


Hyperdrive te permite un acceso ultrarrápido a tus bases de datos existentes desde Cloudflare Workers, dondequiera que se ejecuten. Conectas Hyperdrive a tu base de datos, modificas una línea de código para conectarte a través de Hyperdrive, y listo: las conexiones y las consultas son más rápidas (spoiler: puedes utilizarlo hoy mismo).
En pocas palabras, Hyperdrive utiliza nuestra red global para acelerar las consultas a tus bases de datos existentes, tanto si se encuentran en un proveedor de nube heredado como en tu proveedor favorito de bases de datos sin servidor; reduce drásticamente la latencia que implica configurar repetidamente nuevas conexiones a la base de datos; y almacena en caché las consultas de lectura a tu base de datos más populares, lo que a menudo evita incluso la necesidad de volver a tu base de datos.
Sin Hyperdrive, esa base de datos principal (la que contiene tus perfiles de usuario, tu inventario de productos o que ejecuta tus aplicaciones web críticas), ubicada en la región us-east1 de tu proveedor de nube heredado, ofrecerá un acceso muy lento a los usuarios en París, Singapur y Dubái, y más lento de lo que debería ser para los usuarios en Los Ángeles o Vancouver. Cada viaje de ida y vuelta puede representar hasta 200 ms, por lo que es fácil perder hasta un segundo (¡o más!) en varios viajes de día y vuelta necesarios solo para establecer una conexión, antes incluso de que hayas realizado la consulta de tus datos. Hyperdrive se ha diseñado para resolver esta situación.
Para demostrar el rendimiento de Hyperdrive, hemos creado una aplicación de demostración que realiza consultas consecutivas a la misma base de datos: con Hyperdrive y sin Hyperdrive (directamente). La aplicación selecciona una base de datos ubicada en un continente vecino: si estás en Europa, selecciona una base de datos de EE. UU. (una experiencia con la que están demasiado familiarizados muchos usuarios de Internet en Europa) y, si estás en África, selecciona una base de datos en Europa (y así sucesivamente). Devuelve los resultados sin procesar de una consulta `SELECT` sencilla, sin promedios seleccionados o métricas elegidas cuidadosamente.
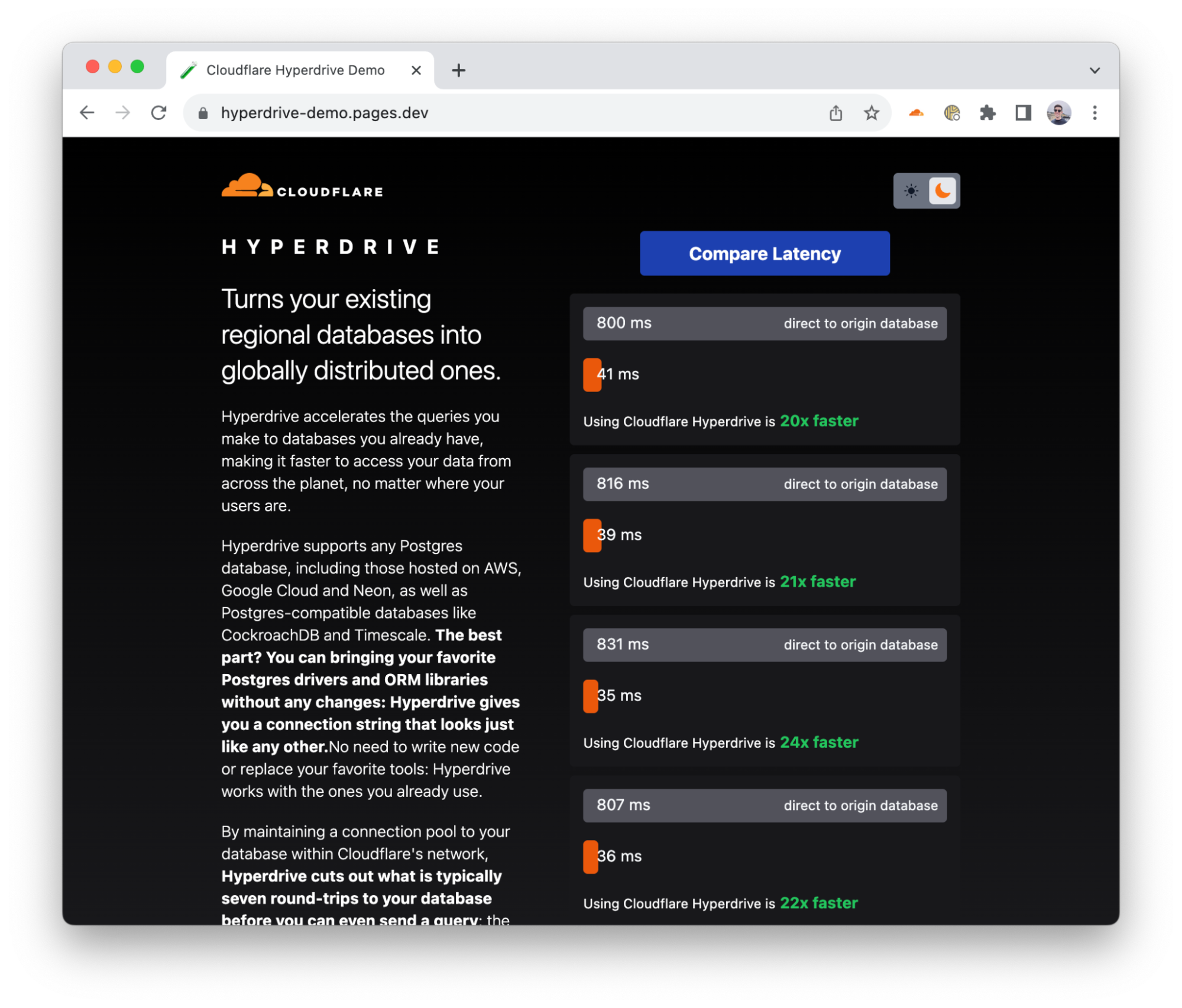
Las pruebas internas, los primeros informes de los usuarios y las múltiples ejecuciones en nuestro banco de pruebas muestran que Hyperdrive mejora el rendimiento entre 17 y 25 veces en comparación con el acceso directo a la base de datos para las solicitudes almacenadas en cache, y entre 6 y 8 veces para las solicitudes y las escrituras no almacenadas en caché. La latencia del almacenamiento en caché podría no extrañarte, pero creemos que el hecho de ser entre 6 y 8 veces más rápido para las consultas no almacenadas en caché hace que cambie la cuestión de "No puedo consultar una base de datos centralizada desde Cloudflare Workers" a "¿por qué no estaba esto disponible antes?". Asimismo, continuamos trabajando para mejorar aún más el rendimiento: ya hemos identificado nuevos métodos de reducir la latencia, y los aplicaremos en las próximas semanas.
¿Lo mejor? Los desarrolladores con un plan de pago de Workers pueden empezar a utilizar la versión beta abierta de Hyperdrive ya mismo: no hay listas de espera ni formularios de registro especiales que rellenar.
¿Hyperdrive? ¿No has oído hablar de él?
Hace relativamente poco que empezamos a trabajar en secreto con Hyperdrive: pero permitir a los desarrolladores conectarse a las bases de datos que ya tienen (con sus datos, sus consultas y sus herramientas existentes) es algo a lo que llevamos bastante tiempo dándole vueltas.
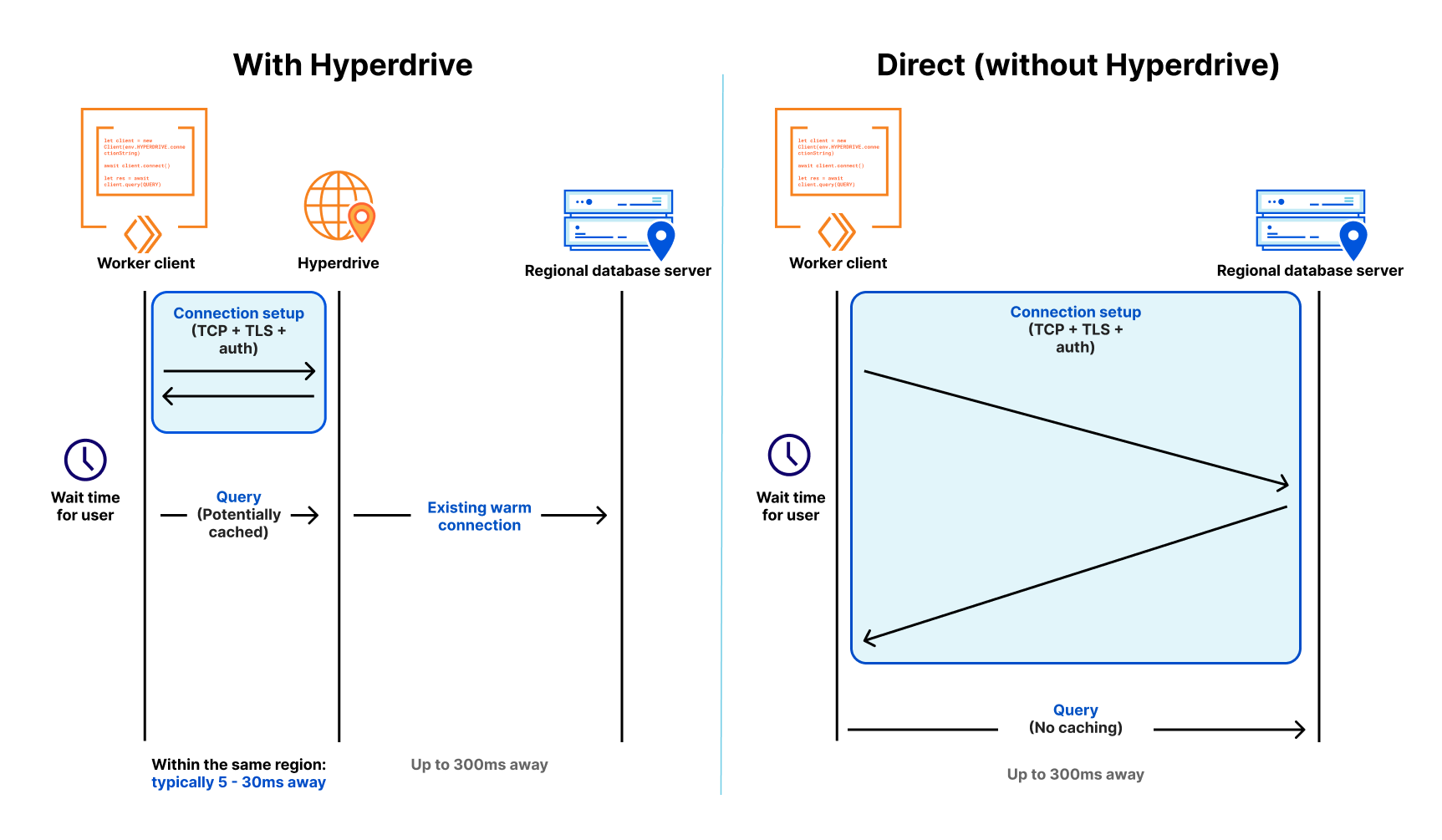
En un entorno moderno de nube distribuida, como Workers, donde los recursos informáticos están distribuidos a nivel global (por lo tanto, cerca de los usuarios) y donde las funciones son de corta duración (para que no pagues más de lo necesario), la conexión a las bases de datos tradicionales ha sido lenta y sin escalabilidad. Lenta porque requiere como mínimo siete viajes de ida y vuelta (protocolo de enlace TCP, negociación TLS y autenticación) para establecer la conexión. Sin escalabilidad porque las bases de datos como PostgreSQL tienen un coste elevado de recursos por conexión. Incluso unos centenares de conexiones a una base de datos pueden consumir una cantidad importante de memoria, aparte de la memoria necesaria para las consultas.
Nuestros amigos de Neon (un conocido proveedor de Postgres sin servidor) han escrito sobre este tema, e incluso han lanzado un proxy y un controlador WebSocket para reducir la carga de conexión, pero aún tienen dificultades a resolver: incluso con un controlador personalizado, nos quedan 4 viajes de ida y vuelta, y cada uno de ellos puede representar entre 50 y 200 milisegundos o más. Cuando estas conexiones son de larga duración, no hay problema (en el mejor de los casos, podría suceder una vez cada cierto número de horas). Sin embargo, cuando se limitan a una invocación de función individual y solo son útiles durante unos milisegundos o minutos en el mejor de los casos, tu código pasa más tiempo a la espera. De hecho, se trata de otro tipo de arranque en frío: el hecho de tener que iniciar una conexión nueva a tu base de datos antes de realizar una consulta significa que la utilización de una base de datos tradicional en un entorno distribuido o sin servidor es (por decirlo suavemente) realmente lenta.
Para hacer frente a este problema, Hyperdrive hace dos cosas.
En primer lugar, mantiene una serie de agrupaciones de conexiones de bases de datos regionales en la red de Cloudflare, por lo que Cloudflare Worker evita crear una nueva conexión a una base de datos con cada solicitud. En su lugar, Worker puede establecer una conexión a Hyperdrive (¡rápidamente!), e Hyperdrive mantiene una agrupación de conexiones listas para usar a la base de datos. Puesto que una base de datos puede estar a entre 30 ms y (a menudo) 300 ms en un único viaje de ida y vuelta (sin contar los siete o más que necesitas para una nueva conexión), el hecho de tener una agrupación de conexiones disponibles reduce considerablemente el problema de latencia que en caso contrario sufrirían las conexiones de corta duración.
En segundo lugar, comprende la diferencia entre las consultas de lectura (no mutantes) y las consultas de escritura (mutantes), y puede almacenar automáticamente en caché tus consultas de lectura más habituales, lo que representa más del 80 % de la mayoría de las consultas realizadas a bases de datos en aplicaciones web típicas. Esa página de listado de productos que visitan a diario decenas de miles de usuarios; las ofertas de empleo en un popular sitio de búsqueda de empleo; o incluso las consultas de datos de configuración que cambian ocasionalmente; una gran parte de lo que consultamos no cambia con frecuencia, y el hecho de almacenarlo en caché más cerca de la ubicación donde el usuario realiza la consulta puede acelerar considerablemente el acceso a esos datos para los siguientes diez mil usuarios. Las consultas de escritura, que no se pueden almacenar de forma segura en la caché, se siguen beneficiando tanto de la agrupación de conexiones de Hyperdrive como de la red global de Cloudflare: el hecho de poder tomar las rutas más rápidas de Internet a través de nuestra red troncal reduce la latencia también en ese caso.
Hyperdrive funciona no solo con las bases de datos PostgreSQL Neon, Google Cloud SQL, AWS RDS y Timescale, sino también con bases de datos compatibles con PostgreSQL como Materialize (una potente base de datos de proceso en streaming), CockroachDB (una de las principales bases de datos distribuidas), AlloyDB de Google Cloud y AWS Aurora Postgres.
Estamos trabajando para añadir compatibilidad con MySQL, incluidos proveedores como PlanetScale, antes de finales de año, así como otros motores de bases de datos más adelante.
La cadena de conexión mágica
Uno de los principales objetivos del diseño de Hyperdrive era permitir a los desarrolladores mantener sus controladores, su creador de consultas y sus bibliotecas ORM (Object-Relational Mapper) existentes. Poca importancia hubiera tenido la velocidad que pudiera ofrecer Hyperdrive si hubieras tenido que abandonar tu ORM favorito o reescribir centenares (o más) de líneas de código y pruebas para beneficiarte de su rendimiento.
Con este fin, hemos trabajado con aquellos que mantienen conocidos controladores de código abierto, como node-postgres y Postgres.js, para ayudar a que sus bibliotecas admitan la nueva API de socket TCP de Worker, que está en curso de normalización y que esperamos que llegue también a Node.js, Deno y Bun.
La cadena de conexión a la base de datos es el lenguaje compartido de los controladores de bases de datos, y suele tener este formato:
postgres://user:[email protected]:5432/postgres
La magia que hace posible Hyperdrive es que puedes empezar a utilizarlo en tus aplicaciones Workers existentes, con tus consultas existentes, simplemente reemplazando tu cadena de conexión por la que genera Hyperdrive.
Creación de un Hyperdrive
Con una base de datos existente lista para su uso (en este ejemplo, utilizaremos una base de datos Postgres de Neon) en menos de un minuto Hyperdrive ya está en funcionamiento (sí, lo hemos cronometrado).
Si no tienes un proyecto Cloudflare Workers existente, puedes crear uno rápidamente:
$ npm create cloudflare@latest
# Call the application "hyperdrive-demo"
# Choose "Hello World Worker" as your template
A partir de aquí, solo necesitamos la cadena de conexión a nuestra base de datos y una invocación rápida en la línea de comandos wrangler para que Hyperdrive se conecte a ella.
# Using wrangler v3.10.0 or above
wrangler hyperdrive create a-faster-database --connection-string="postgres://user:[email protected]:5432/neondb"
# This will return an ID: we'll use this in the next step
Añade nuestro Hyperdrive al archivo de configuración wrangler.toml para nuestro Worker:
[[hyperdrive]]
name = "HYPERDRIVE"
id = "cdb28782-0dfc-4aca-a445-a2c318fb26fd"
Ahora podemos escribir un Worker (o utilizar un script de Worker existente) y utilizar Hyperdrive para acelerar las conexiones y consultas a nuestra base de datos existente. Aquí utilizamos node-postgres, pero sería igual de fácil utilizar Drizzle ORM.
import { Client } from 'pg';
export interface Env {
HYPERDRIVE: Hyperdrive;
}
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext) {
console.log(JSON.stringify(env));
// Create a database client that connects to our database via Hyperdrive
//
// Hyperdrive generates a unique connection string you can pass to
// supported drivers, including node-postgres, Postgres.js, and the many
// ORMs and query builders that use these drivers.
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
try {
// Connect to our database
await client.connect();
// A very simple test query
let result = await client.query({ text: 'SELECT * FROM pg_tables' });
// Return our result rows as JSON
return Response.json({ result: result });
} catch (e) {
console.log(e);
return Response.json({ error: JSON.stringify(e) }, { status: 500 });
}
},
};
El código anterior es intencionadamente sencillo, pero esperamos que puedas ver la magia: nuestro controlador de base de datos obtiene una cadena de conexión de Hyperdrive, sin ninguna dificultad. No es necesario conocer Hyperdrive, no tenemos que deshacernos de nuestra biblioteca favorita de creación de consultas, y podemos beneficiarnos inmediatamente de las ventajas de velocidad al hacer consultas.
Las conexiones se agrupan automáticamente y se mantienen listas para usar, nuestras consultas más habituales se almacenan en caché, y toda nuestra aplicación es más rápida.
También hemos elaborado guías para cada uno de los principales proveedores de bases de datos a fin de facilitar la integración en Hyperdrive que necesitas.
La rapidez no puede ser barata, ¿no?
Creemos que Hyperdrive es esencial para acceder a tus bases de datos existentes cuando desarrolles en Cloudflare Workers: las bases de datos tradicionales simplemente nunca estuvieron adecuadamente diseñadas para un mundo donde los clientes están distribuidos a nivel global.
La agrupación de conexiones de Hyperdrive siempre será gratuita, para los dos protocolos de base de datos que admitimos actualmente y para los nuevos protocolos de base de datos que admitiremos más adelante. Al igual que con la protección contra DDoS y nuestra CDN global, creemos que el acceso a la función principal de Hyperdrive es demasiado útil para que esté limitado.
Durante la versión beta abierta, la utilización de Hyperdrive será gratuita, independientemente de cómo lo utilices. Proporcionaremos más detalles acerca de las tarifas de Hyperdrive cuando la fecha de disponibilidad general esté próxima (a principios de 2024), y lo haremos con la antelación suficiente.
Es la hora de las consultas
¿Qué será lo siguiente con Hyperdrive?
Tenemos previsto lanzar la disponibilidad general de Hyperdrive a principios de 2024. Estamos centramos en la implementación de controles adicionales sobre el almacenamiento en caché y la invalidación automática en función de las escrituras, las consultas detalladas y los análisis del rendimiento (¡en breve!) y en la compatibilidad con más motores de bases de datos (incluido MySQL), así como en seguir trabajando para que sea aún más rápido.
También estamos trabajando para ofrecer conectividad de red privada mediante Magic WAN y Cloudflare Tunnel, para que puedas conectarte a las bases de datos que no están (o no pueden estar) expuestas a la red pública.
Para conectar Hyperdrive a tu base de datos existente, visita nuestra documentación para desarrolladores (en menos de un minuto puedes crear un Hyperdrive y actualizar el código existente para utilizarlo). Únete al canal #hyperdrive-beta en Developer Discord para plantear preguntas, indicar errores y hablar directamente con nuestros equipos de productos e ingeniería.
