


Cloudflare ya puede identificar de forma automática todos los puntos finales de la API y aprender los esquemas de la API para todos nuestros clientes de API Gateway Los clientes pueden empezar a utilizar estas nuevas funciones para aplicar un modelo de seguridad positivo en los puntos finales de sus API, incluso si tienen poca o ninguna información sobre sus API actuales.
El primer paso para proteger tus API es conocer tus nombres de host y puntos finales. A menudo sabemos que los clientes se ven obligados a iniciar la labor de catalogación y gestión de sus API con algo parecido a: "Enviamos por correo electrónico una hoja de cálculo y pedimos a los desarrolladores que enumeren todos sus puntos finales".
¿Te imaginas los problemas que conlleva este enfoque? Tal vez los hayas sufrido en primera persona. El enfoque de "enviar un correo electrónico y preguntar" crea un inventario puntual que probablemente cambiará con la próxima versión del código. Se basa en un conocimiento tribal que puede desaparecer cuando la gente deja la organización. Por último, pero no por ello menos importante, es susceptible al error humano.
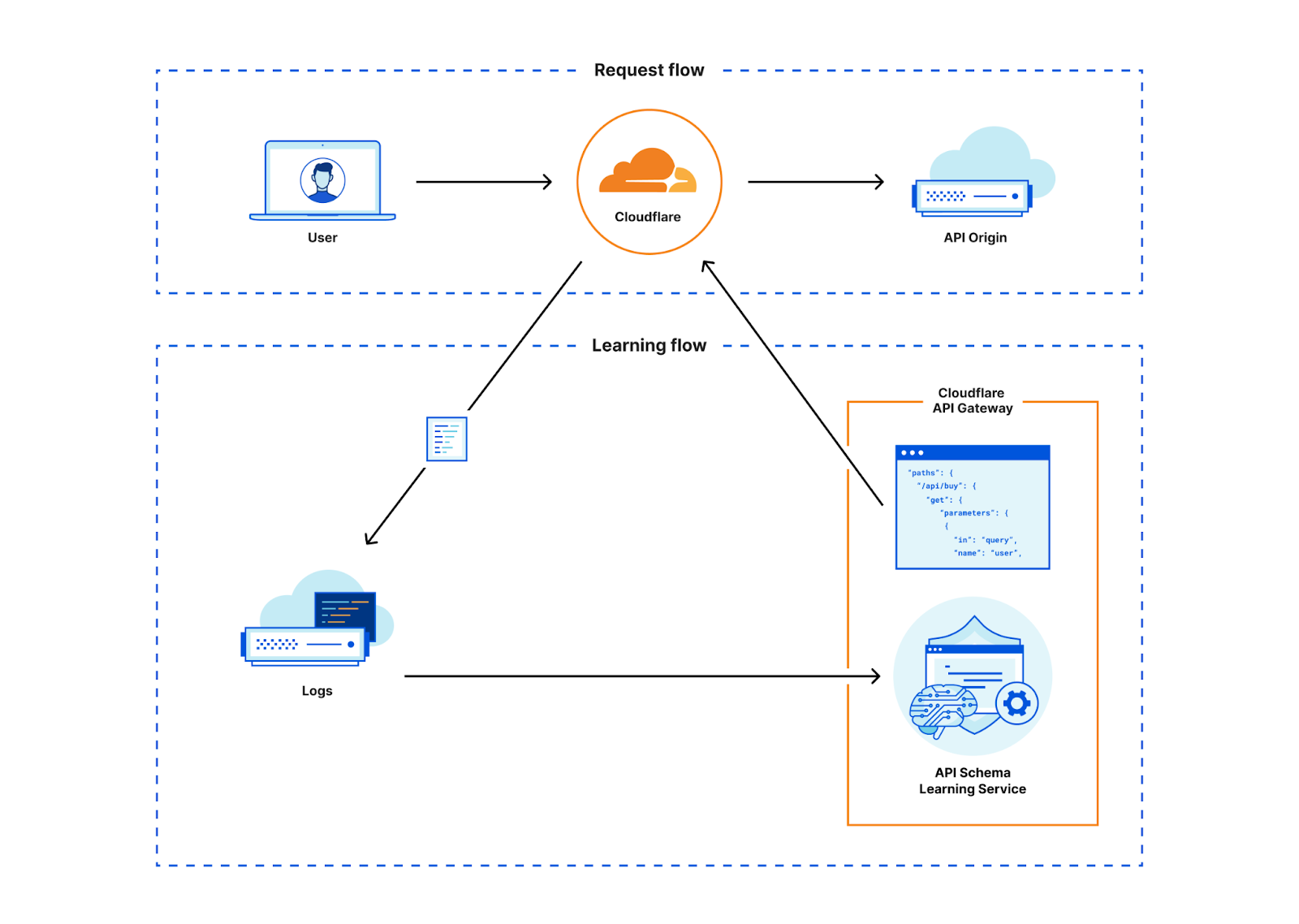
Aunque dispusieras de un inventario preciso de las API resultado de un trabajo en equipo, validar que la API se está utilizando según lo previsto aplicando un esquema de API requerirá mayor conocimiento colectivo para crear ese esquema. Ahora, las nuevas funciones API Discovery y Schema Learning de API Gateway se combinan para proteger automáticamente las API en toda la red global de Cloudflare y eliminar la necesidad de identificar las API de forma manual y crear esquemas.
API Gateway identifica y protege las API
API Gateway identifica las API a través de una función denominada API Discovery. Antes, API Discovery utilizaba identificadores de sesión específicos del cliente (encabezados HTTP o cookies) para identificar los puntos finales de la API y mostrar sus análisis a nuestros clientes.
La identificación funcionaba de esta forma, pero presentaba tres inconvenientes:
- Los clientes tenían que saber qué encabezado o cookie utilizaban para definir las sesiones. Si bien los identificadores de sesión son habituales, encontrar el token adecuado para utilizarlos puede llevar tiempo.
- El hecho de necesitar un identificador de sesión para API Discovery nos impedía supervisar e informar sobre las API que no estaban plenamente autenticadas. Hoy en día, los clientes siguen queriendo visibilidad del tráfico sin sesión para garantizar que todos los puntos finales de sus API están documentados y de que el abuso es mínimo.
- Una vez introducido el identificador de sesión en el panel de control, los clientes tenían que esperar hasta 24 horas para que se completara el proceso de identificación. A nadie le gusta esperar.
Aunque este enfoque tenía sus inconvenientes, sabíamos que podíamos ofrecer rápidamente valor a los clientes empezando con un producto basado en sesiones. A medida que ganábamos clientes y transitaba más tráfico por el sistema, sabíamos que nuestros nuevos datos etiquetados serían sumamente útiles para seguir desarrollando nuestro producto. Si pudiéramos entrenar un modelo de aprendizaje automático con nuestros metadatos de API y los nuevos datos etiquetados, ya no necesitaríamos un identificador de sesión para señalar qué puntos finales correspondían a las API. Así que decidimos crear este nuevo enfoque.
Recopilamos todo lo aprendido a partir de los datos basados en el identificador de sesión y desarrollamos un modelo de aprendizaje automático para revelar todo el tráfico de API a un dominio, independientemente del identificador de sesión. Con nuestro nueva función API Discovery basada en el aprendizaje automático, Cloudflare identifica continuamente todo el tráfico de la API enrutado a través de nuestra red sin que el cliente tenga que intervenir. Con esta versión, los clientes de API Gateway podrán empezar a utilizar API Discovery más rápido que nunca, e identificarán API no autenticadas que antes no podían identificar.
Los identificadores de sesión siguen siendo importantes para API Gateway, ya que constituyen la base de nuestros límites de velocidad para prevenir los abusos volumétricos, así como de nuestro servicio de análisis de secuencias. Más información sobre cómo funciona el nuevo enfoque en la sección "Cómo funciona" que encontrarás más abajo.
Protección de la API desde cero
Ahora que has identificado nuevas API mediante API Discovery, ¿cómo las proteges? Para protegerse de los ataques, los desarrolladores de API deben saber exactamente cómo esperan que se utilicen sus API. Por suerte, pueden generar mediante programación un archivo de esquema de API que codifique las entrada aceptables para una API y cargarlo en la validación de esquemas de API Gateway.
Sin embargo, ya hemos hablado de que muchos clientes no pueden encontrar sus API al ritmo que los desarrolladores las crean. Cuando encuentran las API, es muy difícil desarrollar con precisión un esquema OpenAPI único para cada uno de los cientos de puntos finales de API potenciales, dado que los equipos de seguridad rara vez ven más que el método de solicitud HTTP y la ruta en sus registros.
Cuando examinamos los patrones de uso de API Gateway, observamos que los clientes identificaban las API, pero casi nunca aplicaban un esquema. Cuando les preguntamos "¿por qué no?", la respuesta fue sencilla: "Incluso cuando sé que existe una API, me lleva mucho tiempo averiguar quién es el propietario de cada una para que me pueda proporcionar un esquema. Me cuesta priorizar este trabajo sobre otras tareas de seguridad imprescindibles". La falta de tiempo y experiencia era la mayor carencia de nuestros clientes para habilitar las protecciones.
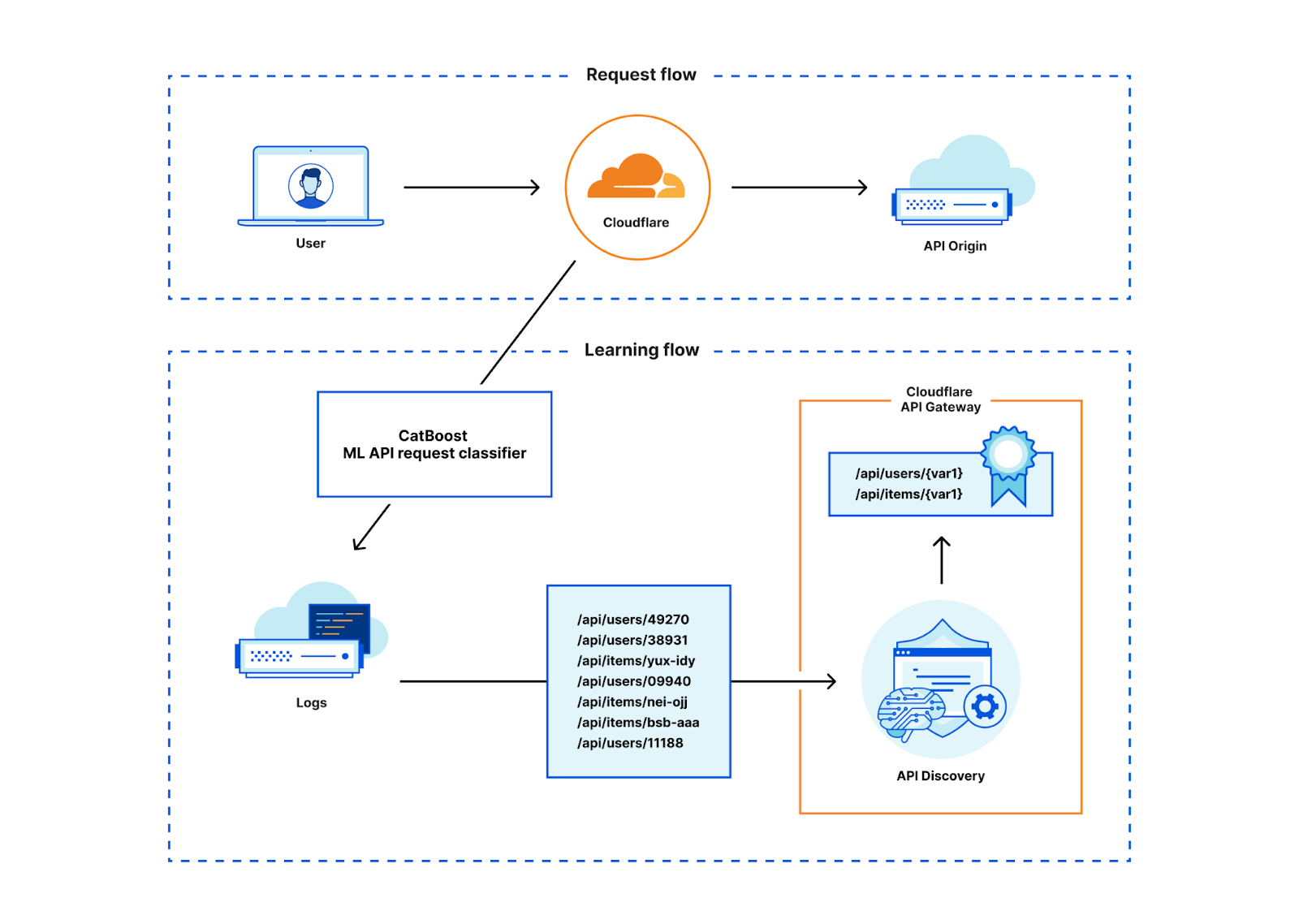
Así que decidimos poner remedio. Descubrimos que el mismo proceso de aprendizaje que utilizábamos para identificar los puntos finales de las API se podía aplicar a los puntos finales una vez identificados para aprender automáticamente un esquema. Con este método, ahora podemos generar un esquema con formato OpenAPI para cada punto final que identifiquemos, en tiempo real. A esta nueva función la llamamos Schema Learning. A continuación, los clientes pueden cargar ese esquema generado por Cloudflare en la validación de esquemas para aplicar un modelo de seguridad positivo.
Cómo funciona
Identificación de las API a través del aprendizaje automático
Con las API RESTful, las solicitudes se componen de diferentes métodos y rutas HTTP. Tomemos como ejemplo la API de Cloudflare. Observarás una tendencia común en las rutas que puede hacer que las solicitudes a esta API destaquen entre las solicitudes a este blog. Todas las solicitudes de API empiezan por /client/v4 y continúan con el nombre del servicio, un identificador único y, a veces, nombres de las funciones del servicio y otros identificadores.
¿Cómo podríamos identificar fácilmente las solicitudes de API? A primera vista, estas solicitudes parecen fáciles de identificar mediante programación con una heurística como "la ruta empieza por /cliente", pero el núcleo de nuestra nueva función Discovery contiene un modelo de aprendizaje automático que activa un clasificador que puntúa las transacciones HTTP. Si las rutas de API están tan estructuradas, ¿por qué se necesita el aprendizaje automático para este proceso y no se puede utilizar una simple heurística?
La respuesta se reduce a la siguiente pregunta: ¿qué constituye realmente una solicitud API y en qué se diferencia de una solicitud no basada en API? Veamos dos ejemplos.
Al igual que la API de Cloudflare, muchas de las API de nuestros clientes siguen patrones como anteponer a la ruta de su solicitud de API un identificador "api" y una versión, por ejemplo /api/v2/user/7f577081-7003-451e-9abe-eb2e8a0f103d.
Así que buscar simplemente "api" o una versión en la ruta ya es una heurística bastante buena que nos indica que es muy probable que esto forme parte de una API, pero desgraciadamente no siempre es tan fácil.
Consideremos otros dos ejemplos, /users/7f577081-7003-451e-9abe-eb2e8a0f103d.jpgy /users/7f577081-7003-451e-9abe-eb2e8a0f103d, ambos solo difieren en una extensión .jpg. La primera ruta podría ser simplemente un recurso estático, como la miniatura de un usuario. La segunda ruta no nos da muchas pistas solo por la ruta.
La elaboración manual de este tipo de heurística se complica al instante. Aunque a los humanos se nos da muy bien encontrar patrones, elaborar heurísticas es todo un reto si tenemos en cuenta la magnitud de los datos que Cloudflare observa cada día. Por ello, utilizamos el aprendizaje automático, para derivar de forma automática estas heurísticas de forma que sepamos que son reproducibles y que cumplen una cierta precisión.
La información para el entrenamiento son funciones de las muestras de solicitud/respuesta HTTP, como el tipo de contenido o la extensión de archivo, que recopilamos mediante la función Discovery basada en identificadores de sesión que hemos mencionado anteriormente. Lamentablemente, no todo lo que tenemos en estos datos es claramente una API. Además, también necesitamos muestras que representen tráfico no basado en API. Por ello, empezamos con los datos de Discovery basados en identificadores de sesión, los limpiamos manualmente y obtuvimos más muestras de tráfico no basado en API. Hemos tenido mucho cuidado de no ajustar en exceso el modelo a los datos, es decir, queremos que el modelo no solo se ciña a los datos de entrenamiento.
Para entrenar el modelo, hemos utilizado la biblioteca CatBoost, que ya conocemos muy bien, ya que también la utilizamos en nuestros modelos de aprendizaje automático de gestión de bots. Para simplificar, podemos considerar el modelo resultante como un diagrama de flujo que nos indica qué condiciones debemos comprobar en orden, por ejemplo: si la ruta contiene "api", comprueba también si no hay extensión de archivo, etc. Al final de este diagrama de flujo hay una puntuación que nos indica la probabilidad de que una transacción HTTP pertenezca a una API.
Dado el modelo entrenado, podemos insertar funciones de las solicitudes/respuestas HTTP que pasan por la red de Cloudflare y calcular la probabilidad de que esta transacción HTTP pertenezca o no a una API. La extracción de funciones y la puntuación del modelo se realizan en Rust y solo tardan un par de microsegundos en nuestra red global. Como Discovery obtiene los datos de nuestro mapa de datos eficaz, en realidad no es necesario puntuar cada transacción. Podemos reducir la carga de nuestros servidores puntuando solo las transacciones que sabemos que acabarán en nuestro mapa de datos, ahorrando así tiempo de CPU y permitiendo que la función sea rentable.
Con los resultados de la clasificación en nuestro mapa de datos, podemos utilizar el mismo mecanismo de API Discovery que hemos estado utilizando para la identificación basada en el identificador de sesión. Este sistema existente funciona muy bien y nos permite reutilizar el código de forma eficaz. También nos ayudó a la hora de comparar nuestros resultados con la función Discovery basada en el identificador de sesión, ya que los sistemas son directamente comparables.
Para que los resultados de API Discovery sean útiles, la primera tarea de Discovery es simplificar las rutas únicas que vemos en variables. Ya hemos hablado de esto antes. No es baladí deducir los distintos esquemas de identificadores que observamos en la red global, especialmente cuando los sitios utilizan identificadores personalizados más allá de un identificador único global (GUID) directo o un formato entero. API Discovery normaliza adecuadamente las rutas que contienen variables con la ayuda de unos cuantos clasificadores de variables diferentes y un proceso de aprendizaje supervisado.
Solo después de normalizar las rutas, los resultados de Discovery estarán listos para que nuestros usuarios los utilicen de forma sencilla.
Los resultados: cientos de puntos finales identificados por cliente
Entonces, ¿cómo se compara la identificación basada en el aprendizaje automático con la identificación basada en identificadores de sesión, que se basa en encabezados o cookies para etiquetar el tráfico de la API?
Lo que esperamos es que detecte un conjunto muy similar de puntos finales. Sin embargo, en nuestros datos sabíamos que habría dos lagunas. En primer lugar, a veces nos damos cuenta de que los clientes no son capaces de examinar correctamente solo el tráfico API utilizando identificadores de sesión. En este escenario, Discovery muestra el tráfico que no está basado en API. En segundo lugar, desde que exigimos identificadores de sesión en la primera versión de API Discovery, los puntos finales que no forman parte de una sesión (p. ej. puntos finales de inicio de sesión o puntos finales no autenticados) no son identificables en términos conceptuales.
El siguiente gráfico muestra un histograma del número de puntos finales identificados en dominios de clientes para ambos procesos de identificación.

Desde una perspectiva general, los resultados parecen muy similares, lo que es un buen indicador de que la identificación basada en el aprendizaje automático funciona como se supone que debe hacerlo. En este gráfico ya se aprecian algunas diferencias, lo que era de esperar, ya que también identificaremos puntos finales que no son identificables en términos conceptuales con solo un identificador de sesión. De hecho, si observamos más detenidamente una comparación por dominio, veremos que no hay cambios en aproximadamente el 46 % de los dominios. El siguiente gráfico compara la diferencia (por porcentaje de puntos finales) entre la identificación basada en sesión y en el aprendizaje automático:

Para cerca del 15 % de los dominios, observamos un aumento de puntos finales entre 1 y 50, y una reducción similar para aproximadamente el 9 %. Para cerca del 28 % de los dominios, encontramos más de 50 puntos finales adicionales.
Estos resultados subrayan que la identificación basada en el aprendizaje automático es capaz de mostrar puntos finales adicionales que antes pasaban desapercibidos, y amplía así el conjunto de herramientas que API Gateway ofrece para ayudar a poner orden en tu entorno API.
Protección instantánea de la API mediante el aprendizaje del esquema de la API
Una vez hemos abordado API Discovery, ¿cómo puede un profesional proteger los puntos finales recién identificados? Ya hemos examinado los metadatos de la solicitud API, así que ahora veamos su cuerpo. La recopilación de todos los formatos esperados para todos los puntos finales de una API se conoce como esquema de API. La validación de esquemas de API Gateway es una buena manera de protegerse contra los 10 principales ataques a la API según OWASP, garantizando que el cuerpo, la ruta y la cadena de consulta de una solicitud contengan la información prevista para ese punto final de la API en un formato esperado. Pero, ¿y si no conoces el formato esperado?
Aunque un cliente no conozca el esquema de una API concreta, los clientes que utilicen esta API se habrán programado para enviar mayoritariamente solicitudes que se ajusten a este esquema desconocido (o no podrían consultar con éxito el punto final). La función Schema Learning aprovecha este hecho y revisará las solicitudes realizadas con éxito a esta API para reconstruir automáticamente el esquema de entrada para el cliente. Por ejemplo, una API puede esperar que el parámetro Id. de usuario de una solicitud tenga la forma id12345-a. Aunque esta previsión no se indique explícitamente, los clientes que quieran una interacción positiva con la API enviarán los Id. de usuario con este formato.
Schema Learning identifica primero todas las solicitudes recientes realizadas con éxito a un punto final de la API y, a continuación, analiza los distintos parámetros de entrada de cada solicitud según su posición y tipo. Tras analizar todas las solicitudes, examina los distintos valores de entrada de cada posición e identifica qué características tienen en común. Tras comprobar que todas las solicitudes observadas comparten estos elementos comunes, Schema Learning crea un esquema de entrada que restringe la entrada para que cumpla estos elementos comunes y que se puede utilizar directamente para la validación de esquema.
Para permitir esquemas de entrada más precisos, Schema Learning identifica cuándo un parámetro puede recibir distintos tipos de entrada. Supongamos que quieres escribir un archivo de esquema OpenAPIv3 y observar manualmente en una pequeña muestra de solicitudes que un parámetro de consulta es una marca de tiempo Unix. Escribes un esquema de API que obliga a que ese parámetro de consulta sea un número entero mayor que el inicio de la época unix del año pasado. Si tu API también permitiera ese parámetro en formato ISO 8601, tu nueva regla crearía falsos positivos cuando el parámetro con formato diferente (aunque válido) llegara a la API. Schema Learning te libera automáticamente de esta tarea tediosa y detecta lo que la inspección manual no puede.
Para evitar falsos positivos, Schema Learning realiza una prueba estadística de la distribución de estos valores y solo escribe el esquema cuando la distribución tiene un alto grado de fiabilidad.
¿Qué tal funciona? A continuación se muestran algunas estadísticas sobre los tipos y valores de parámetros que vemos:

El aprendizaje de parámetros clasifica algo más de la mitad de los parámetros como cadenas, seguidos de datos integer, que constituyen casi un tercio. El 17 % restante está formado por matrices, booleanos y parámetros numéricos (float), mientras que los parámetros objeto se ven en muy pocas ocasiones en la ruta y la consulta.

El número de parámetros en la ruta suele ser muy bajo, ya que el 94 % de todos los puntos finales tienen como máximo un parámetro en su ruta.

En la consulta, sí vemos muchos más parámetros, ¡incluso a veces los 50 parámetros diferentes en un punto final!
El aprendizaje de parámetros es capaz de estimar restricciones numéricas con un 99,9 % de fiabilidad para la mayoría de los parámetros observados. Estas restricciones pueden ser un máximo/mínimo en el valor, longitud o tamaño del parámetro, o un conjunto limitado de valores únicos que debe llevar un parámetro.
Protege tus API en minutos
A partir de hoy, todos los clientes de API Gateway pueden identificar y proteger las API con solo unos clics, incluso aunque seas nuevo en esto. En el panel de control de Cloudflare, haz clic en API Gateway y en la pestaña Discovery para observar tus puntos finales identificados. Estos puntos finales estarán disponibles inmediatamente sin que tengas que hacer nada. A continuación, añade los puntos finales relevantes desde Discovery a Gestión de puntos finales. Schema Learning se ejecuta automáticamente para todos los puntos finales que se añadan a la Gestión de puntos finales. Transcurridas 24 horas, exporta tu nuevo esquema y cárgalo en Validación de esquema.
Los clientes Enterprise que no han comprado API Gateway pueden empezar activando la prueba de API Gateway en el panel de control de Cloudflare o poniéndose en contacto con su gerente de cuenta.
¿Y ahora qué?
Tenemos previsto mejorar Schema Learning para que admita más parámetros aprendidos en más formatos, como los parámetros del cuerpo POST tanto en formato JSON como a través de codificación de URL, así como los esquemas de encabezado y de cookies. En el futuro, Schema Learning también notificará a los clientes cuando detecte cambios en el esquema de API identificado y mostrará un esquema actualizado.
Nos gustaría conocer tu opinión sobre estas nuevas funciones. Por favor, envía tus comentarios a tu equipo de cuenta para que podamos priorizar las áreas de mejora adecuadas. ¡Esperamos recibir tus comentarios!