
Cloudflare’s network processes more than fourteen million HTTP requests per second at peak for Internet users around the world. We spend a lot of time thinking about the tools we use to make those requests faster and more secure, but a secret-sauce which makes all of this possible is how we distribute configuration globally. Every time a user makes a change to their DNS, adds a Worker, or makes any of hundreds of other changes to their configuration, we distribute that change to 200 cities in 90 countries where we operate hardware. And we do that within seconds. The system that does this needs to not only be fast, but also impeccably reliable: more than 26 million Internet properties are depending on it. It also has had to scale dramatically as Cloudflare has grown over the past decade.
Historically, we built this system on top of the Kyoto Tycoon (KT) datastore. In the early days, it served us incredibly well. We contributed support for encrypted replication and wrote a foreign data wrapper for PostgreSQL. However, what worked for the first 25 cities was starting to show its age as we passed 100. In the summer of 2015 we decided to write a replacement from scratch. This is the story of how and why we outgrew KT, learned we needed something new, and built what was needed.
How KT Worked at Cloudflare
Where should traffic to example.com be directed to?
What is the current load balancing weight of the second origin of this website?
Which pages of this site should be stored in the cache?
These are all questions which can only be answered with configuration, provided by users and delivered to our machines around the world which serve Internet traffic. We are massively dependent on our ability to get configuration from our API to every machine around the world.
It was not acceptable for us to make Internet requests on demand to load this data however, the data had to live in every edge location. The architecture of the edge which serves requests is designed to be highly failure tolerant. Each data center must be able to successfully serve requests even if cut off from any source of central configuration or control.
Our first large-scale attempt to solve this problem relied on deploying Kyoto-Tycoon (KT) to thousands of machines. Our centralized web services would write values to a set of root nodes which would distribute the values to management nodes living in every data center. Each server would eventually get its own copy of the data from a management node in the data center in which it was located:
Data flow from the API to data centres and individual machines
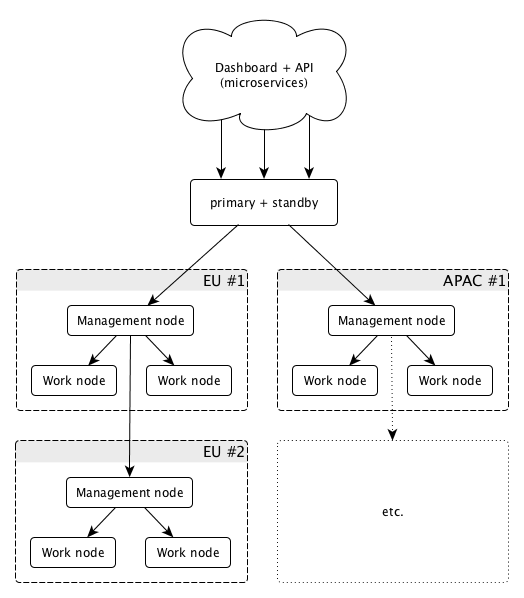
Doing at least one read from KT was on the critical path of virtually every Cloudflare service. Every DNS or HTTP request would send multiple requests to a KT store and each TLS handshake would load certificates from it. If KT was down, many of our services were down, if KT was slow, many of our services were slow. Having a service like KT was something of a superpower for us, making it possible for us to deploy new services and trust that configuration would be fast and reliable. But when it wasn’t, we had very big problems.
As we began to scale one of our first fixes was to shard KT into different instances. For example, we put Page Rules in a different KT than DNS records. In 2015, we used to operate eight such instances storing a total of 100 million key-value (KV) pairs, with about 200 KV values changed per second. Across our infrastructure, we were running tens of thousands of these KT processes. Kyoto Tycoon is, to say the least, very difficult to operate at this scale. It’s clear we pushed it past its limits and for what it was designed for.
To put that in context it’s valuable to look back to the description of KT provided by its creators:
[It] is a lightweight datastore server with auto expiration mechanism, which is useful to handle cache data and persistent data of various applications. (http://fallabs.com/kyototycoon/)
It seemed likely that we were not uncovering design failures of KT, but rather we were simply trying to get it to solve problems it was not designed for. Let’s take a deeper look at the issues we uncovered.
Exclusive write lock… or not?
To talk about the write lock it’s useful to start with another description provided by the KT documentation:
Functions of API are reentrant and available in multi-thread environment. Different database objects can be operated in parallel entirely. For simultaneous operations against the same database object, rwlock (reader-writer lock) is used for exclusion control. That is, while a writing thread is operating an object, other reading threads and writing threads are blocked. However, while a reading thread is operating an object, reading threads are not blocked. Locking granularity depends on data structures. The hash database uses record locking. The B+ tree database uses page locking.
On first glance this sounds great! There is no exclusive write lock over the entire DB. But there are no free lunches; as we scaled we started to detect poor performance when writing and reading from KT at the same time.
In the world of Cloudflare, each KT process replicated from a management node and was receiving from a few writes per second to a thousand writes per second. The same process would serve thousands of read requests per second as well. When heavy write bursts were happening we would notice an increase in the read latency from KT. This was affecting production traffic, resulting in slower responses than we expect of our edge.
Here are the percentiles for read latency of a script reading from KT the same 20 key/value pairs in an infinite loop. Each key and each value is 2 bytes. We never update these key/value pairs so we always get the same value.
Without doing any writes, the read performance is somewhat acceptable even at high percentiles:
- P99: 9ms
- P99.9: 15ms
When we add a writer sequentially adding a 40kB value, however, things get worse. After running the same read performance test, our latency values have skyrocketed:
- P99: 154ms
- P99.9: 250ms
Adding 250ms of latency to a request through Cloudflare would never be acceptable. It gets even worse when we add a second writer, suddenly our latency at the 99.9th percentile (the 0.1% slowest reads) is over a second!
- P99: 701ms
- P99.9: 1215ms

These numbers are concerning: writing more increases the read latency significantly. Given how many sites change their Cloudflare configuration every second, it was impossible for us to imagine a world where write loads would not be high. We had to track down the source of this poor performance. There must be either resource contention or some form of write locking, but where?
The Lock Hunt
After looking into the code the issue seems to be that when reading from KT, the function accept in the file kcplandb.h of Kyoto Cabinet acquires a lock:
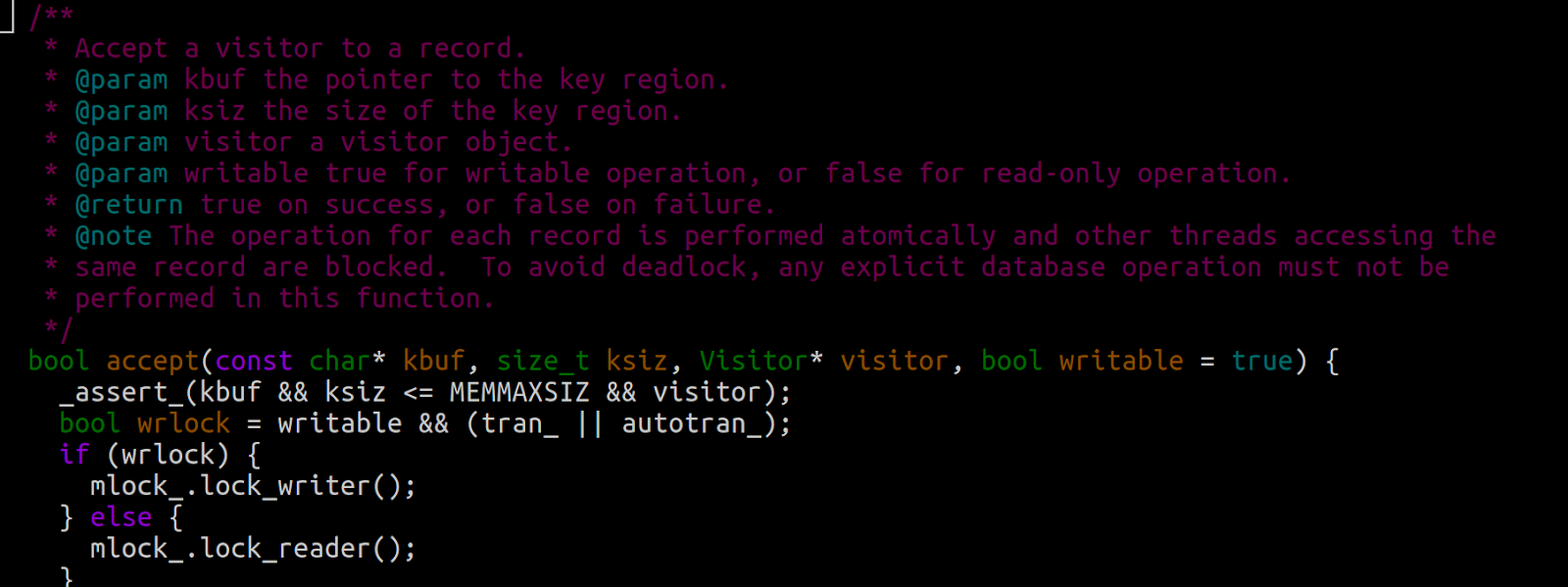
This lock is also acquired in the synchronize function of kcfile.cc in charge of flushing data to disk:

This is where we have a problem. Flushing to disk blocks all reads and flushing is slow.
So in theory the storage engine can handle parallel requests but in reality we found at least one place where this is not true. Based on this and other experiments and code review we came to the conclusion that KT was simply not designed for concurrent access. Due to the exclusive write lock implementation of KT, I/O writes degraded read latency to unacceptable levels.
In the beginning, the occurrence of that issue was rare and not a top priority. But as our customer base grew at rocket speed, all related datasets grew at the same pace. The number of writes per day was increasing constantly and this contention started to have an unacceptable impact on performance.
As you can imagine our immediate fix was to do less writes. We were able to make small-scale changes to writing services to reduce their load, but this was quickly eclipsed by the growth of the company and the launch of new products. Before we knew it, our write levels were right back to where they began!
As a final step we disabled the fsync which KT was doing on each write. This meant KT would only flush to disk on shutdown, introducing potential data corruption which required its own tooling to detect and repair.
Unsynchronized Swimming
Continuing our theme of beginning with the KT documentation, it’s worth looking at how they discuss non-durable writes:
If an application process which opened a database terminated without closing the database, it involves risks that some records may be missing and the database may be broken. By default, durability is settled when the database is closed properly and it is not settled for each updating operation.
At Cloudflare scale, kernel panics or even processor bugs happen and unexpectedly stop services. By turning off syncing to improve performance we began to experience database corruption. KT comes with a mechanism to repair a broken DB which we used successfully at first. Sadly, on our largest databases, the rebuilding process took a very long time and in many cases would not complete at all. This created a massive operational problem for our SRE team.
Ultimately we turned off the auto-repair mechanism so KT would not start if the DB was broken and each time we lost a database we copied it from a healthy node. This syncing was being done manually by our SRE team. That team’s time is much better spent building systems and investigating problems; the manual work couldn’t continue.
Not syncing to disk caused another issue: KT had to flush the entire DB when it was being shut down. Again, this worked fine at the beginning, but with the DB getting bigger and bigger, the shut down time started to sometimes hit the systemd grace period and KT was terminated with a SIGKILL. This led to even more database corruption.
Because all of the KT DB instances were growing at the same pace, this issue went from minor to critical seemingly overnight. SREs wasted hours syncing DBs from healthy instances before we understood the problem and greatly increased the grace period provided by systemd.
We also experienced numerous random instances of database corruption. Too often KT was shut down cleanly without any error but when restarted the DB was corrupted and had to be restored. In the beginning, with 25 data centers, it happened rarely. Over the years we added thousands of new servers to Cloudflare infrastructure and it was occurring multiple times a day.
Writing More
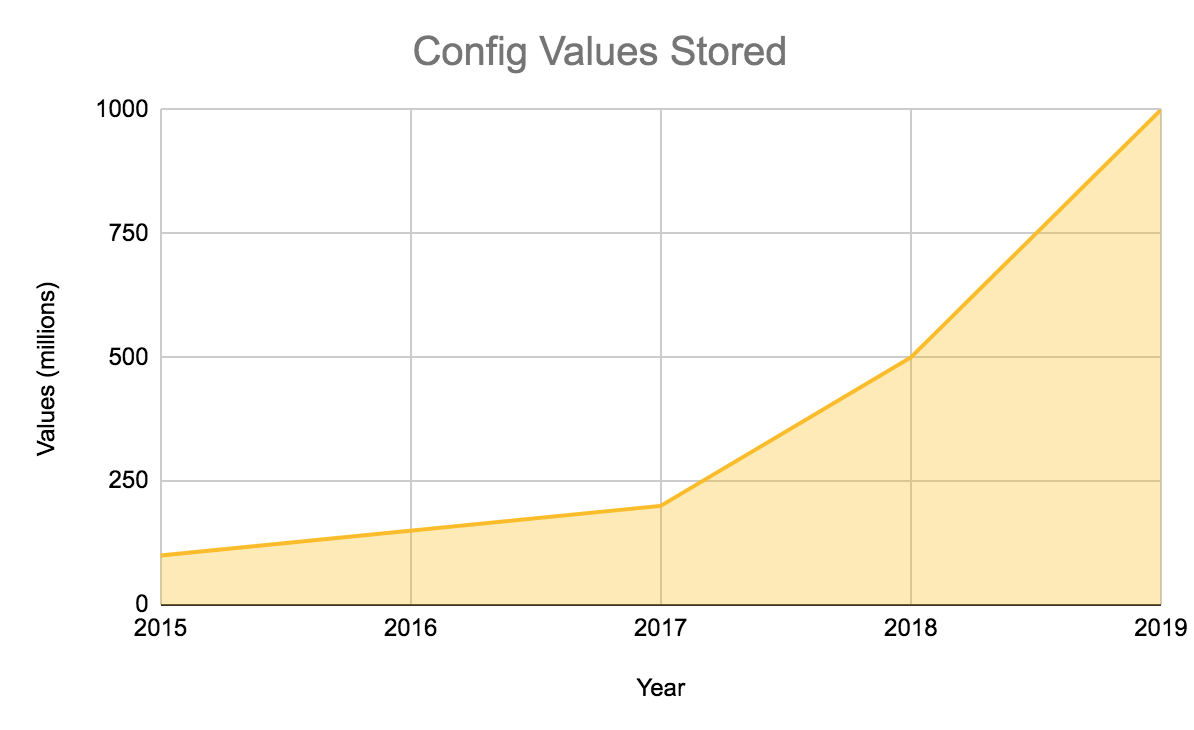
Most of our writes are adding new KV pairs, not overwriting or deleting. We can see this in our key count growth:
- In 2015, we had around 100 million KV pairs
- In 2017, we passed 200 million
- In 2018, we passed 500 million
- In 2019, we exceeded 1 billion
Unfortunately in a world where the quantity of data is always growing, it’s not realistic to think you will never flush to disk. As we write new keys the page cache quickly fills. When it’s full, it is flushed to disk. I/O saturation was leading to the very same contention problems we experienced previously.
Each time KT received a heavy write burst, we could see the read latency from KT increasing in our DC. At that point it was obvious to us that the KT DB locking implementation could no longer do the job for us with or without syncing. Storage wasn’t our only problem however, the other key function of KT and our configuration system is replication.
The Best Effort Replication Protocol
KT replication protocol is based solely on timestamp. If a transaction fails to replicate for any reason but it is not detected, the timestamp will continue to advance forever missing that entry.
How can we have missing log entries? KT replicates data by sending an ordered list of transaction logs. Each log entry details what change is being made to our configuration database. These logs are kept for a period of time, but are eventually ‘garbage collected’, with old entries removed.
Let’s think about a KT instance being down for days, it then restarts and asks for the transaction log from the last one it got. The management node receiving the request will send the nearest entries to this timestamp, but there could be missing transaction logs due to garbage collection. The client would not get all the updates it should and this is how we quietly end up with an inconsistent DB.
Another weakness we noticed happens when the timestamp file is being written. Here is a snippet of the file ktserver.cc where the client replication code is implemented:

This code snippet runs the loop as long as replication is working fine. The timestamp file is only going to be written when the loop terminates. The call to write_rts (the function writing to disk the last applied transaction log) can be seen at the bottom of the screenshot.
If KT terminates unexpectedly in the middle of that loop, the timestamp file won’t be updated. When this KT restarts and if it successfully repairs the database it will replicate from the last value written to the rts file. KT could end up replaying days of transaction logs which were already applied to the DB and values written days ago could be made visible again to our services for some time before everything gets back up to date!
We also regularly experienced databases getting out of sync without any reason. Sometimes these caught up by themselves, sometimes they didn’t. We have never been able to properly identify the root cause of that issue. Distributed systems are hard, and distributed databases are brutal. They require extensive observability tooling to deploy properly which didn’t exist for KT.
Upgrading Kyoto Tycoon in Production
Multiple processes cannot access one database file at the same time. A database file is locked by reader-writer lock while a process is connected to it.
We release hundreds of software updates a day across our many engineering teams. However, we only very rarely deploy large-scale updates and upgrades to the underlying infrastructure which runs our code. This frequency has increased over time, but in 2015 we would do a “CDN Release” once per quarter.
To perform a CDN Release we reroute traffic from specific servers and take the time to fully upgrade the software running on those machines all the way down to the kernel. As this was only done once per quarter, it could take several months for an upgrade to a service like KT to make it to every machine.
Most Cloudflare services now implement a zero downtime upgrade mechanism where we can upgrade the service without dropping production traffic. With this we can release a new version of our web or DNS servers outside of a CDN release window, which allows our engineering teams to move much faster. Many of our services are now actually implemented with Cloudflare Workers which can be deployed even faster (using KT’s replacement!).
Unfortunately this was not the case in 2015 when KT was being scaled. Problematically, KT does not allow multiple processes to concurrently access the same database file so starting a new process while the previous one was still running was impossible. One idea was that we could stop KT, hold all incoming requests and start a new one. Unfortunately stopping KT would usually take over 15 minutes with no guarantee regarding the DB status.
Because stopping KT is very slow and only one KT process can access the DB, it was not possible to upgrade KT outside of a CDN release, locking us into that aging process.
High-ish Availability
One final quote from the KT documentation:
Kyoto Tycoon supports "dual main" replication topology which realizes higher availability. It means that two servers replicate each other so that you don't have to restart the survivor when one of them crashed.
[...]
Note that updating both of the servers at the same time might cause inconsistency of their databases. That is, you should use one main as a "active main" and the other as a "standby main".
Said in other words: When dual main is enabled all writes should always go to the same root node and a switch should be performed manually to promote the standby main when the root node dies.
Unfortunately that violates our principles of high availability. With no capability for automatic zero-downtime failover it wasn’t possible to handle the failure of the KT top root node without some amount of configuration propagation delay.
Building Quicksilver
Addressing these issues in Kyoto Tycoon wasn’t deemed feasible. The project had no maintainer, the last official update being from April 2012, and was composed of a code base of 100k lines of C++. We looked at alternative open source systems at the time, none of which fit our use case well.
Our KT implementation suffered from some fundamental limitations:
- No high availability
- Weak replication protocol
- Exclusive write lock
- Not zero downtime upgrade friendly
It was also unreliable, critical replication and database functionality would break quite often. At some point, keeping KT up in running at Cloudflare was consuming 48 hours of SRE time per week.
We decided to build our own replicated key value store tailored for our needs and we called it Quicksilver. As of today Quicksilver powers an average of 2.5 trillion reads each day with an average latency in microseconds.
Fun fact: the name Quicksilver was picked by John Graham-Cumming, Cloudflare’s CTO. The terrible secret that only very few members of the humankind know is that he originally named it “Velocireplicator”. It is a secret though. Don’t tell anyone. Thank you.
Storage Engine
One major complication with our legacy system, KT, was the difficulty of bootstrapping new machines. Replication is a slow way to populate an empty database, it’s much more efficient to be able to instantiate a new machine from a snapshot containing most of the data, and then only use replication to keep it up to date. Unfortunately KT required nodes to be shut down before they could be snapshotted, making this challenging. One requirement for Quicksilver then was to use a storage engine which could provide running snapshots. Even further, as Quicksilver is performance critical, a snapshot must also not have a negative impact on other services that read from Quicksilver. With this requirement in mind we settled on a datastore library called LMDB after extensive analysis of different options.LMDB’s design makes taking consistent snapshots easy. LMDB is also optimized for low read latency rather than write throughput. This is important since we serve tens of millions of reads per second across thousands of machines, but only change values relatively infrequently. In fact, systems that switched from KT to Quicksilver saw drastically reduced read response times, especially on heavily loaded machines. For example, for our DNS service, the 99th percentile of reads dropped by two orders of magnitude!
LMDB also allows multiple processes to concurrently access the same datastore. This is very useful for implementing zero downtime upgrades for Quicksilver: we can start the new version while still serving current requests with the old version. Many data stores implement an exclusive write lock which requires only a single user to write at a time, or even worse, restricts reads while a write is conducted. LMDB does not implement any such lock.
LMDB is also append-only, meaning it only writes new data, it doesn’t overwrite existing data. Beyond that, nothing is ever written to disk in a state which could be considered corrupted. This makes it crash-proof, after any termination it can immediately be restarted without issue. This means it does not require any type of crash recovery tooling.
Transaction Logs
LMDB does a great job of allowing us to query Quicksilver from each of our edge servers, but it alone doesn’t give us a distributed database. We also needed to develop a way to distribute the changes made to customer configurations into the thousands of instances of LMDB we now have around the world. We quickly settled on a fan-out type distribution where nodes would query main-nodes, who would in turn query top-mains, for the latest updates.
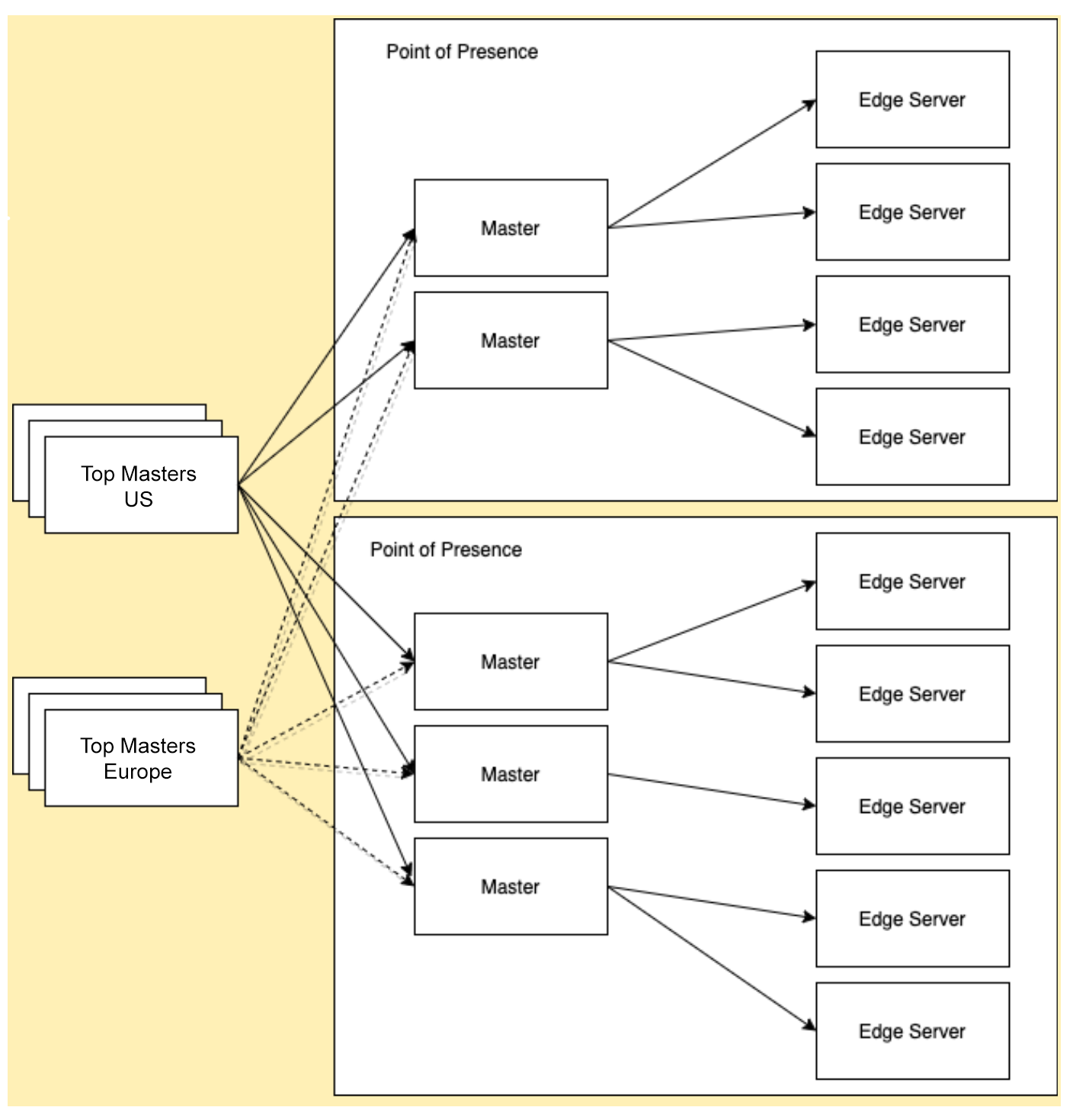
Unfortunately there is no such thing as a perfectly reliable network or system. It is easy for a network to become disconnected or a machine to go down just long enough to miss critical replication updates. Conversely though, when users make changes to their Cloudflare configuration it is critical that they propagate accurately whatever the condition of the network. To ensure this, we used one of the oldest tricks in the book and included a monotonically increasing sequence number in our Quicksilver protocol:
…
< 0023 SET “hello” “world”
< 0024 SET “lorem” “ipsum”
< 0025 DEL “42”…It is now easily possible to detect whether an update was lost, by comparing the sequence number and making sure it is exactly one higher than the last message we have seen. The astute reader will notice that this is simply a log. This process is pleasantly simple because our system does not need to support global writes, only reads. As writes are relatively infrequent and it is easy for us to elect a single data center to aggregate writes and ensure the monotonicity of our counter.
One of the most common failure modes of a distributed system are configuration errors. An analysis of how things could go wrong led us to realize that we had missed a simple failure case: since we are running separate Quicksilver instances for different kinds of data, we could corrupt a database by misconfiguring it. For example, nothing would prevent the DNS database from being updated with changes for the Page Rules database. The solution was to add unique IDs for each database and to require these IDs when initiating the replication protocol.
Through our experience with our legacy system, KT, we knew that replication does not always scale as easily as we would like. With KT it was common for us to saturate IO on our machines, slowing down reads as we tried to replay the replication log. To solve this with Quicksilver we decided to engineer a batch mode where many updates can be combined into a single write, allowing them all to be committed to disk at once. This significantly improved replication performance by reducing the number of disk writes we have to make. Today, we are batching all updates which occur in a 500ms window, and this has made highly-durable writes manageable.
Where should we store the transaction logs? For design simplicity we decided to store these within a different bucket of our LMDB database. By doing this, we can commit the transaction log and the update to the database in one shot. Originally the log was kept in a separate file, but storing it with the database simplifies the code.
Unfortunately this came at a cost: fragmentation. LMDB does not naturally fragment values, it needs to store every value in a sequential region of the disk. Eventually the disk begins to fill and the large regions which offer enough space to fit a particularly big value start to become hard to find. As our disks begin to fill up, it can take minutes for LMDB to find enough space to store a large value. Unfortunately we exacerbated this problem by storing the transaction log within the database.
This fragmentation issue was not only causing high write latency, it was also making the databases grow very quickly. When the reasonably-sized free spaces between values start to become filled, less and less of the disk becomes usable. Eventually the only free space on disk is too small to store any of the actual values we can store. If all of this space were compacted into a single region, however, there would be plenty of space available.
The compaction process requires rewriting an entire DB from scratch. This is something we do after bringing data centers offline and its benefits last for around 2 months, but it is far from a perfect solution. To do better we began fragmenting the transaction log into page-sized chunks in our code to improve the write performance. Eventually we will also split large values into chunks that are small enough for LMDB to happily manage, and we will handle assembling these chunks in our code into the actual values to be returned.
We also implemented a key-value level CRC. The checksum is written when the transaction log is applied to the DB and checks the KV pair is read. This checksum makes it possible to quickly identify and alert on any bugs in the fragmentation code. Within the QS team we are usually against this kind of defensive measure, we prefer focusing on code quality instead of defending against the consequences of bugs, but database consistency is so critical to the company that even we couldn’t argue against playing defense.
LMDB stability has been exceptional. It has been running in production for over three years. We have experienced only a single bug and zero data corruption. Considering we serve over 2.5 trillion read requests and 30 million write requests a day on over 90,000 database instances across thousands of servers, this is very impressive.
Optimizations
Transaction logs are a critical part of our replication system, but each log entry ends up being significantly larger than the size of the values it represents. To prevent our disk space from being overwhelmed we use Snappy to compress entries. We also periodically garbage collect entries, only keeping the most recent required for replication.
For safety purposes we also added an incremental hash within our transaction logs. The hash helps us to ensure that messages have not been lost or incorrectly ordered in the log.
One other potential misconfiguration which scares us is the possibility of a Quicksilver node connecting to, and attempting to replicate from, itself. To prevent this we added a randomly generated process ID which is also exchanged in the handshake:
type ClientHandshake struct {
// Unique ID of the client. Verifies that client and main have distinct IDs. Defaults to a per-process unique ID.
ID uuid.ID
// ID of the database to connect to. Verifies that client and main have the same ID. Disabled by default.
DBID uuid.ID
// At which index to start replication. First log entry will have Index = LastIndex + 1.
LastIndex logentry.Index
// At which index to stop replication.
StopIndex logentry.Index
// Ignore LastIndex and retrieve only new log entries.
NewestOnly bool
// Called by Update when a new entry is applied to the db.
Metrics func(*logentry.LogEntry)
}
Each Quicksilver instance has a list of primary servers and secondary servers. It will always try to replicate from a primary node which is often another QS node near it. There are a variety of reasons why this replication may not work, however. For example, if the target machine’s database is too old it will need a larger changeset than exists on the source machine. To handle this, our secondary mains store a significantly longer history to allow machines to be offline for a full week and still be correctly resynchronized on startup.
Upgrades
Building a system is often much easier than maintaining it. One challenge was being able to do weekly releases without stopping the service.
Fortunately the LMDB datastore supports multiple process reading and writing to the DB file simultaneously. We use Systemd to listen on incoming connections, and immediately hand the sockets over to our Quicksilver instance. When it’s time to upgrade we start our new instance, and pass the listening socket over to the new instance seamlessly.
We also control the clients used to query Quicksilver. By adding an automatic retry to requests we are able to ensure that momentary blips in availability don’t result in user-facing failures.
After years of experience maintaining this system we came to a surprising conclusion: handing off sockets is really neat, but it might involve more complexity than is warranted. A Quicksilver restart happens in single-digit milliseconds, making it more acceptable than we would have thought to allow connections to momentarily fail without any downstream effects. We are currently evaluating the wisdom of simplifying the update system, as in our experience simplicity is often the best true proxy for reliability.
Observability
It’s easy to overlook monitoring when designing a new system. We have learned however that a system is only as good as our ability to both know how well it is working, and our ability to debug issues as they arise. Quicksilver is as mission-critical as anything possibly can be at Cloudflare, it is worth the effort to ensure we can keep it running.
We use Prometheus for collecting our metrics and we use Grafana to monitor Quicksilver. Our SRE team uses a global dashboard, one dashboard for each datacenter, and one dashboard per server, to monitor its performance and availability. Our primary alerting is also driven by Prometheus and distributed using PagerDuty.
We have learned that detecting availability is rather easy, if Quicksilver isn’t available countless alerts will fire in many systems throughout Cloudflare. Detecting replication lag is more tricky, as systems will appear to continue working until it is discovered that changes aren’t taking effect. We monitor our replication lag by writing a heartbeat at the top of the replication tree and computing the time difference on each server.
Conclusion
Quicksilver is, on one level, an infrastructure tool. Ideally no one, not even most of the engineers who work here at Cloudflare, should have to think twice about it. On another level, the ability to distribute configuration changes in seconds is one of our greatest strengths as a company. It makes using Cloudflare enjoyable and powerful for our users, and it becomes a key advantage for every product we build. This is the beauty and art of infrastructure: building something which is simple enough to make everything built on top of it more powerful, more predictable, and more reliable.
We are planning on open sourcing Quicksilver in the near future and hope it serves you as well as it has served us.
If you’re interested in working with us on this and other projects, please take a look at our jobs page and apply today.