


D1은 현재 오픈 베타 버전으로, 그 테마는 "확장"입니다. 데이터베이스당 스토리지 한도를 높이고더 많은 데이터베이스를 생성할 수 있는 기능을 통해 Cloudflare에서는 개발자가 D1에서 프로덕션 규모의 앱을 구축할 수 있도록 지원합니다. 기존 유료 Workers 요금제를 사용 중인 개발자라면 누구나 혜택을 누릴 수 있습니다. 기존의 모든 D1 데이터베이스에 소급 적용되었기 때문입니다.
지난번 Developer Week의 D1 업데이트, 변경 로그의 수많은 업데이트를 놓치셨거나 D1을 처음 접하는 분이라면 계속 읽어보세요.
상기시켜 주세요. D1? 데이터베이스?
D1은 작년 11월 알파 버전으로 출시된 네이티브 서버리스 데이터베이스입니다. 쿼리 가능한 이 데이터베이스는 Workers KV, Durable Objects, R2를 보완합니다.
D1을 구축하기 시작했을 때, 우리는 몇 가지 확실한 사실을 알고 있었습니다. 속도가 빨라야 하고, 데이터베이스를 매우 쉽게 생성할 수 있어야 하며, SQL 기반이어야 한다는 것이었습니다.
마지막 항목이 중요했습니다. SQL 기반이어야만 개발자가 a) 또 다른 사용자 정의 쿼리 언어를 배우는 것을 피하고 b) 기존 쿼리 빌딩, ORM(개체 관계형 매퍼) 라이브러리 및 기타 도구가 최소한의 노력으로 D1에 쉽게 연결될 수 있도록 할 수 있으니까요. 그 결과, Drizzle ORM, Kysely의 D1 지원부터, D1을 데이터베이스로 사용하는 전체 스택 툴킷인 T4 앱에 이르기까지 수많은 프로젝트에서 D1에 대한 지원을 구축하는 것을 볼 수 있었습니다.
우리는 또한 D1이 Workers에서 데이터베이스를 쿼리하는 유일한 방법이 될 수 없다는 것을 알고 있었습니다. 기존 데이터베이스가 있고 수천 줄의 SQL 또는 기존 ORM 코드가 있는 팀의 경우, D1으로 마이그레이션하는 것이 하루 아침에 끝날 일이 아니기 때문입니다. 이러한 팀을 위해 Cloudflare에서는 기존 데이터베이스에 연결하여 글로벌한 느낌을 줄 수 있는 Hyperdrive를 구축했습니다. 우리는 이에 따라 팀에 유연성이 제공된다고 생각합니다. 전 세계적으로 분산된 앱을 위해 D1과 Workers를 결합하고 Hyperdrive를 사용하여 레거시 클라우드에 있는 데이터베이스를 쿼리하고 하룻밤 사이에 제거할 수는 없습니다.
더 큰 데이터베이스, 더 많은 데이터베이스
이는 알파 테스트 기간 동안 수천 명의 D1 사용자들이 가장 많이 요구한 사항으로, 더 많은 데이터베이스뿐만 아니라 더 큰 데이터베이스를제공해 달라는 것이었습니다.
이제 Workers 유료 요금제를 이용하는 개발자는 각 데이터베이스를 (500MB 및 10개에서 더 늘려) 최대 2GB까지 확장하고 50,000개의 데이터베이스를 생성할 수 있습니다. 그렇습니다. 제대로 읽으셨습니다. 계정당 50,000개의 데이터베이스입니다. 이를 통해 사용자별 데이터베이스 사용 사례의 폭을 넓히고 기존의 관계형 데이터베이스 배포에서는 불가능했던 고객 간의 진정한 격리를 실현할 수 있습니다.
앞으로 몇 주, 몇 달에 걸쳐 더 큰 데이터베이스를 활용하는 작업을 계속할 예정이며, D1 베타를 사용하는 개발자는 D1의 공개 변경 로그에 이러한 한도가 자동으로 증가하는 것을 확인할 수 있습니다.
두 자릿수 기가바이트 데이터베이스의 가장 큰 장애물 중 하나는 성능입니다. 데이터베이스를 정말 빠르게 로드하고 준비할 수 있어야 하는데, 몇 초(또는 그 이상)의 콜드 스타트 시간은 용납할 수 없습니다. 쿼리에 응답하기까지 15초가 걸리는 10GB 또는 20GB 용량의 데이터베이스는 결국 사용하기에 상당히 불편합니다.
Workers 무료 요금제 이용자는 10개의 500MB 데이터베이스(변경 로그)를 영원히 보유하게 됩니다. 우리는 더 많은 개발자가 합류하기 전에 D1과 Workers를 실험해 볼 여지를 제공하고자 합니다.
Time Travel이 출시되었습니다
Time Travel을 사용하면 데이터베이스를 특정 시점, 즉 지난 30일 중 어느 시점으로든 롤백시킬 수있습니다. 이 기능은 모든 D1 데이터베이스에 기본적으로 활성화되어 있으며, 추가 비용이 들지 않고 스토리지 한도에 포함되지도 않습니다.
Time Travel은 올해 초에 처음 발표되었고, 7월에 모든 D1 사용자가 사용할 수 있게 되었습니다. 그 핵심은 놀라울 정도로 간단합니다. Time Travel은 D1에 "북마크"라는 개념을 채택한 것입니다. 북마크는 특정 시점의 데이터베이스 상태를 나타내며, 사실상 추가 전용 로그입니다. Time Travel은 타임스탬프를 가져와 북마크로 만들거나 직접 북마크로 만들어 해당 시점으로 복원시킬 수 있습니다. 더 좋은 점은 복원해도 더 뒤로 돌아갈 수 있다는 점입니다.
Time Travel은 예제를 통해 가장 잘 설명할 수 있으므로 전자 상거래 스토어에 대한 모든 주문을 저장하는 주문표가 있는 데이터베이스로 변경해 보겠습니다.
# 예를 들어, 주문 데이터베이스에는 89,185개의 고유 주소가 있습니다.
➜ wrangler d1 execute northwind --command "SELECT count(distinct ShipAddress) FROM [Order]"
┌──────────┐
│ count(*) │
├──────────┤
│ 89185 │
└──────────┘
자, 좋습니다. 이제 주소 변경이나 운송 회사 변경과 같은 특정 주문 집합을 변경하려면 어떻게 해야 할까요?
# 제 생각엔 여기서 뭔가 잊고 있는 것 같은데...
➜ wrangler d1 execute northwind --command "UPDATE [Order] SET ShipAddress = 'Av. Veracruz 38, Roma Nte., Cuauhtémoc, 06700 Ciudad de México, CDMX, Mexico'
잠깐만요. 이전에 많은 사람이 했던 실수를 저질렀네요. 업데이트 쿼리에서 WHERE 절을 잊어버렸습니다. 특정 주문 ID를 업데이트하는 대신 테이블의 모든 주문에 대해 ShipAddress를 업데이트했습니다.
# 이제 모든 주문이 멕시코 시티의 와인 바에 전달됩니다.
➜ wrangler d1 execute northwind --command "SELECT count(distinct ShipAddress) FROM [Order]"
┌──────────┐
│ count(*) │
├──────────┤
│ 1 │
└──────────┘
패닉이 시작됩니다. 이 작업을 수행하기 전에 백업하는 것을 기억했나요? 얼마나 오래 전이었나요? 특정 시점 복구를 설정했나요? 당시에는 비용이 많이 들 것 같았는데...
괜찮습니다. D1을 사용하고 있습니다. Time Travel을 할 수 있습니다. 기본적으로 켜져 있습니다. 이 문제를 해결하고 몇 분 전으로 돌아가 보겠습니다.
# 시간을 거슬러 올라가 보겠습니다.
➜ wrangler d1 time-travel restore northwind --timestamp="2023-09-23T14:20:00Z"
🚧 Restoring database northwind from bookmark 0000000b-00000002-00004ca7-9f3dba64bda132e1c1706a4b9d44c3c9
✔ OK to proceed (y/N) … yes
⚡️ Time travel in progress...
✅ Database dash-db restored back to bookmark 00000000-00000004-00004ca7-97a8857d35583887de16219c766c0785
↩️ 이 작업의 실행을 취소하려면 이전 북마크로 복원하면 됩니다. 00000013-ffffffff-00004ca7-90b029f26ab5bd88843c55c87b26f497
잘 작동했는지 확인해 보겠습니다.
#휴. 괜찮군요.
➜ wrangler d1 execute northwind --command "SELECT count(distinct ShipAddress) FROM [Order]"
┌──────────┐
│ count(*) │
├──────────┤
│ 89185 │
└──────────┘
우리는 더 작은 데이터베이스가 많을 때 Time Travel이 더욱 강력해진다고 생각합니다. 모든 복원 작업의 단점이 더 줄어들고 범위가 단일 사용자 또는 테넌트로 제한됩니다.
Cloudflare에서는 데이터베이스 복원뿐만 아니라 기존 데이터베이스에서 분기하고 덮어쓰는 기능도 지원하기 위해 노력 중이니 Time Travel은 이제 시작에 불과합니다. 단일 명령으로 데이터베이스를 분기시키거나 실제 데이터에 대해 마이그레이션 및 스키마 변경을 테스트할 수 있다면, 데이터베이스 작업을 하면서 기존에 수반되었던 많은 어려움을 해소할 수 있습니다.
행 기반 가격 책정
지난 5월, 우리는 Free 및 유료 요금제에 포함된 사항에 대한 많은 긍정적인 피드백에 힘입어 D1의 가격 책정을 발표했습니다. 8월에는 사용량을 더 쉽게 예측하고 정량화할 수 있도록 기존의 바이트 단위를 대체하는 새로운 행 기반 모델을 발표했습니다. 특히, 행을 작성하는 경우 1KB든 1MB든 상관없다는 추론을 기반으로 더 쉬워진 행 단위로 전환했습니다. 읽기 쿼리에서 인덱싱된 열을 사용하여 필터링하는 경우 성능 향상뿐 아니라 비용 절감 효과도 볼 수 있습니다.
D1의 가격은 거의 모든 항목이 동일하게 유지되며, 행을 기준으로 과금한다는 혜택이 추가되었습니다.
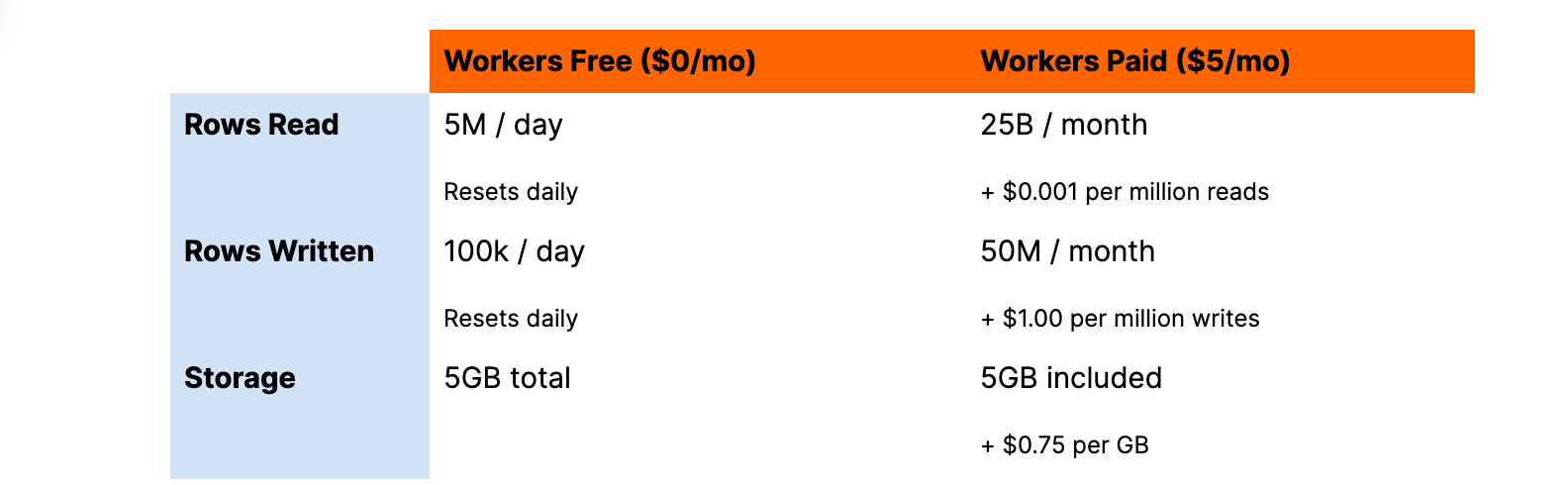
이전과 마찬가지로 D1은 '데이터베이스 시간', 데이터베이스 수, 특정 시점 복구(Time Travel)에 대해 요금을 부과하지 않으며, D1에 쿼리하고 읽기, 쓰기, 스토리지에 대한 비용만 지불하면 끝입니다.
D1을 사용하면 비용 효율성이 훨씬 높아질 뿐만 아니라 여러 데이터베이스를 관리하여 고객 데이터 또는 프로덕션과 스테이징을 분리할 수 있으므로 어떤 데이터베이스를 쿼리하든 상관없습니다. 원하는 방식으로 데이터를 관리하고, 고객 데이터를 분리하며, 직관적이지 않거나 팀에 합리적이지 않더라도 과금 방식만을 중심으로 구축하는 '청구 기반 아키텍처'의 함정에 빠지지 마세요.
특정 쿼리의 비용 및 인덱스로 쿼리를 최적화할 시기를 더 쉽게 확인할 수 있도록 D1은 쿼리에서 읽거나 쓴 행 수(또는 둘 다)도 반환하므로 비용과 속도 측면에서 비용이 어떻게 발생하는지 이해할 수 있습니다.
예를 들어 다음 쿼리에서는 날짜를 기준으로 주문이 필터링됩니다.
SELECT * FROM [Order] WHERE ShippedDate > '2016-01-22'"
[
{
"results": [],
"success": true,
"meta": {
"duration": 5.032,
"size_after": 33067008,
"rows_read": 16818,
"rows_written": 0
}
}
]
위의 색인되지 않은 쿼리는 16,800개의 행을 스캔합니다. 최적화를 하지 않더라도 D1에는 매월 250억 개의 쿼리가 무료로 포함되므로, 이 쿼리를 한 달 동안 140만 번 실행해도 추가 비용에 대해 걱정할 필요가 없습니다.
하지만 인덱스를 사용하면 더 나은 결과를 얻을 수 있습니다.
CREATE INDEX IF NOT EXISTS idx_orders_date ON [Order](ShippedDate)
인덱스가 생성되었으므로 이제 쿼리에서 얼마나 많은 행을 읽어야 하는지 확인해 보겠습니다.
SELECT * FROM [Order] WHERE ShippedDate > '2016-01-22'"
[
{
"results": [],
"success": true,
"meta": {
"duration": 3.793,
"size_after": 33067008,
"rows_read": 417,
"rows_written": 0
}
}
]
ShippedDate 열에 인덱스가 있는 동일한 쿼리에서는 417행만 읽습니다. 이 쿼리는 더 빠를 뿐만 아니라(소요 시간은 밀리초 단위!) 비용도 저렴합니다. 이 쿼리를 한 달에 5,900만 번 실행해도 Workers 요금제에서 제공하는 $5보다 더 많은 비용을 지불할 필요가 없습니다.
또한 D1은 Cloudflare 대시보드와 GraphQL 분석 API 모두를 통해행 수가 노출되므로 성능을 조정할 때 쿼리별로 확인할 수 있을 뿐만 아니라 모든 데이터베이스의 쿼리 패턴을 분석할 수도 있습니다.
플랫폼용 D1
D1의 알파 테스트 기간 동안 우리는 D1’의 수평적 확장 기능에 대해 기대하는 여러 팀의 의견을 들으며 함께 작업해왔습니다. 이 기능을 사용하면 고객(또는 사용자!)별로 데이터베이스를 배포하여 팀에서 데이터에 액세스하는 위치에 데이터를 더 가깝게 유지하고 아울러 다른 사용자로부터 데이터를 더 강력하게 격리할 수 있습니다.
Workers for Platforms에서 차세대 혁신을 구축하는 팀("서비스형 기능"이라고 생각하세요)에서는 D1을 사용하여 사용자별로 데이터베이스를 배포해서 고객 데이터를 서로 강력하게 분리할 수 있습니다.
예를 들어, D1의 얼리 어답터 중 하나인 RONIN은 고객당 전용 D1 데이터베이스로 뒷받침되는 에지 우선 콘텐츠 및 데이터 플랫폼을 구축하여 데이터를 사용자에게 더 가깝게 배치하고 각 고객을 다른 고객의 쿼리로부터 격리할 수 있도록 하고 있습니다.
수많은 기존 데이터베이스 인스턴스를 스핀업하고 관리하는 대신, RONIN은 D1 for Platforms를 사용해 에지에서 자동 무한 확장성을 제공합니다. 이를 통해 RONIN은 콘텐츠에 직관적인 편집 환경을 제공하는 데 집중할 수 있습니다.
"D1 for Platforms"를 활성화하기 위해 우리는 처음부터 몇 가지 측면에서 숙고했습니다.
- D1에서 이미 계정당 50,000개의 데이터베이스를 지원하는 것 외에, Workers for Platforms 사용자를 위한 100,000여 개의 데이터베이스 지원(제한은 없지만 "무제한"이라고 하면 믿지 못할 수도 있습니다).
- D1의 요금제. 데이터베이스당 또는 "유휴 데이터베이스"에 대해 비용을 지불하지 않습니다. 사용자 수가 10분마다 수천 QPS(초당 조회수)에서 1~2명에 이르기까지 다양한 경우, 트래픽이 적은 데이터베이스의 "데이터베이스 시간"에 대해 더 많은 비용을 지불하거나 사용자 기반 전반에서 급증하는 워크로드에 대한 계획을 세우지 않아도 됩니다.
- D1의 HTTP API를 통해 더 많은 데이터베이스를 프로그래밍 방식으로 구성하고, 다시 배포하지 않고도 Worker에 연결할 수 있는 기능. "프로비저닝" 지연도 없습니다. 데이터베이스를 생성하는 즉시 귀사나 귀사의 사용자가 쿼리할 수 있습니다.
- 상세한 데이터베이스별 분석. 따라서 어떤 데이터베이스가 사용되고 있는지, 어떤 방식으로 쿼리되는지 D1의 GraphQL 분석 API를 통해 파악할 수 있습니다.
Workers를 기반으로 차세대 대형 플랫폼을 구축 중이고 D1을 대규모로 사용하고 싶다면 Workers Launchpad 프로그램에 참여하고 있는지 여부와 관계없이 문의해 주세요.
D1의 다음 계획은 무엇일까요?
내년 초(2024년 1분기)까지 프로덕션 사용 사례에 D1을 "일반 사용 가능(GA)"하도록 하겠다는 명확한 목표를 세우고 있습니다. 대기자 명단이나 승인 절차 없이 이미 D1을 사용할 수 있지만, 데이터베이스와 관련하여 많은 사람에게 GA 레이블 지정이 중요하다는 것을 잘 알고 있습니다(우리도 마찬가지입니다).
지금부터 GA까지, Cloudflare에서는 안정성과 성능에 지속해서 중점을 두면서 D1 비전의 핵심적인 부분을 개선하겠습니다.
이 비전의 가장 큰 남은 부분 중 하나는 올해 초에 소개한글로벌 읽기 복제입니다. 중요한 것은 복제가 무료이고, 스토리지 사용량을 늘리지 않으며, 세션 일관성(작성 내용 읽기)을 유지할 수 있다는 점입니다. D1의 사명 중 하나는 데이터를 사용자가 있는 곳에 더 가깝게 가져오는 것이며, 이를 실현하게 되어 매우 기쁩니다.
또한 특정 시점의 데이터베이스를 즉시 분기 및/또는 복제할 수 있도록 D1에 내장된 시점 복구 기능인 Time Travel을 확대하는 작업도 진행 중입니다.
또한 올해 남은 기간 동안 데이터베이스별 스토리지 제한을 점진적으로 개방하여 계정당 스토리지와 생성할 수 있는 데이터베이스 수를 늘릴 예정이므로, D1 변경 로그(또는 받은 편지함)를 계속 주시해 주시기 바랍니다.
아직 D1을 사용해 보지 않으셨다면 지금 바로 시작하시거나, D1의 개발자 문서를방문하여 아이디어를 얻거나, Cloudflare Developer Discord의 #d1-beta 채널에 참여하여 다른 D1 개발자 및 당사의 제품 엔지니어링 팀과 이야기를 나눌 수 있습니다.