


This post is also available in 简体中文, 繁體中文, 日本語, 한국어, Deutsch, Français and Español.
Cloudflare now automatically discovers all API endpoints and learns API schemas for all of our API Gateway customers. Customers can use these new features to enforce a positive security model on their API endpoints even if they have little-to-no information about their existing APIs today.
The first step in securing your APIs is knowing your API hostnames and endpoints. We often hear that customers are forced to start their API cataloging and management efforts with something along the lines of “we email around a spreadsheet and ask developers to list all their endpoints”.
Can you imagine the problems with this approach? Maybe you have seen them first hand. The “email and ask” approach creates a point-in-time inventory that is likely to change with the next code release. It relies on tribal knowledge that may disappear with people leaving the organization. Last but not least, it is susceptible to human error.
Even if you had an accurate API inventory collected by group effort, validating that API was being used as intended by enforcing an API schema would require even more collective knowledge to build that schema. Now, API Gateway’s new API Discovery and Schema Learning features combine to automatically protect APIs across the Cloudflare global network and remove the need for manual API discovery and schema building.
API Gateway discovers and protects APIs
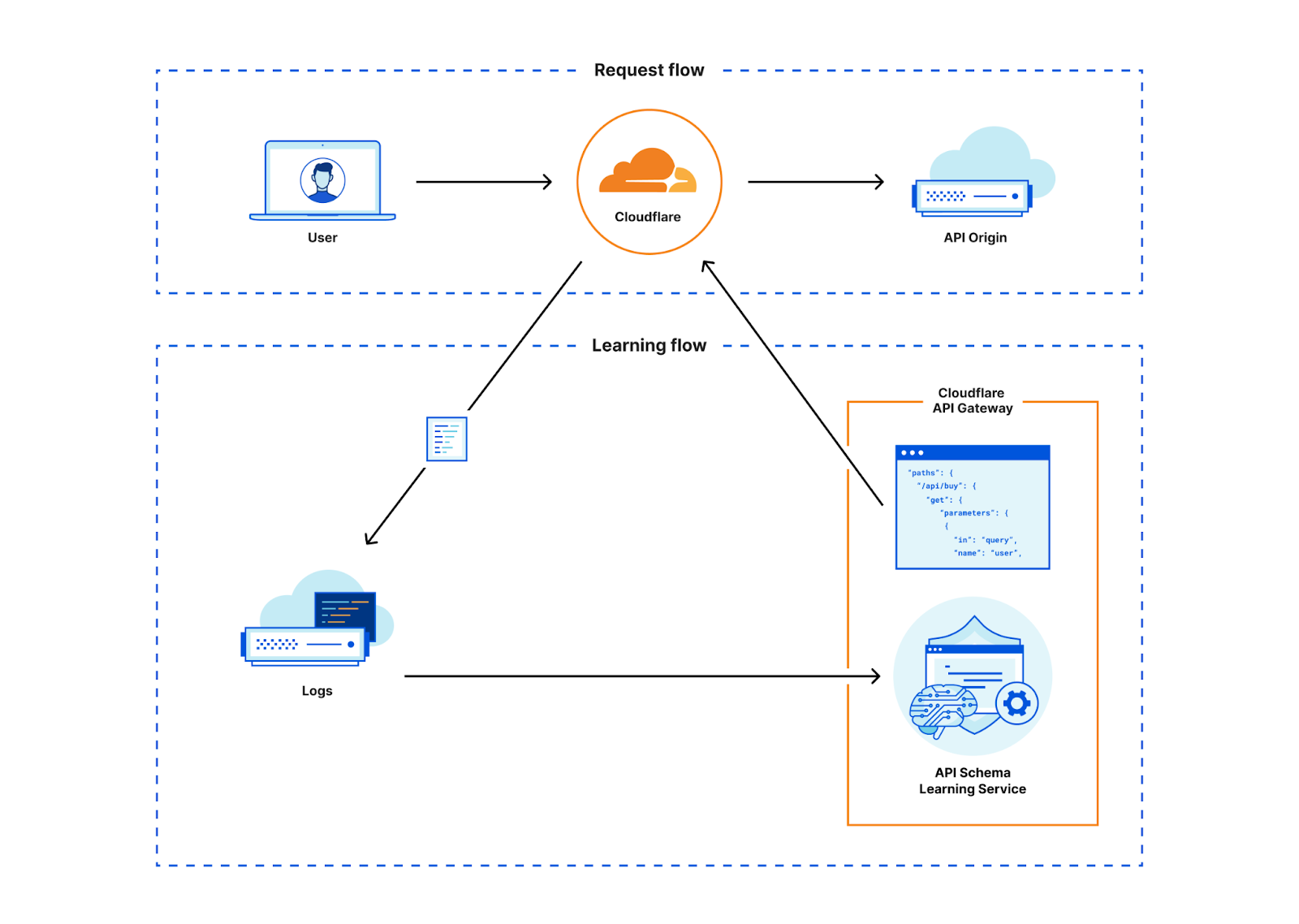
API Gateway discovers APIs through a feature called API Discovery. Previously, API Discovery used customer-specific session identifiers (HTTP headers or cookies) to identify API endpoints and display their analytics to our customers.
Doing discovery in this way worked, but it presented three drawbacks:
- Customers had to know which header or cookie they used in order to delineate sessions. While session identifiers are common, finding the proper token to use can take time.
- Needing a session identifier for API Discovery precluded us from monitoring and reporting on completely unauthenticated APIs. Customers today still want visibility into session-less traffic to ensure all API endpoints are documented and that abuse is at a minimum.
- Once the session identifier was input into the dashboard, customers had to wait up to 24 hours for the Discovery process to complete. Nobody likes to wait.
While this approach had drawbacks, we knew we could quickly deliver value to customers by starting with a session-based product. As we gained customers and passed more traffic through the system, we knew our new labeled data would be extremely useful to further build out our product. If we could train a machine learning model with our existing API metadata and the new labeled data, we would no longer need a session identifier to pinpoint which endpoints were for APIs. So we decided to build this new approach.
We took what we learned from the session identifier-based data and built a machine learning model to uncover all API traffic to a domain, regardless of session identifier. With our new Machine Learning-based API Discovery, Cloudflare continually discovers all API traffic routed through our network without any prerequisite customer input. With this release, API Gateway customers will be able to get started with API Discovery faster than ever, and they’ll uncover unauthenticated APIs that they could not discover before.
Session identifiers are still important to API Gateway, as they form the basis of our volumetric abuse prevention rate limits as well as our Sequence Analytics. See more about how the new approach performs in the “How it works” section below.
API Protection starting from nothing
Now that you’ve found new APIs using API Discovery, how do you protect them? To defend against attacks, API developers must know exactly how they expect their APIs to be used. Luckily, developers can programmatically generate an API schema file which codifies acceptable input to an API and upload that into API Gateway’s Schema Validation.
However, we already talked about how many customers can't find their APIs as fast as their developers build them. When they do find APIs, it’s very difficult to accurately build a unique OpenAPI schema for each of potentially hundreds of API endpoints, given that security teams seldom see more than the HTTP request method and path in their logs.
When we looked at API Gateway’s usage patterns, we saw that customers would discover APIs but almost never enforce a schema. When we ask them ‘why not?’ the answer was simple: “Even when I know an API exists, it takes so much time to track down who owns each API so that they can provide a schema. I have trouble prioritizing those tasks higher than other must-do security items.” The lack of time and expertise was the biggest gap in our customers enabling protections.
So we decided to close that gap. We found that the same learning process we used to discover API endpoints could then be applied to endpoints once they were discovered in order to automatically learn a schema. Using this method we can now generate an OpenAPI formatted schema for every single endpoint we discover, in real time. We call this new feature Schema Learning. Customers can then upload that Cloudflare-generated schema into Schema Validation to enforce a positive security model.
How it works
Machine learning-based API discovery
With RESTful APIs, requests are made up of different HTTP methods and paths. Take for example the Cloudflare API. You’ll notice a common trend with the paths that might make requests to this API stand out amongst requests to this blog: API requests all start with /client/v4 and continue with the service name, a unique identifier, and sometimes service feature names and further identifiers.
How could we easily identify API requests? At first glance, these requests seem easy to programmatically discover with a heuristic like “path starts with /client”, but the core of our new Discovery contains a machine-learned model that powers a classifier that scores HTTP transactions. If API paths are so structured, why does one need machine-learning for this and can’t one just use some simple heuristic?
The answer boils down to the question: what actually constitutes an API request and how does it differ from a non-API request? Let’s look at two examples.
Like the Cloudflare API, many of our customers’ APIs follow patterns such as prefixing the path of their API request with an “api” identifier and a version, for example: /api/v2/user/7f577081-7003-451e-9abe-eb2e8a0f103d.
So just looking for “api” or a version in the path is already a pretty good heuristic that tells us this is very likely part of an API, but it is unfortunately not always as easy.
Let’s consider two further examples, /users/7f577081-7003-451e-9abe-eb2e8a0f103d.jpg and /users/7f577081-7003-451e-9abe-eb2e8a0f103d, both just differ in a .jpg extension. The first path could just be a static resource like the thumbnail of a user. The second path does not give us a lot of clues just from the path alone.
Manually crafting such heuristics quickly becomes difficult. While humans are great at finding patterns, building heuristics is challenging considering the scale of the data that Cloudflare sees each day. As such, we use machine learning to automatically derive these heuristics such that we know that they are reproducible and adhere to a certain accuracy.
Input to the training are features of HTTP request/response samples such as the content-type or file extension that we collected through the session identifiers-based Discovery mentioned earlier. Unfortunately, not everything that we have in this data is clearly an API. Additionally, we also need samples that represent non-API traffic. As such, we started out with the session-identifier Discovery data, manually cleaned it up and derived further samples of non-API traffic. We took great care in trying to not overfit the model to the data. That is, we want that the model generalizes beyond the training data.
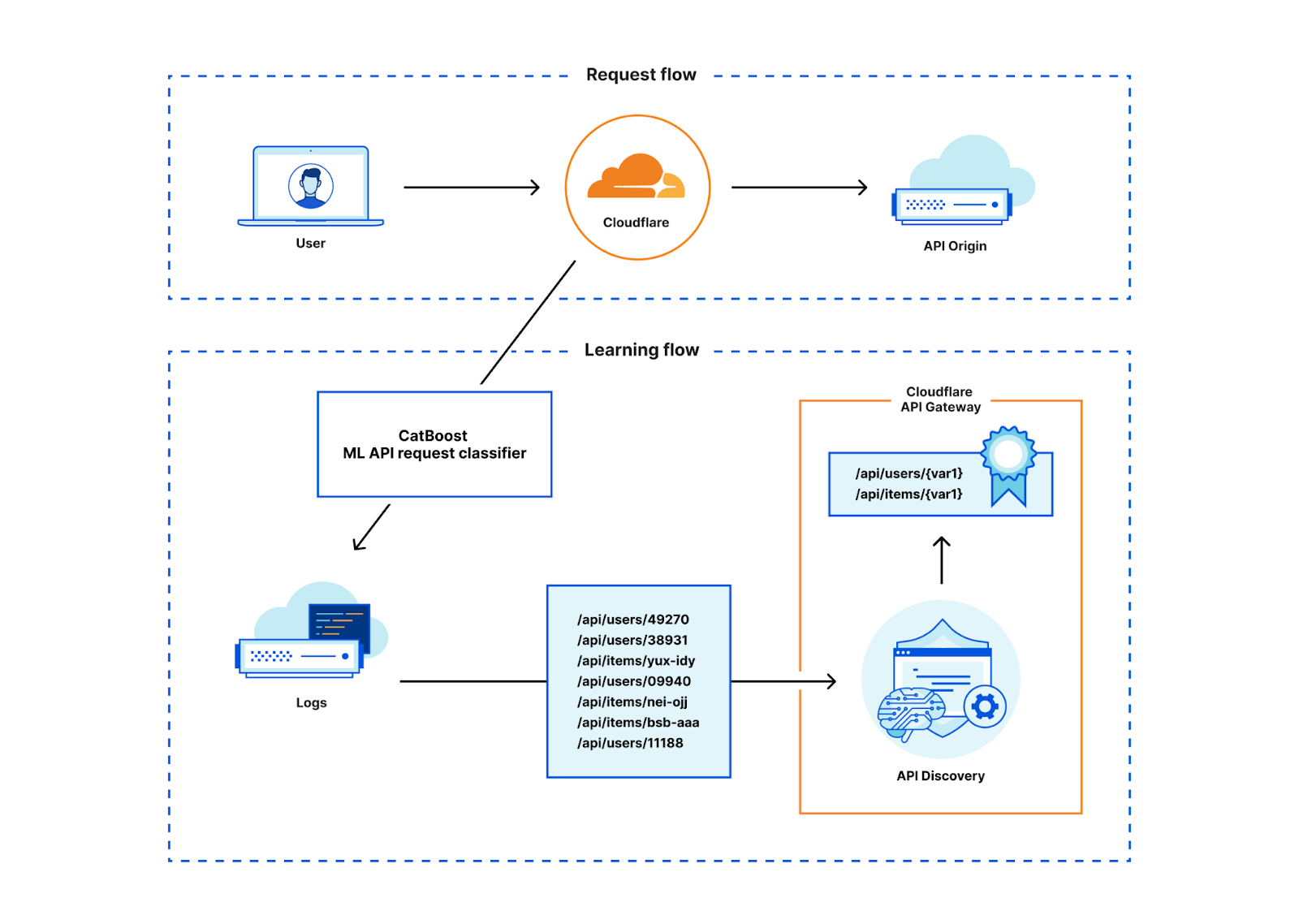
To train the model, we’ve used the CatBoost library for which we already have a good chunk of expertise as it also powers our Bot Management ML-models. In a simplification, one can regard the resulting model as a flow chart that tells us which conditions we should check after another, for example: if the path contains “api” then also check if there is no file extension and so forth. At the end of this flowchart is a score that tells us the likelihood that a HTTP transaction belongs to an API.
Given the trained model, we can thus input features of HTTP request/responses that run through the Cloudflare network and calculate the likelihood that this HTTP transaction belongs to an API or not. Feature extraction and model scoring is done in Rust and takes only a couple of microseconds on our global network. Since Discovery sources data from our powerful data pipeline, it is not actually necessary to score each transaction. We can reduce the load on our servers by only scoring those transactions that we know will end up in our data pipeline to begin with thus saving CPU time and allowing the feature to be cost effective.
With the classification results in our data pipeline, we can use the same API Discovery mechanism that we’ve been using for the session identifier-based discovery. This existing system works great and allows us to reuse code efficiently. It also aided us when comparing our results with the session identifier-based Discovery, as the systems are directly comparable.
For API Discovery results to be useful, Discovery’s first task is to simplify the unique paths we see into variables. We’ve talked about this before. It is not trivial to deduce the various different identifier schemes that we see across the global network, especially when sites use custom identifiers beyond a straightforward GUID or integer format. API Discovery aptly normalizes paths containing variables with the help of a few different variable classifiers and supervised learning.
Only after normalizing paths are the Discovery results ready for our users to use in a straightforward fashion.
The results: hundreds of found endpoints per customer
So, how does ML Discovery compare to the session identifier-based Discovery which relies on headers or cookies to tag API traffic?
Our expectation is that it detects a very similar set of endpoints. However, in our data we knew there would be two gaps. First, we sometimes see that customers are not able to cleanly dissect only API traffic using session identifiers. When this happens, Discovery surfaces non-API traffic. Second, since we required session identifiers in the first version of API Discovery, endpoints that are not part of a session (e.g. login endpoints or unauthenticated endpoints) were conceptually not discoverable.
The following graph shows a histogram of the number of endpoints detected on customer domains for both discovery variants.

From a bird's eye perspective, the results look very similar, which is a good indicator that ML Discovery performs as it is supposed to. There are some differences already visible in this plot, which is also expected since we’ll also discover endpoints that are conceptually not discoverable with just a session identifier. In fact, if we take a closer look at a domain-by-domain comparison we see that there is no change for roughly ~46% of the domains. The next graph compares the difference (by percent of endpoints) between session-based and ML-based discovery:

For ~15% of the domains, we see an increase in endpoints between 1 and 50, and for ~9%, we see a similar reduction. For ~28% of the domains, we find more than 50 additional endpoints.
These results highlight that ML Discovery is able to surface additional endpoints that have previously been flying under the radar, and thus expands the set tools API Gateway offers to help bring order to your API landscape.
On-the-fly API protection through API schema learning
With API Discovery taken care of, how can a practitioner protect the newly discovered endpoints? We already looked at the API request metadata, so now let’s look at the API request body. The compilation of all expected formats for all API endpoints of an API is known as an API schema. API Gateway’s Schema Validation is a great way to protect against OWASP Top 10 API attacks, ensuring the body, path, and query string of a request contains the expected information for that API endpoint in an expected format. But what if you don’t know the expected format?
Even if the schema of a specific API is not known to a customer, the clients using this API will have been programmed to mostly send requests that conform to this unknown schema (or they would not be able to successfully query the endpoint). Schema Learning makes use of this fact and will look at successful requests to this API to reconstruct the input schema automatically for the customer. As an example, an API might expect the user-ID parameter in a request to have the form id12345-a. Even if this expectation is not explicitly stated, clients that want to have a successful interaction with the API will send user-IDs in this format.
Schema Learning first identifies all recent successful requests to an API-endpoint, and then parses the different input parameters for each request according to their position and type. After parsing all requests, Schema Learning looks at the different input values for each position and identifies which characteristics they have in common. After verifying that all observed requests share these commonalities, Schema Learning creates an input schema that restricts input to comply with these commonalities and that can directly be used for Schema Validation.
To allow for more accurate input schemas, Schema Learning identifies when a parameter can receive different types of input. Let's say you wanted to write an OpenAPIv3 schema file and manually observe in a small sample of requests that a query parameter is a unix timestamp. You write an API schema that forces that query parameter to be an integer greater than the start of last year's unix epoch. If your API also allowed that parameter in ISO 8601 format, your new rule would create false positives when the differently formatted (yet valid) parameter hit the API. Schema Learning automatically does all this heavy lifting for you and catches what manual inspection can't.
To prevent false positives, Schema Learning performs a statistical test on the distribution of these values and only writes the schema when the distribution is bounded with high confidence.
So how well does it work? Below are some statistics about the parameter types and values we see:

Parameter learning classifies slightly more than half of all parameters as strings, followed by integers which make up almost a third. The remaining 17% are made up of arrays, booleans, and number (float) parameters, while object parameters are seen more rarely in the path and query.

The number of parameters in the path is usually very low, with 94% of all endpoints seeing at most one parameter in their path.

For the query, we do see a lot more parameters, sometimes reaching 50 different parameters for one endpoint!
Parameter learning is able to estimate numeric constraints with 99.9% confidence for the majority of parameters observed. These constraints can either be a maximum/minimum on the value, length, or size of the parameter, or a limited set of unique values that a parameter has to take.
Protect your APIs in minutes
Starting today, all API Gateway customers can now discover and protect APIs in just a few clicks, even if you're starting with no previous information. In the Cloudflare dash, click into API Gateway and on to the Discovery tab to observe your discovered endpoints. These endpoints will be immediately available with no action required from you. Then, add relevant endpoints from Discovery into Endpoint Management. Schema Learning runs automatically for all endpoints added to Endpoint Management. After 24 hours, export your learned schema and upload it into Schema Validation.
Enterprise customers that haven’t purchased API Gateway can get started by enabling the API Gateway trial inside the Cloudflare Dashboard or contacting their account manager.
What’s next
We plan to enhance Schema Learning by supporting more learned parameters in more formats, like POST body parameters with both JSON and URL-encoded formats as well as header and cookie schemas. In the future, Schema Learning will also notify customers when it detects changes in the identified API schema and present a refreshed schema.
We’d like to hear your feedback on these new features. Please direct your feedback to your account team so that we can prioritize the right areas of improvement. We look forward to hearing from you!