


오늘 Workers AI에 Mistral-7B-v0.1-instruct를 추가했다는 소식을 알려드리게 되어 기쁩니다. Mistral 7B는 73억 개의 매개변수 언어 모델로, 여러 가지 고유한 장점을 갖추고 있습니다. Mistral AI 창립자의 도움을 받아 Mistral 7B 모델의 주요 특징 몇 가지를 살펴보고, 이 기회를 통해 "어텐션"과 다중 쿼리 어텐션, 그룹화된 쿼리 어텐션 등 그 변형에 대해 자세히 알아보겠습니다.
Mistral 7B tl;dr:
Mistral 7B는 73억 개의 매개변수로 구성된 모델로 벤치마크에서 인상적인 수치를 기록합니다. 모델:
- 모든 벤치마크에서 동급 13B 모델보다 뛰어난 성능 제공
- 많은 벤치마크에서 동급의 34B보다 뛰어난 성능을 발휘
- 영어 작업에 능숙하면서도 코드에 대한 CodeLlama 7B 성능에 근접
- 우리가 배포한 채팅 미세 조정 버전은 Mistral에서 제공하는 벤치마크에서 비슷한 2 13B 채팅보다 성능이 뛰어남.
다음은 REST API로 스트리밍을 사용하는 예제입니다.
curl -X POST \
“https://api.cloudflare.com/client/v4/accounts/{account-id}/ai/run/@cf/mistral/mistral-7b-instruct-v0.1” \
-H “Authorization: Bearer {api-token}” \
-H “Content-Type:application/json” \
-d '{ “prompt”: “What is grouped query attention”, “stream”: true }'
API Response: { response: “Grouped query attention is a technique used in natural language processing (NLP) and machine learning to improve the performance of models…” }
또한 다음은 Worker 스크립트를 사용하는 예제입니다.
import { Ai } from '@cloudflare/ai';
export default {
async fetch(request, env) {
const ai = new Ai(env.AI);
const stream = await ai.run('@cf/mistral/mistral-7b-instruct-v0.1', {
prompt: 'What is grouped query attention',
stream: true
});
return Response.json(stream, { headers: { “content-type”: “text/event-stream” } });
}
}
Mistral은 더 빠른 추론을 위해 그룹화된 쿼리 어텐션을 활용합니다. 최근에 개발된 이 기술은 출력 품질에 영향을 주지 않으면서 추론 속도를 향상합니다. 70억 개의 매개변수 모델의 경우, 그룹화된 쿼리 어텐션 덕분에 Mistral을 사용하면 초당 4배에 가까운 토큰을 생성할 수 있습니다(우리가 Llama를 사용할 때보다).
Mistral-7B 사용을 시작하기 위해 이 이상의 정보가 필요하지 않으며, 지금 바로 테스트해 볼 수 있습니다(ai.cloudflare.com). 어텐션 및 그룹화된 쿼리 어텐션에 대해 자세히 알아보려면 계속 읽어보세요!
그런데 대체 "어텐션"이란 무엇일까요?
어텐션의 기본 메커니즘, 특히 획기적인 논문 Attention Is All You Need에서 소개된 "스케일링된 내적 어텐션(Scaled Dot-Product Attention)"은 아주 간단합니다.
우리는 우리의 특별한 어텐션을 "Scale Dot-Product Attention"이라고 부릅니다. 입력은 쿼리와 차원 d_k의 키, 차원 d_v의 값으로 구성됩니다. 모든 키로 쿼리의 내적을 계산하고, 각각을 sqrt(d_k)로 나눈 다음 softmax 함수를 적용하여 값에 가중치를 구합니다.
좀 더 구체적으로 설명하면 다음과 같습니다.
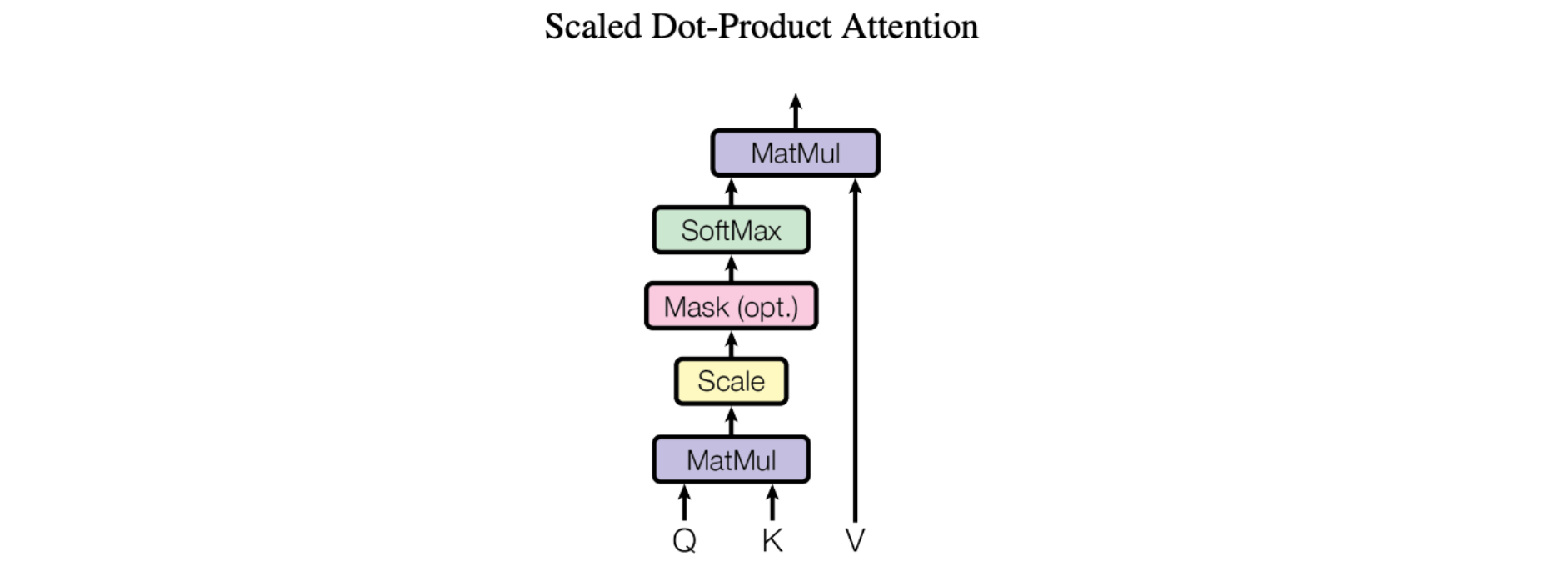
간단히 말해서, 이를 통해 모델은 입력의 중요한 부분에 집중할 수 있습니다. 문장을 읽고 그 문장을 이해하려고 노력한다고 상상해 보세요. 스케일링된 내적 어텐션을 사용하면 관련성에 따라 특정 단어에 더 많은 주의를 기울일 수 있습니다. 이는 문장의 각 단어(K)와 쿼리(Q) 간의 유사도를 계산하는 방식으로 작동합니다. 그런 다음 유사도 스코어를 쿼리 차원의 제곱근으로 나누어 스케일링합니다. 이 스케일링은 매우 작거나 매우 큰 값을 피하는 데 도움이 됩니다. 마지막으로, 이러한 유사도 스코어를 사용하여 각 단어가 얼마나 많은 어텐션을 받아야 하는지 또는 얼마나 중요한지 결정할 수 있습니다. 이 어텐션 메커니즘은 모델이 중요한 정보(V)를 식별하고 이해 및 번역 능력을 향상하는 데 도움이 됩니다.
쉽죠? 이 간단한 메커니즘에서 "Jerry가 버블 정렬 알고리즘을 배우는 Seinfeld 에피소드"를 작성할 수 있는 AI로 발전시키려면 더 복잡하게 만들어야 합니다. 사실, 방금 다룬 모든 것에는 어텐션 블록의 출력을 사용자 지정하는 모델 학습 중에 학습된 상수 값인 학습된 매개변수조차 없습니다!
Attention Is All You Need 유형의 어텐션 블록은 주로 세 가지 유형의 복잡성을 추가합니다.
학습된 매개변수
학습된 매개변수는 모델의 성능을 개선하기 위해 모델의 학습 과정에서 조정되는 값 또는 가중치를 의미합니다. 이러한 매개변수는 모델 내에서 정보나 관심의 흐름을 제어하여 입력 데이터의 가장 관련성이 높은 부분에 집중할 수 있도록 하는 데 사용됩니다. 간단히 말해서, 학습된 매개변수는 기계의 조절 가능한 손잡이와 같아서 이를 돌려 작동을 최적화할 수 있습니다.
수직 스태킹 - 레이어드 어텐션 블록
수직 레이어 스태킹은 여러 개의 어텐션 메커니즘을 서로 겹쳐서 쌓는 방법으로, 각 레이어는 이전 레이어의 결과물을 기반으로 합니다. 이를 통해 모델은 다양한 추상화 수준에서 입력 데이터의 다른 부분에 집중할 수 있으므로 특정 작업에서 더 나은 성능을 얻을 수 있습니다.
수평 스태킹 - 일명 멀티 헤드 어텐션
논문의 그림은 전체 멀티 헤드 어텐션 모듈을 나타냅니다. 여러 어텐션 연산이 병렬로 수행되며, 각각에 대한 Q-K-V 입력은 동일한 입력 데이터의 고유한 선형 투영(고유한 학습된 매개변수 집합으로 정의됨)에 의해 생성됩니다. 이러한 병렬 어텐션 블록을 "어텐션 헤드"라고 합니다. 모든 어텐션 헤드의 가중치 합산 출력은 단일 벡터로 연결되고 매개변수화된 또 다른 선형 변환을 거쳐 최종 출력을 얻습니다.
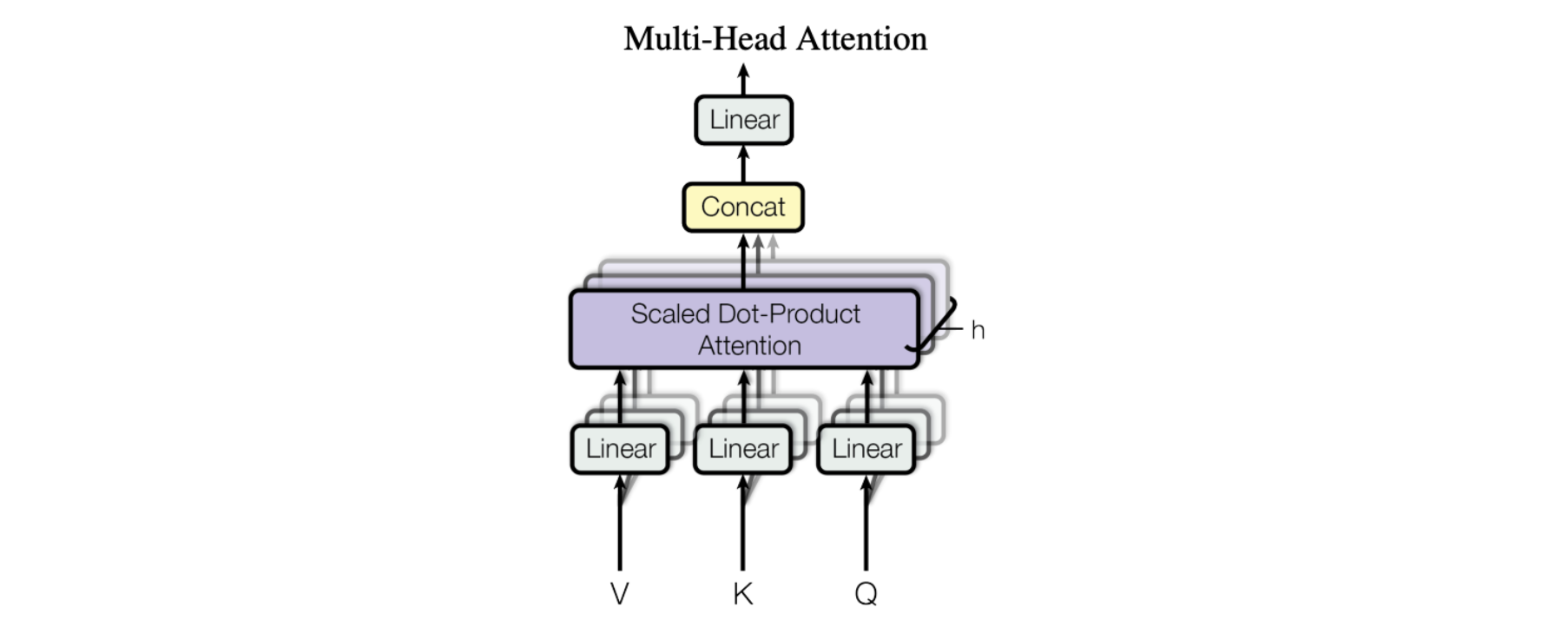
이 메커니즘을 통해 모델은 입력 데이터의 여러 부분에 동시에 집중할 수 있습니다. 문장이나 단락과 같은 복잡한 정보를 이해하려고 한다고 상상해 보세요. 이를 이해하려면 동시에 각기 다른 부분에 주의를 기울여야 합니다. 예를 들어, 문장의 의미를 이해하기 위해서는 문장의 주어, 동사, 목적어에 동시에 주의를 기울여야 할 수도 있습니다. 멀티헤드 어텐션도 비슷하게 작동합니다. 여러 개의 "헤드" 를 사용하여 모델이 입력 데이터의 여러 부분에 동시에 주의를 기울일 수 있도록 합니다. 각 어텐션 헤드는 입력 데이터의 각기 다른 측면에 초점을 맞추고 모든 헤드의 출력을 결합하여 모델의 최종 출력을 생성합니다.
어텐션의 유형
최근에 개발된 대규모 언어 모델에서 사용하는 어텐션 블록에는 다중 헤드 어텐션, 그룹화된 쿼리 어텐션, 다중 쿼리 어텐션의 세 가지 일반적인 배열이 있습니다. 쿼리 벡터의 수에 비례하여 K 및 V 벡터의 수가 다릅니다. 멀티 헤드 어텐션은 아래 표에서 "N"으로 표시된 Q 벡터와 동일한 수의 K 및 V 벡터를 사용합니다. 다중 쿼리 어텐션은 단일 K 및 V 벡터만 사용합니다. Mistral 7B 모델에서 사용되는 유형인 그룹화된 쿼리 어텐션은 Q 벡터를 각각 "G" 벡터를 포함하는 그룹으로 균등하게 나눈 다음 각 그룹에 대해 단일 K 및 V 벡터를 사용하여 총 N을 G 세트의 K 및 V 벡터로 나눕니다. 이것으로 차이점을 요약했으며, 그 의미에 대해서는 아래에서 자세히 살펴보겠습니다.
|
키/값 블록 수 |
품질 |
메모리 사용량 |
|
|
멀티 헤드 어텐션(MHA) |
N |
최고의 |
대부분 |
|
그룹화된 쿼리 어텐션(GQA) |
N / G |
더 나은 |
더 적은 |
|
다중 쿼리 어텐션(MQA) |
1 |
양호한 |
최소 |
어텐션 유형 요약
이 다이어그램은 세 가지 유형의 차이점을 설명하는 데 도움이 됩니다.
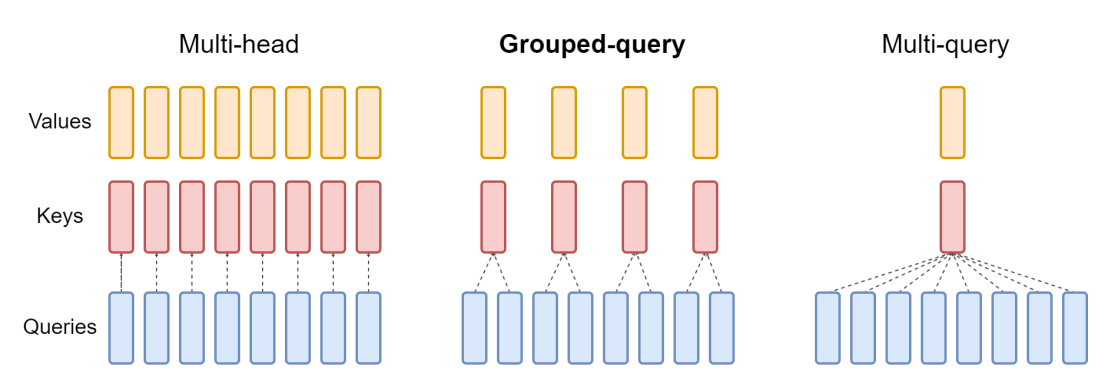
다중 쿼리 어텐션
다중 쿼리 어텐션은 2019년 Google의 다음 논문에서 설명된 바 있습니다. Fast Transformer Decoding: One Write-Head is All You Need. 이 아이디어는 위의 다중 헤드 어텐션에서처럼 어텐션 메커니즘의 모든 Q 벡터에 대해 별도의 K 및 V 항목을 생성하는 대신 전체 Q 벡터 집합에 대해 하나의 K 및 V 벡터만 사용한다는 것입니다. 따라서 여러 개의 쿼리가 하나의 어텐션 메커니즘으로 결합된 것입니다. 이 논문에서는 번역 작업을 벤치마크한 결과 벤치마크 작업에서 다중 헤드 어텐션과 동등한 성능을 보였습니다.
원래의 아이디어는 모델에 대한 추론을 수행할 때 액세스하는 총 메모리 크기를 줄이는 것이었습니다. 이후 일반화된 모델이 등장하고 매개변수 수가 증가함에 따라 세 가지 어텐션 유형 중 가장 적은 가속기 메모리를 필요로 하는 다중 쿼리 어텐션의 강점인 GPU 메모리가 병목 현상이 발생하는 경우가 많습니다. 그러나 모델의 크기와 일반성이 커짐에 따라 다중 쿼리 어텐션의 성능은 다중 헤드 어텐션에 비해 상대적으로 떨어졌습니다.
그룹화된 쿼리 어텐션
이 중 가장 최신이며 Mistral에서 사용하는 것은 그룹화된 쿼리 어텐션으로, 논문 GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints에서 설명되었습니다. 이 논문은 2023년 5월 arxiv.org에 게재되었습니다. 그룹화된 쿼리 어텐션은 멀티헤드 어텐션의 품질과 멀티 쿼리 어텐션의 속도 및 낮은 메모리 사용량이라는 두 가지 장점을 결합한 것입니다. 단일 세트의 K 및 V 벡터 또는 모든 Q 벡터에 대해 하나의 세트 대신 모든 Q 벡터에 대해 고정된 비율의 K 및 V 벡터 1세트가 사용되므로 메모리 사용량은 줄지만, 많은 작업에서 높은 성능을 유지합니다.
성능, 메모리 사용량, 배치 크기, 사용 가능한 하드웨어(또는 클라우드 비용) 간의 절충점을 고려해야 하므로 프로덕션 작업에 적합한 모델을 선택하는 것은 단순히 가장 좋은 모델을 고르는 것이 아닌 경우가 많습니다. 이 세 가지 어텐션 스타일을 이해하면 이러한 결정을 내리고 상황에 따라 특정 모델을 선택할 수 있는 시기를 이해하는 데 도움이 됩니다.
Mistral 시작하기 - 지금 바로 체험해 보세요
그룹화된 쿼리 어텐션을 활용하고 이를 슬라이딩 윈도우 어텐션과 결합한 최초의 대규모 언어 모델 중 하나인 Mistral은 대기 시간이 짧고 처리량이 높으며 더 큰 모델(13B)과 비교해도 벤치마크에서 매우 우수한 성능을 보이는 등 골디락스 영역에 도달한 것으로 보입니다. 앞서 언급한 모든 것은 Mistral이 크기에 비해 강력한 기능을 갖추고 있다는 것을 이야기하고자 한 것이며, Workers AI를 통해 모든 개발자가 사용할 수 있게 되어 매우 기쁩니다.
개발자 문서로 이동하여 시작하고, 도움이 필요하거나 피드백을 제공하고 싶거나 개발 중인 내용을 공유하고 싶으면 Cloudflare의 개발자 Discord로 이동하세요!
Workers AI 팀에서도 확장 중이고 채용 중입니다. AI 엔지니어링에 열정이 있고 글로벌 서버리스 GPU 기반 추론 플랫폼의 구축과 발전을 돕고 싶은 분은 채용 페이지에서 채용 중인 직책을 확인해 보시기 바랍니다.