

Durante mi reciente visita al Computer History Museum (Museo de historia de los ordenadores) en Mountain View, me detuve a contemplar una antigua memoria de núcleos magnéticos.

Inmediatamente llegué a la conclusión de que no tenía ni idea de cómo funcionaban estas cosas. Me pregunté si los anillos rotaban (no lo hacen) y por qué cada anillo tenía tres cables entrelazados (y todavía no entiendo cómo funcionaban exactamente). Y lo que es más importante, me di cuenta de que apenas entendía el funcionamiento de la memoria moderna - RAM dinámica.
Particularmente, me interesaba una de las consecuencias del funcionamiento de la RAM dinámica. Verás, cada bit de datos se almacena por la carga (o falta de ella) en un pequeño condensador dentro del chip de la RAM. Pero estos condensadores pierden gradualmente su carga con el tiempo. Para evitar perder los datos almacenados, deben actualizarse regularmente para restaurar la carga (si existe) a su nivel original. Este proceso de actualización implica leer el valor de cada bit y luego reescribirlo. Durante este tiempo de "actualización", la memoria está ocupada y no puede realizar operaciones normales como cargar o almacenar bits.
Esto es algo que me ha preocupado durante cierto tiempo y me pregunté... ¿se puede percibir el retraso de la actualización en el software?
Manual básico de actualización de la RAM dinámica
Cada módulo DIMM está compuesto por «celdas» y «filas», «columnas», «lados» y/o «rangos». En esta presentación de la Universidad de Utah se explica la nomenclatura. Puede comprobar la configuración de la memoria en su ordenador con el comando decode-dimms. A continuación, un ejemplo:
$ decode-dimms
Size 4096 MB
Banks x Rows x Columns x Bits 8 x 15 x 10 x 64
Ranks 2
No vamos a entrar hoy en el formato completo de la DDR DIMM, solo necesitamos entender una sola celda de memoria, que almacena un bit de información. Específicamente, solo nos interesa cómo se realiza el proceso de actualización.
Vamos a revisar dos fuentes:
- Un Tutorial de actualización de DRAM, de la Universidad de Utah
- Y una impresionante documentación de una celda de 1 gigabit de micron: Diseño de TN-46-09 para DDR SDRAM de 1 GB
Cada bit almacenado en la memoria dinámica debe actualizarse, por lo general, cada 64 ms (lo que se conoce como actualización estática). Esta es una operación bastante costosa. Para evitar una paralización importante cada 64 ms, este proceso se divide en 8192 operaciones de actualización más pequeñas. En cada operación, el controlador de memoria del ordenador envía comandos de actualización a los chips de la DRAM. Después de recibir la instrucción, un chip actualizará 1/8192 de sus celdas. Si se hace el cálculo: 64 ms / 8192 = 7812,5 ns o 7,81 μs. Esto significa:
- Se emite un comando de actualización cada 7812,5 ns. Esto se llama tREFI.
- El chip necesita algo de tiempo para realizar la actualización y la recuperación, de modo que pueda realizar operaciones normales de lectura y escritura de nuevo. Este tiempo, llamado tRFC, es de 75 ns o 120 ns (según la hoja de datos mencionada de Micron).
Cuando la memoria está caliente (> 85° C), el tiempo de retención de memoria disminuye y el tiempo de actualización estática se reduce a la mitad, hasta 32 ms, y el tREFI desciende a 3906,25 ns.
Un chip de memoria típico está ocupado con actualizaciones durante una fracción significativa de su tiempo de ejecución: entre 0,4 % y 5 %. Además, los chips de memoria son responsables de una parte no menor del consumo de potencia típico de un ordenador, y gran parte de esa energía se emplea en la aplicación de las actualizaciones.
Durante la acción de actualización, se bloquea el chip de memoria completo. Esto significa que cada uno de los bits en la memoria se bloquea por más de 75 ns cada 7812 ns. Midámoslo.
Preparación de un experimento
Para medir las operaciones con una granularidad a nanosegundo, tenemos que escribir un bucle ajustado, tal vez en C. Se ve así:
for (i = 0; i < ...; i++) {
// Perform memory load. Any load instruction will do
*(volatile int *) one_global_var;
// Flush CPU cache. This is relatively slow
_mm_clflush(one_global_var);
// mfence is needed, otherwise sometimes the loop
// takes very short time (25ns instead of like 160). I
// blame reordering.
asm volatile("mfence");
// Measure and record time
clock_gettime(CLOCK_MONOTONIC, &ts);
}
El código completo está disponible en Github.
El código es realmente sencillo. Realizar una lectura de memoria. Limpiar datos de las memorias caché de la CPU. Medir tiempo.
(Nota: en el segundo experimento, intenté usar MOVNTDQA para realizar la carga de datos, pero esto requiere una página especial que no se pueda guardar en caché, y para ello se necesita acceso de administrador.)
En mi ordenador, genera datos como estos:
# timestamp, loop duration
3101895733, 134
3101895865, 132
3101896002, 137
3101896134, 132
3101896268, 134
3101896403, 135
3101896762, 359
3101896901, 139
3101897038, 137
Por lo general, obtengo ~ 140 ns por bucle, y la duración del bucle salta periódicamente a ~ 360 ns. A veces, obtengo extrañas lecturas superiores a 3200 ns.
Desafortunadamente, los datos resultan ser muy ruidosos. Es muy difícil ver si hay un retraso notable relacionado con los ciclos de actualización.
Transformada rápida de Fourier
En algún momento, tuve una idea. Ya que queremos encontrar un evento de intervalo fijo, podemos añadir los datos en el algoritmo FFT (transformada rápida de Fourier), que descifra las frecuencias subyacentes.
No soy el primero que pensó en esto. Mark Seaborn de Rowhammer implementó con notoriedad esta técnica en 2015. Incluso después de echarle un vistazo al código de Mark, conseguir que FFT funcionara resultó ser más difícil de lo esperado. Pero finalmente conseguí reunir todas las piezas.
Primero, tenemos que preparar los datos. FFT requiere que los datos de entrada se muestreen con un intervalo de muestreo constante. También queremos recortar los datos para reducir el ruido. Con el método de prueba y error, descubrí que los mejores resultados se producen cuando los datos están preprocesados:
- Los valores pequeños (menores que el promedio * 1,8) de iteraciones de bucle se eliminan, ignoran y sustituyen por lecturas de "0". No queremos incluir el ruido en el algoritmo.
- Todas las lecturas restantes se reemplazan por "1", ya que realmente no nos importa la amplitud del retraso que provoca el ruido.
- Fijé un intervalo de muestro de 100 ns, pero cualquier número hasta un valor de Nyquist (frecuencia doble esperada) también funciona bien.
- Los datos se deben muestrear con tiempos fijos antes de introducirlos en la FFT. Todos los métodos de muestreo razonables funcionan adecuadamente, y terminé realizando una interpolación lineal básica.
El algoritmo es parecido al siguiente:
$ decode-dimms
Size 4096 MB
Banks x Rows x Columns x Bits 8 x 15 x 10 x 64
Ranks 2
UNIT=100ns
A = [(timestamp, loop_duration),...]
p = 1
for curr_ts in frange(fist_ts, last_ts, UNIT):
while not(A[p-1].timestamp <= curr_ts < A[p].timestamp):
p += 1
v1 = 1 if avg*1.8 <= A[p-1].duration <= avg*4 else 0
v2 = 1 if avg*1.8 <= A[p].duration <= avg*4 else 0
v = estimate_linear(v1, v2, A[p-1].timestamp, curr_ts, A[p].timestamp)
B.append( v )
Que en mis datos produce un vector bastante aburrido como este:
[0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ...]
Sin embargo, el vector es bastante largo, normalmente con alrededor de 200 000 puntos de datos. Los datos preparados así ya están listos para introducirse en FFT.
C = numpy.fft.fft(B)
C = numpy.abs(C)
F = numpy.fft.fftfreq(len(B)) * (1000000000/UNIT)
Bastante simple, ¿verdad? Esto produce dos vectores:
- C contiene números complejos de los componentes de frecuencia. No nos interesan los números complejos, así que podemos aplanarlos al llamar a abs().
- F contiene las etiquetas de qué contenedor de frecuencia radica en qué lugar en el vector C. Tenemos que normalizarlo a Hz, multiplicándolo por la frecuencia de muestreo de los vectores de entrada.
El resultado se puede mostrar en un gráfico:
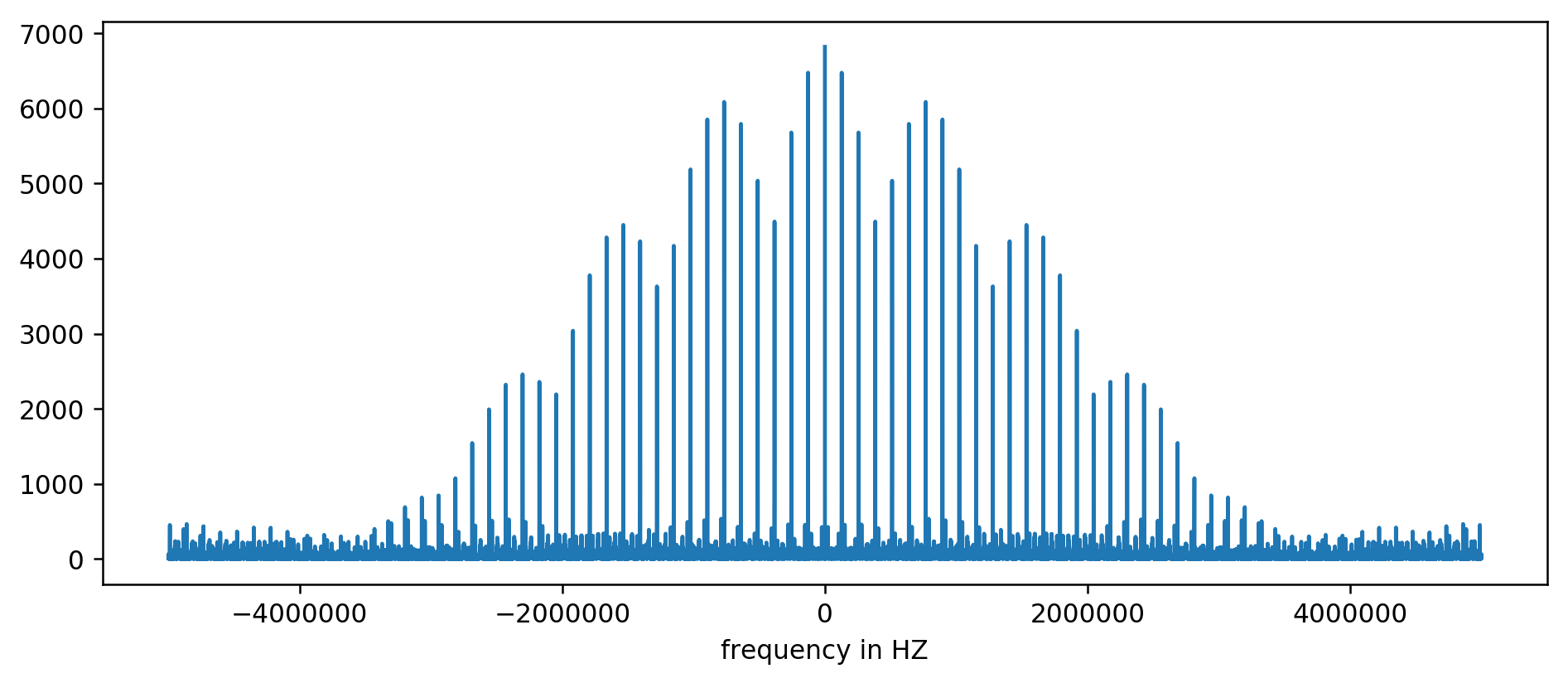
El eje Y no tiene unidad, ya que normalizamos los tiempos de retraso. Sin embargo, muestra picos claros en algunos intervalos de frecuencia fija. Ampliemos:
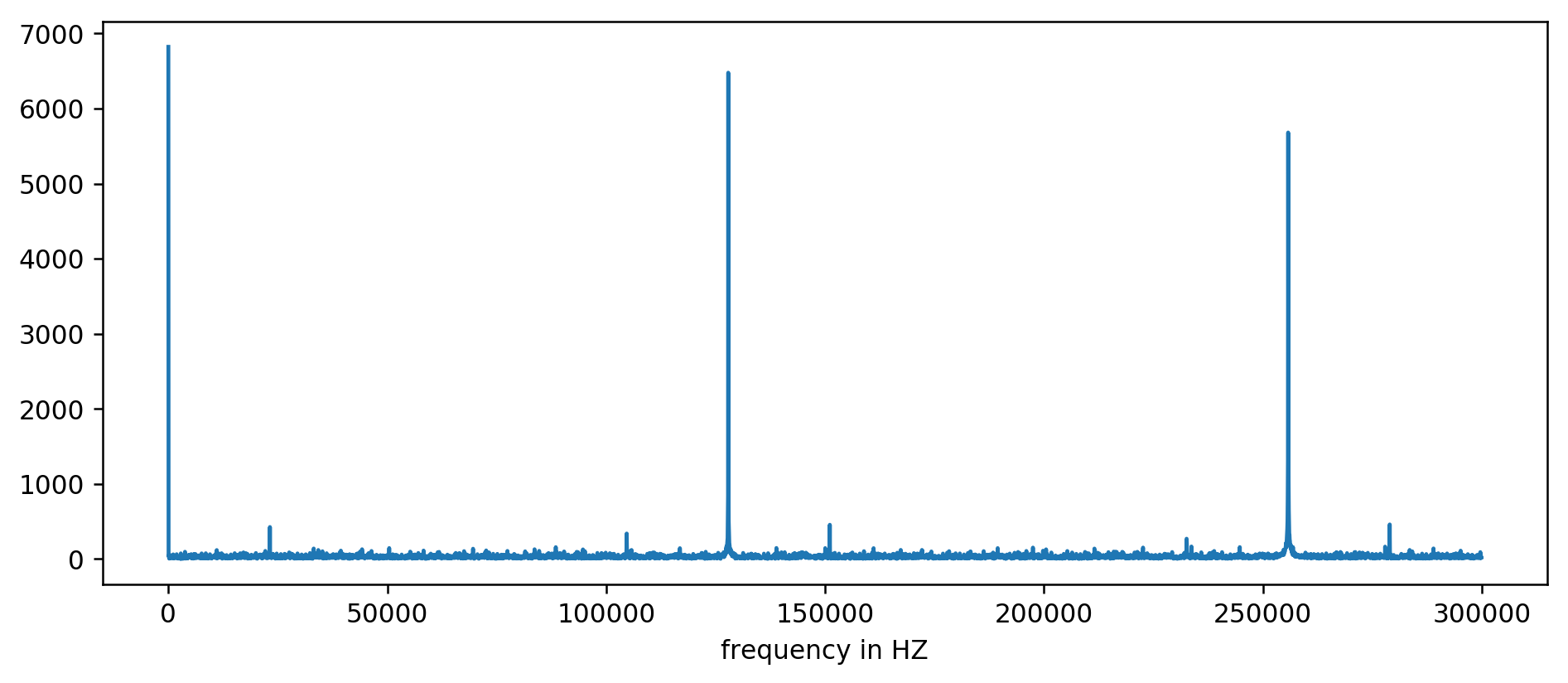
Primero, podemos ver tres picos claros. Después de un poco de insípida aritmética, con un filtrado de la lectura de al menos 10 veces el tamaño de la media, podemos extraer las frecuencias subyacentes:
127850.0
127900.0
127950.0
255700.0
255750.0
255800.0
255850.0
255900.0
255950.0
383600.0
383650.0
Si se hace el cálculo: 1000000000 (ns/s) / 127900 (Hz) = 7818,6 ns
¡Hurra! El primer pico de frecuencia es ciertamente lo que estábamos buscando y, de hecho, se correlaciona con los tiempos de actualización.
Los otros picos a 256 kHz, 384 kHz, 512 kHz, etc., son multiplicaciones de nuestra frecuencia base de 128 kHz, llamada armonía. Estos son un efecto secundario de realizar la FFT sobre algo parecido a una onda cuadrada, y es algo totalmente esperado.
Para una experimentación más sencilla, preparamos una versión de la línea de comando de esta herramienta. Usted mismo puede ejecutar el código. A continuación, una ejecución de muestra en mi servidor:
~/2018-11-memory-refresh$ make
gcc -msse4.1 -ggdb -O3 -Wall -Wextra measure-dram.c -o measure-dram
./measure-dram | python3 ./analyze-dram.py
[*] Verifying ASLR: main=0x555555554890 stack=0x7fffffefe2ec
[ ] Fun fact. I did 40663553 clock_gettime()'s per second
[*] Measuring MOVQ + CLFLUSH time. Running 131072 iterations.
[*] Writing out data
[*] Input data: min=117 avg=176 med=167 max=8172 items=131072
[*] Cutoff range 212-inf
[ ] 127849 items below cutoff, 0 items above cutoff, 3223 items non-zero
[*] Running FFT
[*] Top frequency above 2kHz below 250kHz has magnitude of 7716
[+] Top frequency spikes above 2kHZ are at:
127906Hz 7716
255813Hz 7947
383720Hz 7460
511626Hz 7141
Tengo que admitir que el código no es perfectamente estable. En caso de problemas, considere deshabilitar Turbo Boost, el escalado de frecuencia de la CPU y el ajuste para rendimiento.
Final
Se pueden sacar dos importantes conclusiones de este trabajo.
Hemos visto que los datos de nivel bajo son bastante difíciles de analizar y parecen ser bastante ruidosos. En lugar de tratar de averiguar algo a simple vista, siempre podemos emplear FFT. Se necesita algo de optimismo al preparar los datos.
Y lo que es más importante, mostramos que a menudo es posible medir los comportamientos sutiles de hardware de un proceso de espacio de usuario simple. Este tipo de pensamiento condujo al descubrimiento de la vulnerabilidad del Rowhammer original, se utilizó en ataques Meltdown/Spectre y se mostró de nuevo en la reciente reencarnación de la derrota de ECC de Rowhammer.
Queda tanto más por decir. Apenas hemos arañado la superficie del funcionamiento interno del subsistema de la memoria. Recomiendo lecturas adicionales:
- L3 cache mapping on Sandy Bridge CPUs
- How physical address maps to rows and banks in DRAM
- Hannu Hartikainen hacking DDR3 SO-DIMM to work... slower
Finalmente, aquí hay una buena lectura sobre la vieja memoria de núcleo magnético: