

Introdução
Existem muitas maneiras de armazenar dados em seus aplicativos. Por exemplo, nos aplicativos do Cloudflare Workers, temos o Workers KV para armazenamento de valor-chave e o Durable Objects para armazenamento coordenado em tempo real sem comprometer a consistência. Fora do ecossistema da Cloudflare, você também pode conectar outras ferramentas como NoSQL e bancos de dados gráficos.
Mas, às vezes, você quer SQL. Os índices nos permitem recuperar dados rapidamente. As junções nos permitem descrever relacionamentos complexos entre tabelas diferentes. O SQL descreve declarativamente como os dados de nosso aplicativo são validados, criados e consultados de maneira eficiente.
O D1 foi lançado hoje em alfa aberto e, para comemorar, quero compartilhar minha experiência na criação de aplicativos com o D1: especificamente, como começar e por que estou animado com o D1 se juntando à longa lista de ferramentas que você pode usar para criar aplicativos na Cloudflare.
O D1 é notável porque agrega valor instantâneo aos aplicativos sem precisar de novas ferramentas ou sair do ecossistema da Cloudflare. Usando o Wrangler, podemos fazer o desenvolvimento local em nossos aplicativos do Workers e, com a adição do D1 ao Wrangler, também podemos desenvolver aplicativos com estado apropriados localmente agora. Então, quando é hora de implantar o aplicativo, o Wrangler nos permite acessar e executar comandos para seu banco de dados D1, bem como para sua própria API.
O que estamos desenvolvendo
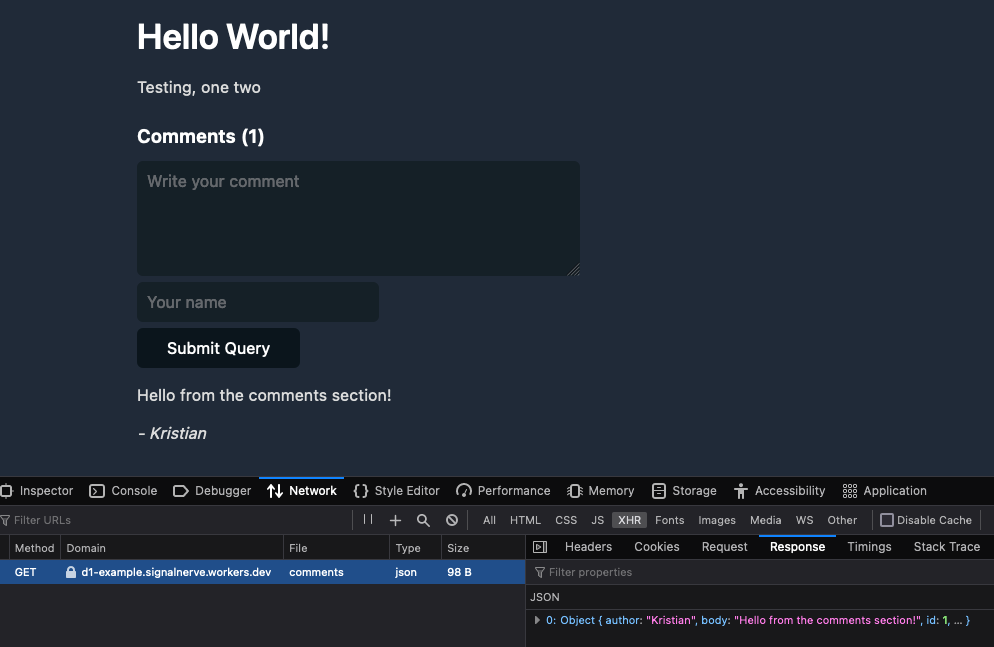
Nesta postagem do blog, mostro como usar o D1 para adicionar comentários a um blog estático. Para fazer isso, vamos criar um novo banco de dados D1 e uma API JSON simples que permite a criação e recuperação de comentários.
Como mencionei, separar o D1 do próprio aplicativo, uma API e um banco de dados que permanece separado do site estático, nos permite abstrair as partes estáticas e dinâmicas do nosso site uma da outra. Também facilita a implantação do nosso aplicativo: vamos implantar o front-end no Cloudflare Pages e a API com tecnologia D1 no Cloudflare Workers.
Como desenvolver um novo aplicativo
Primeiro, adicionamos uma API básica no Workers. Crie um novo diretório e dentro dele um novo projeto Wrangler:
$ mkdir d1-example && d1-example
$ wrangler init
Neste exemplo, usaremos o Hono, um framework estilo Express.js, para criar nossa API rapidamente. Para usar o Hono neste projeto, instale-o usando o NPM:
$ npm install hono
Em seguida, em src/index.ts, inicializamos um novo aplicativo Hono e definimos alguns endpoints - GET /API/posts/:slug/comments e POST /get/api/:slug/comments.
import { Hono } from 'hono'
import { cors } from 'hono/cors'
const app = new Hono()
app.get('/api/posts/:slug/comments', async c => {
// do something
})
app.post('/api/posts/:slug/comments', async c => {
// do something
})
export default app
Agora vamos criar um banco de dados D1. No Wrangler 2, há suporte para o subcomando wrangler d1, que permite criar e consultar seus bancos de dados D1 diretamente da linha de comando. Assim, por exemplo, podemos criar um novo banco de dados com um único comando:
$ wrangler d1 create d1-example
Com nosso banco de dados criado, podemos pegar o ID do nome do banco de dados e associá-lo a uma vinculação dentro do wrangler.toml, arquivo de configuração do wrangler. As vinculações nos permitem acessar os recursos da Cloudflare, como bancos de dados D1, namespaces KV e buckets R2, usando um nome de variável simples em nosso código. Abaixo, criaremos o DB de vinculação e o usaremos para representar nosso novo banco de dados:
[[ d1_databases ]]
binding = "DB" # i.e. available in your Worker on env.DB
database_name = "d1-example"
database_id = "4e1c28a9-90e4-41da-8b4b-6cf36e5abb29"
Observe que nesta diretiva, o campo [[d1_databases]], atualmente requer uma versão beta do wrangler. Você pode instalá-lo para o seu projeto usando o comando npm install -D wrangler/beta.
Com o banco de dados configurado em nosso wrangler.toml, podemos começar a interagir com ele a partir da linha de comando e dentro de nossa função do Workers.
Primeiro, você pode emitir comandos SQL diretos usando wrangler d1 execute:
$ wrangler d1 execute d1-example --command "SELECT name FROM sqlite_schema WHERE type ='table'"
Executing on d1-example:
┌─────────────────┐
│ name │
├─────────────────┤
│ sqlite_sequence │
└─────────────────┘
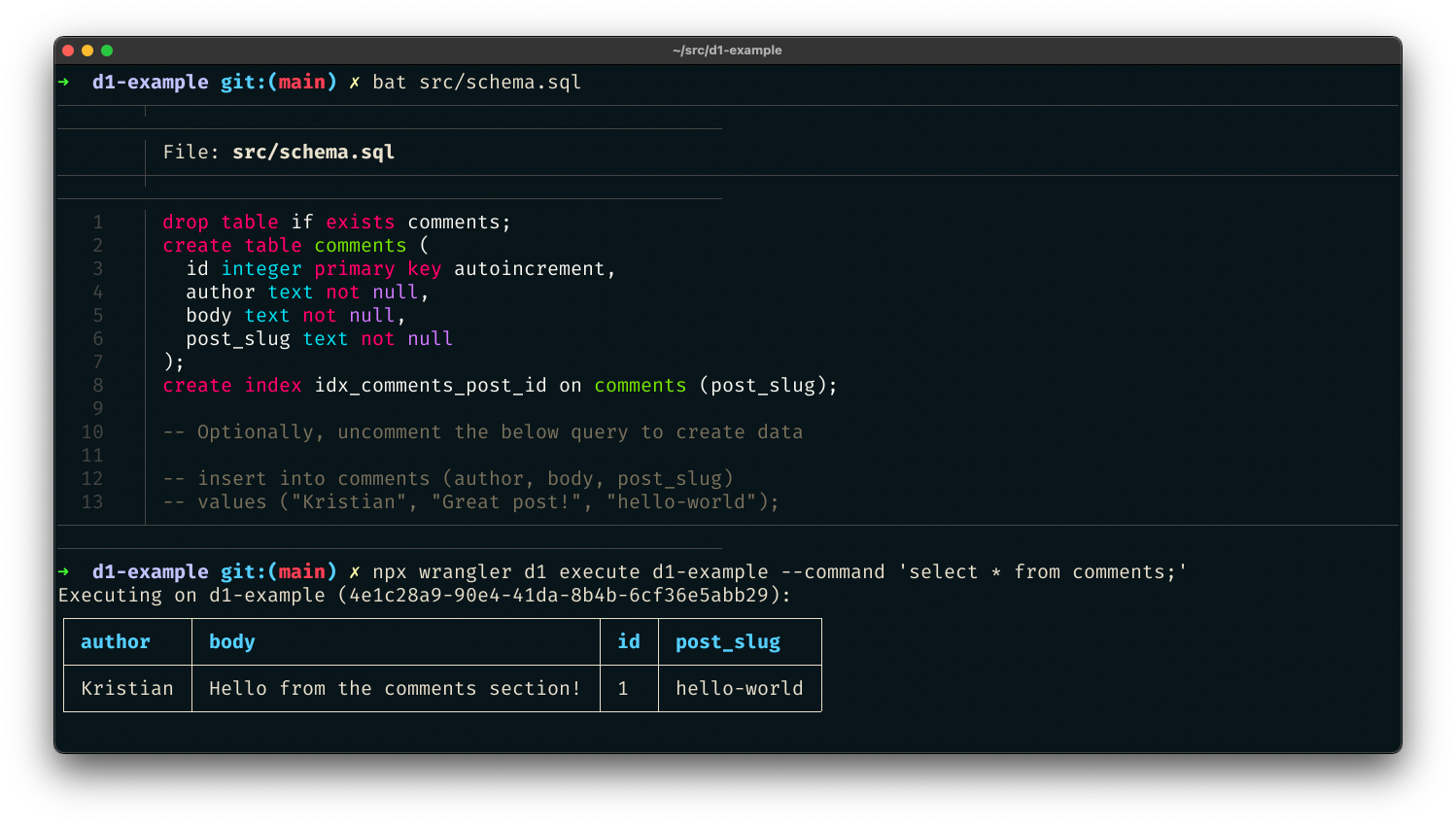
Você também pode transferir um arquivo SQL. Perfeito para a propagação inicial de dados em um único comando. Crie src/schema.sql, que vai produzir uma nova tabela de comments para o nosso projeto:
drop table if exists comments;
create table comments (
id integer primary key autoincrement,
author text not null,
body text not null,
post_slug text not null
);
create index idx_comments_post_id on comments (post_slug);
-- Optionally, uncomment the below query to create data
-- insert into comments (author, body, post_slug)
-- values ("Kristian", "Great post!", "hello-world");
Com o arquivo criado, execute o arquivo de esquema no banco de dados D1 transferindo-o com o sinalizador --file:
$ wrangler d1 execute d1-example --file src/schema.sql
Criamos um banco de dados SQL com apenas alguns comandos e o semeamos com os dados iniciais. Agora podemos adicionar uma rota à nossa função do Workers para recuperar dados desse banco de dados. Com base em nossa configuração wrangler.toml, o banco de dados D1 agora pode ser acessado por meio da vinculação do DB. Em nosso código, podemos usar a vinculação para preparar instruções SQL e executá-las, por exemplo, para recuperar comentários:
app.get('/api/posts/:slug/comments', async c => {
const { slug } = c.req.param()
const { results } = await c.env.DB.prepare(`
select * from comments where post_slug = ?
`).bind(slug).all()
return c.json(results)
})
Nesta função, aceitamos um parâmetro de consulta de URL slug e configuramos uma nova instrução SQL onde selecionamos todos os comentários com um valor post_slug correspondente ao nosso parâmetro de consulta. Podemos então retorná-lo como uma resposta JSON simples.
Até agora, criamos acesso somente leitura aos nossos dados. Mas "inserir" valores no SQL também é possível. Então, vamos definir outra função que permite fazer POST em um endpoint para criar um novo comentário:
app.post('/API/posts/:slug/comments', async c => {
const { slug } = c.req.param()
const { author, body } = await c.req.json<Comment>()
if (!author) return c.text("Missing author value for new comment")
if (!body) return c.text("Missing body value for new comment")
const { success } = await c.env.DB.prepare(`
insert into comments (author, body, post_slug) values (?, ?, ?)
`).bind(author, body, slug).run()
if (success) {
c.status(201)
return c.text("Created")
} else {
c.status(500)
return c.text("Something went wrong")
}
})
Neste exemplo, criamos uma API de comentários para alimentar um blog. Para ver a fonte dessa API de comentários com tecnologia D1, você pode acessar cloudflare/templates/worker-d1-api.
Conclusão
Uma das coisas mais empolgantes do D1 é a oportunidade de aumentar os aplicativos ou sites existentes com dados relacionais dinâmicos. Como ex-desenvolvedor da Ruby on Rails, uma das coisas que mais sinto falta dessa estrutura no mundo do JavaScript e das ferramentas de desenvolvimento sem servidor é a capacidade de criar rapidamente aplicativos completos orientados por dados sem precisar ser um especialista em gerenciamento de infraestrutura de banco de dados. Com o D1 e seu acesso fácil aos dados baseados em SQL, podemos criar verdadeiros aplicativos orientados por dados sem comprometer o desempenho ou a experiência do desenvolvedor.
Essa mudança corresponde muito bem ao advento de sites estáticos nos últimos anos, usando ferramentas como Hugo ou Gatsby. Um blog criado com um gerador de site estático, como o Hugo, tem um desempenho incrível, ele é criado em segundos com ativos pequenos.
Mas ao trocar uma ferramenta como o WordPress por um gerador de sites estáticos, você perde a oportunidade de adicionar informações dinâmicas ao seu site. Muitos desenvolvedores corrigiram esse problema adicionando mais complexidade aos seus processos de desenvolvimento: buscar e recuperar dados e gerar páginas usando esses dados como parte do desenvolvimento.
Essa adição de complexidade no processo de criação tenta corrigir a falta de dinamismo nos aplicativos, mas ainda não é genuinamente dinâmico. Em vez de poder recuperar e exibir novos dados à medida que são criados, o aplicativo é reconstruído e reimplantado sempre que os dados são alterados para que pareçam uma representação em tempo real e dinâmica dos dados. Seu aplicativo pode permanecer estático e os dados dinâmicos vão residir geograficamente próximos aos usuários de seu site, acessíveis por meio de uma API expressiva e consultável.