


소개
2022년 6월 21일 오늘 Cloudflare 가동이 중단되어 데이터 센터 19곳의 트래픽에 영향을 미쳤습니다. 안타깝게도 이 19곳은 Cloudflare에서 가장 큰 데이터 센터이며 전 세계 트래픽의 상당 부분을 처리합니다. 해당 대규모 데이터 센터는 Cloudflare 인프라의 핵심 요소이며 Cloudflare 트래픽의 상당 부분을 처리하므로, 복원력을 높이기 위해 장기 프로젝트를 진행하는 과정에서 변경을 수행하다가 가동 중단이 발생하게 되었습니다. 이러한 데이터 센터에서 네트워크 구성을 변경하면서 6시 27분(UTC)부터 중단이 발생했습니다. 6시 58분(UTC)에 첫 번째 데이터 센터가 다시 온라인 상태가 되었고 7시 42분(UTC)에는 모든 데이터 센터가 온라인 상태로 돌아와 올바르게 작동했습니다.
전 세계 사용자의 위치에 따라 Cloudflare를 이용하는 웹 사이트 및 서비스에 액세스하지 못했을 수 있습니다.다른 곳에서는 Cloudflare가 계속 정상적으로 작동했습니다.
가동 중단이 발생하게 되어 정말 죄송합니다. 이는 Cloudflare 측의 오류이며 공격이나 악의적 활동으로 발생하지 않았습니다.
배경
지난 18개월 동안 Cloudflare는 가장 규모가 큰 데이터 센터들의 아키텍처를 더 확실히 이중화하기 위해 노력해 왔습니다. 이번에는 내부적으로 MCP(Multi-Colo PoP)라고 부르는 이 아키텍처를 암스테르담, 애틀랜타, 애쉬번, 시카고, 프랑크푸르트, 런던, 로스앤젤레스, 마드리드, 맨체스터, 마이애미, 밀라노, 뭄바이, 뉴어크, 오사카, 상파울루, 새너제이, 싱가포르, 시드니, 도쿄까지 총 19곳의 데이터 센터에 적용했습니다.
Clos 네트워크로 설계된 이 새로운 아키텍처의 핵심 요소는 연결 메시를 생성하도록 추가된 라우팅 계층입니다. 이 메시를 사용하면 유지 관리를 수행하거나 문제를 처리하기 위해 데이터 센터의 내부 네트워크의 일부를 쉽게 비활성화하고 활성화할 수 있습니다. 이 계층은 다음 다이어그램에서 스파인으로 표현되어 있습니다.
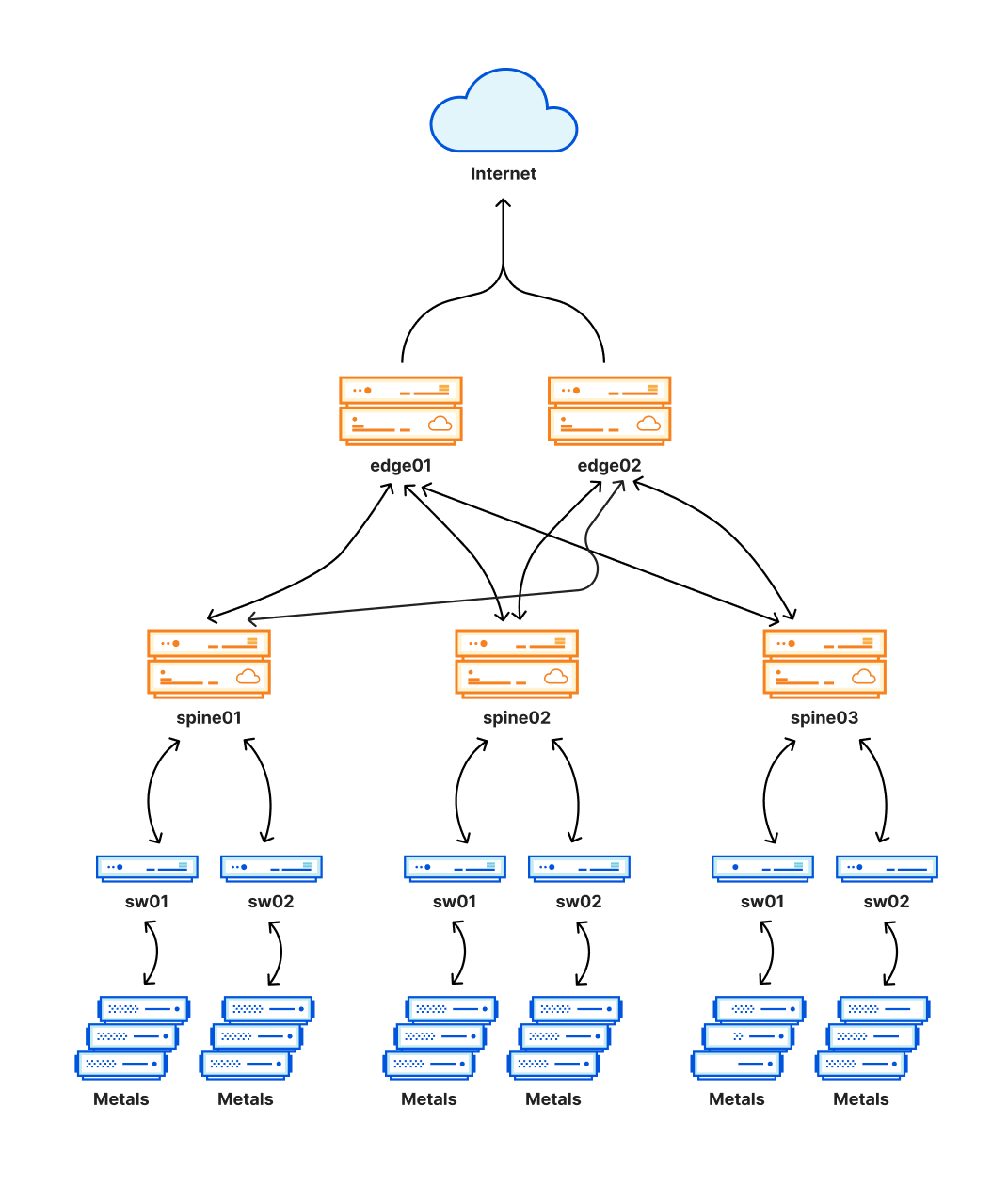
이 새로운 아키텍처는 안정성을 크게 높일 뿐만 아니라, 데이터 센터에서 고객 트래픽을 방해하지 않고도 유지 관리를 실행할 수 있게 해줍니다. 이와 같은 데이터 센터는 Cloudflare 트래픽의 상당 부분을 처리하기 때문에 이곳에서 문제가 발생한다면 어떤 문제든 매우 광범위하게 영향을 미칠 수 있습니다. 이로 인해 오늘 중단이 발생하게 되었습니다.
사고 타임라인(UTC) 및 영향
Cloudflare와 같은 네트워크는 인터넷으로 연결할 수 있도록 BGP라는 프로토콜을 사용합니다. 이 프로토콜의 일환으로 운영자는 피어(연결하려는 다른 네트워크)에 알릴 접두사(인접한 IP 주소 모음)나 피어에서 수락하게 될 피어를 결정하는 정책을 정의합니다.
이러한 정책에는 순차적 방식으로 평가하는 개별 구성 요소가 있습니다.주어진 접두사를 알리거나 알리지 않는 것으로 최종 결과가 나타납니다. 정책을 변경하면 이전에 알리던 접두사를 더 이상 알리지 않게 될 수 있습니다. 이 경우 접두사를 철회하며 해당 IP 주소에 인터넷으로 연결할 수 없게 됩니다.
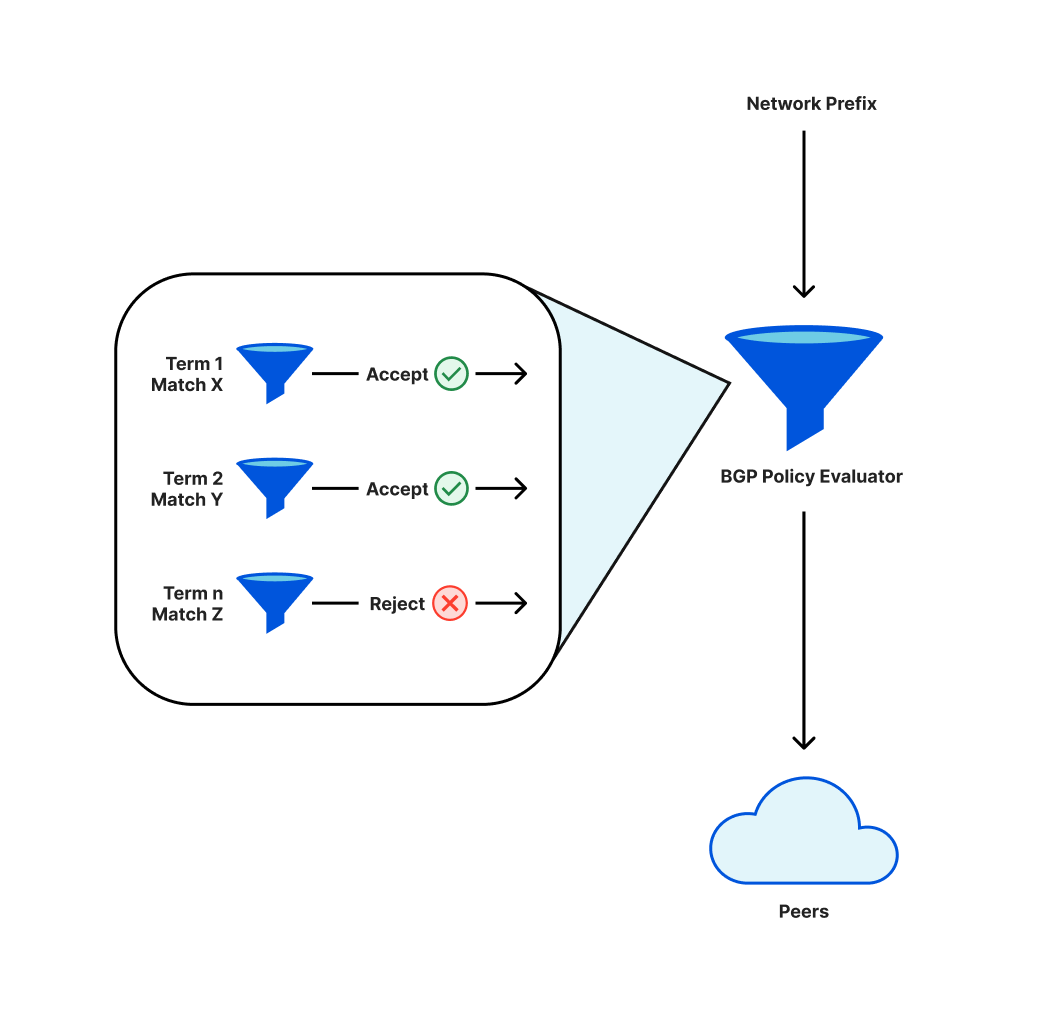
접두사 알림 정책에 대한 변경 사항을 배포하는 동안, 항을 재정렬하면서 접두사의 필수 하위 집합을 철회하게 되었습니다.
이 철회 작업으로 인해 Cloudflare 엔지니어가 영향을 받는 곳에 연결하고 문제가 있는 변경 사항을 되돌리기가 더욱 어려워졌습니다.Cloudflare에는 이러한 이벤트를 처리할 백업 절차가 있으며, 영향을 받는 위치를 제어하는 데 백업 절차를 사용했습니다.
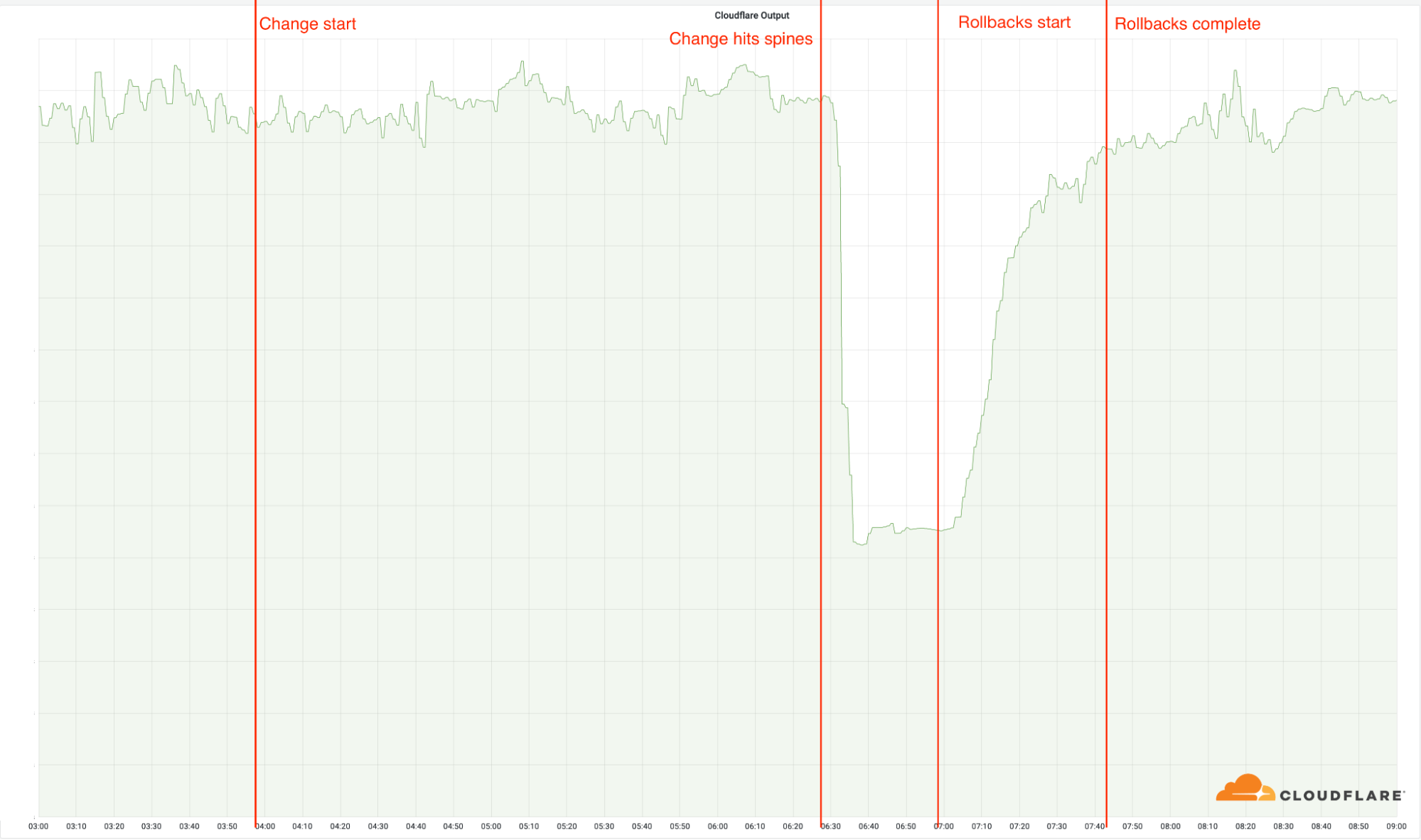
03:56: 첫 번째 데이터 센터 위치에 변경 사항을 배포했습니다. 이전 아키텍처를 사용했으므로 데이터 센터 위치에 변경 사항이 영향을 미치지 않았습니다.
06:17: 대규모 데이터 센터 위치에 변경 사항이 배포되었지만 새 아키텍처가 있는 데이터 센터 위치에는 배포되지 않습니다.
06:27: 새로운 아키텍처를 갖춘 대규모 데이터 센터 위치에 롤아웃이 전달되었으며 스파인에 변경 사항이 배포되었습니다. 이때 데이터 센터 19곳이 빠르게 오프라인 상태가 되면서 사고가 시작되었습니다.
06:32: 내부적 Cloudflare 사고가 선언되었습니다.
06:51: 가능성 있는 근본 원인을 확인하기 위해 라우터에서 첫 번째 변경을 수행했습니다.
06:58: 근본 원인을 찾고 이해했습니다. 문제가 있는 변경 사항을 되돌릴 수 있도록 작업을 재개했습니다.
07:42: 마지막 복구 작업이 완료되었습니다.네트워크 엔지니어가 서로의 변경 사항을 덮어 쓰고 이전의 복구 상태로 되돌려 산발적으로 문제가 다시 발생하면서 마지막 작업이 지연되었습니다.
08:00: 사고가 종료되었습니다.
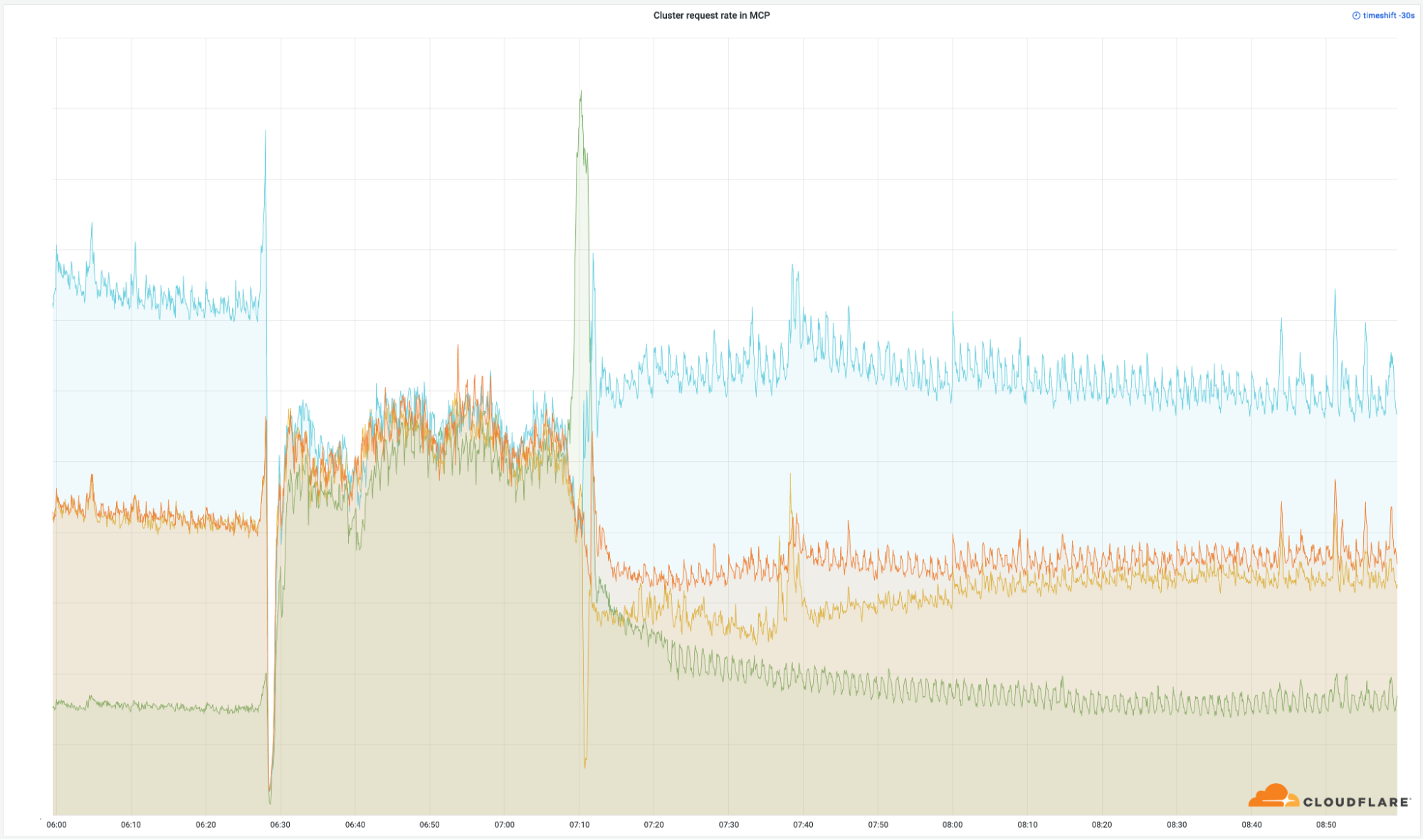
전 세계에 성공적으로 반환한 요청의 양을 보면 이러한 데이터 센터의 중요도를 명확하게 확인할 수 있습니다.
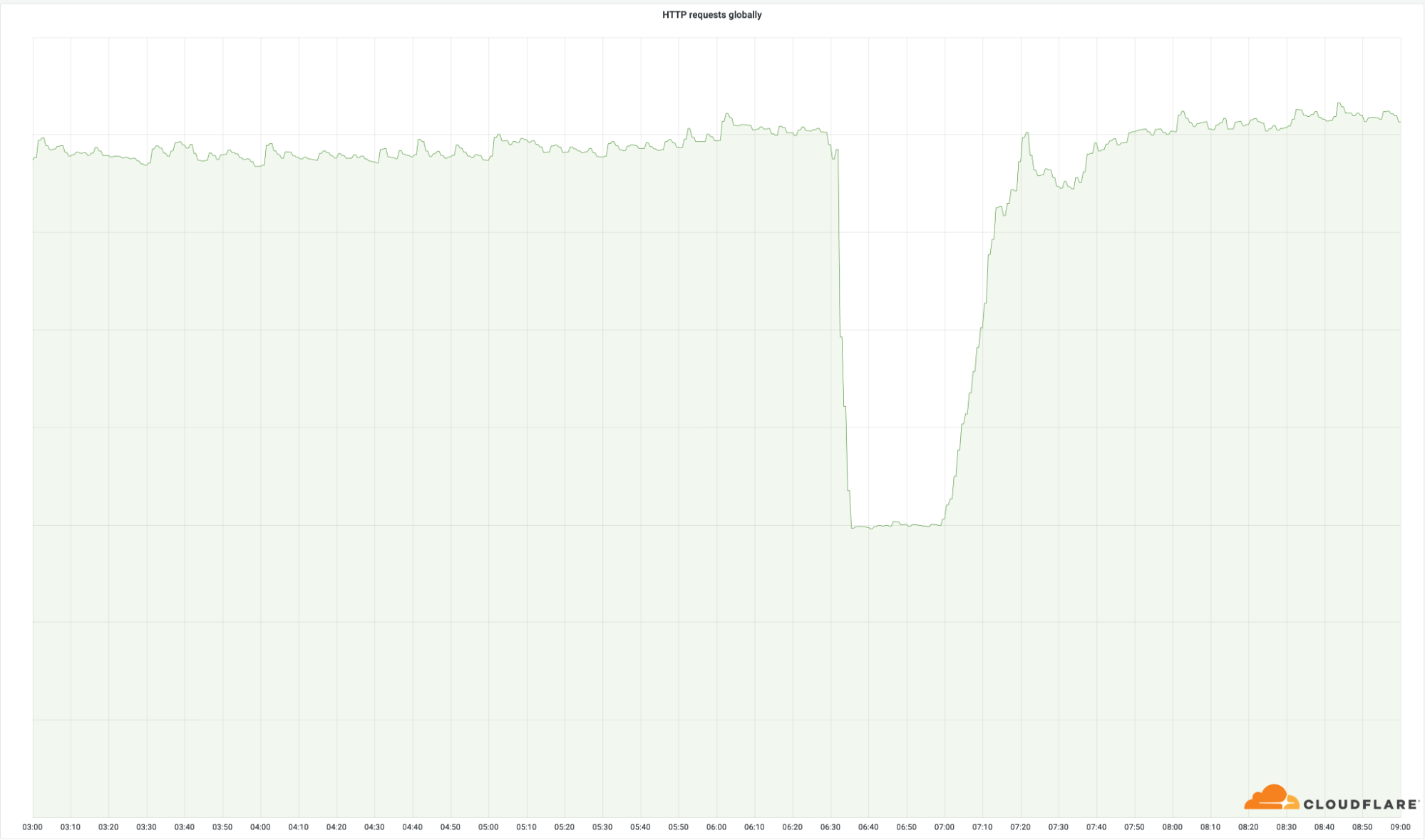
이러한 데이터 센터는 Cloudflare 전체 네트워크에서 작은 비율(4%)만 차지하지만 전체 요청의 50%에 영향을 미쳤습니다.송신 대역폭도 마찬가지입니다.
오류에 대한 기술적 설명 및 발생한 방식
Cloudflare는 인프라 구성을 표준화하기 위한 지속적인 노력의 일환으로, Cloudflare에서 알리는 접두사의 하위 집합에 연결하는 BGP 커뮤니티를 표준화하도록 변경 사항을 배포하는 중이었습니다. 특히 사이트 로컬 접두사에 정보 커뮤니티를 추가하고 있었습니다. 이러한 접두사를 이용해 컴퓨팅 노드가 서로 통신하고 고객 원점에 연결할 수 있습니다. Cloudflare에서 수행한 변경 절차를 진행하면서 변경 요청(CR) 티켓이 생성되었는데, 이 티켓에는 테스트 목적으로 변경 사항을 실행하고 단계적으로 롤아웃하는 절차가 포함됩니다. 이를 적용하기 전에 여러 엔지니어들이 동료 검토까지 마쳤습니다. 이번 사례에서는 안타깝게도 모든 스파인에 전달되기 전에 오류를 포착할 수 있을 만큼 단계가 짧지 않았습니다.
한 라우터에서 수행된 변경 내용은 다음과 같습니다.
[edit policy-options policy-statement 4-COGENT-TRANSIT-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
[edit policy-options policy-statement 4-PUBLIC-PEER-ANYCAST-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
[edit policy-options policy-statement 6-COGENT-TRANSIT-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
[edit policy-options policy-statement 6-PUBLIC-PEER-ANYCAST-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
이는 문제를 일으키지 않았으며 접두사 알림에 추가 정보를 몇 가지 더했을 뿐입니다. 스파인에서 수행된 변경 내용은 다음과 같습니다.
[edit policy-options policy-statement AGGREGATES-OUT]
term 6-DISABLED_PREFIXES { ... }
! term 6-ADV-TRAFFIC-PREDICTOR { ... }
! term 4-ADV-TRAFFIC-PREDICTOR { ... }
! term ADV-FREE { ... }
! term ADV-PRO { ... }
! term ADV-BIZ { ... }
! term ADV-ENT { ... }
! term ADV-DNS { ... }
! term REJECT-THE-REST { ... }
! term 4-ADV-SITE-LOCALS { ... }
! term 6-ADV-SITE-LOCALS { ... }
[edit policy-options policy-statement AGGREGATES-OUT term 4-ADV-SITE-LOCALS then]
community delete NO-EXPORT { ... }
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add AMS07;
+ community add EUROPE;
[edit policy-options policy-statement AGGREGATES-OUT term 6-ADV-SITE-LOCALS then]
community delete NO-EXPORT { ... }
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add AMS07;
+ community add EUROPE;
이 diff를 처음 보면 변경 내용이 같다고 생각할 수도 있겠지만, 안타깝게도 그렇지 않습니다. diff의 한 부분에 초점을 맞춰보면 이유가 명확히 보입니다.
! term REJECT-THE-REST { ... }
! term 4-ADV-SITE-LOCALS { ... }
! term 6-ADV-SITE-LOCALS { ... }
이 diff 형식에서 항 앞에 있는 느낌표는 항 재정렬을 나타냅니다. 이 경우 여러 항이 위로 이동하고 항 두 개가 아래에 추가되었습니다. 특히 4-ADV-SITE-LOCALS 항은 위에서 아래로 이동했습니다.REJECT-THE-REST 항 뒤에 해당 항이 위치하게 되었고, 이름에서 알 수 있듯이 이는 명시적 거부를 나타냅니다.
term REJECT-THE-REST {
then reject;
}
이 항이 사이트 로컬 항 앞에 위치하게 되었으므로, Cloudflare에서는 즉시 사이트 로컬 접두사 알림을 중단하고 영향을 받는 모든 데이터 센터 위치에 직접 액세스를 신속히 제거했으며 서버가 원본에 도달하는 기능을 없앴습니다.
원본에 도달할 수도 없지만, 이러한 사이트 로컬 접두사를 제거하면 내부 로드 밸런싱 시스템인 Multimog(Cloudflare의 Unimog 로드 밸런서 변형 시스템)가 MCP에서 서버 간에 요청을 전달할 수 없게 되기 때문에 작동이 중지됩니다. 즉, MCP의 작은 컴퓨팅 클러스터가 가장 큰 클러스터와 같은 양으로 트래픽을 수신하므로 작은 클러스터에 과부하가 발생하는 것입니다.
복원 및 후속 조치
이 사고는 광범위한 영향을 미쳤으며 Cloudflare는 가용성을 아주 중요하게 생각합니다. 개선 영역을 몇 가지 확인했고, 재발을 초래할 수 있는 또 다른 허점을 찾을 수 있도록 계속 노력할 것입니다.
다음 사항을 즉시 작업하고 있습니다.
프로세스 : MCP 프로그램은 가용성을 높이기 위해 설계되었지만, 데이터 센터 업데이트 방식에서 나타나는 절차상 허점은 결국 MCP 위치에 특히 더 광범위하게 영향을 미쳤습니다. Cloudflare는 이 변경을 수행할 때 스태거 절차를 사용했지만 스태거 정책의 마지막 단계까지 MCP 데이터 센터가 포함되지는 않았습니다. 변경 절차 및 자동화 과정에서는 의도하지 않은 결과가 없도록 MCP별 테스트와 배포 절차를 포함해야 합니다.
아키텍처 : 라우터 구성이 잘못되어 에지에 적절한 경로가 알려지지 않아, 인프라에 트래픽이 제대로 전달되지 못했습니다. 의도치 않게 순서가 잘못 구성되지 않도록 결과적으로 잘못된 라우팅 알림을 초래한 정책 문을 다시 설계할 예정입니다.
자동화 : Cloudflare의 자동화 제품군에는 이 이벤트로 확인된 영향을 일부, 또는 전체적으로 완화할 수 있는 몇 가지 방법이 있습니다. Cloudflare는 자동화 개선에 주로 집중하여, 네트워크 구성 롤아웃 시 개선한 스태거 정책을 시행하고 자동화된 "커밋-확인" 롤백을 이용할 수 있게 하려고 합니다. 첫 번째 개선 사항은 전반적인 영향을 크게 줄일 것이고 두 번째 개선 사항은 사고가 벌어지는 동안 해결 시간을 크게 단축할 것입니다.
결론
Cloudflare는 서비스 가용성을 높이기 위해 MCP 설계에 크게 투자했지만, 규모가 큰 이 사고가 일어나면서 분명히 고객의 기대에 미치지 못했습니다. 가동 중단이 벌어지는 동안 인터넷 자산에 액세스할 수 없었던 고객과 모든 사용자에게 지장을 초래한 것에 대해 깊이 사과드립니다. Cloudflare는 앞서 설명한 변경 작업을 이미 시작했으며, 다시 이런 일이 벌어지지 않도록 끊임없이 노력하겠습니다.