

Hoy Cloudflare presenta el desarrollo de Firewall for AI, una capa de protección que se puede implementar delante de modelos de lenguaje de gran tamaño (LLM) para identificar los abusos antes de que lleguen a los modelos.
Aunque los modelos de IA, y específicamente los LLM, están en auge, los clientes nos indican que les preocupa encontrar las mejores estrategias para proteger sus propios LLM. La utilización de los LLM como parte de las aplicaciones conectadas a Internet añade nuevas vulnerabilidades que los ciberdelincuentes pueden aprovechar.
Algunas de las vulnerabilidades que afectan a las aplicaciones web y API tradicionales también son aplicables al mundo de los LLM, como las inyecciones o la exfiltración de datos. Sin embargo, hay un nuevo conjunto de amenazas que ahora son relevantes debido a cómo funcionan los LLM. Por ejemplo, los investigadores han descubierto recientemente una vulnerabilidad en una plataforma de colaboración de IA que les permite secuestrar modelos y realizar acciones no autorizadas.
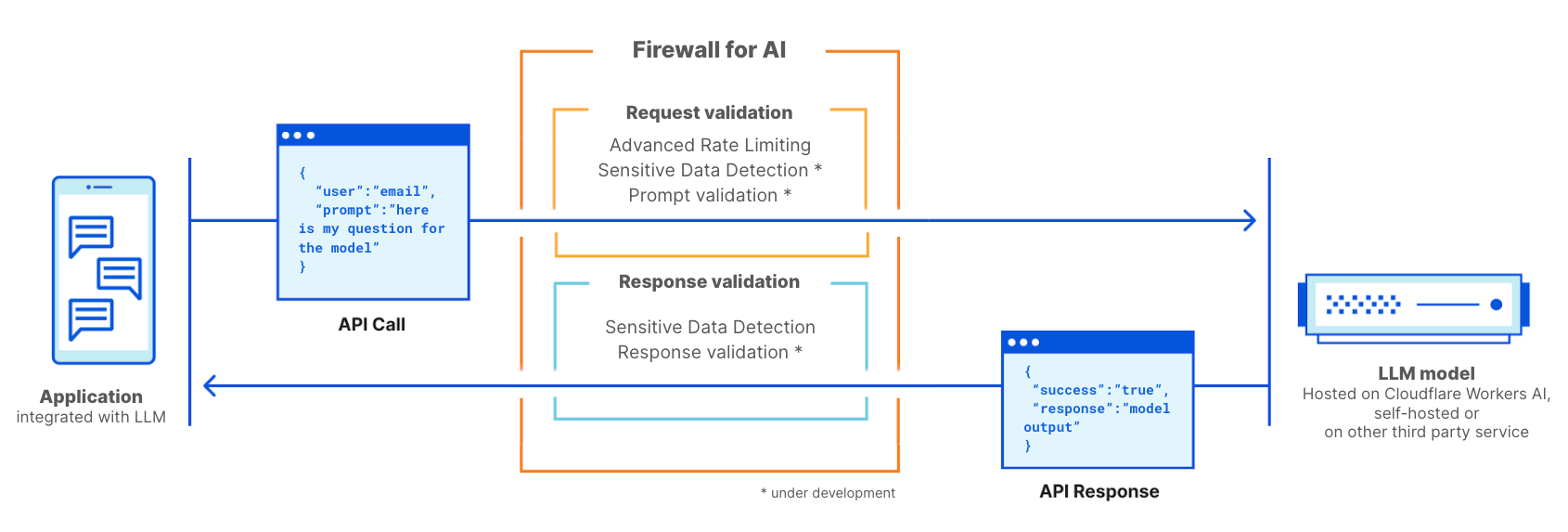
Firewall for AI es un firewall de aplicaciones web (WAF) avanzado, personalizado específicamente para las aplicaciones que utilizan LLM. Constará de un conjunto de herramientas que se pueden implementar delante de las aplicaciones para detectar vulnerabilidades y ofrecer visibilidad a los propietarios de los modelos. Este conjunto de herramientas incluirá productos que ya forman parte de WAF, como la limitación de velocidad y la detección de datos confidenciales, y una nueva capa de protección que está actualmente en desarrollo. Esta nueva validación analiza la instrucción que envía el usuario final para identificar los intentos de explotar el modelo a fin de extraer datos y otros tipos de abuso. Gracias al gran tamaño de la red de Cloudflare, Firewall for AI se ejecuta lo más cerca posible del usuario. Esto nos permite identificar los ataques en un etapa temprana y proteger tanto al usuario final como a los modelos contra abusos y ataques.
Antes de analizar el funcionamiento de Firewall for AI y su completo conjunto de funciones, analicemos primero qué hace únicos a los LLM, y las superficies de ataque que introducen. Como referencia, utilizaremos las 10 principales vulnerabilidades de OWASP para LLM.
¿Por qué los LLM difieren de las aplicaciones tradicionales?
Al considerar los LLM como aplicaciones conectadas a Internet, observamos dos diferencias principales respecto a las aplicaciones web más tradicionales.
En primer lugar, la forma como los usuarios interactúan con el producto. Las aplicaciones tradicionales son deterministas por naturaleza. Considera una aplicación bancaria. Se define en función de un conjunto de operaciones (consultar mi saldo, realizar una transferencia, etc.). Podemos garantizar la seguridad de la operación comercial (y de los datos) controlando el conjunto específico de operaciones que aceptan estos puntos finales: "GET /balance" o "POST /transfer".
Por diseño, las operaciones de los LLM son no deterministas. Para empezar, las interacciones con los LLM se basan en el lenguaje natural, por lo que identificar las solicitudes problemáticas es más difícil que la correspondencia con firmas de ataque. Además, a menos que haya una respuesta almacenada en la caché, los LLM suelen ofrecer una respuesta distinta cada vez, incluso si se repite la misma instrucción de entrada. Por lo tanto, limitar cómo un usuario interactúa con la aplicación es considerablemente más complejo. Esto también plantea una amenaza para el usuario, ya que podría estar expuesto a información errónea que debilite la confianza en el modelo.
En segundo lugar, una diferencia importante es cómo el plano de control de la aplicación interactúa con los datos. En las aplicaciones tradicionales, el plano de control (el código) está claramente separado del plano de datos (la base de datos). Las operaciones definidas son la única forma de interactuar con los datos subyacentes (p. ej. "muéstrame el historial de mis transacciones de pago"). Esto permite a los expertos en seguridad centrarse en añadir comprobaciones y protección al plano de control y así proteger indirectamente la base de datos.
Los LLM difieren en que los datos de entrenamiento pasan a formar parte del propio modelo durante el proceso de entrenamiento, por lo que controlar cómo se comparten esos datos como resultado de la instrucción de un usuario resulta muy difícil. Se han estudiado algunas soluciones a nivel de arquitectura, como separar los LLM en distintos niveles y segregar los datos. Sin embargo, aún no se ha encontrado la fórmula mágica.
Desde una perspectiva de la seguridad, estas diferencias permiten a los ciberdelincuentes crear nuevos vectores de ataque dirigidos a los LLM y burlar las herramientas de seguridad existentes diseñadas para las aplicaciones web tradicionales.
Vulnerabilidades OWASP para LLM
La fundación OWASP publicó una lista de las 10 principales clases de vulnerabilidades para los LLM, proporcionando un marco útil para explorar cómo proteger los modelos de lenguaje. Algunas de las amenazas recuerdan a las 10 principales vulnerabilidades de OWASP para aplicaciones web, mientras que otras son específicas de los modelos de lenguaje.
Al igual que con las aplicaciones web, algunas de estas vulnerabilidades se pueden abordar mejor cuando la aplicación de LLM se ha diseñado, desarrollado y entrenado. Por ejemplo, el envenenamiento de datos de entrenamiento se puede llevar a cabo introduciendo vulnerabilidades en el conjunto de datos de entrenamiento utilizados para entrenar nuevos modelos. A continuación, la información envenenada se presenta al usuario cuando el modelo está activo. Las vulnerabilidades de la cadena de suministro y el diseño de complemento no seguro son vulnerabilidades introducidas en componentes añadidos al modelo, como paquetes de software de terceros. Por último, la gestión de la autorización y de los permisos es fundamental para abordar la autonomía excesiva, donde modelos no restringidos pueden realizar acciones no autorizadas en la aplicación o la infraestructura a nivel más general.
Por el contrario, la inyección de instrucciones, la denegación de servicio del modelo y la divulgación de información confidencial se pueden mitigar mediante la adopción de una solución de seguridad de proxy como Cloudflare Firewall for AI. En las secciones siguientes comentaremos en más detalle estas vulnerabilidades y cómo Cloudflare se encuentra en una posición privilegiada para mitigarlas.
Implementaciones de LLM
Los riesgos de los modelos de lenguaje dependen también del modelo de implementación. Actualmente hay las tres principales estrategias de implementación: LLM internos, LLM públicos y LLM de productos. En los tres escenarios, debemos proteger los modelos contra los abusos, proteger los datos privados almacenados en el modelo y proteger al usuario final frente a información errónea o la exposición a contenido inadecuado.
- LLM internos: las empresas desarrollan LLM para ayudar a sus empleados con sus tareas cotidianas. Estos LLM se consideran activos corporativos y no deberían ser accesibles a personas ajenas a la empresa. Por ejemplo, un copiloto de IA entrenado con datos de ventas e interacciones con los clientes utilizado para generar propuestas personalizadas, o un LLM entrenado con una base de conocimiento interna que los ingenieros pueden consultar.
- LLM públicos: son LLM a los que se puede acceder desde fuera de la empresa. Estas soluciones suelen tener versiones gratuitas que todo el mundo puede utilizar, y a menudo se entrenan con conocimientos generales o públicos. Pore ejemplo, GPT de OpenAI o Claude de Anthropic.
- LLM de productos: desde la perspectiva de una empresa, los LLM pueden formar parte de un producto o servicio ofrecido a sus clientes. Estos LLM suelen ser soluciones personalizadas y autoalojadas que pueden estar disponibles como una herramienta para interactuar con los recursos de la empresa. Por ejemplo, los chabots de asistencia o Cloudflare AI Assistant.
Desde la perspectiva de los riesgos, la diferencia entre los LLM públicos y los LLM privados es quién resulta afectado cuando los ataques tienen éxito. Los LLM públicos se consideran una amenaza para los datos porque prácticamente cualquiera puede acceder a los datos que acaban formando parte del modelo. Esta es una de las razones por las que muchas empresas aconsejan a sus empleados que no incluyan información confidencial en las instrucciones de servicios disponibles públicamente. Los LLM de productos se consideran una amenaza para las empresas y su propiedad intelectual si los modelos han accedido a información privada durante el entrenamiento (ya sea por diseño o inadvertidamente).
Firewall for AI
Cloudflare Firewall for AI se implementará como un WAF tradicional, donde se analiza cada solicitud de API con una instrucción de LLM en busca de patrones y firmas de posibles ataques.
Firewall for AI se puede implementar delante de modelos alojados en la plataforma de Cloudflare Workers AI o de modelos alojados en cualquier otra infraestructura de terceros. Se puede utilizar junto con Cloudflare AI Gateway, y los clientes podrán controlar y configurar Firewall for AI mediante el plano de control de WAF.
Evitar los ataques volumétricos
Una de las amenazas que incluye OWASP es la denegación de servicio del modelo. Al igual que con las aplicaciones tradicionales, se lanza un ataque DoS, consumiendo una cantidad excepcionalmente alta de recursos, lo que daña la calidad del servicio o puede aumentar los costes de ejecución del modelo. Debido a la gran cantidad de recursos que requiere la ejecución de los LLM, y a la imprevisibilidad de la entrada de los usuarios, este tipo de ataque puede ser dañino.
Es posible mitigar este riesgo mediante la adopción de políticas de limitación de velocidad que controlen la velocidad de las solicitudes de sesiones individuales, limitando por lo tanto la ventana de contexto. Hoy, redireccionando tu modelo a través de Cloudflare, te beneficias de protección contra DDoS lista para usar. También puedes utilizar la limitación de velocidad y la limitación de velocidad avanzada para gestionar la velocidad de las solicitudes que permites que lleguen a tu modelo, estableciendo una velocidad máxima de las solicitudes que puede enviar una dirección IP o una clave de API individual durante una sesión.
Identificar información confidencial con la detección de datos confidenciales
Hay dos casos de uso para los datos confidenciales, en función de si eres propietario del modelo y de los datos, o de si deseas evitar que los usuarios envíen datos a los LLM públicos.
Según define OWASP, la divulgación de información confidencial se produce cuando los LLM revelan inadvertidamente datos confidenciales en las respuestas, lo que causa el acceso a datos no autorizados, violaciones de la privacidad y fallos de seguridad. Una forma de evitarlo es añadir estrictas validaciones de las instrucciones. Otra estrategia es identificar la información de identificación personal que sale del modelo. Esto es relevante, por ejemplo, cuando se ha entrenado un modelo con una base de conocimiento de una empresa que puede incluir información confidencial, como información de identificación personal (p. ej., números de la seguridad social), código privado o algoritmos.
Los clientes que utilizan modelos LLM detrás del WAF de Cloudflare pueden emplear el conjunto de reglas administradas del WAF de detección de datos confidenciales para identificar determinada información de identificación personal que devuelva el modelo en la respuesta. Los clientes pueden revisar las coincidencias de detección de datos confidenciales en los eventos de seguridad del WAF. Hoy, la detección de datos confidenciales se ofrece como un conjunto de reglas administradas diseñadas para analizar la información financiera (por ejemplo, números de tarjeta de crédito) así como secretos (claves de API). Como parte de la hoja de ruta, tenemos previsto permitir que nuestros clientes creen sus propias huellas digitales personalizadas.
El otro caso de uso tiene como objetivo evitar que los usuarios compartan información de identificación personal u otra información confidencial con proveedores de LLM externos, como OpenAI o Anthropic. Para estar protegidos ante esta situación, tenemos previsto ampliar la detección de datos confidenciales para analizar la instrucción de la solicitud e integrar su resultado con AI Gateway, donde, junto con el historial de la instrucción, detectamos si se han incluido determinada información confidencial en la solicitud. Empezaremos utilizando las reglas de detección de datos confidenciales y tenemos previsto permitir que los clientes escriban sus propias firmas personalizadas. De la misma forma, la ofuscación es otra función que nos comentan muchos de nuestros clientes. Cuando esté disponible, la detección de datos confidenciales ampliada permitirá que los clientes ofusquen determinados datos confidenciales en una instrucción antes de que estos lleguen al modelo. La detección de datos confidenciales en la fase de solicitud está en desarrollo.
Evitar los abusos de los modelos
El abuso de modelos es una categoría más amplia de abuso. Incluye estrategias como la "inyección de instrucciones" o el envío de solicitudes que generan alucinaciones o causan respuestas imprecisas, ofensivas, inadecuadas o simplemente no relacionadas con el tema.
La inyección de instrucciones es un intento de manipular un modelo de lenguaje mediante entradas elaboradas especialmente, que causan que el LLM devuelva respuestas no deseadas. Los resultados de una inyección pueden variar, desde extraer información confidencial a influenciar la toma de decisiones imitando las interacciones normales con el modelo. Un ejemplo clásico de inyección de instrucciones es manipular un CV para afectar al resultado de las herramientas de cribado de currículums.
Un caso de uso común que nos comentan los clientes de nuestra solución AI Gateway es que quieren evitar que su aplicación genere lenguaje tóxico, ofensivo o problemático. Los riesgos de no controlar el resultado del modelo incluyen daños a la reputación y perjudicar al usuario final proporcionando una respuesta no fiable.
Podemos abordar estos tipos de abuso añadiendo una capa adicional de protección delante del modelo. Esta capa se puede entrenar para bloquear los intentos de inyección o para bloquear los intentos correspondientes a las categorías inapropiadas.
Validación de las instrucciones y las respuestas
Firewall for AI ejecutará una serie de detecciones diseñadas para identificar los intentos de inyección de instrucciones y otros tipos de abuso, por ejemplo, garantizando que el tema se mantiene dentro de los límites que ha definido el propietario del modelo. Al igual que otras funciones existentes del WAF, Firewall for AI buscará automáticamente las instrucciones incorporadas en las solicitudes HTTP o permitirá a los clientes crear reglas según la ubicación del cuerpo JSON de la solicitud donde se puede encontrar la instrucción.
Una vez activado, el firewall analizará cada instrucción y proporcionará una puntuación según la probabilidad de que esta sea maliciosa. También etiquetará la instrucción según las categorías predefinidas. La puntuación va de 1 a 99 e indica la probabilidad de una inyección de instrucción, donde 1 es la probabilidad más alta.
Los clientes podrán crear reglas de WAF para bloquear o manejar las solicitudes con una puntuación determinada en una o en ambas de estas dimensiones. Podrás combinar esta puntuación con otros indicadores existentes (como la puntuación de bots o la puntuación de ataques) para determinar si la solicitud debe llegar al modelo o se debe bloquear. Por ejemplo, se podría combinar con una puntuación de bots para identificar si la solicitud era maliciosa y la ha generado una fuente automatizada.
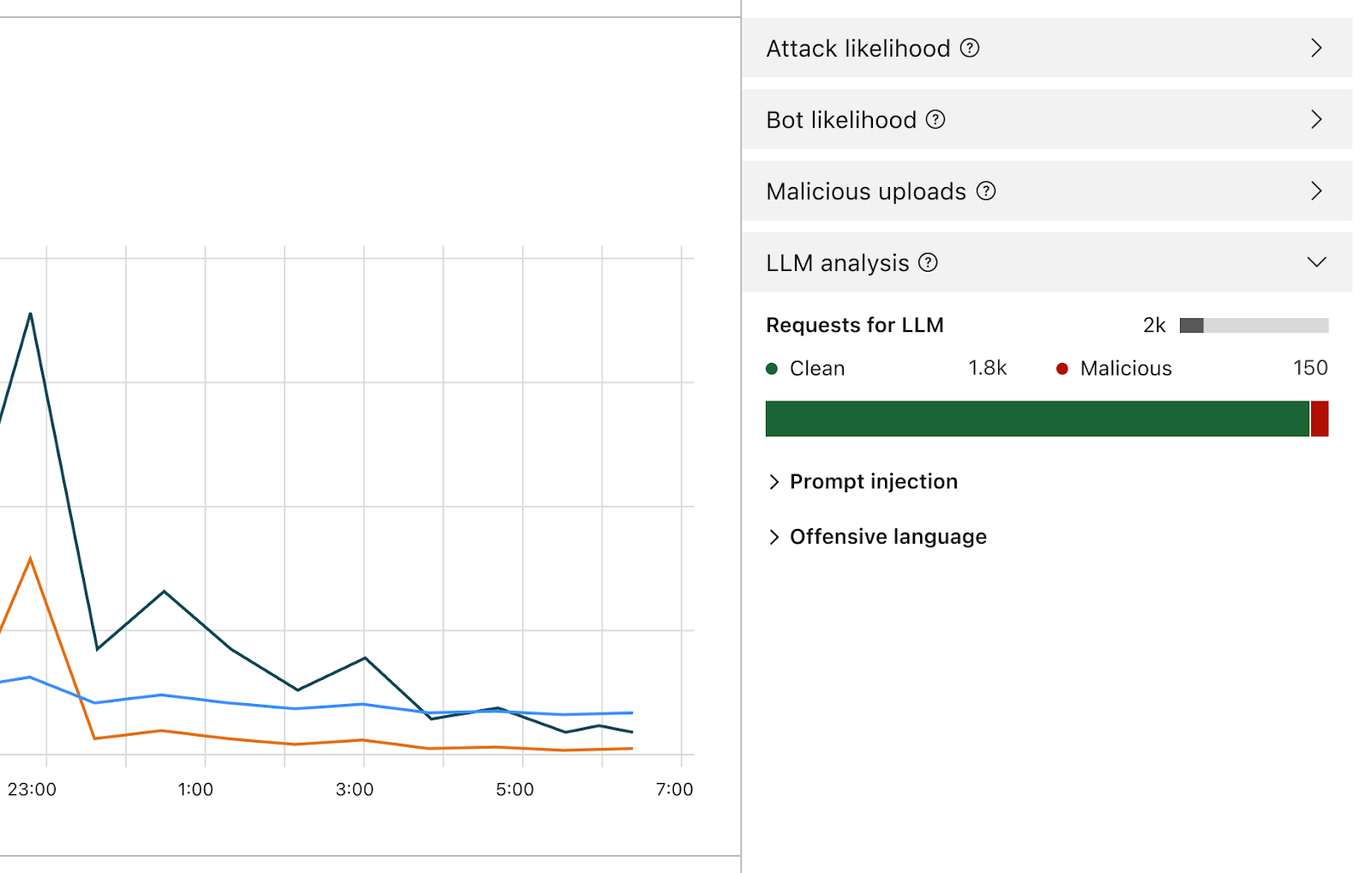
Además de la puntuación, asignaremos etiquetas a cada instrucción, que se pueden utilizar al crear reglas para impedir que las instrucciones correspondientes a cualquiera de estas categorías lleguen a su modelo. Por ejemplo, los clientes podrán crear reglas para bloquear temas específicos. Esto incluye las instrucciones que utilicen palabras categorizadas como ofensivas, o vinculadas a la religión, a contenido sexual o a la política, por ejemplo.
¿Cómo puedo utilizar Firewall for AI? ¿Quién se puede beneficiar?
Los clientes del plan Enterprise en la solución de seguridad avanzada para aplicaciones pueden empezar ya a utilizar la limitación de velocidad avanzada y la detección de datos confidenciales (en la fase de respuesta). Ambos productos se pueden encontrar en la sección del WAF del panel de control de Cloudflare. La función de validación de instrucciones de Firewall for AI está actualmente en desarrollo y lanzaremos una versión beta en los próximos meses para todos los usuarios de Workers AI. Inscríbete en la lista de espera y te avisaremos cuando la función esté disponible.
Conclusión
Cloudflare es uno de los primeros proveedores de seguridad que lanza un conjunto de herramientas para proteger las aplicaciones de IA. Con Firewall for AI, los clientes pueden controlar qué instrucciones y solicitudes llegan a sus modelos de lenguaje, reduciendo el riesgo de abusos y la exfiltración de datos. Sigue atento para saber más sobre la evolución de la seguridad para las aplicaciones de IA.