


La inferencia a partir de LLM ajustados con LoRA ya está disponible en la versión beta abierta
Hoy nos complace anunciar que ya puedes ejecutar inferencia ajustada con LoRA en Workers AI. Esta función está en la versión beta abierta y disponible para adaptadores LoRA entrenados previamente para su uso con Mistral, Gemma o Llama 2, con ciertas limitaciones. Echa un vistazo a nuestra publicación del blog sobre los anuncios de productos para ver una descripción general de nuestra función "Bring Your Own (BYO) LoRAs".
En esta publicación, analizaremos qué son los ajustes (Fine-tuning) y los adaptadores LoRA, te mostraremos cómo utilizarlos en nuestra plataforma Workers AI, y a continuación nos centraremos en los detalles técnicos de cómo los hemos implementado en nuestra plataforma.
¿Qué es Fine-tuning?
"Ajustes" (Fine-tuning) es un término genérico que hace referencia a la modificación de un modelo de IA porque su entrenamiento continúa con datos adicionales. El objetivo de los ajustes es aumentar la probabilidad de que una generación sea similar a tu conjunto de datos. Entrenar un modelo desde cero no es práctico en muchos casos de uso, dado lo costoso y lento que puede resultar el entrenamiento. El ajuste de un modelo existente entrenado previamente te permite beneficiarte de sus capacidades al mismo tiempo que realizas la tarea deseada. El protocolo LoRA (Low-Rank Adaptation) es un método específico de ajuste que puede aplicarse a diversas arquitecturas de modelos, no sólo a los LLM. En los métodos de ajuste tradicionales, es habitual que las ponderaciones de los modelos entrenados previamente se modifiquen directamente o se fusionen con ponderaciones de ajuste adicionales. Por el contrario, con LoRA las ponderaciones de ajuste y el modelo entrenado previamente se mantienen separados, y el modelo ya entrenado no cambia. El resultado final es que puedes entrenar los modelos para que sean más precisos en tareas específicas, como generar código, tener una personalidad específica o generar imágenes con un estilo concreto. Incluso puedes ajustar un LLM existente para que comprenda información adicional sobre un tema determinado.
El enfoque de mantener las ponderaciones del modelo base original significa que puedes crear nuevas ponderaciones de ajuste con relativamente pocos procesos. Puedes beneficiarte de los modelos básicos existentes (como Llama, Mistral y Gemma) y adaptarlos a tus necesidades.
¿Cómo funciona el ajuste?
Para comprender mejor el ajuste y por qué LoRA es tan eficaz, debemos retroceder un poco para entender cómo funcionan los modelos de IA. Estos (como los LLM) son redes neuronales que se entrenan mediante técnicas de aprendizaje profundo. En las redes neuronales, un conjunto de parámetros actúan como una representación matemática del conocimiento del dominio del modelo, formado por ponderaciones y sesgos (en términos sencillos, números). Estos parámetros suelen representarse como grandes matrices de números. Cuantos más parámetros tiene un modelo, mayor es el modelo. Así, cuando ves modelos como llama-2-7b, al leer "7b" sabes que el modelo tiene 7000 millones de parámetros.
Los parámetros de un modelo definen su comportamiento. Cuando entrenas un modelo desde cero, estos parámetros suelen ser inicialmente números aleatorios. A medida que entrenas el modelo en un conjunto de datos, estos parámetros se ajustan poco a poco hasta que el modelo refleja el conjunto de datos y muestra el comportamiento correcto. Algunos parámetros serán más importantes que otros, así que aplicamos una ponderación y la utilizamos para mostrar su mayor o menor relevancia. Las ponderaciones desempeñan un papel clave en la capacidad del modelo de captar patrones y relaciones en los datos con los que se entrena.
El ajuste tradicional ajustará todos los parámetros del modelo entrenado con un nuevo conjunto de ponderaciones. Como tal, un modelo ajustado requiere que le proporcionemos la misma cantidad de parámetros que el modelo original. Esto significa que el entrenamiento y la ejecución de la inferencia de un modelo completamente ajustado puede requerir mucho tiempo y muchos procesos. Además, periódicamente se lanzan nuevos modelos de última generación, o nuevas versiones de modelos existentes. Esto significa que el entrenamiento, el mantenimiento y el almacenamiento de los modelos totalmente ajustados puede resultar costoso.
LoRA es un método eficaz de ajuste
En términos más sencillos, LoRA evita ajustar los parámetros de un modelo entrenado previamente y, en su lugar, nos permite aplicar un pequeño número de parámetros adicionales. Estos se aplican temporalmente al modelo base para controlar eficazmente el comportamiento del modelo. En comparación con los métodos tradicionales de ajuste, entrenar estos parámetros adicionales, que denominamos adaptador LoRA, requiere mucho menos tiempo y menos recursos informáticos. Tras el entrenamiento, empaquetamos el adaptador LoRA como un archivo de modelo independiente que puede conectarse al modelo base a partir del cual se ha entrenado. Un modelo totalmente ajustado puede tener decenas de gigabytes, mientras que estos adaptadores suelen tener apenas unos pocos megabytes. Por ello, es mucho más fácil de distribuir, y el servicio de inferencia ajustada con LoRA sólo añade unos milisegundos de latencia al tiempo total de inferencia.
Si tienes curiosidad por entender por qué LoRA es tan eficaz, ¡prepárate! Primero toca una breve lección sobre álgebra lineal. Si no has pensado en este término desde la universidad, no te preocupes, te guiaremos.
Los cálculos
Con el ajuste tradicional, podemos tomar las ponderaciones de un modelo (W0) y ajustarlas para obtener un nuevo conjunto de ponderaciones, de modo que la diferencia entre las ponderaciones del modelo original y las nuevas ponderaciones sea ΔW, que representa el cambio en las ponderaciones. Por tanto, un modelo ajustado tendrá un nuevo conjunto de ponderaciones que puede representarse como las ponderaciones del modelo original más el cambio de las ponderaciones, W0 + ΔW.
Recuerda que todas estas ponderaciones del modelo se representan en realidad como grandes matrices de números. En matemáticas, todas las matrices tienen una propiedad llamada rango (r), que describe el número de columnas o filas linealmente independientes de una matriz. Cuando las matrices son de rango bajo, sólo tienen unas pocas columnas o filas que son "importantes", por lo que de hecho podemos descomponerlas o dividirlas en dos matrices más pequeñas con los parámetros más importantes (de forma similar a la factorización en álgebra). Esta técnica se denomina descomposición de rangos, y nos permite reducir y simplificar enormemente las matrices conservando los bits más importantes. En el contexto del ajuste, el rango determina cuántos parámetros cambian respecto al modelo original: cuanto más alto sea el rango, mayor será el ajuste, lo que te proporcionará más granularidad sobre el resultado.
Según el artículo original dedicado a LoRA, los investigadores han descubierto que cuando un modelo es de rango bajo, la matriz que representa el cambio en las ponderaciones también lo es. Por tanto, podemos aplicar la descomposición de rangos a nuestra matriz que representa el cambio en las ponderaciones ΔW para crear dos matrices más pequeñas A, B, donde ΔW = BA. Ahora, el cambio en el modelo puede representarse mediante dos matrices de rango bajo más pequeñas. Por eso este método de ajuste se denomina Low-Rank Adaptation.
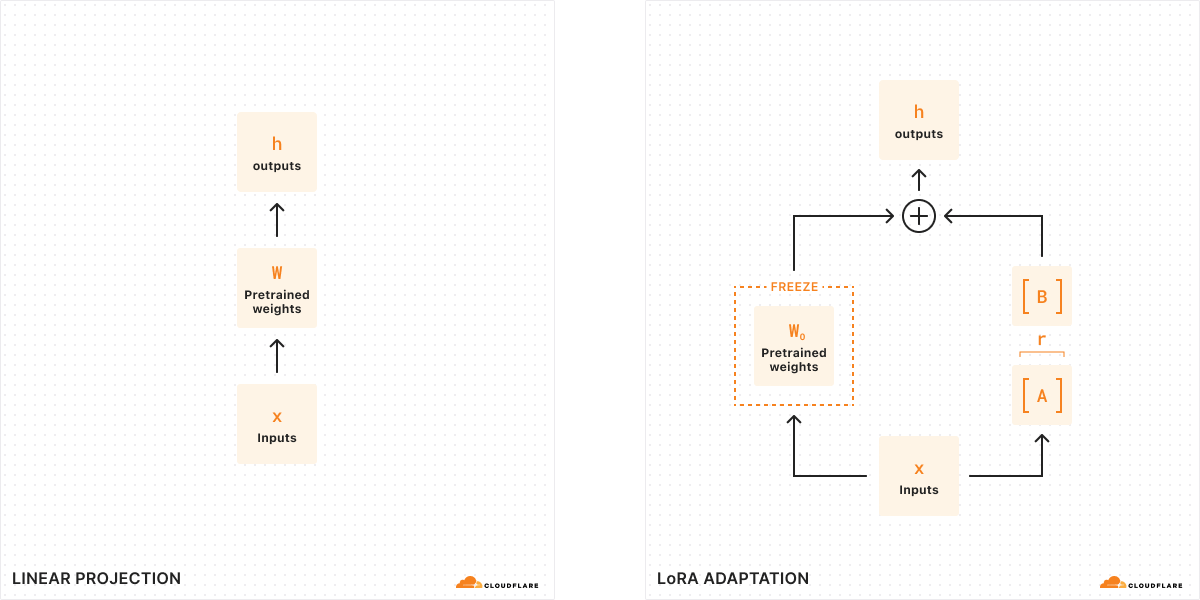
Cuando ejecutamos la inferencia, sólo necesitamos las matrices más pequeñas A, B para cambiar el comportamiento del modelo. Las ponderaciones del modelo en A, B constituyen nuestro adaptador LoRA (junto con un archivo de configuración). Durante la ejecución, sumamos las ponderaciones del modelo, combinando el modelo original (W0) y el adaptador LoRA (A, B). Sumar y restar son operaciones matemáticas sencillas, por lo que podemos intercambiar rápidamente distintos adaptadores LoRA sumando y restando A, B en W0 .. Mediante ajustes temporales de las ponderaciones del modelo original, modificamos el comportamiento y la salida del modelo y, como resultado, obtenemos una inferencia ajustada con una latencia adicional mínima.
Según el https://arxiv.org/abs/2106.09685artículo original dedicado a LoRA, LoRA puede reducir 10 000 veces el número de parámetros entrenables y 3 veces el requisito de memoria de GPU. Por ello, LoRA es uno de los métodos más populares de ajuste, ya que es mucho menos costoso a nivel de proceso que un modelo totalmente ajustado, no aumenta el tiempo de inferencia material y es mucho más pequeño y transferible.
¿Cómo puedes utilizar LoRA con Workers AI?
Workers AI es una plataforma muy adecuada para LoRA debido a la forma en que ejecutamos la inferencia sin servidor. Los modelos de nuestro catálogo siempre están cargados previamente en nuestras GPU, lo que significa que las mantenemos en caliente para que tus solicitudes nunca se encuentren con un arranque en frío. Por lo tanto, el modelo base está siempre disponible, y podemos cargar e intercambiar dinámicamente los adaptadores LoRA según sea necesario. De hecho, podemos conectar varios adaptadores LoRA a un modelo base, de modo que podemos atender varias solicitudes distintas de inferencia ajustada a la vez.
Cuando realices ajustes con LoRA, el resultado serán dos archivos: las ponderaciones de tu modelo personalizado (en formato safetensors) y un archivo de configuración del adaptador (en formato json). Para crear tú mismo estas ponderaciones, puedes entrenar un método LoRA con tus propios datos utilizando la biblioteca de Hugging Face PEFT (Parameter-Efficient Fine-Tuning) en combinación con la biblioteca de Hugging Face AutoTrain LLM. También puedes ejecutar tus tareas de entrenamiento en servicios como Auto Train y Google Colab. Como alternativa, actualmente hay muchos adaptadores LoRA de código abierto disponibles en Hugging Face que abarcan una gran variedad de casos de uso.
Con el tiempo, queremos admitir las cargas de trabajo de entrenamiento LoRA en nuestra plataforma, pero necesitamos que traigas tus adaptadores LoRA entrenados a Workers AI hoy mismo. Este es el motivo por el que hemos denominado esta función "Bring Your Own (BYO) LoRAs".
En la versión beta abierta inicial, puedes utilizar los adaptadores LoRA con nuestros modelos Mistral, Llama y Gemma. Hemos reservado versiones de estos modelos que aceptan los adaptadores LoRA, a las que puedes acceder añadiendo "-lora" al final del nombre del modelo. Tu adaptador debe haber sido ajustado a partir de uno de nuestros modelos base compatibles siguientes:
@cf/meta-llama/llama-2-7b-chat-hf-lora@cf/mistral/mistral-7b-instruct-v0.2-lora@cf/google/gemma-2b-it-lora@cf/google/gemma-7b-it-lora
Puesto que lanzamos esta función en la versión beta abierta, actualmente aún existen algunas limitaciones que debes tener en cuenta: los modelos LoRA cuantizados aún no se admiten, los adaptadores LoRA deben tener menos de 100 MB y un rango máximo de 8, y puedes probar hasta 30 adaptadores LoRA por cuenta durante nuestra versión beta abierta inicial. Para empezar a utilizar los adaptadores LoRA en Workers AI, consulte la documentación para desarrolladores.
Como siempre, esperamos que los usuarios utilicen Workers AI y nuestra nueva función BYO LoRA de acuerdo con nuestras condiciones del servicio, incluidas las restricciones de uso específicas de cada modelo que figuran en las condiciones de licencia correspondientes.
¿Cómo hemos desarrollado el servicio LoRA multiinquilino?
La implementación simultanea de varios modelos LoRA plantea un desafío en términos de utilización de los recursos de GPU. Aunque es posible procesar por lotes las solicitudes de inferencia enviadas a un modelo base, esto es mucho más complejo cuando se trata de solicitudes con la complejidad añadida de operar con adaptadores LoRA exclusivos. Para abordar este problema, utilizamos el diseño del núcleo Punica CUDA en combinación con optimizaciones globales de la caché para gestionar la carga de trabajo con un uso intensivo de memoria del servicio LoRA multiinquilino, ofreciendo al mismo tiempo una baja latencia de inferencia.
El núcleo Punica CUDA se presentó en el artículo Punica: Multi-Tenant LoRA Serving como un método para operar con múltiples modelos LoRA considerablemente distintos aplicados al mismo modelo base. En comparación con las técnicas de inferencia anteriores, el método ofrece mejoras sustanciales de rendimiento y latencia. Esta optimización se consigue, en parte, gracias al procesamiento por lotes de las solicitudes, incluso de solicitudes que operan con distintos adaptadores LoRA.
El sistema de núcleos Punica se basa en un nuevo núcleo CUDA denominado Segmented Gather Matrix-Vector Multiplication (SGMV). Con SGMV, una GPU puede almacenar sólo una copia del modelo entrenado previamente mientras opera con distintos modelos LoRA. El sistema de diseño del núcleo Púnica consolida el procesamiento por lotes de las solicitudes de modelos LoRA exclusivos a fin de mejorar el rendimiento, mediante la paralelización de la multiplicación de ponderaciones de las características de las distintas solicitudes de un lote. Las solicitudes del mismo modelo LoRA se agrupan para aumentar la intensidad operativa. Inicialmente, la GPU carga el modelo base reservando la mayor parte de su memoria GPU para la caché KV. Los componentes LoRA (las matrices A y B) se cargan bajo demanda desde el almacenamiento remoto (la caché de Cloudflare o R2) cuando lo requiere una solicitud entrante. Esta carga bajo demanda supone sólo unos milisegundos de latencia adicionales, por lo que se pueden obtener y servir sin problemas varios adaptadores LoRA sin que apenas afecte al rendimiento de la inferencia. Los adaptadores LoRA solicitados con más frecuencia se almacenan en la caché para que la inferencia sea lo más rápida posible.
Una vez que un adaptador LoRA solicitado se ha almacenado localmente en la caché, la velocidad a la que puede estar disponible para la inferencia sólo está limitada por el ancho de banda de PCIe. En cualquier caso, dado que cada solicitud puede requerir su propio adaptador LoRA, es fundamental que las descargas de LoRA y las operaciones de copia en memoria se realicen de forma asíncrona. El programador de Punica resuelve precisamente este desafío, procesando por lotes sólo las solicitudes que actualmente tienen las ponderaciones LoRA necesarias disponibles en la memoria de GPU, y poniendo en cola las solicitudes que no las tienen hasta que las ponderaciones necesarias estén disponibles y la solicitud pueda unirse eficazmente a un lote.
Mediante una gestión eficaz de la caché KV y el procesamiento por lotes de estas solicitudes, es posible gestionar una gran cantidad de cargas de trabajo del servicio LoRA multiinquilino. Otra optimización importante es el uso del procesamiento por lotes continuo. Los métodos más comunes de procesamiento por lotes requieren que todas las solicitudes enviadas al mismo adaptador entren en condición de parada antes de su liberación. Con el procesamiento por lotes continuo, una solicitud de un lote se puede liberar antes, de modo que no tiene que esperar a la solicitud que requiera más tiempo.
Dado que los LLM implementados en la red de Cloudflare están disponibles en todo el mundo, es importante que los modelos de adaptador LoRA también lo estén. En breve implementaremos archivos de modelos remotos almacenados en la caché en el perímetro de Cloudflare para reducir aún más la latencia de la inferencia.
Una hoja de ruta para el ajuste en Workers AI
El lanzamiento de la compatibilidad con los adaptadores LoRA es un paso importante para permitir los ajustes en nuestra plataforma. Además de los ajustes de LLM ya disponibles, esperamos poder admitir más modelos y diversos tipos de tareas, incluida la generación de imágenes.
Nuestro objetivo es que Workers AI sea la mejor plataforma para que los desarrolladores ejecuten sus cargas de trabajo de IA, y esto incluye el propio proceso de ajuste. Con el tiempo, queremos poder ejecutar el trabajo de entrenamiento de ajuste, así como modelos totalmente ajustados, directamente en Workers AI. Esto abre la puerta a muchos casos de uso para que la IA sea más relevante en las organizaciones, al posibilitar modelos con más granularidad y más detallados para tareas específicas.
Con AI Gateway, podremos ayudar a los desarrolladores a registrar sus preguntas y respuestas, que luego podrán utilizar para ajustar los modelos con los datos de producción. Nuestra visión es disponer de un servicio de ajuste con un solo clic, en el que los datos de registro de AI Gateway puedan utilizarse para volver a entrenar un modelo (en Cloudflare) y, a continuación, el modelo ajustado pueda volver a implementarse en Workers AI para la inferencia. De esta forma, los desarrolladores podrán personalizar sus modelos de IA para adaptarlos a sus aplicaciones, con una granularidad incluso a nivel de usuario. El modelo ajustado puede ser más pequeño y estar más optimizado, lo que ayudará a los usuarios a ahorrar tiempo y dinero en la inferencia de IA. Y lo mejor es que todo esto se puede lograr en nuestra propia plataforma para desarrolladores.
¡Estamos deseando que pruebes la versión beta abierta de BYO LoRA! Consulta nuestra documentación para desarrolladores para saber más y dinos qué te parece en Discord.