Vectorize es nuestra nueva solución de base de datos vectorial, diseñada para que puedas desarrollar aplicaciones de IA integrales en la red global de Cloudflare. ¡Empieza a usarla ya! La versión beta abierta de Vectorize ya está disponible para cualquier desarrollador que utilice Cloudflare Workers.
Puedes utilizar Vectorize con Workers AI para implementar casos de uso de búsqueda semántica, clasificación, recomendación y detección de anomalías directamente con Workers, mejorar la precisión y el contexto de las respuestas de los modelos de lenguaje de gran tamaño (LLM), y usar tus propias incrustaciones de plataformas populares, como OpenAI y Cohere.
Visita la documentación para desarrolladores de Vectorize para empezar, o sigue leyendo si quieres entender mejor qué hacen las bases de datos vectoriales y en qué se diferencia Vectorize.
¿Por qué necesito una base de datos vectorial?
Los modelos de aprendizaje automático no pueden recordar nada, excepto aquello en lo que fueron entrenados.
Las bases de datos vectoriales están diseñadas para resolver esta deficiencia, ya que registran la forma en que un modelo de aprendizaje automático representa los datos, tales como el texto estructurado y no estructurado, imágenes y audio, y los almacena para que puedas compararlos con entradas futuras. De esta forma puedes aprovechar la potencia de los modelos de aprendizaje automático y los LLM existentes para contenidos en los que no han sido entrenados, lo que, en vista del enorme coste que supone entrenar modelos, resulta sumamente eficaz.
Para explicar mejor las razones de la utilidad de una base de datos vectorial como Vectorize, hagamos como si no existieran, y veamos lo difícil que es dar contexto a un modelo de aprendizaje automático o LLM para una tarea de búsqueda semántica o de recomendación. Nuestro objetivo es comprender qué contenido es similar a nuestra consulta y devolverlo, basándonos en nuestro propio conjunto de datos.
- Llega la consulta de nuestro usuario, que busca "cómo escribir en R2 desde Cloudflare Workers".
- Cargamos todo nuestro conjunto de datos de documentación, un conjunto de datos afortunadamente "pequeño" de unas 65 000 frases, o 2,1 GB, y lo proporcionamos junto con la consulta de nuestro usuario. De esta forma, el modelo puede tener el contexto que necesita, basado en nuestros datos.
- Esperamos.
- (Mucho tiempo)
- Obtenemos nuestras puntuaciones de similitud, con las frases más parecidas a la consulta del usuario, y las volvemos a asociar a las URL antes de devolver los resultados de la búsqueda.
... y entonces llega otra consulta, y tenemos que volver a empezar.
En la práctica, esta práctica no es viable. No podemos pasar tanto contexto en una llamada API (consulta) a la mayoría de los modelos de aprendizaje automático, e incluso si pudiéramos, se necesitarían cantidades enormes de memoria y tiempo para procesar nuestro conjunto de datos una y otra vez.
Con una base de datos vectorial, no tenemos que repetir el paso 2. Lo realizamos una vez, o conforme se actualiza nuestro conjunto de datos, y utilizamos nuestra base de datos vectorial para proporcionar una forma de memoria a largo plazo a nuestro modelo de aprendizaje automático. Nuestro flujo de trabajo se parece un poco más a esto:
- Cargamos todo nuestro conjunto de datos de documentación, lo ejecutamos en nuestro modelo, y almacenamos las incrustaciones vectoriales resultantes en nuestra base de datos vectorial (solo una vez).
- Para cada consulta de usuario (y solo la consulta) preguntamos al mismo modelo y recuperamos una representación vectorial.
- Consultamos nuestra base de datos vectorial con ese vector de consulta, que nos devuelve los vectores más próximos a nuestro vector de consulta.
Si observamos estos dos flujos conjuntamente, podemos ver rápidamente lo ineficaz y poco práctico que es utilizar nuestro propio conjunto de datos con un modelo existente sin una base de datos vectorial:
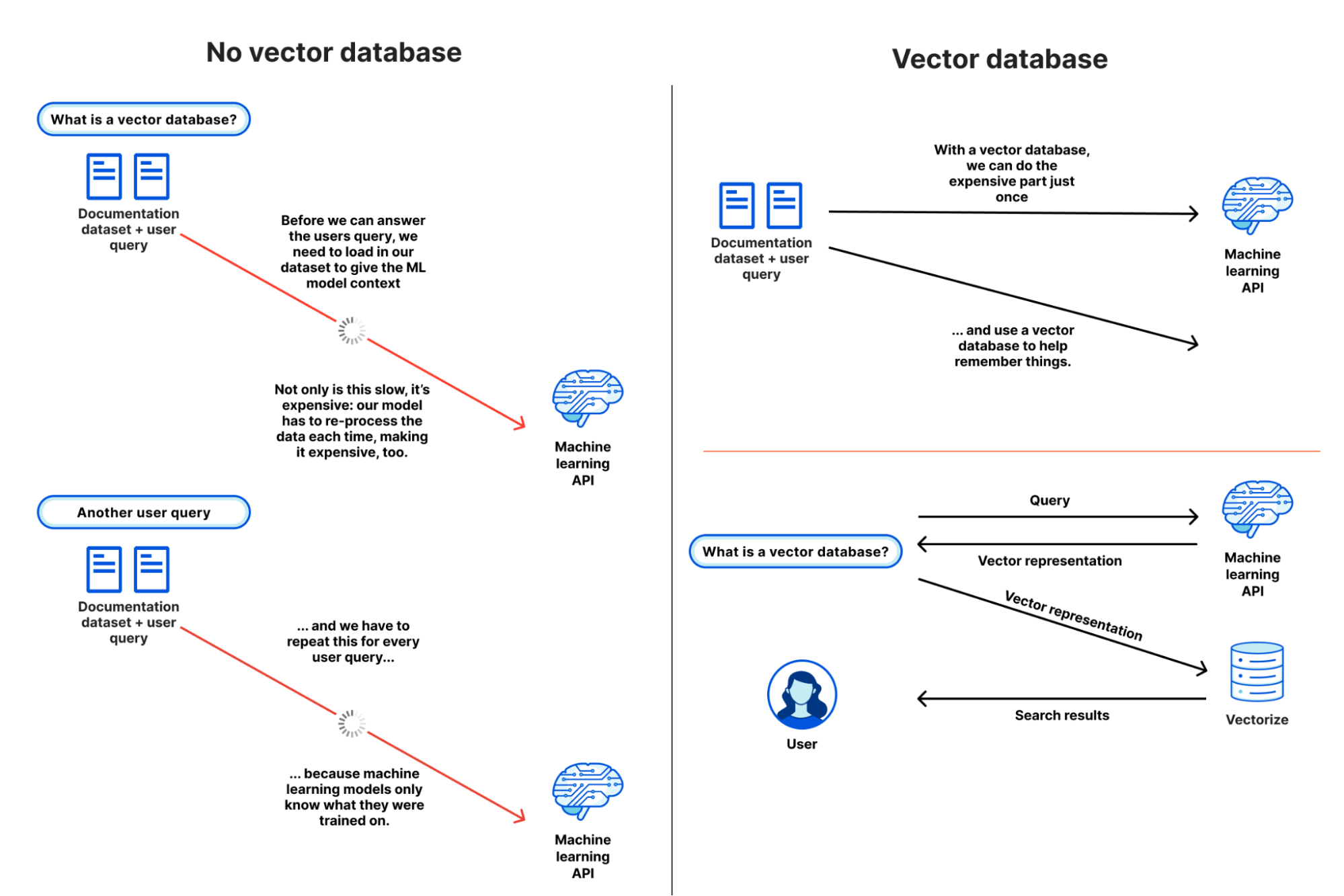
A partir de este ejemplo tan sencillo, puede que empiece a tener algún sentido, pero también puede que te preguntes por qué necesitas una base de datos vectorial en lugar de una base de datos normal.
Los vectores son la representación del modelo de una entrada, la forma en la que se asigna esa entrada a su estructura interna, o "funciones". A grandes rasgos, cuanto más parecidos sean los vectores, más parecido creerá el modelo que son esas entradas, basándose en cómo extrae las funciones de una entrada.
Parece fácil cuando nos fijamos en ejemplos de vectores de solo varias dimensiones, pero con resultados reales, la búsqueda entre 10 000 y 250 000 vectores, cada uno potencialmente de 1536 dimensiones, no es baladí. Aquí es donde entran en juego las bases de datos vectoriales. Para que la búsqueda funcione a escala, las bases de datos vectoriales utilizan una clase específica de algoritmos, como el algoritmo k vecinos más cercanos (kNN) u otros algoritmos de vecino más cercano aproximado (ANN) para determinar la similitud de los vectores.
Aunque las bases de datos vectoriales son muy útiles cuando se crean aplicaciones de IA y aprendizaje automático, también se pueden utilizar para numerosas tareas de clasificación y detección de anomalías. Saber si la entrada de una consulta es similar, o potencialmente diferente, a otras entradas puede servir también para tareas de moderación de contenidos (¿coincide con un contenido "malo conocido"?) y de alertas de seguridad (¿lo he visto antes?).
Creación de un motor de recomendación con búsqueda vectorial
Hemos creado Vectorize para que sea un fuerte aliado de Workers AI, de manera que puedas ejecutar tareas de búsqueda vectorial lo más cerca posible de los usuarios, y sin tener que pensar en cómo escalarlo para producción.
Veamos un ejemplo real: la creación de un motor de recomendación (de productos) para una tienda de comercio electrónico, y optimización de algunos aspectos.
Nuestro objetivo es mostrar una lista de "productos relevantes" en cada página de listado de productos, un caso de uso perfecto para la búsqueda vectorial. Nuestros vectores de entrada en el ejemplo son marcadores de posición, pero en una aplicación real los generaríamos basándonos en las descripciones de los productos o los datos de los carritos, ejecutándolos en un modelo de similitud de frases (como el modelo de incrustación de texto de Workers AI).
Cada vector representa un producto de nuestra tienda, y le asociamos la URL del producto. También podríamos definir el Id. de cada vector en el Id. del producto, ambos enfoques son válidos. Nuestra consulta, búsqueda vectorial, representa la descripción y el contenido del producto que el usuario está viendo en ese momento.
Veamos cómo se ve esto en código. Este ejemplo está sacado directamente de nuestra documentación para desarrolladores:
export interface Env {
// This makes our vector index methods available on env.MY_VECTOR_INDEX.*
// e.g. env.MY_VECTOR_INDEX.insert() or .query()
TUTORIAL_INDEX: VectorizeIndex;
}
// Sample vectors: 3 dimensions wide.
//
// Vectors from a machine-learning model are typically ~100 to 1536 dimensions
// wide (or wider still).
const sampleVectors: Array<VectorizeVector> = [
{ id: '1', values: [32.4, 74.1, 3.2], metadata: { url: '/products/sku/13913913' } },
{ id: '2', values: [15.1, 19.2, 15.8], metadata: { url: '/products/sku/10148191' } },
{ id: '3', values: [0.16, 1.2, 3.8], metadata: { url: '/products/sku/97913813' } },
{ id: '4', values: [75.1, 67.1, 29.9], metadata: { url: '/products/sku/418313' } },
{ id: '5', values: [58.8, 6.7, 3.4], metadata: { url: '/products/sku/55519183' } },
];
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
if (new URL(request.url).pathname !== '/') {
return new Response('', { status: 404 });
}
// Insert some sample vectors into our index
// In a real application, these vectors would be the output of a machine learning (ML) model,
// such as Workers AI, OpenAI, or Cohere.
let inserted = await env.TUTORIAL_INDEX.insert(sampleVectors);
// Log the number of IDs we successfully inserted
console.info(`inserted ${inserted.count} vectors into the index`);
// In a real application, we would take a user query - e.g. "durable
// objects" - and transform it into a vector emebedding first.
//
// In our example, we're going to construct a simple vector that should
// match vector id #5
let queryVector: Array<number> = [54.8, 5.5, 3.1];
// Query our index and return the three (topK = 3) most similar vector
// IDs with their similarity score.
//
// By default, vector values are not returned, as in many cases the
// vectorId and scores are sufficient to map the vector back to the
// original content it represents.
let matches = await env.TUTORIAL_INDEX.query(queryVector, { topK: 3, returnVectors: true });
// We map over our results to find the most similar vector result.
//
// Since our index uses the 'cosine' distance metric, scores will range
// from 1 to -1. A value of '1' means the vector is the same; the
// closer to 1, the more similar. Values of -1 (least similar) and 0 (no
// match).
// let closestScore = 0;
// let mostSimilarId = '';
// matches.matches.map((match) => {
// if (match.score > closestScore) {
// closestScore = match.score;
// mostSimilarId = match.vectorId;
// }
// });
return Response.json({
// This will return the closest vectors: we'll see that the vector
// with id = 5 has the highest score (closest to 1.0) as the
// distance between it and our query vector is the smallest.
// Return the full set of matches so we can see the possible scores.
matches: matches,
});
},
};
El código anterior es sencillo de manera intencionada, pero muestra la búsqueda vectorial en su esencia. Insertamos vectores en nuestra base de datos y buscamos vectores próximos a nuestro vector de consulta.Aquí están los resultados, con los valores incluidos, para que observemos visualmente que nuestro vector de consulta [54,8, 5,5, 3,1] es similar a nuestra coincidencia de mayor puntuación: [58 799, 6699, 3400] que ha devuelto nuestra búsqueda. Este índice utiliza la similitud coseno para calcular la distancia entre vectores, lo que significa que cuanto más se acerque la puntuación a 1, más similar es una coincidencia a nuestro vector de consulta.
{
"matches": {
"count": 3,
"matches": [
{
"score": 0.999909,
"vectorId": "5",
"vector": {
"id": "5",
"values": [
58.79999923706055,
6.699999809265137,
3.4000000953674316
],
"metadata": {
"url": "/products/sku/55519183"
}
}
},
{
"score": 0.789848,
"vectorId": "4",
"vector": {
"id": "4",
"values": [
75.0999984741211,
67.0999984741211,
29.899999618530273
],
"metadata": {
"url": "/products/sku/418313"
}
}
},
{
"score": 0.611976,
"vectorId": "2",
"vector": {
"id": "2",
"values": [
15.100000381469727,
19.200000762939453,
15.800000190734863
],
"metadata": {
"url": "/products/sku/10148191"
}
}
}
]
}
}
En una aplicación real, podríamos devolver ahora rápidamente las URL de recomendación de productos basadas en los productos más similares, ordenándolos por su puntuación (de mayor a menor), y aumentando el valor topK si queremos mostrar más. Los metadatos almacenados junto a cada vector también podrían incluir una ruta a un objeto R2, un identificador único universal (UUID) para una fila de una base de datos D1, o un par clave-valor de Workers KV.
Workers AI y Vectorize: búsqueda vectorial integral en Cloudflare
En una aplicación real, necesitamos un modelo de aprendizaje automático que pueda tanto generar incrustaciones vectoriales a partir de nuestro conjunto de datos original (para rellenar inicialmente nuestra base de datos) como convertir también rápidamente las consultas de los usuarios en incrustaciones vectoriales. Tienen que proceder del mismo modelo, ya que cada modelo representa las funciones de forma diferente.
Aquí tienes un ejemplo resumido de creación de un proceso completo de búsqueda vectorial de principio a fin en Cloudflare:
import { Ai } from '@cloudflare/ai';
export interface Env {
TEXT_EMBEDDINGS: VectorizeIndex;
AI: any;
}
interface EmbeddingResponse {
shape: number[];
data: number[][];
}
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
const ai = new Ai(env.AI);
let path = new URL(request.url).pathname;
if (path.startsWith('/favicon')) {
return new Response('', { status: 404 });
}
// We only need to generate vector embeddings just the once (or as our
// data changes), not on every request
if (path === '/insert') {
// In a real-world application, we could read in content from R2 or
// a SQL database (like D1) and pass it to Workers AI
const stories = ['This is a story about an orange cloud', 'This is a story about a llama', 'This is a story about a hugging emoji'];
const modelResp: EmbeddingResponse = await ai.run('@cf/baai/bge-base-en-v1.5', {
text: stories,
});
// We need to convert the vector embeddings into a format Vectorize can accept.
// Each vector needs an id, a value (the vector) and optional metadata.
// In a real app, our ID would typicaly be bound to the ID of the source
// document.
let vectors: VectorizeVector[] = [];
let id = 1;
modelResp.data.forEach((vector) => {
vectors.push({ id: `${id}`, values: vector });
id++;
});
await env.TEXT_EMBEDDINGS.upsert(vectors);
}
// Our query: we expect this to match vector id: 1 in this simple example
let userQuery = 'orange cloud';
const queryVector: EmbeddingResponse = await ai.run('@cf/baai/bge-base-en-v1.5', {
text: [userQuery],
});
let matches = await env.TEXT_EMBEDDINGS.query(queryVector.data[0], { topK: 1 });
return Response.json({
// We expect vector id: 1 to be our top match with a score of
// ~0.896888444
// We are using a cosine distance metric, where the closer to one,
// the more similar.
matches: matches,
});
},
};
El código anterior hace las siguientes cuatro acciones:
- Pasa las tres frases al modelo de incrustación de texto de Workers AI (@cf/baai/bge-base-en-v1.5) y recupera sus incrustaciones vectoriales.
- Inserta esos vectores en nuestro índice Vectorize.
- Coge la consulta del usuario y la transforma en una incrustación vectorial mediante el mismo modelo Workers AI.
- Busca coincidencias en nuestro índice Vectorize.
Este ejemplo puede parecer "demasiado" sencillo, pero en una aplicación de producción, solo tendríamos que cambiar dos cosas: insertar nuestros vectores una sola vez (o periódicamente a través Cron Triggers), y sustituir nuestras tres frases de ejemplo por datos reales almacenados en R2, una base de datos D1 u otro proveedor de almacenamiento.
De hecho, este ejemplo es increíblemente similar a cómo ejecutamos Cursor, el asistente de IA que puede responder preguntas sobre Cloudflare Worker. Migramos Cursor para que se ejecutara en Workers AI y Vectorize. Generamos incrustaciones de texto de nuestra documentación para desarrolladores utilizando su modelo de incrustación de texto incorporado, las insertamos en un índice Vectorize y transformamos las consultas de los usuarios sobre la marcha a través de ese mismo modelo.
Incrustaciones propias desde tu API de IA favorita
Sin embargo, Vectorize no se limita a Workers AI. Es una base de datos vectorial independiente y completa.
Si ya utilizas la API de incrustación de OpenAI, el modelo multilingüe de Cohere, o cualquier otra API de incrustación, puedes añadir fácilmente tus propios vectores a Vectorize.
Funciona igual. Genera tus incrustaciones, insértalas en Vectorize y pasa tus consultas por el modelo antes de consultar tu índice. Vectorize incluye algunos atajos para algunos de los modelos de incrustación más populares.
# Vectorize has ready-to-go presets that set the dimensions and distance metric for popular embeddings models
$ wrangler vectorize create openai-index-example --preset=openai-text-embedding-ada-002
Este proceso puede ser especialmente útil si ya tienes un flujo de trabajo en torno a una API de incrustaciones existente, o si has validado un modelo de incrustaciones multimodal o multilingüe específico para tu caso de uso.
Previsibilidad del coste de la IA
Hay un gran entusiasmo en torno a la inteligencia artificial y el aprendizaje automático, pero también una gran preocupación acerca del elevado coste de experimentación y la dificultad de predecir a escala.
Con Vectorize, queríamos simplificar el modelo de precios de las bases de datos vectoriales. ¿Tienes una idea para una prueba de concepto en el trabajo? Debería encajar en nuestros límites de nivel gratuito. ¿Estás ampliando y optimizando tus dimensiones de incrustación en función del rendimiento vs. precisión? No debería salirte caro.
Y lo que es más importante, Vectorize pretende ser predecible. No necesitas estimar el consumo de CPU y memoria, lo que puede ser difícil cuando estás empezando, e incluso más cuando intentas planificar tus horas de máxima y mínima actividad en producción para un caso de uso totalmente nuevo. En lugar de eso, se te cobra en función del número total de dimensiones vectoriales que almacenes y del número de consultas que realices sobre ellas cada mes. Nosotros nos encargamos de escalar para satisfacer tus patrones de consulta.
Estos son los precios de Vectorize, y si tienes un plan de pago Workers, Vectorize es totalmente gratuito hasta 2024:
| Workers: versión gratuita (próximamente) | Workers: versión de pago (5 USD/mes) | |
|---|---|---|
| Incluye dimensiones vectoriales consultadas | 30 millones de dimensiones consultadas/mes | 50 millones de dimensiones consultadas/mes |
| Incluye dimensiones vectoriales almacenadas | 5 millones de dimensiones almacenadas/mes | 10 millones de dimensiones almacenas/mes |
| Coste adicional | 0,04 USD/1 millón de dimensiones vectoriales consultadas o almacenadas | 0,04 USD/1 millón de dimensiones vectoriales consultadas o almacenadas |
El precio se basa solo en lo que almacenas y consultas: (dimensiones vectoriales totales consultadas + almacenadas) * dimensiones_por_vector * precio. ¿Realizas más consultas? Es fácil de predecir. ¿Deseas optimizar para dimensiones más pequeñas por vector para mejorar la velocidad y reducir la latencia general? El coste baja. ¿Tienes unos cuantos índices para crear prototipos o experimentar con nuevos casos de uso? No cobramos por índice.
Por ejemplo, si cargas 10 000 vectores de Workers AI (384 dimensiones cada uno) y realizas 5000 consultas en tu índice cada día, el resultado sería un total de 49 millones de dimensiones de vectores consultadas y aun así se ajustaría a lo que incluimos en el plan de pago de Workers (5 USD/mes). Mejor aún: no eliminamos tus índices por inactividad.
Ten en cuenta que, aunque estos precios no son definitivos, apenas esperamos cambios en el futuro. Queremos evitar sorpresas. No hay nada peor que empezar a crear en una plataforma y darse cuenta de que el precio es insostenible después de haber invertido tiempo escribiendo código, pruebas y aprendiendo los matices de una tecnología.
¡Vectorize!
Todos los desarrolladores de Workers que tengan un plan de pago pueden empezar a utilizar Vectorize desde ya. La versión beta abierta ya está disponible, y puedes consultar nuestra documentación para desarrolladores para empezar.
Esto es solo el principio del recorrido de la base de datos vectorial en Cloudflare. En las próximas semanas y meses, tenemos la intención de lanzar un nuevo motor de consultas que debería seguir mejorando el rendimiento de las consultas, admitir índices aún mayores, incorporar capacidades de filtrado de subíndices, mayores límites de metadatos y análisis por índice.
Si buscas inspiración sobre lo que puedes crear consulta el tutorial de búsqueda semántica, que combina Workers AI y Vectorize para la búsqueda de documentos, y que se ejecuta íntegramente en Cloudflare. También puedes consultar un ejemplo de cómo combinar OpenAI y Vectorize para dar más contexto a un LLM y mejorar significativamente la precisión de sus respuestas.
Y si quieres consultar cómo utilizar Vectorize con nuestros equipos de producto e ingeniería, o deseas compartir una idea con otros desarrolladores que trabajan con Workers AI, únete a los canales #vectorize y #workers-ai en Discord.