


Los desarrolladores que crean aplicaciones Worker se centran en lo que están creando, no en la infraestructura necesaria, y se benefician del alcance global de la red de Cloudflare. Muchas aplicaciones requieren datos persistentes, desde proyectos personales hasta cargas de trabajo esenciales para el negocio. Workers ofrece varias opciones de bases de datos y almacenamiento adaptadas a las necesidades de los desarrolladores, como el almacenamiento de pares clave-valor y de objetos.
Las bases de datos relacionales son la red troncal de muchas aplicaciones actuales. D1, el complemento de base de datos relacional de Cloudflare, ya está disponible. Desde el lanzamiento de la versión alfa a finales de 2022 hasta la disponibilidad general en abril de 2024 nuestro objetivo ha sido que los desarrolladores pudieran crear cargas de trabajo de producción con la familiaridad de los datos relacionales y SQL.
¿Qué es D1?
D1 es la base de datos relacional sin servidor integrada en Cloudflare. Para las aplicaciones Worker, D1 ofrece la expresividad de SQL, utilizando el dialecto SQL de SQLite, e integraciones de herramientas para desarrolladores, incluidos ORM (Object-Relational Mapper) como Drizzle ORM. Se puede acceder a D1 a través de Workers o mediante una API HTTP.
"Sin servidor" significa recuperación tras desastre por defecto sin aprovisionamiento con Time Travel y precios basados en el uso. D1 incluye un generoso nivel gratuito que permite a los desarrolladores experimentar con D1 y luego pasar esas pruebas a producción.
¿Cómo globalizar los datos?
La versión de disponibilidad general de D1 se ha centrado en la fiabilidad y en la experiencia del desarrollador. Ahora tenemos previsto ampliar D1 para mejorar la compatibilidad con las aplicaciones distribuidas globalmente.
En el modelo Workers, una solicitud entrante invoca la ejecución sin servidor en el centro de datos más cercano. Una aplicación Worker puede escalar globalmente en función de las solicitudes de los usuarios. Sin embargo, los datos de la aplicación siguen almacenados en bases de datos centralizadas, y el tráfico global de los usuarios debe tener en cuenta los viajes de ida y vuelta de acceso a las ubicaciones de los datos. Por ejemplo, hoy en día una base de datos D1 reside en una única ubicación.
Workers admite Smart Placement para tener en cuenta la localización de los datos a los que se accede con frecuencia. Smart Placement invoca un Worker más cercano a los servicios backend centralizados, como las bases de datos, para reducir la latencia y mejorar el rendimiento de la aplicación. Nos hemos ocupado de la colocación de Workers en las aplicaciones globales, pero necesitamos resolver la colocación de los datos.
Por lo tanto, la pregunta es: ¿cómo puede D1, como solución de base de datos integrada de Cloudflare, mejorar la compatibilidad con la colocación de los datos para las aplicaciones globales? La respuesta es la replicación asíncrona de lectura.
¿Qué es la replicación asíncrona de lectura?
En un sistema de gestión de bases de datos basado en servidor, como Postgres, MySQL, SQL Server u Oracle, una réplica de lectura es un servidor de base de datos independiente que sirve como copia casi actualizada y de sólo lectura del servidor de base de datos primario. Un administrador crea una réplica de lectura iniciando un nuevo servidor a partir de una instantánea del servidor primario y configurándolo para que envíe las actualizaciones de forma asíncrona al servidor de réplica. Puesto que las actualizaciones son asíncronas, la réplica de lectura puede ir con retraso respecto al estado actual del servidor primario. La diferencia entre el servidor primario y una réplica se denomina retardo de réplica. Es posible tener más de una réplica de lectura.
La replicación asíncrona de lectura es una solución probada para mejorar el rendimiento de las bases de datos:
- Es posible aumentar el rendimiento distribuyendo la carga entre varias réplicas.
- Es posible reducir la latencia de las consultas cuando las réplicas están cerca de los usuarios que las envían.
Ten en cuenta que algunos sistemas de bases de datos también ofrecen replicación síncrona. En un sistema replicado síncrono, las escrituras deben esperar a que todas las réplicas hayan confirmado la escritura. Los sistemas replicados síncronos sólo pueden funcionar tan rápido como la réplica más lenta y se detienen cuando falla una réplica. Por tanto, si intentamos mejorar el rendimiento a escala global, ¡querremos evitar la replicación síncrona en la medida de lo posible!
Modelos de coherencia y réplicas de lectura
La mayoría de los sistemas de bases de datos proporcionan modelos de coherencia de lectura comprometida, aislamiento de instantáneas o serializables, dependiendo de su configuración. Por ejemplo, Postgres utiliza por defecto la lectura comprometida, pero puede configurarse para utilizar modos más estrictos. SQLite proporciona aislamiento de instantáneas en modo WAL. Es más fácil programar con los modos más potentes, como el aislamiento de instantáneas o el serializable, porque limitan los escenarios de concurrencia permitidos en el sistema y el tipo de condiciones de carrera de concurrencia de las que tiene que preocuparse el programador.
Las réplicas de lectura se actualizan independientemente, por lo que el contenido de cada réplica puede diferir en cualquier momento. Si todas tus consultas van al mismo servidor, ya sea el primario o una réplica de lectura, tus resultados deberían ser coherentes según el modelo de coherencia que proporcione tu base de datos subyacente. Si utilizas una réplica de lectura, puede que los resultados estén obsoletos.
En una base de datos basada en servidor con réplicas de lectura, es importante utilizar el mismo servidor para todas las consultas de una sesión. Si cambias entre distintas réplicas de lectura en la misma sesión, comprometes el modelo de coherencia que proporciona tu aplicación, ¡lo que puede violar tus suposiciones sobre cómo actúa la base de datos y hacer que tu aplicación devuelva resultados incorrectos!
Ejemplo
Por ejemplo, hay dos réplicas, A y B. El retardo de la réplica A con respecto a la base de datos primaria es de 100 ms, mientras que el de la réplica B es de 2 s. Supongamos que un usuario desea:
- Ejecutar la consulta 1
1a. Realizar algún cálculo basado en los resultados de la consulta 1 - Ejecutar la consulta 2 basándose en los resultados del cálculo de (1a)
En el tiempo t=10s, la consulta 1 va a la réplica A y vuelve. La consulta 1 ve cómo era la base de datos primaria en t=9,9s. Supongamos que tarda 500 ms en hacer el cálculo, así que en t=10,5s, la consulta 2 va a la réplica B. Recuerda que el retardo de la réplica B con respecto a la base de datos primaria es de 2 segundos, por lo que en t=10,5s, la consulta 2 ve el aspecto de la base de datos en t=8,5s. En lo que respecta a la aplicación, ¡según los resultados de la consulta 2 parece como si la base de datos hubiera retrocedido en el tiempo!
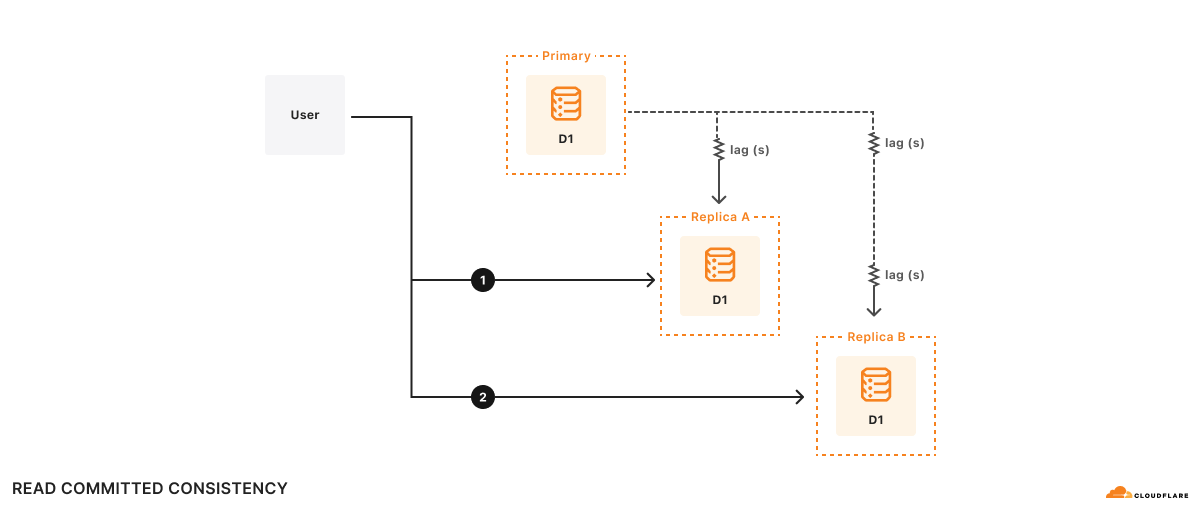
Formalmente, esto es la coherencia de lectura comprometida, ya que tus consultas sólo verán datos comprometidos, pero no hay ninguna otra garantía, ni siquiera que puedas leer tus propias escrituras. Aunque la lectura comprometida es un modelo de coherencia válido, es difícil razonar sobre todas las posibles condiciones de carrera que permite el modelo de lectura comprometida, lo que dificulta escribir correctamente las aplicaciones.
Modelo de coherencia y réplicas de lectura de D1
Por defecto, D1 proporciona el aislamiento de instantáneas que ofrece SQLite.
El aislamiento de instantáneas es un conocido modelo de coherencia que a la mayoría de los desarrolladores les resulta fácil de usar. Implementamos este modelo de coherencia en D1 garantizando que existe como máximo una copia activa de la base de datos D1 y enrutando todas las solicitudes HTTP a esa única base de datos. Aunque garantizar que haya como máximo una copia activa de la base de datos D1 es un problema complejo de los sistemas distribuidos, lo hemos resuelto desarrollando D1 con Durable Objects. Durable Objects garantiza la unicidad global, así que una vez que dependemos de Durable Objects, enrutar las solicitudes HTTP es fácil: basta con enviarlas a la base de datos D1 Durable Object.
Este truco no funciona si tienes varias copias activas de la base de datos, ya que no hay ninguna forma totalmente fiable de considerar una solicitud HTTP entrante genérica y enrutarla siempre a la misma réplica. Lamentablemente, como hemos visto en el ejemplo de la sección anterior, si no enrutamos siempre las solicitudes relacionadas a la misma réplica, el mejor modelo de coherencia que podemos ofrecer es el de lectura comprometida.
Dado que es imposible enrutar las solicitudes a una réplica concreta de forma coherente, otro enfoque es enrutar las solicitudes a cualquier réplica y garantizar que la réplica elegida responda a las solicitudes según un modelo de coherencia que "tenga sentido" para el programador. Si estamos dispuestos a incluir una marca de tiempo Lamport en nuestras solicitudes, podemos implementar la coherencia secuencial utilizando cualquier réplica. El modelo de coherencia secuencial tiene propiedades importantes como "leer mis propias escrituras" y "las escrituras siguen a las lecturas", así como una completa ordenación de las escrituras. Esta ordenación significa que todas las réplicas verán las transacciones confirmadas en el mismo orden, y este es exactamente el comportamiento que queremos en un sistema transaccional. La coherencia secuencial conlleva la limitación de que cualquier entidad individual del sistema puede estar arbitrariamente desactualizada. Sin embargo, esta limitación es una función útil para nosotros, ya que nos permite tener en cuenta el retardo de réplica al diseñar nuestras API.
La idea es que si D1 proporciona a las aplicaciones una marca de tiempo Lamport para cada consulta a la base de datos, y esas aplicaciones indican a D1 la última marca de tiempo Lamport que han observado, podemos hacer que cada réplica determine cómo hacer que las consultas funcionen según el modelo de coherencia secuencial.
Esta es una manera eficaz pero sencilla de implementar la coherencia secuencial con las réplicas:
- Asocia una marca de tiempo Lamport a cada solicitud a la base de datos. Un token de confirmación que se incremente monotónicamente funciona bien para esto.
- Envía todas las consultas de escritura a la base de datos primaria para garantizar la completa ordenación de las escrituras.
- Envía las consultas de lectura a cualquier réplica, pero haz que la réplica retarde atender la consulta hasta que la réplica reciba las actualizaciones de la base de datos primaria que sean posteriores a la marca de tiempo Lamport de la consulta.
La ventaja de esta implementación es que es rápida en el caso habitual de que una carga de trabajo de mucha lectura se dirija siempre a la misma réplica, y funcionará aunque las solicitudes se enruten a réplicas distintas.
Vista preliminar: añadimos la replicación de lectura a D1 con las sesiones
Para añadir la réplica de lectura a D1, ampliaremos la API de D1 con un nuevo concepto: las sesiones. Una sesión encapsula todas las consultas que representan una sesión lógica para tu aplicación. Por ejemplo, una sesión podría representar todas las solicitudes procedentes de un navegador web determinado o todas las solicitudes procedentes de una aplicación móvil. Si utilizas sesiones, tus consultas utilizarán la copia de la base de datos D1 que tenga más sentido para tu solicitud, ya sea la base de datos primaria o una réplica cercana. La implementación de las sesiones de D1 garantizará la coherencia secuencial de todas las consultas de la sesión.
Dado que la API de sesiones cambia el modelo de coherencia de D1, los desarrolladores deben activar la nueva API. Los métodos existentes de la API de D1 no han cambiado y seguirán teniendo el mismo modelo de coherencia de aislamiento de instantáneas que antes. Sin embargo, sólo las consultas enviadas mediante la nueva API de sesiones utilizarán las réplicas.
Aquí tienes un ejemplo de la API de sesiones de D1:
export default {
async fetch(request: Request, env: Env) {
// When we create a D1 Session, we can continue where we left off
// from a previous Session if we have that Session's last commit
// token. This Worker will return the commit token back to the
// browser, so that it can send it back on the next request to
// continue the Session.
//
// If we don't have a commit token, make the first query in this
// session an "unconditional" query that will use the state of the
// database at whatever replica we land on.
const token = request.headers.get('x-d1-token') ?? 'first-unconditional'
const session = env.DB.withSession(token)
// Use this Session for all our Workers' routes.
const response = await handleRequest(request, session)
if (response.status === 200) {
// Set the token so we can continue the Session in another request.
response.headers.set('x-d1-token', session.latestCommitToken)
}
return response
}
}
async function handleRequest(request: Request, session: D1DatabaseSession) {
const { pathname } = new URL(request.url)
if (pathname === '/api/orders/list') {
// This statement is a read query, so it will execute on any
// replica that has a commit equal or later than `token` we used
// to create the Session.
const { results } = await session.prepare('SELECT * FROM Orders').all()
return Response.json(results)
} else if (pathname === '/api/orders/add') {
const order = await request.json<Order>()
// This statement is a write query, so D1 will send the query to
// the primary, which always has the latest commit token.
await session
.prepare('INSERT INTO Orders VALUES (?, ?, ?)')
.bind(order.orderName, order.customer, order.value)
.run()
// In order for the application to be correct, this SELECT
// statement must see the results of the INSERT statement above.
// The Session API keeps track of commit tokens for queries
// within the session and will ensure that we won't execute this
// query until whatever replica we're using has seen the results
// of the INSERT.
const { results } = await session
.prepare('SELECT COUNT(*) FROM Orders')
.all()
return Response.json(results)
}
return new Response('Not found', { status: 404 })
}
La implementación de sesiones en D1 utiliza tokens de confirmación. Estos identifican una consulta confirmada determinada en la base de datos. En una sesión, D1 utilizará los tokens de confirmación para garantizar que las consultas se ordenan secuencialmente. En el ejemplo anterior, la sesión de D1 garantiza que la consulta "SELECT COUNT(*)" se realice después de la consulta "INSERT" de la nueva ordenación, aunque cambiemos las réplicas entre las esperas.
Tienes varias opciones para iniciar una sesión en un controlador de recuperación de Workers. db.withSession(<condition>) acepta estos argumentos:
Es posible hacer que una sesión abarque varias solicitudes si el token de confirmación de la última consulta de la sesión realiza un recorrido de ida y vuelta y se utiliza para iniciar una nueva sesión. Esto permite a los agentes de usuario individuales, como una aplicación web o una aplicación móvil, garantizar que todas las consultas que ve el usuario son secuencialmente coherentes.
La replicación de lectura de D1 estará integrada, no incurrirá en costes adicionales de uso o de almacenamiento ni requerirá configuración de las réplicas. Cloudflare supervisará el tráfico de D1 de una aplicación y creará automáticamente réplicas de la base de datos para distribuir el tráfico de los usuarios entre varios servidores en ubicaciones más cercanas a ellos. Al igual que con nuestro modelo sin servidor, los desarrolladores de D1 no deben preocuparse del aprovisionamiento ni de la gestión de las réplicas. Deben centrarse en diseñar aplicaciones que logren un equilibrio entre la replicación y la coherencia de los datos.
Estamos trabajando activamente en la replicación global de lectura y en hacer realidad la propuesta anterior (comparte tus comentarios en el canal #d1 de nuestro Discord para desarrolladores). Hasta entonces, la versión de disponibilidad general de D1 incluye varias novedades interesantes.
Echa un vistazo a la versión de disponibilidad general de D1
Hemos dado respuesta a las peticiones de los desarrolladores que solicitaban bases de datos más grandes. D1 admite ahora bases de datos de hasta 10 GB, con 50 000 bases de datos en el plan de pago de Workers. Con el escalado horizontal de D1, las aplicaciones pueden modelar casos de uso de base de datos por entidad empresarial. Desde la versión beta, las nuevas bases de datos D1 procesan 40 veces más solicitudes que las bases de datos D1 alfa en un periodo determinado.
Desarrolla a mayor escala con bases de datos más grandes
We’ve listened to developers who requested larger databases. D1 now supports up to 10GB databases, with 50K databases on the Workers Paid plan. With D1’s horizontal scaleout, applications can model database-per-business-entity use cases. Since beta, new D1 databases process 40x more requests than D1 alpha databases in a given period.
Importa y exporta datos masivos
Los desarrolladores importan y exportan datos por muchas razones:
- Pruebas de migración de bases de datos a/desde distintos sistemas de bases de datos
- Copias de datos para desarrollo local o pruebas
- Copias de seguridad manuales para requisitos personalizados como el cumplimiento
Aunque antes podías ejecutar archivos SQL en D1, estamos mejorando wrangler d1 execute –file=<filename> para garantizar que las importaciones grandes sean operaciones atómicas, que nunca salgan de tu base de datos en un estado intermedio. wrangler d1 execute también aplica ahora por defecto 'local-first' para proteger tu base de datos de producción remota.
Para importar nuestra base de datos de demostración Northwind Traders, puedes descargar el esquema y los datos y ejecutar los archivos SQL.
npx wrangler d1 create northwind-traders
# omit --remote to run on a local database for development
npx wrangler d1 execute northwind-traders --remote --file=./schema.sql
npx wrangler d1 execute northwind-traders --remote --file=./data.sql
Puedes exportar a un archivo SQL los datos y el esquema de la base de datos D1, solo el esquema o solo los datos, utilizando:
# database schema & data
npx wrangler d1 export northwind-traders --remote --output=./database.sql
# single table schema & data
npx wrangler d1 export northwind-traders --remote --table='Employee' --output=./table.sql
# database schema only
npx wrangler d1 export <database_name> --remote --output=./database-schema.sql --no-data=true
Depura el rendimiento de la consulta
Comprender el rendimiento de las consultas SQL y depurar las consultas lentas es un paso fundamental para las cargas de trabajo de producción. Hemos añadido la función experimental wrangler d1 insights para ayudar a los desarrolladores a analizar las métricas de rendimiento de las consultas, también disponibles mediante la GraphQL API.
# To find top 10 queries by average execution time:
npx wrangler d1 insights <database_name> --sort-type=avg --sort-by=time --count=10
Herramientas para desarrolladores
Varios proyectos de desarrolladores de la comunidad admiten D1. Las nuevas incorporaciones incluyen Prisma ORM, en la versión 5.12.0, que ahora admite Workers y D1.
Pasos siguientes
Las funciones disponibles ahora con la versión GA y nuestro diseño de la replicación global de lectura son sólo el principio de la entrega de la base de datos SQL que los desarrolladores de aplicaciones necesitan. Si aún no has utilizado D1, puedes empezar ahora mismo, visitar la documentación para desarrolladores de D1 para sacar algunas ideas, o unirte al canal #d1 en nuestro Discord para desarrolladores para hablar con otros desarrolladores de D1 y con nuestro equipo de ingeniería de producto.
