

At Cloudflare, engineers spend a great deal of time refactoring or rewriting existing functionality. When your company doubles the amount of traffic it handles every year, what was once an elegant solution to a problem can quickly become outdated as the engineering constraints change. Not only that, but when you're averaging 40 million requests a second, issues that might affect 0.001% of requests flowing through our network are big incidents which may impact millions of users, and one-in-a-trillion events happen several times a day.
Recently, we've been working on a replacement to one of our oldest and least-well-known components called cf-html, which lives inside the core reverse web proxy of Cloudflare known as FL (Front Line). Cf-html is the framework in charge of parsing and rewriting HTML as it streams back through from the website origin to the website visitor. Since the early days of Cloudflare, we’ve offered features which will rewrite the response body of web requests for you on the fly. The first ever feature we wrote in this way was to replace email addresses with chunks of JavaScript, which would then load the email address when viewed in a web browser. Since bots are often unable to evaluate JavaScript, this helps to prevent scraping of email addresses from websites. You can see this in action if you view the source of this page and look for this email address: [email protected].
FL is where most of the application infrastructure logic for Cloudflare runs, and largely consists of code written in the Lua scripting language, which runs on top of NGINX as part of OpenResty. In order to interface with NGINX directly, some parts (like cf-html) are written in lower-level languages like C and C++. In the past, there were many such OpenResty services at Cloudflare, but these days FL is one of the few left, as we move other components to Workers or Rust-based proxies. The platform that once was the best possible blend of developer ease and speed has more than started to show its age for us.
When discussing what happens to an HTTP request passing through our network and in particular FL, nearly all the attention is given to what happens up until the request reaches the customer's origin. That’s understandable as this is where most of the business logic happens: firewall rules, Workers, and routing decisions all happen on the request. But it's not the end of the story. From an engineering perspective, much of the more interesting work happens on the response, as we stream the HTML response back from the origin to the site visitor.
The logic to handle this is contained in a static NGINX module, and runs in the Response Body Filters phase in NGINX, as chunks of the HTTP response body are streamed through. Over time, more features were added, and the system became known as cf-html. cf-html uses a streaming HTML parser to match on specific HTML tags and content, called Lazy HTML or lhtml, with much of the logic for both it and the cf-html features written using the Ragel state machine engine.
Memory safety
All the cf-html logic was written in C, and therefore was susceptible to memory corruption issues that plague many large C codebases. In 2017 this led to a security bug as the team was trying to replace part of cf-html. FL was reading arbitrary data from memory and appending it to response bodies. This could potentially include data from other requests passing through FL at the same time. This security event became known widely as Cloudbleed.
Since this episode, Cloudflare implemented a number of policies and safeguards to ensure something like that never happened again. While work has been carried out on cf-html over the years, there have been few new features implemented on the framework, and we’re now hyper-sensitive to crashes happening in FL (and, indeed, any other process running on our network), especially in parts that can reflect data back with a response.
Fast-forward to 2022 into 2023, and the FL Platform team have been getting more and more requests for a system they can easily use to look at and rewrite response body data. At the same time, another team has been working on a new response body parsing and rewriting framework for Workers called lol-html or Low Output Latency HTML. Not only is lol-html faster and more efficient than Lazy HTML, but it’s also currently in full production use as part of the Worker interface, and written in Rust, which is much safer than C in terms of its handling of memory. It’s ideal, therefore, as a replacement for the ancient and creaking HTML parser we’ve been using in FL up until now.
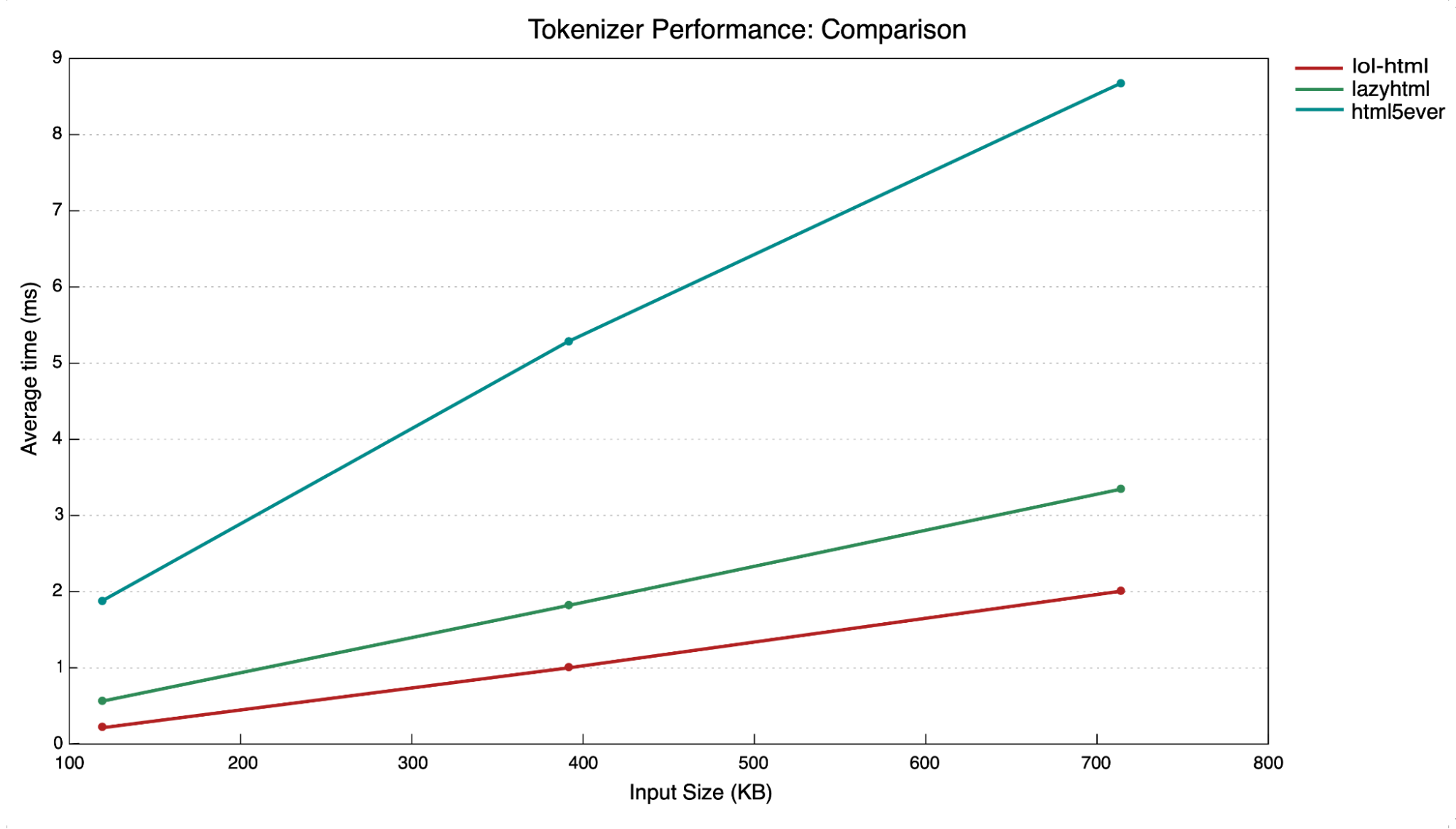
So we started working on a new framework, written in Rust, that would incorporate lol-html and allow other teams to write response body parsing features without the threat of causing massive security issues. The new system is called ROFL or Response Overseer for FL, and it’s a brand-new NGINX module written completely in Rust. As of now, ROFL is running in production on millions of responses a second, with comparable performance to cf-html. In building ROFL, we’ve been able to deprecate one of the scariest bits of code in Cloudflare’s entire codebase, while providing teams at Cloudflare with a robust system they can use to write features which need to parse and rewrite response body data.
Writing an NGINX module in Rust
While writing the new module, we learned a lot about how NGINX works, and how we can get it to talk to Rust. NGINX doesn’t provide much documentation on writing modules written in languages other than C, and so there was some work which needed to be done to figure out how to write an NGINX module in our language of choice. When starting out, we made heavy use of parts of the code from the nginx-rs project, particularly around the handling of buffers and memory pools. While writing a full NGINX module in Rust is a long process and beyond the scope of this blog post, there are a few key bits that make the whole thing possible, and that are worth talking about.
The first one of these is generating the Rust bindings so that NGINX can communicate with it. To do that, we used Rust’s library Bindgen to build the FFI bindings for us, based on the symbol definitions in NGINX’s header files. To add this to an existing Rust project, the first thing is to pull down a copy of NGINX and configure it. Ideally this would be done in a simple script or Makefile, but when done by hand it would look something like this:
$ git clone --depth=1 https://github.com/nginx/nginx.git
$ cd nginx
$ ./auto/configure --without-http_rewrite_module --without-http_gzip_module
With NGINX in the right state, we need to create a build.rs file in our Rust project to auto-generate the bindings at build-time of the module. We’ll now add the necessary arguments to the build, and use Bindgen to generate us the bindings.rs file. For the arguments, we just need to include all the directories that may contain header files for clang to do its thing. We can then feed them into Bindgen, along with some allowlist arguments, so it knows for what things it should generate the bindings, and which things it can ignore. Adding a little boilerplate code to the top, the whole file should look something like this:
use std::env;
use std::path::PathBuf;
fn main() {
println!("cargo:rerun-if-changed=build.rs");
let clang_args = [
"-Inginx/objs/",
"-Inginx/src/core/",
"-Inginx/src/event/",
"-Inginx/src/event/modules/",
"-Inginx/src/os/unix/",
"-Inginx/src/http/",
"-Inginx/src/http/modules/"
];
let bindings = bindgen::Builder::default()
.header("wrapper.h")
.layout_tests(false)
.allowlist_type("ngx_.*")
.allowlist_function("ngx_.*")
.allowlist_var("NGX_.*|ngx_.*|nginx_.*")
.parse_callbacks(Box::new(bindgen::CargoCallbacks))
.clang_args(clang_args)
.generate()
.expect("Unable to generate bindings");
let out_path = PathBuf::from(env::var("OUT_DIR").unwrap());
bindings.write_to_file(out_path.join("bindings.rs"))
.expect("Unable to write bindings.");
}
Hopefully this is all fairly self-explanatory. Bindgen traverses the NGINX source and generates equivalent constructs in Rust in a file called bindings.rs, which we can import into our project. There’s just one more thing to add- Bindgen has trouble with a couple of symbols in NGINX, which we’ll need to fix in a file called wrapper.h. It should have the following contents:
#include <ngx_http.h>
const char* NGX_RS_MODULE_SIGNATURE = NGX_MODULE_SIGNATURE;
const size_t NGX_RS_HTTP_LOC_CONF_OFFSET = NGX_HTTP_LOC_CONF_OFFSET;
With this in place and Bindgen set in the [build-dependencies] section of the Cargo.toml file, we should be ready to build.
$ cargo build
Compiling rust-nginx-module v0.1.0 (/Users/sam/cf-repos/rust-nginx-module)
Finished dev [unoptimized + debuginfo] target(s) in 4.70s
With any luck, we should see a file called bindings.rs in the target/debug/build directory, which contains Rust definitions of all the NGINX symbols.
$ find target -name 'bindings.rs'
target/debug/build/rust-nginx-module-c5504dc14560ecc1/out/bindings.rs
$ head target/debug/build/rust-nginx-module-c5504dc14560ecc1/out/bindings.rs
/* automatically generated by rust-bindgen 0.61.0 */
[...]
To be able to use them in the project, we can include them in a new file under the src directory which we’ll call bindings.rs.
$ cat > src/bindings.rs
include!(concat!(env!("OUT_DIR"), "/bindings.rs"));
With that set, we just need to add the usual imports to the top of the lib.rs file, and we can access NGINX constructs from Rust. Not only does this make bugs in the interface between NGINX and our Rust module much less likely than if these values were hand-coded, but it’s also a fantastic reference we can use to check the structure of things in NGINX when building modules in Rust, and it takes a lot of the leg-work out of setting everything up. It’s really a testament to the quality of a lot of Rust libraries such as Bindgen that something like this can be done with so little effort, in a robust way.
Once the Rust library has been built, the next step is to hook it into NGINX. Most NGINX modules are compiled statically. That is, the module is compiled as part of the compilation of NGINX as a whole. However, since NGINX 1.9.11, it has supported dynamic modules, which are compiled separately and then loaded using the load_module directive in the nginx.conf file. This is what we needed to use to build ROFL, so that the library could be compiled separately and loaded-in at the time NGINX starts up. Finding the right format so that the necessary symbols could be found from the documentation was tricky, though, and although it is possible to use a separate config file to set some of this metadata, it’s better if we can load it as part of the module, to keep things neat. Luckily, it doesn’t take much spelunking through the NGINX codebase to find where dlopen is called.
So after that it’s just a case of making sure the relevant symbols exist.
use std::os::raw::c_char;
use std::ptr;
#[no_mangle]
pub static mut ngx_modules: [*const ngx_module_t; 2] = [
unsafe { rust_nginx_module as *const ngx_module_t },
ptr::null()
];
#[no_mangle]
pub static mut ngx_module_type: [*const c_char; 2] = [
"HTTP_FILTER\0".as_ptr() as *const c_char,
ptr::null()
];
#[no_mangle]
pub static mut ngx_module_names: [*const c_char; 2] = [
"rust_nginx_module\0".as_ptr() as *const c_char,
ptr::null()
];
When writing an NGINX module, it’s crucial to get its order relative to the other modules correct. Dynamic modules get loaded as NGINX starts, which means they are (perhaps counterintuitively) the first to run on a response. Ensuring your module runs after gzip decompression by specifying its order relative to the gunzip module is essential, otherwise you can spend lots of time staring at streams of unprintable characters, wondering why you aren’t seeing the response you expected. Not fun. Fortunately this is also something that can be solved by looking at the NGINX source, and making sure the relevant entities exist in your module. Here’s an example of what you might set-
pub static mut ngx_module_order: [*const c_char; 3] = [
"rust_nginx_module\0".as_ptr() as *const c_char,
"ngx_http_headers_more_filter_module\0".as_ptr() as *const c_char,
ptr::null()
];
We’re essentially saying we want our module rust_nginx_module to run just before the ngx_http_headers_more_filter_module module, which should allow it to run in the place we expect.
One of the quirks of NGINX and OpenResty is how it is really hostile to making calls to external services at the point that you’re dealing with the HTTP response. It’s something that isn’t provided as part of the OpenResty Lua framework, even though it would make working with the response phase of a request much easier. While we could do this anyway, that would mean having to fork NGINX and OpenResty, which would bring its own challenges. As a result, we’ve spent a lot of time over the years thinking about ways to pass state from the time when NGINX’s dealing with an HTTP request, over to the time when it’s streaming through the response, and much of our logic is built around this style of work.
For ROFL, that means in order to determine if we need to apply a certain feature for a response, we need to figure that out on the request, then pass that information over to the response so that we know which features to activate. To do that, we need to use one of the utilities that NGINX provides you with. With the help of the bindings.rs file generated earlier, we can take a look at the definition of the ngx_http_request_s struct, which contains all the state associated with a given request:
#[repr(C)]
#[derive(Debug, Copy, Clone)]
pub struct ngx_http_request_s {
pub signature: u32,
pub connection: *mut ngx_connection_t,
pub ctx: *mut *mut ::std::os::raw::c_void,
pub main_conf: *mut *mut ::std::os::raw::c_void,
pub srv_conf: *mut *mut ::std::os::raw::c_void,
pub loc_conf: *mut *mut ::std::os::raw::c_void,
pub read_event_handler: ngx_http_event_handler_pt,
pub write_event_handler: ngx_http_event_handler_pt,
pub cache: *mut ngx_http_cache_t,
pub upstream: *mut ngx_http_upstream_t,
pub upstream_states: *mut ngx_array_t,
pub pool: *mut ngx_pool_t,
pub header_in: *mut ngx_buf_t,
pub headers_in: ngx_http_headers_in_t,
pub headers_out: ngx_http_headers_out_t,
pub request_body: *mut ngx_http_request_body_t,
[...]
}
As we can see, there’s a member called ctx. As the NGINX Development Guide mentions, it’s a place where you’re able to store any value associated with a request, which should live for as long as the request does. In OpenResty this is used heavily for the storing of state to do with a request over its lifetime in a Lua context. We can do the same thing for our module, so that settings initialised during the request phase are there when our HTML parsing and rewriting is run in the response phase. Here’s an example function which can be used to get the request ctx:
pub fn get_ctx(request: &ngx_http_request_t) -> Option<&mut Ctx> {
unsafe {
match *request.ctx.add(ngx_http_rofl_module.ctx_index) {
p if p.is_null() => None,
p => Some(&mut *(p as *mut Ctx)),
}
}
}
Notice that ctx is at the offset of the ctx_index member of ngx_http_rofl_module - this is the structure of type ngx_module_t that’s part of the module definition needed to make an NGINX module. Once we have this, we can point it to a structure containing any setting we want. For example, here’s the actual function we use to enable the Email Obfuscation feature from Lua, via FFI to the Rust module using LuaJIT’s FFI tools:
#[no_mangle]
pub extern "C" fn rofl_module_email_obfuscation_new(
request: &mut ngx_http_request_t,
dry_run: bool,
decode_script_url: *const u8,
decode_script_url_len: usize,
) {
let ctx = context::get_or_init_ctx(request);
let decode_script_url = unsafe {
std::str::from_utf8(std::slice::from_raw_parts(decode_script_url, decode_script_url_len))
.expect("invalid utf-8 string for decode script")
};
ctx.register_module(EmailObfuscation::new(decode_script_url.to_owned()), dry_run);
}
The function is called get_or_init_ctx here- it performs the same job as get_ctx, but also initialises the structure if it doesn’t exist yet. Once we’ve set whatever data we need in ctx during the request, we can then check what features need to be run in the response, without having to make any calls to external databases, which might slow us down.
One of the nice things about storing state on ctx in this way, and working with NGINX in general, is that it relies heavily on memory pools to store request content. This largely removes any need for the programmer to have to think about freeing memory after use- the pool is automatically allocated at the start of a request, and is automatically freed when the request is done. All that’s needed is to allocate the memory using NGINX’s built-in functions for allocating memory to the pool and then registering a callback that will be called to free everything. In Rust, that would look something like the following:
pub struct Pool<'a>(&'a mut ngx_pool_t);
impl<'a> Pool<'a> {
/// Register a cleanup handler that will get called at the end of the request.
fn add_cleanup<T>(&mut self, value: *mut T) -> Result<(), ()> {
unsafe {
let cln = ngx_pool_cleanup_add(self.0, 0);
if cln.is_null() {
return Err(());
}
(*cln).handler = Some(cleanup_handler::<T>);
(*cln).data = value as *mut c_void;
Ok(())
}
}
/// Allocate memory for a given value.
pub fn alloc<T>(&mut self, value: T) -> Option<&'a mut T> {
unsafe {
let p = ngx_palloc(self.0, mem::size_of::<T>()) as *mut _ as *mut T;
ptr::write(p, value);
if let Err(_) = self.add_cleanup(p) {
ptr::drop_in_place(p);
return None;
};
Some(&mut *p)
}
}
}
unsafe extern "C" fn cleanup_handler<T>(data: *mut c_void) {
ptr::drop_in_place(data as *mut T);
}
This should allow us to allocate memory for whatever we want, safe in the knowledge that NGINX will handle it for us.
It is regrettable that we have to write a lot of unsafe blocks when dealing with NGINX’s interface in Rust. Although we’ve done a lot of work to minimise them where possible, unfortunately this is often the case with writing Rust code which has to manipulate C constructs through FFI. We have plans to do more work on this in the future, and remove as many lines as possible from unsafe.
Challenges encountered
The NGINX module system allows for a massive amount of flexibility in terms of the way the module itself works, which makes it very accommodating to specific use-cases, but that flexibility can also lead to problems. One that we ran into had to do with the way the response data is handled between Rust and FL. In NGINX, response bodies are chunked, and these chunks are then linked together into a list. Additionally, there may be more than one of these linked lists per response, if the response is large.
Efficiently handling these chunks means processing them and passing them on as quickly as possible. When writing a Rust module for manipulating responses, it’s tempting to implement a Rust-based view into these linked lists. However, if you do that, you must be sure to update both the Rust-based view and the underlying NGINX data structures when mutating them, otherwise this can lead to serious bugs where Rust becomes out of sync with NGINX. Here’s a small function from an early version of ROFL that caused headaches:
fn handle_chunk(&mut self, chunk: &[u8]) {
let mut free_chain = self.chains.free.borrow_mut();
let mut out_chain = self.chains.out.borrow_mut();
let mut data = chunk;
self.metrics.borrow_mut().bytes_out += data.len() as u64;
while !data.is_empty() {
let free_link = self
.pool
.get_free_chain_link(free_chain.head, self.tag, &mut self.metrics.borrow_mut())
.expect("Could not get a free chain link.");
let mut link_buf = unsafe { TemporaryBuffer::from_ngx_buf(&mut *(*free_link).buf) };
data = link_buf.write_data(data).unwrap_or(b"");
out_chain.append(free_link);
}
}
What this code was supposed to do is take the output of lol-html’s HTMLRewriter, and write it to the output chain of buffers. Importantly, the output can be larger than a single buffer, so you need to take new buffers off the chain in a loop until you’ve written all the output to buffers. Within this logic, NGINX is supposed to take care of popping the buffer off the free chain and appending the new chunk to the output chain, which it does. However, if you’re only thinking in terms of the way NGINX handles its view of the linked list, you may not notice that Rust never changes which buffer its free_chain.head points to, causing the logic to loop forever and the NGINX worker process to lock-up completely. This sort of issue can take a long time to track down, especially since we couldn’t reproduce it on our personal machines until we understood it was related to the response body size.
Getting a coredump to perform some analysis with gdb was also hard because once we noticed it happening, it was already too late and the process memory had grown to the point the server was in danger of falling over, and the memory consumed was too large to be written to disk. Fortunately, this code never made it to production. As ever, while Rust’s compiler can help you to catch a lot of common mistakes, it can’t help as much if the data is being shared via FFI from another environment, even without much direct use of unsafe, so extra care must be taken in these cases, especially when NGINX allows the kind of flexibility that might lead to a whole machine being taken out of service.
Another major challenge we faced had to do with backpressure from incoming response body chunks. In essence, if ROFL increased the size of the response due to having to inject some large amount of code into the stream (such as replacing an email address with a large chunk of JavaScript), NGINX can feed the output from ROFL to the other downstream modules faster than they could push it along, potentially leading to data being dropped and HTTP response bodies being truncated if the EAGAIN error from the next module is left unhandled. This was another case where the issue was really hard to test, because most of the time the response would be flushed fast enough for backpressure never to be a problem. To handle this, we had to create a special chain to store these chunks called saved_in, which required a special method for appending to it.
#[derive(Debug)]
pub struct Chains {
/// This saves buffers from the `in` chain that were not processed for any reason (most likely
/// backpressure for the next nginx module).
saved_in: RefCell<Chain>,
pub free: RefCell<Chain>,
pub busy: RefCell<Chain>,
pub out: RefCell<Chain>,
[...]
}
Effectively we’re ‘queueing’ the data for a short period of time so that we don’t overwhelm the other modules by feeding them data faster than they can handle it. The NGINX Developer Guide has a lot of great information, but many of its examples are trivial to the point where issues like this don’t come up. Things such as this are the result of working in a complex NGINX-based environment, and need to be discovered independently.
A future without NGINX
The obvious question a lot of people might ask is: why are we still using NGINX? As already mentioned, Cloudflare is well on its way to replacing components that either used to run NGINX/OpenResty proxies, or would have done without heavy investment in home-grown platforms. That said, some components are easier to replace than others and FL, being where most of the logic for Cloudflare’s application services runs, is definitely on the more challenging end of the spectrum.
Another motivating reason for doing this work is that whichever platform we eventually migrate to, we’ll need to run the features that make up cf-html, and in order to do that we’ll want to have a system that is less heavily integrated and dependent on NGINX. ROFL has been specifically designed with the intention of running it in multiple places, so it will be easy to move it to another Rust-based web proxy (or indeed our Workers platform) without too much trouble. That said it’s hard to imagine we’d be in the same place without a language like Rust, which offers speed at the same time as a high degree of safety, not to mention high-quality libraries like Bindgen and Serde. More broadly, the FL team are working to migrate other aspects of the platform over to Rust, and while cf-html and the features of which make it up are a key part of our infrastructure that needed work, there are many others.
Safety in programming languages is often seen as beneficial in terms of preventing bugs, but as a company we’ve found that it also allows you to do things which would be considered very hard, or otherwise impossible to do safely. Whether it be providing a Wireshark-like filter language for writing firewall rules, allowing millions of users to write arbitrary JavaScript code and run it directly on our platform or rewriting HTML responses on the fly, having strict boundaries in place allows us to provide services we wouldn’t be able to otherwise, all while safe in the knowledge that the kind of memory-safety issues that used to plague the industry are increasingly a thing of the past.
If you enjoy rewriting code in Rust, solving challenging application infrastructure problems and want to help maintain the busiest web server in the world, we’re hiring!