
Conozco los filtros de Bloom (llamados así por Burton Bloom) desde la universidad, pero no he tenido realmente la oportunidad de utilizarlos. Esto cambió el mes pasado: me fascinaba lo que prometía esta estructura de datos, pero no tardé en darme cuenta de que presentaba algunos inconvenientes. En esta publicación del blog explico mi breve historia de pasión y desencanto con los filtros de Bloom.
Mientras investigaba sobre la suplantación de IP, necesitaba analizar si las direcciones IP de origen extraídas de los paquetes que llegaban a nuestros servidores eran legítimas, según la ubicación geográfica de nuestros centros de datos. Por ejemplo, las direcciones IP de origen pertenecientes a un proveedor de acceso a Internet legítimo de Italia no deberían llegar a un centro de datos de Brasil. Este problema puede parecer sencillo, pero resulta complejo dado el panorama de Internet en constante evolución. Baste decir que acabé con un gran número de archivos de texto grandes que contenían datos como estos:

Esto indica el registro de la llegada de la dirección IP 192.0.2.1 al centro de datos de Cloudflare número 107 con una solicitud legítima. Estos datos proceden de muchas fuentes, incluidos nuestros análisis activos y pasivos, registros de determinados dominios propios (como Cloudflare.com), fuentes públicas (como una tabla de BGP), etc. Por lo general, la misma línea se repetiría en varios archivos.
Terminé con una ingente colección de datos de este tipo. En algún momento contabilicé 1000 millones de líneas entre todas las fuentes recopiladas. Normalmente escribo scripts bash para preprocesar las entradas, pero a tan gran escala este método no funcionaba. Por ejemplo, eliminar los duplicados de este pequeño archivo de apenas 600 MiB y 40 millones de líneas, me llevó... una eternidad:

Basta con decir que la deduplicación de líneas usando los comandos bash habituales como 'sort' en diversas configuraciones ('--parallel', '--buffer-size' y '--unique') no era el procedimiento óptimo para un conjunto de datos tan grande.
Filtros de Bloom al rescate
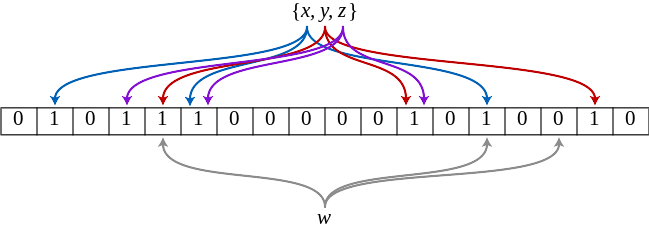
Entonces tuve una idea brillante: ¡no es necesario ordenar las líneas! Simplemente necesito eliminar las líneas duplicadas: con algún tipo de estructura de datos de "conjunto" debería ser mucho más rápido. Además, conozco la cardinalidad aproximada del archivo de entrada (el número de líneas únicas) y puedo permitirme perder algunos puntos de datos, por lo que utilizar una estructura de datos probabilística me va bien.
¡Los filtros de Bloom son la solución perfecta!
Te recomiendo consultar la Wikipedia sobre los filtros de Bloom, pero aquí te muestro cómo abordo esta estructura de datos.
¿Cómo implementarías un "conjunto"? Dada una función hash perfecta, y memoria infinita, podríamos simplemente crear una matriz infinita de bits y establecer un número de bits 'hash(item)' para cada elemento que encontremos. Esto nos daría una perfecta estructura de datos de "conjunto". ¿Verdad? Es obvio. Por desgracia, las funciones hash tienen colisiones y la memoria infinita no existe, así que tenemos que hacer concesiones en nuestra realidad. Pero podemos calcular y gestionar la probabilidad de colisiones. Por ejemplo, imaginemos que tenemos una buena función hash, y 128 GiB de memoria. Podemos calcular que la probabilidad de colisión del segundo elemento añadido a la matriz de bits sería de 1 en 1099511627776. La probabilidad de colisión al añadir más elementos aumenta a medida que llenamos la matriz de bits.
Además, podríamos utilizar varias funciones hash, y acabar con una matriz de bits más densa. Esto es exactamente para lo que optimizan los filtros de Bloom. Un filtro de Bloom es una serie de cálculos que utilizan las cuatro variables:
- 'n': el número de elementos de entrada (cardinalidad)
- 'm': la memoria utilizada por la matriz de bits
- 'k': el número de funciones hash contabilizadas para cada entrada
- 'p': la probabilidad de una coincidencia de falso positivo
Dada la cardinalidad de entrada 'n' y la probabilidad 'p' deseada de falso positivo, el cálculo del filtro de Bloom devuelve la memoria 'm' requerida y el número 'k' de funciones hash necesarias.
Echa un vistazo a esta excelente visualización de Thomas Hurst que muestra cómo los parámetros se influyen entre ellos:
mmuniq-bloom
Basándome en esta intuición, me fijé como objetivo añadir una nueva herramienta a lo que ya utilizaba: 'mmuniq-bloom', una herramienta probabilística que, dada la entrada en STDIN, devuelve solo líneas únicas en STDOUT, con suerte mucho más rápido que la combinación de 'sort' y 'uniq'.
Aquí la tienes:
Por simplicidad y rapidez, diseñé 'mmuniq-bloom' asumiendo un par de premisas. En primer lugar, a menos que se indique lo contrario, utiliza 8 funciones hash k=8. Este parece ser un número cercano al óptimo para los tamaños de datos con los que trabajo, y la función hash puede generar rápidamente 8 hash decentes. Alineamos 'm', el número de bits de la matriz de bits, para que sea una potencia de dos. Esto es para evitar la costosa operación % modulo, que se compila en el lento ensamblador 'div'. Con tamaños de potencia de dos podemos simplemente ejecutar AND a nivel de bits. (Como curiosidad, lee cómo los compiladores pueden optimizar algunas divisiones usando la multiplicación por una constante mágica.)
Ahora podemos ejecutar esto en el mismo archivo de datos que utilizamos antes:

¡Oh, esto es mucho mejor! 12 segundos es algo mucho más manejable que los 2 minutos que teníamos antes. Pero espera... El programa utiliza una estructura de datos optimizada, un consumo de memoria relativamente limitado, un análisis de líneas optimizado y un buen almacenamiento en búfer de salida... 12 segundos sigue siendo una eternidad en comparación con la herramienta 'wc -l':

¿Qué está pasando? Entiendo que contar líneas con 'wc' es más fácil que averiguar qué líneas son únicas, pero ¿realmente vale la pena que requiera 26 veces más tiempo? ¿A dónde va toda la CPU en 'mmuniq-bloom'?
Debe ser mi función hash. 'wc' no necesita gastar toda esta CPU realizando todos estos extraños cálculos para cada una de las 40 millones de líneas de entrada. Utilizo una función hash 'siphash24' bastante compleja, así que seguramente consume la CPU, ¿verdad? Comprobémoslo ejecutando el código para que calcule la función hash pero sin ninguna operación de filtro de Bloom:

Hay algo raro aquí. Contabilizar la función hash cuesta efectivamente unos 2 segundos, pero el programa ha tardado 12 segundos en la ejecución anterior. ¿Solo el filtro de Bloom requiere 10 segundos? ¿Cómo es posible? Es una estructura de datos tan simple...
Un arma secreta: un generador de perfiles
Llegó el momento de utilizar una herramienta adecuada para la tarea: activemos un generador de perfiles y veamos a dónde va la CPU. En primer lugar, activemos 'strace' para confirmar que no estamos ejecutando llamadas inesperadas al sistema:
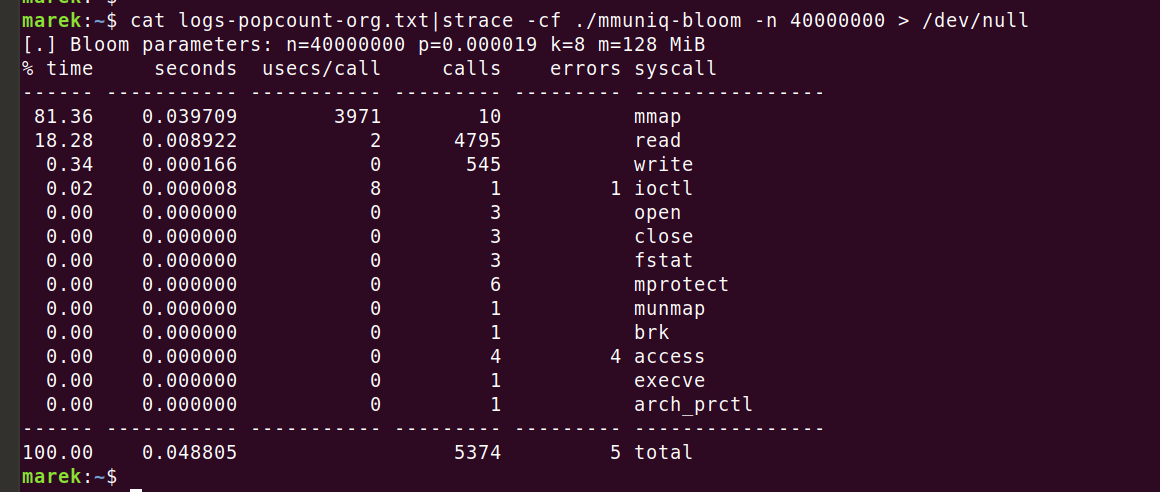
Todo parece en orden. Es curioso que cada una de las 10 llamadas a 'mmap' tarde 4 ms (3971 us), pero está bien. Rellenamos la memoria por adelantado con 'MAP_POPULATE' para evitarnos errores de página más adelante.
¿Cuál es el siguiente paso? ¡Por supuesto, el 'perf' de Linux!

A continuación podemos ver los resultados:
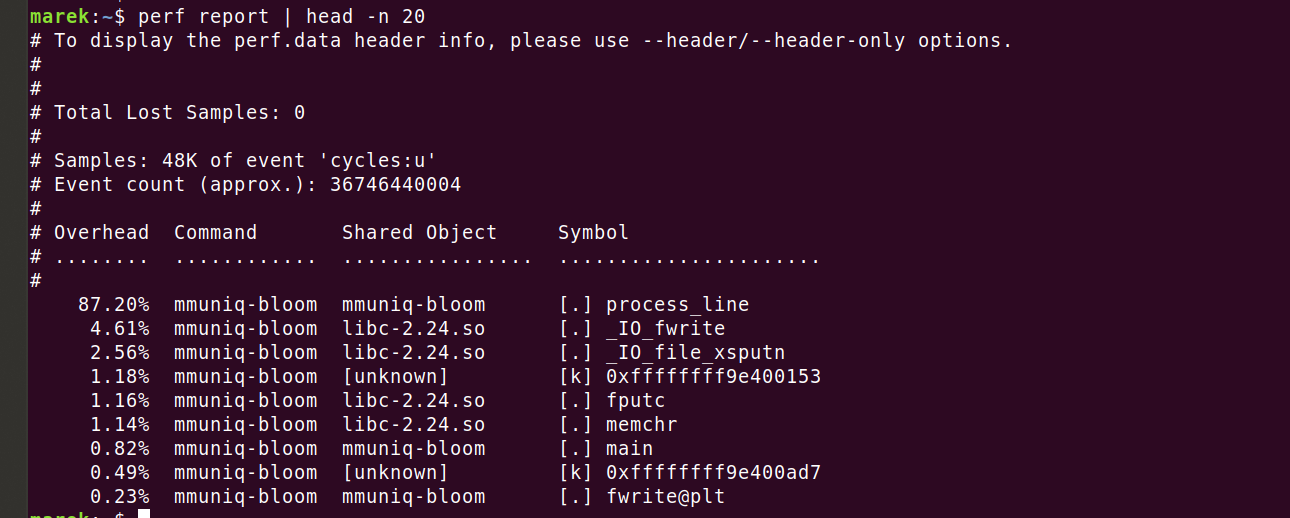
Realmente consumimos el 87,2 % de los ciclos en la repetición de nuestro código. Veamos dónde exactamente. La ejecución de 'perf annotate process_line --source' muestra rápidamente algo inesperado.
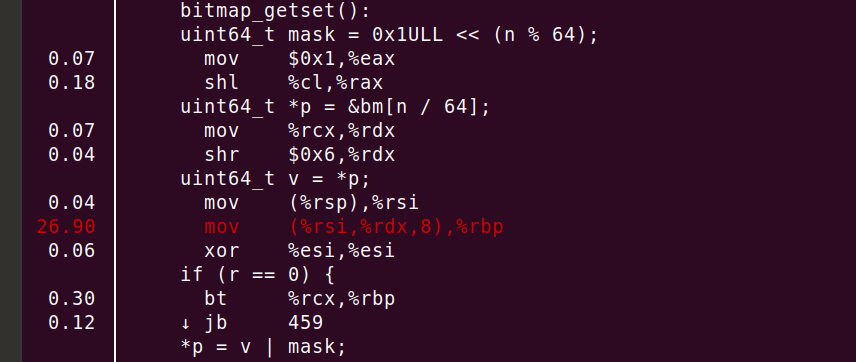
Puedes ver un consumo del 26,90 % de la CPU en 'mov', ¡pero eso no es todo! El compilador ha alineado correctamente la función y ha desplegado el bucle 8 veces. En resumen, la línea 'mov' o 'uint64_t v = *p' se suma a una gran mayoría de los ciclos.
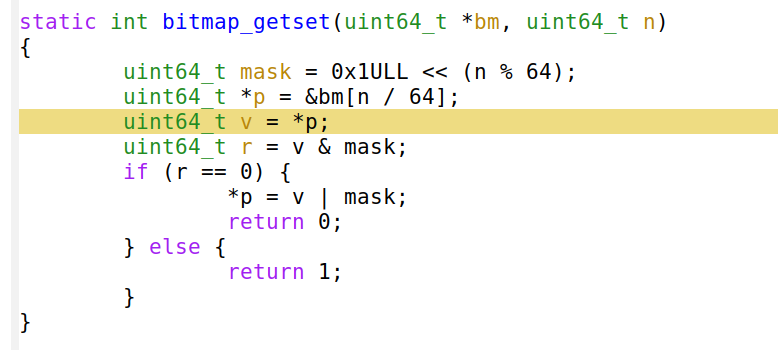
Está claro que 'perf' debe estar equivocado, ¿cómo puede costar tanto una línea tan simple? Podemos repetir la evaluación con cualquier otro generador de perfiles y nos mostrará el mismo problema. Por ejemplo, me gusta utilizar 'google-perftools' con kcachegrind porque genera gráficos muy atractivos:
La representación del resultado tiene este aspecto:
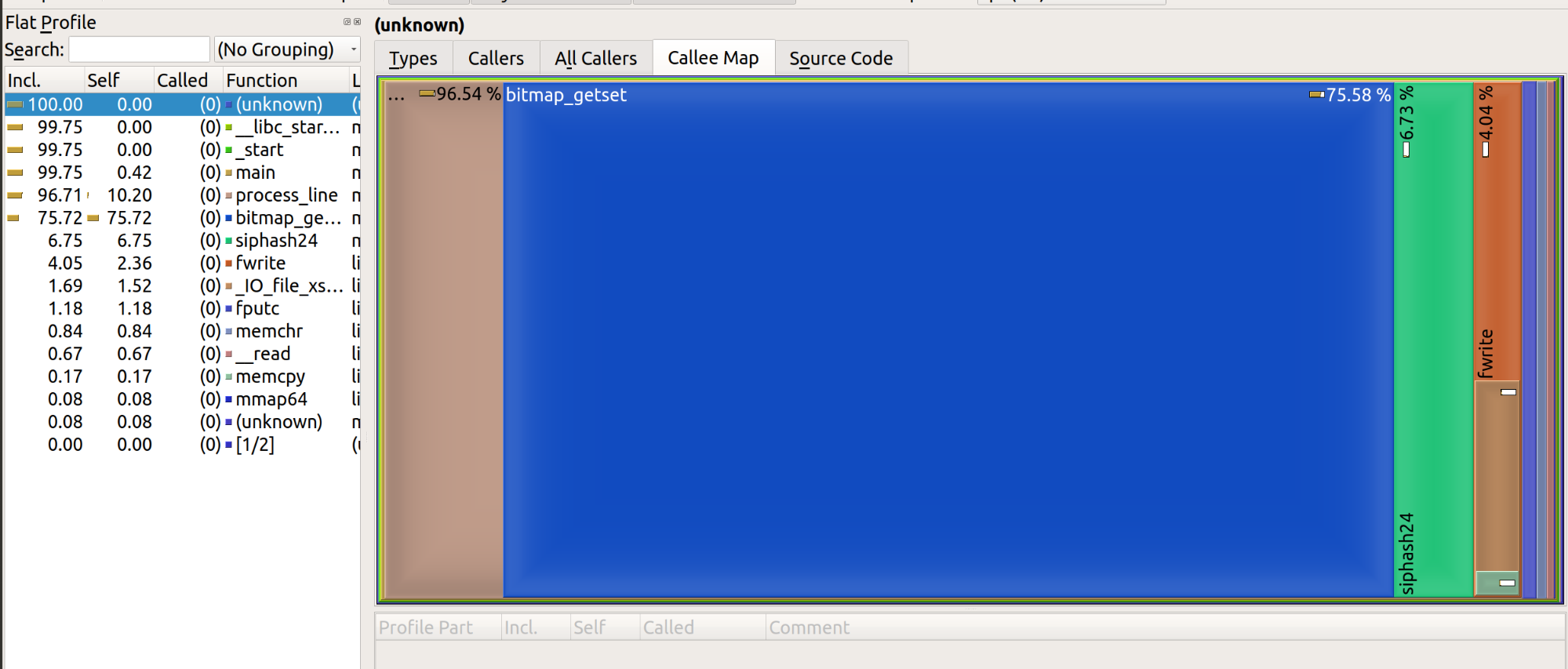
Me gustaría resumir lo que hemos encontrado hasta ahora.
La herramienta genérica 'wc' requiere 0,45 segundos de CPU para procesar un archivo de 600 MiB. Nuestra herramienta optimizada 'mmuniq-bloom' tarda 12 segundos. La CPU se consume en una sola instrucción 'mov', desreferenciando la memoria...

¡Oh! ¿Cómo podría haberlo olvidado? El acceso de la memoria aleatoria es lento. ¡Muy, muy, muy lento!
De acuerdo con la regla general que indica "los números de latencia que todo programador debería conocer", un fetch de RAM son unos 100 ns. Hagamos los cálculos: 40 millones de líneas, 8 hash contabilizados por cada línea. Como nuestro filtro de Bloom es de 128 MiB, nuestro hardware anterior no se ajusta a la caché L3. Los hash se distribuyen uniformemente en el amplio rango de la memoria, y cada hash genera un error de memoria. Si lo sumamos todo, eso es...

Eso sugiere que se utilizaron 32 segundos solo en las operaciones fetch en la memoria. El programa real es más rápido, y requiere solo 12 segundos. La razón es que, aunque los datos del filtro de Bloom no se ajustan por completo a la caché L3, siguen beneficiándose en cierta forma del almacenamiento en caché. Es fácil verlo con 'perf stat -d':
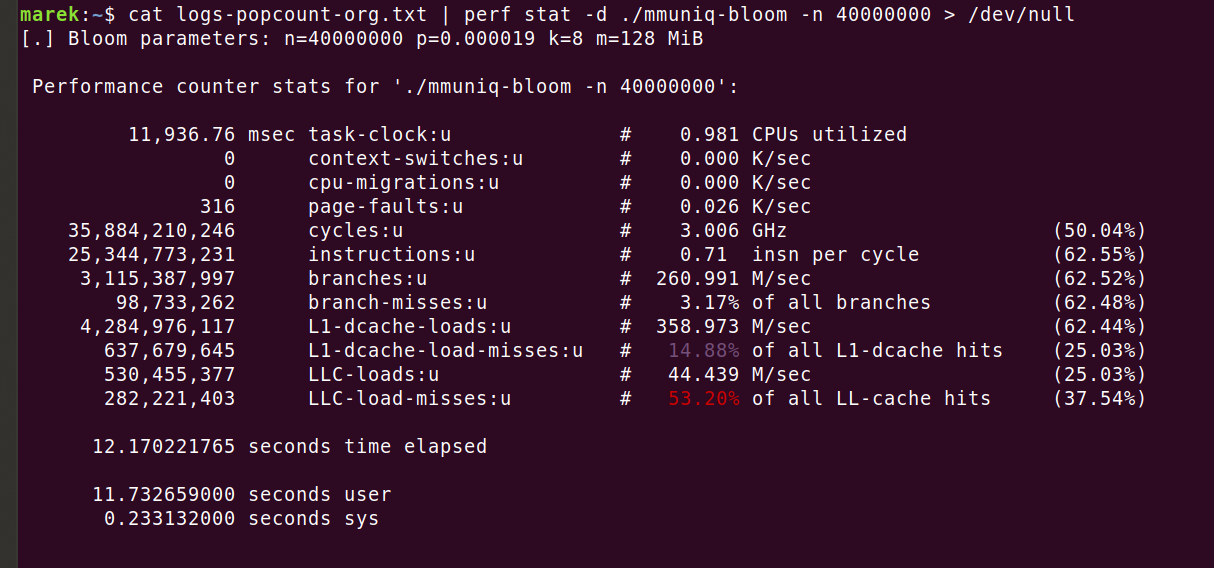
Así que deberíamos haber tenido al menos 320 millones de errores de carga de LLC, pero solo tuvimos 280 millones. Esto todavía no explica por qué el programa se ejecutaba solo 12 segundos. Pero de hecho no importa. Lo que importa es que el número de errores de caché es un problema real y solo podemos solucionarlo reduciendo el número de accesos a la memoria. Intentemos ajustar el filtro de Bloom para que solo utilice una función hash:

¡Ay! ¡Eso sí que dolió! El filtro de Bloom ha requerido 64 GiB de memoria para obtener nuestro índice de probabilidad de falsos positivos deseado de 1 error por cada 10 000 líneas. ¡Qué desastre!
Tampoco parece que hayamos mejorado mucho. El sistema operativo ha tardado 22 segundos en prepararnos la memoria, pero aun así consumimos 11 segundos en espacio de usuario. Supongo que esta vez las ventajas de acceder a la memoria con menos frecuencia se han visto contrarrestadas por una menor probabilidad de aciertos en la caché debido al importante incremento del tamaño de la memoria. ¡En las ejecuciones anteriores solo necesitábamos 128 MiB para el filtro de Bloom!
Desechar los filtros de Bloom por completo
Esto ya es ridículo. Para obtener las mismas garantías de falsos positivos, o bien debemos utilizar muchos hash en el filtro de Bloom (como 8) y, por tanto, muchas operaciones en la memoria, o bien podemos tener 1 función hash, pero con enormes requisitos de memoria.
En realidad, no estamos limitados por la memoria disponible, sino que queremos optimizar para reducir los accesos a la memoria. Lo único que necesitamos es una estructura de datos que requiera como máximo 1 error de memoria por elemento y utilice menos de 64 gigas de RAM...
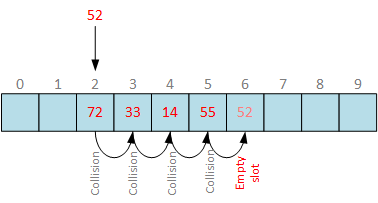
Aunque podríamos considerar estructuras de datos más sofisticadas, como el filtro Cuckoo, quizá podamos simplificar más. ¿Qué tal una simple tabla hash con análisis lineal?
{kind=link}
Damos la bienvenida a mmuniq-hash
Aquí puedes encontrar una versión de mmuniq-bloom con algunos ajustes, pero usando una tabla hash:
En lugar de almacenar los bits como para el filtro de Bloom, ahora almacenamos hash de 64 bits de la función 'siphash24'. Esto nos da la garantía de una probabilidad mucho más alta, con una probabilidad de falsos positivos mucho mejor que un error en cada 10 000 líneas.
Hagamos el cálculo. Añadir un nuevo elemento a una tabla hash que contenga, digamos, 40 millones de entradas, tiene '40M/2^64' posibilidades de colisión con hash. Es decir, una entre 461 000 millones, una probabilidad razonablemente baja. Pero no estamos añadiendo un elemento a un conjunto precargado. Estamos añadiendo 40 millones de líneas a un conjunto inicialmente vacío. Según la paradoja del cumpleaños, esto tiene muchas más probabilidades de colisionar en algún momento. Una aproximación decente es '~n^2/2m', que en nuestro caso es '~(40M2)/(2*(264))'. Esto supone una probabilidad de una entre 23 000. En otras palabras, suponiendo que estemos utilizando una buena función hash, uno de cada 23 mil conjuntos aleatorios de 40 millones de elementos tendrá una colisión hash. Esta probabilidad práctica de colisión no es insignificante, pero sigue siendo mejor que un filtro de Bloom y totalmente aceptable para mi caso de uso.
El código de la tabla hash se ejecuta más rápido, tiene mejores patrones de acceso a la memoria y mejor probabilidad de falsos positivos que el enfoque del filtro de Bloom.

No te asustes por la línea "hash conflicts", solo indica lo llena que estaba la tabla hash. Estamos utilizando el análisis lineal, por lo que cuando ya se utiliza un grupo, simplemente seleccionamos el siguiente grupo vacío. En nuestro caso, tuvimos que omitir más de 0,7 grupos de promedio para encontrar un espacio vacío en la tabla. Esto está bien y, dado que iteramos sobre los grupos de forma lineal, podemos esperar que la memoria esté bien precargada.
Del ejercicio anterior sabemos que nuestra función hash tarda unos 2 segundos. Por lo tanto, es justo decir que 40 millones de accesos a la memoria tardan alrededor de 4 segundos.
Qué hemos aprendido
Las CPU modernas son realmente buenas en el acceso secuencial a la memoria cuando es posible predecir patrones de búsqueda en la memoria (consulta Búsqueda previa de caché). El acceso aleatorio a la memoria, por otro lado, es muy costoso.
Las estructuras de datos avanzadas son muy interesantes, pero debemos tener cuidado. Las computadoras modernas requieren algoritmos optimizados para caché. Al trabajar con conjuntos de datos grandes, que no se ajustan a L3, es preferible la optimización para reducir el número de cargas, en lugar de la cantidad de memoria utilizada.
Supongo que es justo decir que los filtros de Bloom son geniales, siempre y cuando se ajusten a la caché L3. En el momento en que esto no es así, son un desastre. Esto no es ninguna novedad, los filtros de Bloom optimizan el uso de la memoria, no el acceso a la memoria. Por ejemplo, consulta el artículo sobre filtros Cuckoo.
Otra cosa es el eterno debate sobre las funciones hash. Sinceramente, en la mayoría de los casos carece de importancia. El coste de contabilizar incluso funciones hash complejas como 'siphash24' es pequeño en comparación con el coste del acceso aleatorio a la memoria. En nuestro caso, si simplificamos la función hash solo obtendremos pequeñas ventajas. El tiempo de CPU simplemente se consume en otro lugar: ¡esperando la memoria!
Un colega suele decir: "Podemos suponer que las CPU modernas son infinitamente rápidas. Se ejecutan a una velocidad infinita hasta que chocan contra el límite de la memoria".
Por último, no repitas mis errores: todo el mundo debería empezar a generar perfiles con 'perf stat -d' y a comprobar el contador de "Instrucciones por ciclo" (IPC). Si está por debajo de 1, normalmente indica que el programa está atascado esperando memoria. Los valores superiores a 2 serían excelentes, indicaría que la carga de trabajo está principalmente vinculada a la CPU. Lamentablemente, todavía no he visto valores altos en las cargas de trabajo con las que estoy trabajando...
Mmuniq mejorado
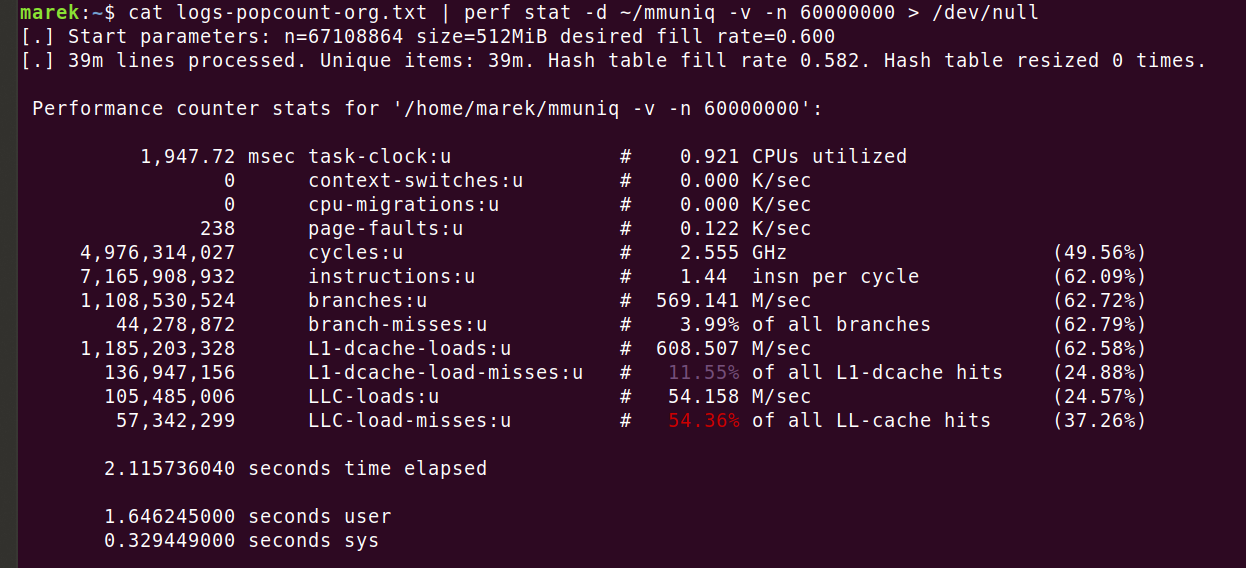
Con la ayuda de mis colegas he preparado una versión mejorada de la herramienta basada en tablas hash 'mmuniq'. Ve el código:
Puede redimensionar dinámicamente la tabla hash para admitir entradas de cardinalidad desconocida. Luego, mediante el procesamiento por lotes, puede utilizar con eficacia la sugerencia de CPU 'prefetch', acelerando el programa entre un 35 y un 40 %. Ten cuidado, utilizar el código con 'prefetch' no suele funcionar. En su lugar, cambia específicamente el flujo de algoritmos para aprovechar esta instrucción. Con todas las mejoras, conseguí que el tiempo de ejecución se redujera a 2,1 segundos:
Fin
Escribir esta herramienta básica que intenta ser más rápida que la combinación 'sort | uniq' reveló algunos tesoros ocultos de la informática moderna. Con un poco de trabajo logramos pasar de más de dos minutos a 2 segundos. Durante este proceso, aprendimos sobre la latencia del acceso a la memoria aleatoria y sobre el poder de las estructuras de datos compatibles con la caché. Las estructuras de datos sofisticadas son interesantes. Sin embargo, en la práctica, la reducción de las cargas de la memoria aleatoria a menudo brinda mejores resultados.