
The following blog post describes a debugging adventure on Cloudflare's Mesos-based cluster. This internal cluster is primarily used to process log file information so that Cloudflare customers have analytics, and for our systems that detect and respond to attacks.
The problem encountered didn't have any effect on our customers, but did have engineers scratching their heads...
The Problem
At some point in one of our cluster we started seeing errors like this (an NXDOMAIN for an existing domain on our internal DNS):
lookup some.existing.internal.host on 10.1.0.9:53: no such hostThis seemed very weird, since the domain did indeed exist. It was one of our internal domains! Engineers had mentioned that they'd seen this behaviour, so we decided to investigate deeper. Queries triggering this error were varied and ranged from dynamic SRV records managed by mesos-dns to external domains looked up from inside the cluster.
Our first naive attempt was to run the following in a loop:
while true; do dig some.existing.internal.host > /tmp/dig.txt || break; doneRunning this for a while on one server did not reproduce the problem: all the lookups were successful. Then we took our service logs for a day and did a grep for “no such host” and similar messages. Errors were happening sporadically. There were hours between errors and no obvious pattern that could lead us to any conclusion. Our investigation discarded the possibility that the error lay in Go, which we use for lots of our services, since errors were coming from Java services too.
Into the rabbit hole
We used to run Unbound on a single IP across a few machines for our cluster DNS resolver. BGP is then responsible for announcing internal routes from the machines to the router. We decided to try to find a pattern by sending lots of requests from different machines and recording errors. Here’s what our load testing program looked like at first:
package main
import (
"flag"
"fmt"
"net"
"os"
"time"
)
func main() {
n := flag.String("n", "", "domain to look up")
p := flag.Duration("p", time.Millisecond*10, "pause between lookups")
flag.Parse()
if *n == "" {
flag.PrintDefaults()
os.Exit(1)
}
for {
_, err := net.LookupHost(*n)
if err != nil {
fmt.Println("error:", err)
}
time.Sleep(*p)
}
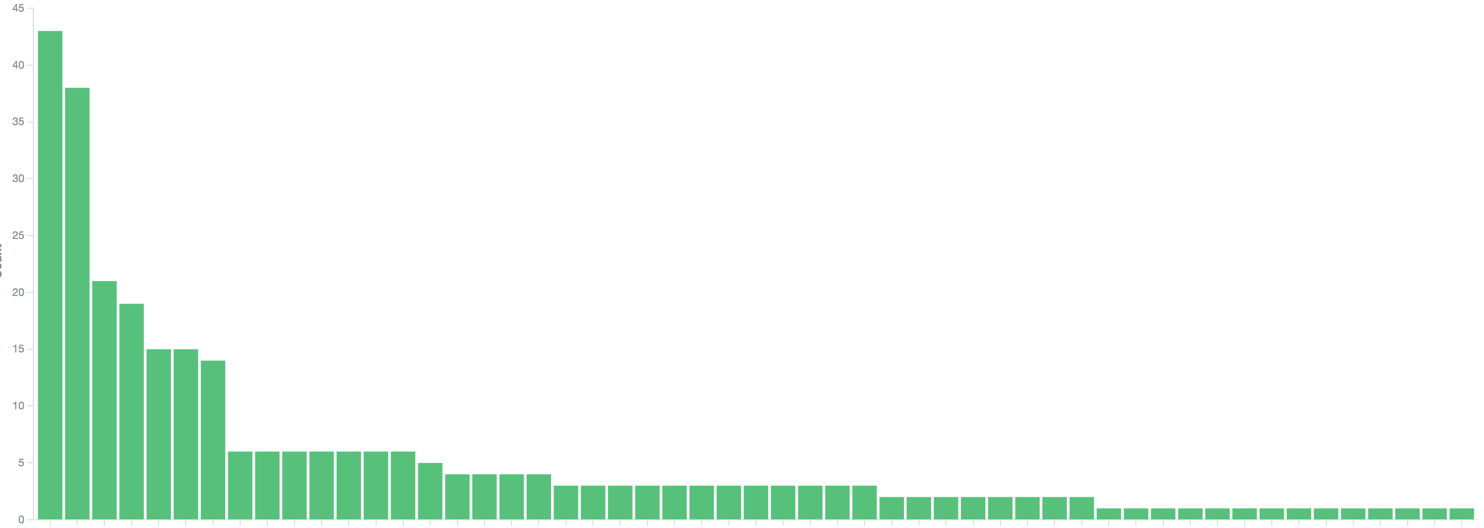
}We run net.LookupHost in a loop with small pauses and log errors; that’s it. Packaging this into a Docker container and running on Marathon was an obvious choice for us, since that is how we run other services anyway. Logs get shipped to Kafka and then to Kibana, where we can analyze them. Running this program on 65 machines doing lookups every 50ms shows the following error distribution (from high to low) across hosts:

We saw no strong correlation to racks or specific machines. Errors happened on many hosts, but not on all of them and in different time windows errors happen on different machines. Putting time on X axis and number of errors on Y axis showed the following:

To see if some particular DNS recursor had gone crazy, we stopped all load generators on regular machines and started the load generation tool on the recursors themselves. There were no errors in a few hours, which suggested that Unbound was perfectly healthy.
We started to suspect that packet loss was the issue, but why would “no such host” occur? It should only happen when an NXDOMAIN error is in a DNS response, but our theory was that replies didn’t come back at all.
The Missing
To test the hypothesis that losing packets can lead to a “no such host” error, we first tried blocking outgoing traffic on port 53:
sudo iptables -A OUTPUT -p udp --dport 53 -j DROPIn this case, dig and similar tools just time out, but don’t return “no such host”:
; <<>> DiG 9.9.5-9+deb8u3-Debian <<>> cloudflare.com
;; global options: +cmd
;; connection timed out; no servers could be reachedGo is a bit smarter and tells you more about what’s going on, but doesn't return “no such host” either:
error: lookup cloudflare.com on 10.1.0.9:53: write udp 10.1.14.20:47442->10.1.0.9:53: write: operation not permittedSince the Linux kernel tells the sender that it dropped packets, we had to point the nameserver to some black hole in the network that does nothing with packets to mimic packet loss. Still no luck:
error: lookup cloudflare.com on 10.1.2.9:53: read udp 10.1.14.20:39046->10.1.2.9:53: i/o timeoutTo continue blaming the network we had to support our assumptions somehow, so we added timing information to our lookups:
s := time.Now()
_, err := net.LookupHost(*n)
e := time.Now().Sub(s).Seconds()
if err != nil {
log.Printf("error after %.4fs: %s", e, err)
} else if e > 1 {
log.Printf("success after %.4fs", e)
}To be honest, we started by timing errors and added success timing later. Errors were happening after 10s, comparatively many successful responses were coming after 5s. It does look like packet loss, but still does not tell us why “no such host” happens.
Since now we were in a place when we knew which hosts were more likely to be affected by this, we ran the following two commands in parallel in two screen sessions:
while true; do dig cloudflare.com > /tmp/dig.log || break; done; date; sudo killall tcpdump
sudo tcpdump -w /state/wtf.cap port 53The point was to get a network dump with failed resolves. In there, we saw the following queries:
00.00s A cloudflare.com
05.00s A cloudflare.com
10.00s A cloudflare.com.in.our.internal.domainTwo queries time out without any answer, but the third one gets lucky and succeeds. Naturally, we don’t have cloudflare.com in our internal domain, so Unbound rightfully gives NXDOMAIN in reply, 10s after the lookup was initiated.
Bingo
Let’s look at /etc/resolv.conf to understand more:
nameserver 10.1.0.9
search in.our.internal.domainUsing the search keyword allows us to use short hostnames instead of FQDN, making myhost transparently equivalent to myhost.in.our.internal.domain.
For the DNS resolver it means the following: for any DNS query ask the nameserver 10.1.0.9, if this fails, append .in.our.internal.domain to the query and retry. It doesn’t matter what failure occurs for the original DNS query. Usually it is NXDOMAIN, but in our case it’s a read timeout due to packet loss.
The following events seemed to have to occur for a “no such host” error to appear:
The original DNS request has to be lost
The retry that is sent after 5 seconds has to be lost
The subsequent query for the internal domain (caused by the
searchoption) has to succeed and return NXDOMAIN
On the other hand, to observe a timed out DNS query instead of NXDOMAIN, you have to lose four packets sent 5 seconds one after another (2 for the original query and 2 for the internal version of your domain), which is a much smaller probability. In fact, we only saw an NXDOMAIN after 15s once and never saw an error after 20s.
To validate that assumption, we built a proof-of-concept DNS server that drops all requests for cloudflare.com, but sends an NXDOMAIN for existing domains:
package main
import (
"github.com/miekg/dns"
"log"
)
func main() {
server := &dns.Server{Addr: ":53", Net: "udp"}
dns.HandleFunc(".", func(w dns.ResponseWriter, r *dns.Msg) {
m := &dns.Msg{}
m.SetReply(r)
for _, q := range r.Question {
log.Printf("checking %s", q.Name)
if q.Name == "cloudflare.com." {
log.Printf("ignoring %s", q.Name)
// just ignore
return
}
}
w.WriteMsg(m)
})
log.Printf("listening..")
if err := server.ListenAndServe(); err != nil {
log.Fatalf("error listening: %s", err)
}
}Finally, we found what was going on and had a way of reliably replicating that behaviour.
Solutions
Let's think about how we can improve our client to better handle these transient network issues, making it more resilient. The man page for resolv.conf tells you that you have two knobs: the timeout and retries options. The default values are 5 and 2 respectively.
Unless you keep your DNS server very busy, it is very unlikely that it would take it more than 1 second to reply. In fact, if you happen to have a network device on the Moon, you can expect it to reply in 3 seconds. If your nameserver lives in the next rack and is reachable over a high-speed network, you can safely assume that if there is no reply after 1 second, your DNS server did not get your query. If you want to have less weird “no such domain” errors that make you scratch your head, you might as well increase retries. The more times you retry with transient packet loss, the less chance of failure. The more often you retry, the higher chances to finish faster.
Imagine that you have truly random 1% packet loss.
2 retries, 5s timeout: max 10s wait before error, 0.001% chance of failure
5 retries, 1s timeout: max 5s wait before error, 0.000001% chance of failure
In real life, the distribution would be different due to the fact that packet loss is not random, but you can expect to wait much less for DNS to reply with this type of change.
As you know many system libraries that provide DNS resolution like glibc, nscd, systemd-resolved are not hardened to handle being on the internet or in a environment with packet losses. We have faced the challenge of creating a reliable and fast DNS resolution environment a number of times as we have grown, only to later discover that the solution is not perfect.
Over to you
Given what you have read in this article about packet loss and split-DNS/private-namespace, how would you design a fast and reliable resolution setup? What software would you use and why? What tuning changes from standard configuration would you use?
We'd love to hear your ideas in the comments. And, if you like working on problems like send us your resume. We are hiring.