


La creación de modelos de lenguaje de gran tamaño (LLM) y modelos de difusión que impulsan la IA generativa requiere una infraestructura masiva. El componente más evidente es el proceso, que requiere entre cientos y miles de unidades de procesamiento de gráficos (GPU). Sin embargo, un componente igualmente crítico (y a menudo ignorado) es la infraestructura de almacenamiento de datos. Los conjuntos de datos de entrenamiento pueden tener un tamaño de terabytes a petabytes, y miles de procesos deben leer estos datos en paralelo. Además, los puntos de control del modelo se deben guardar con frecuencia durante la ejecución de entrenamiento, y en el caso de los LLM, cada uno de estos puntos de control puede ocupar cientos de gigabytes.
Para gestionar los costes de almacenamiento y la escalabilidad, muchos equipos de trabajo dedicados al aprendizaje automático se han pasado al almacenamiento de objetos para alojar sus conjuntos de datos y puntos de control. Por desgracia, la mayoría de los proveedores de almacenamiento de objetos utilizan tarifas de salida para "mantener" a los usuarios en su plataforma. Esta práctica dificulta el uso de la capacidad de la GPU en varios proveedores de nube, o la ventaja de aprovechar los precios más bajos o dinámicos de otros proveedores, ya que la transferencia de los datos y los puntos de control del modelo es demasiada cara. En un momento en el que escasean las GPU en la nube y se están incorporando nuevas opciones de hardware en el mercado, es más importante que nunca ser flexible.
Además de las elevadas tarifas de salida, existe un obstáculo técnico para el entrenamiento del aprendizaje automático basado en el almacenamiento de objetos. La lectura y la escritura de datos entre el almacenamiento de objetos y los clústeres de proceso requieren un alto rendimiento, un uso eficiente del ancho de banda de la red, determinismo y flexibilidad (la capacidad de entrenar en distintas GPU). La creación de un software de entrenamiento que gestione todo esto de forma correcta y fiable es difícil.
Hoy nos complace mostrar cómo el uso conjunto de las herramientas de MosaicML y Cloudflare R2 puede afrontar estos desafíos. En primer lugar, con las bibliotecas de código abierto StreamingDataset y Composer de MosaicML, puedes transmitir fácilmente datos de entrenamiento y leer/escribir puntos de control del modelo en R2. Todo lo que necesitas es una conexión a Internet. En segundo lugar, gracias a las tarifas gratuitas de ancho de banda de salida de R2, puedes iniciar/detener/mover/redimensionar trabajos en respuesta a la disponibilidad de la GPU y a los precios de los proveedores de proceso, sin pagar ninguna tarifa de transferencia de datos. La plataforma de entrenamiento MosaicML simplifica al máximo la organización de estos trabajos de entrenamiento en varias nubes.
Juntos, Cloudflare y MosaicML te dan la libertad de entrenar LLM en cualquier proceso, en cualquier parte del mundo, sin costes de conmutación. De esta forma, te beneficiarás de ejecuciones de entrenamiento más rápidas y más baratas, sin depender de proveedores.
"Con la plataforma de entrenamiento MosaicML, los clientes pueden utilizar R2 de manera eficaz como backend de almacenamiento duradero para entrenar LLM en cualquier proveedor de proceso, sin costes de salida. Las empresas de IA se enfrentan a unos costes exorbitantes en la nube, y están buscando herramientas que puedan proporcionarles la velocidad y la flexibilidad que necesitan para entrenar su mejor modelo al mejor precio".
– Naveen Rao, consejero delegado y cofundador, MosaicML
Lectura de datos desde R2 con StreamingDataset
Para leer datos desde R2 de forma eficiente y determinista, puedes utilizar la biblioteca StreamingDataset de MosaicML. En primer lugar, escribe tus datos de entrenamiento (imágenes, texto, vídeo, ¡lo que sea!) en archivos de partición `.mds` utilizando la API de Python proporcionada:
import numpy as np
from PIL import Image
from streaming import MDSWriter
# Local or remote directory in which to store the compressed output files
data_dir = 'path-to-dataset'
# A dictionary mapping input fields to their data types
columns = {
'image': 'jpeg',
'class': 'int'
}
# Shard compression, if any
compression = 'zstd'
# Save the samples as shards using MDSWriter
with MDSWriter(out=data_dir, columns=columns, compression=compression) as out:
for i in range(10000):
sample = {
'image': Image.fromarray(np.random.randint(0, 256, (32, 32, 3), np.uint8)),
'class': np.random.randint(10),
}
out.write(sample)
Una vez convertido tu conjunto de datos, puedes cargarlo a R2. A continuación, lo demostramos con la herramienta de línea de comandos `awscli`, pero también puedes utilizar `wrangler` o cualquier herramienta de tu elección compatible con S3. StreamingDataset también admitirá la escritura directa en la nube a R2 próximamente.
$ aws s3 cp --recursive path-to-dataset s3://my-bucket/folder --endpoint-url $S3_ENDPOINT_URL
Por último, puedes leer los datos en cualquier dispositivo que tenga acceso de lectura a tu bucket R2. Puedes capturar muestras individuales, configurar un bucle sobre el conjunto de datos e introducirlo en un cargador de datos PyTorch estándar.
from torch.utils.data import DataLoader
from streaming import StreamingDataset
# Make sure that R2 credentials and $S3_ENDPOINT_URL are set in your environment
# e.g. export S3_ENDPOINT_URL="https://[uid].r2.cloudflarestorage.com"
# Remote path where full dataset is persistently stored
remote = 's3://my-bucket/folder'
# Local working dir where dataset is cached during operation
local = '/tmp/path-to-dataset'
# Create streaming dataset
dataset = StreamingDataset(local=local, remote=remote, shuffle=True)
# Let's see what is in sample #1337...
sample = dataset[1337]
img = sample['image']
cls = sample['class']
# Create PyTorch DataLoader
dataloader = DataLoader(dataset)
StreamingDataset no necesita configuración, ofrece alto rendimiento, determinismo elástico, reanudación rápida y soporte multiworker. También utiliza funciones inteligentes de orden y difusión para garantizar que se minimiza el ancho de banda de descarga. A través de una variedad de cargas de trabajo como LLM y modelos de difusión, encontramos que no hay impacto en el rendimiento del entrenamiento (no hay cuello de botella en el cargador de datos) cuando se entrena desde almacenes de objetos como R2. Para más información, ¡consulta el blog del anuncio de StreamingDataset!
Lectura/escritura de puntos de control del modelo en R2 con Composer
La transmisión de datos en tu bucle de entrenamiento resuelve la mitad del problema, pero ¿cómo cargas/guardas los puntos de control de tu modelo? Por suerte, si utilizas una biblioteca de entrenamiento como Composer, es tan fácil como apuntar a una ruta R2.
from composer import Trainer
...
# Make sure that R2 credentials and $S3_ENDPOINT_URL are set in your environment
# e.g. export S3_ENDPOINT_URL="https://[uid].r2.cloudflarestorage.com"
trainer = Trainer(
run_name='mpt-7b',
model=model,
train_dataloader=train_loader,
...
save_folder=s3://my-bucket/mpt-7b/checkpoints,
save_interval='1000ba',
# load_path=s3://my-bucket/mpt-7b-prev/checkpoints/ep0-ba100-rank0.pt,
)
Composer utiliza cargas asíncronas para minimizar el tiempo de espera mientras se guardan los puntos de control durante el entrenamiento. También es fácil de usar, con entrenamiento multi-GPU y multinodos, y no requiere un sistema de archivos compartido. Esto significa que puedes omitir la configuración de un sistema EFS/NFS caro para tu clúster de proceso, ahorrando así miles de dólares o más al mes en nubes públicas. Todo lo que necesitas es una conexión a Internet y las credenciales adecuadas. Tus puntos de control llegan a salvo a tu bucket R2, lo que te proporciona un almacenamiento escalable y seguro para tus modelos privados.
MosaicML y R2 para ejecutar eficazmente trabajos de entrenamiento en cualquier lugar
El uso de las herramientas anteriores junto con Cloudflare R2 permite a los usuarios ejecutar cargas de trabajo de entrenamiento en cualquier proveedor de procesos, con total libertad y sin costes de conmutación.
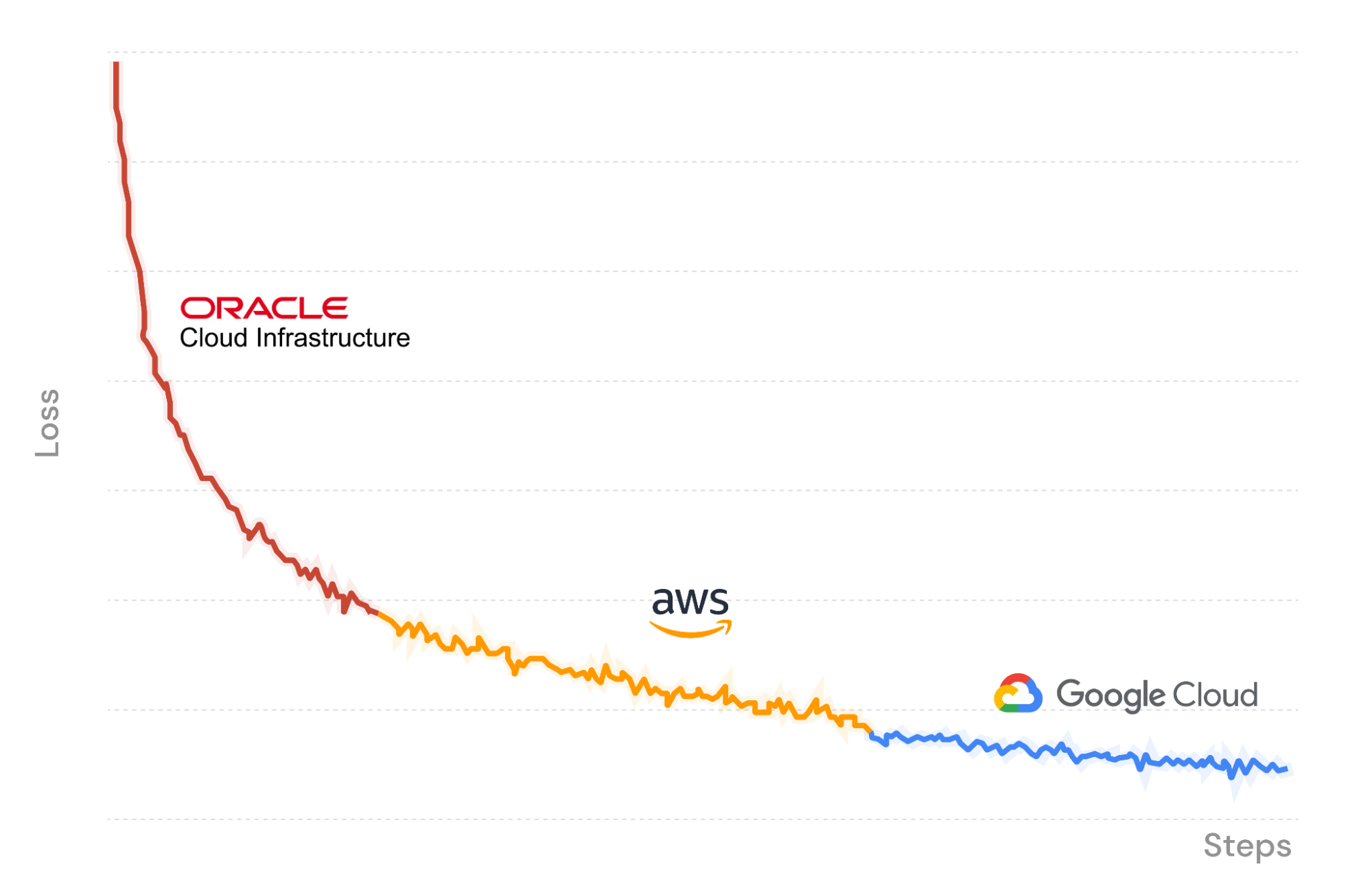
Como ejemplo, en la figura X utilizamos la plataforma de entrenamiento MosaicML para lanzar un trabajo de entrenamiento LLM que comienza en Oracle Cloud Infrastructure, con la transmisión de datos y la carga de puntos de control en R2. En el transcurso, interrumpimos el trabajo y lo reanudamos sin problemas en un conjunto diferente de GPU en Amazon Web Services. Composer carga las ponderaciones del modelo desde el último punto de control guardado en R2, y el cargador de datos de flujo se reanuda instantáneamente en el lote correcto. El entrenamiento continúa de forma determinista. Por último, nos trasladamos de nuevo a Google Cloud para finalizar la ejecución.
Como entrenamos nuestro LLM a través de tres proveedores de nube, los únicos costes que pagamos son los de proceso en la GPU y el almacenamiento de datos. ¡Sin tarifas de salida ni dependencias de proveedores gracias a Cloudflare R2!
$ mcli get clusters
NAME PROVIDER GPU_TYPE GPUS INSTANCE NODES
mml-1 MosaicML │ a100_80gb 8 │ mosaic.a100-80sxm.1 1
│ none 0 │ cpu 1
gcp-1 GCP │ t4 - │ n1-standard-48-t4-4 -
│ a100_40gb - │ a2-highgpu-8g -
│ none 0 │ cpu 1
aws-1 AWS │ a100_40gb ≤8,16,...,32 │ p4d.24xlarge ≤4
│ none 0 │ cpu 1
oci-1 OCI │ a100_40gb 8,16,...,64 │ oci.bm.gpu.b4.8 ≤8
│ none 0 │ cpu 1
$ mcli create secret s3 --name r2-creds --config-file path/to/config --credentials-file path/to/credentials
✔ Created s3 secret: r2-creds
$ mcli create secret env S3_ENDPOINT_URL="https://[uid].r2.cloudflarestorage.com"
✔ Created environment secret: s3-endpoint-url
$ mcli run -f mpt-125m-r2.yaml --follow
✔ Run mpt-125m-r2-X2k3Uq started
i Following run logs. Press Ctrl+C to quit.
Cloning into 'llm-foundry'...
Uso de la herramienta de línea de comandos MCLI para gestionar clústeres de proceso, secretos y enviar ejecuciones.
### mpt-125m-r2.yaml ###
# set up secrets once with `mcli create secret ...`
# and they will be present in the environment in any subsequent run
integrations:
- integration_type: git_repo
git_repo: mosaicml/llm-foundry
git_branch: main
pip_install: -e .[gpu]
image: mosaicml/pytorch:1.13.1_cu117-python3.10-ubuntu20.04
command: |
cd llm-foundry/scripts
composer train/train.py train/yamls/mpt/125m.yaml \
data_remote=s3://bucket/path-to-data \
max_duration=100ba \
save_folder=s3://checkpoints/mpt-125m \
save_interval=20ba
run_name: mpt-125m-r2
gpu_num: 8
gpu_type: a100_40gb
cluster: oci-1 # can be any compute cluster!
Una plantilla de trabajo MCLI. Especifica un nombre de ejecución, una imagen Docker, un conjunto de comandos y un clúster de proceso en el que ejecutarlo.
¡Empieza hoy mismo!
La plataforma MosaicML es una herramienta valiosa para llevar tu entrenamiento un paso más allá, y en esta publicación descubrimos cómo Cloudflare R2 te permite entrenar modelos con tus propios datos, con cualquier proveedor de procesos, o con todos ellos. Gracias a que no tiene tarifas de salida, el almacenamiento de R2 es un complemento muy rentable para el entrenamiento MosaicML, que proporciona la máxima autonomía y control. Con esta combinación, puedes cambiar entre proveedores de servicios en la nube para adaptarte a las necesidades de tu organización a lo largo del tiempo.
Si deseas más información sobre el uso de MosaicML para entrenar modelos de IA personalizados de última generación con tus propios datos, haz clic aquí o ponte en contacto con nosotros.