


Desarrollo web integral, más fácil
Aunque sea 1 de abril (April Fool's day), y nos gusta divertirnos como a cualquiera, queremos aprovechar este día para publicar anuncios importantes. De hecho, a fecha de hoy, hay más de 2 millones de desarrolladores creando en la plataforma de Cloudflare, ¡no es ninguna broma!
Para dar comienzo a esta nueva edición de la Developer Week, anunciamos tres productos "listos para su implementación en entornos de producción": D1, nuestra base de datos SQL sin servidor, Hyperdrive, que hace que tus bases de datos existentes parezcan distribuidas (¡y más rápidas!) y Workers Analytics Engine, nuestra base de datos de serie temporal.
Llevamos algún tiempo trabajando para que los desarrolladores puedan crear toda su pila en Cloudflare, pero ¿qué aspecto podría tener una aplicación creada en Cloudflare?
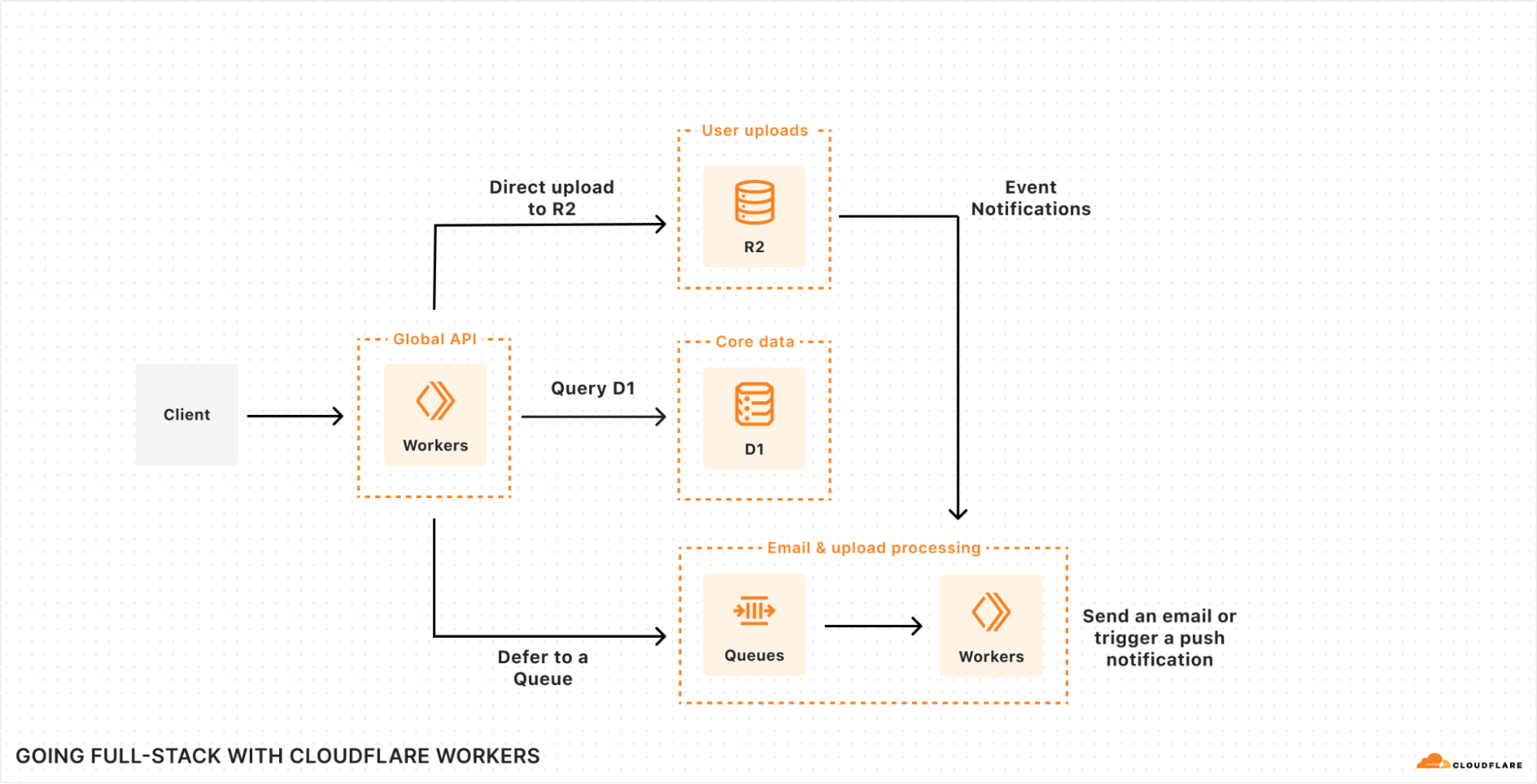
El diagrama en sí no debería parecer demasiado diferente de las herramientas con las que ya estás familiarizado. Quieres una base de datos para los datos principales de tus usuarios, almacenamiento de objetos para activos y contenido de usuarios, tal vez una cola para tareas en segundo plano, como el correo electrónico o el procesamiento de cargas. Además, te interesa un almacén clave-valor rápido para la configuración del entorno de ejecución o incluso una base de datos de serie temporal para añadir eventos de usuario y/o datos de rendimiento. Y eso antes de llegar a la IA, que se está convirtiendo cada vez más en una parte esencial de muchas aplicaciones en tareas de búsqueda, recomendación y/o análisis de imágenes (¡como mínimo!).
Sin embargo, sin tener que pensar en ello, esta arquitectura se ejecuta en region: planeta Tierra, lo que significa que es escalable, fiable y rápida, todo desde el primer momento.
Disponibilidad general de la base de datos D1: lista para entornos de producción

Tu base de datos básica es una de las piezas más críticas de tu infraestructura. Tiene que ser ultrafiable, no puede perder datos y tiene que escalar. Por eso, durante el último año hemos estado muy ocupados con su puesta en marcha para asegurarnos de que su implementación está lista para entornos de producción, y estamos muy contentos de poder decir que D1, nuestra base de datos SQL global sin servidor, ya está disponible de forma general.
La disponibilidad de forma general de D1 incluye algunas de las funciones más solicitadas, entre ellas:
- Soporte para bases de datos de 10 GB, y 50 000 bases de datos por cuenta.
- Nuevas funciones de exportación de datos.
- Depuración de consultas optimizada (la llamamos "D1 Insights"), que te permite comprender qué consultas llevan más tiempo, cuestan más o son sencillamente ineficaces.
... para que los desarrolladores puedan crear aplicaciones listas para producción con D1 y satisfacer todas las necesidades de la base de datos relacional SQL. Y lo que es más importante, en una época en la que el concepto de "plan gratuito" o "plan para principiantes" parece estar en peligro, no tenemos intención de eliminar el nivel gratuito de D1 ni de reducir los 25 000 millones de lecturas de filas incluidos en el plan de pago Workers de 5 USD/mes:
Para los que han seguido la base de datos D1 desde el principio, mantenemos el mismo precio que anunciamos en la versión beta abierta
Sin embargo, no todo acaba con la disponibilidad general. Tenemos nuevas funciones importantes preparadas para D1, incluida la replicación de lectura global, bases de datos aún mayores, más funciones de Time Travel que te permitirán dividir tu base de datos, y nuevas API para consultar dinámicamente y/o crear nuevas bases de datos sobre la marcha desde dentro de un Worker.
La replicación de lectura de D1 implementará automáticamente réplicas de lectura según sea necesario para acercar los datos a tus usuarios, y sin que tengas que acelerar, gestionar el escalado o encontrarte con problemas de consistencia (retraso de replicación). Aquí tienes un adelanto de cómo será la próxima API de replicación de D1:
export default {
async fetch(request: Request, env: Env) {
const {pathname} = new URL(request.url);
let resp = null;
let session = env.DB.withSession(token); // An optional commit token or mode
// Handle requests within the session.
if (pathname === "/api/orders/list") {
// This statement is a read query, so it will work against any
// replica that has a commit equal or later than `token`.
const { results } = await session.prepare("SELECT * FROM Orders");
resp = Response.json(results);
} else if (pathname === "/api/orders/add") {
order = await request.json();
// This statement is a write query, so D1 will send the query to
// the primary, which always has the latest commit token.
await session.prepare("INSERT INTO Orders VALUES (?, ?, ?)")
.bind(order.orderName, order.customer, order.value);
.run();
// In order for the application to be correct, this SELECT
// statement must see the results of the INSERT statement above.
//
// D1's new Session API keeps track of commit tokens for queries
// within the session and will ensure that we won't execute this
// query until whatever replica we're using has seen the results
// of the INSERT.
const { results } = await session.prepare("SELECT COUNT(*) FROM Orders")
.run();
resp = Response.json(results);
}
// Set the token so we can continue the session in another request.
resp.headers.set("x-d1-token", session.latestCommitToken);
return resp;
}
}
Y lo que es más importante, ofreceremos a los desarrolladores la posibilidad de mantener la coherencia en función de la sesión, para que los usuarios sigan viendo reflejados sus propios cambios, al tiempo que se benefician de las mejoras de rendimiento y latencia que puede aportar la replicación.
Puedes obtener más información sobre el funcionamiento avanzado de la replicación de lectura de D1 en nuestro artículo técnico, y si quieres empezar a desarrollar en D1 hoy mismo, consulta nuestros documentos para desarrolladores para crear tu primera base de datos.
Disponibilidad general de Hyperdrive

Lanzamos la versión beta abierta de Hyperdrive el pasado mes de septiembre, durante la Semana aniversario, y ahora está disponible de forma general, es decir, probado y listo para su implementación en entornos de producción.
Si aún no sabes qué es Hyperdrive, está diseñado para que las bases de datos centralizadas que ya tienes parezcan globales. Utilizamos nuestra red global para conseguir rutas más rápidas a tu base de datos, mantener las agrupaciones de conexiones preparadas y almacenar en caché tus consultas más frecuentes, lo más cerca posible de los usuarios.
Además, Hyperdrive es compatible con los controladores y bibliotecas ORM (Object Relational Mapper) más populares desde el primer momento, por lo que no tendrás que volver a aprender ni a escribir tus consultas:
// Use the popular 'pg' driver? Easy. Hyperdrive just exposes a connection string
// to your Worker.
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
await client.connect();
// Prefer using an ORM like Drizzle? Use it with Hyperdrive too.
// https://orm.drizzle.team/docs/get-started-postgresql#node-postgres
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
await client.connect();
const db = drizzle(client);
Pero el trabajo en Hyperdrive no para porque esté disponible de forma general. En los próximos meses, ofreceremos compatibilidad con el otro motor de bases de datos más utilizado que existe, MySQL. También admitiremos la conexión a bases de datos dentro de redes privadas (incluidas redes VPC en la nube) a través de Cloudflare Tunnel y Magic WAN. Además, tenemos previsto aumentar la capacidad de configuración de las estrategias de invalidación y almacenamiento en caché, para que puedas tomar decisiones más precisas sobre el rendimiento vs. la actualidad de los datos.
Cuando pensamos en cómo queríamos fijar el precio de Hyperdrive, nos dimos cuenta de que no nos parecía correcto cobrar por este servicio. Al fin y al cabo, las ventajas de rendimiento de Hyperdrive no solo son significativas, sino esenciales para conectarse a los motores de bases de datos tradicionales. Sin Hyperdrive, pagar los costes generales de latencia de más de 6 viajes de ida y vuelta para conectarte y consultar tu base de datos por cada solicitud no es justo.
Por eso nos complace anunciar que Hyperdrive es gratuito para cualquier desarrollador con un plan de pago Workers. Se incluye tanto el almacenamiento en caché de las consultas como la agrupación de conexiones, así como la posibilidad de crear varios Hyperdrives para separar diferentes aplicaciones, producción frente a preparación, o para proporcionar diferentes configuraciones (en caché frente a sin caché, por ejemplo).
Para empezar a utilizar Hyperdrive, consulta la documentación para aprender a conectar tu base de datos existente y empezar a consultarla desde tu Workers.
Queues, extracciones desde cualquier parte
La cola de tareas es una parte cada vez más esencial del desarrollo de una aplicación moderna y completa, y esto es lo que teníamos en mente cuando anunciamos inicialmente la versión beta abierta de Queues. Desde entonces hemos estado trabajando en varias funciones importantes, y esta semana lanzamos dos de ellas: consumidores basados en la extracción y medidas de control de la transmisión de nuevos mensajes.
Cualquier cliente basado en HTTP puede ahora extraer (pull) mensajes de una cola, llamando al nuevo punto final /pull de una cola para solicitar un lote de mensajes, y llamando al punto final /ack para confirmar cada mensaje (o lote de mensajes) cuando los procesa con éxito:
// Pull and acknowledge messages from a Queue using any HTTP client
$ curl "https://api.cloudflare.com/client/v4/accounts/${CF_ACCOUNT_ID}/queues/${QUEUE_ID}/messages/pull" -X POST --data '{"visibilityTimeout":10000,"batchSize":100}}' \
-H "Authorization: Bearer ${QUEUES_TOKEN}" \
-H "Content-Type:application/json"
// Ack the messages you processed successfully; mark others to be retried.
$ curl "https://api.cloudflare.com/client/v4/accounts/${CF_ACCOUNT_ID}/queues/${QUEUE_ID}/messages/ack" -X POST --data '{"acks":["lease-id-1", "lease-id-2"],"retries":["lease-id-100"]}' \
-H "Authorization: Bearer ${QUEUES_TOKEN}" \
-H "Content-Type:application/json"
Un consumidor basado en pull se puede ejecutar en cualquier lugar, lo que te permite ejecutar consumidores en cola junto con tu infraestructura de nube heredada existente. Los equipos de Cloudflare lo adoptaron muy pronto, con un caso de uso centrado en escribir telemetría de dispositivos en una cola desde nuestros más de 310 centros de datos y usarla dentro de parte de nuestra infraestructura interna que se ejecuta en Kubernetes. Es importante destacar que nuestra infraestructura de colas distribuida globalmente permite mantener los mensajes en la cola hasta que el consumidor está listo para procesarlos.
Queues también admite ahora el retardo de mensajes, tanto cuando se envían a una cola como cuando se marca un mensaje para un nuevo intento. Esta ventaja puede ser útil para poner en cola (valga la ironía) tareas para el futuro, así como para aplicar un mecanismo de retroceso si una API o infraestructura ascendente tiene límites de velocidad que te obliguen a controlar la rapidez con la que procesas los mensajes.
// Apply a delay to a message when sending it
await env.YOUR_QUEUE.send(msg, { delaySeconds: 3600 })
// Delay a message (or a batch of messages) when marking it for retry
for (const msg of batch.messages) {
msg.retry({delaySeconds: 300})
}
También aumentaremos sustancialmente el rendimiento por cola en los próximos meses, con el fin de que Queues esté disponible de forma general. Para nosotros es importante que Queues sea sumamente fiable. Si los mensajes se pierden u omiten, un usuario no recibirá el correo electrónico de confirmación de su pedido, la notificación de restablecimiento de contraseña y/o el procesamiento de sus cargas.

Disponibilidad general de Workers Analytics Engine
Workers Analytics Engine ofrece análisis de cardinalidad ilimitada a escala, a través de una API integrada para escribir puntos de datos desde Workers, y una API de SQL para consultar esos datos.
Workers Analytics Engine está respaldado por el mismo sistema basado en ClickHouse del que hemos dependido durante años en Cloudflare. Nosotros mismos lo utilizamos para observar el estado de nuestros propios servicios, capturar datos de uso de productos para facturación y responder a preguntas sobre patrones de uso de clientes concretos. Se escribe al menos un punto de datos en este sistema en casi todas las solicitudes a la red de Cloudflare. Workers Analytics Engine te permite crear tus propios análisis personalizados utilizando esta misma infraestructura, mientras nosotros gestionamos las dificultades por ti.
Desde el lanzamiento de la versión beta, los desarrolladores han empezado a depender de Workers Analytics Engine para estos mismos casos de uso y más, desde grandes empresas a proyectos de código abierto como Counterscale. Workers Analytics Engine lleva años funcionando a escala de producción con cargas de trabajo esenciales, pero no habíamos informado sobre los precios, hasta hoy.
Los precios de Workers Analytics Engine son sencillos y se basan en dos parámetros:
- Puntos de datos escritos: cada vez que llamas a writeDataPoint() en un Worker, se cuenta como un punto de datos escrito. Cada punto de datos cuesta lo mismo, a diferencia de otras plataformas, no hay penalización por añadir dimensiones o cardinalidad, ni necesidad de predecir cuál puede ser el tamaño y el coste de un punto de datos comprimido.
- Consultas de lectura: cada vez que publicas en la API de SQL de Workers Analytics Engine, cuenta como una consulta de lectura. Cada consulta cuesta lo mismo, a diferencia de otras plataformas, no hay penalización por la complejidad de la consulta, ni necesidad de razonar sobre el número de filas de datos que leerá cada consulta.
Tanto el plan gratuito como el plan de pago de Workers incluirán una asignación de puntos de datos escritos y consultas de lectura, con los siguientes precios por uso adicional:
Con estos precios, puedes responder "¿cuánto me costará Workers Analytics Engine?" contando el número de veces que llamas a una función en tu Worker, y cuántas veces haces una solicitud a un punto final de la API HTTP. Cuentas sencillas, sin complicaciones.
Estos precios estarán disponibles para todos en los próximos meses. Hasta entonces, Workers Analytics Engine seguirá estando disponible sin ningún coste. Puedes empezar a escribir puntos de datos desde tu Worker hoy mismo. Solo te llevará unos minutos y menos de 10 líneas de código empezar a capturar datos. Nos encantaría conocer tu opinión.
La semana no ha hecho más que empezar
Descubre lo que tenemos preparado para ti mañana en nuestro segundo día de la Developer Week. Si tienes alguna pregunta o quieres mostrar algo interesante que ya hayas desarrollado, únete a Discord, nuestra comunidad para desarrolladores.