


Introducción
Hoy, 21 de junio de 2022, se ha producido una interrupción de los servicios de Cloudflare que ha afectado al tráfico en 19 de nuestros centros de datos. Desafortunadamente, estos 19 centros son los más grandes y manejan una proporción significativa de nuestro tráfico global. La interrupción fue causada por un cambio que formaba parte de un proyecto de larga duración para aumentar la resistencia de nuestras ubicaciones más grandes, ya que son una parte crítica de nuestra infraestructura y manejan una proporción significativa del tráfico de Cloudflare. Un cambio de la configuración de la red en estas ubicaciones provocó una interrupción que comenzó a las 06:27 UTC. A las 06:58 UTC restablecimos el servicio del primer centro de datos, y a las 07:42 UTC ya todos funcionaban correctamente.
Dependiendo de dónde te encuentres, es posible que no hayas podido acceder a sitios web y servicios que dependen de Cloudflare. En otros lugares, Cloudflare siguió funcionando con normalidad.
Lamentamos mucho esta interrupción. Ha sido un error nuestro y no el resultado de un ataque o una actividad maliciosa.
Antecedentes
Durante los últimos 18 meses, Cloudflare ha estado trabajando para implementar una arquitectura más redundante en todas nuestras ubicaciones más grandes. Hasta ahora, hemos implementado esta arquitectura, a la que llamamos internamente Multi-Colo PoP (MCP), en 19 de nuestros centros de datos: Ámsterdam, Atlanta, Ashburn, Chicago, Fráncfort, Londres, Los Ángeles, Madrid, Manchester, Miami, Milán, Bombay, Newark, Osaka, São Paulo, San José, Singapur, Sídney y Tokio.
Una parte crítica de esta nueva arquitectura, que está diseñada como red de Clos, es una capa añadida de enrutamiento que crea una malla de conexiones. Esta malla nos permite desactivar y activar fácilmente partes de la red interna de un centro de datos para su mantenimiento o para hacer frente a un problema. Esta capa está representada por las espinas en el siguiente diagrama.
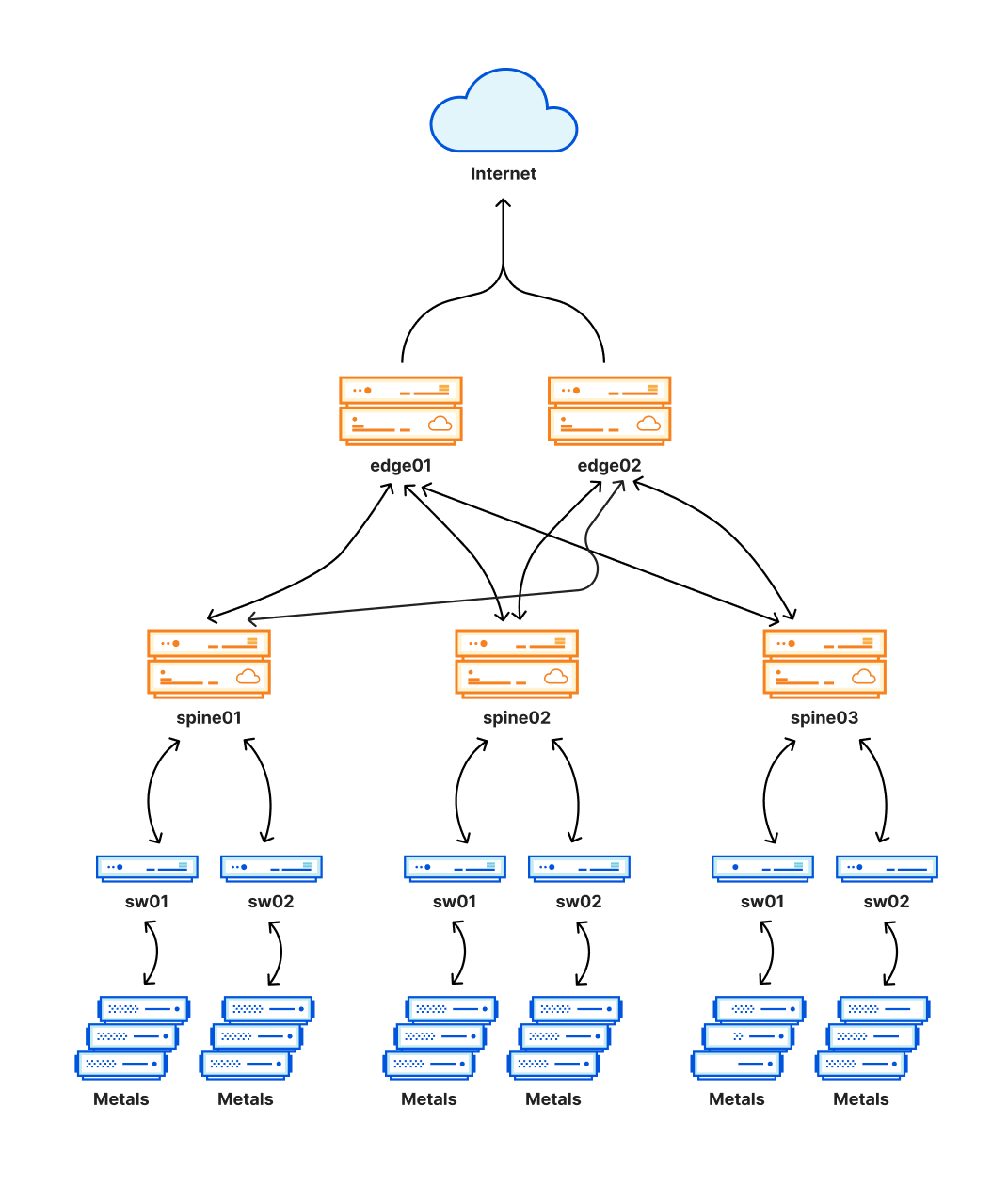
Esta nueva arquitectura nos ha proporcionado importantes mejoras en la fiabilidad, además de permitirnos realizar el mantenimiento en estas ubicaciones sin interrumpir el tráfico de los clientes. Como estas ubicaciones también alojan una proporción significativa del tráfico de Cloudflare, cualquier problema en ellas puede tener un impacto muy amplio y, desafortunadamente, eso es lo que ha ocurrido hoy.
Cronología (UTC) e impacto del incidente
Para que sea posible acceder a redes como Cloudflare por Internet, estas utilizan un protocolo que se llama BGP. Como parte de este protocolo, los operadores definen políticas que deciden qué prefijos (una colección de direcciones IP adyacentes) se anuncian a los pares (las otras redes a las que se conectan) o se aceptan de los pares.
Estas políticas tendrán componentes individuales, que se evalúan de forma secuencial. El resultado final es que los prefijos se anunciarán o no. Un cambio de política puede implicar que deje de anunciarse un prefijo previamente anunciado, en cuyo caso se retira y esas direcciones IP dejarán de ser accesibles por Internet.
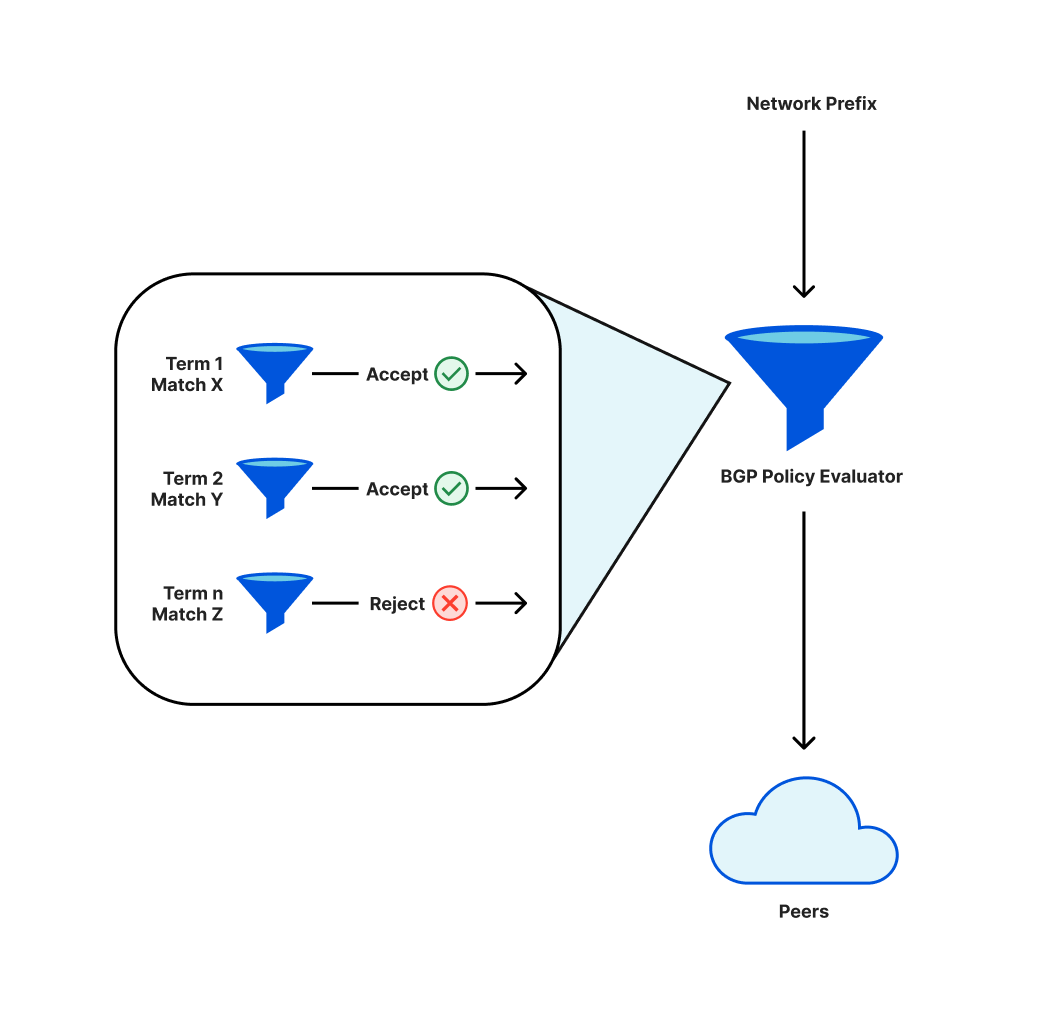
Al implementar un cambio en nuestras políticas de anuncio de prefijos, una reordenación de los términos nos hizo retirar un subconjunto crítico de prefijos.
Debido a esta retirada, los ingenieros de Cloudflare experimentaron una mayor dificultad para acceder a las ubicaciones afectadas para revertir el cambio problemático. Contamos con procedimientos de respaldo para manejar incidentes de este tipo y los utilizamos para tomar el control de las ubicaciones afectadas.
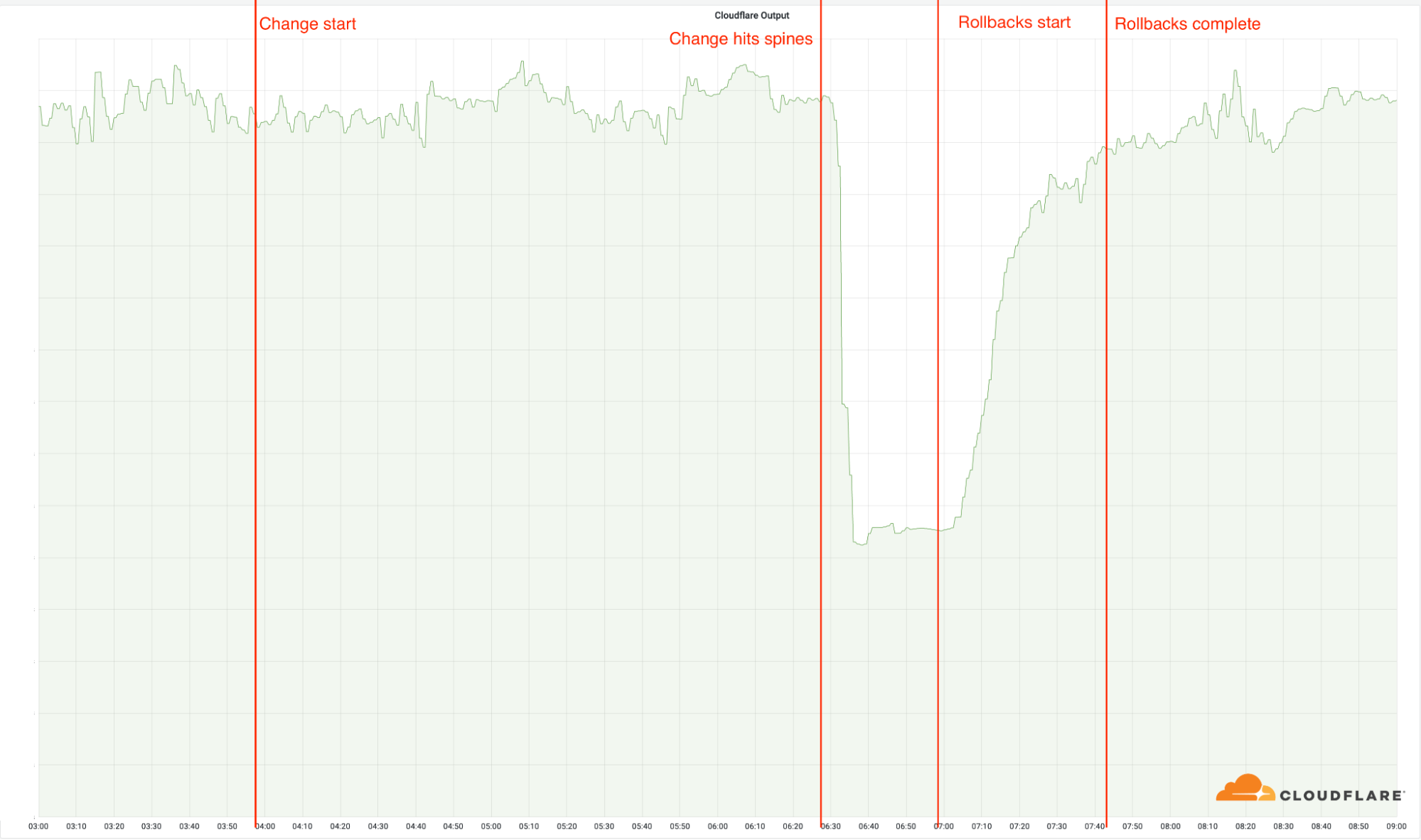
03:56: implementamos el cambio en nuestra primera ubicación. Ninguna de nuestras ubicaciones se ve afectada por el cambio, ya que estas utilizan nuestra arquitectura más antigua.
06:17: el cambio se implementa en nuestras ubicaciones más grandes, pero no en las ubicaciones con la nueva arquitectura.
06:27: la implementación llega a nuestras ubicaciones más grandes con la nueva arquitectura, y el cambio se implementa en nuestras espinas. Es entonces cuando comienza el incidente, ya que el cambio dejó rápidamente fuera de servicio a estas 19 ubicaciones.
06:32: se declara el incidente interno de Cloudflare.
06:51: se hace el primer cambio en un enrutador para verificar la posible causa principal.
06:58: se encuentra y comprende la causa principal. Comienza el trabajo para revertir el cambio problemático.
07:42: se completa la última de las reversiones. El proceso se retrasó porque los ingenieros de la red pasaron por encima de los cambios de los demás, revirtiendo las reversiones anteriores, lo que hizo que el problema reapareciera esporádicamente.
08:00: fin del incidente.
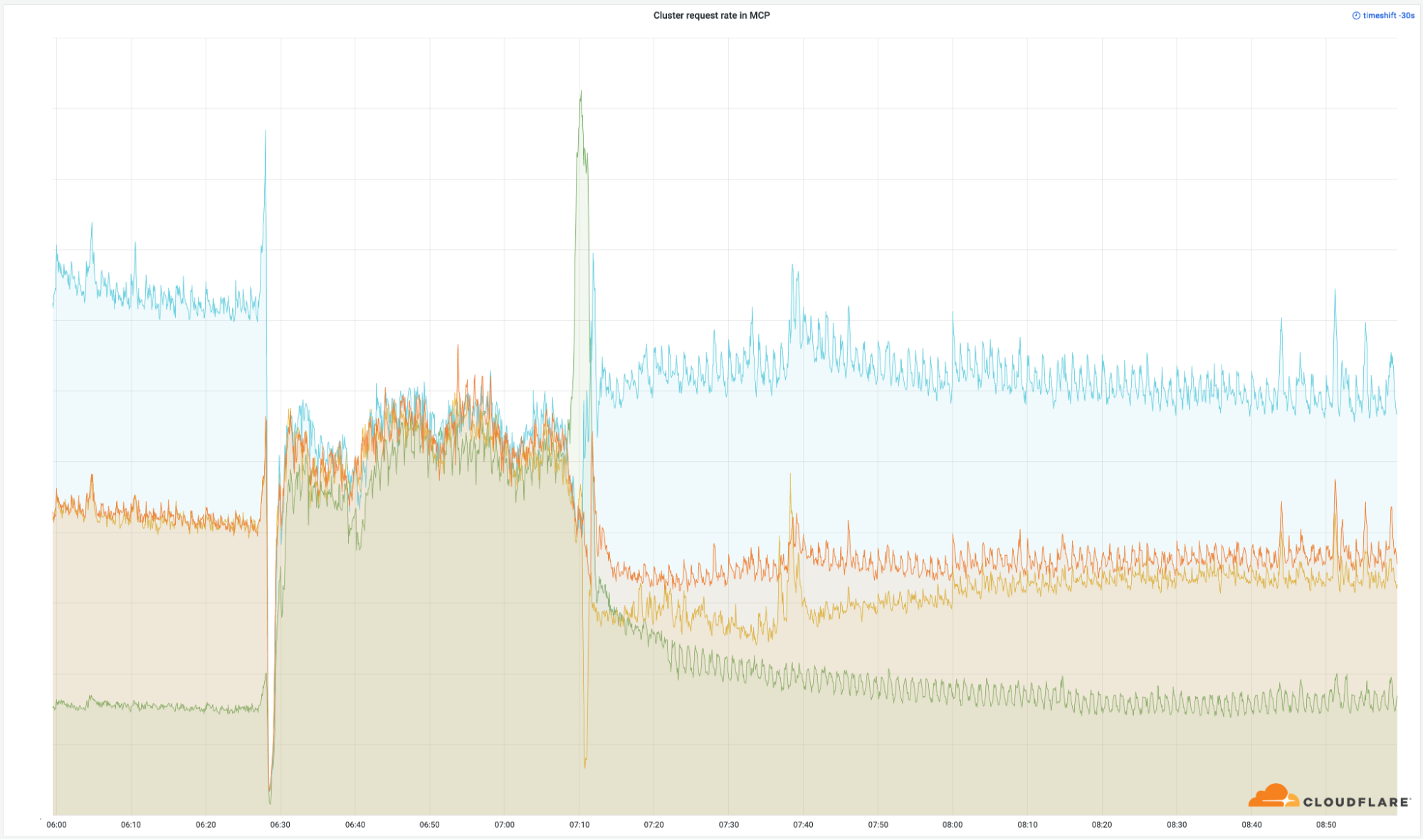
La importancia de estos centros de datos queda claramente demostrada por la cantidad de solicitudes que devolvimos con éxito a nivel mundial:
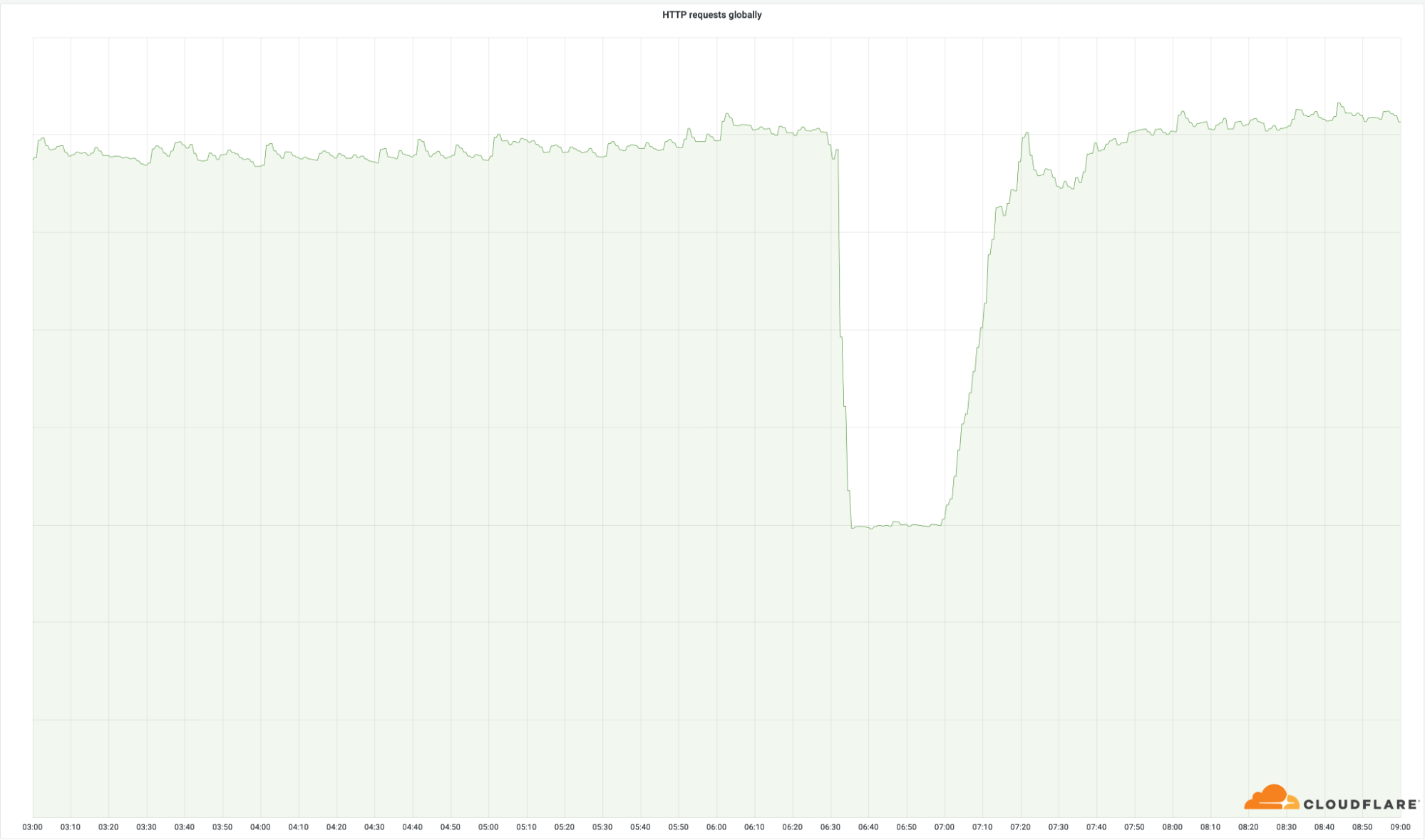
Aunque estas ubicaciones suponen únicamente un pequeño porcentaje de nuestra red total (el 4 %), afectamos el 50 % de nuestras solicitudes totales. Lo mismo puedes verse en nuestro ancho de banda de salida:
Descripción técnica del error y cómo ocurrió
Como parte de nuestro esfuerzo continuo por estandarizar la configuración de nuestra infraestructura, hemos introducido un cambio para estandarizar las comunidades BGP que adjuntamos a un subconjunto de los prefijos que anunciamos. Específicamente, añadimos comunidades informativas a nuestros prefijos locales de ubicación. Estos prefijos permiten que nuestros nodos de cálculo se comuniquen entre sí y se conecten a los orígenes de los clientes. Como parte del procedimiento de cambio en Cloudflare, se creó un ticket de solicitud de cambio, que incluye una prueba del cambio, así como un procedimiento de implementación por etapas. Múltiples ingenieros revisaron el cambio antes de realizarlo. Desafortunadamente, en este caso las etapas no fueron lo suficientemente pequeñas para detectar el error antes de que afectase a todas nuestras espinas.
El cambio tenía este aspecto en uno de los enrutadores:
[edit policy-options policy-statement 4-COGENT-TRANSIT-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
[edit policy-options policy-statement 4-PUBLIC-PEER-ANYCAST-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
[edit policy-options policy-statement 6-COGENT-TRANSIT-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
[edit policy-options policy-statement 6-PUBLIC-PEER-ANYCAST-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
Era inofensivo y solo añadía algo de información adicional a estos anuncios de prefijos. El cambio en las espinas fue el siguiente:
[edit policy-options policy-statement AGGREGATES-OUT]
term 6-DISABLED_PREFIXES { ... }
! term 6-ADV-TRAFFIC-PREDICTOR { ... }
! term 4-ADV-TRAFFIC-PREDICTOR { ... }
! term ADV-FREE { ... }
! term ADV-PRO { ... }
! term ADV-BIZ { ... }
! term ADV-ENT { ... }
! term ADV-DNS { ... }
! term REJECT-THE-REST { ... }
! term 4-ADV-SITE-LOCALS { ... }
! term 6-ADV-SITE-LOCALS { ... }
[edit policy-options policy-statement AGGREGATES-OUT term 4-ADV-SITE-LOCALS then]
community delete NO-EXPORT { ... }
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add AMS07;
+ community add EUROPE;
[edit policy-options policy-statement AGGREGATES-OUT term 6-ADV-SITE-LOCALS then]
community delete NO-EXPORT { ... }
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add AMS07;
+ community add EUROPE;
Un primer vistazo a este formato diff podría dar la impresión de que el cambio es idéntico, pero lamentablemente no es así. Si nos centramos en una parte de del diff, puede quedar claro el motivo:
! term REJECT-THE-REST { ... }
! term 4-ADV-SITE-LOCALS { ... }
! term 6-ADV-SITE-LOCALS { ... }
En este formato diff, los signos de exclamación delante de los términos indican la reordenación de los términos. En este caso, varios términos se desplazaron hacia arriba, y dos términos se añadieron a la parte inferior. En concreto, el término 4-ADV-SITE-LOCALS se desplazó de la parte superior a la inferior. Por tanto, este término quedó detrás del término REJECT-THE-REST, que en inglés significa “Rechazar el resto”. Tomando en cuenta esto, queda claro que este término es un rechazo explícito:
term REJECT-THE-REST {
then reject;
}
Como este término pasó a estar delante de los términos locales de ubicación, inmediatamente dejamos de anunciar nuestros prefijos locales de ubicación, eliminando nuestro acceso directo a todas las ubicaciones afectadas en un instante, así como la capacidad de nuestros servidores para llegar a los orígenes.
Además de la incapacidad de contactar con los orígenes, la eliminación de estos prefijos locales de ubicación también hizo que nuestro sistema interno de equilibrado de cargas Multimog (una variación de nuestro equilibrador de carga Unimog) dejara de trabajar, ya que no podía reenviar las solicitudes entre los servidores en nuestras MCP. Debido a esto, nuestros clústeres de computación más pequeños en una MCP recibieron la misma cantidad de tráfico que nuestros clústeres más grandes, por lo que se sobrecargaron.
Medidas de corrección y seguimiento
Este incidente tuvo una amplia repercusión, y nos tomamos la disponibilidad del servicio muy en serio. Hemos identificado varias áreas de mejora y seguiremos trabajando para descubrir cualquier otra brecha que pueda causar una repetición del incidente.
Estamos trabajando de forma inmediata en lo siguiente:
Proceso: aunque el programa de MCP se diseñó para mejorar la disponibilidad, una brecha de procedimiento en la forma de actualizar estos centros de datos acabó causando un impacto más amplio en las ubicaciones MCP específicamente. Aunque utilizamos un procedimiento por etapas para este cambio, la política de establecimiento de etapas no incluyó un centro de datos MCP hasta la última etapa. Los procedimientos de cambio y la automatización deben incluir procedimientos de prueba e implementación específicos de MCP para garantizar que no haya consecuencias imprevistas.
Arquitectura: la incorrecta configuración de los enrutadores impidió que se anunciasen las rutas adecuadas a nuestro perímetro, impidiendo que fluyera el tráfico correctamente a nuestra infraestructura. Finalmente, la declaración de la política que provocó el anuncio incorrecto de enrutamiento será rediseñada para evitar una ordenación incorrecta no intencionada.
Automatización: hay varias oportunidades en nuestro conjunto de automatización para mitigar parte o todo el impacto que hemos observado en este incidente. Principalmente, nos enfocaremos en mejoras de automatización que apliquen una política de establecimiento de etapas mejorada para implementaciones de configuración de red y ofrezcan una implementación automatizada “commit-confirm”. La primera mejora habría disminuido significativamente el impacto general y la segunda habría reducido mucho el tiempo de resolución del incidente.
Conclusión
Aunque Cloudflare ha invertido significativamente en nuestro diseño de MCP para mejorar la disponibilidad del servicio, claramente nos quedamos cortos con respecto a las expectativas de nuestros clientes con este incidente. Lamentamos muchísimo la interrupción que ocasionamos a nuestros clientes y todos los usuarios que no pudieron acceder a propiedades de Internet durante la interrupción. Ya hemos comenzado a trabajar en los cambios que se resumen más arriba y seguiremos esforzándonos por garantizar que esto no pueda ocurrir de nuevo.