

Hoy, un cambio en nuestro sistema Tiered Cache ha originado un fallo en algunas solicitudes que ha llevado a los usuarios a recibir un error de código de estado 530. El impacto ha durado casi seis horas en total. Calculamos que alrededor del 5 % de todas las solicitudes fallaron en el punto álgido del incidente. La complejidad de nuestro sistema y un punto ciego en nuestras pruebas evitaron la detección cuando lanzamos el cambio en nuestro entorno de pruebas.
Los fallos obedecían a los efectos secundarios de la forma en que gestionamos las solicitudes almacenables en caché en las distintas ubicaciones. A primera vista, los errores parecían estar causados por un sistema diferente que había iniciado una versión un poco antes. Hicieron falta varios intentos para que nuestros equipos identificaran exactamente la raíz del problema. Una vez identificado, aceleramos una reversión que se completó en 87 minutos.
Lo lamentamos y estamos tomando las medidas necesarias para garantizar que no vuelva a ocurrir.
Antecedentes
Uno de los productos de Cloudflare es nuestra red de entrega de contenido, o CDN. Se utiliza para almacenar en caché los activos de los sitios web a nivel global, si bien no se garantiza que un centro de datos tenga un activo almacenado en caché, ya que puede ser nuevo, haber caducado o haber sido purgado. Si eso ocurre, y un usuario solicita ese activo, nuestra CDN necesita recuperar una copia nueva del servidor de origen del sitio web. Sin embargo, el centro de datos al que accede el usuario puede estar muy lejos del servidor de origen, lo que supone un problema adicional para los clientes. Cada vez que un activo no se almacena en la caché del centro de datos, tenemos que recuperar una copia nueva del servidor de origen.
Con el fin de mejorar la proporción de aciertos de la caché, desarrollamos Tiered Cache. Con este sistema, organizamos nuestros centros de datos en la CDN en una jerarquía de "niveles inferiores" que están más cerca de los usuarios finales y "niveles superiores" que están más cerca del servidor de origen. Cuando se produce un fallo de la caché en un nivel inferior, se comprueba el nivel superior. Si este tiene una copia nueva del activo, podemos servirla en respuesta a la solicitud. Esto mejora el rendimiento y reduce la cantidad de veces que Cloudflare tiene que recurrir a un servidor de origen para recuperar activos que no están almacenados en caché en los centros de datos de nivel inferior.
Cronología e impacto del incidente
A las 08:40 UTC comenzó el despliegue gradual de una versión de software de un componente de la CDN que contenía un error. El fallo se inició cuando un usuario estaba visitando un sitio que tenía configurado Tiered Cache, Cloudflare Images o Bandwidth Alliance. Este fallo devolvía a un subconjunto de clientes el código de estado HTTP 530, un error. El contenido que se podía servir directamente desde la caché local de un centro de datos no se vio afectado.
Iniciamos una investigación después de que los clientes notificaran un aumento intermitente de errores 530 una vez se lanzó el componente defectuoso a un subconjunto de centros de datos.
Cuando el lanzamiento comenzó a desplegarse globalmente al resto de los centros de datos, el aumento de los errores 530 activó las alertas, junto con los informes de los clientes. Fue entonces cuando se comunicó el incidente.
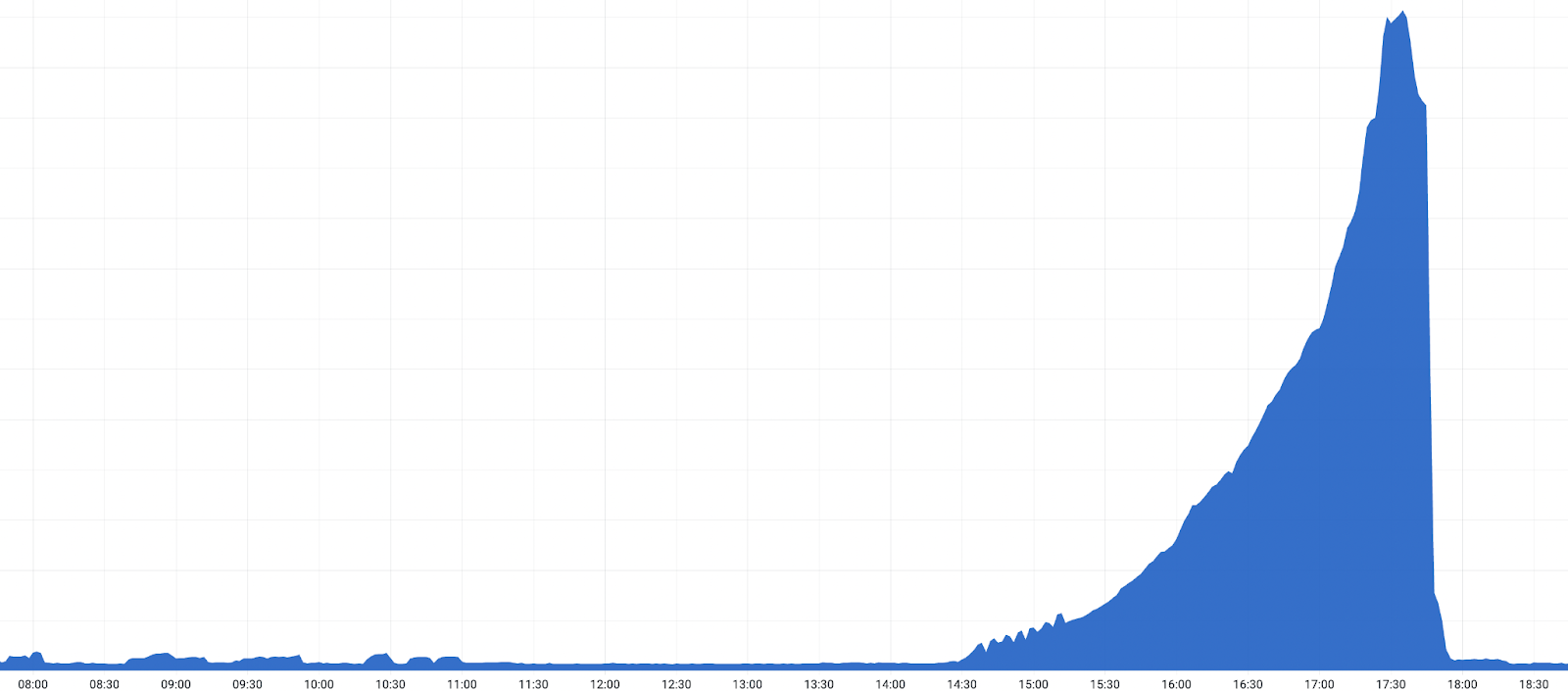
Confirmamos que la causa era una versión incorrecta tras revertir la versión en un centro de datos a las 17:03 UTC. Tras ello, observamos un descenso de los errores 530. Después de esta confirmación, se inició una reversión global acelerada y los errores 530 empezaron a disminuir. El impacto finalizó una vez que se revirtió la versión en todos los centros de datos configurados como niveles superiores de Tiered Cache a las 18:04 UTC.
Cronograma
- 25-10-2022 / 08:40: se inicia el despliegue de la versión en un pequeño subconjunto de centros de datos.
- 25-10-2022 / 10:35: se activa una alerta de cliente individual, que indica un aumento de los códigos de error 500.
- 25-10-2022 / 11:20: tras una investigación, se identifica un único centro de datos pequeño como origen del problema y se retira de la producción mientras los equipos investigan el problema en el mismo.
- 25-10-2022 / 12:30: el problema comienza a extenderse más ampliamente a medida que más centros de datos reciben los cambios de código.
- 25-10-2022 / 14:22: aumentan los errores 530 conforme la versión comienza a extenderse de forma gradual a nuestros centros de datos más grandes.
- 25-10-2022 / 14:39: se suman varios equipos a la investigación conforme más clientes empiezan a notificar un aumento de los errores.
- 25-10-2022 / 17:03: la versión de la CDN se revierte en Atlanta y se confirma la raíz del problema.
- 25-10-2022 / 17:28: punto álgido del impacto en el que aproximadamente un 5 % de todas las solicitudes HTTP devuelven un error con código de estado 530.
- 25-10-2022 / 17:38: continúa una reversión acelerada con grandes centros de datos que actúan como nivel superior para muchos clientes.
- 25-10-2022 / 18:04: la reversión se ha completado en todos los niveles superiores.
- 25-10-2022 / 18:30: se completa la reversión.
Durante las primeras fases de la investigación, los indicadores apuntaban a que se trataba de un problema con nuestro sistema DNS interno, del que se estaba desplegando una versión al mismo tiempo. Como se muestra en la siguiente sección, esto solo fue un efecto secundario y no la causa de la interrupción.
La incorporación del rastreo distribuido a Tiered Cache fue la causa del problema
Para ayudar a mejorar nuestro rendimiento, añadimos habitualmente código de monitorización en varias partes de nuestros servicios. El código de monitorización nos ayuda a conocer el rendimiento de los distintos componentes, lo que nos permite determinar los cuellos de botella que podemos mejorar. Recientemente, nuestro equipo ha añadido un rastreo distribuido adicional a nuestra lógica de Tiered Cache. El código del punto de entrada del sistema Tiered Cache es el siguiente:
* Antes:
function _M.go()
-- code to run here
end
* Después:
local trace_fn = require("opentracing").trace_fn
local function go()
-- code to run here
end
function _M.go()
trace_fn(ngx.ctx, "tiered_cache_rewrite", go)
endEl código anterior encapsula la función go() existente con trace_fn(), que llamará a la función go() y luego informará de su tiempo de ejecución.
Sin embargo, la lógica que inyecta una función al módulo opentracing borra los encabezados de control en cada solicitud:
require("opentracing").configure_module(conf,
-- control header extractor
function(ctx)
-- Always clear the headers.
clear_control_headers()
-- Normalmente, extraemos los datos de estos encabezados de control antes de borrarlos como parte rutinaria de cómo procesamos las solicitudes.
Sin embargo, el tráfico interno de Tiered Cache espera que los encabezados de control del nivel inferior se transmitan tal cual. La combinación de la extracción de los encabezados y el uso de un nivel superior impidió que la información que podría ser crítica para el enrutamiento de la solicitud estuviera disponible. En el subconjunto de solicitudes afectadas, nos faltaba el nombre de servidor para resolver mediante nuestra búsqueda interna de DNS las direcciones IP del servidor de origen. Como resultado, se devolvía al cliente un error de DNS 530.
Medidas de corrección y seguimiento
Para evitar que esto vuelva a ocurrir, además de solucionar el error, hemos identificado un conjunto de cambios que nos ayudarán a detectar y prevenir problemas como este en el futuro:
- Incorporación de un centro de datos más grande que se configure como un nivel superior de Tiered Cache en una fase anterior del plan de lanzamiento. Esto nos permitirá detectar problemas similares más rápido, antes de un lanzamiento global.
- Ampliación de nuestra cobertura de pruebas de aceptación para incluir un conjunto más amplio de configuraciones, incluidas varias topologías de Tiered Cache.
- Alertar de forma más contundente en situaciones en las que no tenemos el contexto completo de las solicitudes, y necesitamos la información adicional del servidor en los encabezados de control.
- Asegurarnos de que nuestro sistema falla rápidamente en un error como este, lo que habría ayudado a identificar el problema durante el desarrollo y las pruebas.
Conclusión
Experimentamos un incidente que afectó a un conjunto importante de clientes que utilizaban Tiered Cache. Tras identificar el componente defectuoso, pudimos revertir rápidamente el problema y solucionarlo. Lamentamos el trastorno ocasionado a nuestros clientes y usuarios finales que intentaban acceder a los servicios.
Pondremos en marcha soluciones lo antes posible para evitar que se produzcan incidentes de este tipo en el futuro.