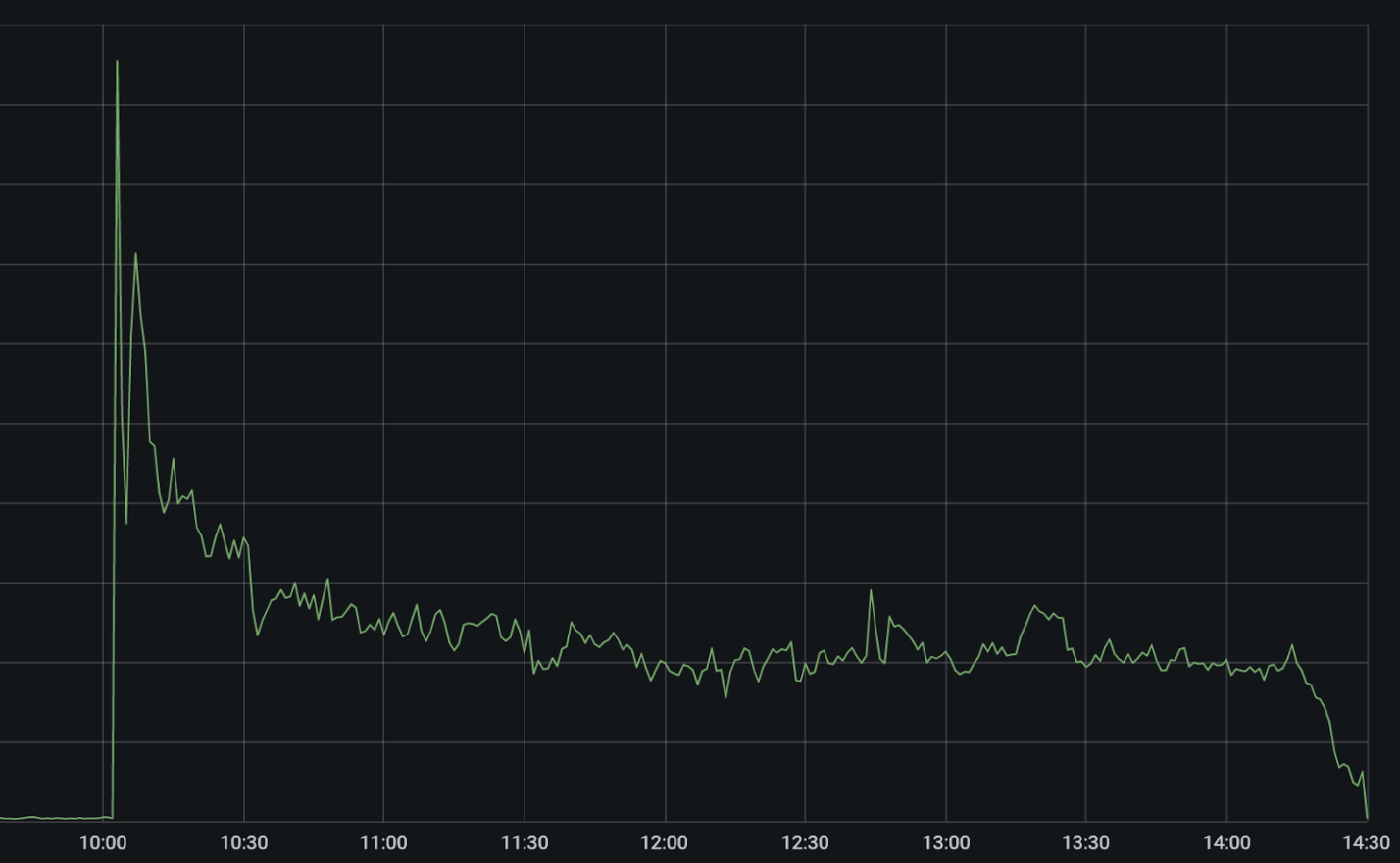
El siguiente gráfico muestra errores 522 (que indican nuestra incapacidad de llegar a las aplicaciones de los clientes) en nuestra red durante el momento del incidente.
El pico más pronunciado a las 10:03 UTC fue el fallo de la red CenturyLink/Level(3). Nuestros sistemas automatizados se activaron inmediatamente para intentar enrutar y reequilibrar el tráfico a través de proveedores de red alternativos, lo que provocó que los errores se redujeran a la mitad de forma inmediata y que luego acabaran cayendo a un 25 % del pico según se fueron optimizando las rutas automáticamente.
Entre las 10:03 UTC y las 10:11 UTC nuestros sistemas desactivaron automáticamente CenturyLink/Level(3) en las 48 ciudades en las que estamos conectados a ellos y enrutaron el tráfico a proveedores de red alternativos. Nuestros sistemas tienen en cuenta la capacidad de otros proveedores antes de redirigir el tráfico para prevenir fallos en cascada. Por ello, aunque el failover fue automático, no se produjo de forma instantánea en todas las ubicaciones. Nuestro equipo fue capaz de aplicar mitigaciones manuales adicionales para reducir el número de errores otro 5 %.
¿Por qué no se redujeron los errores a cero?
Por desgracia, todavía había un elevado número de errores que nos impedían llegar a algunos clientes. CenturyLink/Level(3) es uno de los mayores proveedores de red del mundo. Como resultado, muchos proveedores de alojamiento solo cuentan con una única conexión a Internet a través de su red.
Usando la antigua analogía de Internet como una "superautopista", sería como tener una única salida a una ciudad. Si se bloquea la salida, no hay forma alguna de llegar a la ciudad. En algunos casos, esto se agravó porque la red de CenturyLink/Level(3) no respetó la cancelación de los enrutamientos y siguió anunciando rutas a redes como la de Cloudflare incluso después de haber sido canceladas. En el caso de los clientes cuya única conectividad a Internet era a través de CenturyLink/Level(3), o cuando CenturyLink/Level(3) siguió anunciando enrutamientos erróneos después de haber sido cancelados, no había manera de que pudiéramos llegar a sus aplicaciones y siguieron encontrándose con errores 522 hasta que CenturyLink/Level(3) resolvió su problema en torno a las 14:30 UTC.
El mismo problema sucedía en el lado de los "consumidores" de la red. Los usuarios necesitan un carril de acceso a la superautopista de Internet, que es básicamente lo que te proporciona un proveedor de servicios de red. CenturyLink es una de las principales empresas estadounidenses que ofrece estos servicios.
Fuente: https://broadbandnow.com/CenturyLink
Debido a que esta interrupción llegó a desconectar toda la red de CenturyLink/Level(3), los clientes de CenturyLink no habrían podido conectarse con Cloudflare o con cualquier otro proveedor de Internet hasta que se hubiera resuelto el problema. A nivel global, vimos una caída del 3,5 % en el tráfico durante la interrupción, debido casi todo ello a una interrupción prácticamente total del servicio de red de CenturyLink en Estados Unidos.
Entonces, ¿qué pudo haber pasado?
Aunque no sabremos qué pasó exactamente hasta que CenturyLink/Level(3) emita un informe post mortem, podemos ver indicios en los anuncios del protocolo de puerta de enlace de frontera (BGP, por sus siglas en inglés) y cómo se propagaron por Internet durante la interrupción. Este protocolo es la forma en que los enrutadores de Internet se anuncian unos a otros las IP que tienen y, por lo tanto, qué tráfico deben recibir.
Hubo un número importante de actualizaciones del BGP a partir de las 10:04 UTC. Una actualización del BGP es la señal que hace un enrutador para indicar que un enrutamiento ha cambiado o ya no está disponible. En condiciones normales, hay en Internet alrededor de 1,5 - 2 MB/s de actualizaciones del BGP cada 15 minutos. Al inicio del incidente, el número de actualizaciones de BGP se disparó a más de 26 MB/s de actualizaciones del BGP por cada período de 15 minutos y se mantuvo a nivel alto durante todo el incidente.
Fuente: http://archive.routeviews.org/bgpdata/2020.08/UPDATES/
Estas actualizaciones muestran la inestabilidad de los enrutamientos de BGP dentro de la red troncal de CenturyLink/Level(3). Lo que nos preguntamos es qué habría causado esta inestabilidad. La actualización del estado de CenturyLink/Level(3) da algunas pistas y todo apunta a una actualización de Flowspec como la causa principal.
¿Qué es Flowspec?
En la actualización de CenturyLink/Level(3) se menciona que una regla de Flowspec causó el problema. Pero, ¿qué es Flowspec? Flowspec es una extensión del BGP, que permite que las reglas del firewall se distribuyan con facilidad a través de una red, o incluso entre varias redes, mediante el uso de BGP. Flowspec es una herramienta potente. Te permite pasar las reglas eficientemente través de toda una red de forma casi instantánea. Es muy útil a la hora de tratar de responder rápidamente a un ataque, pero puede llegar a ser peligroso si se comete un error.
En los inicios de Cloudflare, solíamos utilizar Flowspec para eliminar las reglas del firewall, por ejemplo, para mitigar los grandes ataques DDoS de la capa de red. Sufrimos nuestra propia interrupción causada por Flowspec hace más de 7 años. Ya no usamos Flowspec, pero sigue siendo un protocolo común para eliminar las reglas del firewall de la red.
Solo podemos especular acerca de lo que pasó en CenturyLink/Level(3), pero es probable que emitieran un comando Flowspec para intentar bloquear un ataque u otro abuso dirigido a su red. El informe de estado indica que la regla Flowspec impidió que se anunciara el propio BGP. No podemos saber cuál era esa regla de Flowspec, pero aquí hay una en el formato de Juniper que habría bloqueado todas las comunicaciones vía BGP a través de su red.
route DISCARD-BGP {
match {
protocol tcp;
destination-port 179;
}
then discard;
}¿Por qué tantas actualizaciones?
Sin embargo, todavía es un misterio por qué las actualizaciones globales del BGP siguieron siendo elevadas durante todo el incidente. Si la regla bloqueó los BGP, entonces era esperable un aumento en los anuncios del BGP inicialmente, para volver luego a los valores normales.
Una explicación plausible es que la regla Flowspec infractora se acercara al final de una larga lista de actualizaciones del BGP. Si así fuera, lo que podría haber sucedido es que cada enrutador de la red de CenturyLink/Level(3) recibiría la regla Flowspec. Entonces, bloquearían el BGP, lo que provocaría que dejaran de recibir la regla. Se iniciarían de nuevo, abriéndose camino a través de todas las reglas del BGP hasta llegar de nuevo a la regla de Flowspec infractora. El BGP volvería a caerse, ya no se recibiría la regla de Flowspec y continuaría el bucle, una y otra vez.
El problema de esto es que, en cada ciclo, la cola de actualizaciones del BGP seguiría aumentando dentro de la red de CenturyLink/Level(3). Con esto se podría haber llegado a un punto en el que la memoria y la CPU de sus enrutadores acabara sobrecargándose, provocando aún más complicaciones para volver a conectar su red.
¿Por qué tardó tanto en repararse?
Fue una importante interrupción de Internet a nivel mundial y, sin duda, el equipo de CenturyLink/Level(3) recibió alertas de forma inmediata. Es un operador de red muy sofisticado con un centro de operaciones de red de clase mundial. Entonces, ¿por qué tardaron más de 4 horas en resolverlo?
De nuevo, solo podemos especular. Primero, es posible que la regla de Flowspec y la carga significativa que una gran cantidad de actualizaciones del BGP impuso a sus enrutadores dificultaran el inicio de sesión en sus propias interfaces. Otros proveedores de nivel 1 tomaron medidas, al parecer tras solicitarlo CenturyLink/Level(3), para desemparejar sus redes. Esto habría limitado el número de anuncios del BGP recibidos por la red de CenturyLink/Level(3) y le habría dado tiempo para ponerse al día.
En segundo lugar, es posible que la regla de Flowspec no la emitiera CenturyLink/Level(3), sino uno de sus clientes. Muchos proveedores de red permitirán el emparejamiento de Flowspec. Esta puede ser una herramienta muy potente para clientes que quieran bloquear el tráfico de ataque, pero puede dificultar bastante la detección de una regla de Flowspec infractora cuando algo sale mal.
Finalmente, no ayuda cuando estos problemas ocurren en la mañana de un domingo. Las redes con un tamaño y escala como el de CenturyLink/Level(3) son extremadamente complicadas, y se producen incidentes. Agradecemos que el equipo nos mantenga informados acerca de todo lo relacionado con esta incidencia. #hugops