
Conheço os filtros de Bloom (em homenagem a Burton Bloom) desde a universidade, mas não tive a oportunidade de usá-los intensivamente. No mês passado isso mudou. Fiquei fascinado com a promessa dessa estrutura de dados, mas logo percebi que ela tinha algumas desvantagens. Este post do blog é a história do meu breve caso de amor com os filtros de Bloom.
Ao fazer pesquisas sobre falsificação de IP, precisei examinar se os endereços de IP de origem extraídos dos pacotes que chegavam aos nossos servidores eram legítimos, dependendo da localização geográfica dos nossos data centers. Por exemplo, IPs de origem pertencentes a um provedor de internet italiano legítimo não devem chegar a um datacenter brasileiro. Este problema pode parecer simples, mas no cenário em constante evolução da internet isto está longe de ser fácil. Basta dizer que acabei com muitos arquivos de texto grandes com dados como estes:

Isso significa que o IP 192.0.2.1 foi registrado alcançando o data center número 107 da Cloudflare com uma solicitação legítima. Esses dados vieram de muitas origens, incluindo nossas sondagens ativas e passivas, logs de determinados domínios que possuímos (como cloudflare.com), fontes públicas (como tabela BGP), etc. A mesma linha, normalmente, era repetida em vários arquivos.
Acabei com uma coleção gigantesca de dados desse tipo. Em algum momento contei 1 bilhão de linhas em todas as origens colhidas. Normalmente escrevo scripts bash para pré-processar as entradas, mas nessa escala essa abordagem não estava funcionando. Por exemplo, remover duplicatas deste pequeno arquivo de escassos 600 MiB e 40 milhões de linhas levou... cerca de uma eternidade:

Basta dizer que a remoção de linhas duplicadas usando os comandos bash habituais como "sort" em várias configurações (consulte "--parallel", "-buffer-size" e "--unique") não era ideal para um conjunto de dados tão grande.
Filtros de Bloom para a salvação
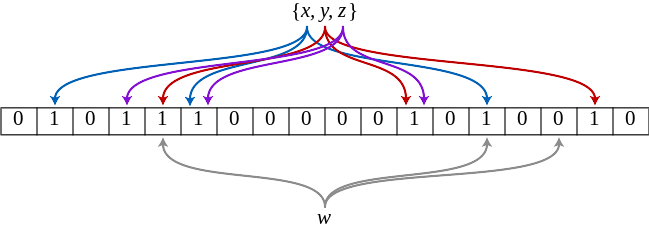
Então tive uma ideia brilhante, não é necessário ordenar as linhas. Só preciso remover as linhas duplicadas. Usar algum tipo de estrutura de dados de "conjunto" deve ser muito mais rápido. Além disso, tenho uma noção aproximada da cardinalidade do arquivo de entrada (número de linhas únicas), e posso aceitar a perda de alguns pontos de dados. Usar uma estrutura de dados probabilística é aceitável.
Os filtros de Bloom são exatamente o que preciso.
Você deve ler a Wikipedia sobre os filtros de Bloom, mas aqui está como vejo essa estrutura de dados.
Como você implementaria um "conjunto"? Dada uma função hash perfeita e memória infinita, poderíamos simplesmente criar uma matriz de bits infinita e definir um número de bit "hash(item)" para cada item que encontrarmos. Isso nos daria uma estrutura de dados de "conjunto" perfeita. Certo? Simples. Infelizmente, as funções hash têm colisões e não existe memória infinita, então temos que nos manter em nossa realidade. Mas podemos calcular e gerenciar a probabilidade de colisões. Por exemplo, imagine que temos uma boa função hash e 128 GiB de memória. Podemos calcular a probabilidade de colisão do segundo item adicionado à matriz de bits seria 1 em 1099511627776. A probabilidade de colisão ao adicionar mais itens piora à medida que preenchemos a matriz de bits.
Além disso, poderíamos usar mais de uma função hash e acabar com uma matriz de bits mais densa. Isso é exatamente o que os filtros de Bloom otimizam. Um filtro de Bloom é um conjunto de operações matemáticas sobre as quatro variáveis:
- "n" - O número de elementos de entrada (cardinalidade)
- "m" - Memória usada pela matriz de bits
- 'k' - Número de funções hash consideradas para cada entrada
- 'p' - Probabilidade de uma correspondência falso positiva
Dada a cardinalidade de entrada "n" e a probabilidade de falso positivo "p" desejada , os cálculos matemáticos do filtro de Bloom retornam a memória "m" necessária e o número "k" de funções hash necessárias.
Confira esta excelente visualização de Thomas Hurst mostrando como os parâmetros influenciam uns aos outros:
mmuniq-bloom
Guiado por esta intuição, embarquei em uma jornada para adicionar uma nova ferramenta à minha caixa de ferramentas, o "mmuniq-bloom", uma ferramenta probabilística que, dada a entrada no STDIN, retorna apenas linhas únicas no STDOUT, esperançosamente muito mais rápido que a combinação "sort" + "uniq".
Aqui está:
Para simplicidade e velocidade, projetei o "mmuniq-bloom" com algumas suposições. Primeiro, a menos que seja instruído de outra forma, ele usa 8 funções hash k=8. Este parece ser um número próximo do ideal para os tamanhos de dados com os quais estou trabalhando, e a função hash pode gerar rapidamente 8 hashes decentes. Em seguida, alinhamos "m", o número de bits na matriz de bits, para ser uma potência de dois. Isso é para evitar a cara operação módulo %, que se traduz em uma instrução assembly "div" lenta. Com tamanhos de potência de dois, podemos simplesmente usar a operação AND bit a bit. (Para uma leitura interessante, veja how compilers can optimize some divisions by using multiplication by a magic constant.)
Agora podemos executá-lo no mesmo arquivo de dados que usamos antes:

Ah, isso é muito melhor! 12 segundos são muito mais administráveis do que os 2 minutos de antes. Mas espere... O programa está usando uma estrutura de dados otimizada, espaço de memória relativamente limitado, análise de linha otimizada e um bom buffer de saída... 12 segundos ainda é uma eternidade comparado à ferramenta "wc -l":

O que está acontecendo? Entendo que contar linhas por "wc" é mais fácil do que descobrir linhas únicas, mas vale mesmo a pena a diferença de 26 vezes? Para onde vai toda a CPU em "mmuniq-bloom"?
Deve ser minha função de hash. O "wc" não precisa gastar toda essa CPU realizando todos esses cálculos estranhos para cada uma das 40 milhões de linhas de entrada. Estou usando uma função de hash bastante complexa, "siphash24", então certamente consome a CPU, certo? Vamos verificar executando o código que calcula a função hash, mas sem realizar operações do filtro de Bloom:

Isto é estranho. Contar a função hash realmente custa cerca de 2s, mas o programa demorou 12s na execução anterior. O filtro de Bloom sozinho leva 10 segundos? Como isso é possível? É uma estrutura de dados tão simples...
Uma arma secreta - um criador de perfil
Era hora de usar uma ferramenta adequada para a tarefa. Vamos iniciar um criador de perfil e ver para onde vai a CPU. Primeiro, vamos disparar um "strace" para confirmar que não estamos executando nenhum syscall inesperado:
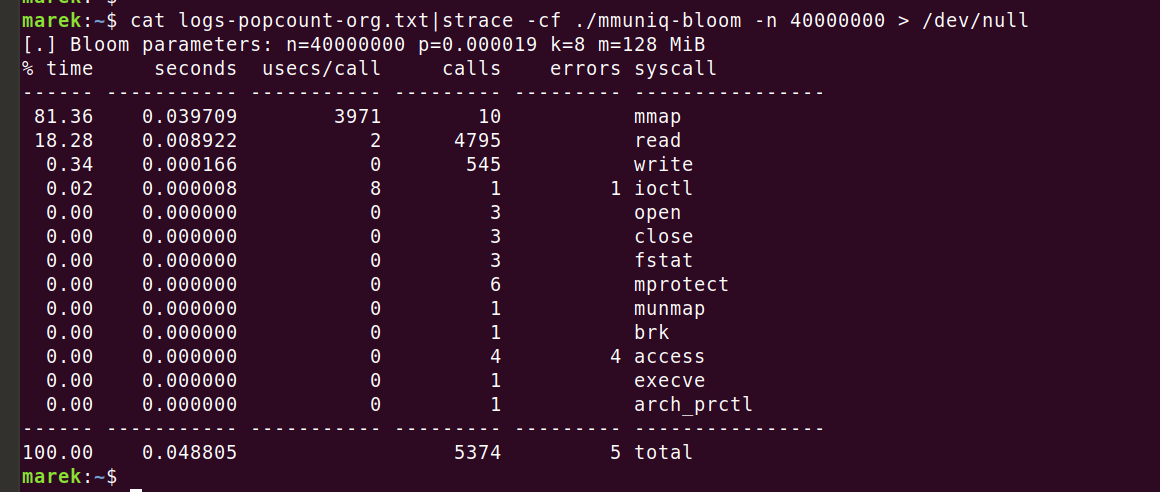
Tudo parece bem. As dez chamadas para "mmap", cada uma levando 4 ms (3971 us), são intrigantes, mas tudo bem. Pré-preenchemos a memória antecipadamente com "MAP_POPULATE" para salvar falhas de página posteriormente.
Qual é a próxima etapa? Claro que é o "perf" do Linux.

Então podemos ver os resultados:
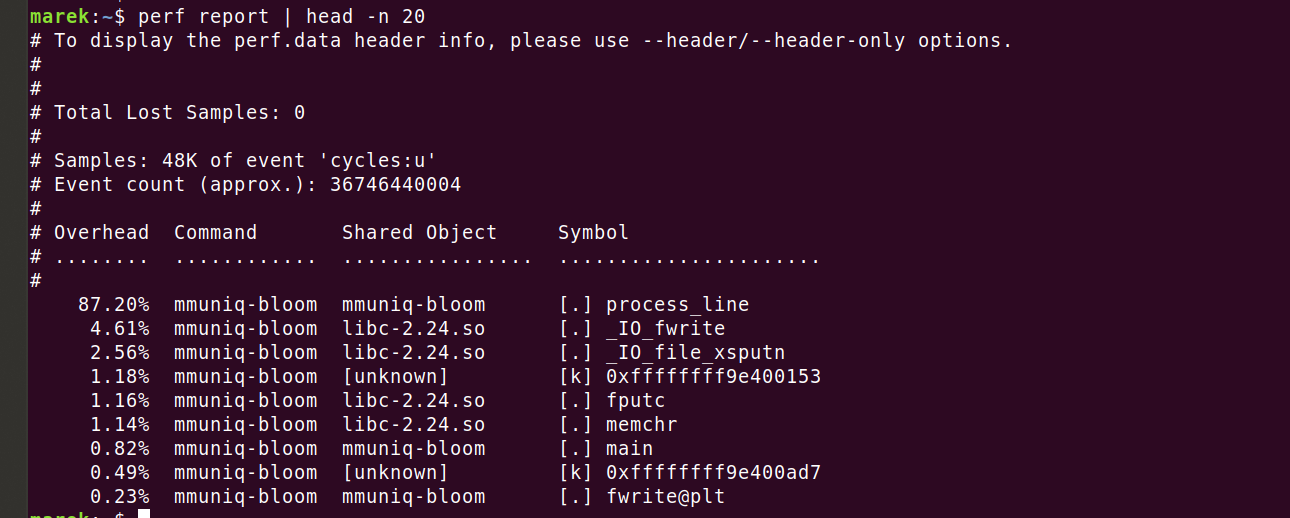
Certo, então realmente consumimos 87,2% dos ciclos em nosso código ativo. Vamos ver onde exatamente. Fazer "perf annotate process_line --source" mostra rapidamente algo que eu não esperava.
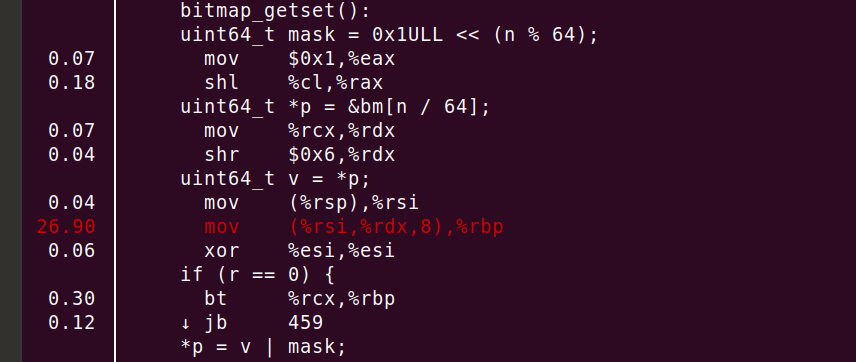
Você pode ver 26,90% da CPU consumida no "mov", mas não é tudo. O compilador incorporou corretamente a função e desenrolou o loop 8 vezes. Resumindo, a linha "mov" ou "uint64_t v = *p" soma a grande maioria dos ciclos.
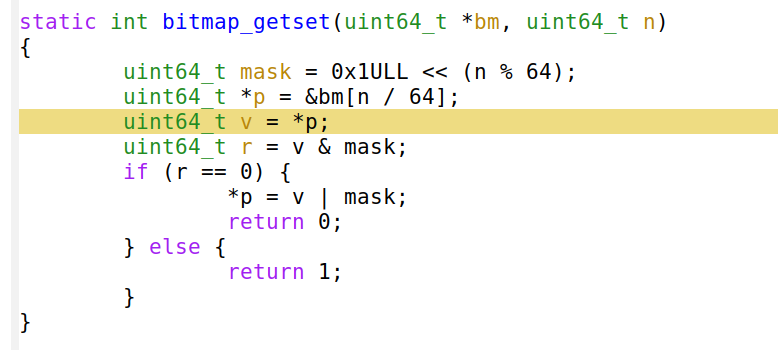
Claramente "perf" deve estar errado, como pode uma linha tão simples custar tanto? Podemos repetir o benchmark com qualquer outro criador de perfil e isso nos mostrará o mesmo problema. Por exemplo, gosto de usar "google-perftools" com kcachegrind, pois eles emitem gráficos atraentes:
O resultado renderizado fica assim:
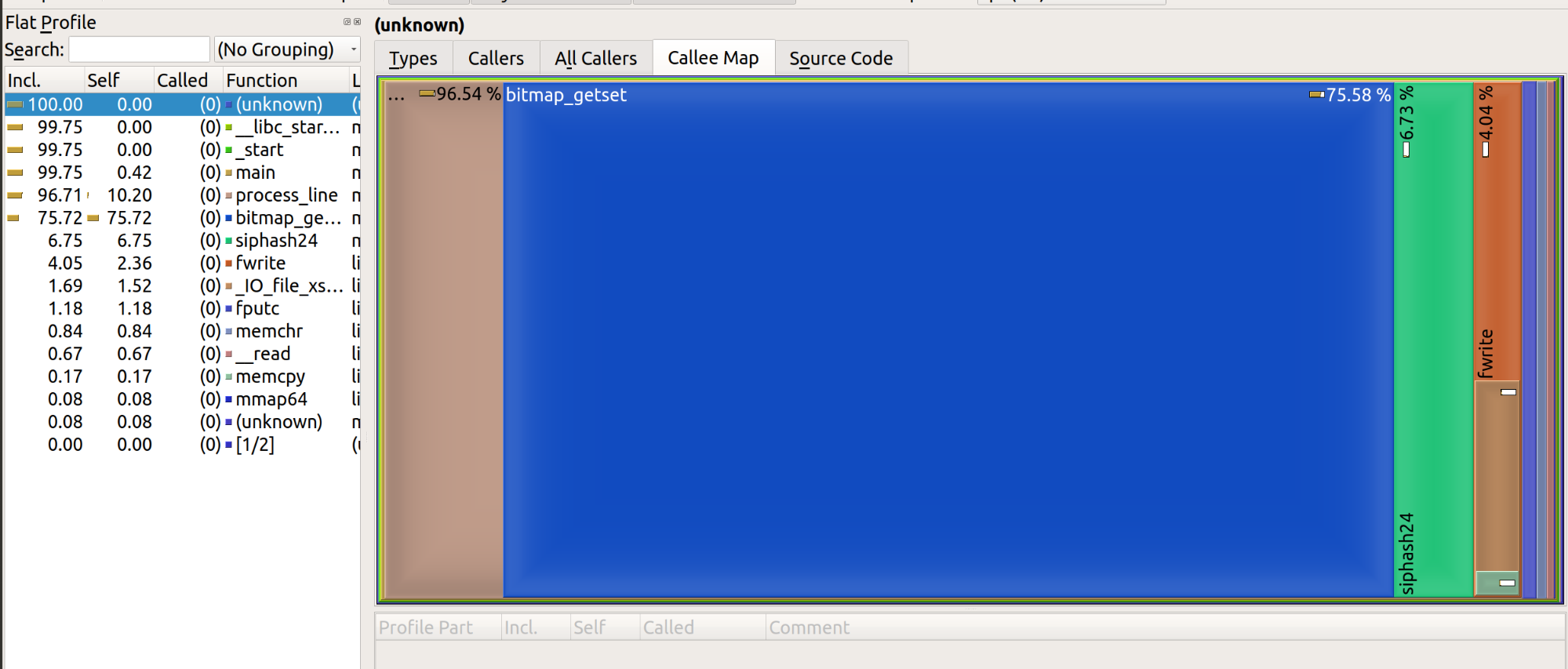
Permita-me resumir o que descobrimos até agora.
A ferramenta genérica "wc" leva 0,45s de tempo de CPU para processar um arquivo de 600 MiB. Nossa ferramenta otimizada "mmuniq-bloom" leva 12 segundos. A CPU é consumida por uma instrução "mov", desreferenciando a memória...

Oh! I how could I have forgotten. Random memory access is slow! It's very, very, very slow!
De acordo com a regra geral "números de latência que todo programador deve conhecer", uma busca de RAM é de cerca de 100 ns. Vamos fazer as contas: 40 milhões de linhas, 8 hashes contados para cada linha. Como nosso filtro de Bloom tem 128 MiB, em nosso hardware mais antigo ele não cabe no cache L3. Os hashes são distribuídos uniformemente por todo o grande intervalo de memória, cada hash gera uma falta de memória. Somando tudo isso é...

Isso sugere 32 segundos consumidos apenas em buscas de memória. O programa real é mais rápido, demorando apenas 12s. Isso ocorre porque, embora os dados do filtro de Bloom não caibam completamente no cache L3, eles ainda obtêm alguns benefícios do armazenamento em cache. É fácil ver com "perf stat -d":
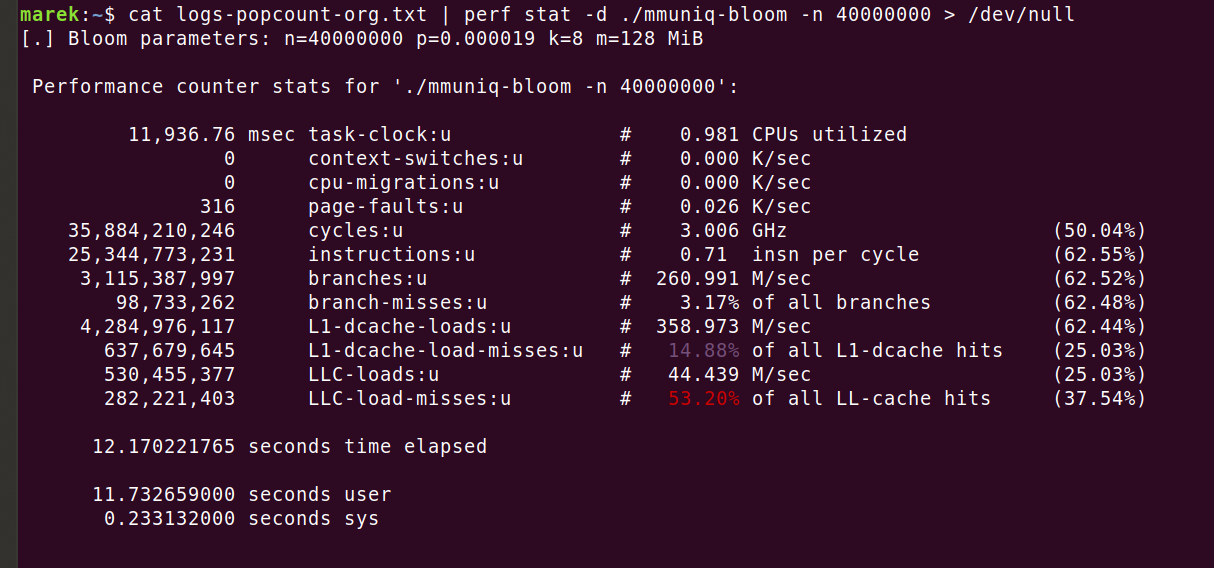
Certo, então deveríamos ter tido pelo menos 320 milhões de erros de carga LLC, mas tivemos apenas 280 milhões. Isso ainda não explica por que o programa ficou rodando apenas 12 segundos. Mas isso realmente não importa. O que importa é que o número de perdas de cache é um problema real e só podemos corrigi-lo reduzindo o número de acessos à memória. Vamos tentar ajustar o filtro de Bloom para usar apenas uma função hash:

Ai! Isso realmente doeu! O filtro de Bloom exigiu 64 GiB de memória para obter nossa taxa de probabilidade de falso positivo desejada de 1 erro por 10 mil linhas. Isso é terrível!
Além disso, não parece que melhoramos muito. O sistema operacional levou 22 segundos para preparar a memória para nós, mas ainda consumimos 11 segundos no espaço do usuário. Acho que desta vez qualquer benefício de atingir a memória com menos frequência foi compensado pela menor probabilidade de acerto no cache devido ao aumento drástico do tamanho da memória. Nas execuções anteriores, precisávamos de apenas 128 MiB para o filtro de Bloom.
Descartando completamente os filtros de Bloom
Isso está ficando ridículo. Para obter as mesmas garantias de falsos positivos, devemos usar muitos hashes no filtro de Bloom (ou seja, 8) e, portanto, muitas operações de memória, ou podemos ter uma função hash, mas com enormes requisitos de memória.
"Na verdade, não estamos limitados pela memória disponível, em vez disso, queremos otimizar para reduzir os acessos à memória. Tudo o que precisamos é de uma estrutura de dados que exija no máximo uma perda de memória por item e use menos de 64 GB de RAM...
Embora possamos pensar em estruturas de dados mais sofisticadas, como o
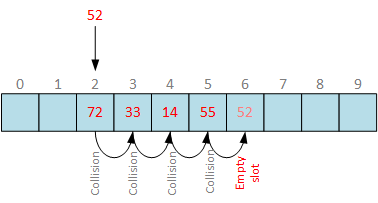
filtro Cuckoo, talvez possamos simplificar. Que tal uma boa e simples tabela de hash com sondagem linear?
{kind=link}
Bem-vindo mmuniq-hash
Aqui você pode encontrar uma versão ajustada do mmuniq-bloom, mas usando tabela hash:
Em vez de armazenar bits como no filtro de Bloom, agora estamos armazenando hashes de 64 bits da função "siphash24". Isso nos dá garantias de probabilidade muito mais fortes, com probabilidade de falsos positivos muito melhor do que um erro em 10 mil linhas.
Vamos fazer as contas. Adicionar um novo item a uma tabela hash contendo, digamos, 40 milhões de entradas tem chances de "40 milhões/2^64" de ocorrer uma colisão de hash. Isto é cerca de um em 461 mil milhões, uma probabilidade razoavelmente baixa. Mas não estamos adicionando um item a um conjunto pré-preenchido. Em vez disso, estamos adicionando 40 milhões de linhas ao conjunto inicialmente vazio. De acordo com o paradoxo do aniversário, isso tem chances muito maiores de resultar em uma colisão em algum momento. Uma boa aproximação é "~n^2/2m", que no nosso caso é "~(40M2)/(2*(264))". Isso representa uma chance de uma em 23 mil. Em outras palavras, assumindo que estamos usando uma boa função de hash, a cada um em 23 mil conjuntos aleatórios de 40 milhões de itens, ocorrerá uma colisão de hash. Essa chance prática de colisão é não negligenciável, mas ainda é melhor do que um filtro de Bloom e totalmente aceitável para o meu caso de uso."
O código da tabela hash é executado mais rápido, tem melhores padrões de acesso à memória e melhor probabilidade de falsos positivos do que a abordagem do filtro de Bloom.

Não se preocupe com a linha "conflitos de hash", ela apenas indica o quanto a tabela hash estava cheia. Estamos usando sondagem linear, então quando um bucket já estiver em uso, basta escolher o próximo bucket vazio. No nosso caso, tivemos que pular, em média, 0,7 buckets para encontrar um espaço vazio na tabela. Isso é aceitável e, como iteramos nos buckets em ordem linear, podemos esperar que a memória seja pré-carregada de maneira eficiente.
Do exercício anterior, sabemos que nossa função hash leva cerca de 2 segundos para isso. Portanto, é justo dizer que 40 milhões de acessos à memória demoram cerca de 4 segundos.
Lições aprendidas
As CPUs modernas são realmente boas no acesso sequencial à memória quando é possível prever padrões de busca de memória (consulte Cache prefetching). O acesso aleatório à memória, por outro lado, é muito caro.
Estruturas de dados avançadas são muito interessantes, mas cuidado. Os computadores modernos requerem algoritmos otimizados para cache. Ao trabalhar com grandes conjuntos de dados, que não se encaixam na L3, é preferível otimizar a redução do número de carregamentos em vez de otimizar a quantidade de memória utilizada.
Acho que é justo dizer que os filtros de Bloom são ótimos, desde que caibam no cache da L3. No momento em que essa suposição é quebrada, eles se tornam problemáticos. Isso não é novidade; os filtros de Bloom otimizam o uso de memória, não o acesso à memória. Veja, por exemplo, o artigo sobre Filtros Cuckoo.
Outra coisa é a discussão constante sobre funções hash. Francamente, na maioria dos casos isso não importa. O custo de contar até mesmo funções hash complexas como "siphash24" é pequeno comparado ao custo do acesso aleatório à memória. No nosso caso, simplificar a função hash trará apenas pequenos benefícios. O tempo da CPU é simplesmente gasto em outro lugar, esperando pela memória.
Um colega costuma dizer: "Você pode presumir que as CPUs modernas são infinitamente rápidas. Elas funcionam em velocidade infinita até
atingirem a parede da memória".
Finalmente, não siga meus erros - todos deveriam começar a criar perfis com 'perf stat -d' e olhar o contador "Instruções por ciclo" (IPC). Se estiver abaixo de um, geralmente significa que o programa está parado aguardando memória. Valores acima de 2 seriam ótimos, pois significariam que a carga de trabalho está principalmente vinculada à CPU. Infelizmente, ainda não vi valores altos nas cargas de trabalho com as quais estou lidando...
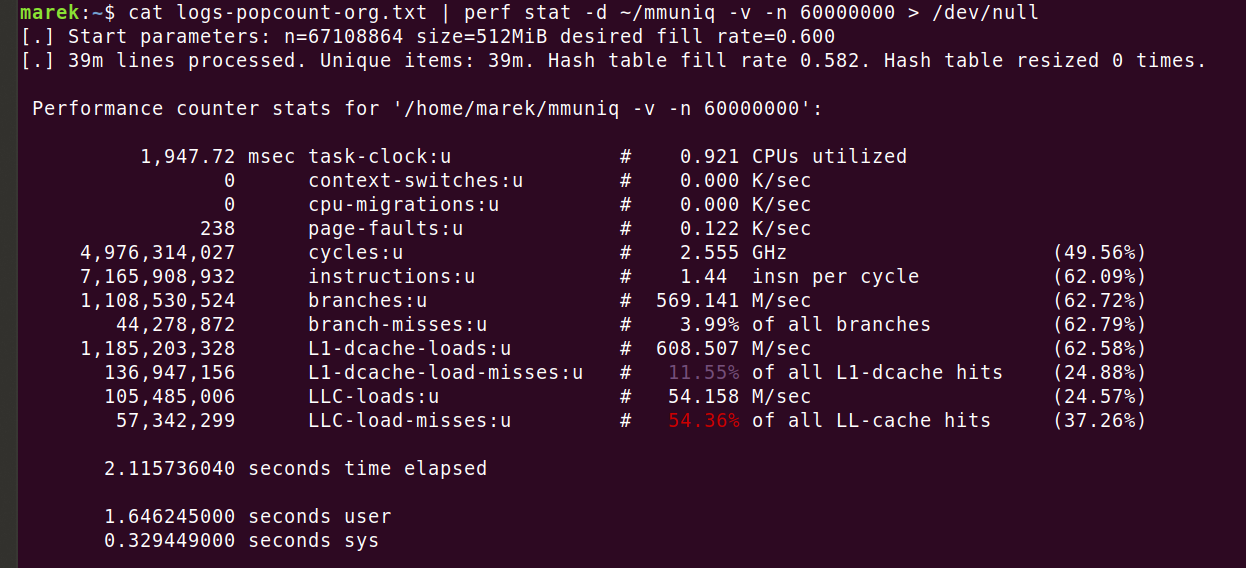
mmuniq aprimorado
Com a ajuda dos meus colegas, preparei uma versão melhorada da ferramenta baseada na tabela hash "mmuniq". Veja o código:
Ele é capaz de redimensionar dinamicamente a tabela de hash para ser compatível com entradas de cardinalidade desconhecida. Em seguida, usando o agrupamento, ele pode efetivamente utilizar a sugestão de CPU "prefetch", acelerando o programa entre 35 e 40%. Cuidado, espalhar "prefetch" no código raramente funciona. Em vez disso, alterei especificamente o fluxo dos algoritmos para tirar vantagem dessa instrução. Com todas essas melhorias, consegui reduzir o tempo de execução para 2.1 segundos:
Fim
Escrever essa ferramenta básica que tenta ser mais rápida que a combinação "sort | uniq" revelou algumas pérolas escondidas da computação moderna. Com um pouco de trabalho, conseguimos acelerá-la de mais de dois minutos para 2 segundos. Durante essa jornada, aprendemos sobre a latência de acesso à memória aleatória e o poder de estruturas de dados amigáveis ao cache. Estruturas de dados sofisticadas são empolgantes, mas, na prática, a redução de carregamentos aleatórios de memória frequentemente traz resultados melhores.