

Introducción
Hay muchas formas de almacenar los datos en sus aplicaciones. Por ejemplo, en las aplicaciones Cloudflare Workers, tenemos Workers KV para el almacenamiento de valores clave y Durable Objects para el almacenamiento coordinado en tiempo real sin poner en riesgo la consistencia. Fuera del ecosistema de Cloudflare, también puede conectar otras herramientas, tales como NoSQL y bases de datos de gráficos.
Sin embargo, a veces quiere SQL. Los índices permiten recuperar datos rápidamente. Las combinaciones nos permiten describir relaciones complejas entre diferentes tablas. SQL describe de manera declarativa cómo se validan, crean y consultan los datos de nuestra aplicación.
D1 se lanzó hoy en open alpha y, para celebrarlo, quiero compartir mi experiencia en la creación de aplicaciones con D1: específicamente, cómo comenzar y por qué estoy emocionado de que D1 se una a la larga lista de herramientas que puede usar para crear aplicaciones en Cloudflare.
D1 es notable porque es un valor agregado instantáneo para las aplicaciones sin necesidad de nuevas herramientas o salir del ecosistema de Cloudflare. Usando wrangler, podemos hacer desarrollo local en nuestras aplicaciones de Trabajadores, y con la adición de D1 en wrangler, ahora también podemos desarrollar aplicaciones con estado apropiadas localmente. Luego, cuando llega el momento de implementar la aplicación, Wrangler nos permite acceder y ejecutar comandos en su base de datos D1, así como en su propia API.
Qué estamos creando
En esta publicación del blog, te mostraré cómo utilizar D1 para añadir comentarios a un blog estático. Para ello, crearemos una nueva base de datos D1 y una sencilla API JSON que permita la creación y la recuperación de comentarios.
Como mencioné, separar D1 de la aplicación en sí, una API y una base de datos que permanece separada del sitio estático, nos permite extraer las piezas estáticas y dinámicas de nuestro sitio web uno del otro. También facilita la implementación de nuestra aplicación: implementaremos la interfaz en Cloudflare Pages y la API con tecnología D1 en Cloudflare Workers.
Creación de una nueva aplicación
Primero, agregaremos una API básica en Workers. Cree un nuevo directorio y un nuevo proyecto de wrangler dentro de este:
$ mkdir d1-example && d1-example
$ wrangler init
En este ejemplo, usaremos Hono, un marco Express.js-style para crear rápidamente nuestra API. Para usar Hono en este proyecto, instálelo usando NPM:
$ npm install hono
Luego, en src/index.ts, inicializaremos una nueva aplicación Hono y definiremos algunos puntos de conexión: GET /API/posts/:slug/comments, and POST /get/api/:slug/comments.
import { Hono } from 'hono'
import { cors } from 'hono/cors'
const app = new Hono()
app.get('/api/posts/:slug/comments', async c => {
// do something
})
app.post('/api/posts/:slug/comments', async c => {
// do something
})
export default app
Ahora, crearemos una base de datos D1. En Wrangler 2, hay soporte para el subcomando wrangler d1, que le permite crear y consultar sus bases de datos D1 directamente desde la línea de comandos. Entonces, por ejemplo, podemos crear una nueva base de datos con un solo comando:
$ wrangler d1 create d1-example
Con nuestra base de datos creada, podemos tomar el ID del nombre de la base de datos y asociarlo con un enlace dentro de wrangler.toml, el archivo de configuración de wrangler. Los enlaces nos permiten acceder a los recursos de Cloudflare, como bases de datos D1, espacios de nombres KV y depósitos R2, usando un nombre de variable simple en nuestro código. A continuación, crearemos el enlace DB y lo utilizaremos para representar nuestra nueva base de datos:
[[ d1_databases ]]
binding = "DB" # i.e. available in your Worker on env.DB
database_name = "d1-example"
database_id = "4e1c28a9-90e4-41da-8b4b-6cf36e5abb29"
Tenga en cuenta que esta directiva, el campo [[d1_databases]], actualmente requiere una versión beta de wrangler. Puede instalar esto para su proyecto usando el comando npm install -D wrangler/beta.
Con la base de datos configurada en nuestro wrangler.toml, podemos comenzar a interactuar con él desde la línea de comando y dentro de nuestra función Workers.
Primero, puede emitir comandos SQL directos al usar wrangler d1 execute:
$ wrangler d1 execute d1-example --command "SELECT name FROM sqlite_schema WHERE type ='table'"
Executing on d1-example:
┌─────────────────┐
│ name │
├─────────────────┤
│ sqlite_sequence │
└─────────────────┘
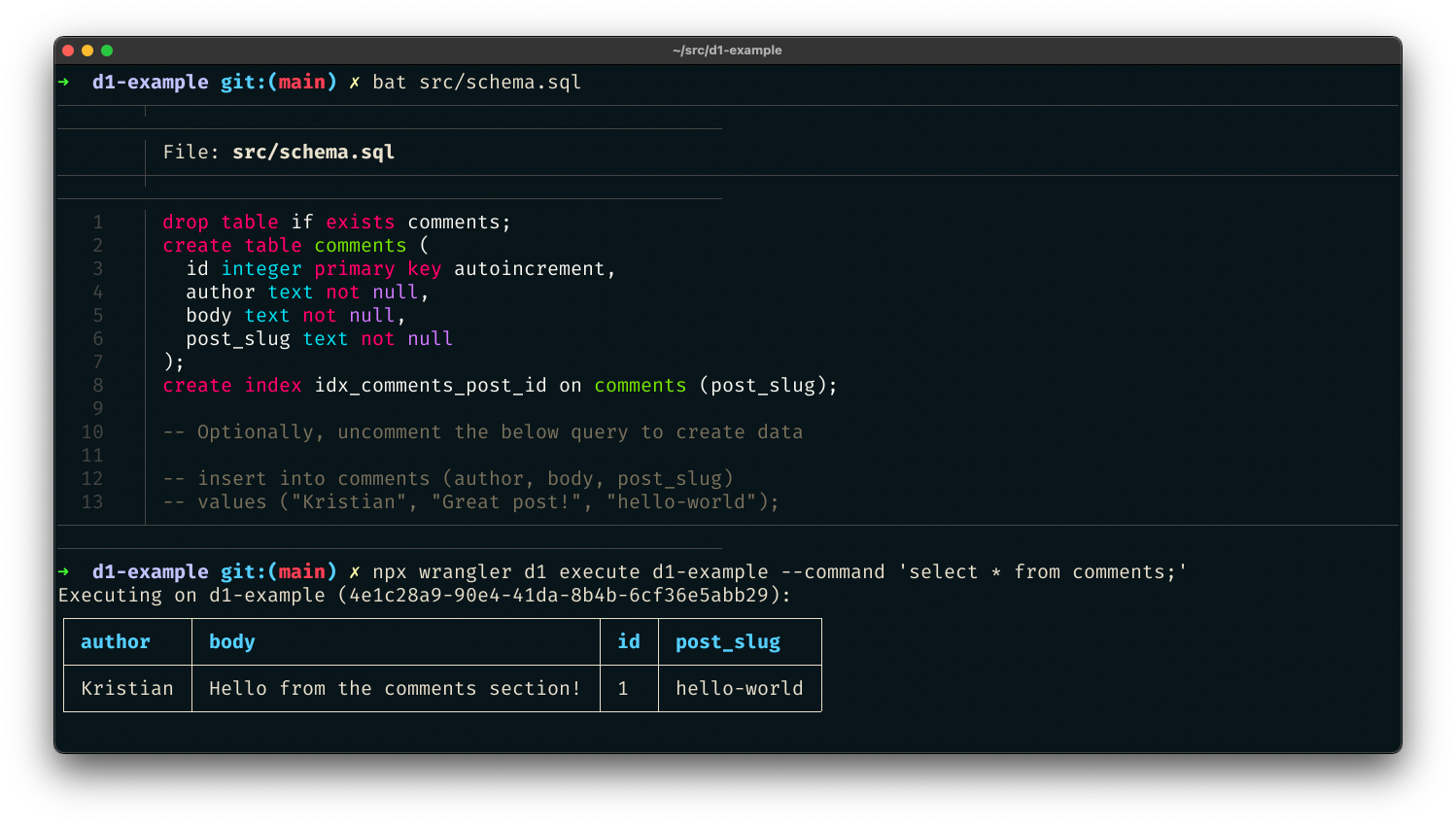
También puede pasar un archivo SQL, lo que es perfecto para la propagación de datos iniciales en un solo comando. Cree src/schema.sql, lo que creará una nueva tabla de comentarios para nuestro proyecto:
drop table if exists comments;
create table comments (
id integer primary key autoincrement,
author text not null,
body text not null,
post_slug text not null
);
create index idx_comments_post_id on comments (post_slug);
-- Optionally, uncomment the below query to create data
-- insert into comments (author, body, post_slug)
-- values ("Kristian", "Great post!", "hello-world");
Con el archivo creado, ejecute el archivo de esquema contra la base de datos D1 y páselo con la marca --file:
$ wrangler d1 execute d1-example --file src/schema.sql
Hemos creado una base de datos SQL con solo algunos comandos y la hemos propagado con datos iniciales. Ahora podemos agregar una ruta a nuestra función de Workers para recuperar datos de esa base de datos. Según nuestra configuración wrangler.toml, ahora se puede acceder a la base de datos D1 a través del enlace DB. En nuestro código, podemos usar el enlace para preparar declaraciones SQL y ejecutarlas, por ejemplo, para recuperar comentarios:
app.get('/api/posts/:slug/comments', async c => {
const { slug } = c.req.param()
const { results } = await c.env.DB.prepare(`
select * from comments where post_slug = ?
`).bind(slug).all()
return c.json(results)
})
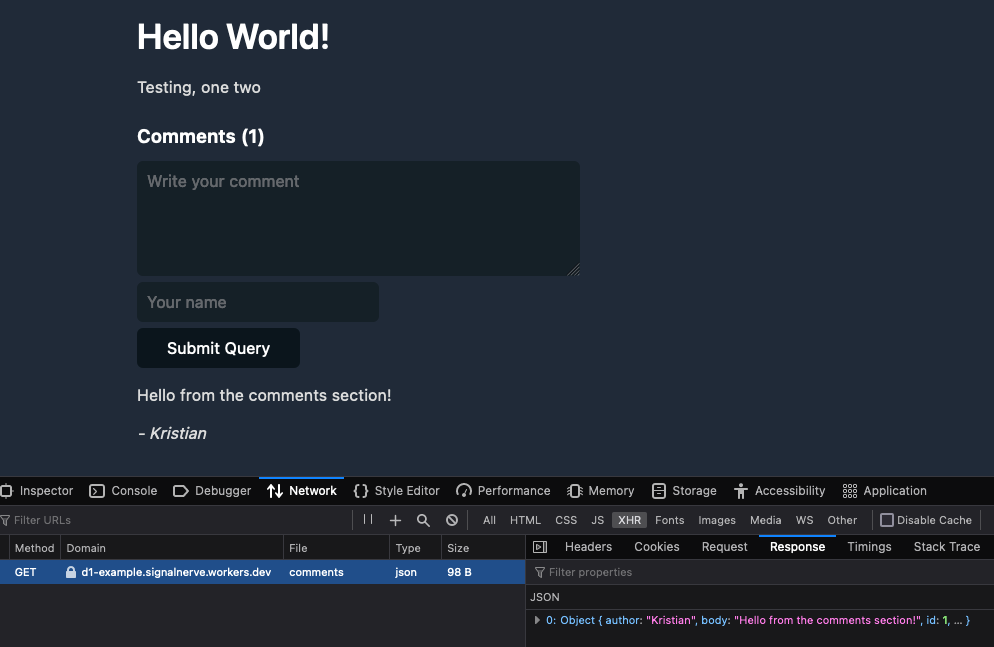
En esta función, aceptamos un parámetro de consulta de URL slug y configuramos una nueva instrucción SQL donde seleccionamos todos los comentarios con un valor post_slug que coincide con nuestro parámetro de consulta. Luego podemos devolverlo como una JSON response.
Hasta ahora, hemos creado acceso de solo lectura a nuestros datos. Sin embargo, por supuesto, también es posible "insertar" valores en SQL. Así que definamos otra función que permita hacer un POST a un punto de conexión para crear un nuevo comentario:
app.post('/API/posts/:slug/comments', async c => {
const { slug } = c.req.param()
const { author, body } = await c.req.json<Comment>()
if (!author) return c.text("Missing author value for new comment")
if (!body) return c.text("Missing body value for new comment")
const { success } = await c.env.DB.prepare(`
insert into comments (author, body, post_slug) values (?, ?, ?)
`).bind(author, body, slug).run()
if (success) {
c.status(201)
return c.text("Created")
} else {
c.status(500)
return c.text("Something went wrong")
}
})
En este ejemplo, creamos una API de comentarios para impulsar un blog. Para ver la fuente de esta API de comentarios basada en D1, puede visitar cloudflare/templates/worker-d1-api.
Conclusión
Una de las cosas más emocionantes de D1 es la oportunidad de aumentar las aplicaciones o sitios web existentes con los datos relacionales dinámicos. Como antiguo desarrollador de Ruby on Rails, una de las cosas que más echo de menos de ese marco en el mundo de JavaScript y las herramientas de desarrollo sin servidor es la capacidad de activar rápidamente aplicaciones completas basadas en datos, sin tener que ser un experto en la gestión de la infraestructura de bases de datos. Con D1 y su fácil acceso a datos basados en SQL, podemos crear verdaderas aplicaciones basadas en datos sin comprometer el rendimiento o la experiencia del desarrollador.
Este cambio corresponde muy bien con la llegada de los sitios estáticos en los últimos años, utilizando herramientas como Hugo o Gatsby. Un blog construido con un generador de sitios estáticos como Hugo tiene un rendimiento increíble: se creará en segundos con activos pequeños.
Sin embargo, al cambiar una herramienta como WordPress por un generador de sitios estáticos, pierde la oportunidad de agregar información dinámica a su sitio. Muchos desarrolladores han solucionado este problema al agregar más complejidad a sus procesos de compilación: obteniendo y recuperando datos y generando páginas al utilizar esos datos como parte del desarrollo.
Esta adición de complejidad en el proceso de desarrollo intenta corregir la falta de dinamismo en las aplicaciones, pero aún no es genuinamente dinámica. En lugar de poder recuperar y mostrar nuevos datos a medida que se crean, la aplicación se reconstruye y vuelve a implementar cada vez que los datos cambian para que parezca una representación dinámica y en vivo de los datos. Su aplicación puede permanecer estática y los datos dinámicos vivirán geográficamente cerca de los usuarios de su sitio, accesibles a través de una API consultable y expresiva.